
Abstract
Computer-Supported Collaborative Learning (CSCL) is one of the most promising innovations to enhance learning through peer interactions supported by technological advances. Collaborative learning refers to the teaching strategies whereby students are encouraged or required to work together in groups on certain learning activities. Thus, group formation is an important step to design effective CSCL environments. Adequate groups foster better interactions between members and boost learning outcomes. Nevertheless, group formation is a complex task and requires computational support to succeed. In this context, there are several studies focusing on the development of algorithms for composing student groups and evaluating them. One of the most effective approaches is the Genetic Algorithms, as it can handle numerous variables and generate optimal solutions according to the problem requirements. However, this research field is very confined. To the best of our knowledge, there is not any study that gathers and analyzes the research findings on the adoption of grouping genetic algorithm in CSCL. To fill this gap, fifteen researches on this field were selected and analyzed in order their contributions to be emerged. Thus, the scope of this paper is to give an overview on how genetic algorithms for student group formation are being applied in web-based collaborative learning environments and what facts need to be considered to develop efficient approaches.
Introduction
The proliferation of Internet has led to the evolution of digital learning, ranging from web-based individual learning environments in which students learn individually at their own pace towards achieving an educational goal, to collaborative ones in which students learn in groups towards achieving a common educational goal [1]. Collaborative learning is an instructional model that focuses on learning through group interactions and combines individual efforts to accomplish a collective activity [2]. When collaborative learning is promoted through technological advances and exploits computational tools to facilitate collaboration, coordination and communication, it refers to Computer-Supported Collaborative Learning (CSCL).
Considering the development of an efficient and effective CSCL environment, a critical task is the learner group formation, since the way students are assigned into groups affects the learning outcomes [3]. Adequate groups lead to better interaction between members of groups, improve student engagement and group potential, divide workload proportionally, increase communicative and collaborative skills, and promote sharing, assisting and encouraging among students [4]. Therefore, choosing the proper method for forming groups provides great opportunities to reach all predefined goals.
There are different approaches to compose groups: a. the groups are formed randomly, b. students select themselves their group-mates, c. teacher defines the group members manually based on several criterion, and d. automatic composition by the system using an algorithm [5]. The three first alternatives have certain disadvantages versus the automatic group formation. In particular, random-selection generates groups with unbalanced attributes, self-selection requires great social relationship from learners, and teacher-selection cannot handle large number of students and complex grouping criterion. Hence, to cope with these problems, the adoption of an effective algorithm for the learner group formation process is essential in CSCL environments [6].
The research community in the field of learner group formation has introduced several algorithmic approaches in order to efficiently face this challenge. Examples of these approaches are probabilistic algorithms, clustering, semantic web, ontologies, and so on [3, 6]. Genetic algorithm is a technique which has been used by researchers, during the last years, to make group compositions in CSCL systems, due to its applicability to handle numerous variables and its capability to generate optimal solutions rapidly [6], but the research efforts are limited. Genetic algorithm is a metaheuristic based on the concept of Darwin’s theory of evolution [7, 8].
There are various studies adopting genetic algorithm approaches for structuring collaborative groups. In each case, a variant of genetic algorithm is developed using different parameters depending on context requirements and an evaluation of the proposed method is conducted. The implementation of an efficient grouping method in CSCL environments is viral for the success of learning process. However, to the best of our knowledge, there is not any study that summarizes and analyzes the several variants in this field. Thus, CSCL community needs a guideline to be informed about how a genetic algorithm is applied for student grouping and which configurations are proper to be employed in order to compose effective grouping and enhance learning outcomes.
To this direction, this paper presents a comparative analysis of fifteen studies related to the confined research field of the exploitation of grouping genetic algorithms for promoting collaborative learning and answers to the following research questions: RQ.a. On which student attributes the group formation is based and what groups are formed? RQ.b. Which encoding and evaluation are used to represent a solution? RQ.c. Which genetic operators are applied? RQ.d. Which initialization and termination condition are determined the algorithm execution? RQ.e. Is any algorithm evaluation conducted? RQ.f. Is any analysis of grouping outcomes performed? The scope of this work is to provide a better understanding to CSCL researchers and genetic algorithm designers about the development of a genetic algorithm approach for composing optimal cooperative learning groups and the facts that influence the performance of that task.
The structure of this paper is organized as follows. In Section 2, an overview of genetic algorithm is presented, describing the operators and methods used in literature. Section 3 briefly presents the applied genetic algorithms’ approaches in student group formation selected for this review. In Section 4, a comparative analysis of these approaches is conducted, answering also the critical research questions emerged. The last section continues with some conclusions deduced from the study.
Genetic algorithm overview
As mentioned above, genetic algorithm is a metaheuristic inspired by Darwin’s theory of evolution and has been presented to be a powerful solution to optimization and search problems. It was formally introduced by Holland in 1975 [8], whereas in 1992, Emmanuel Falkenauer propounded the Grouping Genetic algorithm, overcoming the difficulties of traditional genetic algorithm in clustering issues [7]. In this paper, we focus on the employment of genetic algorithm for grouping problems, namely creating cooperative learning groups, and the term genetic algorithm is used for short to refer to grouping genetic algorithm.
There are four different types of groups in the group formation problem:
Homogeneous: the members should have common characteristics between them, i.e. the higher the number of common characteristics, the better group formation is achieved. Heterogeneous: it is required to include differential values at the characteristics among the members, i.e. most of different values at characteristics, the better group formation is achieved. Mixed: there are characteristics where the members should have similar values and others where they should have different values. Balanced: the distribution of members in a way that the characteristics among the groups are balanced.
Flow chart of genetic algorithm.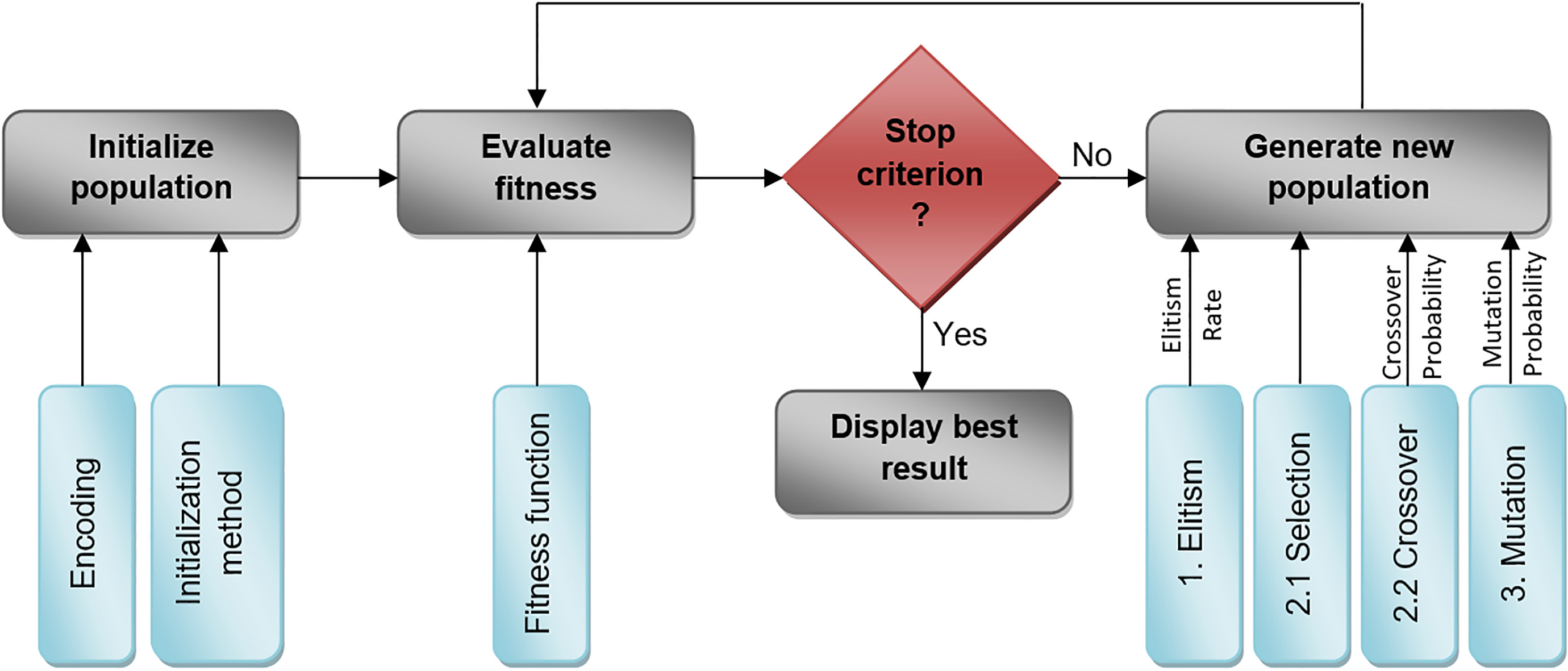
Encoding schemes of grouping learners problems.
The genetic algorithm represents the potential solutions of the grouping problem as a chromosome-like data structure, and applies a series of operators in order to investigate the optimal solution. The solutions are called chromosomes or individuals, and consist of element positions, called genes. A complete set or pool of generated solutions (chromosomes) refers to population, whereas the new population produced after each iteration of performing a series of computations, is called a new generation.
Figure 1 illustrates the steps followed in a genetic algorithm approach. First, the initial population is generated based on the desired chromosome encoding and the initialization method. When a population is generated, an evaluation value for each gene is calculated based on the defined fitness function. Afterwards, iterations producing a new population using genetic operators are performed until the algorithm reaches termination criteria and converges to the optimal solution. The genetic operators applied are: a. the elitism selection of current population’s chromosomes to be included in new one, b. the selection of two chromosomes, called parents, where crossover operator is applied in order to produce new chromosomes, c. mutation of new generation to insert new chromosomes. The steps of genetic algorithm are extensively described below.
Encoding is the process of chromosomes’ representation using bits, numbers or string values in a tree, array, list or other structure. The encoding scheme varies based on the characteristics of the solving problem. Examples of the most commonly used encoding schemes in grouping learners problems are shown in Fig. 2.
Suppose that students should be assigned to cooperative learning groups. The chromosome representation usually used is an array where either the elements refer to the group and their index to the student ID, or the opposite one (Fig. 2a and b). However, in some cases, a matrix representation is adopted where the rows correspond to the groups and the columns to the group size. The elements of the matrix are the student ID (Fig. 2c).
Initialization
Once the encoding scheme has been defined, the initialization process should be executed. In this stage, an initial population is generated randomly or using heuristics. The most commonly used method in grouping learners problems is the random initialization, however the heuristic can be adapted to produce a population with diversity.
The most commonly used selection methods.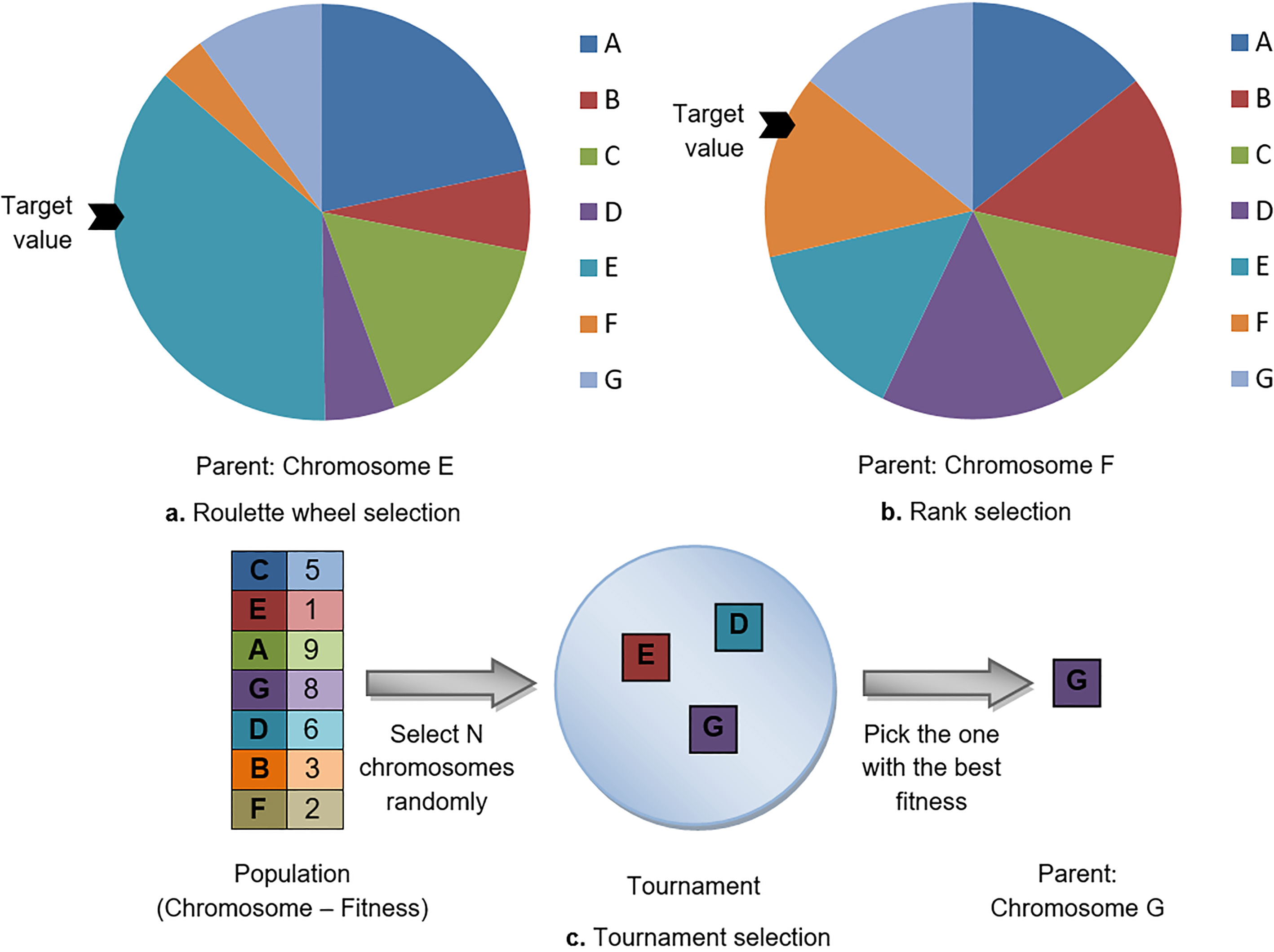
The fitness function is an objective function that measures how “fit” or “good” a solution is, considering the problem constrains. It takes a chromosome as input and produces as output its fitness through a series of computations on genes characteristics. The fitness function is essential for the decision of the appropriate solutions and should be sufficiently fast to compute as it is repeatedly used in the genetic algorithm. The choice of the fitness function is depended on the characteristics used for the grouping problem and the type of groups needed to be formed.
Selection
Selection is the process of choosing two chromosomes, as parents, from the population in order to create offspring for the next generation through crossing. The selection strategy is based on picking the fitter chromosomes in hopes that their offspring have better fitness. There are various selection methods depending on the way the parents selected. Figure 3 illustrates the most popular methods.
Roulette wheel selection is one of the most widely used genetic algorithm selection techniques and works as follows. Consider a wheel with size equal to the sum of all chromosomes fitness values. At each chromosome is corresponded a slot in this wheel proportional to its fitness. Then a random target value is set in the range of fitness sum, and the population is stepped through until the target value is reached. The chromosome in the position where the target value reached is the parent. In this technique, the better fitness a chromosome has, the higher probability to be selected. In case the chromosomes in the population have very close fitness values, each chromosome will have an almost equal slot in the wheel and hence the same probability to be selected as parent. This scenario comprises a variant of roulette wheel, called rank selection.
Tournament selection is another frequently used method where tournament competitions are conducted among a few chromosomes (tournament size) which have been selected randomly. The winner of each tournament is the one with the higher fitness and, by extension, the parent.
Finally, other selection techniques, not used so widespread, are the random and stochastic universal sampling.
The most popular crossover operators.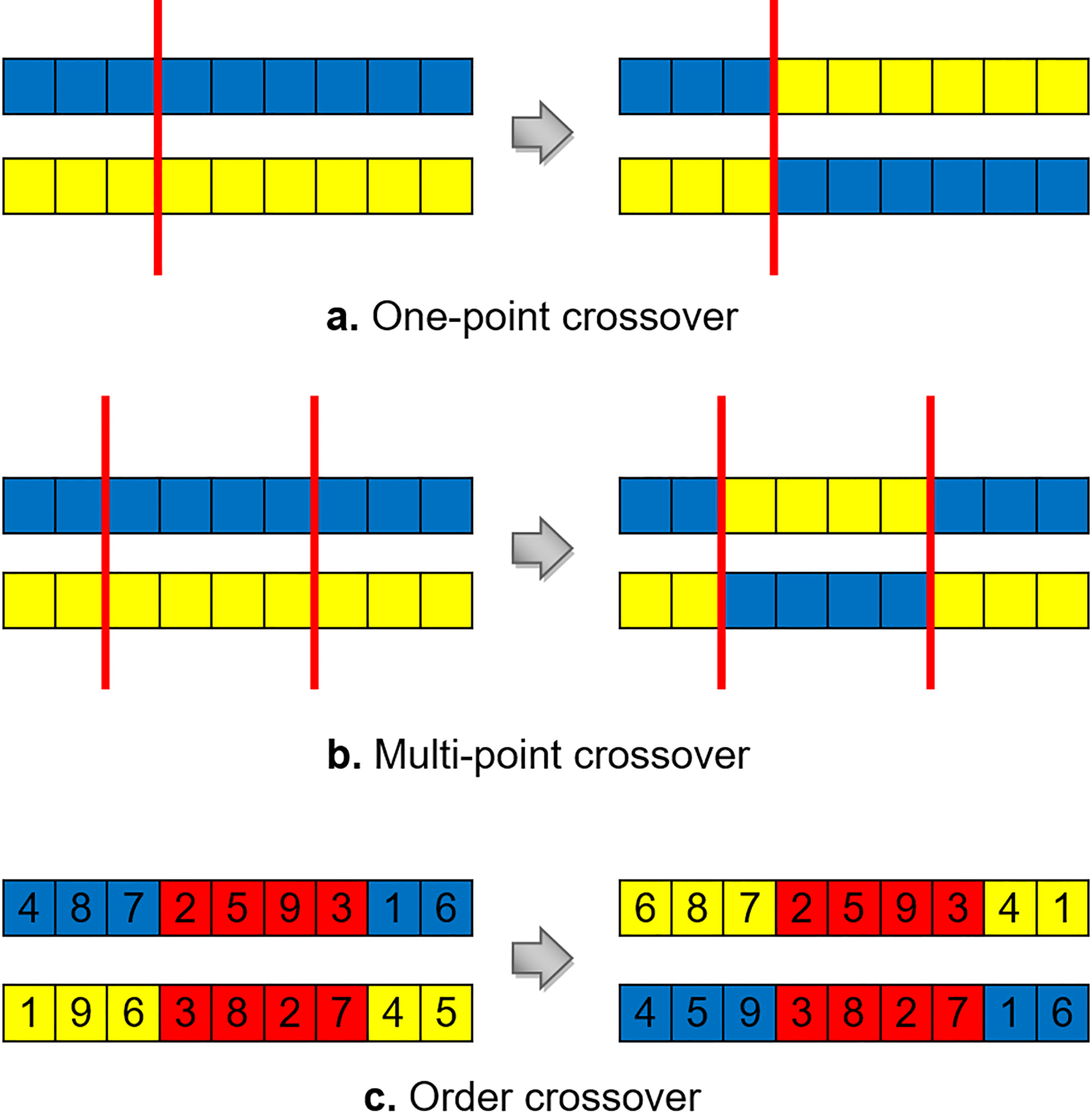
Crossover is a recombination operator that takes two parents and produces offspring based on genetic material of the parents. Crossover is usually applied in a genetic algorithm with a high probability in a hope that better offspring will be generated by exchanging the genetic information between two parents. The most popular crossover operators are shown in Fig. 4. However, there is not an operator characterized as the best. Several genetic algorithm designers implement their own crossover, which usually is a modification of the following generic operators related to problem context and requirements, and/or combine these approaches.
In one-point crossover, a random crossover point is selected along the length of the chromosome and the two parents are split at this point. The segments after this point are exchanged, generating the two offsprings. Apart from this approach, many algorithms are devised according the number of cut points. Thus, a multi-point crossover is performed where the parents’ segments between the points are swapped to produce the offspring. Note that adding further points reduces the performance of the algorithm, but on the other hand the problem space can be searched more thoroughly.
The aforementioned approached, when applied to a grouping problem, may generate overlapping among the groups or students, depending on the selected representation, i.e. if the gene represents the group or the student id. In the first case, the offspring may be invalid since the groups formed could have different size, out of the pre-defined one; whereas, in the second case, a student could appear in the offspring twice. To overcome this conflict, special repair algorithms, such as group size adjustment algorithm, rejection method, renumbering, or other crossover operators, like order crossover, need to be performed for producing legal offspring.
The order crossover (OX1) uses two random crossover points and copies the middle segment from the fist parent to the offspring, at the same positions. Afterwards, the empty genes of the offspring are filled in, starting from the right side of segment, with the unused genes of the other parent as they are met by scanning the parent from the second crossover point. There are a variety of other crossovers operators, such as partially mapped crossover (PMX), order-based crossover (OX2), cycle crossover, etc.
Mutation
The role of mutation is to insert new characteristics into the new population, in order to enhance the search space of the algorithm. Mutation is performed with very low probability to the new population; otherwise the algorithm gets reduced to a random search. The aim of mutation is to increase diversity into the population by introducing random variations into the chromosomes. Therefore, it prevents the algorithm to be trapped in a local minimum.
The most common mutation operators.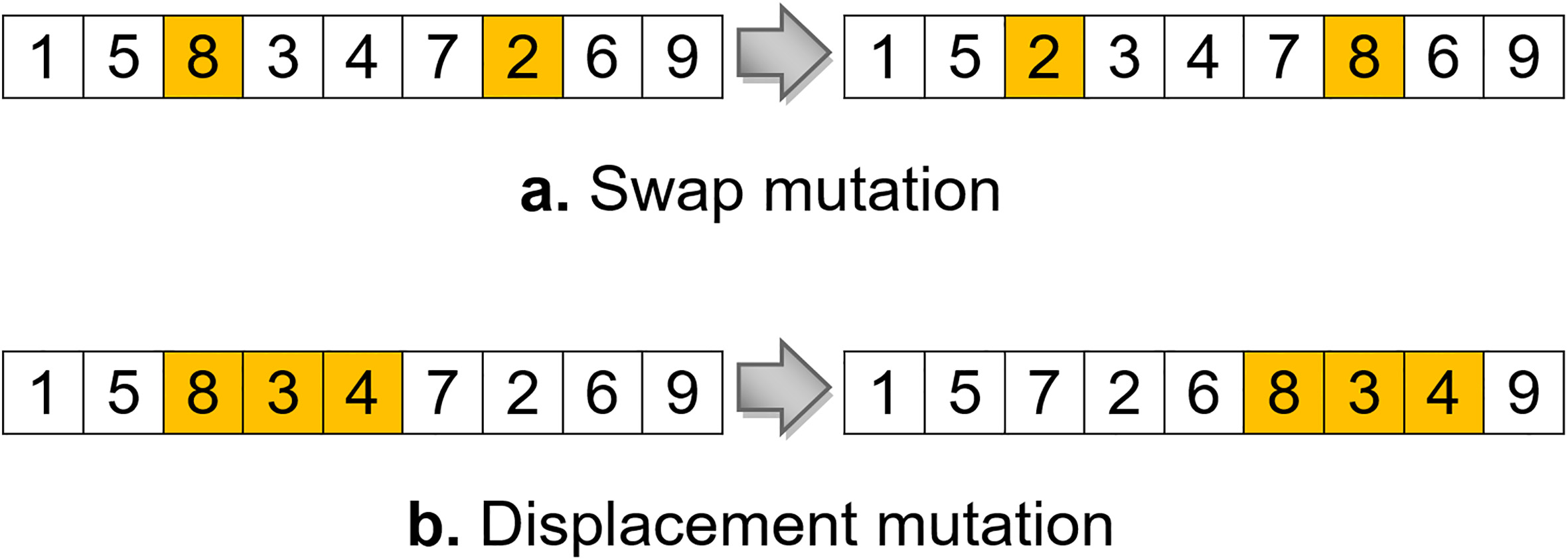
There are many different forms of mutation for the different kinds of representation and problems. For grouping problems, the most commonly used mutation is presented in Fig. 5. In swap mutation, two genes are selected randomly and swap their positions; whereas, in displacement one, a segment in the chromosome is selected and is inserted in a random place.
Elitism is a kind of selection where a small proportion of the fittest chromosomes is copied to the new population unaffected. Such chromosomes can be lost if they are not selected to reproduce or if crossover and mutation destroys them. This strategy assures that the best chromosome of a population will be better or at least equal to the best chromosome of the previous population. Thus, elitism can increase the performance of a genetic algorithm, because it prevents losing the best found solution. When elitism is used, the elitism rate is needed to be specified, indicating the number of top chromosomes to be duplicated.
Termination
The termination condition of a genetic algorithm is essential to determinate when the algorithm will stop running. The choice of the proper termination condition is vital to the algorithm performance, as it affects the computation time and the convergence to the optimal solution. The most common stopping criteria are listed as follows:
Maximum generations: The genetic algorithm stops when the fixed number of generations has reached. Elapsed time: The genetic process will end when a specified time has elapsed. No change in fitness: The iterations will stop if there is no change to the population’s best fitness for a specified number of generations. Desired fitness: The algorithm will end if the fitness value has reached a certain pre-defined value.
The three last terminating conditions are used in combination with the first one, i.e. if the maximum number of generation has been reached before the other criterion satisfied, the process will stop.
One of the factors that affect the efficiency of collaborative learning is the group formation. Composing proper groups can be beneficial to students to achieve the appropriate learning results through the better interactions among group members to which can lead this task. Due to the large amount of information that has to be processed for the group formation, namely the number of learners, the different characteristics to be considered and the group constrains, this process requires computing techniques to be completed successfully. Genetic algorithm is one of the most widely applied approaches in this field, as it can handle a large number of variables and generate immediately optimal solutions [6].
The scope of this paper is to investigate the applicability of genetic algorithm approaches in the context of collaborative group formation in order to help research community to develop more efficient solutions in this field. Therefore, a thorough literature search was conducted in important electronic databases and fifteen papers were chosen to be included in this research based on the criterion to apply genetic algorithm in collaborative learning. It needs to be underlined that genetic algorithms have not been used yet extensively for group formation in CSCL environments and thus there are not so many efforts to this direction. Our study is the first study that conducts a synthetic literature review at this topic. The 60% of the selected papers were published in qualitative research journals, whereas the rest derived from significant international conferences. The description of their approaches is presented as follows and an evaluation of their configurations is analyzed in the next section.
Comparative analysis of applied approaches and discussion
The scope of this review is to identify and classify the features of genetic algorithms used to assist the formation of cooperative learning groups. To define the objectives and report the evidences on genetic algorithms for group formation in collaborative learning environments, the following research questions were arisen:
On which student attributes the group formation is based and what groups are formed? Which encoding and evaluation are used to represent a solution? Which genetic operators are applied? Which initialization and termination condition are determined the algorithm execution? Is any algorithm evaluation conducted? Is any analysis of grouping outcomes performed?
To this direction, a comparative analysis of the fifteen applied genetic algorithms’ approaches in student group formation, presented in the previous section, was conducted and the results were tabulated, as shown in Table 1. The answers of the aforementioned research questions and a discussion on them are presented below.
To answer RQ.a (on which student attributes the group formation is based and what groups are formed?), the learning context needs to be studied. It is observed that heterogeneous groups mainly are formed (54% of reviewed studies, Fig. 6) with group size of 4 to 5 students. A possible reason why this type of cooperative groups preferred is because they can improve outcomes for all of the students as the different characteristics they have can be complementary, boosting the learning potential of group. The domain student characteristic used for the group formation is the student grades achieved in courses. This is expected as the groups pertain to students that need to work together on the same project in a collaborative learning envi- ronment, and the lesson grades is the most simple and
Comparison of genetic algorithm approaches in student group formation (n/m: not mentioned)
Comparison of genetic algorithm approaches in student group formation (n/m: not mentioned)
Type of groups formed using genetic algorithm.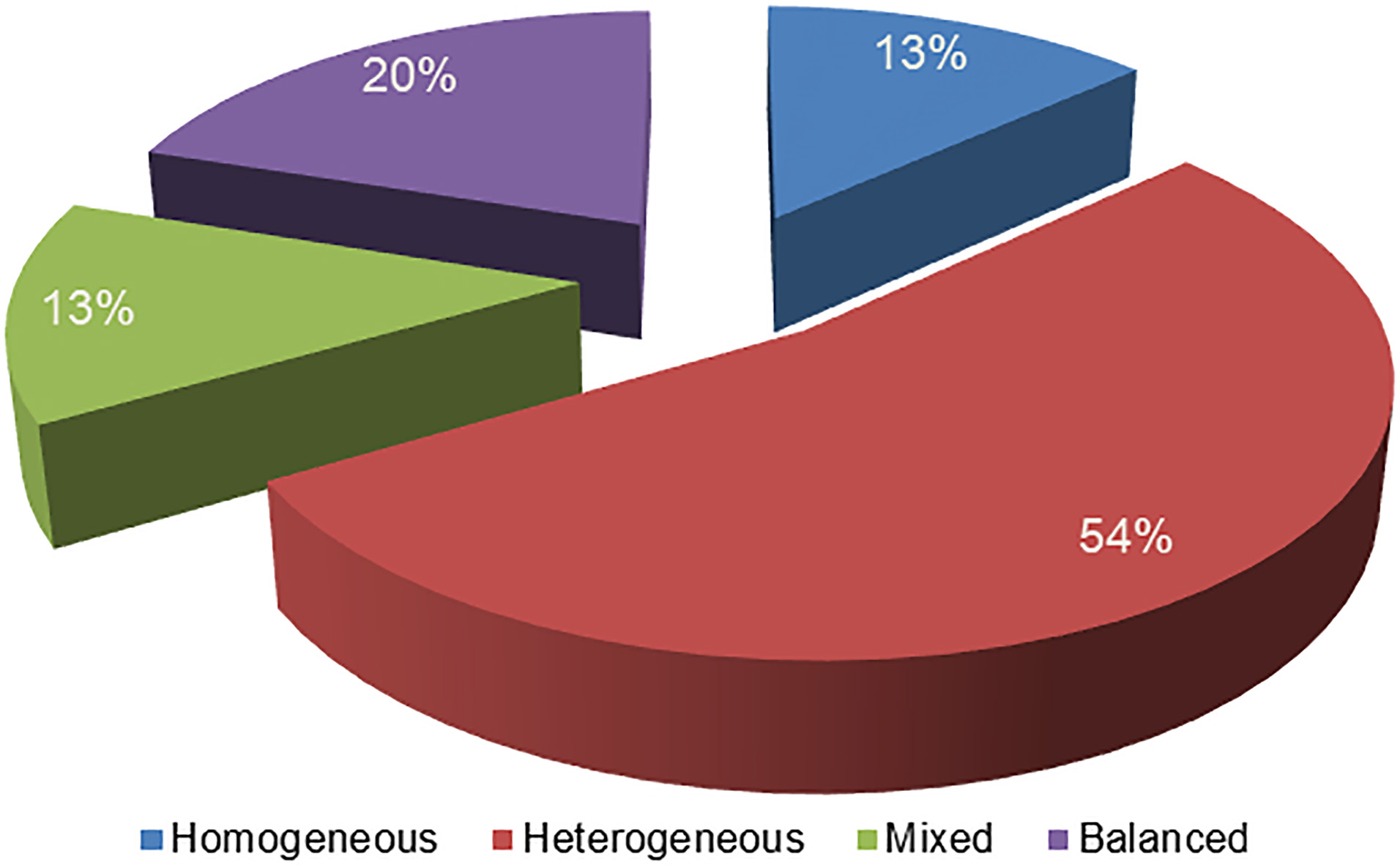
Attributes used for the group formation.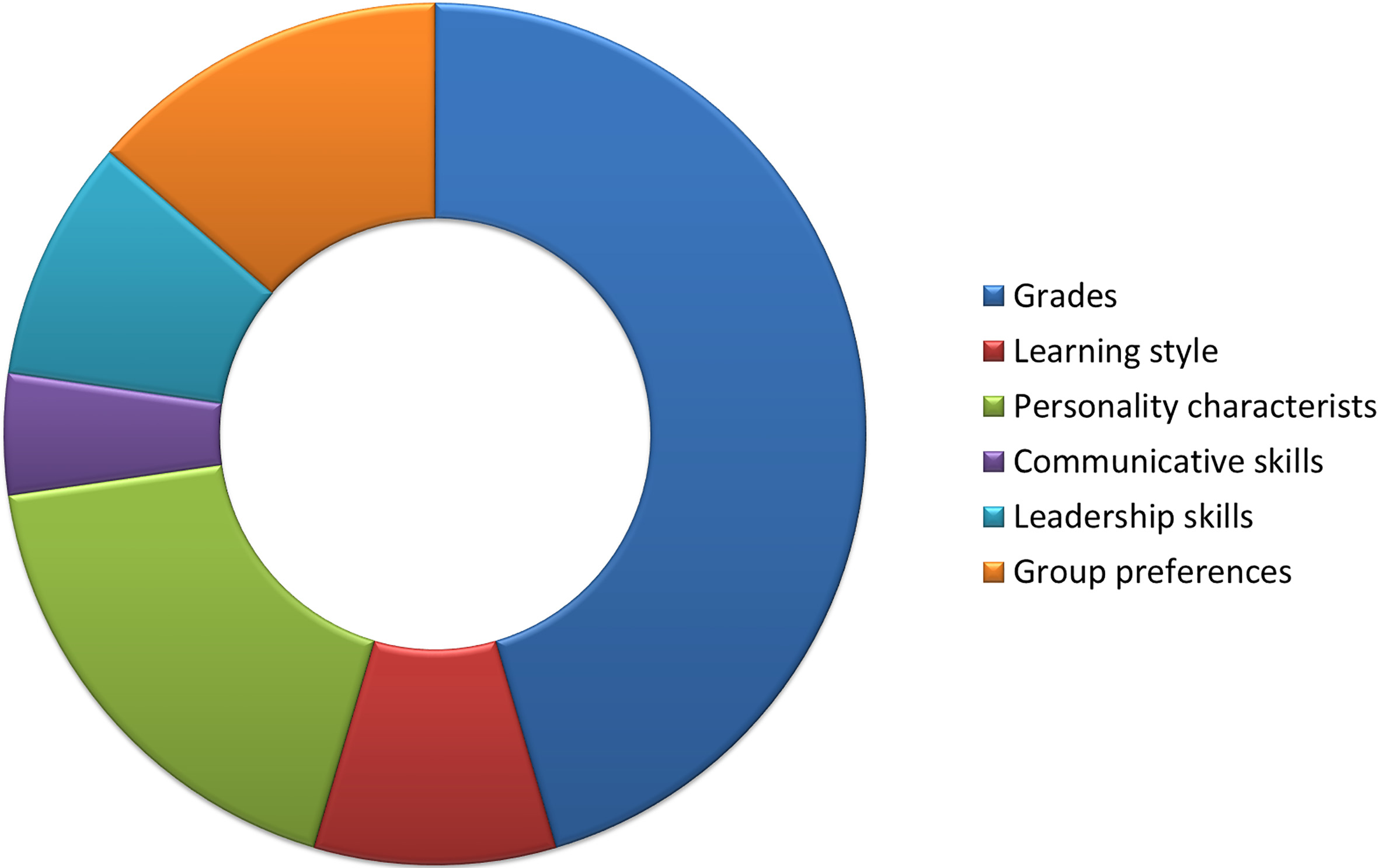
Data structure used for encoding chromosomes.
Metrics used in fitness function.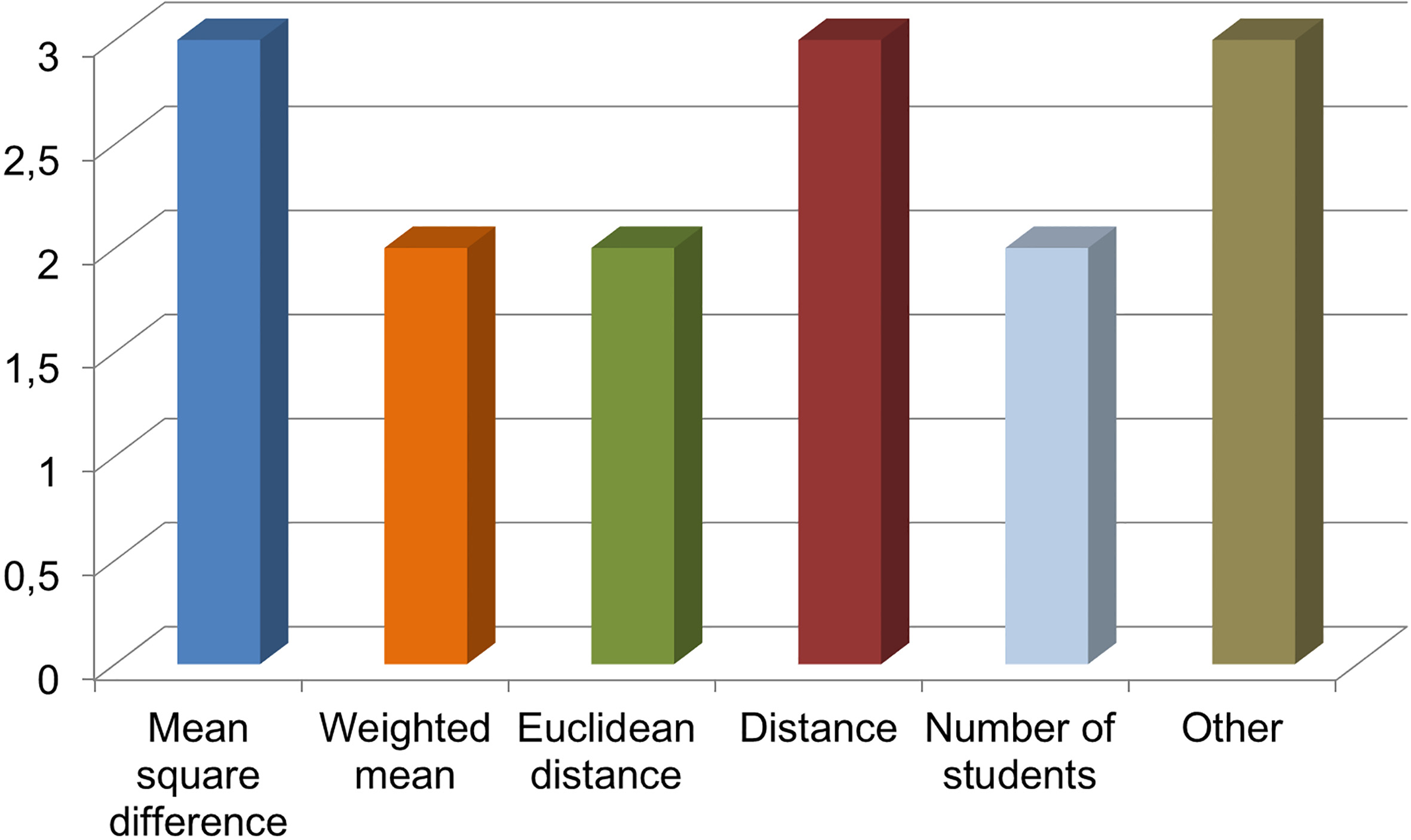
Selection methods used.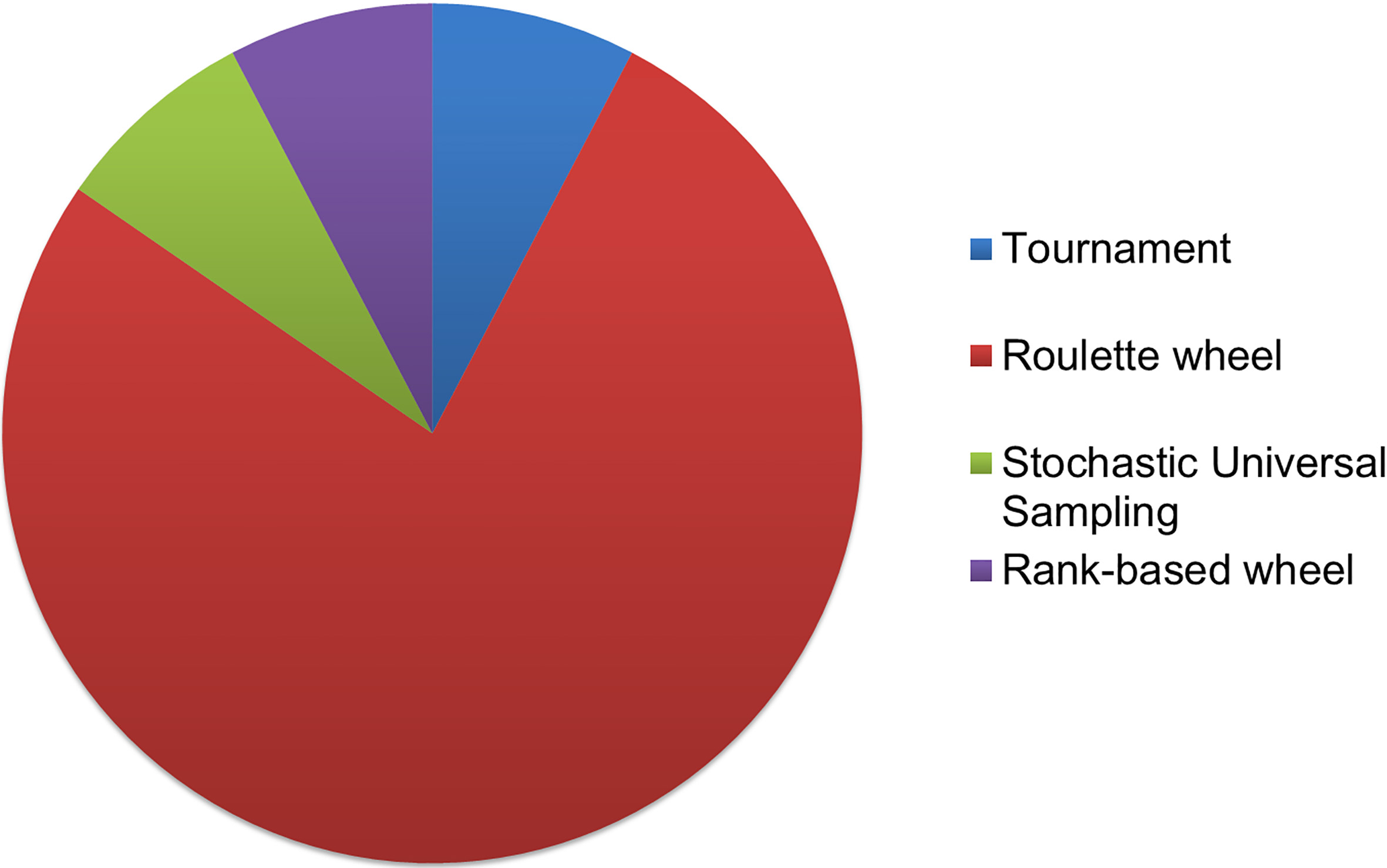
Crossover operators used.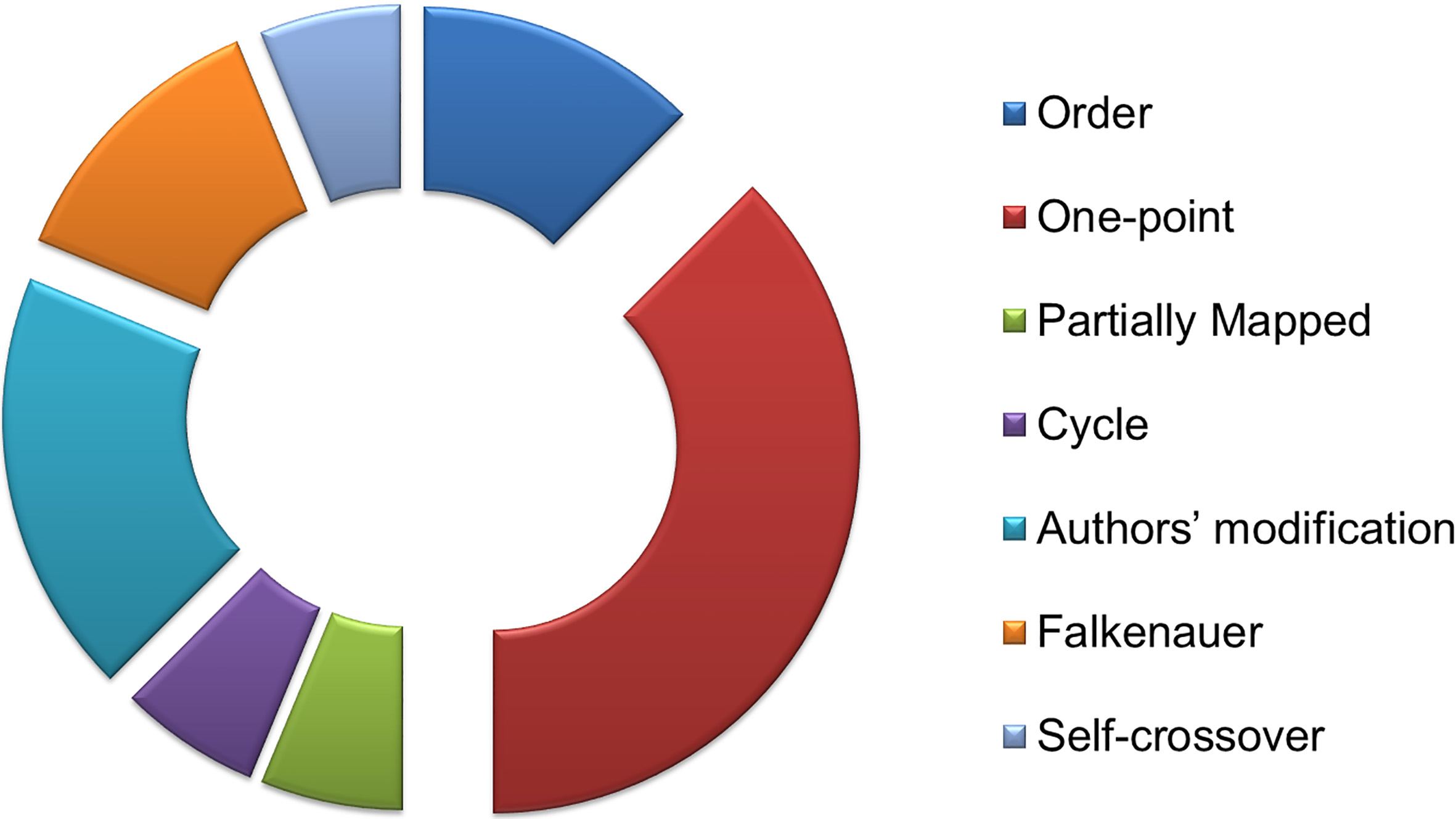
easily available attribute to characterized a learner. Several studies use as grouping criterion characteristics of student personality, e.g. multiple intelligences, assertiveness, social skills, which emerge from user profile or respective tests given. Moreover, student learning style, communicative and leadership skills are also used, as they affect the success of collaboration. Finally, student group preferences constitutes another criterion for group composition, as sometimes people feel more comfortable and are more productive when working with group-mates they have chosen. The algorithms studied in this research use a small number of attributes, 1 to 3 mainly, based on which the groups formed. Figure 7 shows the attributes used for the group formation.
Mutation operators applied.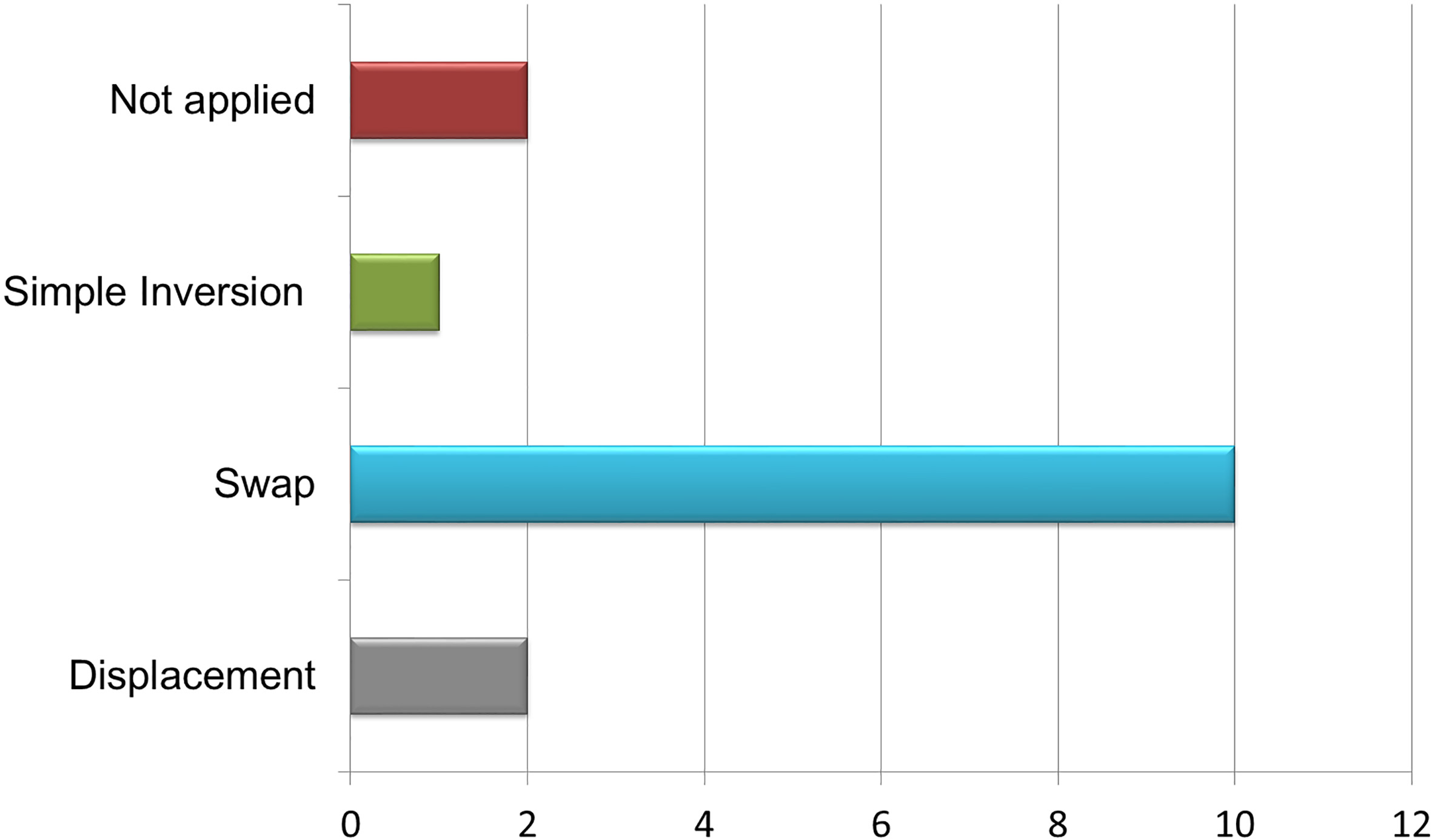
Percentage of studies performed algorithm and/or grouping outcomes evaluation.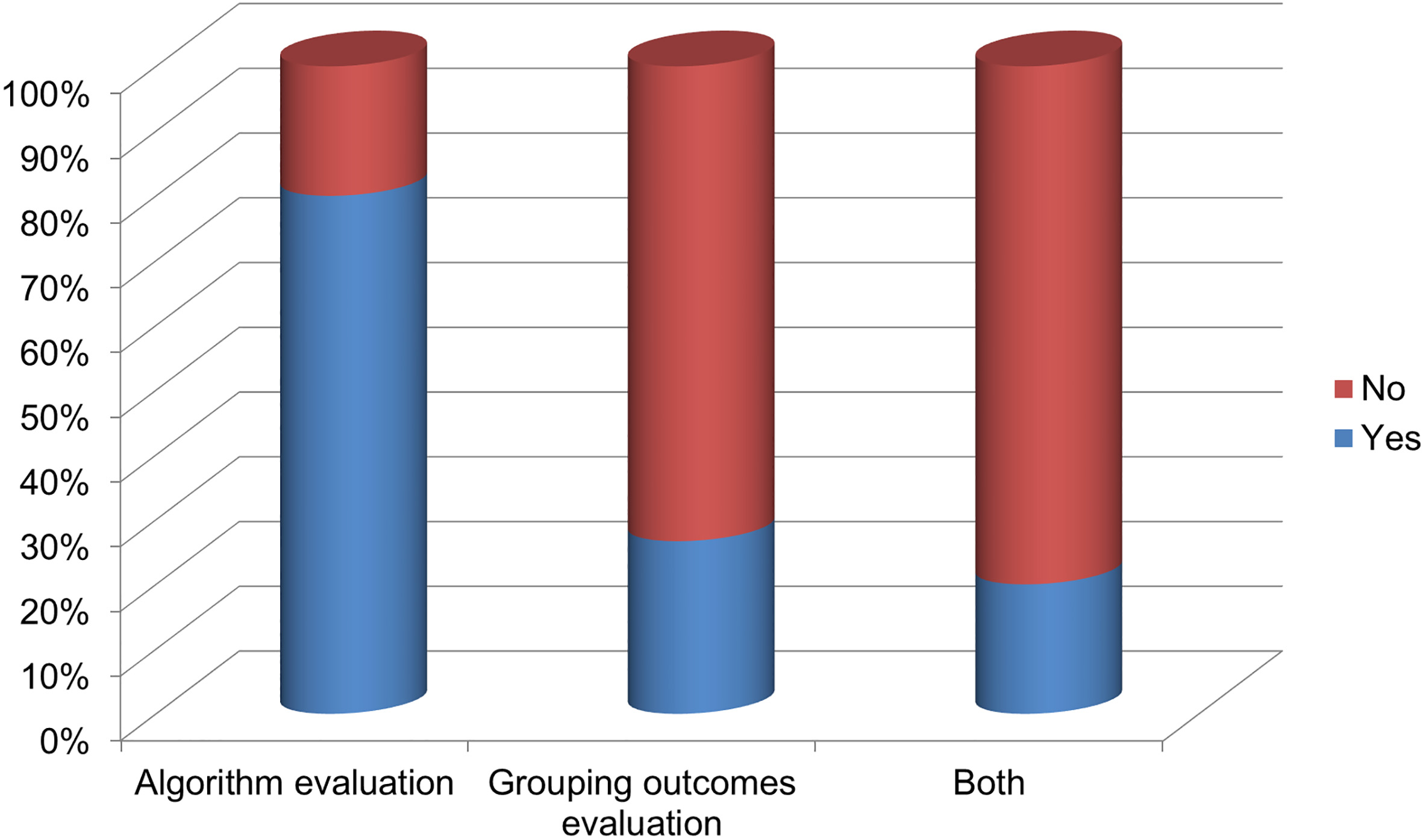
To tackle RQ.b., RQ.c. and RQ.d., we extract information about the implementation of genetic algorithms and the configurations used. Concerning RQ.b. (which encoding and evaluation are used to represent a solution?), most of works represent the solution using an array (approximately 70% of the studies, Fig. 8). This data structure is preferred because it facilitates the computation on the chromosomes and the implementation of genetic operators. The matrix is only used by approximately 30% of the studies, even though the simplicity of its formulation and its clear interpretation. In these studies, modifications of crossover operator are used, taking advantage of the matrix representation. For evaluating the solutions generated by the algorithm, a function is defined where several calculation on students characteristics performed for measuring the fitness of each chromosome. This fitness function is mainly based on the distance metric (Euclidean or not) of the attributes selected for group composition. Other metrics used are the mean square difference, weighted mean or number of students having each attribute (Fig. 9).
Regarding RQ.c. (which genetic operators are applied?), the three genetic operators, namely selection/elitism, crossover and mutation, used in selected approaches of this review, are analyzed. The most common selection method used is the roulette wheel with 70% of the studies to employ this method (Fig. 10). In comparison to other methods, roulette wheel gives a chance all of the chromosomes to be selected as parent, assigning a better chance to the fitter chromosomes. The most popular crossover operator is the one-point. This operator is easily deployed and generates effective offspring. In some cases, the researches introduce their own modification of crossover adapted to their problem context, aiming to generate better offspring. Whereas others employ more than one crossover operators (Table 1). Figure 11 illustrates the different crossover used. The swap mutation is widely used in group genetic algorithms, as shown in Fig. 12, because it is an easy way to insert new genetic information to the population. Analyzing elitism employment, Table 1 depicts that only few studies incorporate this survivor selection, whereas others do not either apply or mention it.
Considering RQ.d. (which initialization and termination condition are determined the algorithm execution?), this review shows that the vast majority of genetic algorithm designers generates randomly the initial population of algorithm (Table 1). Whereas, the termination criterion is either a maximum number of generation reached, or a combination of this with fitness convergent (Table 1). The last criterion is used in order to improve the performance of algorithm by eliminating the needless iterations which do not bring better results, and thus reducing the execution time.
Concerning RQ.e. (is any algorithm evaluation conducted?) and RQ.f. (is any analysis of grouping outcomes performed?), the majority of the studies in the field of cooperative learning group formation evaluate mainly the results of the genetic algorithm in the view of different settings used and their impact on the performance of the algorithm. Moreover, in some cases, they compare their approach to other grouping methods. However, these studies lack in the evaluation of the performance of groups and the learning objectives achieved, which is valuable for the learning process and the entire success of grouping algorithm. This kind of evaluation can be performed by comparing the performance of students before collaboration to the one after collaboration or to group one, and/or measuring the quality and quantity of interactions between group members in order to recognize the blockages in team collaboration. In particular, the results of this review indicate that the 80% of proposed grouping approaches have evaluated their algorithm, and only the 20% have performed two dimensions evaluation, algorithm and grouping outcomes one (Fig. 13).
Group formation is a hot issue in the field of CSCL due to its domain role in the success of learning process. Having adequate groups promotes better interactions between members and provides more opportunities to improve learning results. The complexity of structuring effective groups manually leads to the exploitation of computational techniques to automate this process and improve its results. Such an approach is the genetic algorithm which is exhaustively analyzed in this work. Genetic algorithm is widely used in CSCL environments, as it produces reliable solutions rapidly handling numerous variables and composing optimal collaborative learning groups.
After the thorough investigation in the literature focusing on the field of genetic algorithms for group composition in collaborative learning environments and given the confined research field, fifteen studies selected to be included in current review. These studies were, firstly, analyzed and the produced evidences were used to answer six critical research questions: RQ.a. On which student attributes the group formation is based and what groups are formed? RQ.b. Which encoding and evaluation are used to represent a solution? RQ.c. Which genetic operators are applied? RQ.d. Which initialization and termination condition are determined the algorithm execution? RQ.e. Is any algorithm evaluation conducted? RQ.f. Is any analysis of grouping outcomes performed?
The results indicate that the algorithm is used mainly for the formation of heterogeneous groups of 4 to 5 students and the domain characteristic employed for this process is the student grades (RQ.a). The most common data structure for the representation of solutions is an array, whereas the fitness evaluation is mostly based on the calculation of the distance between members’ attributes (RQ.b). Regarding the genetic operators, the most widely used are the roulette wheel selection, one-point crossover and swap mutation (RQ.c). The vast majority of approaches generate their initial population randomly, whereas the algorithm terminate when a maximum of iterations reached or fitness converges (RQ.d). Finally, most of the works evaluate the performance of proposed algorithm and lack analysis of grouping outcomes (RQ.e/f).
The contribution of this research is to provide to CSCL community an overview of the genetic algorithm approaches used for student group formation. This can be used as guideline for the genetic algorithm designers to choose the proper settings in order to boost algorithm performance and enhance learning outcomes due to the effectiveness of provided grouping. Besides the exhaustive investigation of the computational features used, this review has identified a critical issue in existing literature, namely the lack of presenting and sharing the source code of developed genetic algorithms. Moreover, the implementation of independent software that deploys a genetic algorithm approach parameterized to any requirement of student grouping problems, i.e. group size, student attributes and genetic operators, is a challenge for future work.