
Abstract
In the contemporary surveillance schemes of Computer Vision, videos concerning human action categorization have become a predominant zone, involving Pattern Recognition tasks. Factually, most of the human actions comprise complex temporal information, and it is quite difficult to discover the diverse activities of humans precisely, in an unpredictable variety of environmental circumstances. A Deep Learning paradigm can tackle this issue, by providing additional capabilities to vision-based human action recognition. However, there are more complex challenges in extracting the spatio-temporal features, for instance, the presence of noise in videos and the highly vague feature points. This paper proposes a hybrid intelligent Intuitionistic Fuzzy 3D Convolution Neural Network that uses Chaotic Quantum Swarm Intelligence (CQSI-IFCNN), to optimize video-based human action categorization. Vagueness and ambiguity of input video frames are inherited by Intuitionistic Fuzzy networks in terms of membership, hesitation and non-membership components. By applying Chaotic Quantum Swarm Intelligence (CQSI), the learning parameters and error rates that occur in standard convolutional neural network are considerably reduced. The chaotic searching scheme is applied to overcome premature local optima in Quantum Swarm Intelligence. Therefore, this model produces optimized outcomes in Intuitionistic fuzzy 3D Convolutional Neural Networks, thus improving the categorization of human actions in videos. The Performance of CQSI-IFCNN is assessed by using the KTH and UCF Sports Action datasets. From the simulation outcomes, it is observed that CQSI-IFCNN has attained a higher rate of action categorization accuracy than standard CNN and PSO-CNN.
Keywords
Introduction
One of the toughest tasks in Computer Vision is recognition of human action. Precisely, in Video Surveillance, recognition of semantic spatial-temporal visual patterns (running, walking, jumping, etc.) is a primary computer vision issue. As such, the human action recognition system begins by extracting significant features from a given video; by using pattern recognition approach, the video is processed and classified into their resultant action category. Feature Extraction based on Deep learning [1] is essential, in several real-world applications like kinematic analysis, criminal investigation, video retrieval and surveillance. This approach gains knowledge about features, directly from the selected videos. Compared to classification of still images, video-based recognition gives significant clues to detect actions, because it has a temporal component that helps to detect actions based on the motion information.
Fusing, Intuitionistic Fuzzy and Chaotic Quantum Swarm Intelligence on 3D convolutional neural network directly obtains spatio-temporal feature information and thus prominently enriches the process of human action categorization in videos, better than what the existing approaches do.
In video-based human action categorization, the input given to the convolution neural network will be composed of video frames.
Quantum particle swarm optimization
Quantum Particle Swarm Optimization (QPSO) is a variant of conventional PSO, the development of which is inspired by the basic principles of PSO [2] and quantum mechanism. The unique feature of QPSO is its fast convergence and good searching capability. QPSO differs from conventional PSO because of its uncertainty principle, to determine both the position and velocity of a particle concurrently [3]. In the proposed approach, among
If rnd()
else
where,
There are three main aspects that makes the QPSO better than traditional PSO, which are given below:
It is an uncertain scheme, and additional diverse state of particles and larger search space can be produced in this approach, so that it can generate better offspring. In conventional PSO, convergence occurs faster and leads to local optima very easily, in a very few iterations. Once an approach falls to local optima very quickly, it fails to obtain the best solution. But in QPSO, hosting Finally, the parameters involved in the process of QPSO are much fewer than conventional PSO. Thus, they make it easier to execute the process and performance of the QPSO is significantly improved.
Chaos theory is a study area in mathematics, which is functional in Philosophy, Economics, Physics and Biology [4]. It is highly sensitive to initial conditions (due to rounding errors in arithmetical calculation) so that its effect is referred to as butterfly effect, in which a slight change in one state of deterministic nonlinear scheme can consequently lead to huge variance in a later state [5]. The chaotic variable can traverse, at a maximum search-space of interest. Even though its variation resembles disorder, it has a delicate inherent rule. Therefore, in the present work, chaotic Quantum PSO algorithm is applied to utilize unevenness and periodicity of variables involved in chaotic, to set the particles and the parameters used by QPSO. The chaotic maps greatly influence the prevention of premature convergence in PSO. In addition, it can also improve the local and global search abilities of the system [6].
Chaotic maps in PSO can be implemented by two different approaches. They are:
The performance of PSO is greatly dependent on the parameters involved in it like W, C1 c2 and random number generators. In the first approach, the chaotic maps reinforce random number generators and the variables are deprived of any fundamental modifications in the algorithm, because the performance of the PSO is highly dependent on such variables and random number generators. In the second approach, the chaos is used to discover the best solution space, by interacting with the PSO. In this approach, additional evaluation is done to find the best candidate solution, which holds the best fitness value. In each iteration, for the boundary of search space is reduced considerably to enhance an effective search. Thus, the particles are kept away from local optima. This kind of search is termed as chaos search.
Owing to the chaos effective performance, this proposed work adopts the first approach, for optimal human action categorization using Intuitionistic Fuzzy Convolution Neural Networks.
Song et al. [7] developed a CNN model as a smart phone application, to recognize the facial expression. Using this approach, the user could capture the picture and transfer it to the server. The facial expression prediction process was done by the network and the result was passed on to the user. With the help of ImageNet dataset, the model trained the network to recognize facial expression, within a couple of hours.
Bregonzio et al. [8] developed a multiple kernel learning approach, which fused features of interesting points. It used global distribution evidence to extract interest points, for recognizing action in videos. It extracted holistic features from temporal features.
Chen and Hauptmann [9] devised an approach known as MoSIFT, to find spatial interest points. SIFT algorithm was adapted on visually unique modules and it discovered interesting points of spatio-temporal with motion constraints. This approach consisted of optical flow around unique points in a sufficient amount.
Baccouche et al. [10] proposed a fully automated deep learning system, which extended CNN to 3D CNN so that it could learn automatically the spatio-temporal features, to classify human actions. With the learned features, recurrent neural network was applied to perform classification on each video sequence.
Juan et al. [11], in their work, proposed probabilistic latent semantic analysis, which handled noise present in the feature points. Noise arose due to moving cameras and dynamic background of action videos. In this approach, given a video sequence, this algorithm localized the actions of humans and categorized them.
Gilbert et al. [12], in their work, mined dense temporal features, which were grouped in hierarchical manner, to generate a complete feature set. By applying data mining approach, frequent patterns of features were discovered. Using hierarchical classifier, real time video action was recognized.
Haiam et al. [13] developed a trajectory-based representation, which captured spatio and temporal feature points termed as cuboid features, using SIFT descriptors on video frames. Using linking and exploring method, Bag-of-Words was designed. At last, to classify human actions, Support Vector Machine was applied.
Sun et al. [14] in their work, extracted significant trajectories with long duration, using SIFT descriptor and KLT tracker. With image structure, its salient features were sampled in a random manner for tracking actions. They used spatio-temporal information of video frames, to perform activity recognition.
Raptis and Soatto [15] developed a trajectory descriptor, using the statistics of spatio-temporal features of image. The final descriptor was used in video analysis and action recognition.
Overall Framework of Human action categorization using Chaotic Quantum Swarm Intelligence based Intuitionistic fuzzy 3D – Convolutional Neural Network.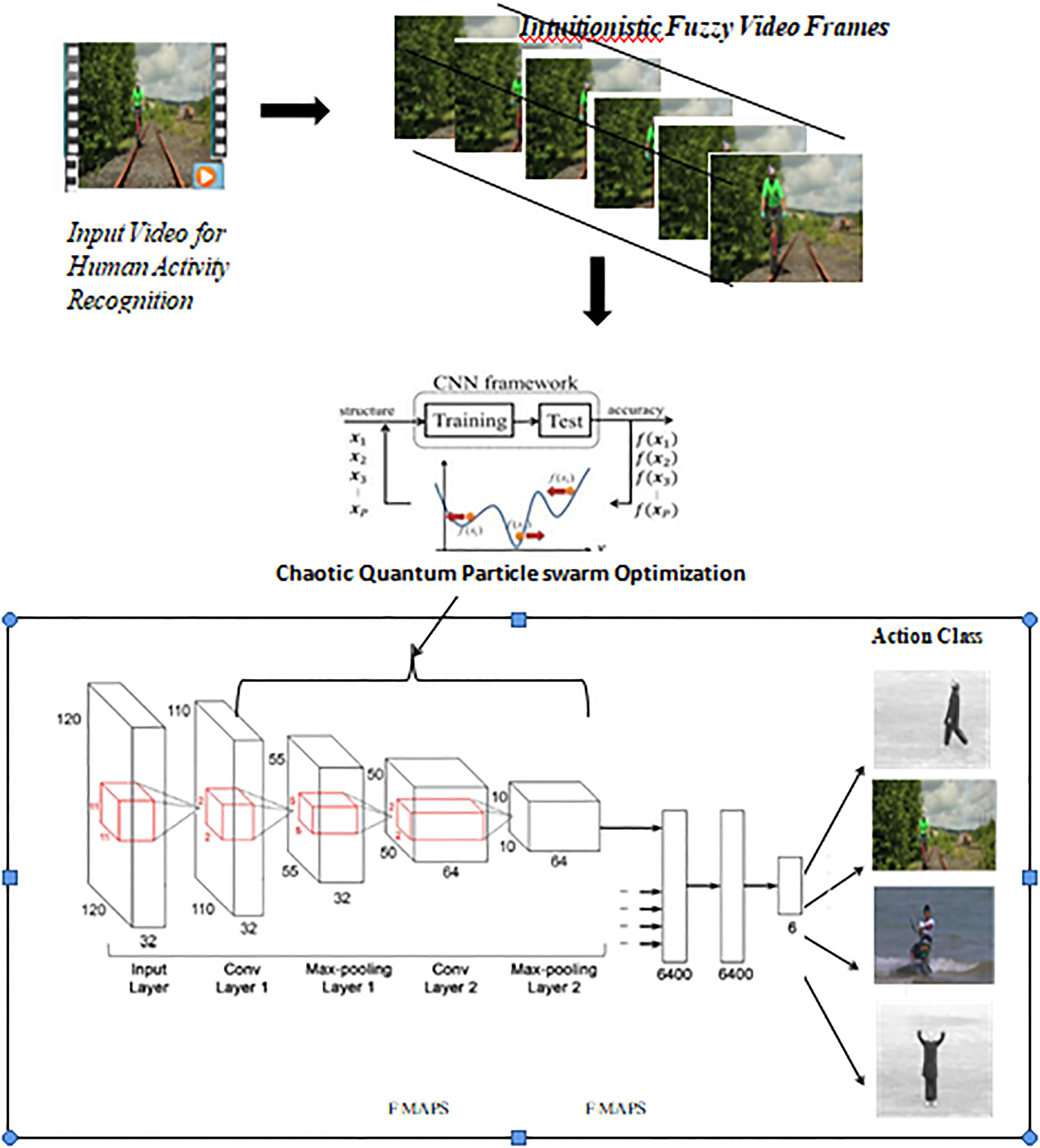
Ignatov [16] presented a deep learning approach, based on user-independent online human activity classification. The local features were extracted along with simple statistical feature using CNN, which preserved details about global system of time series. They also investigated the length of time series (which might influence accuracy) and controlled it, which made a potential continuous activity classification.
Li et al. [17] applied, unsupervised feature extraction using deep Boltzmann machine. It was not intended to capture local features of data, but its performance was superior to other existing hand-crafted solutions.
Kumaravel and Veni [18] developed a Multi-Object Categorization Model in Scenes, using Fuzzy Swarm Intelligence technique, in Deep Belief Neural Network model. The element of Uncertainty was better handled by using the Fuzzy technique.
Kwapisz et al. [19] performed activity recognition using a phone-based accelerometer. They designed a customized smart phone application and acquired data through an accelerometer embedded within it. The system had the ability to recognize various actions.
The aforementioned works on human activity recognition, nevertheless, have not established any method to handle vagueness and imprecision in video-based human action categorization. The significance of this proposed approach is, the use of optimal depth knowledge of convolution neural network in dynamic images for action categorization. Fusing, Intuitionistic Fuzzy and Chaotic Quantum Swarm Intelligence on 3D convolutional neural network, directly obtains spatio-temporal feature information, thus evidently enriching the process of human action categorization in videos, better than existing approaches.
Chaotic Quantum Swarm Intelligence fused Convolutional Neural Network for human action categorization in videos (CQSI-CNNHAC) (Fig. 1).
This work enumerates a hybrid intelligent Human action categorization, by developing Chaotic Quantum Swarm Intelligence-based, Intuitionistic fuzzy 3D – Convolutional Neural Network, for human action categorization using videos. Two different datasets are collected from most popularly used KTH [20] and UCF sports dataset [21]. After acquiring the video dataset, its resolution is enhanced by representing the video frames in terms of Intuitionistic Fuzzy Domain, where each pixel is represented using three different components, namely degree of membership (
Layers in a 3D – CNN.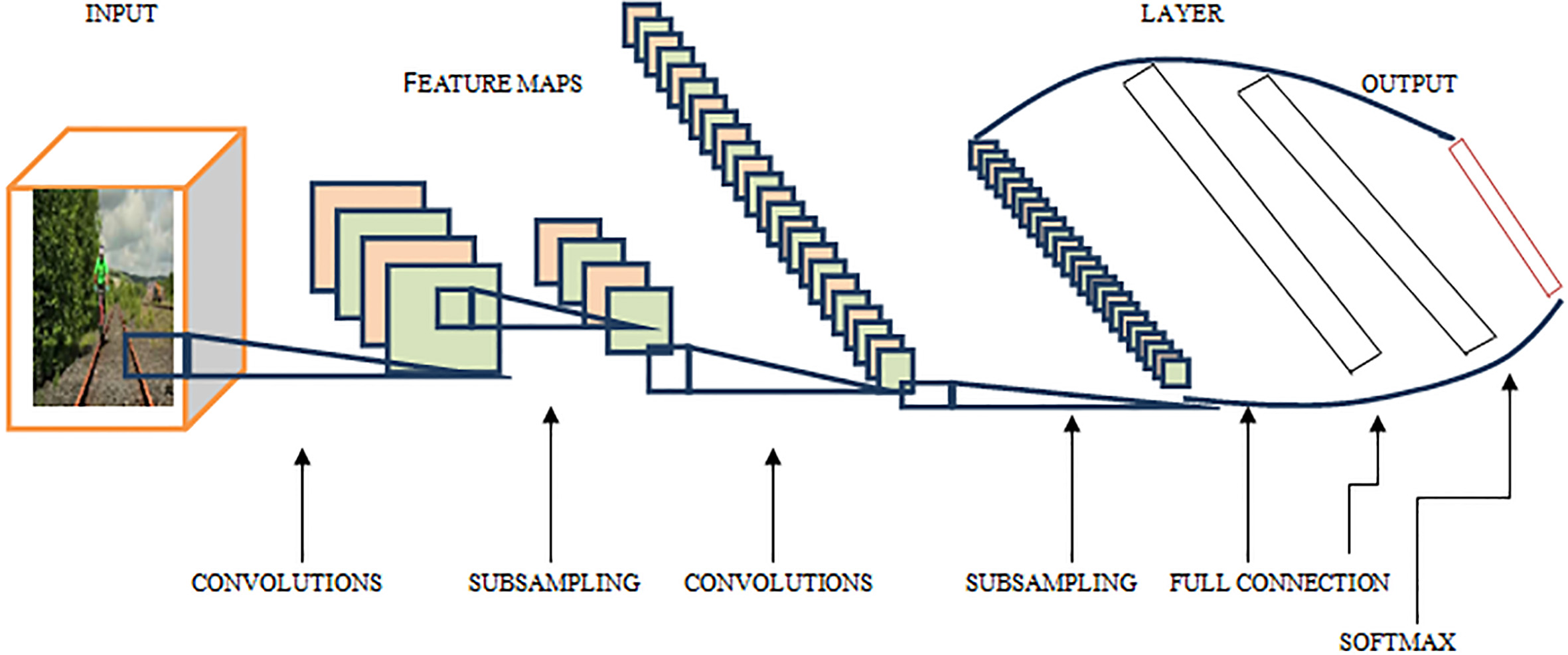
In dynamic environment, to obtain the temporal information, frame difference is applied on 3D Motion cuboid to discover the gesture in frames, identical to moving objects. By subtracting previous frame
After retrieving the temporal evidence, it is observed that 3D convolution kernel has the ability to choose any kind of feature from cuboid patch. The present design scheme of CNN is that, when the layers started increasing, the number of feature maps also grows and consequently, the different map levels give rise to increased Feature types. The value at a specific position of the video frame (
Where
Parameters’ receptive field (RF), stride length (SL), zero padding (ZP) and volume (wt, ht, dm) are used in computing the Spatial Magnitude, corresponding to the Output of the Intuitionistic Fuzzy 3D Convolution Network (Fig. 2). The neurons in the convolution layer are computed by:
The input layer of 3D CNN comprises
Each time the weight and bias of the 3D CNN are updated, the chaotic quantum swarm intelligence is applied, to assign the weights of the layers. The Chaotic Quantum based approach thus significantly handles the uncertainty in the selection of feature points to detect action and overcome premature local optima, thereby providing enriched knowledge to CNN during the training phase to yield more accurate output vectors, compared to the existing approaches, and finally, the fully connected layer produces the label of category that the human action video actually belongs to.
The detailed explanation of each stage, are given in the following subsections:
Assume the universe of discourse to be U and W a set in the universe U which comprises bright pixel values. An Intuitionistic Fuzzy image is signified using three unique subsets, namely the grade of membership (
where
A lot of versions related to PSO algorithms i.e., swarm intelligence are available. In the present work, chaotic quantum particle swarm optimization (CQPSO) is used for optimizing the vectors in video frames, processed by Convolution neural network to categorize the human activity in videos. The chaotic approach is used to traverse on a large population of particles in a chaotic motion, to select the optimal particles instead of using randomness. It also prevents the QPSO from early convergence to local optima, and the CQPSO replaces the random sequence with chaotic sequence, to gain the diversity of PSO population, and thus, it improves the performance of the algorithm by restraining the minimization of local convergence.
The logistic equation of chaotic mapping is represented as follows:
Where
The procedure of CQPSO is well-defined as trails:
Set the particle’s population at maximum iteration. Set particles’ velocities and positions by chaos theory. Compute each particle’s fitness value, according to:
where, Calculating the position of each particle using the formula:
To find the local optima, Eq. (12) is used and for global optimal position of each particle Eq. (13) is used:
where Select Produce novel Positions and velocities of particles, by quantum mechanism, as below:
Subtracting the local and global optimal value of each particle
If
Sample frames of the 4 categories. Using equations of mean best position of particles, the position of the next generation of particles is calculated. Verify whether the termination condition is reached or not. If it meets the criteria, then stop the process and output the result, else go to step 3.

If the result
In this work, the CNN consists of input video frames which are represented in intuitionistic fuzzy domain to enhance the quality of the frames. Six convolution kernels with their 5
The CQSI-IFCNN is used to improve the output vector. Using
Procedure for CQSI-IFCNN training phase
Initialize the CNN learning rate as 1. Initialize the batch size, number of CNNs epoch. Initialize CQPSO iteration. Check the convergence of CQPSO:
if the error rate has not been different for consecutive three iterations, then expect convergence. Regenerate the particles and set the position of the particles using quantum PSO theory. The vector output produced by CNNs, will be optimized using CQPSO system reducing the error rate of CNN. If the solution obtained by swarm holds lower error rate, while comparing with old output of the vector, then the vector value will be updated. CQPSO continues its process, until the maximum iteration is reached and the result of convergence is not satisfactory. The Accuracy of CNN model reflects how well it predicts the actual value during testing phase.
Obtain the original video and convert it into frames. Apply intuitionistic fuzzy Contrast intensification to enhance the quality of the video frames for further process. Pass the input frames into 3D convolution network, to identify the significant features based on spatio-temporal evidence.
In this work, the 3D CNN comprises an of 11 frame cube, to extract the motion information as input. The original frame size 160 The Intuitionistic fuzzy 3D CNN, as shown in Fig. 1, contains 120 The first convolutional layer uses 11
Overall Performance comparison of three different methods, with four categories of action video. For the layers of max pooling, the kernel size is 2
Applying Chaotic Quantum Particle Swarm Optimization to detect the optimal feature vectors for categorization of the human action
Call function CQSI-IFCNN
Lastly, the entire activation results in the preceding layer is converted into 6400 vectors of features, in the fully connected layer of CNN. The output units, which hold the result of categories of human action, are available in softmax layer. After passing the feature vectors to the fully connected layer of the 3D CNN, the class to which the selected video belongs is given as output.
This work, CQSI-IFCNN, is simulated using Matlab software. The dataset used for human action recognition is KTH Dataset [20], which comprises six different action categories like hand waving, walking, running, jogging, hand clapping and boxing. Each kind of action involves 25 different themes in four unique scenarios like outdoors, scale variation based outdoors, indoors and different clothes in indoors). The experimental setups are divided into two sets, test and train.
For simulation analysis, samples of four different categories of action video such as walking, waving the hands, cycling and surfing are selected. The KTH dataset is used for two categories namely, running and waving hands, and the remaining two categories (surfing and cycling) are collected from UCF Sports Action datasets [21].
The sample frames of the four different categories are given in the Fig. 3.
CQSI-IFCNN classifier’s confusion matrix on action-based videos are exposed in Table 2, where precise predictions are exposed across diagonal cells of the table, and, at the most, all four actions categories are predicted above 95%.
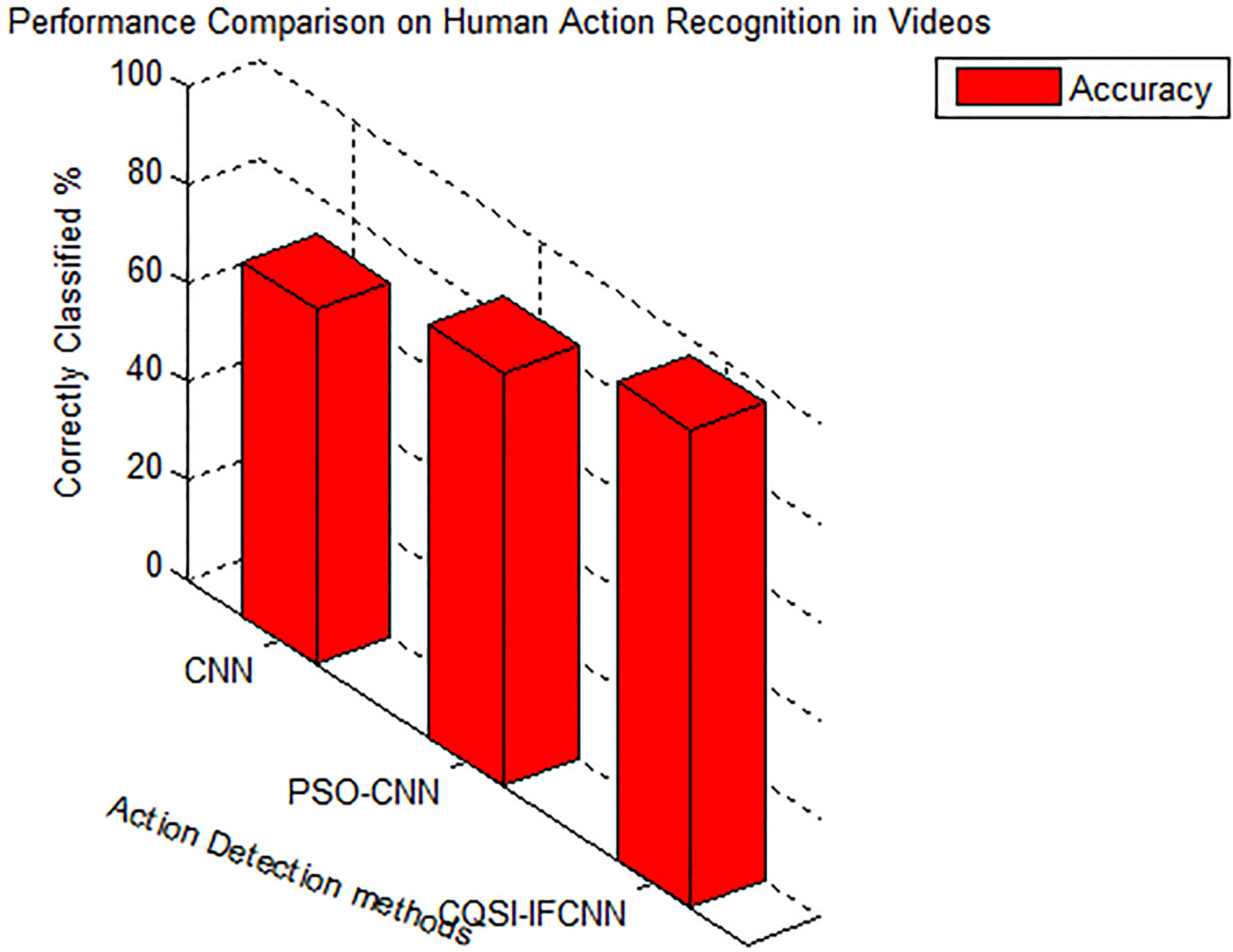
From Fig. 4, it is observed that the accuracy in categorization of human actions is greatly improved in CQSI-IFCNN. This is because the optimal knowledge gained by CQSI-IFCNN using the chaotic quantum swarm intelligence overwhelms the premature decision of action categorization and handling uncertainty by representing the video frames in intuitionistic fuzzy domain. The other two existing methods fail to handle the issues related to ambiguity, vagueness and uncertainty that arise during feature point extraction and temporal feature extraction.
Performance metrics obtained from four different categories of action categorization using CQSI-IFCNN
Performance metrics obtained from four different categories of action categorization using CQSI-IFCNN
Performance comparison of the 3 Methods, based on PRECISION.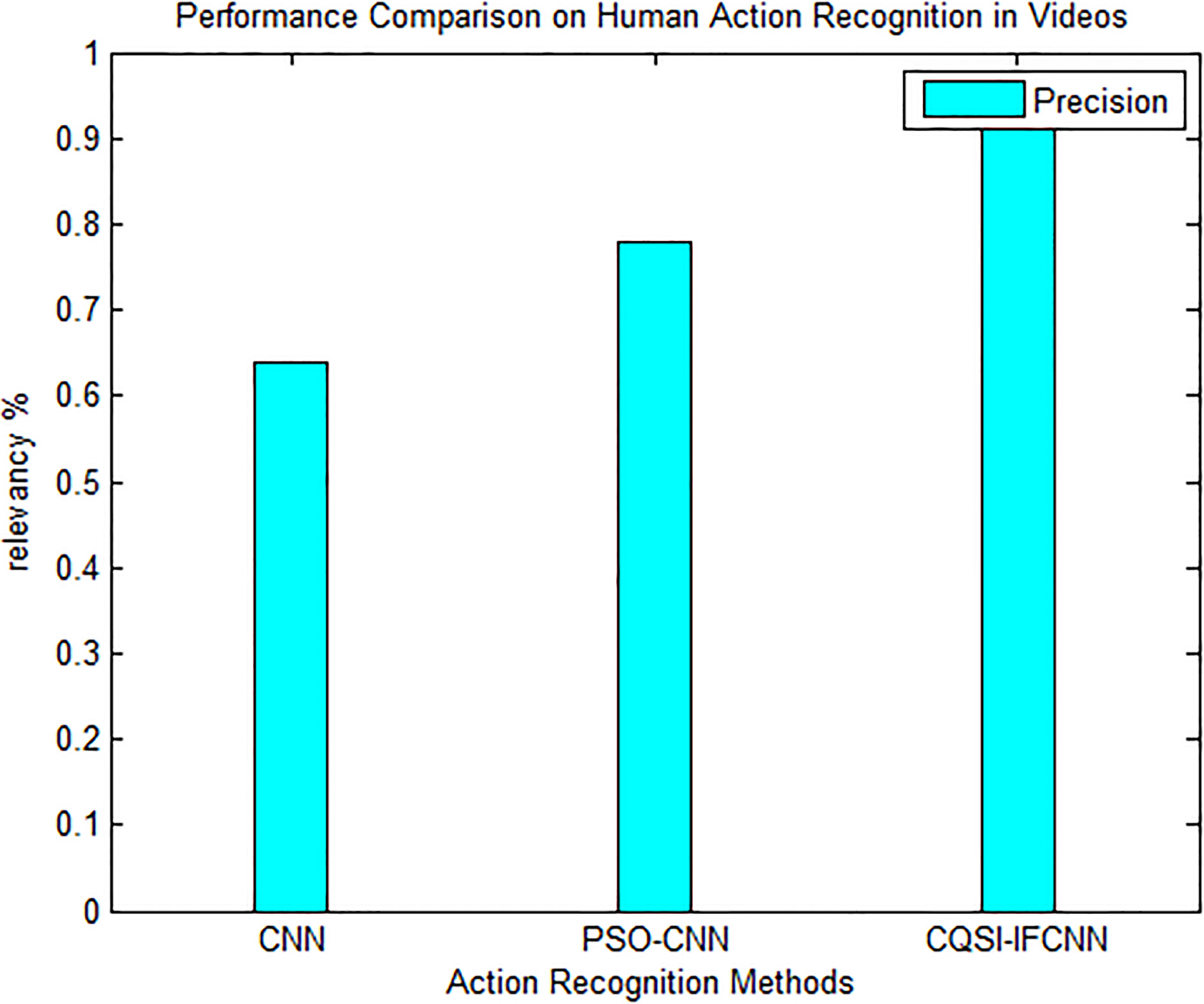
Performance Comparison of the 3 Methods, based on RECALL.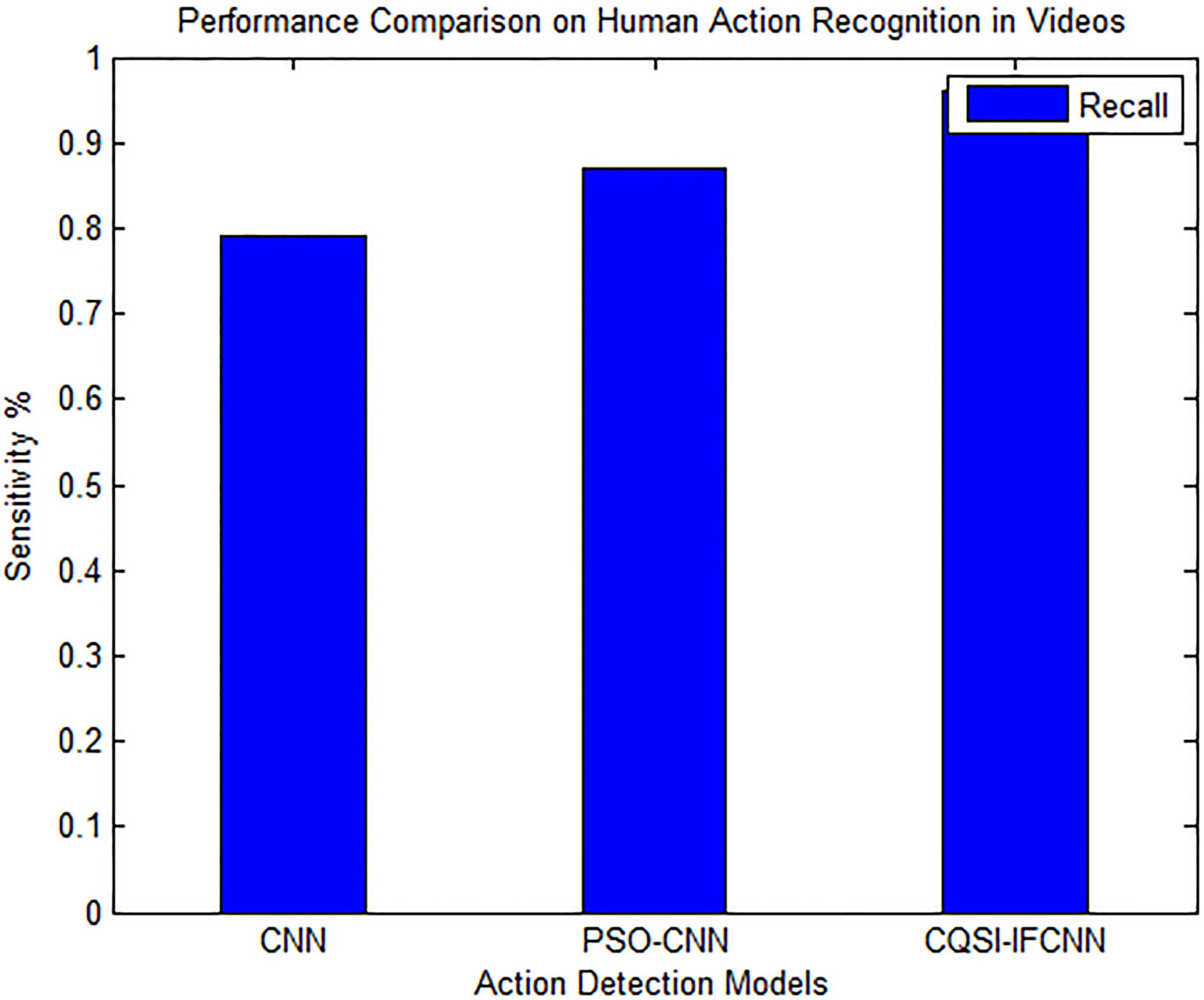
From Table 1 and Figs 5 and 6, it is observed that the average categorization rate of CQSI-IFCNN is 96.7%. This approach produces better result, while compared to standard CNN and PSO-CNN, because the CQSI-IFCNN has the ability to handle vagueness and indeterminacy in recognition of the action points of humans, in Videos.
Confusion matrix of CQSI-IFCNN for four different categories of human action
From Table 2 it is observed that the diagonal cell produces accuracy in the categorization of walking, hand waving, cycling and surfing. By reducing the dimensionality of vector search space using quantum swarm intelligence and chaotic mechanism for selecting the best feature point trajectories during the learning phase of the 3D CNN, the human action recognition is empowered.
Performance comparison of the 3 methods, based on time taken. 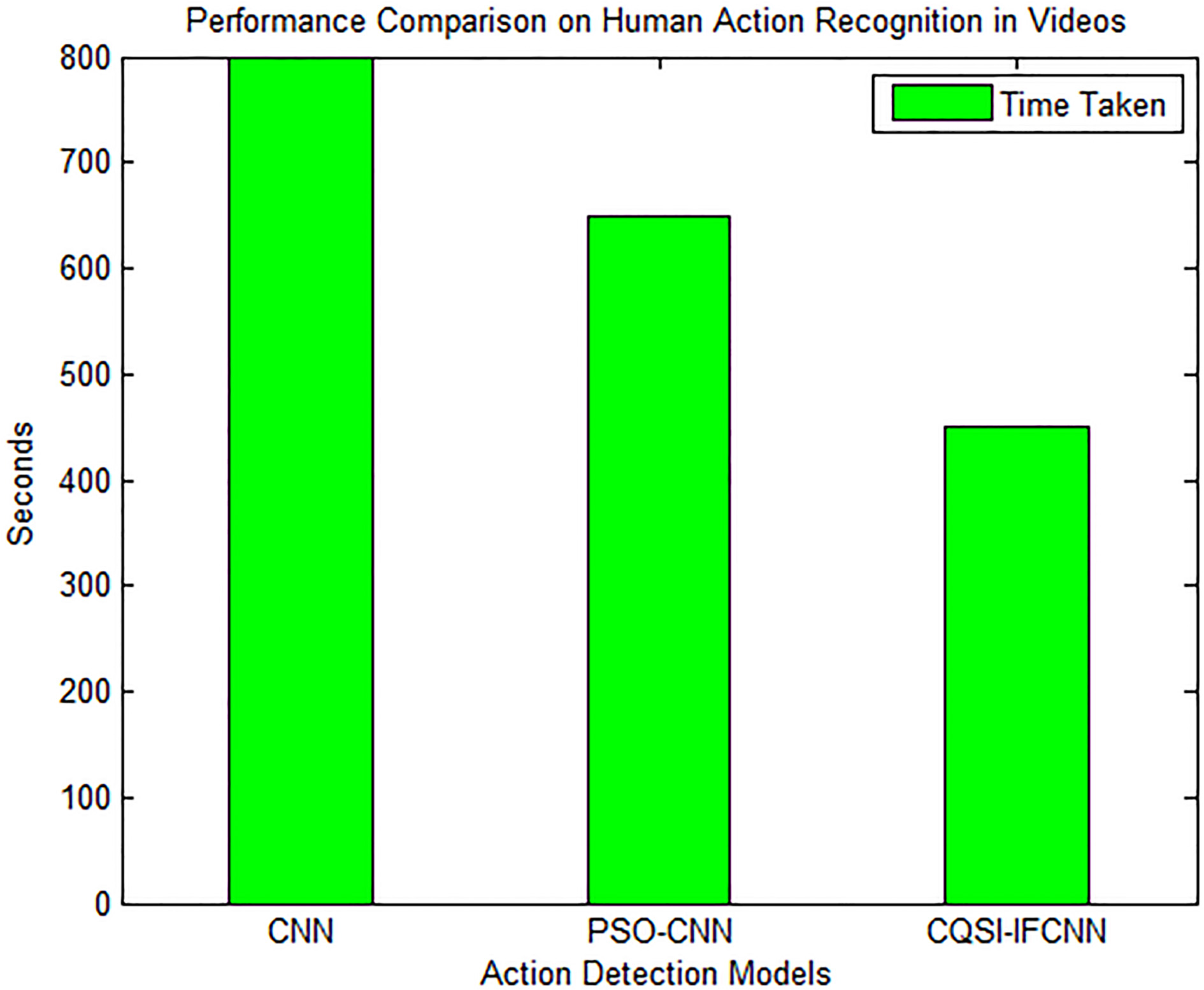
Figure 7 depicts, the time taken by three different approaches, namely CNN, PSO-CNN and CQSI-IFCNN. The time taken by the CQSI-IFCNN is considerably reduced, even after the integration of many approaches, because the frames are represented by intuitionistic fuzzy components and the premature convergence of swarm intelligence is well-handled by chaotic mechanism. IFCNN takes into account the significant features, and the search space is also greatly reduced by adapting CQSI. Thus, the process of CQSI-IFCNN is faster than the other two existing approaches, which have large search space and high computation complexity.
Performance comparison of the 3 methods, based on error rate (MSE). 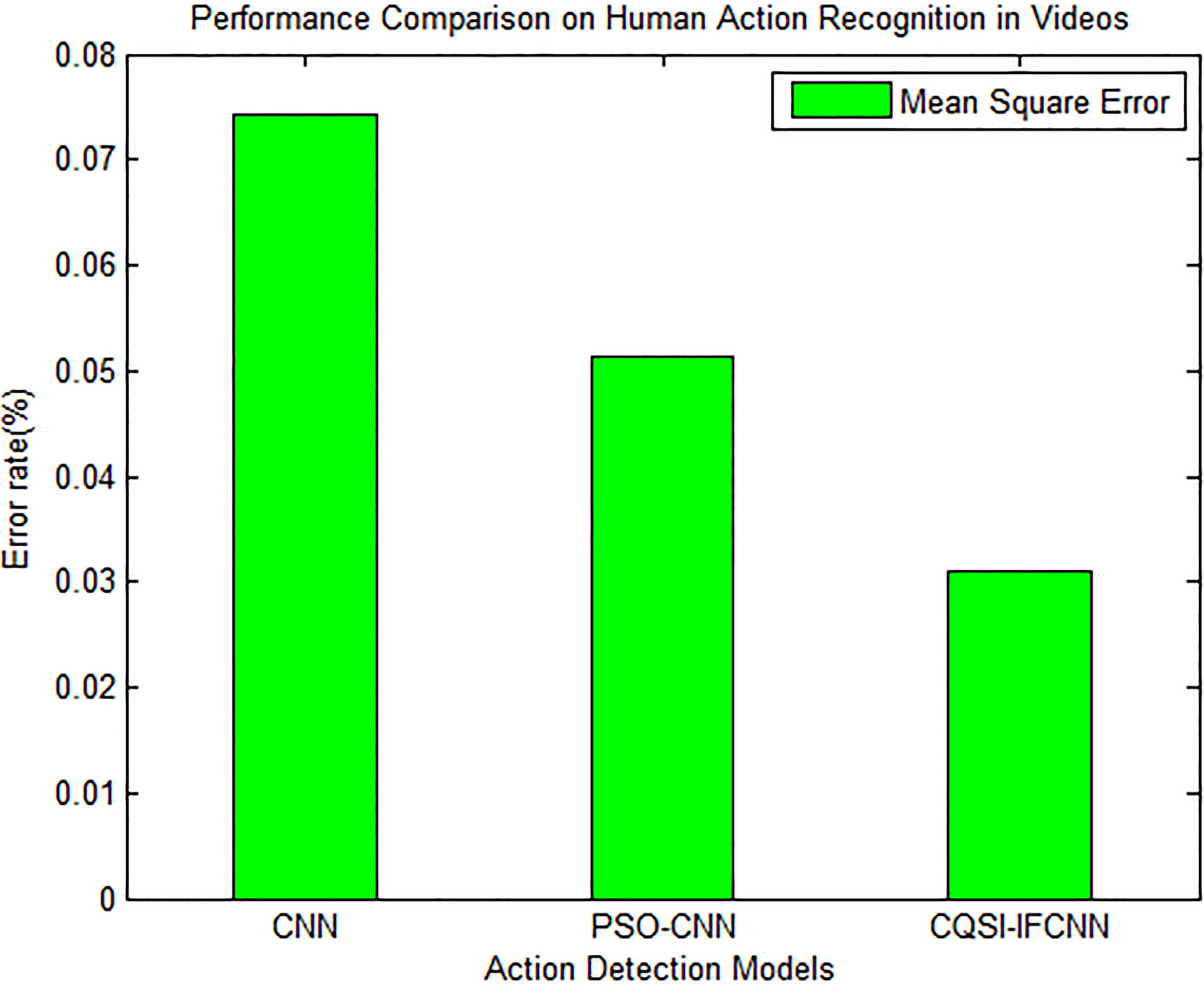
Figure 8 shows that, the CQQSI-IFCNN produces a lesser error rate of 0.0309 in action recognition, when compared to the other two models CNN and PSO-CNN, which gave error rates of 0.0742 and 0.0543 respectively. In the CNN and PSO-CNN models, the identification of significant feature vectors are done through sampling, max pooling and filtering processes, which work under random location selection; while in the CQQSI-IFCNN model, the quantum swarm intelligence is introduced, to derive the potential feature vector of spatio-temporal features more precisely and in a parallel manner, and thus, it reduces the false alarms during feature extraction.
Computation Sequence of CQSI-IFCNN e.g. CYCLING. 
Computation Sequence of CQSI-IFCNN e.g. SURFING. 
Computation Sequence of CQSI-IFCNN e.g. WALKING. 
Computation Sequence of CQSI-IFCNN e.g. HAND WAVING. 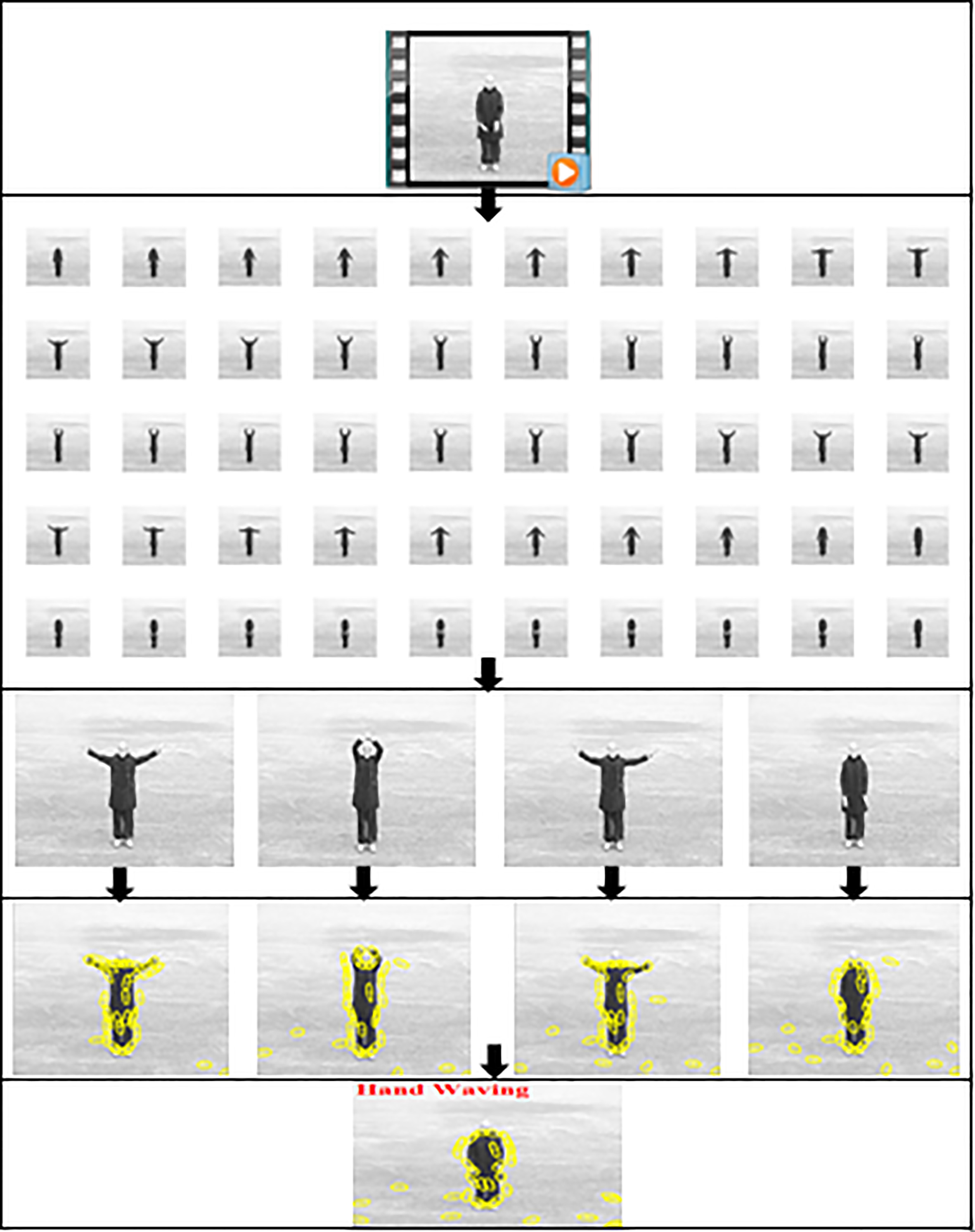
The Fig. 9 – Cycling, Fig. 10 – surfing, Fig. 11 – Walking, Fig. 12 – hand waving, show, the step by step process of CQSI-IFCNN based human action recognition. After receiving the input, the videos are converted to video frames and are preprocessed using intuitionistic fuzzy to enhance the quality of the video frames, by representing the pixels based on the components of membership, hesitation and non-membership degree. This representation inhibits the insignificant feature points under consideration. The 3D CNN, after receiving the frames, extracts the spatio-temporal features, by inducing the knowledge of chaotic quantum particle swarm optimization during the learning phase, by fine tuning the weights, bias and constant parameters. Finally, with this hybrid intelligent approach, the technique categorizes the human actions with a high degree of precision.
This work focuses on three main aspects of human action catagorization, using hybrid intelligent CQSI-IFCNN model.
in the first phase, vagueness and ambiguity pres-ent in action videos are handled by
adopting intuitionistic fuzzy representations of video frames. secondly, adopting chaotic quantum swarm inteligence to improve the knowledge of 3D CNN, in extraction of feature points and finally, fine-tuning the parameters used in the learning phase.
From the simulation results, it is observed that the CQSI-IFCNN exhibits more accuracy in human action categorization. While comparing the existing approaches like CNN and PSO-CNN, CQSI-IFCNN performs better categorization of action videos (as shown in the tables and the figures) due to its inherent knowledge, in avoiding premature selection of negative solutions and its ability to handle the uncertainty environment, which commonly arises in real time videos.
The present work can be extended to perform multi-action recognition system and automatic action captioning in videos. Other bionic behavior intelligence can be adopted for weight optimization and uncertainty handling.