
Abstract
The examination of the Elliott Wave theory is the main motivation of this contribution. All of the fundamental features of an proper Elliott Wave pattern (EW pattern) are reviewed and explained. Based on this knowledge, an algorithm for detection of these patterns is designed, developed and tested. Under several different algorithm settings, several EW pattern sets are obtained. They differ in amount of found EW patterns, quality and size.
The following application of the developed detection algorithm was based on recognition of an incomplete EW patterns with aim of the prediction of the following progress of the time set. The Random Decision Forest and the Support Vector Machine are the machine learning algorithms employed for this task. The accuracy of trend prediction above 70% proves the relevancy of EW patterns on stock market data as well as the validity of the algorithm as a tool for detection of such patterns.
Introduction
The behavior of stock market price is a reflection of complex interactions of multiple underlined processes like political statements, macroeconomic situation, news, investors psychology, previous behavior of the price itself, etc. These interactions bring huge amount of noise, uncertainty and non-rational moves into the price progress which makes it difficult to forecast.
The Efficient Market Hypothesis (EMH) is one of the most known ideology connected with predictability of the stock market price behavior [1]. EMH simply denies its possibility. Market price, in the view of this hypothesis, is an absolutely rational reflection of all inner and outer influences as well as all available information without any misunderstandings or misinterpretations. Such a statement describes the market as unpredictable. Because EMS contains several empirical drawbacks [2] and also some very first attempts proved that well designed predictive model is able to proceed much better forecasting [3, 4, 5] than random walk [6], the market is mostly not considered as fully efficient and unpredictable.
There are many high quality studies aiming into this topic with application of ML [7, 8, 9]. The movement prediction with widely known Support Vector Machine obtained interesting results in study of Huang et al. [10]. The application of neuro-fuzzy system in the study of Atsalakis et al. [11] brought results of comparable quality. The next proposal combining the Genetic Algorithm and Support Vector Machine was tested also with success in study of Choudhry [12]. The application of robust random number generator showed its purpose in several studies [13, 14] and also experiment proposed in this contribution relies on application of Mersenne Twister approach [15]. All of these models faced with different conditions (time series length, chosen markets, length of forecast, etc.) but most of them comes with similar results which confirms the difficulty of forecasting of the stock market direction.
Up-trending (right) and down-trending (left) waves recognized on EURUSD market with 15 minute time scale and 10% tolerance.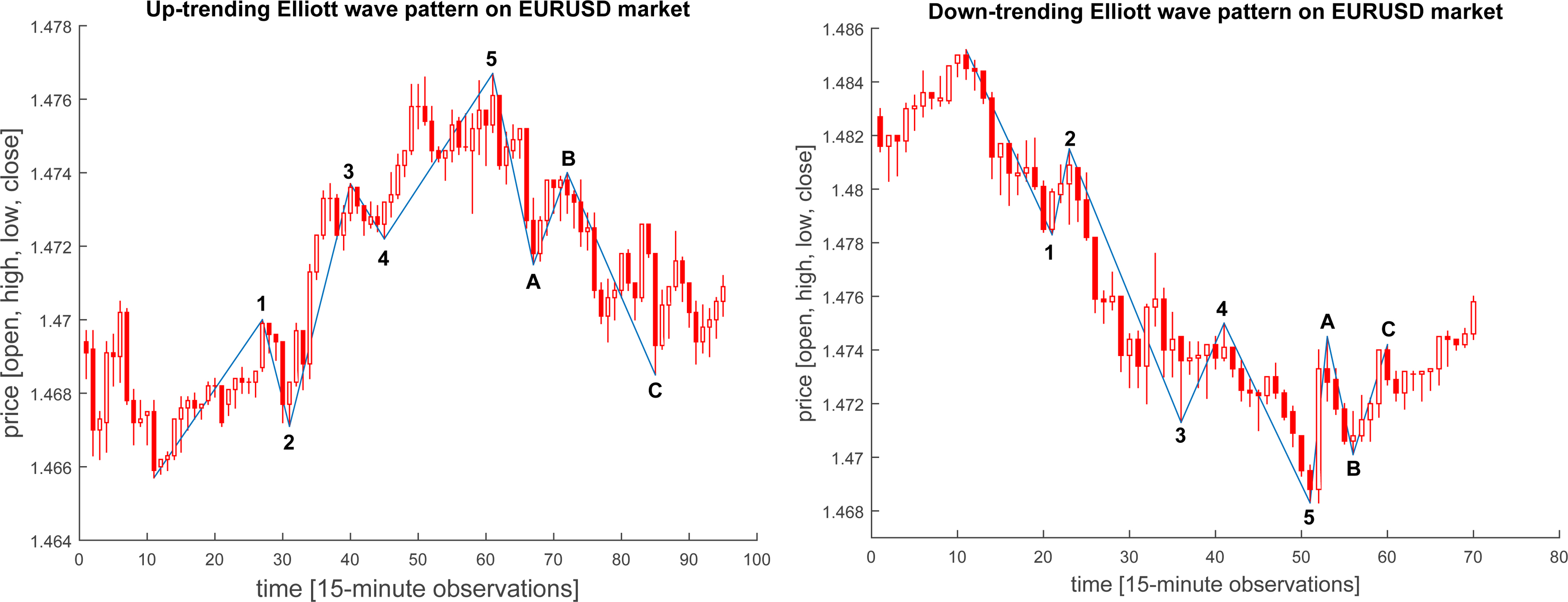
The high quality reviewing study brought by Soni [16]
concludes the strong predictive ability of Artificial Neural Network as a computational model in this task. In [17], Atsalakis and Valavanis conclude that soft-computing models such as ANN and Neuro-fuzzy models are able to outperform the conventional models in most cases, as well as the study by Yoo et al. [18]. The wider review brought by Enke and Thawornwong [19] describes also the influence of statistical relations between different economic variables valuable for the forecasting.
Based on these studies, the market can be definitely considered as a predictable as well as by the proposal of Elliott, which brought the theory of Elliott Wave patterns in 1946 [20]. He described how every stock market repeats itself in some predictable patterns, so called waves. The application of Elliott waves, recognized by Artificial Neural network proposed by Volna et al. [21] includes several tests for its predictability performance as well.
This paper describes our algorithm for EW pattern detection, that is based on hard-coded rules. The information background of the EW’s theory, the work-flow of the algorithm as well as the platform ans programming language are covered in the first part of the paper. The following parts describe the experimental application of the algorithm on real stock market data. The EW patterns are extracted on several different adjustments and they are examined on the fitting to the defined rules. In the further step, the selected patterns serve as input values for the trend prediction models based on machine learning algorithms. The final discussion covers advantages and disadvantages of the model as well as the future research.
UML diagram of EW pattern detection algorithm. Described process examines all IFs in a given time set window and returns the matrix of found EW patterns with their fitness values.
This theory defines the basic pattern of five motive and three corrective waves, which appears in both trend directions, bearish and bullish. These patterns posse the feature of “self-similarity”, which means that the same pattern can be observed in sub-parts of the entire EW. This feature is a sign of fractal behavior of the EW’s pattern. The form of the waves is very consistent and it follows Fibonacci’s ratios, which is one of the major guide line of their detection.
This proposal of Elliott Waves (EW) is still an active area of study and it was reviewed and extended by many authors [22, 23]. The EW’s patterns were many times the motivation of application of algorithmic pattern recognition based on fuzzy logic or artificial neural networks [24, 21]. The proper identification of the actual wave can be considered as the ideal tool for prediction of the future price move and final profit target placement [25, 26].
For proper indentification of the EW pattern, it has to be considered three major rules [22, 23]
The second wave never ends below the starting point of the first wave. The third wave is never the shortest wave. The wave four never ends in the price are of the fist wave.
and rules based on Fibonacci ratio’s.
The length of wave 2 is from 50% to 62% of the wave 1. The wave 3 can be 1.62, 2.62 or 4.25 longer than wave 1. The wave 4 is retracing from 24% to 38% of the wave 3. The wave 5 is the multiplication of 1, 1.62 or 2.62 and wave 1. The wave A is almost equally length as the wave 5. The wave B is retracing from 50% to 76.8% of the wave A. The wave C can be length of 0.62, 1 or 1.62 times wave A.
The EW detection algorithm described in this study is based on hard-coded rules with adjustable set of coefficients representing fuzzy tolerances in pattern detection process. The UML diagram of the algorithm is depicted in Fig. 2.
Up initiating fractals examples, source “Trading Chaos” [27].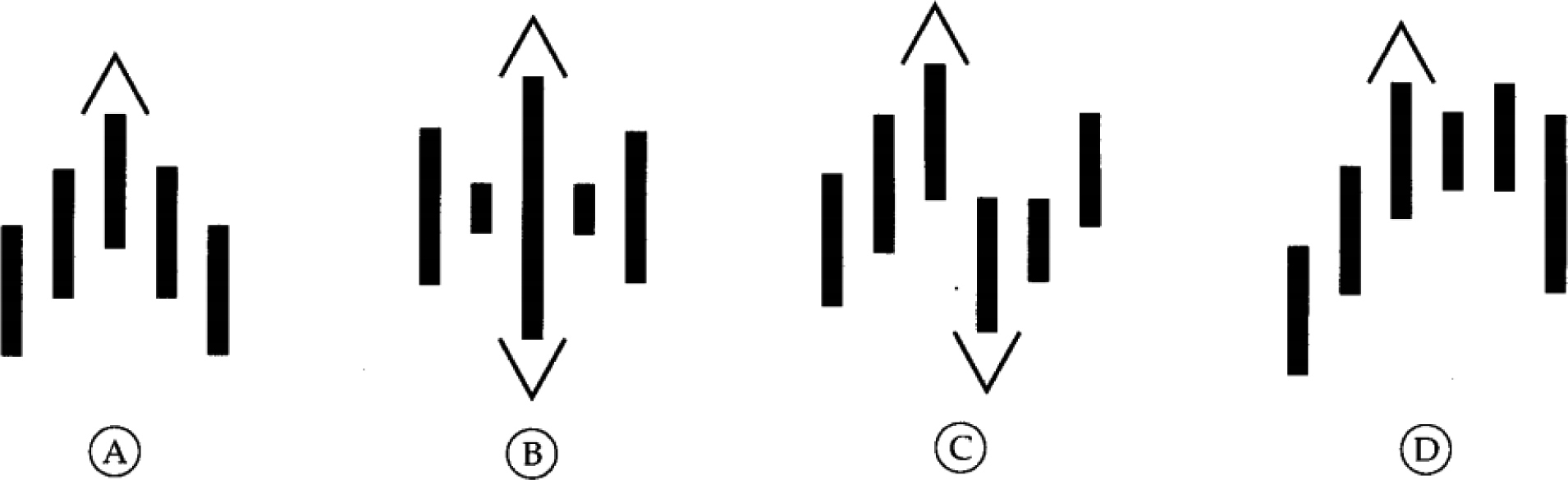
There are several very important variables that serves as the inputs of the algorithm. The first is the vector
At the start of the process there are initialized two vectors
Pattern selection
Up-trending EW starts in the down IF, therefore the process iterates all of the indexes from
The process comes through both local extremes to complete the entire wave pattern and in every time the process looks for the best matching opposite extreme which can fit to the defined rules with adjusted level of tolerance. The application of tolerances can be generically described by following equations.
where
Every time the fractal structure can be connected to more possible fractal structures and all of this combinations are stored in stack and used in next step as valid sub-waves. When the fractal can not connect to its next follower, the entire sub-wave in deleted from the stack. During every step, some of the sub-waves which can grow multiple ways are multiplied and others, which are not able to grow anywhere are removed. When the last fractal is added into the sub-pattern, the complete EW is found (under the certain level of tolerance) and it is saved in the output matrix M. In the end of the process, the matrix M can contain similar and overlapping patterns which has to be handled before the process terminates.
Up-trending (right) and down-trending (left) waves recognized on EURUSD market with 15 minute time scale and 10% tolerance.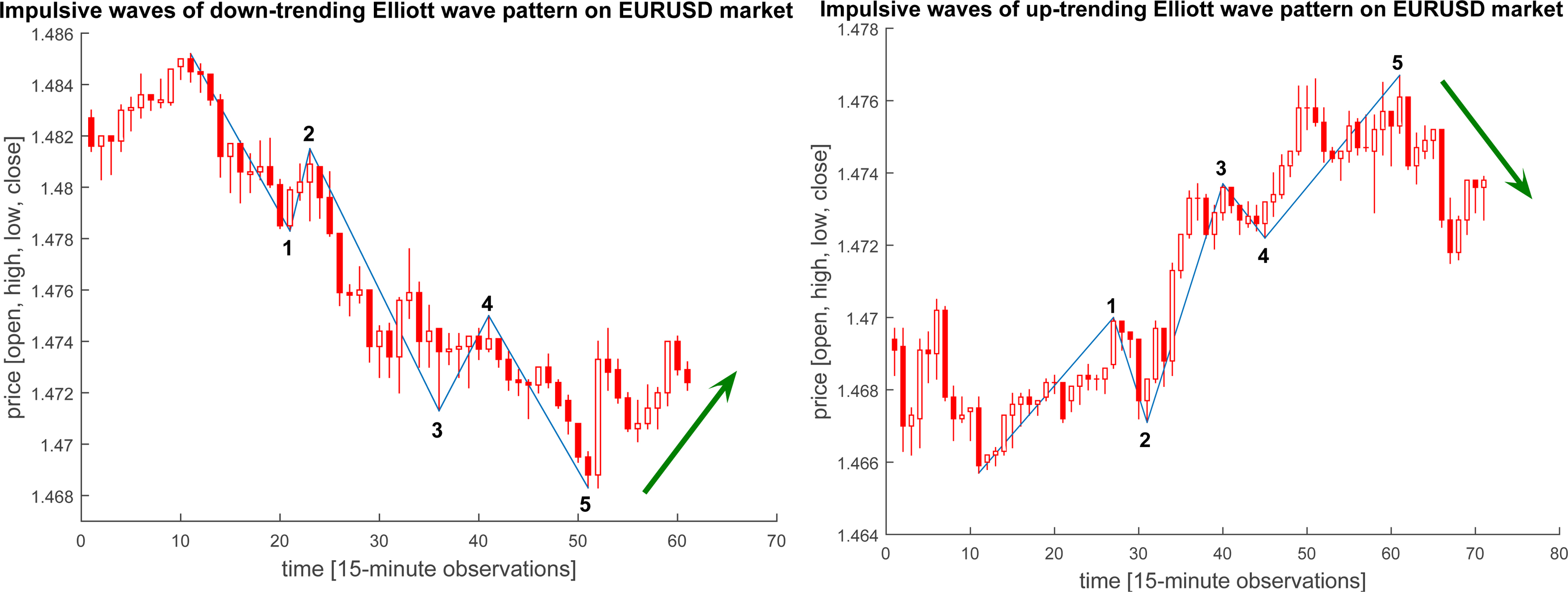
Rows of the matrix M represent the found EW patterns and columns are the indexes of each of the waves (including the starting point). Some of the rows differs only in few indexes and some of the rows represents patterns which are overlapped. From every group of similar or overlapped patterns it should be saved only one which fits the EW pattern’s conditions the most.
It is computed the cost function of each of the pattern, which is the averaged difference in percentage between found (real) Fibonacci ratio (
where
MATLAB served as a programming language and integrated development environment (IDE) for purposes of implementation and testing of the entire experiment. The source code is provided as an open-source package available for further testing and applications for free [28].
Our experiments were executed on basic PC configuration (4x cpu and 8 GB RAM) with application of parallel environment that is supported by proper design of EW detector.
Experimental applications
The first part of the experiment focuses on EW pattern extraction and evaluation of the few basic statistical features of the found patterns. The following part is an evaluation of the impact on the predictable performance of the ML models by application of extracted patterns. The Support Vector Machine (SVM) and Random Decision Forest (RF) were applied algorithms for this trend prediction. The incomplete EW patterns (1-2-3-4 and 1-2-3-4-5) of price values were the input values of these algorithms. The output value of the algorithms were only binary values where 1/0 stands for prediction of up/down-trend (average price of
Data acquisition
The stock market data were obtained from public sources. The data is in format of one-minute measurement for MetaTrader platform [29]. It contains the price behavior of GOLD (XAG/USD) from 2011-01-01 to 2015-12-31, SILVER (XAU/USD) from 2011-01-01 to 2015-12-31 and currency pair EURUSD (EUR/USD) from 2005-01-01 to 2015-12-31. These market titles were chosen because the higher amount of trades performed on these titles and free availability of data to study.
Each observation contains open, high, low, close price and traded volume of the commodity. The time series contain more than 2 millions observations in case of GOLD and SILVER and in case of the currency pair, it was more than 4 million observations (ticks). Because of the assumption of possible application of EW’s fractality (ability to be recognized on all of the time-scales), the time series were transformed also into 10-minute, 15-minute and 1-hour time series.
Graphical interpretation of Optimal Separating Hyperplane between separated observations of SVM classification [35].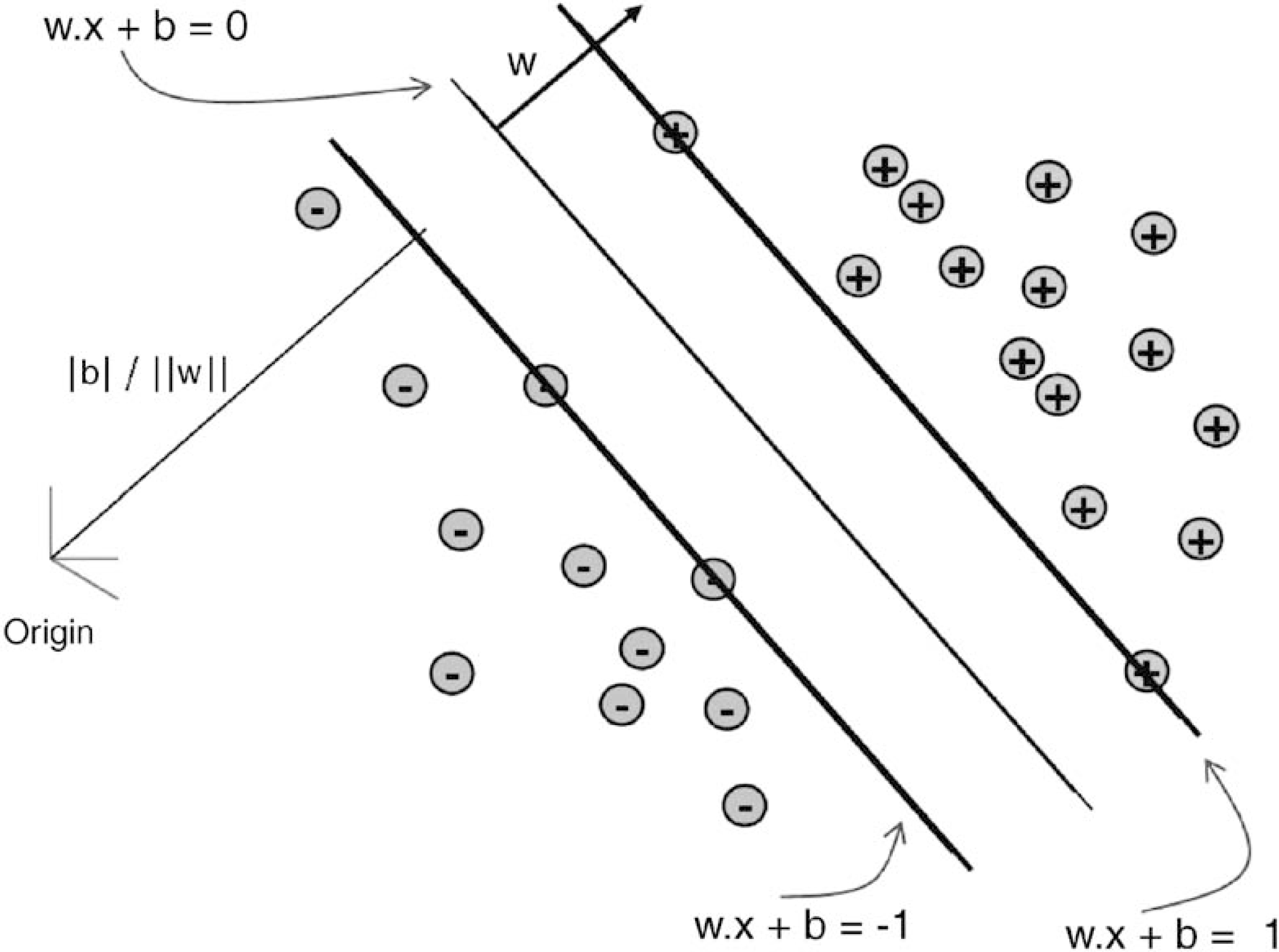
As it was mentioned before, the ML algorithms predict the trend from five or four input values, which represents the prices of wave ends (see in Fig. 4).
The output class represents the following trend direction after the last input wave.
Support Vector Machine
The SVM was introduced by Vapnik in 1995 [30, 31] as a classifier for two-class (binary) problems and from this time it was applied in many studies for stock market prediction [32, 33] or classification [34].
In basic manner, SVM creates mapping for input vector
In case of the observations are lineary separable, the solution (OSH) is given by following equation
where
In other (non-linear) cases, the SVM applies a kernel transformation function (
There are several known kernel functions which are able to by applied for example polynomial kernel function (
Training of the SVM is equals to solve a linearly constrained quadratic problem (QP) where number of variables is equal to the number of input vectors of the training dataset (see in Fig. 5).
A decision tree with three input variables (b1, b2 and b3). At each of the root and internal nodes (splits), a statistical measure is applied. The values a, b, c and d are thresholds for splitting. A dataset is split into smaller subsets until the terminal nodes (leaves) return the class labels (A, B and C) [40].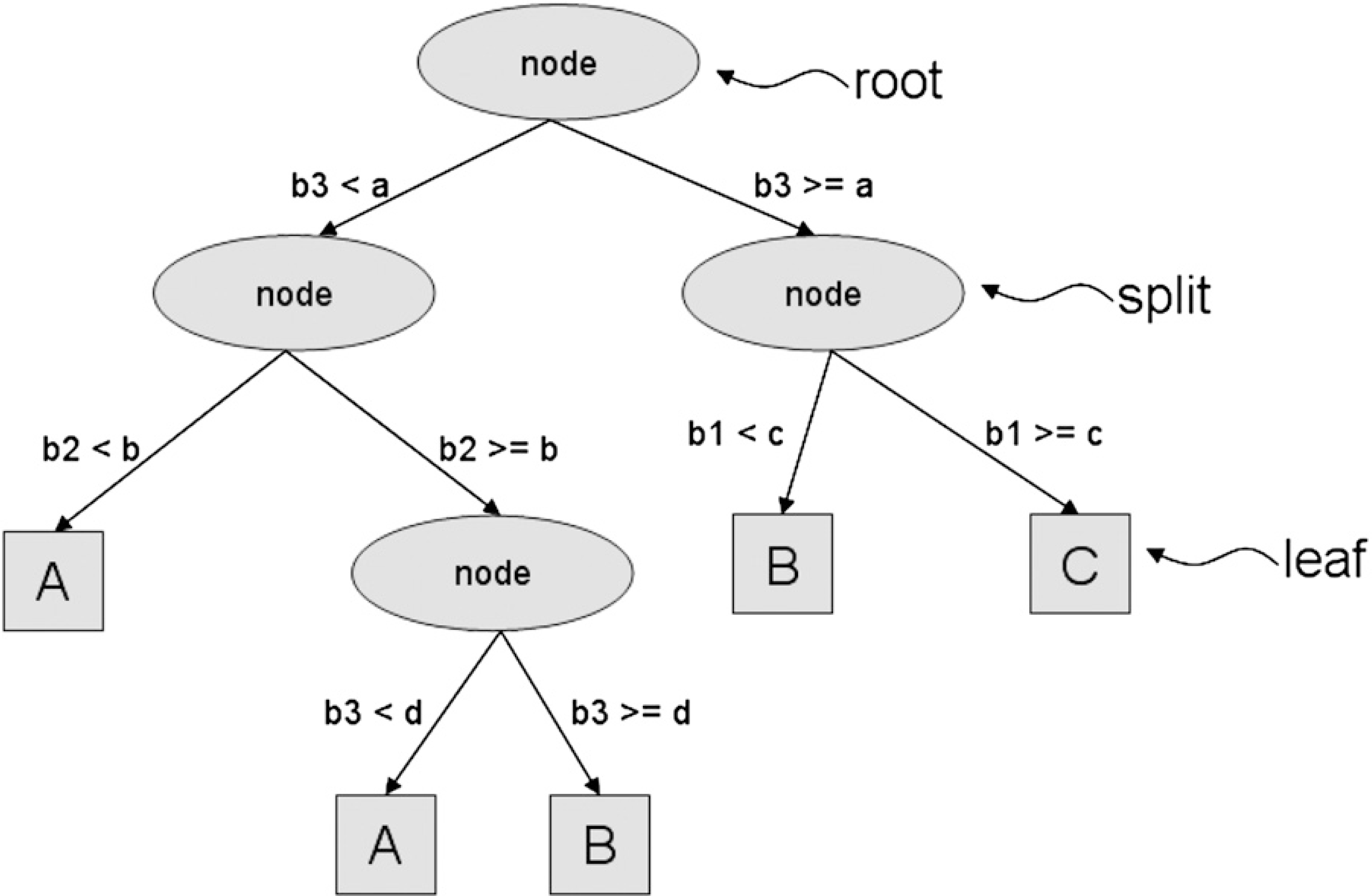
Random Decision Forest is a general title for ensemble based machine learning model which was proposed by Breiman in 2001 [36]. This model was succesfuly applied in many machine learning studies [37, 38]. The core idea of the algorithm is focused on application of an ensemble of CART-like tree classifiers (boosting) and their learning performed on the boosted-aggregated observations (bagging).
The decision tree (DT) is a tree-like structure of conditions with binary output values [39]. These conditions represent the nodes and leaves of the tree and serve as conditions for classification of the observation. Each condition make a single decision on one chosen attribute from the dataset and such an attribute is called splitting criteria. The attribute becomes the splitting criteria, when his information gain value (see Eq. (8)) is the highest on the particular subset of observations. The structure of such tree is depicted in Fig. 6.
Learning of the ensemble of trees means to train the set of trees where each of them obtain different random subset of the observations and different random subset of variables. This process minimizes the correlation between the trees, which increase the robustness of the model and decrease the possible amount of over-fitting. The final classification is derived from voting mechanism where votes from all of the trees are taken into account and final class is assigned to the observation by votes of the majority of the ensemble.
The bootstrapping mechanism comes from statistic and it is also know as random sampling with replacement [41]. This mechanism in context of RF algorithm produces balanced subset of observations for each of the tree. They are trained on resampled observations, which can handle the imbalanced problem or the problem of inability to learn some specific observations.
The other useful feature of RF algorithm is the possibility to compute the importance of the dataset’s variables. The ranking value is derived from averaged value of information gain of the variable across all of the learned trees. This feature was reviewed and applied in many studies [42, 43].
During the second phase of the experiment, the trend prediction by ML algorithm, the Grid search optimization was employed to find the near optimal hyper parameter adjustment of the used ML models. The final setting of the parameters is listed in Table 1.
Setting of parameters of applied machine learning algorithms
Setting of parameters of applied machine learning algorithms
Grid search hyper-parameter optimization (GSO) is an optimisation technique frequently applied for fine tuning of the ML model by optimisation of its hyper-parameter values [44]. This process comes through all combinations of parameter values (defined by their ranges) and according to the performance of the classifier, it chooses the best combination of settings.
The first part of the experiment was focused on EW pattern detection. The patterns were extracted from windows of length of 1000 observations from time series of ten-minute data and time series of hourly data. The different conditions were applied on the width of the initial fractal. The width of IF was set to 5 observations in case of hourly time series and 9 observations in case 10-minute time series.
All of the EW extractions were proceeded with four level of tolerances (10%, 15%, 20%, 25% for all of the Fibonacci ratios) and only complete EW were taken into account (all of the waves should fit the defined criteria under the given level of tolerance). The hypothesis of this experiment were focused on how the quality and amount of found EW’s depends on adjusted tolerances. The amount of found EW patterns is simply the count of patterns which fulfills the criteria and not over-lap the other selected patterns. EW’s which are inside of some longer EW pattern were not recognized in this experiment.
The median of the EW’s length is also observed. The longer EW is recognized, the easier opportunity is to open the position for a trade in the matter of time. The last statistic that was computed was the Market’s coverage, which simply means the ratio between observations that were members of found pattern to observations without membership to any EW. The higher amount of correctly recognized patterns implies the higher coverage, which leads to higher number of trading opportunities in the market.
Description of the quality and amount of founded EW patterns in 10-minute stock market data. The time series described GOLD (G), SILVER (S) and EURUSD (E) markets. For each of the market, there is number of found waves (N) and their average cost value (AC)
Description of the quality and amount of founded EW patterns in 10-minute stock market data. The time series described GOLD (G), SILVER (S) and EURUSD (E) markets. For each of the market, there is number of found waves (N) and their average cost value (AC)
Tables 2 and 3 describe the numbers and quality of found waves and other simple statistic according to the set level of tolerance.
Description of the quality and amount of founded EW patterns in 10-minute stock market data. The time series described GOLD (G), SILVER (S) and EURUSD (E) markets. For each of the market, there is number of waves (N) and their average cost value (AC)
The number of found patters increased with higher level of tolerance but on the other hand, the higher number of waves obtained lower quality according to their cost function. The average length of found waves also differs with different applied tolerances. Higher number of found patters implied in all of the cases the higher Market’s coverage.
As it was mentioned before the prediction was simple binary classification (two classes for up/down trends). The input values were prices of waves from incompletely recognized EW patterns and the output value should be the continued trend direction (1
The number of observations for classification differs for each of the market. In case of the GOLD title, there were 840 observations of 4-wave pattern and 699 observation of 5-wave pattern and in case of the SILVER title, there were 772 observations of 4-wave pattern and 642 observation of 5-wave pattern. Because the EURUSD time set contained the longest observed time-range (more than 4 millions of observations represents 10-year’s data) the number of incomplete patterns was higher. The number of EURUSD’s 4-wave patterns was 1738 and 1464 5-wave patterns.
The cross-validation method [45] was applied for testing of classification performance and the results covers calculated values of accuracy, precision, recall, specificity and basic f-score (see in Table 4).
Performance of binary classification for trend predictions, the metrics like accuracy, recall, specificity, precision and f-score are sorted line by line for each of the market title (Gold (G), Silver (S), Eurusd (E))
The results between SVM and RF algorithms obtained minimal differences and there is no motivation to compare their performance. The more interesting comparison is the increase of the performance between the application of randomly selected observations (with similar distances as EW’s patterns) and application of extracted EW patterns. As we can see, when the all of the impulsive waves were detected, the trend direction was easier to predict. On the other hand, the incomplete impulsive wave pattern (1-2-3-4) had no difference in progress from the random price picks.
The Elliott Wave theory was considered as a main idea of this paper, because even if the original idea of the repetitive waved behavior is older, it is still possible to find an occurrence of such a pattern in the price progress. This was the main motivation for the development of the algorithm for EW’s pattern detection.
The pattern matching is driven by the fundamental knowledge based on Fibonacci ratio sequences described in previous studies. The possibility of pattern matching is extended by ability of adjustable tolerance for each of the Fibonacci ratios of the EW’s pattern. It leads to higher amount of found patterns, higher coverage of the market data and also higher control of the trading strategy.
The advantages of the presented algorithm is its simplicity, possibility of running in parallel environment, adjustable tolerances which are able to handle even higher amount of noise interference and no dependence on the length of the time set, that causes the possible finding of EW patterns in all the possible scales and sizes. As a disadvantage, it is considered the inability of self-optimization on a given time set, because the default version of the algorithm does not cover any learning ability. This requirement is possible to fulfill by extension of evolutionary based optimization algorithm, which will optimize the tolerances based on the given criteria. This step will be considered in our future work.
The detected EW patterns worked as a valuable tool for the price progress forecasting, however it was tested only on very specific stock market price titles. Each market title preserves different behavior and the level of fluctuation, that affects the possibility and quality of finding of the EW patterns. Because these conditions vary from title to tile and also across the observed time, the another future study should be aimed on the measurement of relevancy between temporal statistical features and found EW patterns.
Conclusions
This paper covers the design, implementation and testing of the algorithm for EW pattern detection. The available literature providing the theory about fundamental features of EW patterns was considered in its development. The open-source package for further research is a result brought by first part of this study.
The second part of this study is focused on application of the developed algorithm. The EW patterns are extracted from three different stock market titles. Different adjustments of the algorithm are compared by quality, length and amount of found waves.
Further the impulsive waves were applied for the trend-prediction. This was compared with randomly selected input waves. The application of complete impulse waves (1-2-3-4-5) implied higher performance than the input based on incomplete impulse waves (1-2-3-4).
Although the conditions of the experiment are not entirely the same from previous studies of the trend-predictions, the results are very comparable which makes the Elliott wave theory still attractive and applicable in this field of interest.
Footnotes
Acknowledgments
This research was conducted within the Students Grant Competition project reg. no. SP2016/175, the framework of the Project TUCENET Sustainable Development of Centre ENET LO1404, supported by Grant SGS 2018/177 of VSB-Technical University of Ostrava; and by The Ministry of Education, Youth and Sports from the National Programme of Sustainability (NPU II) project “IT4Innovations excellence in science – LQ1602”. We also wanted to acknowledge the COMPSE 2016, First EAI International Conference on Computer and Engineering, Penang, Malaysia, November 11–12, 2016.