
Abstract
Affect detection is a key component in developing Intelligent Human Computer Interface (IHCI) systems. State of the art affect detection systems assume the availability of full un-occluded face images. However image occlusion is a prominent problem which one comes across while dealing with such systems. The challenge is to identify affect states from portions of the face that are available. This paper proposes a novel method of assessing only a segment of the face instead of the whole face for affect detection. This paper aims at finding segments of the face which contain sufficient information to correctly classify the basic affect states. This work uses Convolutional Neural Networks (CNN) with transfer learning to detect 7 basic affect states viz. Angry, Contempt, Disgust, Fear, Happy, Sad and Surprise from a few prominent facial segments. Full face images are partitioned into separate segments viz. Right segment, Left segment, Lower segment and Upper segment. Modified VGG-16 and ResNet-50 networks were trained using each of the segments. Experiments were conducted using these facial segments and results obtained were compared with that of the full face. Using the VGG-16 network, we have been able to achieve validation accuracies of 96.8% for Full face, 97.3% for Right segment of the face, 97.3% for Left segment of the face, 96.6% for Lower segment of the face and 84.7% for Upper segment of the face. The validation accuracies are higher using the ResNet-50 network. Using the ResNet-50 network we have been able to achieve validation accuracies of 99.7% for Full face, 99.47% for Right segment of the face, 100% for Left segment of the face, 99.6% for Lower segment of the face and 90.8% for Upper segment of the face. Apart from accuracy, the other performance matrices used in this work are Precision, Recall and f1-score. Our evaluation, based on these performance matrices show that the results obtained for Right segment, Left segment and Lower segment of the face using both, VGG-16 as well as ResNet-50 networks, are comparable with that of the Full face. Experiments performed clearly indicate that Right segment, Left segment and Lower segment of the face contain sufficient information about the seven affect states and that CNN with transfer learning can be used to accurately classify them.
Introduction
Affect describes the experience of feeling or emotion. The expression of emotion is achieved through a complex combination of information produced from the body and the brain. There have been several attempts to quantify the relationship between facial expressions and the mental state of a person. Effective affect analysis hugely depends upon the accurate identification of facial features. Image occlusion is a prominent problem while dealing with identifying the various affect states. One case where occlusions frequently occur is while capturing facial expressions of students during online learning. Affect detection plays a major part in developing educational interfaces which are capable of responding to the learning needs of students. Occlusions can arise due to posture of sitting, palms on the chin, glasses etc. Automatic expression recognition systems, which are tolerant to partial occlusion remain a challenging task.
A lot of ongoing research is being carried out in the area of Artificial Intelligence (AI) and Deep Learning (DL). AI aims to narrow the communicative gap between the humans and computers by developing systems which are capable of recognizing and responding to the affect states [1].
Deep learning models extract relevant features from the data automatically and have shown to achieve very high accuracies, sometimes exceeding human performance [2]. With the evolution of DL in computer vision and advances Graphics Processing Units (GPU), emotion recognition has become a widely-tackled research problem [3].
One of the most popular types of deep neural networks used is the Convolutional Neural Network (CNN). In a CNN, filters are applied to each image from the training dataset at different resolutions. The output of such a layer is used as the input to the next layer. The filters start by extracting simple features, such as edges, and increase in complexity at subsequent layers to identify specific features that uniquelydefine the objects. These algorithms are gaining popularity and are now widely used in a variety of image detection and classificationapplications [4]. Transfer learning is a technique used in CNN in which a model trained on one set of data is used to identify features in a second set of data. CNN’s are known to give excellent results only when provided with enormous amounts of data, running into thousands of samples. Since this is not practically possible in most of the cases, transfer learning is used where a pre-trained network is trained using data from the new dataset. The main benefit of transfer learning is that it reduces the time taken to develop and train a model by reusing weights of already developed models.
This paper is organized as follows. Section 2 discusses Related works. Section 3 explains the Dataset that is used to carry out our experiments. In Section 4 we discuss the Proposed methodology used in our work. Experimental Results are provided in Section 5. This is followed by Discussion in Section 6 and Conclusion in Section 7.
Related work
A number of studies have been reported inliterature which is focused on automatic detection of affect states. Most of the papers available use systematic measurements created by Ekman and Friesen [5], which have proved to be the standard for subsequent studies in Affect analysis. They introduced a new system known as the Facial Action Coding System (FACS) whichis a broad, anatomically based system used for measuring nearly all visually noticeable facial movements.
Arushi and Vivek [6] have used CNN to classify human faces. A five layer CNN model is developed using fractional Maxpooling. They obtained a validation accuracy of 47%. They also fine tuned the VGG-16 network and obtained an accuracy of 38%.
Paper by Happy et al. [7] proposes a novel framework for expression recognition by using appearance features of selected facial patches. Eye and nose localization is performed along with Lip corner detection. Sobel filtering followed by otsu thresholding is used to achieve this. They use the Local binary patterns (LBP) for feature extraction and classification. They have achieved results varying from 87.8% for Angry to 98.46% for Surprise using the CK
While there has been some work carried out in detecting the standard affect states, there is not much research reported on detection and classification of learning centered affective states. Paper [8] deals with classifying Frustrated and Delighted smiles. In the paper, local and global features related to human smile dynamics are extracted. The authors evaluated and compared two variants of Support Vector Machines (SVM), Hidden Markov Models (HMM), and Hidden-state Conditional Random Fields (HCRF) for binary classification. Their dynamic SVM classifier obtained an accuracy of 92 percent in distinguishing smiles under frustrating and delighted stimuli.
In [9], authors introduce SPLITFACE, a deep convolutional neural network-based method that is explicitly designed to perform attribute detection in partially occluded faces. They have taken several segments of the face to determine which attributes are localized in which facial segments. The unique architecture of the network allows each attribute to be predicted by multiple segments. The authors successfully show that SPLITFACE significantly outperforms other recent methods especially for partial faces.
Large convolutional network models have recently demonstrated impressive classification performances on the ImageNet benchmark. However there is no clear understanding of why they perform so well. Paper [10] discusses a novel visualization technique that gives insight into the function of intermediate feature layers and the operation of the classifier.
a. Disgust, b. Happy, c. Surprised, d. Fear, e. Angry, f. Contempt, g. Sad.
VGG-16 is a deep CNN network which was published in 2015 [11]. In this work the Visual Geometry Group (VGG) investigate the effect of the convolutional network depth on its accuracy in a large-scale image recognition setting. They use an architecture with very small convolution filters of size 3
ResNet-50 is another deep CNN network which was published in 2016. The paper presents a residual learning framework to ease the training of networks that are substantially deeper. The paper gives exhaustive evidence to show that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth [12].
We use the Extended Cohn-Kanade dataset (CK
The database consists of 7 standard expressions viz. Disgust, Happy, Surprised, Fear, Angry Contempt and Sad. The peak expressions are shown in Fig. 1.
In our work, we have used the target frame along with a few more frames prior to it. This gave us an increased number of images to carry out our experiments. The distribution of labeled images used is shown in Table 1.
Distribution of labeled images used for experimentation
Distribution of labeled images used for experimentation
The paper attempts to understand the importance of particular segments of the face in detection of affect states. In a novel way, the paper attempts to understand which segments of the face are more effective in detecting affect states.
Pre processing
The first step was to locate the face and eliminate the background. This was done by using the Viola& Jones algorithm [14]. The extracted face image was resized to 256
a. Full face, b. Right segment, c. Left segment, d. Upper segment, e. Lower segment.
This was done on every image in the database. At the end of this procedure we arranged the images in five basic folders viz. Full face, Right segment, Left segment, Upper segment and Lower segment. Each of these folders comprised of 7 sub-folders consisting of the 7 affect states. Hence we have 5 folders each having 2502 images.
Of the total 2502 images, 70% were used for training while 30% were used for validation. Hence we had 1751 images for training and 751 images for validation. The distribution of images in the validation set is shown in Table 2. All images of the training set and the validation set were normalized.
Distribution of labeled images in the validation set
Convolutional Neural Networks (CNN) is one of the most popular deep learning architectures. Due to its practical effectiveness, there has been an increased interest in deep learning. The interest in CNN started with AlexNet which won the ImageNet competition in 2012 [15].
CNN automatically detects important features without any human supervision and is also very computationally efficient. CNN’s are found to be extremely effective in processing images. The CNN broadly compromises of three basic layers viz. convolution layers with Rectified Linear unit (ReLU), sub-sampling layers, and fully connected layers. Convolution and sub-sampling layers are repeated depending on the application and the accuracies obtained and are finally connected to the fully connected layer.
The convolutional layer is basically the filtering layer. It takes images from the dataset and performs 2-dimensional convolution using a set of filter masks. This is done by moving the filters horizontally and vertically and computing the dot product of the mask coefficients, known as weights with the input. A bias term is then added to the result. The initial values of the weights are randomly generated from a Gaussian distribution which has a mean equal to 0 and standard deviation equal to 0.01. The initial bias is by default equal to 0. These filters are applied to each training image at different resolutions, and the output of each is used as the input to the next layer. The filters start identifying simple features such as edges and increase in complexity in subsequent layers to identify complex features that uniquely define the object.
ReLU is a non-linearity function which converts all negative values to zero. A ReLU layer basically performs a threshold operation where all values less than zero are made equal to zero. ReLU is very simple to implement and forward and backward passes through a ReLU are just a simple if statement. This substantially reduces the computational cost for training of the network.
The sub-sampling layer down samples the images thereby reducing the spatial resolution. Sub-sampling makes the network more robust. The most commonly used sub-sampling technique is Max pooling. The max pooling layer outputs the maximum values of a rectangular regions. The size of this rectangular window is set by the user. Max pooling layer scans through the image input horizontally and vertically in step sizes known as stride.
Several repetitions of convolution with ReLU and sub-sampling are used. The final convolution layer is flattened and is connected to the fully connected layer. The fully connected layer has all its neurons connected to all the neurons in the previous layer. This layer combines all of the features that the network has learnt in the previous layers. The fully connected layer results in an N dimensional vector, where N is the number of classes in the dataset.
This is then given to the classification layer which selects the desired class from the list of N classes present in the dataset. A typical block diagram of CNN architecture is shown in Fig. 3 [16].
Schematic of CNN architecture.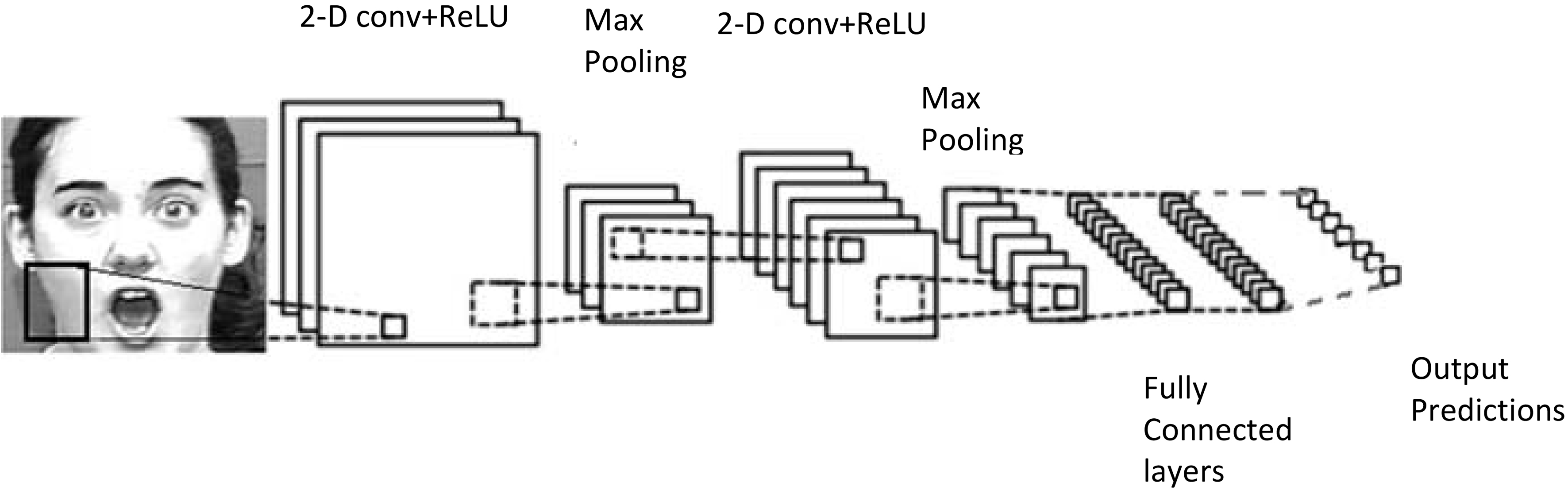
A schematic of VGG-16 network trained on ImageNet database.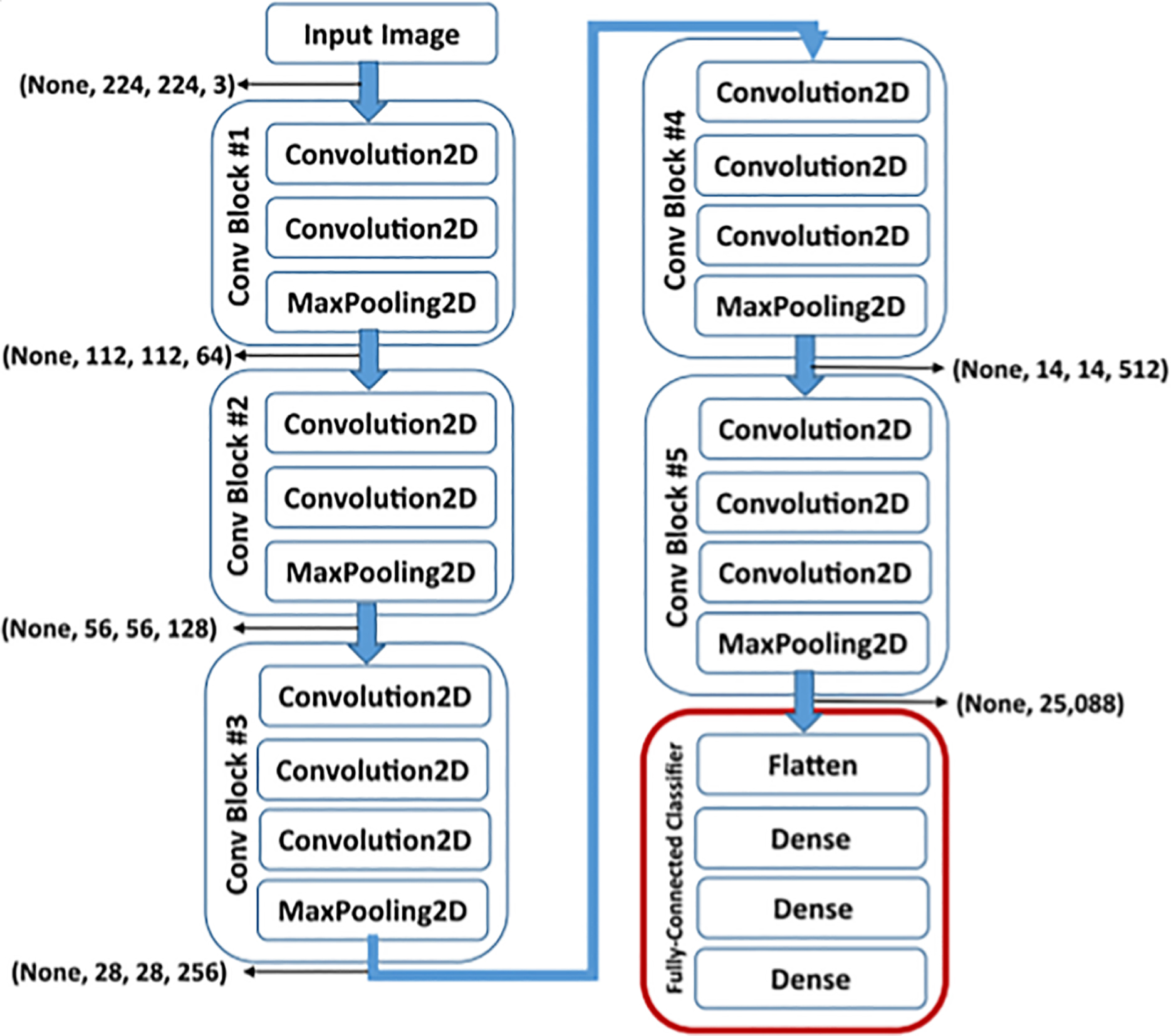
Residual learning: a building block.
We used the Keras deep learning framework [17] which includes various pre-trained deep learning models along with their weights. In this work we use the VGG-16 network and the ResNet-50 network. The VGG-16 network was trained on the ImageNet database [18]. The ImageNet database contains more than 3.2 million annotated images distributed over 5247 categories [19]. Because of the extensive training that the VGG-16 network has undergone, it is known to achieve excellent results even when applied to other, much smaller image datasets.
The VGG-16 network consists of 16 convolution layers with very small receptive fields of 3
In our work we replace the top fully connected layer with a new layer and use the VGG-16 network as a classifier to classify the 7 classes under study.
ResNet-50
ResNet-50 which is a short form of Residual Networks is similar in architecture to networks such as VGG-16 but has an additional identity mapping capability. It consists of 50 layers. Instead of fitting the latent weights to predict the final emotion at each layer, Res-Net models fit a residual mapping to predict the delta needed to reach the final prediction from one layer to the next.
When deeper networks start converging, the accuracy of the network tends to get saturated and then degrades rapidly. This problem is solved by ResNet by introducing an identity shortcut connection that bypasses one or more layers to make the architecture more efficient. ResNet-50 diminishes the vanishing gradient problem by allowing a alternate shortcut path for gradient to flow through. The identity mapping permits the model to bypass a CNN weight layer if the current layer is not necessary. This further helps the model to avoid over fitting to the training set. The basic unit of ResNet-50 is shown in Fig. 5 [12].
Results
In this section, we discuss the results of using pre-trained VGG-16 and ResNet-50 networks as feature extraction and classification methods to categorize an image into the seven affect states viz., Anger, Contempt, Disgust, Fear, Happy, Sad and Surprise.
All our experiments were developed in Keras and trained using Intel Core i5-7200U (7th Gen) CPU on 64-bit Window 10 OS.
The VGG16 has 16 layers including the 13 convolutional layers. These 13 convolution layers use a filter size of 3
As mentioned earlier, Full face and the 4 other face segments are passed through the modified VGG-16 and ResNet-50 networks separately. These networks are trained for the face as well as for the facial segments. The networks are trained using the images from the training set and tested using images from the validation set. The training set and the validation set comprised of 1751 and 751 images respectively. We shuffle the data to randomize in order to train the network better. Validation set comprises of images that the network has not seen before. The image batch size was set to 32 and all the networks were trained for 25 epochs.
The training and validation accuracy at the end of 25 epochs for each of the expressions is given in Table 3.
Training and validation accuracy of VGG-16 and ResNet-50 at the end of 25 epochs
Training and validation accuracy of VGG-16 and ResNet-50 at the end of 25 epochs
It is observed that the validation accuracy for Right segment, Left Segment and Lower segment is very high for both the networks and is comparable with that of the Full face. For VGG-16 the validation accuracy is in the range of 96% to 97% while for ResNet-50 it is in the range of 99% and 100%. The validation accuracy for Upper segment is lower than the other segments at 84.69% and 90.81% for VGG-16 and ResNet-50 networks respectively. The validation accuracy curves for Full face and the four facial segments using VGG-16 and ResNet-50 are shown in Fig. 6.
Validation accuracy of Full face, Right segment, Left segment, Lower segment and Upper segment.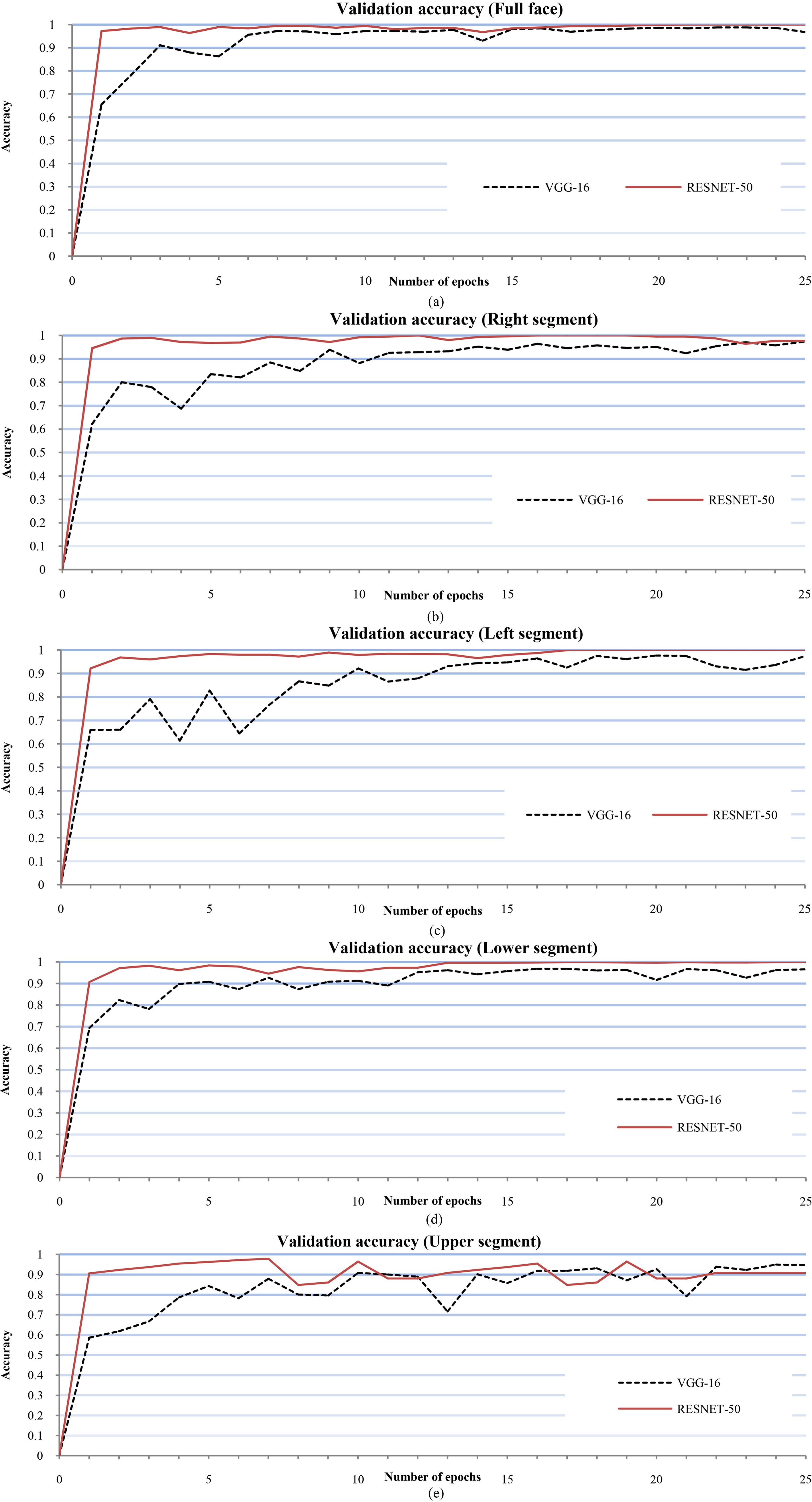
Precision values obtained for various segments of face using VGG-16 and ResNet-50
VGG-16 confusion matrix (a) Full face, (b) Right segment, (c) Left segment, (d) Lower segment, (e) Upper segment.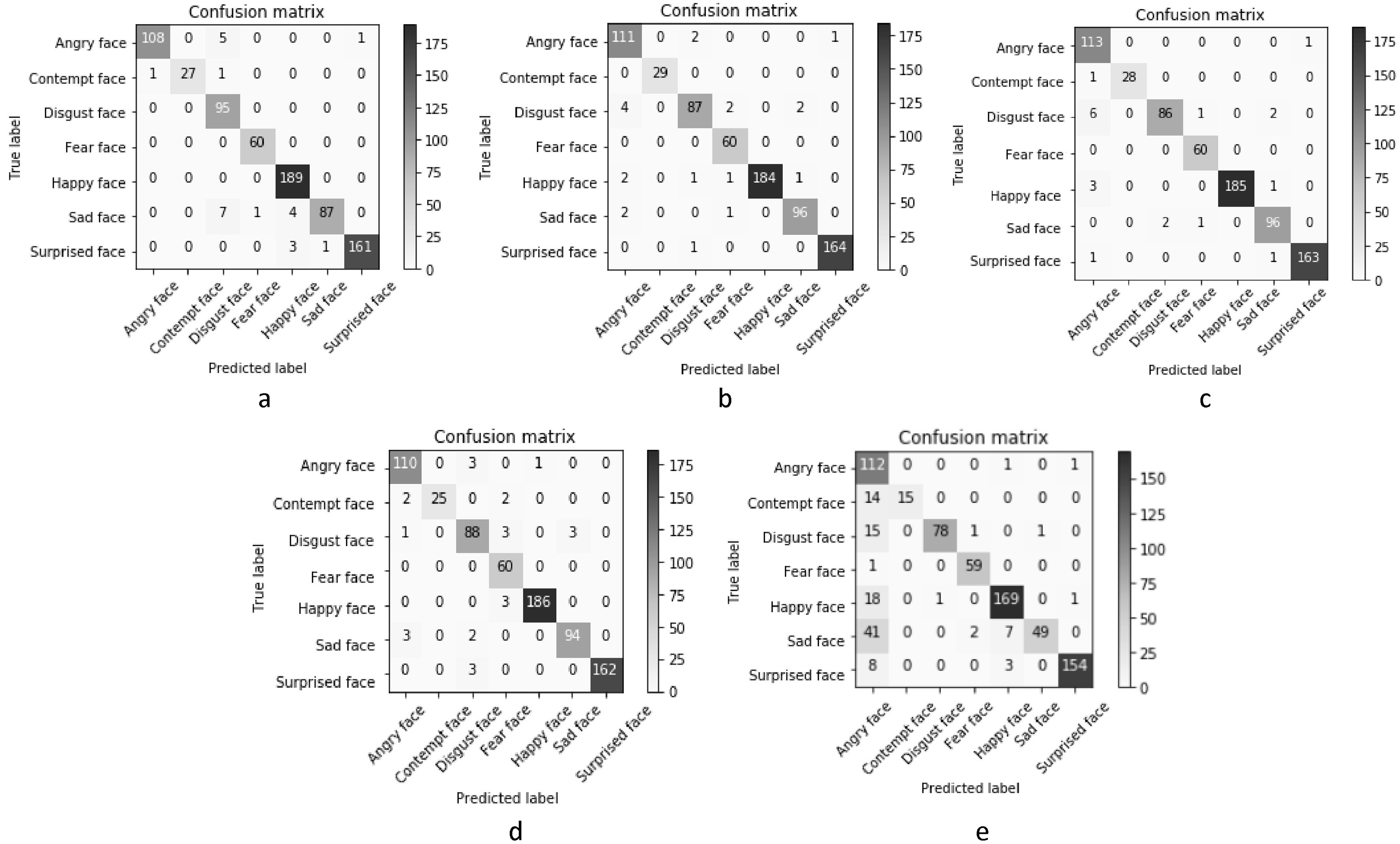
Recall values obtained for various segments of face using VGG-16 and ResNet-50
ResNet-50 confusion matrix (a) Full face, (b) Right segment, (c) Left segment, (d) Lower segment, (e) Upper segment.
f1-score values obtained for various segments of face using VGG-16 and ResNet-50
It is clear that for both, VGG-16 as well as ResNet-50 networks, the Right segment, Left Segment and Lower segment curves approach the Full face accuracy curves at the end of 25 epochs however the Upper segment curve for both the networks is oscillatory and thus performs poorer compared to the other facial segments. Based on the accuracy values and curves we can state that the affect states can be successfully identified from the Right segment, Left segment and the Lower facial segments and their accuracy is comparable to that of the entire face.
From all the curves in Fig. 6, it is evident that ResNet-50 reaches higher accuracies in a fewer number of epochs as compared to the VGG-16. Hence ResNet-50 is not only slightly more accurate but also achieves this accuracy in lesser time.
While accuracy is one of the measures used to test a model, it tends to be misleading at times. Apart from accuracy we have, in this paper, used Precision, Recall and f1-score and Confusion Matrix as performance matrices to evaluate the results obtained. Precision, recall and f1-score depend on True positives (TP), True negatives (TN), False positives (FP) and False negatives (FN).
Precision is the ratio of correctly predicted positive observations to the total predicted positive observations and gives us the false positives.
Recall is the ratio of correctly predicted positive observations to the all observations in actual class
f1-score is the weighted average of Precision and Recall and therefore takes both, false positives and false negatives into account. This measure is useful especially if we have an uneven class distribution.
Results obtained for Full face, Right Segment of face, Left Segment of face, Lower Segment of face and Upper segment of face using VGG-16 and ResNet-50 networks are illustrated in the form of tables and confusion matrices. To help assess the performances of individual segments, the results obtained have been rearranged in terms of Precision, Recall and f1-score for the different affect states.
Precision and recall values can also be expressed in the form of a confusion matrix. Figures 7 and 8 give the confusion matrices obtained using VGG-16 and ResNet-50 networks for each of the facial segments. The precision value for each of the affect states listed in Table 4 can be obtained from the respective columns of the confusion matrix while the recall value for each of the affect states listed in Table 5 can be obtained from the respective rows of the confusion matrix.
The confusion matrix gives a pictorial representation of the number of images which are correctly classified.
Both, VGG-16 as well as ResNet-50 networks, perform very well for Right segment, Left segment and Lower segment of the face and have validation accuracies comparable to that of the Full face. The ResNet-50 reaches a validation accuracy above 99% while the VGG-16 reaches a validation accuracy between 96% and 98%. From the accuracy curves in Fig. 6a–d we note Resent50 achieves a high validation accuracy in fewer epochs compared to the VGG-16 and hence is faster of the two networks.
Tables 4 and 6 give us the Precision, Recall and f1-score achieved for various segments of the face. It is observed that we get very high Precision, Recall and f1-score values for Right segment, Left segment, and Lower segment of the face for all the 7 basic expressions using VGG-16 as well as ResNet-50 networks. The results obtained for these segments are comparable to that obtained using Full face.
ResNet-50 network performs marginally better than VGG-16 giving 100% precision and recall for classifying most of the affect states from the Right, Left and Lower facial segments. The VGG-16 network also gives very high precision and recall values of above 96% for the Right, Left and Lower facial segments. We can thus state that effective affect state classification is achieved using CNN with transfer learning even if one of these three facial segments viz. Right segment, Left segment and Lower segment is available.
The Upper segment performs poorly compared to the other segments of the face. The validation accuracy for Upper segment of the face drops to 84.7% and 90.8% for VGG-16 and ResNet-50 respectively thereby indicating that the Upper segment of the face does not contain as much information about affect states as the other segments of the face.
If we observe the last column of Tables 5 and 6, we note that some affect states are not faithfully classified from the Upper segment using either of the two networks. VGG-16 and ResNet-50 gives us a precision of 54% and 84% respectively for classifying anger using the Upper segment of the face. Similarly VGG-16 gives us a recall of 52% and 49% for classifying Contempt and Sad respectively from the Upper segment of the face. ResNet-50 gives us a recall of 74 % for classifying Sad from the Upper segment of the face.
The f1-score is dependent on the precision and recall values. Observing the last column of Table 6 we note that VGG-16 gives us low f1-scores of 69%, 68% and 66% for classifying Angry, Contempt and Sad expressions respectively from the Upper segment of the face. Similarly ResNet-50 gives us low f1-scores of 87%, 85% for classifying Fear and Sad expressions respectively from the Upper segment of the face.
Apart from precision, recall and f1-score, we have also computed the confusion matrix which is a summary of all predication results and gives us an actual count of correctly classified affect states for different facial segments. The confusion matrix is computed for classifying all the facial segments using VGG-16 as well as ResNet-50 networks.
The confusion matrix of the Upper segment using VGG-16 is shown in Fig. 7e. From this confusion matrix it is clear that 41 Sad states, 18 Happy states, 15 Disgust states, 14 Contempt states and 8 Surprised states were wrongly classified as Angry (54% Precision). Similarly 14 Contempt states were wrongly classified as Angry (52% Recall), 41 Sad states were classified as Angry and 7 Sad states were wrongly classified as Happy (49% Recall). 15 Disgust states were classified as Angry (Recall 82%).
The confusion matrix of the Upper segment using ResNet-50 is shown in Fig. 8e. It is clear that this network is superior to the VGG-16 network. From this confusion matrix it is clear that 18 Sad states, 1 Fear state and 2 Disgust states were wrongly classified as Angry (84% Precision). Similarly 11 Happy states were wrongly classified as Disgust and 9 Happy faces were wrongly classified as Fear (89% Recall),
We thus note that the Upper segment of the face does not contain sufficient information to detect Angry, Contempt and Sad states accurately.
Based on all the performance matrices mentioned here, we can infer that Right segment, Left segment, and the Lower segment of the face contain sufficient visual information required to classify the various affect states. The experimental results presented in this paper show that CNN with transfer learning gives us very high accuracies and hence can be used to classify affect states even when there are substantial occlusions present in facial images.
Conclusion
This paper proposes a novel method of assessing only a segment of the face instead of the whole face for affect detection. Using CNN with transfer learning shows that instead of the entire face, we only need sections of the face to accurately classify the various affect states. Experiments were performed on the CK
The results obtained also suggest that the entire face, even when available, is not required to detect the affect states. We can thus conclude that Right segment, Left segment, and the Lower segment of the face contain rich visual information which is sufficient for correctly classifying the various affect states.