
Abstract
There are many useful data mining methods for diagnosis of diseases and cancers. However, early diagnosis of a disease or cancer could significantly affect the chance of patient survival in some cases. The objective of this study is to develop a method for helping accurate diagnosis of different diseases based on various classification methods. Knowledge collection from domain experts is challenging, inaccessible and time-consuming; so we design a multi-classifier using a dynamic classifier and clustering selection approach to takes advantages of these methods based on data. We combine Forward-backward and Principal Component Analysis for feature reduction. The multi-classifier evaluates three clustering methods and ascertains the best classification methods in each cluster based on some training data. In this study, we use ten datasets taken from Machine Learning Repository datasets of the University of California at Irvine (UCI). The proposed multi-classifier improves both computation time and accuracy as compared with all other classification methods. It achieves maximum accuracy with minimum standard deviation over the sampled datasets.
Keywords
Introduction
Machine learning methods and their applications in different domains have increased because of the increasing computing power. Therefore, applications of classification methods have increased in diverse scientific fields and many researchers tried to increase the accuracy and efficiency of classification methods. An important application area is disease diagnosis due to the importance of diagnostic accuracy. Diseases and cancers diagnosis are associated with many problems among other applications, like difficulty of decision-making for diseases and cancers, the variety of diseases and cancers, similarity of the diseases symptoms, human errors, diversity of persons in each community, etc. Therefore, machine learning methods and data mining techniques are widely accepted in this field. Obviously, no dataset has all samples of a particular disease in the world and no classification method can learn all existing relationships for diseases. Consequently, there are inevitable errors in every classification method in the real world.
We can use experts’ knowledge for designing diagnosis systems but collecting experts’ knowledge is often very challenging and time-consuming. Therefore, we design a proposed Multi-Classifier (MC) to deal with classification restrictions and complexity of real data. MC is based on six methods including Naïve Bayesian (NB), Decision Tree (DT), K-Nearest Neighborhood (KNN), Case-Based Reasoning (CBR), Radial Basis Function (RBF) and Support Vector Machine (SVM). We also use three clustering methods including K-means, Fuzzy Clustering (FC means) and Particle Swarm Optimization (PSO) to improve the performances of classification methods, especially the proposed MC. In addition, we combine Forward-backward feature selection and Principal Component Analysis (PCA) feature reduction for creating a proposed feature reduction method that takes advantages of both methods.
Literature review
Classification is a great field with many applications. We study papers of Web of Science between the years 1985 and 2020 and find over 883000 results that have “classification” in their fields. According to our aims, we focus on disease and find over 6000 results that have “classifier” and “disease” in their fields. Then, we search for “multi-classifier” & “disease” and find 20 results about both of them. These results show the lack of studies about MC in disease, especially in the differential diagnosis.
In this section, we study papers related to disease diagnosis. There is the high variety of used methods in the studied papers because of different situations and disease dataset. Consequently, many authors considered MC methods for diseases diagnosis; for example, Sboner et al. used them for diagnosing a skin cancer with a black tumor in deep skin cortex [1]. They used three classification methods (Linear Discriminant Analysis, KNN, and DT) for this purpose. Their input data were some image data processing with a skin dataset by eight classes. They applied MC with significant results. Binder et al. [2] and Bischof et al. [3] designed a diagnostic support system similar to Sboner et al.’s system [1]. Daskalakis et al. designed a system for identifying malignant thyroid gland using some data taken from cell-related images [4]. They used MC with three classification methods (KNN, probabilistic neural network and Bayesian Network (BN)). Their method accuracy for the selected dataset was 95.7% and the best accuracy from other classification methods was 89.6%. Peng and Hayashi et al. have independently designed a similar MC in different applications [5, 6].
Polat et al. used MC together with DT and one-against-all approach [7]. They used three datasets (dermatology, image segmentation, and lymphographic) have been taken from UCI. Their results showed that the combined approach had better accuracy and performance than other classification methods. Nanni et al. and Polat et al. worked in the same fields and had similar results reported in Ref. 77 [8, 9]. Das et al. designed and developed MC with a neural network, DMneural, regression, and DT for Parkinson disease [10, 11]. MC had the best diagnostic performance for new data among other methods.
Wozniak et al. reviewed intelligent diagnostic systems with MC approach [12]. Their paper studied a variety of MC systems analytically. There is no specific dataset used in their paper. Rather, they proposed a system for diagnosing diseases and discussed the importance of such systems. Yin et al. designed a hierarchical system for making a better diagnosis [13]. There was a voting approach among several classification methods in their system. The processed medical sensor was their system inputs and their results showed that their designed system was very efficient for five diseases datasets.
Beevi et al. designed MC system with classification methods for detecting mitosis in breast tissue images [14]. Mitosis detection has a significant role in detecting breast cancer, but it is very difficult to find out the complexity and diversity of mitoses by considering visual limits. They used classification methods and deep belief networks for dividing cells into mitotic and non-microscopic cells. Their designed system was able to detect cells with 84.29% accuracy. Chen et al. [15], Tek et al. [16], Wang et al. [17] and Veta et al. [18] created other designed models like the aforementioned model.
Dalvi et al. combined classification methods and statistical models for detecting anemia [19]. They used Stacking, Bagging, Voting, AdaBoost, and Bayesian boost combinations for combining classification methods like DT, Artificial Neural Networks (ANN), NB and KNN. Each combination method tried to achieve the highest possible accuracy by adjusting its parameters. Finally, the stacking method achieved the highest accuracy. ANN showed the highest accuracy among other classification methods in their paper and their designed MC showed better performances. Lan et al. [20] and Bashir et al. [21] had papers like the aforementioned research. Kim et al. used several Bayesian classification methods for designing a system with the highest accuracy [22]. BN can show suitable results with learning prior information and nonlinear relationships from data. In their paper, a designed MC provides appropriate accuracies for different datasets by combining several BN. Fei et al. designed a model like the previous one for predicting and classifying customer activities for an organization [23]. Therefore, we understand that MC can be a good proposed solution for disease diagnosis according to its potential.
Used datasets
Used datasets
The steps of data preparation and standardization.
We use ten cancer and disease datasets taken from UCI datasets. In each dataset, about 20% of the data considered as test data and the rest of them as train data. We mention this number for understanding the relevant accuracies and indexes in Table 1. The number of data is in the range of 32 to 1040, and the number of features of the datasets is from nine to 69 features. There are also two, three and six classes of diseases. These intervals indicate that we focus on the significant number of datasets with different data and features; so, the results are sufficiently reliable. On the other hand, we use datasets with more than two classes of disease, so we evaluate our methods in the differential diagnosis and different disease groups. Table 1 presents some information about the selected datasets.
In the first step of data preparation, we examine the data units in each column so that each column in the dataset has a unique unit. Then, we remove all incomplete and without unit data from the datasets because of the classification methods used in this paper, which cannot work with incomplete data. However, there are other ways to solve missing and incomplete data problems, but we delete these data for learning classification methods with correct data and reducing the complexity of their learning method. We survived the noise data of each dataset as well. After deleting data with incomplete values and some noise data, we delete the features of the datasets that indicate a value for all data because these features do not contain semantics for classification methods, leading to additional operations and increased complexity.
Next, we rearrange all data randomly in each dataset because there were the same classes consecutively in some datasets. For example, assume that class of first 50 data in a dataset were all class 1 and second 50 data were all class 2; if we get first 20% of data for test data, then all of the test data have the same class and the accuracy of the classification method is not properly evaluated. In addition, this layout in a dataset occasionally led to wrong classification learning. Therefore, we mix different classes of a dataset using data rearrangement. In the fifth step, we standardize data with three methods include Z index, Min-Max, and decimal scaling. Then, we examine the standardized data and select the best standardization method for each dataset based on the correlation between the features and the data class. For most datasets, the Min-Max method is suitable because this method maintains the data behavior and makes it easier to work with the data (see Fig. 1).
After standardization, we apply feature reduction methods using PCA and Forward-backward feature selection method. Finally, we evaluate the results of this feature reduction method based on the accuracy and performances of the classification methods used herein.
A proposed feature reduction
Searching all subsets and orders for features is hard and time-consuming, especially for the dataset with a large number of features. Therefore, we use feature selection and feature reduction methods for decreasing complexity of computational results and increasing performances of other data mining methods. Every feature reduction and feature selection method considers a part of previous features and ignores other parts. Some of these methods pay attention to the value of features and some of them consider learning methods for evaluating resulting features. Therefore, their behaviors make different strengths and weaknesses for them. However, no method is best among feature selections and feature reductions. Therefore, we combine two different methods and create a proposed feature reduction method.
According to the literature review, feature selection methods are divided into three types based on their model and combination of selection algorithm:
Filter methods: These methods focus on general features like the correlation with the variables. They select features regardless of the model; for example, Fast Correlation-Based Filter (FCBF) is one of them and removes features highly correlated to each other for selecting features. Wrapper methods: They consider a learning algorithm and evaluate subsets of features, unlike filter approaches, to detect the possible interactions between features. Embedded methods: They try to combine the advantages of both previous methods. A learning algorithm takes advantage of its own feature selection process and performs feature selection and classification simultaneously.
Forward-backward feature selection is one of the wrapper methods. This feature selection has two steps, forward step, and backward step. If the forward step was more than the backward step, then it selects a number of features that make the best performances for learning algorithm and stores them. Next, it selects another number of features among stored features that the learning algorithm has better performances without them. If there is no any subset of feature that makes better performances for learning algorithm, feature selection stops, and stored features are accepted. If the forward step was smaller than the backward step, then it deletes a number of features that make the best performances for learning algorithm. Next, it selects another number of features among deleted features that the learning algorithm has better performances with them.
In the other hands, PCA is a feature reduction method that transforms the data to a new coordinate system such that the greatest variance by some projection of the data comes to lie on the first coordinate (called the first principal component), the second greatest variance on the second coordinate, and so on. The largest component selected in the PCA method has more value among different features, but it does not necessarily represent the most relevant feature for classifying different disease. PCA focuses on the value of features and ignores their effects on classification methods.
In the proposed feature reduction method, we use Forward-backward feature selection using NB as a learning algorithm. Then, we use PCA for finding a subset of features with more value. Therefore, the proposed feature reduction has the following steps:
Select Delete Select If there is no subset of features that make greater accuracy for NB, go to step 5, else go to step 2; Apply PCA and keep a subset of features with the greatest eigenvalues that summation of them is more than 90% of summation of all eigenvalues.
We use classification methods for disease diagnosis in this paper. Classification and regression are supervised-learning methods that match an instructional set of input-output pairs
The structure of supervised learning problems.
The network structure of NB is a simple structure that the class or label node is the parent of other nodes. All features are independent in its structure, so we can find every feature probability according to independent conditional probability. Despite all the limitations, the effectiveness of NB is good even when the assumed independence among the features in most datasets is unrealistic because the independence of the features ignores any relationship between them.
Decision tree method
DT is a powerful tool for classifying and forecasting. The process of classifying for each instance in this method begins by evaluating the features expressed in the root node and then decreases the tree branches according to its value. This algorithm begins by selecting a test set that performs the best separation for the classes. In the next steps, the same steps done for other nodes with fewer data to create the best rules. There are different types of developed DT such as ID3, C4.5, CART, CHILD, and MARS. We use the C4.5 algorithm as DT in our paper.
K-nearest neighborhood method
KNN was very effective when faced with large educational collections in the 1960s, but it did not welcome widely until computational power increased. KNN learning methods are based on the analogy that comparing a set of tests with educational sets that are similar. Density or proximity defined using metric distance as Euclidean, Manhattan, Geodesic, etc. In this paper, we use Euclidean distance in the KNN method.
Case-based reasoning method
CBR is one of the decisions making methods that finds solutions for a problem by focusing on previous problem solutions in a particular domain. The basis of this approach is based on a principle that similar problems have similar solutions. Therefore, after finding solutions for previous problems similar to the new problem and adapting their solutions, we can find a suitable solution to the current problem. The criterion and standard used by this method to find similarities is an important feature. In this paper, we have taken the distance of data as the criterion.
Radial basis functions method
RBF is a type of neural networks that their processor units focused on radial basis functions. Its neural networks do not differ much from Multilayer perceptron networks in terms of general structure, but they differ in the type of processing that neurons perform on their inputs. However, its networks often have faster learning and preparation processes. In fact, it is easier to adjust its neurons because of neurons concentration on a specific functional range.
Support vector machine
We often pay attention to improve the structure of the neural network by minimizing estimation errors in neural networks such as multilayer perceptron and RBF. However, in a particular kind of neural network known as the SVM, we focus on reducing the operational risk. The structure of its network has many similarities to the multilayer perceptron neural network and practically the main difference is in the learning method. This method makes a linear superficial separator with maximum margins in a larger dimensional space. In other words, we can say that the margin of a linear classification is the smallest distance among all of the learning points on the superficial separator.
Reinforcing classification learning using clustering
Clustering methods are useful when we want to put data in some similar clusters and find suitable relationships. In clustering methods, we have a training dataset
(Average distance of clusters centers or Separation – Average distance of the points within the clusters or Compactness)
According to this criterion, the greater criterion is better and it presents a suitable number of clusters. We use K-means, Fuzzy Clustering (FC means) and Particle Swarm Optimization (PSO) as clustering methods. The number of studied clusters for each dataset is between one and
Therefore, we find the best clustering method and the number of clusters according to the previous criterion. Next, we divide the data into train and test data groups, cluster data according to the best clustering method and find the train and test data in every cluster. Then, we learn every classification method with train data in each cluster, separately. When we want to predict the class of test data, we assign every test data to its cluster(s) and give it to the special classification method that learns related train data. Finally, we compare the calculated labels of test data and its main labels for finding accuracy. In this paper, we use the weighted mean for calculating classification accuracy according to the number of predicted data in every cluster.
Table 2 presents two related figures for understanding previous steps. The first figure in this table presents defined criterion variations according to the number of clusters for every clustering method. According to the defined criterion, the higher criterion is better. The second figure in this table presents all data with the first third features of a dataset in the three-dimensional space.
The output of clustering methods for one of the datasets
The output of clustering methods for one of the datasets
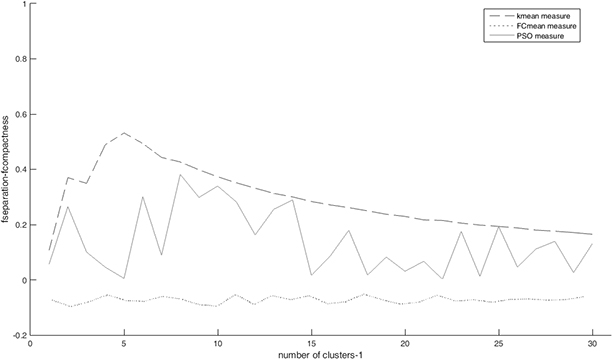
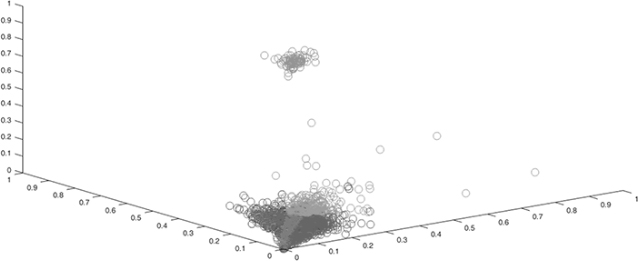
Summarily, we reduced the computation time of classification methods and their complexity using clustering and reducing the number of data for each train data. These methods have significant effects on classification performances.
According to previous steps, we make new datasets after data preparation, standardization, and applying the proposed feature reduction. Then, we use clustering methods and find the best clustering method among three clustering methods for every dataset and number of its clusters. We determine the cluster of every data and save it. Next, we select 80% of data as train data and consider them for making some rules. Rest of data are test data and the selection of test data is randomly in 10 different sets, so calculated accuracies are different for each random set. We use classification methods including NB, DT, KNN, CBR, RBF and SVM for train data of all clusters in every dataset and save their accuracy separately. These accuracies create some rules for the proposed MC. All accuracies are stored in the memory of MC. When we enter a test data to MC, it finds the cluster of this data and finds accuracies of classification methods related to this cluster. Then, it sorts these accuracies from high to low and identifies the best classification method among used classification methods. It is similar to proposed MC in the paper of Schapire [24], but there are different classification methods at previous step. The proposed MC selects one of them based on cluster of test data and accuracies of classification methods. According to samples in selected cluster, AdaBoost maintains a weight distribution over them. This distribution is uniform at first, but it updates based on following algorithm.
A set of training samples with labels
The weights of training samples:
Do the following steps for
Use the ComponentLearn algorithm to train a component classifier, Calculate the training error of
Set weight for the component classifier
Update the weights of training samples:
Selected processes in this paper.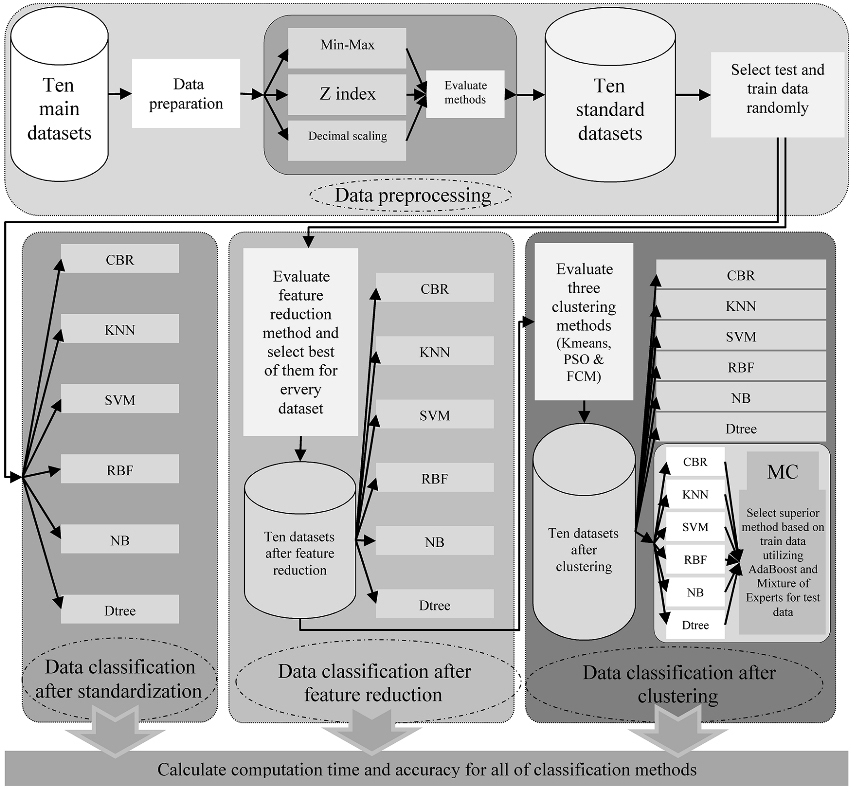
Obviously, the proposed algorithm is different for each cluster because of different selected classification method. ComponentLearn algorithm is adjusted based on this classification method. For example, we assume
Finally, Fig. 3 shows all the steps used in this paper.
The accuracy mean of classification methods
Accuracy variations for classification methods after modifying different train and test data for all datasets
We used Matlab R2015a (8.5.0.197613) 64-bit software on a personal computer with Intel (R) Core (TM) i3-2120 CPU @ 3.30GHz processor and 4.00 GB RAM for all runs. We use 10 random sets of train and test data for evaluating classification methods. Table 3 presents the accuracy mean of them.
The computation time mean of classification methods
The computation time mean of classification methods
According to Table 3, the accuracy mean of CBR is better than other classification methods after standardization (68%). Next, we use the proposed feature reduction and it improves classification accuracies. The most improvement belongs to SVM (28%) and it has the best accuracy mean (86%) as well. Then, we use clustering for improving previous results. All classification methods present better accuracy means and MC has the best accuracy mean among them (92%). In addition, CBR has better accuracy among rest of classification methods (87%).
Figures 4–6 are related to first, second and third part of Table 3 and present more details about accuracy mean variations of classification methods.
Accuracy mean of different classification methods for every dataset.
Accuracy mean of different classification methods for every dataset after feature reduction.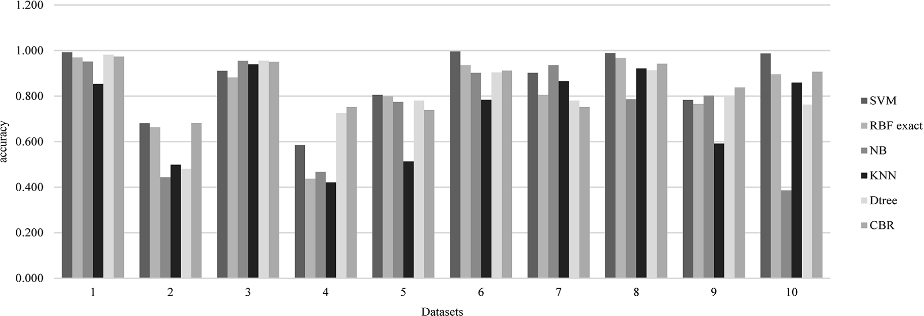
Accuracy mean of different classification methods for every dataset after feature reduction and clustering.
We use 10 random sets of train and test data for evaluating the performances of the classification methods in different datasets. Table 4 presents standard devariations for accuracies of classification methods. According to Table 4, MC has the least accuracy mean variations with random sets.
In Table 5, we present the computation time of classification methods for different datasets.
According to Table 5, the computation time mean of KNN is better than other classification methods after standardization (2.66). Next, we use the proposed feature reduction and it decreases all classification computation times. The most improvement belongs to NB (2.74) and it has the best computation time mean (0.02) as well. Then, we use clustering for improving accuracies. It increases their accuracy and computation time means. NB has the best computation time mean among them after clustering (0.79).
Every classification method has certain strengths and weaknesses. We can improve its performances using some methods but they cannot improve all of their weaknesses. In this paper, we combine Forward-backward feature selection and PCA feature reduction methods and present a proposed feature reduction method that increases accuracy and decreases computation time of all used classification methods. In addition, we use three clustering methods for dividing the datasets into smaller datasets in order to simplify the classification learning process and increase accuracy. Then, we present the MC classification method that takes advantages of all used classification methods in this paper. We evaluate and compare the performances of different classification methods based on ten disease-related datasets from the UCI website according to accuracy, computation time and variations of accuracies for different test and train datasets. We use 10 random different sets of train and test data for every dataset.
According to our computational results, we conclude that CBR has the best accuracy mean (68%) and KNN has best computation time mean (2.66) after standardization. Next, we use the proposed feature reduction and it improves all classification accuracies and computation times. The most improvement in accuracy belongs to SVM (28%) and it has the best accuracy mean (86%) as well. However, the most improvement in computation time belongs to NB (2.74) and it has the best computation time mean (0.02) as well. Then, we use clustering for improving previous results. All classification methods present better accuracy means. MC has the best accuracy mean among them (92%) and the least accuracy mean variations with random sets. In addition, CBR has better accuracy among rest of classification methods (87%). It is noteworthy that NB has the best computation time mean among classification methods after clustering (0.79).
The proposed MC presents good results for differential diagnosis in datasets with more than two disease classes. Therefore, it is a very useful method for designing a decision support system for the aforementioned cancers and diseases. Based on our extensive computational results, we believe that the proposed MC can reduce physicians’ decision errors and the cost of medical care.