
Abstract
There is a greater need to develop and establish Artificial Intelligence (AI) and its subdomains, as the computing requirements are increasingly met by the emerging hardware technologies. The machine-learning techniques are well suited for the learning-based AI applications that are useful to our daily life. Further, the machine-learning applications can resolve numerous problems of the South Indian Classical Dance (SICD). Nevertheless, these aspects are not yet addressed thoroughly owing to the vastness of the domain. Moreover, the lack of a combined expertise in both domains of the SICD and the computing aggravates the problem. The automatic identification and annotation of a vital aspect called sthanas (foot postures) are necessary for the process of digitizing, archiving and analytics of the SICD. Hence in this paper, we propose a framework to classify the SICD images based on the foot sthanas. The proposed framework incorporates methods to convert raw data to a curated dataset, and extract principal features that are unique to the various foot posture in classical dance, in order to generate an accurate classification. Among the different techniques that were used to evaluate the accuracy, Naive Bayes, trained with the domain-specific features, outperformed all other classification models. The methodology followed in this work can be applied to various national and international dance forms with proper incorporation of their domain-specific features.
Keywords
Introduction
General postures of six sthanas.
The recent initiatives towards digitization of art [1] has alleviated the difficulties in preserving the culture of art forms through archiving. The Indian classical dance or Shastriyanritha [2] is one of the widely recognized art forms, and the works like Natya Shastra [3], Abhinaya Darpana, and Thandavalakshana have expounded its theories and practices lucidly. The digitization of these data opens up the possibilities of computation analysis since the domain is potential. For example, different computational tools can be used to analyze the concept of Karanas in South Indian Classical Dance (henceforth SICD). The Karana consists of three elements called Sthanas or static postures of feet, Nritha Hasthas or movement of arms, and Chaaris or movement of legs and feet. In this work, automatic identification of sthanas (static postures of feet) from images and video segments, which alone posed a problem that requires an efficient computational model for analysis. The set of sthanas slightly alters with each dance form, even though Natya Shastra and Abhinaya Darpana have defined the static foot postures in SICD as a whole. Even though the sthanas are primarily defined based on the lower body and the legs, the entire body posture of the dancer marks its features. In this paper, sthanas as they figure in Kuchipudi dance form, in accordance with the definition of Natya Shastra. In Natya Shastra, sthanas are defined according to their geometrical peculiarities such as Vaishnava, Samapada, Vaishakha, Mandala, Alidha, and Prathyalida. Hence, this work consider these six different classes of Sthanas for classification and analysis. The following Fig. 1 shows the general postures of these sthanas.
We adopted a pipeline of computational processes like Digital Image Processing, Computer Vision, and Machine Learning techniques in order to classify SICD images according to the sthanas of the dancer.
The primary challenge for the work was the unavailability of dataset for the SICD Sthanas. Initially, the Image Processing and the Computer Vision experiments were performed on images available on the internet. Gradually, we created our own dataset for the SICD sthanas that consists of around 500 images of 6 sthanas. These images were collected from dance videos available on the YouTube and archives of different dance schools.
The Image Processing and The Computer Vision techniques were used to extract the required features from images for learning purpose. The unavailability of an efficient Segmentation algorithm for the proper segmentation of the Dancer and the background was a challenge faced at the image processing stage. Nevertheless, a deep learning-based Semantic Segmentation method helped to overcome this difficulty and obtain a good segmentation result. The Image Processing stage was completed using the existing algorithms, and successfully extracted the sthana based features from the dataset of the SICD sthanas.
Image Classification is a widely known machine-learning problem. A supervised learning defines a set of the target class and builds a model that recognizes an input image and its label class. This paper describes the development of a classification model for the sthanas dataset. The CNN is the state-of-the-art method for the image classification, and hence, we first attempted to build a CNN model for the sthanas dataset. But, the dataset was too small, and the performance of the CNN was insufficient. As a result, in this work, we performed identification and extraction of the features followed by their classification. Further, different classification models such as SVM, KNN, and Naive Bayes were applied in the SICD sthanas dataset for better accuracy in classification.
This section offers a brief review of different works that elucidate the theoretical aspects of the posture recognition in the dance forms. Computational models that are used in the field are also exhaustively studied.
Protopapadakis [4] evaluate the classification techniques for the recognition of dance types from motion-captured human skeleton data. They used Microsoft Kinectic2 for sensing motion in traditional folk dances. The device is capable of capturing depth, video, and voice. And, the authors make use of the data related to the depth for real-time skeleton-tracking. The overall architecture as explained in the work consists of 3 stages: capturing of dance poses, identification of key poses and classification of poses. The authors investigated classification techniques such as the KNN, Naive Bayes, Discriminant Analysis, Classification Tree, Ensemble Methods and SVM in order to classify postures, and have identified the KNN and the Random Forest as the best performing classifiers among them. Nagata et al. [5] has proposed that the motion-capture method detected motions in the Latin dance forms and its outcome was used to synthesize the dance animations. Whereas, Ofli et al. [6] proposed the Hidden Markov Model (HMM) in order to determine the figures of dance that are present in a video recording. This work proposes to capture the dynamics of the motion pattern of the body and synthesize the dance-figures. Further, Saha et al. [7] have proposed Gestures Recognition Algorithm that uses a Kinect sensor, as the best method for Indian Classical Dance forms. They have extracted altogether 23 features using this framework based on the distance between different parts of the upper human body. The velocity and acceleration that was generated during the performance, along with the angle between the different joints, were put to use in the analysis and interpretation of the Indian Classical Dance. According to Partha [8] the Advanced Sensor Technology has led to the development of affordable multimedia cameras like Kinect that can detect and track various human movements that are synchronized with the audio streams. Incidentally, hardly any work has been done in the computaional analysis of dance forms so far. And, none of the proposed methods can be applied for the image data analyzed in this study.
Kannan et al. [9] proposes a Tutoring System for learning danceand summarizes the previous works done by the authors towards modeling, extracting, querying and annotating expressive semantics of a dance video as well as its archiving and retrieving process. Sangeetha [10] has developed a Computational Model for Bharatanatyam Choreography, which identifies and classifies different angalakshanas in the dance form. Hassan et al.’s [11] method based on the Multiple Kernel Learning (MKL) Algorithm was applied for annotation in a novel set of dance images that were foregrounded on texture-based features. This annotation method gave a promising result and was tested along with SIFT. Samanta et al. [12] suggested a new way to represent the dance poses in a video using Pose Descriptor (action descriptor), which uses the histogram of Oriented Optic Flow (HOOF). This further led to the development of a classification model for the dance-videos. Again, as the Indian Classical Dance uses expressive gestures called the mudras that enhances the visual mode of communication with the audience, Mozarkar and Warnekar [13] called attention to the need for a computer-aided recognition of Bharatanatyam mudras in order to depict the salient features of the static double hand mudra image. Fukayama and Goto [14] who is enriched with a large amount of consumer generated data of dance-motion obtained from the web, suggested the Probabilistic Model that maps the beat structures and dance movements using a Gaussian Process. Jadhav et al. [15] has recommended the Stick Figure Representation for automated choreography of dances and Nelson Yalta advocated the implementation of a Sequential Learning Model for dancing-robots. The model generates quasi-realistic patterns of dance-moves without being constrained by the accompanied music. Karavarsamis et al. [16] defined a dance step as the shortest possible extract of the bodily motion that can be uniquely identifiied as a particularly repetitive movement through the time. So, he proposed a classifier that classifies the primitive of Salsa dance. Sicchio [17] has put forward a Machine-Learning algorithm for layering the choreographic process. According to this model, the system creates live choreographic scores from a collection of time-lapsed photos as it works with the t-SNE algorithm. King [18] developed a database for K-pop dance and designed an efficient Rectified Linear Unit (RELU)-based Extreme Learning Machine Classifier (ELMC) with features extracted from Fisher-dance. Shubhangi [19] proposed an algorithm to archive the poses in the Indian Classical Dance domain using the SVM. Kishore [20] classifies the images of hand-mudras in various classical dances using the HOG features and the SVM. Further, Kishore [21] developed a new model using the discrete wavelet transformation of local binary pattern that helps in the segmentation of dance-images and also compared classification-accuracy of AGM with SVM. And finally, P. Kishore classified the acts in the Indian classical dance using a powerful artificial intelligence tool known as Convolutional Neural Networks (CNN). Different CNN architectures were designed and tested with our data to obtain better accuracy in recognition [22]. This exhaustive review literature has proved that the academic discourses has not yet addressed the proposed problem regarding the classification of the SICD images on sthanas.
Preliminaries
Hu moment
In the field of Image Processing, the weighted average of the image pixel intensity, also called as moments or functions of such moments, are usually used as invariant features for representing the objects. Consider a digital image
Where
where,
The normalized Central moment,
The set of seven invariant moments that can be derived from the second and third moment which is invariant to translation scale change, mirroring and rotation is known as hu-moment and are defined as
K-Nearest Neighbour(KNN) classifier
Nearest Neighbor (KNN) algorithm is a simple classifier that predicts the unknown values by comparing them with the most similar known values. Simple method to find the closeness between two objects
The KNN algorithm finds K nearest neighbors based on minimum distance from the query instance to the training samples. After getting k-nearest neighbors the algorithm chooses the class of majority of the k-nearest neighbors as the predicted class. In Fig. 2 three classes of data points are shown with red, blue and yellow colors, the new data point represented using green has four neighbors three in the class of red and on in the class of yellow, so it will be classified to the class of red object since it has majority neighbors there.
KNN classifier.
The Naive Bayes classifier is a simple and powerful classifier which works with the Bayes Theorem. It computes the probability of the membership of a query instance with the existing classes and chooses the class with maximum probability. Mathematically it is modeled as:
For finding the membership of a data item
The class of
Which is the class with the maximum probability of membership for
Different approaches of multi-class SVM.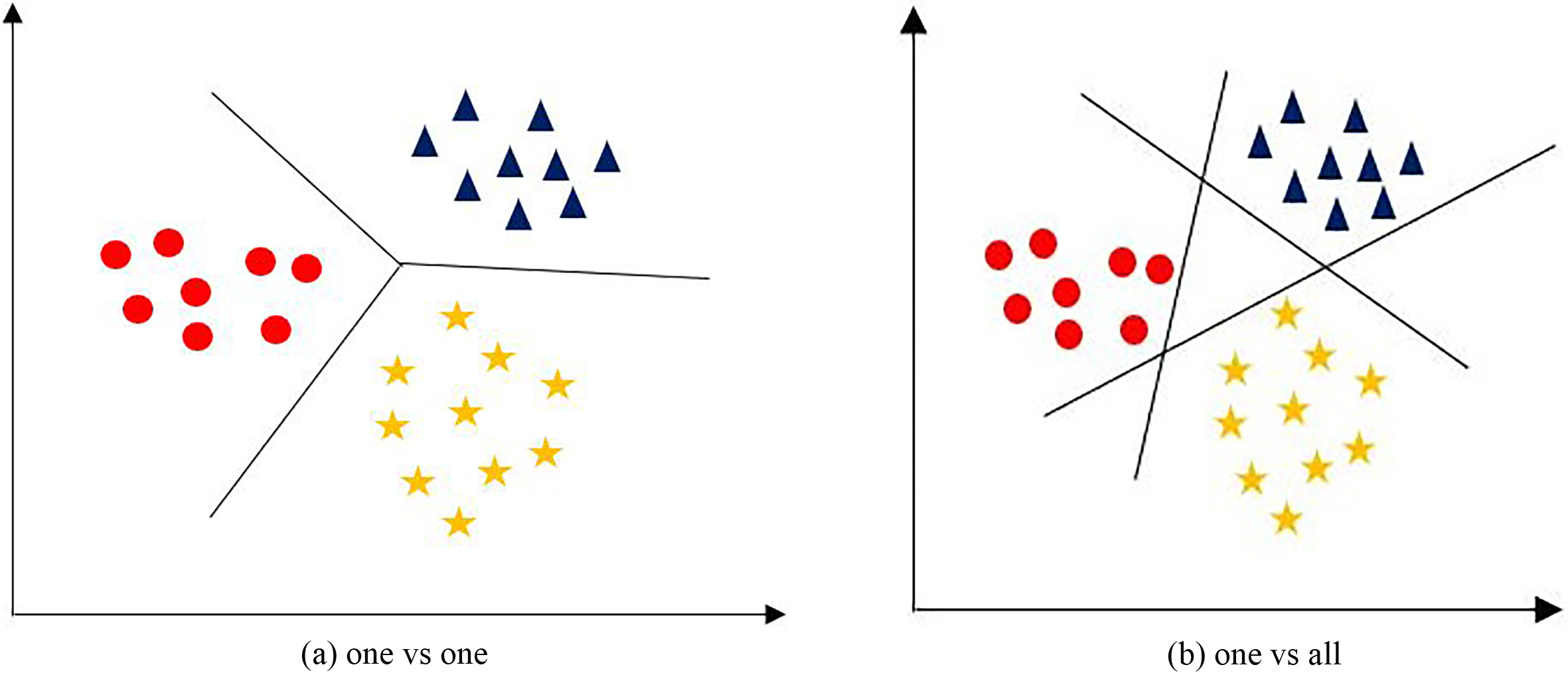
BlitzNet architecture.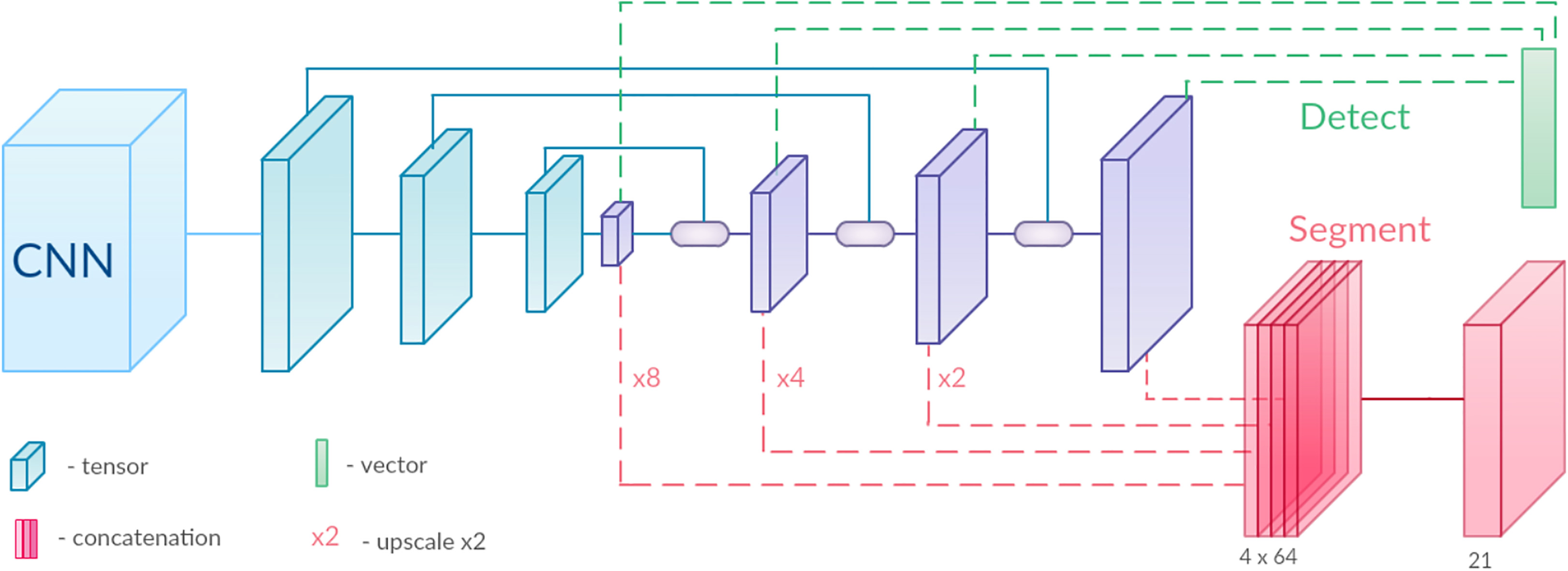
Support vector machine (SVM) is a classification tool used for binary classification. SVM always tried to find a hyper-plane which is characterized by a subset of data points supported vectors. SVM is trained with a set of training vectors
subject to,
Where
CNN and Semantic Segmentation
The Convolution Neural Networks (CNN) is a class of deep neural network. It has an organized multi-layer perceptron architecture which utilizes the Convolution for extracting features. The CNN performs classification task through its architecture consisting of several convolution layers, pooling layers, ReLU layers and finally a fully connected layer. In this paper, the CNN was tried for the classification procedure, but it produced poor accuracy as the dataset was too small. Segmentation is one of the important procedures for image-analysis. Most of the successful Segmentation algorithms failed while segmenting the dancer from the scene. Semantic Segmentation [23, 24] is a method that relies on deep neural network, where each pixel in an image is mapped with a class label. Figure 4 shows the BlitzNet [25] Semantic Segmentation architecture which is used in this work.
BlitzNet use the Adam algorithm with a mini-batch size of 32 images, it uses use ResNet-50 as a feature extractor, 512 feature maps for each layer in down-scale and up-scale streams, 64 channels for intermediate representations in the segmentation branches. BlitzNet300 takes input images of size 300
Proposed framework
In this section, workflow of the proposed method for the classifier framework implementation is described. Data collection and preparation, pre-processing, segmentation, feature extraction, and learning are the different stages in the classifier implementation as illustrated in Fig. 5. In the following subsections, each of this stage is elaborately explained.
Proposed system architecture.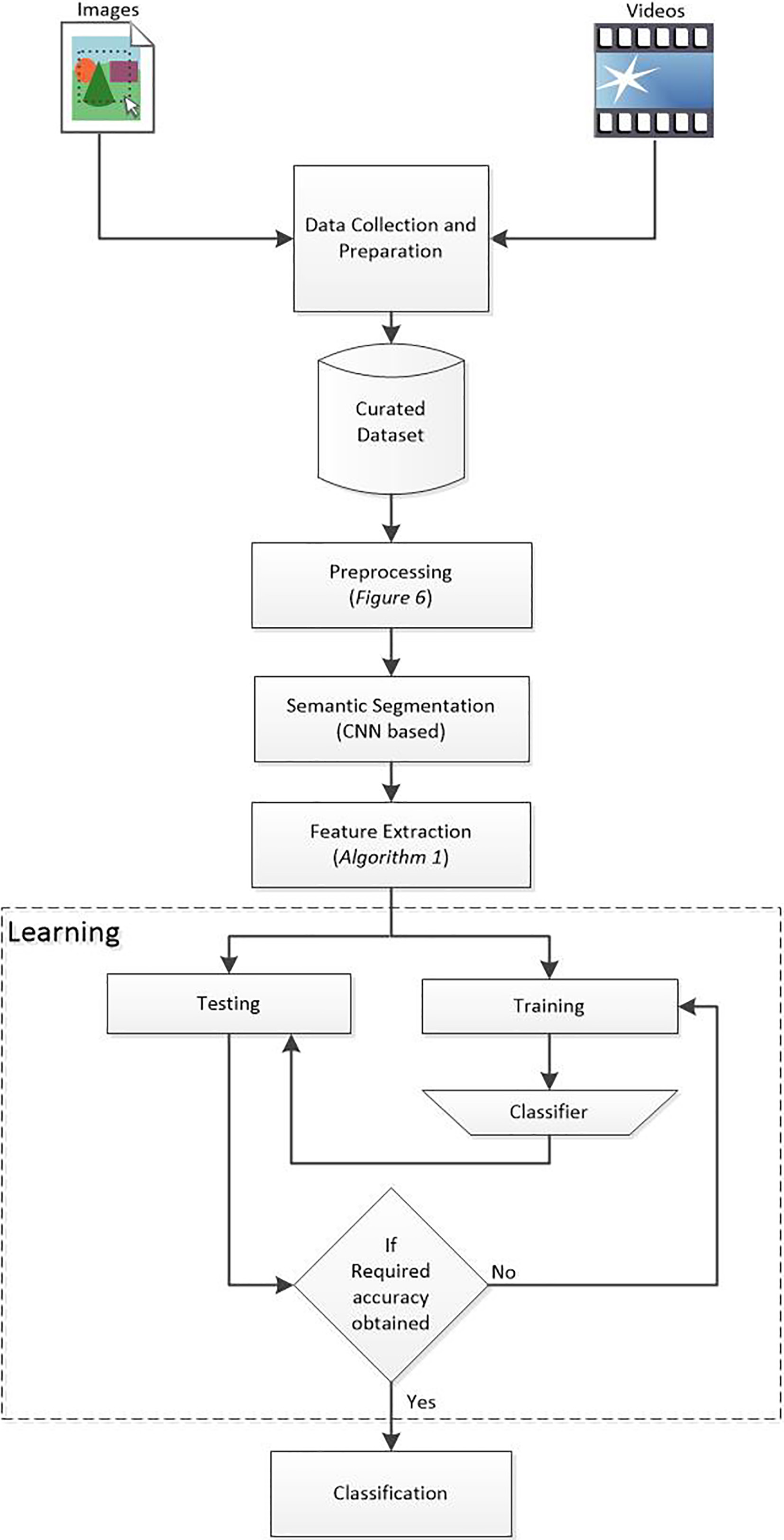
The difficulty in procuring the relevant data was one of the primary requirements and the greatest challenge that we faced while conducting this study. TheImage Processing and the Machine Learning techniques were unexplored avenues in the SICD domain until now, and, no work has been done specifically in relation to the sthanas. It implies the unavailability of the required dataset for learning purpose. Hence, creation of a dataset for SICD sthanas was the priority of this work. After accruing and understanding the theoretical and practical aspects of sthanas, a large collection of images and videos were examined in order to pick the frames with the sthanas from them. These frames that consisted of sthanas were cut and kept as a labelled dataset. Around 500 images of 6 different sthanas were collected. The sources of the images and videos are different online archives, YouTube, and recordings of dance performances from different institutions.
Preprocessing
The properties of the data in this raw dataset of the sthanas highly vary, owing to the diversity of our sources. All these data had to be somehow allied for the proper processing of the entire dataset. Hence, in the pre-processing stage of the Image Processing pipeline, each image in the dataset was routed through three different stages as shown in the Fig. 6. It is obvious that the data obtained from different sources have different dimensions. The first stage where images with different dimensions were scaled to a common dimension of 225
Preprocessing pipeline.
Preprocessed result of a sample image.
Semantic Segmentation input image and segmented image.
Segmentation procedure.
In the field of Digital Image Processing and Computer Vision, the segmentation is still a challenging problem. Many scholars have proposed several segmentation algorithms based on certain image features like pixel intensity value, color, texture, etc. But, as explicated in the Literature Review, it is clear that no single algorithm is better than the others as a universally applicable frame and not all algorithms suit every particular image type. In this work, the segmentation of the dancer from the background was crucial in order to extract his/her geometric and shape-based features., and hence, finding a suitable algorithm for the proper segmentation was our greatest challenge. In the initial stages, algorithms like the Watershed Algorithm, the Grab Cut Algorithms, etc. were tried, failing to produce competent results. Finally, the scope of Semantic Segmentation for object detection and segmentation matched with our own requirements for a suitable method. In general, the Semantic Segmentation [23, 24] is a method that relies on deep neural network, where each pixel in an image is mapped with a class label. A typical illustration is shown in Fig. 8. This work used such a semantic segmentation model implementation called BlitzNet [25] for effectively segmenting the dancer from the image. BlitzNet is a deep architecture that performs both the object-detection and the semantic segmentation in one forward pass, that allows real-time computations. We utilized the human object-detection capability of BlitzNet and segmented the human from the background. However, the segmented result did not completely match with the requirements of the feature extraction stage. Hence, a post processing is done by incorporating some modification in the code, which helped in obtaining a competent segmented result by creating a binary image. The overall flow of the procedure is shown in Fig. 9.
Feature extraction
Geometrical attributes for feature extraction.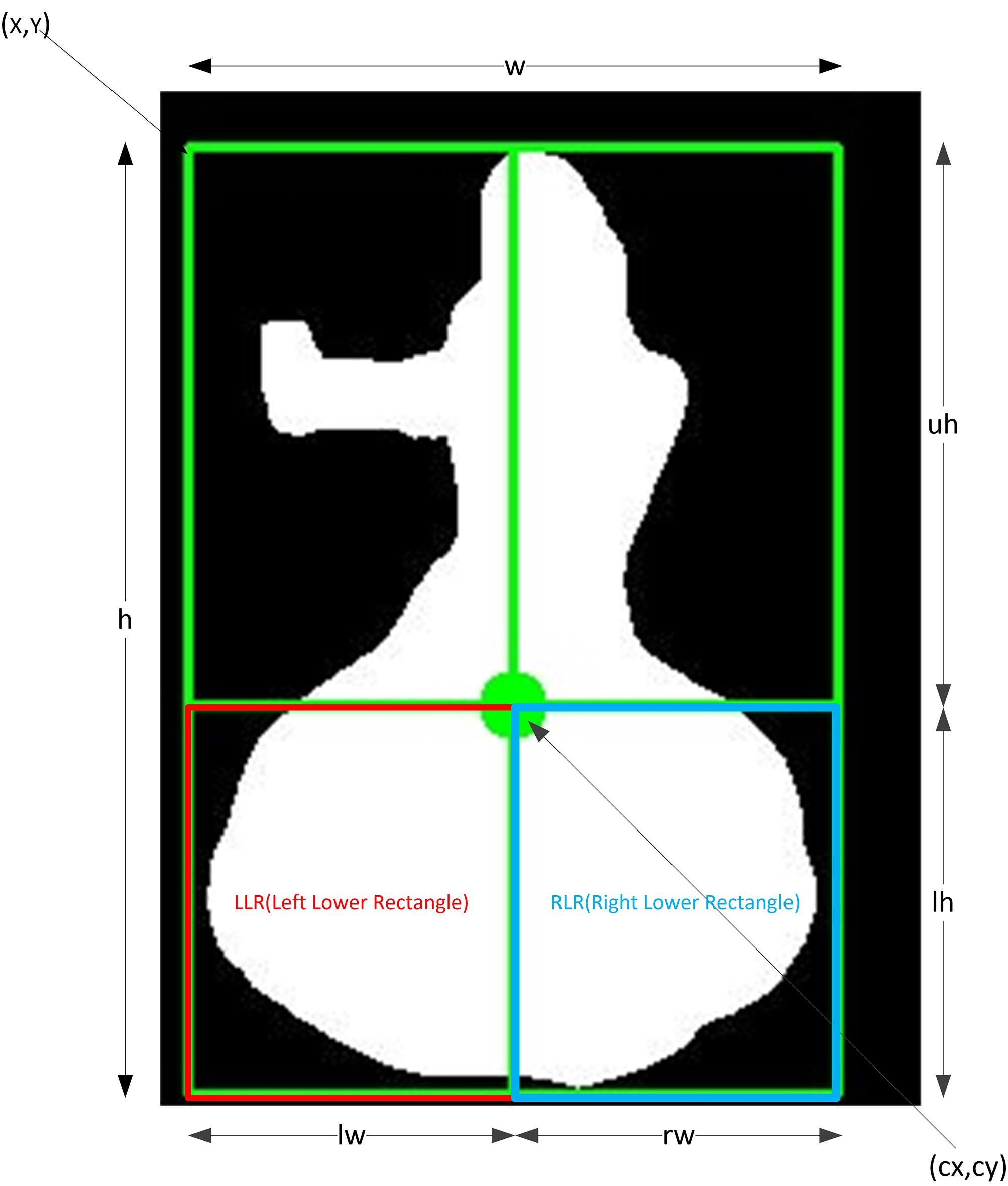
As already discussed, according to Natya Shastra, the sthanas are the postures of the legs, which are aligned and placed according to the given definitions. In a computational perspective, these positioning of the legs yield a set of geometrical attributes foreach of the sthanas, as shown in the Fig. 9. That is in mandala pada position, the posture can be divided vertically as two symmetrical halves, but the symmetric nature cannot be found for positions like alida and prathyalida. Similarly, this paper proposes eight sthana-specific geometric features. Among the eight features, six features correspond to the ratios between different length measures obtained from the contour of a dancer in the segmented image and two correlate with the ratios between the areas measured from the lower body. In the feature-extraction procedure, the input image is the segmented image,
Further, using this moment center, the boundary rectangle is divided into four sub-rectangular regions say Left Upper Rectangle (LUR), Left Lower Rectangle (LLR), Right Upper Rectangle (RUR), and Right Lower Rectangle (RLR). The geometrical attributes such as dimensions and areas of these sub regions are very significant for the sthana based features. From these sub regions, four different dimensions say upper height (uh), lower height (LH), left width (LW), right width (RW) can be calculated. By taking the ratio of different combinations of these dimensions, six different features are extracted, two area-based features are also extracted by taking the ratios of white and black region areas in LLR and RLR.
Feature extraction[1]
Compute area vector
Apart from these six features, seven invariant hu moments are also included in feature vector for improving the learning accuracy. In total thirteen features are extracted from each segmented image. Algorithm 1 explains the exact steps followed in the feature extraction process. Following Fig. 11 shows the sample data extracted form the dataset using above procedure. The first six columns in the figure represents the ratio based features, next two represents the area based features and remaining seven is invariant hu moments. After the extraction process the data were kept as comma separated values (csv) file.
Sample data extracted from the dataset.
Output at different processing stages.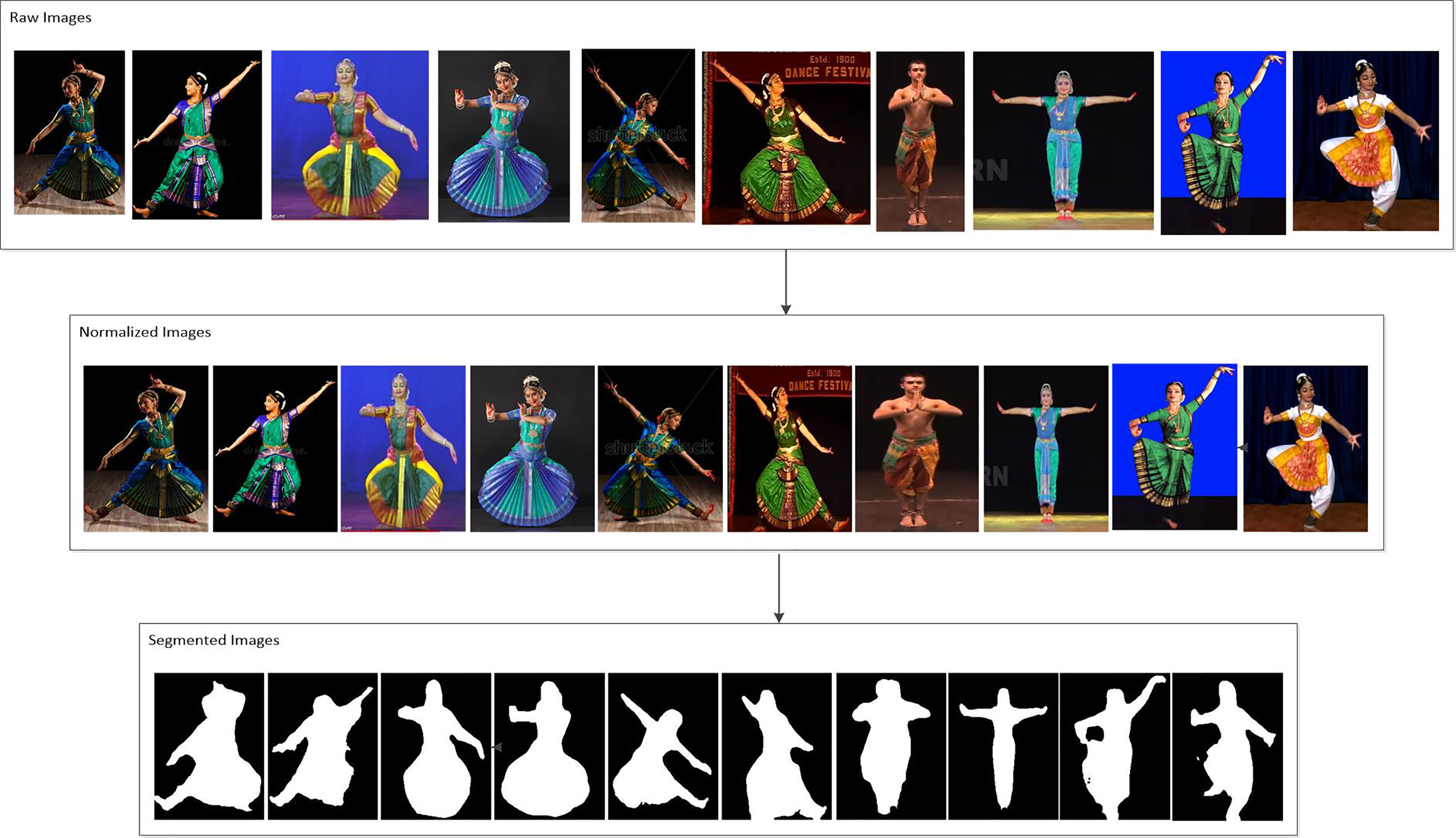
Confusion Matrix fro different classifiers.
Classification summary for different classifier.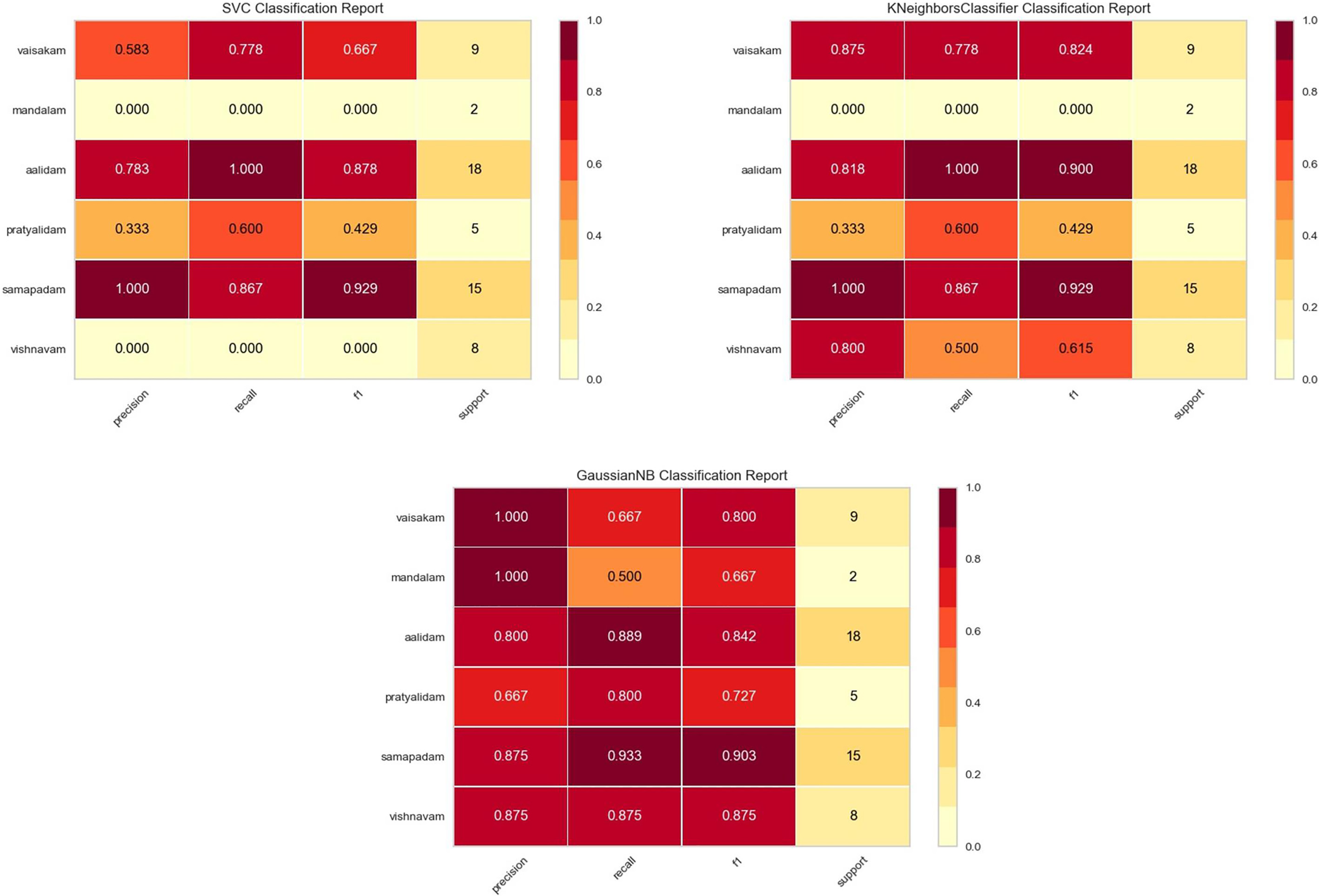
The extraction of the features brings us one-step closer to accomplishing the main objective of this work, which is building a framework for the classification of the SICD sthanas. The remaining task of identifying the best classifier model required a Brute Force Strategy, that is, the features extracted from the dataset of the SICD sthanas were fed to different classifiers such as KNN, SVM, and Naive Bayes. After rigorous analysis of the classification results from each classifier, we have located the Naive Bayes as the best classifier model to meet the concerns of the study. The details of the classifier implementation and analysis are elaborated in the next section.
Implementation and result analysis
Implementation of the proposed work was done with the Python programming language. Different library packages were used for various purposes, like sklearn for machine learning, OpenCV for computer vision and image processing, Yellow Brick and matplotlib for visualization, and other packages like NumPy, pandas etc. for scientific computations. The TensorFlow and related packages were also used for executing the BlitzNet.
The experiment was first carried out with CNN as it is the most prominent tool for image classification. But as the volume of the dataset is less CNN failed to give better accuracy. In the newly developed hand-crafted machine learning approach, the first phase consists of the implementation of the image-processing pipeline and feature-extraction. The raw images from the dataset were processed at different stages as already mentioned in the discussion on the proposed framework. These processed images were further used for the extraction of features. A simple illustration of the outputs obtained at various stages is shown in Fig. 12. After the feature-extraction was completed, three classifier models namely SVM, KNN and Naive Bayes classifiers were used for the classification of the data. An analysis of the results obtained from each of the classifier models is discussed below. In the first level of analysis, the entire dataset of SICD sthanas were split into 2 subset with the ratios 9:1 (90% for training and 10% for testing), 8:2 (80% for training and 20% for testing), 7:3 (70% for training and 30% for testing) in 3 different trials. The Fig. 13 depicts the Confusion Matrices of KNN classifier, SVM classifier, and Naive Bayes classifier respectively for the first trial.
Accuracy is yet another parameter used for validating the classifier models. In general, accuracy is a metric that measures the ratio of correct predictions done by the model over the total number of instances that are evaluated. The accuracy obtained for the three models is shown in Table 1. From the table, it is clear that Naive Bayes classifier gives better accuracy of 82.21%, though it is only for a single instance.
For validating the obtained model K Fold cross-validation was done with the value of
Accuracy obtained from different classifiers
Accuracy obtained from different classifiers
Accuracy obtained from cross validation
Some other metrics are also there for evaluating the classifier like precision, recall, f1-score, and support. Precision gives a measure of correctly predicted actual class observations within total predicted actual class observations. High precision indicated low false positive rate. Recall is the ratio of correctly predicted actual class observation in the total actual class observation. f1 score is the harmonic mean of precision and recall. Good f1 score helps to select the best classifier. Classification summary for different models are visualized and illustrated in Fig. 14.
Dance is best understood as a coordinated outcome of movements, postures, and expressions. These components of the South Indian Classical Dance are well defined and theorized in the seminal works like Natya Shastra, Abhinaya Darpana, etc. The Natya Shastra has lucidly defined sthanas as the leg-postures of the dancers. Nonetheless, despite the compelling presence of the sthanas in the dance-images, the academic discourses have not produced a competent method to identify them. In order to address this computational problem, this work builds a classification framework for identifying and classifying the sthanas that are present in the dance-images. The proposed model was implemented as an application of Image Processing, Computer Vision, and Machine Learning. An image-dataset was created for the SICD sthanas containing six classes of the sthanas. This image dataset was processed at different stages like the pre-processing, the segmentation, the feature-extraction and thereby obtained thirteen specific features of the sthanas. These extracted features were fed to the classifiers for building a classification model. Models like the SVM, the KNN and the Naive Bayes were applied and Naive Bayes gave a better classification accuracy of 85.95%. In this work, we have considered only sthanas for the purpose of classification. But there are other concepts like hastha bedhas, mudras, bhava, etc. which can also be analyzed computationally. Further, the features extracted in this work has considered only the geometrical attributes of the sthanas. The classification can be done more precisely by using deep learning models like CNN, but the size of the dataset is a concern for such methods. However, other ways like Transfer Learning and Data Augmentation Techniques can be adopted for such minimal dataset. The methodology followed in this work can be applied to various national and international dance forms with proper incorporation of their domain-specific features.