
Abstract
This paper aims to reduce the storage space required for data storage in a distributed storage environment and it provides an optimal repair bandwidth when a system failure occurs. Previous scientific literature suggests various approaches such as replication, erasure code, local reconstruction, regenerating codes etc. to overcome from system failure. These approaches are applied on archival storage, cloud storage etc. to provide data availability and reliability. Although, these approaches have proved efficient, but they have their own strengths and weaknesses as some of them deals with storage improvement and others focus on providing an effective repair mechanism. In this paper, we present a new approach, Group Repair Codes, which provides optimal repair bandwidth by replicating the nodes and calculating parity nodes for smaller groups. In comparison to approaches (hybrid and double code) that provide optimal repair, it utilizes less storage space. Moreover, it improves fault tolerance, disk reads and data transferred by the system in case of failure of nodes. The current study is conducted considering various existing approaches like replication, erasure codes, LRC, hybrid and double coding that were implemented to manage the big data. The results reported in the paper prove the suitability of our approach. We have also discussed the significance of intelligent system for the present study. We are intended to propose an intelligent based system for Group Repair Codes in the near future. We believe that our research will be beneficial for several communities such as cloud storage, big data and distributed storage.
Keywords
Introduction
Today we are surrounded by social networking, digitization, e-commerce, data analytics and lot many things that are available to us online. In order to share relevant information, various exchange mechanisms are available which generate enormous amount of data. Various researchers have suggested different methods to store and manage this data. The data is thus stored in distributed fashion with a goal to provide 100% availability and prevent the data from being lost due to any permanent or temporary failures occurring from natural or unnatural disasters. Peer-to-Peer systems, distributed and cloud storage systems implement various coding methods to store massive amount of data [1]. The most popular real time applications are OceanStore [2], Windows Azure [3], Amazon, Google File System [4], HDFS-RAID Xorbus [5], NCCloud [6].
The simplest method that can be applied in distributed storage is replication. Replication stores the same data at different locations. Maintaining multiple copies/replica at different nodes makes data readily available to the users by connecting to the nearest location where the data is stored. In case any node gets damaged, its replica stored at some other location can serve the users’ requirements and the lost data of the failed node can be recovered from any of its replica nodes [7, 8]. Though it is easier to maintain, the biggest drawback of this scenario is that it requires a lot of space because the same data has to be stored multiple times.
To address the storage issue discussed above, network coding [9] has been used. It divides the original data into smaller units, apply codes on it to obtain few redundant units and then stores the encoded data (which has original fragmented data and redundant units both) onto different nodes. To obtain the original data it has to be collected from multiple nodes and then reconstructed. If any node gets damaged, the remaining nodes are used to recover the data of the failed node. Although network coding reduces the storage requirements considerably, but it introduces some other significant considerations like 1) encoding and decoding complexities, 2) number of nodes accessed for reconstructing the original data, 3) number of nodes required to recover data of the failed nodes, 4) number of faults that can be tolerated by the system simultaneously, 5) amount of data read and transferred by each node for reconstruction or repair, 6) bandwidth required for repairing a failed node and many more.
Erasure codes [7, 10], a type of network coding technique, proves efficient for storage requirement. Reed-Solomon erasure codes utilize the minimum storage space but other issues were not efficiently dealt with. The research was carried forward to improve other parameters and as a result local reconstruction code [3, 5] was implemented to reduce node accessed for repair and repair bandwidth, but this approach used slightly more storage. New class of codes introduced by Dimakis, called the regenerating codes [11, 12] is available in two flavors – minimum storage and minimum bandwidth. In this the author had explained the use of functional repair to obtain minimum storage and minimum bandwidth of repair values. Other methods of storing data are hybrid code [13] and double coding [14, 15] which are a combination of replication and erasure codes. These codes have the optimal repair bandwidth, better fault tolerance, node access, data read and data transfer but the storage requirement in these methods is almost double the storage required in erasure codes.
The problem identified in all these methods is the trade-off between storage and repair [16], which are the two main parameters of concern. Erasure codes have minimum storage requirements but did not improve upon repair bandwidth. Other mentioned codes improved repair bandwidth by slightly increasing the storage requirement. In simple words, if the cost of repair is reduced, the storage is increased and if the cost of storing the data is reduced, the cost of repair is increased.
Motivated by this we propose an algorithm with an objective to provide an optimal repair bandwidth as in hybrid and double codes but with reduction in amount of storage that was used by these systems. The main contributions of our approach are: 1) to provide optimal repair bandwidth during failure of a node, 2) improved storage space required by the system, 3) large number of faults tolerated simultaneously, and 4) less number of nodes accessed for repair, resulting in 5) reduced disk read and data transfer.
The purposed GRC method can be applied for big data centers, cloud storage and distributed storage systems. The encoding algorithm used in Group Repair Codes (GRC) and its decoding mechanism is discussed in this paper. A comparison with existing literature and a quantitative analysis proves GRC to be efficient for various parameters already mentioned. Further, the GRC algorithm can be combined with machine learning techniques to identify confidential or sensitive data so that it can be protected from public access and provide higher security. Also, storing the data intelligently adds value to the data and may provide support for data analytics and efficient data retrieval.
The remainder of this paper is structured as follows: the relevant background and related work by researchers is discussed in Section 2. The proposed work is explained in Section 3 along with the algorithm used for encoding in Group Repair Code. This section also gives the decoding mechanisms and presents the main outcomes of our research. In Section 4, we analyze the performance of the proposed approach by comparing it with existing approaches. The result of quantitative analysis proves GRC to be efficient on multiple parameters out of which reducing the storage is our major objective. Section 5 gives the overview of how artificial intelligence can be combined with data storage and benefit us. Finally, we conclude the paper in Section 6 with future research directions.
Related work
This section highlights the research carried out by various scientists. Network coding has been applied in various fields like network communication, satellite communication, wireless sensor network and distributed storage to name a few. Our focus here is distributed storage systems. The data is stored in big data centers to provide data availability and reliability. Different approaches have been applied to store the data. Simplest of all the approaches is replication [7, 8] that maintains the same copy of the data at different locations. The users can access their data from any of the nearest location. In case any node gets damaged, its data can be recovered from other nodes where the same data is stored. Replication has been successfully used in Amazon Dynamo, Google File System [4], Cassandra of Facebook and other file storage systems. Maintaining only two replicas may result in data loss because in doing so, it may sometimes happen that while recovering the data of failed node from its only replica, this replica is also damaged, resulting in data loss. So, considering the mean time between failures of a node and the time required to recover the data, the minimum replicas required for reliable storage is three. Also it has been proved on PlanetLab trace that by maintaining three replicas, the data will never be lost [8]. Triple replication is thus widely used but it leads to three times storage requirement. To store
The large storage requirement and bandwidth for repair means lots of resources are required. With a prediction of increase in the amount of data from terabytes to petabytes in the nearer future, replication does not prove to be an efficient way for storage. So, the storage systems implemented network coding techniques. By using erasure codes [7, 10], the storage requirements are reduced to a large extent. The popular erasure coding techniques like Reed-Solomon Codes [17], EVENODD Codes [18], STAR Codes [19], Row Diagonal Parity (RDP) Codes [20], X-Code [21] and Fountain Codes [22] have been used in storage systems like OceanStore [2], Cleversafe, Facebook-HDFS RAID, HDFS [23], HP and IBM [16, 24]. In the recent research, erasure codes have also been used for hot storage or caching systems. Before that it was limited to cloud and archival data [25]. Procodes, a proactive erasure code have been implemented in cloud storage on HDFS RAID of Facebook which predicts the failure of disk prior to its occurrence and provides safety to the data [26]. The erasure codes divide the data into
The repair bandwidth was reduced in Local Reconstruction Codes (LRC) [3, 5], Locally Repairable Codes [11, 12] and Regenerating Codes [9, 10]. In LRC,
System model for Group Repair Code (GRC).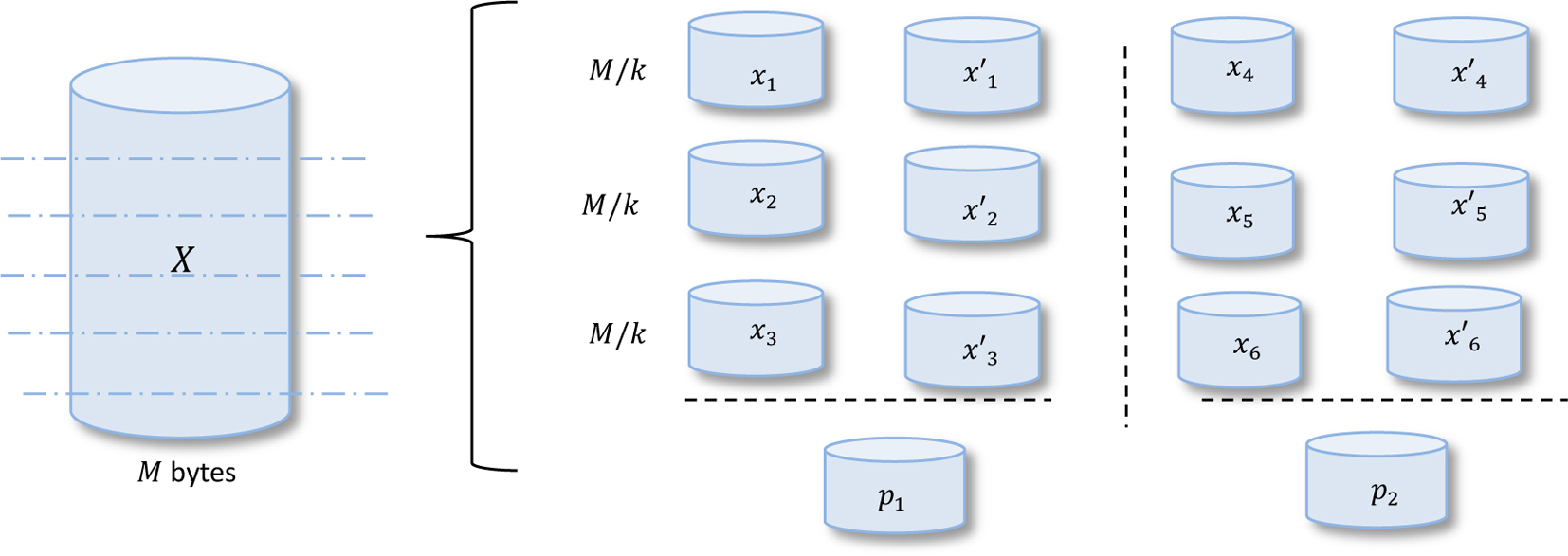
The Regenerating Codes (RC) [11, 12] is of two major types: Minimum Storage Regeneration (MSR) and Minimum Bandwidth Regeneration (MBR). It divides the data into
The above mentioned erasure codes, LRC and RC approaches have reduced either storage or repair bandwidth, but the optimal repair bandwidth is obtained from hybrid coding [13] and double coding [14, 15]. These codes use a combination of both replication and erasure codes. The hybrid code maintains one original copy of the data along with erasure coded data ending up with a total storage of
The roots of the proposed work, Group Repair Codes (GRC) lie in replication and erasure code with an objective to provide optimal repair bandwidth along with reduced storage. The GRC divides the data into fragments to form smaller groups in which they are further replicated and coded. Before explaining GRC, first let us recall what Reed-Solomon code RS(6,10) does. It divided the data to be coded in 6 equal fragments and distribute over 6 data nodes and then 4 parity nodes are computed using all these data nodes [17]. The total number of nodes here are 10 and each data node stores 1/6
Here, replication allows failures to be recovered only by accessing a single replica node and directly transferring its data thus reducing the repair bandwidth. If we use only two replica nodes without using any parity node and in case both the replicas fail simultaneously, then this results in data loss. And using three replica nodes is same as triple replication wherein the cost of storage is very high. So, GRC approach maintains two copies of the same data along with parity node to prevent from data loss. The storage requirement is thus reduced to a large extent. In GRC, replica nodes help in faster recovery and provide optimal repair bandwidth value. The purpose of parity node is that in case both of the replica nodes fail simultaneously then the data can be recovered from remaining nodes and the parity node in that group. In this case also, the recovery is done with comparatively less value of repair bandwidth because the less number of nodes are accessed within the group.
System model
Consider that the data of size
Notations used for Group Repair Codes
Notations used for Group Repair Codes
We now introduce the algorithm used for encoding data in Group Repair Code. In order to build the entire system encoding is done using the following algorithm:
We describe the encoding algorithm with value of
The data that is encoded and stored using the GRC encoding algorithm needs to be decoded in two cases. First, the decoding for reconstruction is done when the user demands for the data. For this
Proof: In GRC, each node stores
Proof: While encoding the data of parity node is calculated from the data nodes in a group. If the parity node
Proof: If both the replica nodes
Based on the above theorems for repair bandwidth we can compare GRC with hybrid and double code which have the same minimum repair bandwidth of
Comparison of repair bandwidth based on four different failure patterns for hybrid code, double Code and GRC.
Comparison of repair bandwidth based on four different failure patterns for hybrid code, double Code and GRC.
One data node fails. The repair bandwidth is minimum in all three approaches if the failed node is a data node. Only one node is accessed which transfer
One parity node fails. To recover data of a parity node, in hybrid code any
Two non-replica data nodes and one parity node fails. Consider that total 3 nodes fail, two of which are data nodes that do not have same data and one is a parity node. The hybrid code recovers the two data nodes by transferring
Both replica nodes fail. The hybrid code maintains one complete replica of
Table 2 shows the repair bandwidth for these three approaches in all 4 cases of different failure patterns. Assuming
Graph showing repair bandwidth values for four different failure patterns in hybrid, double and GRC codes.
Graph for comparing total storage required for different approaches in a distributed storage systems.
Total storage required for different approaches to store 50 Mb, 100 Mb, 150 Mb, 200 Mb and 250 Mb of data
Proof: The Group Repair Codes divide the original data of size
Using this value a comparison can be made for storage requirement for GRC with other approaches used for distributed storage like replication, erasure code, LRC, hybrid and double coding. Table 3, gives the values of total storage required for all these approaches to store 50 Mb, 100 Mb, 150 Mb, 200 Mb and 250 Mb of data. The graph obtained by plotting the storage requirements for these approaches is shown in Fig. 3. The maximum storage is required for replication and the minimum storage needed for erasure code and LRC codes. If we compare the storage requirements of only three approaches, hybrid, double and GRC, that have the optimal repair bandwidth values then it can be easily noticed that the minimum storage value is required for GRC. The aim of optimal repair bandwidth along with reduced storage requirement if thus achieved. In GRC(6, 2) there are 12 data nodes and only 2 parity nodes. If all nodes have equal probability of failures, then a data node will fail more frequently in comparison to parity node and hence the repair of the data node is done more frequently which has the optimal repair bandwidth value.
Proof: Let us suppose that all the
(a) Graph for total storage required for various approaches with different values of 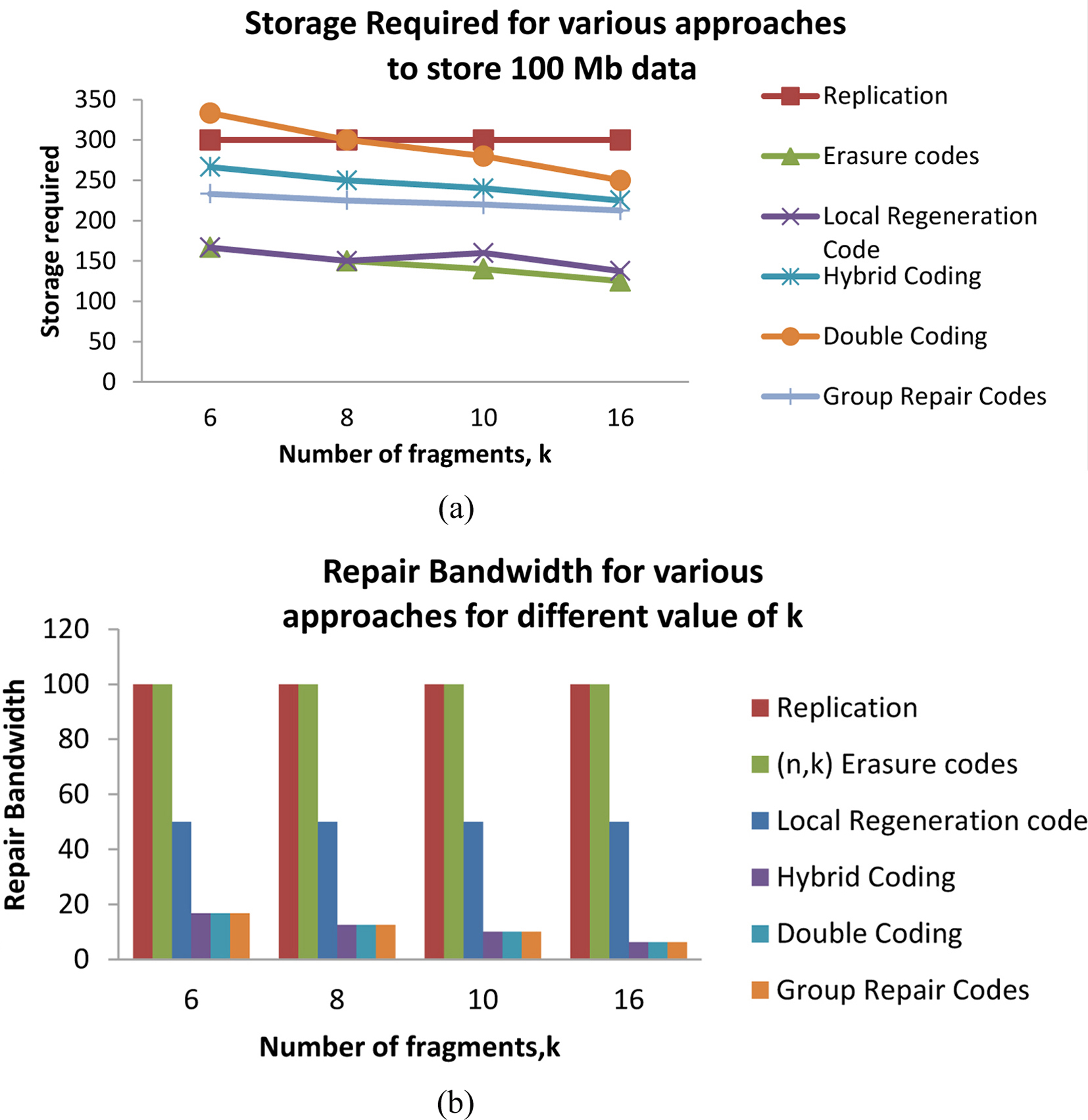
Comparison of all the approaches based on various parameters for
In this section, we compare the performance of Group Repair Code with replication, erasure code, LRC, hybrid and double coding for two different values of number of fragments,
We take a set of values for number of fragments,
Intelligent data storage: A future perspective
In the current study we have presented an approach for efficient data storage and optimal repair, but we have not made it intelligent. Supervised and unsupervised machine learning and artificial intelligence has been applied in recent study to improve the system by adding some sort of intelligence. But these have not been combined with distributed storage environment [30]. In this section, we highlight the importance of artificial intelligence for storage and related areas and we aim to extend our work in near future along with machine learning and artificial intelligence.
The relation between artificial intelligence (AI) and data storage is bidirectional. AI needs vast amount of data to train a model in order to get accurate predictions. And in return AI is needed to maintain and extract valuable data from the vast storage. To manage the stored data is challenging. When AI is applied to store the data, it can differentiate between the data which is most often used and the data which is never used, so that it can be stored in either cache or archival storage.
Furthermore, the data stored on a public cloud is accessible to all the users making it unsecure to store private and confidential data of an organization. As a result, Amazon Macie (a machine learning-powered security service) has been introduced that uses machine learning to detect certain keywords in the data, classify it and protect it from unwanted access. On combining machine learning with distributed storage, significant improvements can be made in the system. So, we aim to carry forward our work with machine learning and artificial intelligence in near future.
Conclusion and future work
This paper investigates various network coding techniques like replication, erasure codes, LRC, regenerating codes, hybrid and double codes that are applied for distributed storage to make the data easily available and reliable. To achieve this, data is replicated and/or coded. It has been challenging for researchers to design an approach which utilize less storage and is capable of efficient recovery of data during failures. We have thus proposed an approach named Group Repair Codes which provides optimal repair and efficient storage. Like hybrid and double coding, it uses two types of architecture (replication and erasure coding) for storing the data and has the optimal repair bandwidth, along with an advantage of reduced storage requirement. It divides the data into fragments, replicate the data and form smaller groups to calculate parities within the group. The GRC