
Abstract
Bengali is the seventh most widely spoken language in the world. Many researchers are working on developing Bengali language based information retrieval, question-answering, query-response systems. The proposed Bengali Language Query Processing System (BLQPS) is based on natural language query-response model. Bengali language has been used in the model to extract knowledge data from a default database. The system is based on scoring and pattern generation algorithm that is able to generate structure query language (SQL) from natural language query in Bengali with the help of a synonym database. The proposed system is domain based and a large number of words have been initialized in the synonym database. The SQL is formulated from semantic analysis. Further, the generated SQL has been used to extract knowledge data in Bengali language from the default database.
Keywords
Introduction
The 21st century is the current century of human-computer interaction era. The main aim of this discipline has to interact with computerized system using less effort. The Natural language processing (NLP) plays a very important role in human-computer interaction. The humans can understand natural language whereas computerized system can understand machine understandable language. As a result the naive user is not able to access the computerized system by their native language. The NLP is a technique which converts the human understandable language to a machine understandable language form. As a result the naive user can be able to access the computerized system by their native language without knowing the details of conversion technique. There is a substantial amount of work that has already been done on natural language interface to database. Different researchers have applied different techniques. The conversion of natural language to SQL can be done through Morphological Analysis, Syntactic Analysis, Semantic Analysis, Discourse integration and Pragmatic Analysis [3]. Some researchers have proposed the Natural Language Query Processing (NLQP) system as an interface to database system using semantic grammar [7]. A Hindi language based graphical user interface for transport system is developed using a set of predefined rules [8]. Another Hindi language interface for database based on karaka theory generates SQL by comparing each token with knowledge base [9]. There are many government awareness campaigns (Health, Education etc.) undertaken by government in various portals or e-platforms in English which majority of the citizens may not be able to access or understand due to language barriers as mostly Indians speaking vernacular languages are not comfortable in English. Bengali is one of the vernacular languages. Bengali language has been used in important states of India such as West Bengal, Tripura, Assam and Andaman Nicobar Islands. The national language of Bangladesh is also Bengali. The proposed system is a query response model in the medical domain that shall able to process medical related query where the query is accepted in Bengali. The system is aimed at overcoming language barrier. The system’s synonym database consists of two tables, one is entities another is attributes table. The default database consists of three tables. These tables are hospital, doctor and department table. The user can post a query in Bengali language. The parts of Speech (POS) tagging is done by scoring method. Then the system generates all possible patterns of unknown words. This generated pattern is compared with synonym database and populated in the semantic table for semantic analysis. This semantic analysis helps to construct the SQL of default database. Finally formal SQL is executed by system and fetch the desired result. No Adjective is used in the proposed system architecture pertaining to medical domain because no qualitative query shall be posted in the system. This is the limitation or constraint of the system.
Related works
Substantial amount of work has been done since last few decades on natural language processing. The Review on Natural Language Processing research papers addresses the challenges between natural language and computing device. The natural language processing applications are based on Phonology, Morphology, Semantics and Pragmatics. Phonology depends on sound of speech of speaker. Morphology is the structural study of word that locates the root word. The Semantic analysis expresses the textual meaning of the sentence without context. The Pragmatic analysis expresses the meaning of the sentence within context. Natural language processing (NLP) is a field of study of interaction with computer by using human language. A wide range of NLP based system has been developed by using mathematical and computational modeling of various aspects of language. NLP is a technique through which the computing device can understand natural language text or speech. Some NLP based applications are machine translation, natural language text processing and summarization, user interfaces, multilingual and cross language information retrieval (CLIR), speech recognition, artificial intelligence (AI) and expert systems are discussed in [1]. Interface between natural language and database is also a hot topic of research. This intelligent interface is designed for naive user who does not have any knowledge of database. An intelligent interface for relational database system converts the English language query to SQL using semantic matching, data dictionary and a set of production rules together has been defined in [2]. Conversion of human language to a formal language like SQL through different phases of analysis like Morphological Analysis, Syntactic Analysis, Semantic Analysis, Discourse integration and Pragmatic Analysis has been done in paper [3]. The Prolog programming language based question answering system named Chat-80 internally represents the meaning of English questions by a set of Prolog programming logic. Finally the answer is fetched by executing the Prolog logic as discussed in [4]. The EFLEX system is an efficient database interface system that consists of analyzer, mapper and translator. The analyzer interprets the given natural language query for the mapper. The mapper maps the natural language to its corresponding SQL. Finally the translator forms the query correctly. The efficiency of the EFLEX system has been improved by using Knuth-Morris-Pratt algorithm that is explained in [5]. The Knowledge Management System (KMS) is query response tool where the user can post the query in English language into the KMS. Then the KMS retrieves the data from default database using a set pre-defined grammar rules and semantic analysis as discussed in [6]. The NLQP as in [7] reduces extra overhead of complex SQL. This NLQP consists of four modules. These modules are Analyzer Module, Parser Module, Query Builder Module and code optimizer Module. The Analyzer Module tokenizes the English language query into keys after which these tokenized keys are sent to the Parser Module and then the Parser Module combines these tokens and performs syntactic analysis. The Query Builder Module forms the SQL query using parsing information. Finally the Code Optimizer Module fetches the data in efficient way is implemented in [7]. A Hindi language based interface for transport system is developed for native Hindi speaker where the data is retrieved from Hindi database using Hindi language query as in [8]. In this system, SQL statements like insert, update, delete, MIN(), MAX(), SUM() and AVG() are implemented in [8]. In [9], a Hindi language interface for database using Karaka theory has been developed which is very useful for native Hindi users. The proposed system divides the Hindi Language query into number of tokens. The shallow parser removes useless tokens. The Case Solver forms a new Hindi language query which is consists of base words. The shallow parser uses POS type verb to determine the SQL command. The token which is present before the case symbol is treated as a table name and the token which present after the case symbol is treated as attribute name. Some condition start tokens or words as mentioned in Section 3(d) of [9] are present in the proposed system which has helped to construct the condition part of the SQL query. Then the graph generator represents the relationship among command, table name, attribute name and conditional part. The query translator converts Hindi token to its corresponding English token using knowledge base. Finally Query Executor executes the SQL query and retrieves desired data from database that has been discussed in [9]. The Natural Language Interface to the Database (NLIDB) based on ontology as in [10] has produced better result than any other existing NLIDB. In this system, the semantic representation is done by using Ontology Web Language (OWL) for knowledge modeling which increases the correct responses of user’s query that is explained in [10]. In [11] deals with structural ambiguity of a Bengali sentence. The given sentence is tokenized by the Tokenizer. Then the validator checks grammatical mistake in the sentence. Whereas the En-converter converts the given sentence into a Universal Networking Language expression using Dictionary Entry-look-up, rules of morphological analysis and semantic analysis. This technique has been discussed in [11]. The proposed system identifies the Bangla grammar using predictive parser. In this system the parser uses the top down technique. The proposed system uses the pre-defined XML dictionary for parts of speech tagging. The access time of XML file is much lesser than other file format. The parse table is generated using context free grammar in this system. The proposed parser has been discussed in [12]. The Syntax Analysis and Machine Translation of Bangla Sentences system in [13] can able to convert all types of Bangla sentence to English sentence using pre-defined grammar rules. The parsing is done in this proposed system through different steps. The system tokenizes the user given Bengali sentence. Then the system counts the number of tokens. After that the proposed system checks given sentence’s length and pre-defined rules length. If both the length is matched then corresponding phrases is retrieved and parse tree is generated. The Bangla to English converter converts the Bangla sentence to English sentence by using training corpus which selects the word to form the sentence which probability is to maximum. The proposed system is discussed in [13]. The Rule Based Bengali Stemmer is a proposed system which derives the Bengali root word by removing the affix from a given word. The proposed system categorizes all words in two parts either verbal affix or nominal affix. The Rule Based Bengali Stemmer checks every letter of a word. If affix is present then remove the affix and find the stem word. The above mentioned process uses for both verbal inflection and nominal inflection. The proposed system is implemented in [14]. The proposed system tokenizes the given English language’s query. Then all tokens are passes through automata. Automata remove articles, connectors and extract correct pattern. Automata substitute the keyword with proper attribute. Finally automata map the value which corresponds to a particular attribute as well as a table also. If the two or more tables are associated with the query then the automata joins up the tables. In these way automata build up the SQL from the English language query is discussed in [15]. In [16], tense based English to Bangla translation system has been implemented which convert the English sentence into corresponding Bangla sentence. The proposed system verifies the syntactical correctness using context-free grammar whereas bottom up approach is used to generate parse tree for the given sentence. The proposed system consists of Tokenizer, Syntax Analyzer, Grammatical Rule Generator, Lexicon, Parse Tree and Conversion Unit. Tokenizer tokenizes the given sentence and sends to the Syntax Analyzer. Then the Syntax Analyzer compares each token with lexicon. If the token does not match with lexicon then token is invalid otherwise find out POS type and Bengali meaning of the token. The Grammatical Rule Generator contains a set of pre-defined production which useful to form a correct parse tree. The Conversion Unit converts the English parse tree into corresponding Bengali parse tree. Finally Bengali sentence prints. This system is discussed in [16]. Link data, SPARQL language and interface in natural language may be an interesting solution for accumulate and disseminate biomedical knowledge in biomedical area. Researchers may have difficulty to handle SPARQL language where natural language interface helps to life science researchers for extraction biomedical knowledge from biomedical knowledge base as in [21]. Non-expert users don’t have ability to access huge data repository. Natural language interface to web data services are working as an immerging technology to non-expert users for accessing huge data repository has been discussed in [22]. Natural language interface are crucial part of semantic knowledge representation system where understanding of formal representation language to model in a particular domain is a difficult task for users. Authors have introduced a semantic wiki system that is based on controlled natural language interface that uses attempto controlled English in grammatical frame work. The grammatical frame work helps to manage other natural language (multi lingual) queries as in [23]. Lot of research work has already been done in parsing, parts of speech tagging, stemming, sentiment analysis in vernacular languages like Hindi, Bengali Assamese. But very little amount research work has been done on query processing in Bengali natural language. So, there is a need to develop query systems in local or vernacular languages. Sine majority of users in India are living in rural or sub-rural areas are not very comfortable with English language, such systems may help the rural or backward areas to use such systems with vernacular language interface to handle queries. It has been found that rural areas mostly require information in domains like medical fields, education, agricultural information etc. This work discusses on a Bengali Language Query Processing System on medical domain as to aid or facilitate the rural people or people in backward areas to access medical information pertaining to their village/district/state. The rest of the research paper is organized as follows. The Section 2 discusses the literature reviews on related works. The Section 3 gives the architecture of the BLQPS. The Section 4 explains methodology and tools used. Then the Section 5 discusses general features based comparative study of the proposed system with similar type system. The Section 6 discusses conclusion and future works of the proposed system.
Data flow diagram of BLQPS.
The architecture of the proposed system has been given in Fig. 1.
Algorithm
The block diagram of algorithmic step has been given in Fig. 2.
Log in into the system and post query in Bengali language
The user will log in into the proposed system and will post the query in Bengali language. A query has been given below as an example.
নদিয়া ও à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ কি কি à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে?
(nothyea o purulyeae ki ki haspathal ache?)
That means in English Language
What are hospitals available in Nadia and Purulia?
Natural language query to SQL generation steps.
Query String array for NL query after tokenization
The proposed system reads the query and slices it into meaningful linguistic units called tokens after removal of punctuation marks. These tokens will be stored in a string array. The pictorial representation of user given query after tokenization has been given in Table 1.
Score array with score value after POS tagging
Score array with score value after POS tagging
The BLQPS contains few stop words which are pre-defined list of Bengali words like interrogative words, pronouns, prepositions and conjunctions. These pre-defined Bengali words (stop words) have been stored in string arrays. The pre-defined words are termed as known words and remaining all other words are treated as unknown words. A numeric value has been assigned to each string array that contains predefined words termed as score. The score of string array of interrogative words, pronouns, preposition and conjunction are 2, 3, 4 and 5 respectively. The score of all unknown words are 1. The pre-defined string arrays have been given below with score.
list_interrogative[ ] list_pronoun[ ] list_preposition[ ] list_conjunction[ ]
When a query is posted in Bengali language, it is first tokenized. The tokens may contain predefined words and unknown words. The tokens are placed in a query string array. The unknown words have a score of 1. Each of the known tokens of the query string array will be compared with predefined words stored in pre-defined string arrays as mentioned in list i through iv, wherein, list i corresponding to interrogative has score 2, list ii corresponding to list pronoun has score 3, list iii corresponding to list preposition has score 4 and list iv corresponding to list conjunction has score 5. If the corresponding token of query string array matches with any predefined word in predefined string array (list i through iv), then score of corresponding string array will be assigned to the token of the query string that is compared to the string array containing predefined words list as in i through iv). Thereby, a score array (as shown in Table 2) is derived from the query string array (shown in Table 1). The score array length is same as token array. The BLQPS maintains this score array to keep track the score of all token(s) after POS tagging.
The BLQPS selects every token from the tokenized query and compares with each word of interrogative’s word list. If token matches with any word of interrogative word’s list then the score of the selected token will be same as score of the interrogative’s word list i.e. 2. Otherwise token will be compared with each word of pronoun’s list. If token matches with any word of pronoun’s list then the score of the selected token will be same as score of the pronoun’s list i.e. 3. Otherwise in the similar way token will be compared with preposition’s list and conjunction’s list respectively. If token matches, then corresponding array list score will be assigned. If the selected token does not match with any of the above mention known word list, then the proposed system will determine that the selected token is unknown and score will be 1. Using above mentioned procedure the proposed system will assign a specific score in the score array after POS tagging. The score value of first token from token array will be assigned at 0
Semantic table
Desired result after processing NL query
Entities table of synonyms database
In this step, the BLQPS generates all possible patterns of unknown tokens. The main objective of pattern generation is composition creation of two or more than two unknown words. The proposed system recognizes as unknown token whose score is 1. The unknown tokens or words which are not consecutive or which are separated by another known token or word shall have only one pattern. But, when the unknown tokens are consecutive and not separated by any known token or word, they shall generate pattern(s) of tokens or words, where the order of the tokens or words will not be changed in the pattern. The known token(s) or word(s) will not be considered for pattern generation because the proposed system will generate the semantic table using unknown token(s) or word(s).
The query নদিয়া ও à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ কি কি à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে? (nothyea o purulyeae ki ki haspathal ache?) (What are hospitals available in Nadia and Purulia?) has been tokenized and shown in Table 1. After POS tagging, the BLQPS maps known and unknown token or word by considering index of token array and score array as well as score value of the score array. The nonconsecutive unknown word generates only one pattern. Here নদিয়া (nothyea), à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ (purulyeae) are two nonconsecutive unknown words because there is a known word ও (o) between them. So the token নদিয়া (nothyea) will be the single pattern. Similarly the token à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ (purulieae) will be another single pattern. But two consecutive unknown tokens or words are à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) and আছে (ache) (Available). So these two consecutive unknown tokens shall generate more than one pattern. The token order occurrence is maintained in the generated pattern which is made up of two or more than two tokens. The generated pattern à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) আছে (ache) (Available) is made up of two tokens. The token à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) occurs before the token আছে (ache) (Available). That why the pattern à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে (haspathal) (ache) (Hospital Available) will be generated and the pattern আছে (ache) (Available) à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) will not be generated by the BLQPS. All generated pattern has been given below.
নদিয়া (nothyea) à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ (purulieae) à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) (Hospital) আছে (ache) (Available) à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে (haspathal) (ache) (Hospital)(Available)
Attributes table of synonyms database
Hospital table of default database
Doctor table of default database
The BLQPS contains two databases. One is synonym database and other is default database. The synonym database contains entities and attributes tables. Table 5 represents entities table and Table 6 represents attributes table. The default database contains Hospital (Table 7), Doctor (Table 8) and Department (Table 9) tables. The pattern (নদিয়া, à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ, à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦, আছে, à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে) will be generated by the BLQPS in step iv. Each pattern may be an entity name, an attribute name or a value. Each pattern will be checked with entities table. If the corresponding pattern matches with any value of synonyms field in entities table, then corresponding row values will be fetched like entity name, primary key, foreign key, candidate key except synonyms value and the corresponding row value will be inserted into the semantic table; else the pattern will go for matching in attributes table. If the corresponding pattern matches with any value of synonyms field in attributes table then corresponding row values will be fetched like entity name, attribute name, primary key, foreign key and candidate key except synonyms value and the system will insert these into the semantic table else the pattern will go to the default data base for matching.
Department table of default database
Department table of default database
If the pattern matches with any value in any table in the default database then the column name of the corresponding table will be selected and the attributes table of the synonyms database will be searched again corresponding to the column name wherein the entire row values with corresponding columns name are selected.
নদিয়া (nothyea) – This will be selected as default database value and corresponding row value from attributes table will be fetched. à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ (purulieae) – This will be selected as default database value and corresponding row value from attributes table will be fetched. à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) (Hospital) – This will be selected as entity from enttities table and corresponding row value will be fetched from entity table. আছে (ache) (Available) – This will not be selected. à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে (haspathal) (ache) (Hospital)(Available) – This will not be selected.
After completion of synonyms database matching, corresponding row values of নদিয়া (nothyea), à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ (purulieae), à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ (haspathal) from attributes and entities tables will be fetched and inserted into the semantic table except value of synonyms attribues from both table.
The representation of above mention query after semantic analysis has given in Table 3.
In this phase, the BLQPS generates SQL from the semantic table. The general format for retrieving data from table(s) is SELECT attribute 1, attribute 2, attribute 3… attribute n FROM entity 1 (table 1), entity 2 (table 2), entity 3 (table 3)… entity
Case i: The system identifies attributes if the attribute_name field is NOT NULL, value field is NULL and entity_name field is also NOT NULL; then values in the attribute_name field of Semantic Table shown in Table 3 is treated as attribute(s). The system concatenates those attribute(s) with their corresponding entity name by “.” operator.
Case ii: The BLQPS considers all attributes if the attribute_name field is NULL, value field is NULL and entity_name field is NOT NULL in the semantic table. The system concatenates the “*” to their corresponding entity name by “.” operator.
Case iii: If the attribute_name field is NOT NULL and value field is also NOT NULL then whatever attributes are contained in the attribute_name field is treated as condition. The system concatenates those attribute(s) followed by “
Case iv: The BLQPS finds entity name from the value of entity_name field in semantic table. In case the entity_name field contains duplicate value, the proposed system selects distinct entity name.
Case v: If the value of primary_key field of one entity matches with the value of foreign_key or candidate_key of other entity in the semantic table then the system will perform joining operation between these two entities.
Case vi: If two or more entries in value field is NOT NULL and their corresponding attribute_name, entity_name field contains same value, it means the particular attribute of an entity has a list of values. In this case system will use IN clause.
Case vii: Single entry in value field is NOT NULL and their corresponding attribute_name, entity_name field is also NOT NULL. In this case system will use “
Case viii: If two or more condition exists, the system concatenates all condition(s) using AND.
After SQL generation the above mentioned query i.e. নদিয়া ও à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ কি কি à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦ আছে? (nothyea o purulyeae ki ki haspathal ache?) will be converted to following SQL SELECT hospital.* FROM hospital WHERE hospital.hos_district IN (‘নদিয়া’ (nothyea), ‘à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾à§Ÿ’ (purulyeae)).
SQL processed by system
Finally the SQL is executed and the desired result is fetched from the default database by the BLQPS. The result has been given in tabular format in Table 4.
Knowledge representation of the BLQPS
The knowledge data has been stored in default database. The default database has been used for knowledge extraction using natural language query. The Database Administrator, Knowledge Administrator,System Administrator or any other resource person may update the proposed knowledge database. The synonyms database has been used to generate the semantic table. The synonym database contains entities table and attributes table. The default database contains of hospital table, doctor table and department table.
Query String array for NL query after tokenization
Query String array for NL query after tokenization
Natural language query in BLQPS.
3.2.1.1. Structure of entities table
The entities table consists of six fields. These fields are entity_id, entity_name, synonyms, primary_key, foreign_key and candidate_key. In this table, entity_id field is the primary key. Entity_name field contains participating entity name corresponding to table names of default database like hospital, doctor and department. The synonyms field contains all possible synonyms of the entities in Bengali language. The primary_key field contains the name of primary key field of their respective entity. Similarly the foreign_key and candidate_key fields contain the name of the foreign key and candidate key field of their corresponding entity if value corresponding to foreign_key and candidate_key exists, otherwise they shall be NULL respectively. The structure of entities table has been given in Table 5.
3.2.1.2. Structure of attributes table
The attributes table consists of seven fields. These fields are attribute_id, entity_name, attribute_name, synonyms, primary_key, foreign_key and candidate_ key. In this table, attrubute_id field is the primary key. The entity_name contains the entity name (Table name) of default database. The attribute_name field contains all attributes of entities in default database. The synonyms field contains all possible synonyms of attributes of entities. Synonym words have been stored in Bengali language. The primary_key field contains the name of primary key field of corresponding entity. Similarly the foreign_key and candidate_key fields contain the name of foreign key and candidate key fields of corresponding entity if the value of them exists; otherwise they shall be NULL respectively. The structure of attributes table has given in Table 6.
Default database
3.2.2.1. Structure of hospital table
The hospital table consists of five fields. These fields are hos_id, hos_name, hos_add, hos_district, hos_state. The hos_id field is the primary key of this table. Using this hos_id field the BLQPS uniquely identify each entity instance of the table. The hos_name field contains hospital name, hos_add field contains the hospital address, hos_distrct field contains district name where hospital is situated. Similarly hos_state field contains state name where the hospital is located. The structure of hospital table has given below in Table 7.
3.2.2.2. Structure of doctor table
The doctor table consists of six fields. These fields are doc_id, doc_name, doc_qualification, doc_ specialist, hos_id and dept_id. The structure of doctor table has given in Table 8.
3.2.2.3. Structure of department table
The department table consists of three fields. These fields are dept_id, dept_name, hos_id. The structure of department table has given in Table 9.
Methodology and tools used
HTML, PHP, MySQL and Avro Bengali software have been used to develop the proposed system. HTML has been used as front end to design the web pages structure. PHP is a server side scripting language that has been used in back end. The knowledge database (default database) and synonyms database has been implemented in MySQL. All Bengali queries in Bengali transcript has followed IPA notation as per Help: IPA/Bengali given in website https://en.wikipedia.org/ wiki/Help:IPA/Bengali
Step i
The Bengali Language Query Processing System (BLQPS) is a domain specific natural language query processing system. The system has been designed to handle medical related queries in Bengali. The user will log into the system and will post a query in Bengali. The query window of the proposed system has given in Fig. 3.
For example the user posts a query in Bengali. The query has been given.
à¦à¦¾à¦•à§à§œà¦¾, à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ ও নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° মধà§à¦¯à§‡ অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— কোথায় কোথায় আছে? (bakuɽa, puruliea o nothyar haspathaler mothe osthi chykitsa bybhag kothae kothae ache?) (Where is the orthopedic department available among Bankura, Purulia and Nadia’s Hospital?).
The BLQPS tokenizes the query into twelve tokens and stores them into a query string array after removing punctuation marks.
The array of tokens and array index of given query string after tokenization has been given in Table 10.
Step ii
After tokenization, The BLQPS selects every token from the tokenized query and compares with each word of interrogative’s word list. If token matches with any word of interrogative’s word list then the score of the selected token will be same as score of the interrogative’s word list i.e. 2. Otherwise token will be compared with each word of pronoun’s list. If token matches with any word of pronoun’s list then the score of the selected token will be same as score of the pronoun’s list i.e. 3. Otherwise in the similar way token will be compared with preposition’s list and conjunction’s list respectively. If token matches then corresponding array list score will be assigned. The selected token is not matched with any of the above mention known word list then the proposed system will determine the selected token is unknown and score will be 1. Using above mentioned procedure the proposed system will assign a specific score in the score array after POS tagging. The score value of first token from token array will be assigned at 0
The score of all tokens of user given has been given in Table 11.
Score array with score value
Score array with score value
à¦à¦¾à¦•à§à§œà¦¾, à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ ও নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° মধà§à¦¯à§‡ অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— কোথায় কোথায় আছে?
(bakuɽa, puruliea o nothyar haspathaler mothe osthi chykitsa bybhag kothae kothae ache?) (Where is the orthopedic department available among Bankura, Purulia and Nadia’s Hospital?), has been tokenized and shown in Table 10. After POS tagging the BLQPS maps known and unknown token or word by considering index of query string array(token array) and score array as well as score value of the score array. The nonconsecutive unknown word generates only one pattern. Here আছে (ache) is one nonconsecutive unknown token or word. So the token আছে (ache) will be the single pattern. But two consecutive unknown tokens or words are à¦à¦¾à¦•à§à§œà¦¾ (bakuɽa) and à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea). So these two consecutive unknown tokens shall generate more than one pattern. The token order occurrence is maintained in the generated pattern which is made up of two or more than two tokens. The generated pattern à¦à¦¾à¦•à§à§œà¦¾ à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (Bakuɽa puruliea) is made up of two tokens. The token à¦à¦¾à¦•à§à§œà¦¾ (bakuɽa) occurs before the token à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea). That why the pattern à¦à¦¾à¦•à§à§œà¦¾ à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (Bakuɽa puruliea) will be generated and the pattern à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ à¦à¦¾à¦•à§à§œà¦¾ (puruliea Bakuɽa) will not be generated by the BLQPS. Similar way all consecutive tokens will generate patterns. All generated pattern has been given below.
à¦à¦¾à¦•à§à§œà¦¾ (bakuɽa) à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea) à¦à¦¾à¦•à§à§œà¦¾ à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (Bakuɽa puruliea) নদিয়ার (nothyar) à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (haspathaler) নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (nothyar haspathaler) অসà§à¦¥à¦¿ (osthi) (Orthopedic) চিকিৎসা (chykitsa) (Treatment) à¦à¦¿à¦à¦¾à¦— (bybhag) (Department) অসà§à¦¥à¦¿ চিকিৎসা (osthi chykitsa) (Orthopedic Treatment) চিকিৎসা à¦à¦¿à¦à¦¾à¦— (chykitsa bybhag) (Treatment Department) অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— (osthi chykitsa bybhag) (Orthopedic Department) আছে (ache) (available)
Instances of semantic table
Conversion of NL query to SQL.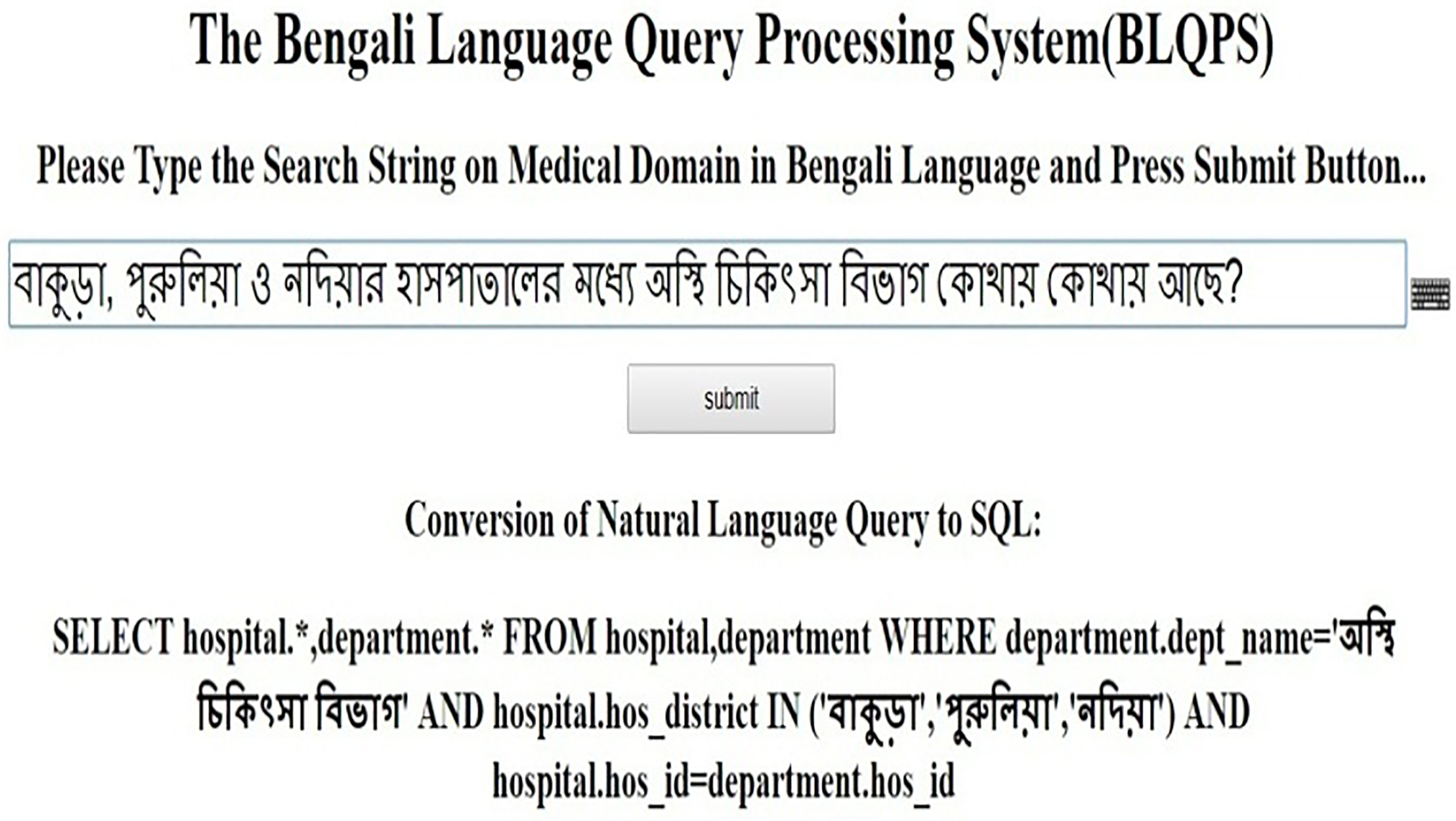
The BLQPS will compare each pattern à¦à¦¾à¦•à§à§œà¦¾(bakuɽa), à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea), à¦à¦¾à¦•à§à§œà¦¾ à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (Bakuɽa puruliea), নদিয়ার (nothyar), à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (haspathal-er), নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (nothyar haspathaler), অসà§à¦¥à¦¿ (osthi) (Orthopedic), চিকিৎসা (chykitsa) (Treatment), à¦à¦¿à¦à¦¾à¦— (bybhag) (Department), অসà§à¦¥à¦¿ চিকিৎসা (osthi chykitsa) (Orthopedic Treatment), চিকিৎসা à¦à¦¿à¦à¦¾à¦— (chykitsa bybhag) (Treatment Department), অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— (osthi chykitsa bybhag)(Orthopedic Department), আছে (ache) (available) with synonym database as well as default database and insert into semantic table the matched value when a match occurs.
à¦à¦¾à¦•à§à§œà¦¾ (bakuɽa) – This will be selected as default database value and corresponding row value from attributes table will be fetched. à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea) – This will be selected as default database value and corresponding row value from attributes table will be fetched. à¦à¦¾à¦•à§à§œà¦¾ à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (Bakuɽa puruliea) – This will not be selected. নদিয়ার (nothyar) – This will be selected as default database value and corresponding row value from attributes table will be fetched. à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (haspathaler) – This will be selected as entity from enttities table and corresponding row value will be fetched from entity table. নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (nothyar haspathaler) – This will not be selected. অসà§à¦¥à¦¿ (osthi) (Orthopedic) – This will not be selected. চিকিৎসা (chykitsa) (Treatment) – This will not be selected. à¦à¦¿à¦à¦¾à¦— (bybhag) (Department) – This will be selected as entity from enttities table and corresponding row value will be fetched from entity table. অসà§à¦¥à¦¿ চিকিৎসা (osthi chykitsa) (Orthopedic Treatment) – This will not be selected. চিকিৎসা à¦à¦¿à¦à¦¾à¦— (chykitsa bybhag) (Treatment Department) – This will not be selected. অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— (osthi chykitsa bybhag) (Orthopedic Department) – This will be selected as default database value and corresponding row value from attributes table will be fetched. আছে (ache) (available) – This will not be selected.
After completion of synonyms database matching, corresponding row values of à¦à¦¾à¦•à§à§œà¦¾ (bakuɽa), à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ (puruliea), নদিয়ার (nothyar), অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— (osthi chykitsa bybhag) (Orthopedic department), à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° (haspathaler), à¦à¦¿à¦à¦¾à¦— (bybhag) (Department) from attributes and entities tables will be fetched and inserted into the semantic table except value of synonyms attribues from both table. The representation of above mention query after semantic analysis has given in Table 12.
User request with generated response.
Numbers of known and unknown tokens.
General features based comparative study of the proposed system with similar type system
After SQL generation the above mentioned query i.e. à¦à¦¾à¦•à§à§œà¦¾, à¦à§à¦°à§à¦à¦¿à§Ÿà¦¾ ও নদিয়ার à¦à¦¾à¦¸à¦à¦¾à¦¤à¦¾à¦à§‡à¦° মধà§à¦¯à§‡ অসà§à¦¥à¦¿ চিকিৎসা à¦à¦¿à¦à¦¾à¦— কোথায় কোথায় আছে?
(bakuɽa, puruliea o nothyar haspathaler mothe osthi chykitsa bybhag kothae kothae ache?) (Where is the orthopedic department available among Bankura, Purulia and Nadia’s Hospital?) will be converted to following SQL SELECT hospital.*,department.* FROM hospital, department WHERE department.dept_name
Step vi
Finally the SQL will be executed by the BLQPS and the desired result will be fetched from default database. The user request with generated response has been given in Fig. 5.
Time complexity of the BLQPS
After tokenization, let Let there be Time taken to search 1st token in the 1st list of words Time taken to search 1st token in the 2nd list of words Time taken to search 1st token in the 3rd list of words … … … Time taken to search 1st token in the Therefore, total time taken by the 1st token
After POS tagging known and unknown tokens have been given in Fig. 6. Above example discussed in Section 3.1 has been taken in the Fig. 6. If token taken one at a time Token taken two at a time Token taken three at a time … Token taken Total number of patterns generation without position replacement
The synonym database search – There are entity table, attribute table, default database tables. Let there are There are Time taken by 1st pattern to search in entity table
Similarly, time taken by Similarly, time taken by So the total time taken Time taken to create SQL Time taken to generate response
The comparative study of proposed system with other similar type system is features based. Few similar type systems have been considered for comparative study. Prabhudeep Kaur et al. have developed Conversion of Natural Language Query to SQL. This system is based on pre-defined grammar rules and WordNet that can able to convert speech to SQL using Hidden Markov Model (HMM) has been implemented in [17]. Another Bengali parser has been developed by Hasan et al. The Bengali parser works on creation of Bengali grammar from Bengali sentences. Authors have considered top down parsing method and avoided left recursion in context free grammar (CFG) as in [12]. Access of the Holy Quran has grown rapidly with the grown of huge numbers of smart mobiles, tablets and laptops. The system has developed by Khaled Nasser ElSayed to access the database of the Holy Quran. The primary features of this system are translation of natural Arabic question or imperative sentences to SQL command and answer extraction from the Holy Quran database. Parsing technique and little morphological process have been used to make the interface of this system that are based on Arabic context free grammar rules has been described in [18]. Aarti Sawant et al. have described natural language to database that can manage natural language question as an input. Authors have stated that the proposed system is able to generate textual response from relational database using natural language query. The natural language interface simplifies the textual data extraction from relational database without having essential knowledge of SQL has been developed in [20]. Other similar type systems like NLWIDB [19] of Alexander et al., natural language interpretation using automata [15] of Kaur et al., Bangla parser [13] of Anwar et al., English to Bangla Translation Using MT System [16] of Muntarina et al. and Natural Language Interface for Databases in Hindi Based on Karaka Theory [9] of Kataria et al. have been discussed details in Table 13.
Conclusion and future work
The Bengali Language Query Processing System (BLQPS) is an automated system which shall be able to handle Bengali language user queries. The user shall submit the query in Bengali Language. Then the BLQPS processes the query and generates response in Bengali language. The BLQPS is designed in such a way that naive Bengali users can interact with computerized system with their own language (i.e. Bengali). Queries containing adjectives cannot be processed by the proposed system, like “What are the best hospitals in Bankura” cannot be processed as best is an adjective. Hence, queries with qualitative terms defined by adjectives cannot be processed which is a limitation of the BLQPS.
From the time complexity analysis it is found that time complexity is in
Footnotes
Acknowledgments
This research work has been done at Research Project Lab under Dept. of Computer Science and Engineering of National Institute of Technology (NIT), Durgapur, The Authors would like to thank Dept. of Computer Science and Engineering, NIT, Durgapur, India for academically support to this research work.