
Abstract
Caching contents at the edge of mobile networks is an efficient mechanism that can alleviate the backhaul links load and reduce the transmission delay. For this purpose, choosing an adequate caching strategy becomes an important issue. Recently, the tremendous growth of Mobile Edge Computing (MEC) empowers the edge network nodes with more computation capabilities and storage capabilities, allowing the execution of resource-intensive tasks within the mobile network edges such as running artificial intelligence (AI) algorithms. Exploiting users context information intelligently makes it possible to design an intelligent context-aware mobile edge caching. To maximize the caching performance, the suitable methodology is to consider both context awareness and intelligence so that the caching strategy is aware of the environment while caching the appropriate content by making the right decision. Inspired by the success of reinforcement learning (RL) that uses agents to deal with decision making problems, we present a modified reinforcement learning (mRL) to cache contents in the network edges. Our proposed solution aims to maximize the cache hit rate and requires a multi awareness of the influencing factors on cache performance. The modified RL differs from other RL algorithms in the learning rate that uses the method of stochastic gradient decent (SGD) beside taking advantage of learning using the optimal caching decision obtained from fuzzy rules.
Introduction
In the era of data flood, storing popular contents at the edge is a promising technique to meet user’s demands while alleviating the overcrowding on the backhaul. The idea that characterizes Mobile Edge Computing (MEC) is to push the computation/storage resources to the network edges that are in the vicinity of the user equipment (UE) [1]. In the other hand, the introduction of MEC paradigm and the development of advanced applications have led to data-traffic growth as MEC services are relying on big data with different types and of significant amounts. Specifically, mobile edge computing servers (MECS) are equipped with computation, analytic and storage capabilities which deal with the significant amount of content requests leading to improve the quality-of-service (QoS) of the network and the quality-of-experience (QoE) to the end user. Local caches are one of the MEC equipment that helps to reduce the request traffic and to improve the response time. In particular, because data requests can be processed by MEC nodes that are close to the user, edge caching will reduce network traffic and speed up the data retrieval. This allows edge caching to relax the need of continuous connectivity by decoupling the producer and the receiver. However, edge caching has been widely investigated due to the requirements in term of information freshness. Caching is considered a critical bottleneck for the development of MEC systems, since edge caches are located at the edge of the networks and physically closer to the end user. With limited storage, edge caches use different strategies of placement and replacement, which are in general designed to allow spreading only popular contents around the network. In addition, MEC paradigm presents an exclusive opportunity to implement edge caching and to design caching placement and replacement strategies. Therefore, caching popular contents at MECS is considered as a cost effective solution [2] due to the benefits of avoiding network congestion and alleviating the backhaul links. Fulfilling the requirement of both network and the end user is a key point of MEC that consists in a dynamic computational offloading that might cause congestion in the network; which decreases QoS and raises the decision making and the optimization problem on the whole system. Our problem statement is how to jointly encompass the problem of stochastic dynamics of the network and enhance the decision of caching. Several pioneer works about caching in mobile edge computing have been proposed and achieved with quite a good results but these approaches suffer from the following issues:
Not enough Inputs: They consider only popularity as a key information factor while there are several factors that can effect on the caching decision. Strategy combination: They consider either placement or replacement strategies and not the whole caching system. Dynamic conditions: Dynamics of the environment and the caching system are not well addressed. Tentative isolation: Most of caching strategies do not consider the long term effect of the current caching decision.
Other proposed solutions are optimal but they suffer from a lack of intelligence. In order to fill this gap, We focus in this paper on the design of a novel intelligent caching strategy that tailors mobile edge computing servers among learning methods. As one of learning methods, we propose the use of reinforcement learning (RL) that enables agents to deal with decision making problems by learning through interactions with the environment [3]. Reinforcement learning model has some limitations notwithstanding its efficacy in many fields since scaling is a big challenge [4, 5, 6]. In fact, RL model does not cope well with areas where there is a large space of possible actions or environment states. Hence, many RL models have been used for simplified learning cases [7].
In this context, we define a modified reinforcement learning (mRL) based caching system for MEC, which considers the content features namely frequency, cost and size as well as the device feature like mobility and storage capability. This aims to solve the problem of caching decision making in a realistic way. The main contribution of this paper is to bring a solution to the caching problems in a scenario where caching units are stochastically distributed through MEC servers with a limited backhaul and storage capacity. In particular, we build on a caching system model and define its performance metrics (cache hit ratio and stability). In addition, we define cache storage size, user mobility and content popularity distribution. By coupling the caching decision problem with reinforcement learning layer while relying on recent results from [19], we show that a certain hit ratio can be achieved by increasing the total storage size while the number of MECs is fixed. To the best of our knowledge, our work differs from the previous works in terms of studying a new system model with both placement and replacement aspects of edge caching. The remaining content of this paper is organized as follows: background and review are presented in Section 2. The modified RL algorithm and its solution process are given in Section 3. Problem formulation and model development are provided in Section 4. Evaluation and discussion of results are given in Section 5. Finally, concluding remarks including future directions are given in Section 6.
Caching in MEC systems
Mobile Edge Computing (MEC) is a decentralized computing concept in which computing resources and application services can be distributed along the communication path from the point storing data to Base Stations (BSs) in wireless networks [53].
Edge caching architecture.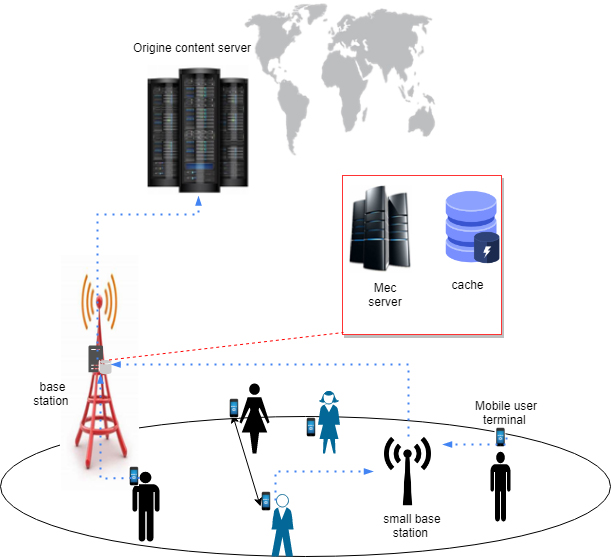
Mobile-edge Computing has been also mentioned in ETSI (European Telecommunications Standards Institute) white paper as an environment that offers applications and content providers cloud-computing capabilities at the edge of the mobile network. This environment is characterized by high bandwidth, low latency and a real-time access to radio network information [10]. In particular, generic-computing platforms are used by mobile edge computing servers to be implemented directly at the base stations, which enables the deployment of caching and context-aware services in the vicinity of the mobile users [11]. Consequently, MECS became a unique opportunity to implement and perform edge caching. To describe the scenario of mobile edge caching, we first should discuss the questions of where to cache, what to cache (popular content) and how to cache (caching policies).
Caching improves data availability during disconnection because even when a connection is unavailable, data can still be accessed through the on-board cache, thus allowing mobile clients to continue operating during disconnection [42].
In general, edge caching means that popular contents can be cached in edge nodes such as macro base stations, small base stations or even user equipment. As shown in Fig. 1, caching a content which is close to the end users can effectively reduce the redundant data traffic and greatly improve the QoE of users [8].
Concerning what to cache, the range of contents is widely increasing including videos, audio files and Internet-of-Things data, which makes the number of reachable contents over the internet extremely huge. Not all of the available contents should be cached, regarding to the fact of limited storage space of edge nodes. In literature, to decide what to cache, content’s popularity is one of the prime concern. It represents the probability of requesting contents by users or the frequency of demanding the contents over specific time period. This feature should be taken into consideration as a main factor. Most of the current works that deal with mobile edge caching consider that content popularity follows a static Zipf distribution [9]. But since the user preferences change with time and the user groups associated with edge nodes are varied, considering only content popularity is not enough as a parameter to infer the caching decision. Appropriate contents are selected by edge caches to be stored using caching policies. The caching policies decide to obtain different objectives such as traffic offloading, quality of experience (QoE), energy consumption and so on in order to maximize the cache hit ratio. Caching policies can be divided into categories depending on their characteristics:
Depending on cache coordination:
Coordinated: caches must exchange information to be efficient, that is, to have a good estimation of where to place the content and to avoid caching the same content in too many caches. Coordinating cache is represented by a distributed session feature that allows multiple instances of a session to broadcast content changes among each other so that each cache is updated.
Uncoordinated: in uncoordinated scheme, each cache is working in an individual way.
Depending on cache size:
Homogeneous: all caches in base stations have the same size.
Heterogeneous: each cache has a different size.
Depending on the cooperation between caches
Cooperative: caches cooperate with each other by establishing a cache state that allows other caches to know the different states like in [43].
Non-cooperative: caching decisions are made independently with no need to advertise the information of cache state.
Depending on where the content is cached:
On path: caching only the contents caught along the downloading path.
Off path: caching the content caught outside the downloading path.
In general, conventional caching policies are divided into two main phases: placement phase and replacement phase:
The placement phase which is the process that decides whether we should cache and how and when we can cache the contents. The replacement phase which is the process that decides which data to drop if there is no free storage space.
To make best usage of edge caching, researchers have prosperously used classical web caching algorithms either for placement or replacement phases relying on popularity as a main factor. For placement, they adapt: leave copy everywhere (LCE) which is the default caching mechanism in most caches designs used to minimize the upstream bandwidth demand and downstream latency [12]. In LCE, the popular contents are cached at every cache along the path and it is considered as a homogeneous and non-cooperative caching mechanism. The methods leave copy down (LCD) and move copy down (MCD) realize the heterogeneous caching in a cooperative way in order to reduce redundancy [12, 13]. Probabilistic mechanisms have been widely used, like the policy referred to Prob(p). It was used as a benchmark scheme in the literature [32, 33, 34]. This mechanism sets to every content a probability
For edge caching, classical web caching was widely used. However, several works have proposed new placement strategies for the edge, such as in [29], where they present the edge buffering as a caching and pre-fetching strategy, pointing out the insufficiency of strategies that rely on past history of the device. Instead, they propose a prediction model based on the aggregated network-level statistics. Unlike blind popularity decisions, authors in [30] proposed a mobility-aware probabilistic (MAP) placing scheme which caches contents at edge servers where the vehicles are connected considering the vehicular trajectory predictions and the time required to serve a content. Zhang et al. [31] propose a cooperative edge caching in large scale, where the optimization is carried on the content placement and the cluster size using different features such as traffic distribution, channel quality, stochastic information of network topology and file popularity. Table 1 summarizes some of classical placement strategies.
Summary of some existing classical placement mechanisms
List of mathematical symbols
Notation
The replacement phase is the phase that decides which content to evict from the cache. It is categorized into: recency, frequency based such as the least frequently used (LFU) [16] and the least recently used (LRU) [17], and semantic like First In First Out (FIFO) that always replaces the oldest contents in the cache [18]. Recently, an age-based caching replacement was developed in [21]. The previous caching mechanism has been successfully adopted in classical web caching, but it may not meet the performance in the mobile edge caching due to the ignorance of other features and by the use only of popularity. Thus, it would be unable to take advantage of specific characteristics of both the environments and the end user like mobile network topology uncertainty, user mobility, limited storage and cost. In order to overcome these limitations and cope with the future internet usage, the works described in [19, 20] adjust the varied content properties and its influencing factors using fuzzy control caching system (placement and replacement) for edge servers, which can select the more and the less priority content to be cached or evicted respectively.
Fuzzy logic is an extension of Boolean logic dealing with the concept of partial truth which denotes the extent to which a proposition is true. While classical logic holds that everything can be expressed in binary terms (0 or 1, black or white, yes or no), fuzzy logic replaces Boolean truth values with a degree of truth. The degree of truth is often employed to capture the imprecise modes of reasoning that play an essential role in the human ability to make decisions in an environment of uncertainty and imprecision [52].
A Fuzzy Inference System consists of an input phase, a processing phase and an output phase. In the input phase, the inputs are mapped to an appropriate membership function with specific values. The processing stage consists in performing each appropriate rule and in generating a corresponding result. It then combines the results. Finally, the output phase converts the combined result back into a specific output value. The membership function of a fuzzy set represented by divided ranges defines how each value in the input space is mapped to a membership degree. The inference system is based on a set of IF-THEN statements representing logic rules, where the IF part is called the “antecedent” and the THEN part is called the “consequent”.
The fuzzy inference system (FIS) that we built, in our work, consist of four inputs:
Mobility that refers to the distance between the mobile user and the nearest base station that contains the cache. Frequency that represents the popularity or how often the contents are requested in a specific period of time interval. The size of the cache that is determined thanks to cache occupancy. The cost of retrieval that reflects the cost of the bandwidth required by a MECS to extract the content as requested by the end user.
Appropriate rules are applied during the processing phase that generates the corresponding results; and finally, producing a quantifiable result with the assignment of the corresponding membership degree. The aim of using fuzzy logic is to take into consideration the environment and the mobile user factors that affect caching performance to make the caching policy context-aware.
Reinforcement learning model.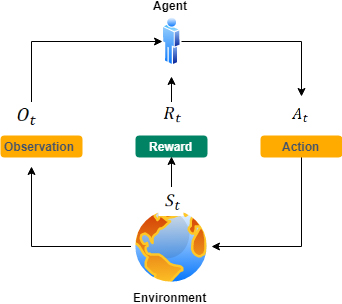
Efficient mobile edge caching policy needs not only to be context-aware, but also to be intelligent to grasp both the environment and the user behavior in order to take optimal or appropriate caching decisions over time. As one of the intelligent learning methods, the reinforcement learning (RL) enables agents to deal with decision making problems by learning through interactions with the environment [3, 28]. As described in [3], the basic components of reinforcement learning enrolment (see Fig. 2) are the following:
In the reinforcement learning model, an agent learns through its perpetual interaction with the environment. At each time The agent earns a reward The agent aims at finding an optimal policy,
Reinforcement learning based caching policies have been studied in many works, since it is capable of learning the environment and making online decision through observations. Thus, it is a potential solution to decision problems under dynamic environment, such as the caching policy design problem in [25]. Specifically, a Q-learning based caching scheme was developed in [22] modeling content popularity as Markov processes, while in [51] the authors applied Q-learning to manage named data networking caching. A more realistic approach have been proposed in [54] where the authors design a content caching strategies in mobile D2D networks using multi-agent reinforcement learning without assuming the knowledge of content popularity distribution.
A policy gradient reinforcement learning based caching scheme was introduced in [23] by considering the Poisson shot noise popularity dynamics. Using both service cost and popularity, a dual-decomposition based Q-learning approach was presented in [24]. Particularly, related studies on edge caching, such as [26, 27], have shown that reinforcement learning is effectively labor to be effective in joint resource management.
The caching policies adopted by the RL are trained with observations, depending basically on a reward function resulting from its actions. This reward covers a wide range of factors that can influence the performance of the caching system. The caching policy can also be configured by using RL. In this paper, an emphasize is given to combine fuzzy logic and RL. In turn, the policy of caching can be made more adaptive with the proposed design of reward function while proposing the modifications. The highlight of the combination is to prepare an optimal caching decision. The optimal caching is indicative towards multi-objective optimization of cache decision influencing several parameters (mobility, cost, size and frequency).
Our aim, in this paper, is to propose a modified reinforcement learning (mRL) by combining RL and Fuzzy logic as an embodiment of the idea of exploiting previously acquired knowledge and capabilities from others in order to speed up learning in RL. For example, the knowledge about the content distribution, the mobile user properties and the network conditions can be used by the caching agent. The combination of knowledge methods and RL has significant advantages like constructing more efficient caching policies. On one hand, transferring prior knowledge can be used to help training RL agents, thus making convergence to the optimal caching decision easier. On the other hand, using policies learned by other relative networks with RL agents will improve the efficiency and the robustness of the current RL algorithm.
In this section, we focus on the scenario of caching contents in edge nodes, as depicted in Fig. 3. There are
Scenario of caching using reinfocement learning.
We illustrate an example of applying mRL to the mobile edge caching, where one MEC server is considered and the storage space of the edge cache is initialized to be enough for caching half of the available contents in the network. The MEC server can serve all the requests directly, according to the arrival time. Initially, the caching policy caches locally the contents according to the priority accomplished by the fuzzy system and to the cache size availability. Otherwise, the cache replaces the content less prior by the highest one. Our aim is to find the optimal caching decision by maximizing the cache hit ratio, that is, the number of contents answered by the edge cache. This problem can be solved based on mRL which requires training an agent for representing the policy, and an appropriate reward function that describes how the agent ought to behave. In other words, reward functions have normative contents that provide what the agents should accomplish.
Block diagrame of caching over mRL.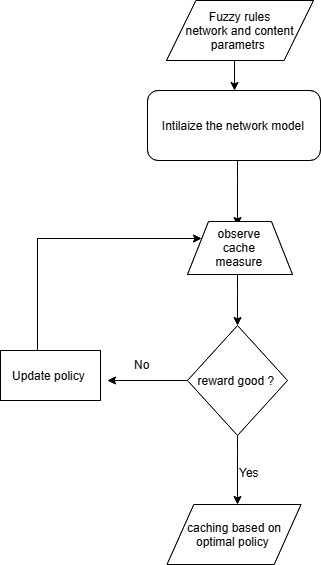
Cahing agnet process.
The detailed features are shown in Figs 4 and 5 and explained below: The environment is modelled thanks to a stochastic finite state where the inputs are the actions sent from the agent (i.e., fuzzy rules and user requests) and where the outputs are the observations and rewards sent to the agent:
State transition function Observation (output) function Reward function
It is noted that the agent observations depend on his actions, which means that perception is an active process. The agent is a stochastic finite state machine having as inputs: observations and rewards received from the environment, and as outputs: actions sent to the environment.
State transition function: Policy/output function:
The agent’s goal is to find the optimal policy and the state function so that to maximize the expected sum of discounted rewards.
In case of caching decision with fuzzy policy dynamically, the learning rate should be modified. However, the modification of learning rate may alter the conventional method of stochastic gradient descent (SGD) [48] considerably. We represent the weight adjustment of mRL as follows: new_weight
with
while
To consider this principle, we initiate certain modifications of
The learning rate will select new learning values at the end of each epoch/session combining statistical optimization and rejection strategy.
We provide further the following modification:
Input search space Find a mean function
High level description of mRL
The reinforcement learning based algorithms have been successfully applied to various optimization problems in many domains. However, in order to obtain better solutions for specific optimization problems like our multi awareness caching system. The core of the modified RL algorithm used in this study is to generate a sub-environment based on fuzzy policy as following:
Fuzzy policy weight: Input search space Update the value of toward an optimum value
We minimize the expected value of the objective in next dynamic instances which implies:
We update the previous learning rate
We also assume an optimum value of the learning rate and that at each step the descent value will change towards all the sessions. However, we need to introduce a continuous function with the context of noise, hence:
The rule can be interpreted as multiplication. This will be an additive adaptation of changing of
The caching policy can be defined as a set of dynamic artifacts [49]. This phenomenon becomes obvious as the context of caching particularly should be dynamic depending on the condition of network traffic. Hence, the modification of RL also demands essential formal model to cope up with respect to dynamic policies.
Formal model of policy improvement
We define a finite state space
where
In the dynamic context of caching, we may have more than one context. This additional context either can be combined or mixed to derive the improved policy. Let there are two such transitional finite kernels to make decision for caching from
If the search space is predefined from a stochastic caching mechanism from If the policy for both kernel
Therefore, if there is a caching context with all four parameters, then obviously we will select a policy that gives a maximum reward. Therefore, the estimated policy for caching decision to a particular network content is:
In Eq. (9),
Recently, there has been novel technologies that replace prediction with a much more efficient way known as reward functions [50]. Reward functions are used for reinforcement learning models and allow to obtain the final results as a conclusion instead of prediction. For decision making problems, prediction is not the only input as the other fundamental input is judgment.
For our caching system, mRL treats learning and content placement/replacement as a whole operation. The caching policy adopted by the mRL agent is trained with observations, based on a reward resulting from its actions that relate to the factors that affect caching performance such as mobility. Usually, this reward should be chosen in a way that covers a wide range of factors that can affect the performance such as offloaded traffic or QoE.
Finding the best reward function to reproduce a set of observations can be implemented by the maximum likelihood estimation, Bayesian, or information theoretic methods. The system reward represents the optimization objective. In our work, the objective is to maximize cache hit ratio. For our caching approach, we have all the variables that can go into known values. The time of retrieving is determined while distributing the contents and the users requests (including the associated parameters of each). In the scenario of mRL, when the system state
In the conventional reinforcement learning, an agent learns how to optimize its behaviors in uncertain environment by executing control polices experiencing the decision of rewards and improvising the policy based on the reward. Without satisfyingly strong reward function or decision, the learning may look very difficult for the present problem of caching the state space (combination of mobility, cost, frequency and cache size) that could be too extended. Therefore the time of retrieving information should be maximum and the learning would be difficult. This type of cases may shape the reward decision of caching as extremely sparse. We can approach three different reward decisions on caching itself as in the following:
A reward decision with the sparse value that is multiplied with certain values compared to the goal state. However, this kind of reward decision may also slow down the learning because the agent needs to achieve many actions before getting the decision of good caching or not effective caching. Reverse reward in case of collisions where the constraints of caching may suffer from the situation where keeping cost always lower cannot optimize the other values of constraints. Zero reward for any other state (ideally, there may be some situations where no decision can be made satisfying the cost as lower).
The reverse reward can be a primary objective in terms of evaluation of the distance and the time of information to be propagated from an initial base station to a nearest base station. It has been observed that collision may happen not for the initial iteration, but when both the number of iterations are increased and either of the three parameters like Mb, Fr and size of the cache are made dynamic. In most of the cases, the designing of the reward function in terms of decision is amalgamated with the respect to the procedure of designing state space. For example, the cache is a time depending problem. Therefore, the distance covered to reach the nearest base station can make a good reward decision or not effective reward decision. To simplify, we only mentioned a generic reward function customized with the present problem:
The state value function The action value function
Cache size over time.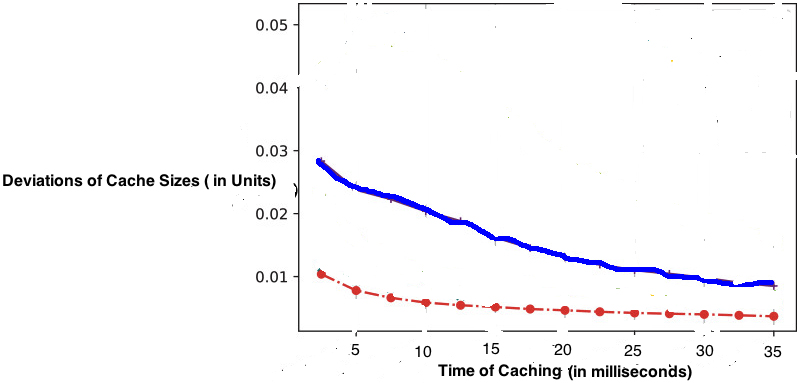
The expected return of decision for caching will be dynamic for caching process. This is because the state of constraints except the cost will change from time to time. This relation is composed with state value function
In the given expression below,
In order to validate our work, a catalogue of
With
The cost to retrieve each content is the time incurred to retrieve the content to the end user. This time is calculated according to the max bandwidth required to provide peak data rates of at least
A resource from the catalogue content is an object that contains an ID, a size and a payload that refer to the type of the content we have (video, image, audio). For simplicity, it is set to a string value. Studies have shown that Zipfs law is an appropriate distribution model for the distribution of requests and contents over Internet such as YouTube videos or peer-to-peer file sharing systems. According to Zipfs law, most user requests target a small fraction of popular web contents. Zipfs distributions related to a catalogue of
where
Based on this distribution law, several characteristics curves can be generated (see appendix for the snap of the data). The characteristics of the curves are defined as following
Choosing an optimization function to balance the four optimal parameters like frequency, mobility, size and cost. However, the cost as well as the mobility always have to be kept as minimum as possible. Deviation of cache size and time of caching is expected. The optimization of objective function to balance mobility and cost with the respect to the others generates another section of optimization. It is also expected that there will be reference mean and an actual mean between the max and the min values of bandwidth. Hence, setting histogram plots could be worthy to demonstrate these variations.
The next subsection describes the analogy behind the data and it demonstrates also the four given components as a holistic performance of the model followed by an optimization characteristic curve.
We should mention that unbalanced data have been used for two reasons. First, the scenario is a multi-objective [47]. Second, using unbalanced data requires methods to solve the problems of optimization under nonlinear constraints of inequalities. Hence, we used Karush-Kuhn-Tucker conditions (KKT) which is an optimization problem with interval-valued objective function [44, 45]. For general characteristics, the deviation of cache size may occur with respect to time of caching (see Fig. 6). In this figure, there are two segments of curves. The one in red color demonstrates that the cache size is 0.01 unit and the time of caching is only variable (in ms), then the slop of the curve becomes linear and deviates more toward a sustain value. After 3 ms, there is no significant change in deviation of cache size. However, in the same figure, the upper segment shows cache size between [0.02–0.03] units. If it differs, then the slop of the curve can only be flat after 25 to 30 ms time. This describes that the deviation of cache size while keeping the time of caching fixed can be a significant characteristic to the performance of this model. In the histogram plot of Fig. 7, frequency is a range of 10
Frequency histogram.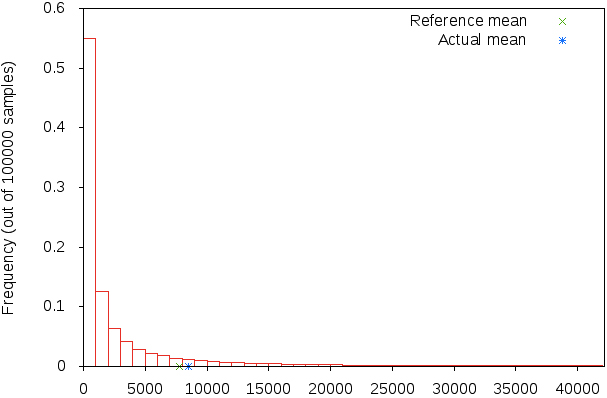
Caching decision evaluation and the optimization of the objective function.
Relation between cost, frequency and size.
Optimal clustering for cost and frequency and size.
After formulating the data generation and investigating the tendency of cache size with time, the given performance has been focused on a multi objective optimization problem. Here, the four parameters, used to analyze the trusted caching decision, can vary and significantly impure the results. For example in Fig. 8, it is shown
The dense blue dots occupy the Fr and the CR region of the plot. This entropy will distribute certain scattered blue dot from CR toward the mapping region of the cost. As it is mentioned, the cost should be kept as minimum. Therefore, very few blue dots are available in the cost region satisfying the variable Fr and CR according to the generated data. This plot is a broader outlier analysis of clustering. It describes the plot regions into different visible sections. However, due to the absence of real effective cost data, it is not possible to find more blue dots which may represent appropriate cost of caching with respect to the other parameters. The modified RL thus can distribute a map value for state – action and reward clustered for appropriate decision of caching.
In both figures:
3D distribution of input data has been shown using scatter diagram. Additionally, these following values are analyzed:
Means, Median, Std/Variance all attributes, data distribution and histograms. Co-variance of pair of attributes.
Pairwise linear regressions.
Multiple linear regressions ( Multiple quadratic regressions
To identify possible clustering, results are shown using graphical representations. For all regressions, we have used Least Square optimization techniques for the learning of model constants, i.e., regression coefficients.
Scatter diagram is showing the distribution of the data in all directions. There is no such biased or prominent grouping of data. From the graphical and tabular views, it can be easily found that some models are working with certain errors. This is also to emphasize that apparently it seems to formulate a perfect optimization function based on 4 parameters. However, in real time, it may not be suitable too.
In this paper, we have proposed and demonstrated a realistic decision scheme for caching scenario by using reinforcement learning as a machine learning component. Hence, to incorporate RL in the mobile edge caching system, we proposed certain elementary modifications. This is because following the principles of RL, the state, policies and actions or rewards are continuous variables inter-playing with each other. To consolidate this objective, the present content of the paper has been initiated with fuzzy logic module [20] followed by the inclusion of RL. This is because in normal fuzzy system, the values of membership becoming static in certain cases, may not follow the continuous function. Therefore, the formulation of a hybrid model with fuzzy and RL is required. However, the modification were expected to customize mobile-edge parameters (frequency, mobility, size and cost) while the respective policies should be kept dynamic. These dynamic properties of the proposal can support the different caching scenarios at different intervals depending on the demand and the hit ratio in real time. Certain interesting observations are made from the given proposal. It is demonstrated in the paper that to keep a minimum cost for the whole system and to vary different other parameters except mobility, a well balanced machine learning based optimization function is formulated. The data snap and the analogy have also been described in appendix of the paper for further reference. Considering the demand of the huge bandwidth and big data, the dynamic and intelligent component could foster machine learning and mobile edge caching systems more contemporary.
Finally, we have presented a decision scheme for caching scenario using a modified reinforcement learning model. Our future work will investigate the use of real datasets generated from real information centric networking scenarios.
Footnotes
Appendix A
Part of the data:
FR (% request)
CR (seconds)
CO (% of Miga)
MB (client IP modeled by distance)
0.7
1
0.01666667
1
1
0.8
0.01666667
0.5
1
0.85
0.01666667
0.1
0.8
1
0.91666667
1
1
1
0.05
0.7
0.6
0.5
0.56666667
0.8
0.55
0.9
0.01666667
1
1
1
0.35
1
0
0.4
0.35
0.8
0.5
1
0.13333333
0.7
1
1
0.03333333
0.45
0.4
0.5
0.05
1
1
0.75
0.05
0.6
0.65
0.6
0.01666667
0.3
0.6
1
0.05
0.3
1
0.45
0.05
0.7
0.4
0
0.13333333
0
1
0.4
0.21666667
1
0.8
0.5
0.01666667
0.2
0.55
1
0.01666667
0.1
0.3
0.7
0.03333333
0.4
0
1
0.05
0.3
1
1
0.03333333
0.1
0.6
1
0.01666667
0.2
0.5
0.9
0.01666667
0.1
1
0.6
0.13333333
1
1
0.9
0.05
0.1
1
1
0.56666667
0.6
0.9
0.1
0.01666667
0.4