
Abstract
Face recognition is the most efficient image analysis application, and the reduction of dimensionality is an essential requirement. The curse of dimensionality occurs with the increase in dimensionality, the sample density decreases exponentially. Dimensionality Reduction is the process of taking into account the dimensionality of the feature space by obtaining a set of principal features. The purpose of this manuscript is to demonstrate a comparative study of Principal Component Analysis and Linear Discriminant Analysis methods which are two of the highly popular appearance-based face recognition projection methods. PCA creates a flat dimensional data representation that describes as much data variance as possible, while LDA finds the vectors that best discriminate between classes in the underlying space. The main idea of PCA is to transform high dimensional input space into the function space that displays the maximum variance. Traditional LDA feature selection is obtained by maximizing class differences and minimizing class distance.
Keywords
Introduction
Face recognition has become a leading technique of biometrics authentication for the last few years. Face recognition is a biometric approach often to verify or recognize a living person’s identity based on their physiological features. The computer model contributes only to theoretical insights, and also to many practical applications such as Automated Crowd Surveillance, Human-Computer Interface (HCI), content-based image database management, criminal database, etc. Face recognition methods are divided into two groups based on face representation they use: appearance-based and feature-based representation. Subspace analysis based on appearance is old, yet it gives promising results among many approaches related to face recognition. Analysis of subspace is implemented by taking an image to lower-dimensional space (subspace) and by calculating the distances between unknown images to be recognized and known images.
After this identification is performed. In this paper, the two most effective subspace projection procedures is presented for recognition of face. Principal Component Analysis (PCA) finds out the set of the most representative projection vectors to retain most of the original sample information. Linear Discriminant Analysis (LDA) uses class information and finds a set of vectors to maximize scattering between classes while minimizing scattering within classes. We conducted surveys of current methods of face recognition, covering both earlier and recent literature related to algorithms and techniques of face recognition. Major techniques of facial recognition are 1) PCA, 2) LDA. In this paper, we have classified each technique of recognition briefly. The rest of this paper is ordered as follows. Related works is summarized in Section 2. Algorithms is explained in Section 3. Difference between PCA and LDA is demonstrated in Section 4. Comparisons of performanes of PCA and LDA on FERET, IFD, and ATT datasets are presented in Section 5. The paper concludes in Section 6.
Related work
In numerous applications in AI and information mining, one is frequently faced with exceptionally high dimensional data. High dimensionality increases the required space and time. A typical method to determine this issue is dimensionality reduction. Dimensionality reduction is vital, since it mitigates the scourge of dimensionality and other undesired properties of high-dimensional spaces [28]. In terms of hardware that creates physical implementation and software that develops algorithmic solutions, face recognition is a challenging task [13]. A wide variety of recognition methods for facial recognition are presented in the literature [14]. For facial recognition, different dimensionality reducing methods are used. Two of such methods are LDA and PCA. In more detail, LDA in contrast to PCA is a supervised method, using only known class labels [3]. Also known as the PCA method of Karhunen- Loève, it is one of the most popular methods for selecting features and reducing dimensions. PCA is a process of variable reduction. PCA is a mathematical procedure which results in a reduction in dimensionality by extracting the main component which is part of multidimensional data [12]. It is useful to have some redundancy when obtained data, which will result in the reduction of variables to a small number of variables called main components.
PCA uses an orthogonal transformation to convert a set of possibly correlated variables observations into a set of values of linearly uncorrelated variables called main components. It is the linear combination of the original dimensions with maximum variability. If the image components are known as random variables, the PCA based vectors are called eigenvectors of scatter matrix. PCA has been applied in a large number of domains such as face recognition [16], classification of coin [14], and analysis of seismic series [17].
The main shortcoming of PCA is that the size of the covariance matrix is proportionate to the dimension of the data points. The computation of the eigenvectors might not be attainable for very high-dimensional data (under the assumption that n
Face recognition fisher face method explained by Belhumeur et al. [2] makes use of both linear discriminant analysis and main component analysis, yielding a matrix of projection of subspace similar to the approach implemented in the Eigenface method. The standard technique for representing original data with lower dimensionality is PCA [36].
On the other hand, for mapping the input into the space of classification, LDA finds an optimal linear discriminating function. The premise vectors are a portrayal of pictures which is related to a face, like structures named Eigenfaces. Projection of pictures in compacted subspace accounts for the simple correlation of pictures with the pictures from the database. The way to deal with face acknowledgment includes the following tasks [11].
Algorithms
Principal Component Analysis (PCA)
Turk and Pent land utilized PCA only to face acknowledge [24]. PCA process a lot of subspace takes premise vectors are a portrayal of pictures which is related to a face, these structures are named Eigen faces. Projection of pictures in this compacted subspace takes into account the simple correlation of pictures with the pictures from the database. The way to deal with face acknowledgement includes the following tasks [11].
Pre-processing: Classification and preprocessing is essential prior to face detection. Then input image is transformed into a Gray image in RGB format. Mean Image: We need to calculate the mean image for PCA to function properly. Matrix of covariance: Calculate a matrix of covariance. Eigenvalue and Eigenvector: Calculate the Eigenvalue and the covariance matrix Eigenvector. Euclidean Distance: Distance of the two values is measured by the Euclidean values. The distance between Euclidean values of the input image and the database image is calculated.
There are two types of PCA namely KPCA and MPCA. 1. Kernel Principal Component Analysis (KPCA) It [4, 5] uses the kernel methods to measure the principal components of a given image. It is beyond conventional principal component analysis (PCA) into a high dimensional feature space using “Kernel Trick”. It can extract up to n (number of samples) nonlinear principal components without expensive computations. 2. Multi-linear Principal Component Analysis (M-PCA) is only a improvised version of PCA having multi-linear algebra, where each image is divided into many sub-block pictures and afterwards PCA is applied for every sub-block image.
Mathematical process
Principal Components Analysis [13] builds a representation of data that is of lower dimension which elaborates the variance in data as much as possible. It is made possible by finding out a reduced dimensionality of the data on linear basis. If we put it using mathematical terms it can be said that, PCA attempts to find a linear transformation that maximizes so that
is a covariance matrix of zero-mean data
The eigenproblem is solved for the d principal eigenvalues
For a given representation of s-dimensional vector of each face in a training set of
Projection matrix WPCA is comprised of
PCA deals with inner-class as well as out-class equally. As a result, it is somewhat sensitive to changes of illumination [16]. In case of Linear Discriminant Analysis (LDA) from [15] we get the following:
Moreover, LDA’s Wopt of subspace is given by
Where,
Linear Discriminant Analysis finds the vectors that best discriminate between classes in the underlying space. For all samples of all classes, the SB scatter matrix and the SW scatter matrix within the class are defined [3]. The objective is to maximize SB while minimizing SW, i.e. maximize the det ratio. This ratio is maximized if the projection matrix column vectors are the own vectors of (SW
Mathematical process
Linear Discriminant Analysis (LDA) identifies the vectors that best discriminate between classes in the underlying space. The inter class scatter matrix SB and in class scatter matrix SW are defined for all samples of all classes by:
Where
From [15] we can say that Linear Discriminant might be a “classical” method in pattern recognition. However, it’s wont to realize a combination of linear options which separates 2 additional categories of events or objects. The ensuing combinations could also be used as linear classifier usually for spatiality reduction before classification is done [6].
In modernized face acknowledgment, every face is spoken to through countless qualities. Direct discriminant examination is basically utilized here for lessening the amount of highlights to a highly reasonable number before ordering. Every one of the new measurements is a straight mix of pixel esteems, which structure a layout. The straight mixes acquired utilizing Fisher’s direct discriminant are called Fisher faces, while those got utilizing the related primary part examination are called eigen faces [6].
Direct Discriminant Analysis effectively manages the situation, in which the frequencies of inside class are not equal and their execution is inspected on arbitrarily produced test information. This kind of strategy augments the proportion between-class change to the inside class fluctuation in a specific informational collection accordingly ensuring maximal uniqueness. Informational collections can be changed and the vectors for testing can be arranged in the changed space using two unique methodologies.
Change of Class Sub-ordiante: This kind of methodology includes expanding the proportion of between the class fluctuations to inside class difference. The fundamental target is to expand this proportion so satisfactory class detachability is acquired. The class-explicit sort strategy includes utilizing two enhancing criteria for changing the informational collections freely. Class-autonomous change: This methodology includes boosting the proportion of by and large difference to inside class fluctuation. This methodology utilizes just a single enhancing model to change the informational collections and thus all information focuses regardless of their class personality are changed utilizing this change. In this kind of LDA, each class is considered as a different class against every single different class [6].
Comparison between PCA and LDA
Representation of different classes by the two varyingt “gaussian-like distributions” [27].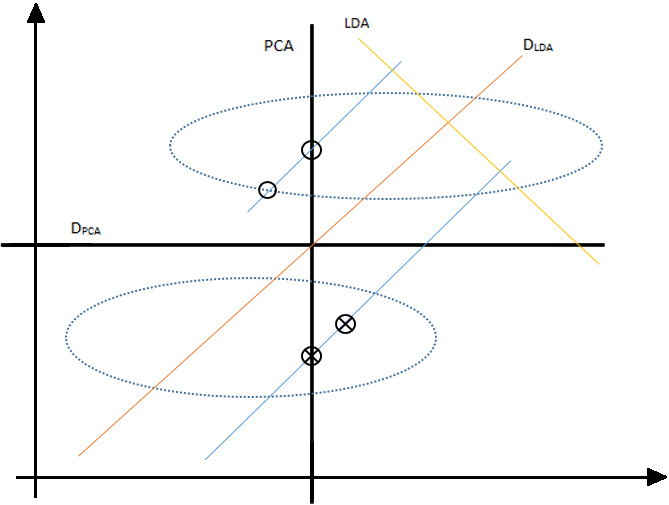
Comparing of the various directions where LDA and PCA projects data from a two-dimensional space into a space of one dimension [29].
The major difference between LDA and PCA is the fact that LDA manages separation between classes, though the PCA manages the information completely for the main segments examination without giving a specific consideration to the basic structure of class [27]. In case of PCA, the location and shape of the first informational indexes alters when changed to an alternate space while LDA does not change the area rather just endeavors to give more class distinctness and draw a choice locale between classes which are given. The objective of Linear Discriminant Analysis (LDA) is to locate an efficient method for speaking to the vector space of face. PCA constructs face space utilizing the entire face preparing information all in all, and not utilizing the face class data. Then again, LDA utilizes class explicit data which best separates between classes. Linear Discriminant Analysis produces an ideal straight discriminant work which maps the contribution to the arrangement space in which the class distinguishing proof of this example is chosen dependent on a few metrics, for example, Euclidean separation. LDA considers the diverse factors of an article and therefore finds out which assemble the item in all probability has a place in [26].
Performance for four different projection procedures and four varying metrics
Performance for four different projection procedures and four varying metrics
Highly efficient combinations of projection-metrics for LDA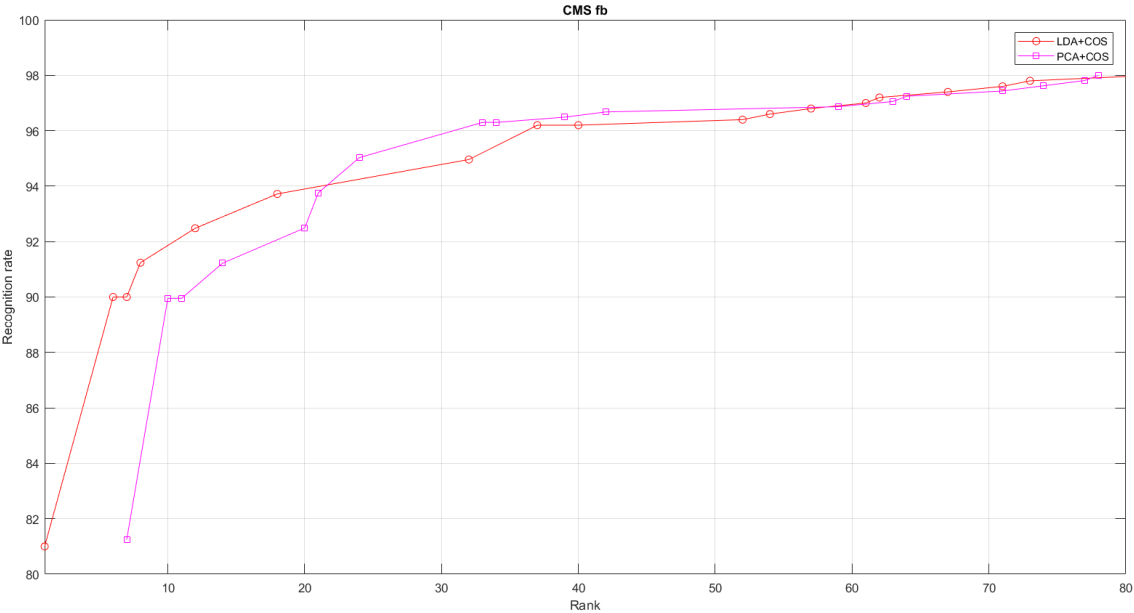
Highly efficient combinations of projection-metrics LDA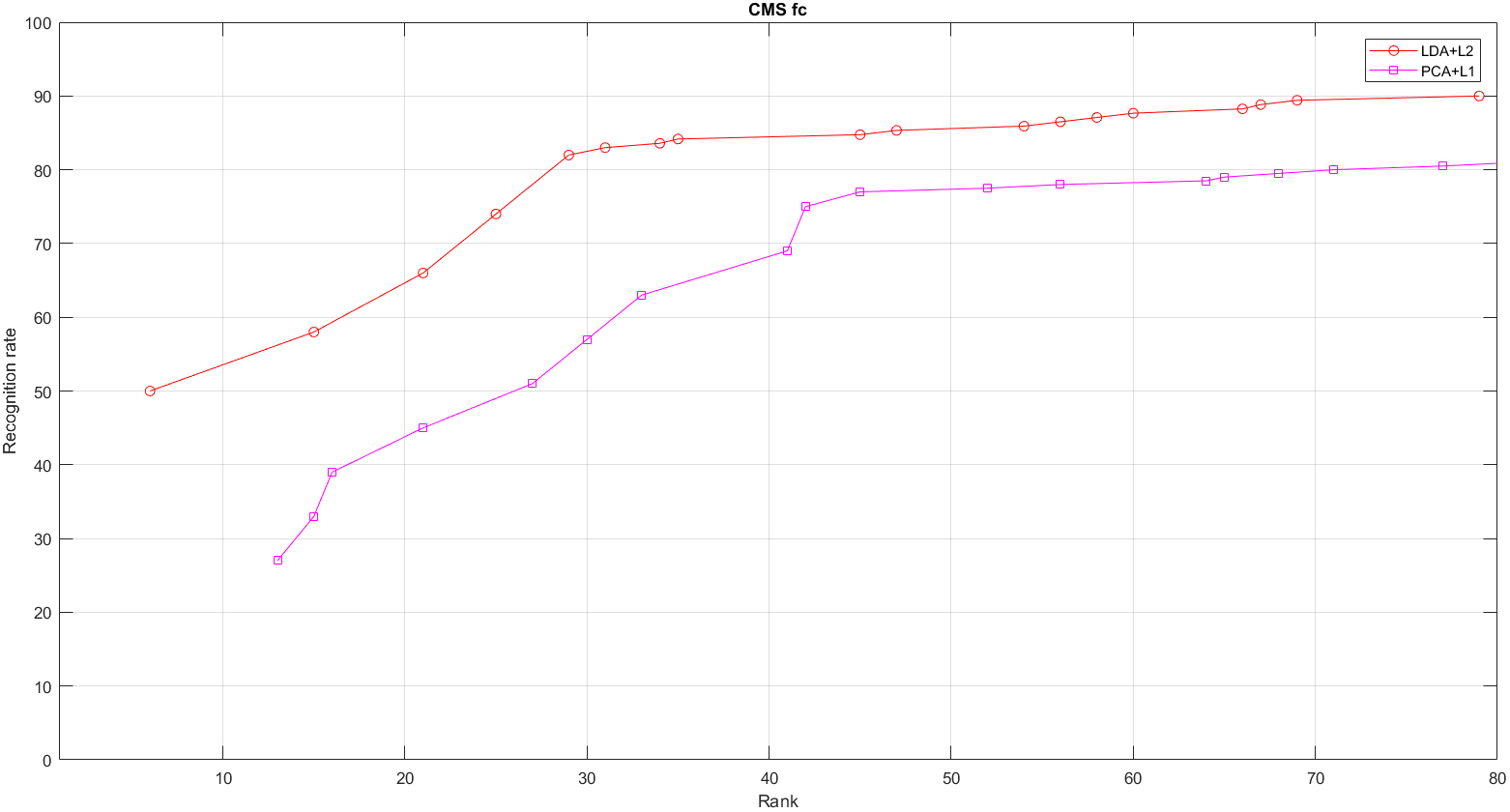
Highly efficient combinations of projection-metrics for LDA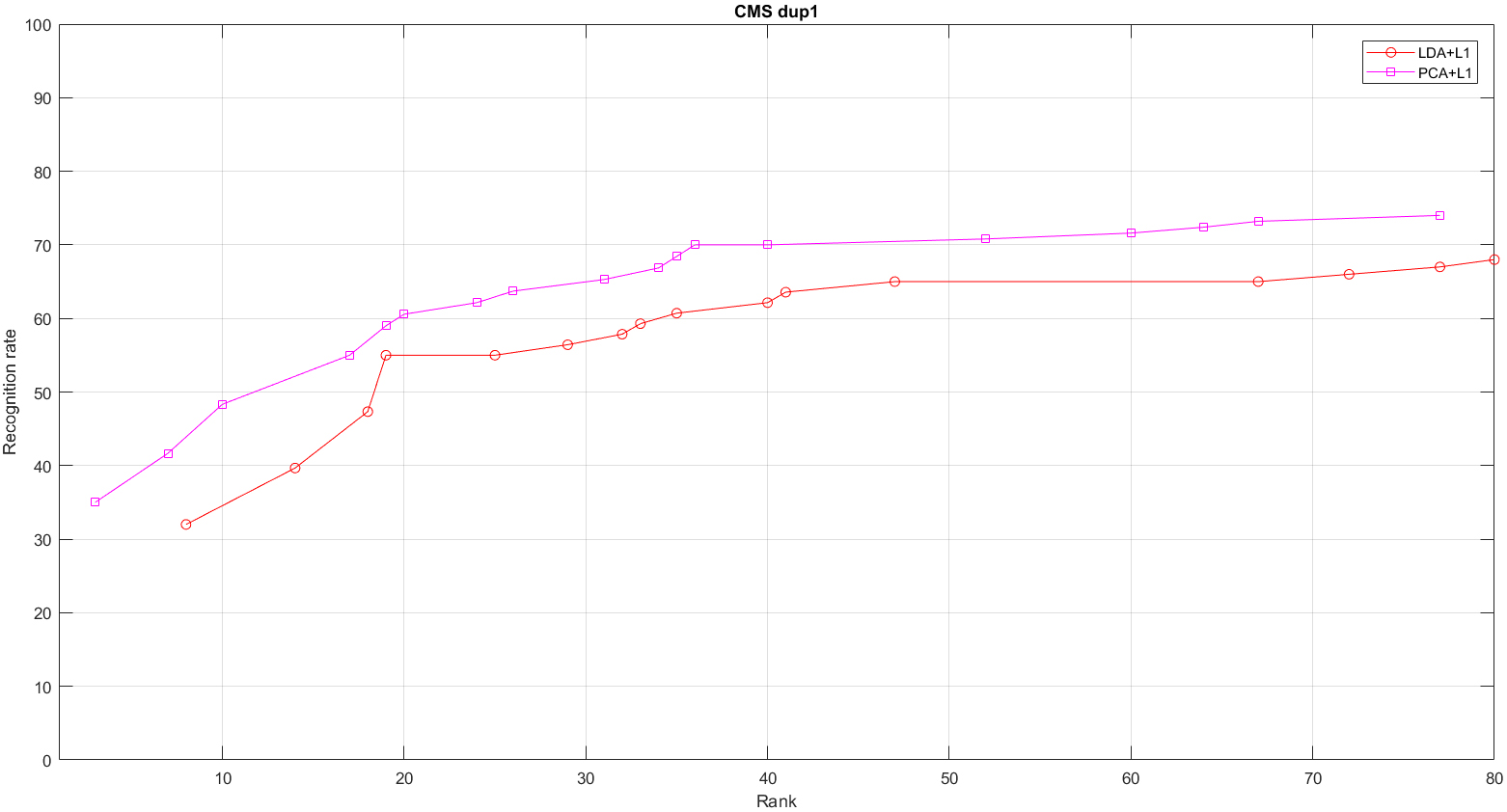
Highly efficient combinations of projection-metrics for LDA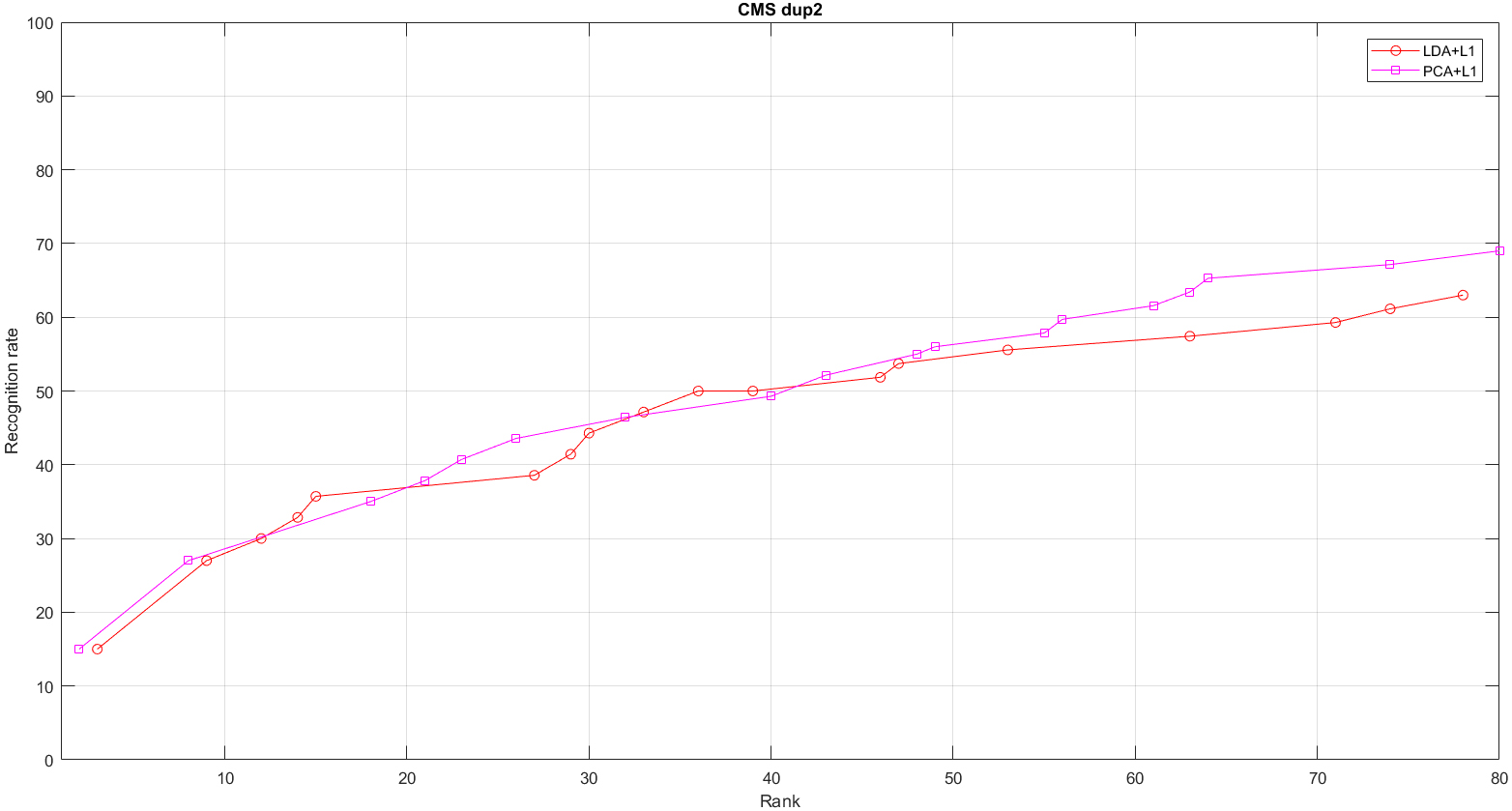
CMS curve for LDA and LDA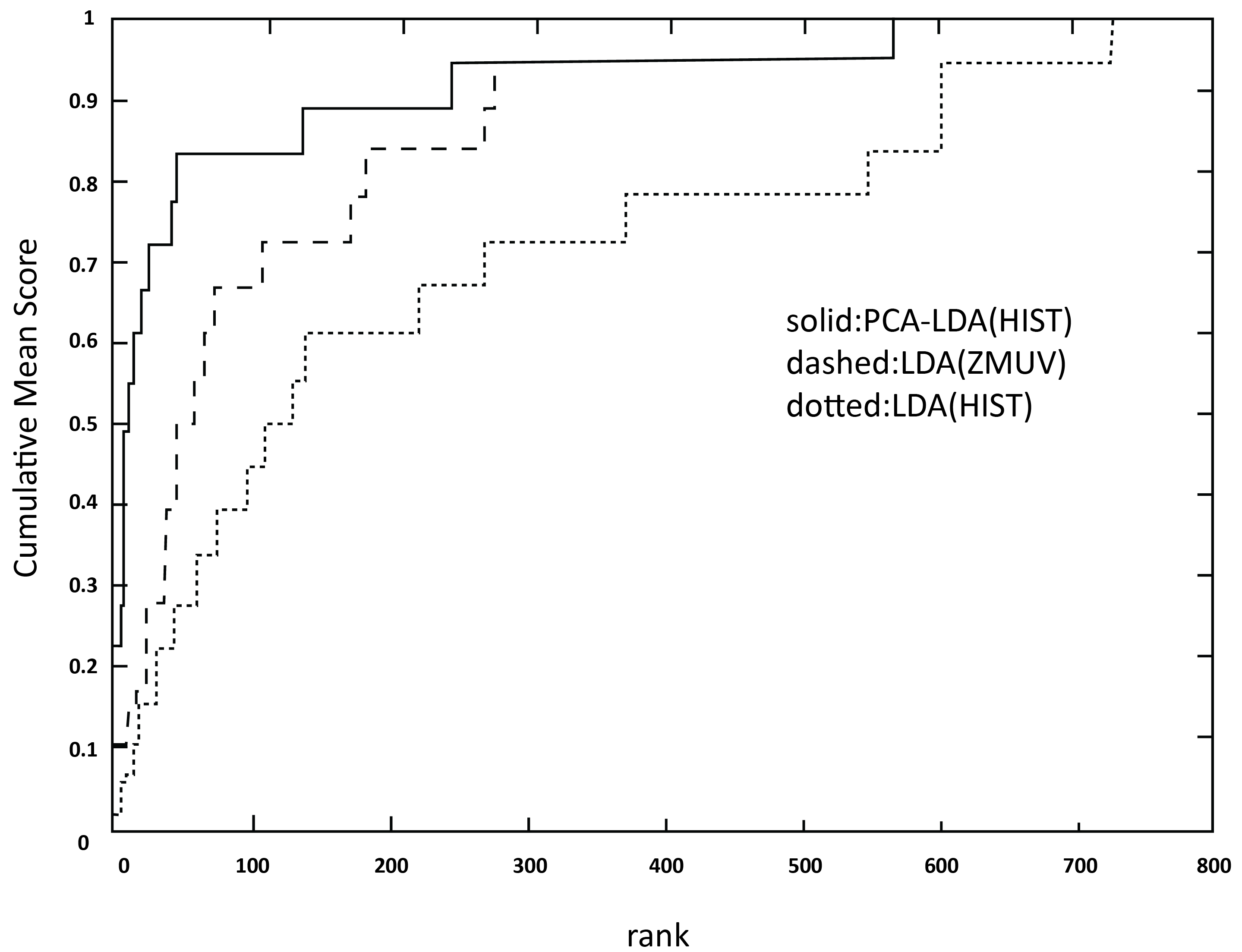
Percentage of the accuracy of PCA and LDA over IFD dataset [37].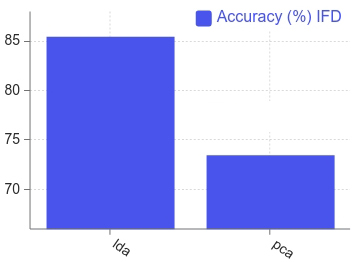
Percentage of accuracy of PCA and LDA over ATT dataset [37].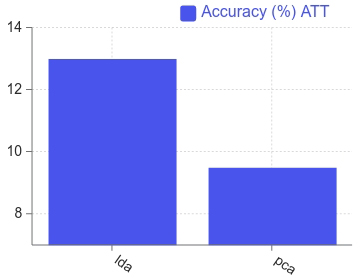
If we look at Fig. 1, there are two distinct classes spoken to by two diverse appropriations that are similar to Gaussian appropriations. Notwithstanding, just two examples for each class are provided to the PCA or LDA. In this reasonable portrayal, the order consequence of the PCA method is better compared to the aftereffect of LDA. DLDA and DPCA speak to the choice limits gotten by utilizing closest neighbor grouping [27].
One normal for PCA and LDA is the fact that they produce a worldwide element vectors. At the end of the day, the premise vectors created by LDA and PCA are non-zero for practically all measurements, meaning that if a change is made to a solitary info pixel, it will modify each component of its subspace projection. In case of one dimension, LDA and PCA are as a whole not the same: LDA is a regulated method of learning that is dependent on marks of class, though PCA is not a supervised strategy [28].
PCA and LDA stream lines the change of T with various expectations. Linear Discriminant Analysis upgrades to T only by augmenting the proportion of between-class variety and inside class variety. PCA derives T by looking for the bearings that have biggest varieties. In this way LDA and PCA venture vectors of parameters along various headings Figure number 7 demonstrates the contrast in between anticipating headings of PCA and LDA, whereas, anticipating the vectors consisting of parameters form a two dimensional parametric space into a one-dimensional figure of component space derived from [29].
On FERET dataset
Different distance measures i.e. to be exact four measures, were used for comparisons in [8]. These are cosine angle (COS), L1, L2, and Mahalanobis distance (MAH). Normally, in case of two vectors,
Here,
Figures 3–6 show the Aggregate CMS bend plots of highly efficient projection-metric combinations (the plots that yields the best astounding bend when all measurements were thought about for a particular calculation) in case of given set of for test [8]. It was found that PCA
IFD stands for Indian Face Database and it consists of images of the pixel size of 640
Comparison on ATT dataset
ATT dataset comprises of images of face of 40 individuals. The background of the images dark homogenous. The subjects were in upright frontal position with varying expressions. For example, with smile or without smile, closed or open eyes, spectacles or no spectacles. Images were captured in different times of the day with changes of lighting.
In this case, the accuracy of LDA on this dataset is 93 percent where as it is 89.5% for PCA [37]. Here the dataset was split into half for training and testing purpose. The accuracy rate is higher for ATT than IFD is due to the higher variation of image angles in IFD. LDA performs better as it uses a class information that maximizes the feature space.
Conclusion
In this paper, we carried out a comparative study of facial recognition algorithms namely PCA and LDA. Principal Component Analysis (PCA) connected to any information distinguishes the mix of qualities (important segments, or bearings in the element space) that represent the most difference in the information. Linear Discriminant Analysis (LDA) attempts to recognize traits that represent the most change between classes. In more detail, LDA rather than PCA is a regulated technique, utilizing just realized class names. There has been an inclination in the computer vision community to lean toward LDA over PCA. This is basically because LDA manages segregation between classes while PCA does not focus on the fundamental class structure. LDA has lower mistake rates LDA functions admirably regardless of whether diverse enlightenment. LDA functions admirably regardless of whether distinctive outward appearances. In contrast to this, we found that for small dataset PCA works better than LDA [27].