
Abstract
Intrusion can compromise the integrity, confidentiality, or availability of a computer system. Intrusion Detection System (IDS) is a type of security software designed to monitor network traffic and identify network intrusions. In this paper, A Fuzzy Rule – Based classification system is used to detect intrusion in a computer network. In order to improve the classification rate, a new method is proposed based on Genetic Algorithm (GA) for rule weights specification. The proposed method is tested on KDD99 dataset. Experimental results show the proposed method improves the performance of the fuzzy rule-based classification systems in terms of detection rate and false alarm rate.
Introduction
With the rapid growth of the Internet, various attacks on the network can pose a major threat to network and information security. Attackers attempt to attack networks in order to gain access to information resources. So intrusion detection [1, 2] is a practical mechanism to handle the hackers from exploiting the data. An intrusion detection system (IDS) is a type of security software designed to automatically alert administrators when someone or something is trying to compromise information system through malicious activities or through security policy violations. There are multiple ways that detection is performed by IDS. In signature-based detection, a pattern or signature is compared to previous events to discover current threats. This is useful for finding already known threats, but does not help in finding unknown threats, variants of threats or hidden threats. Another type of detection is anomaly-based detection, which identifies malicious traffic based on deviations from recognized normal network traffic patterns. The problem of intrusion detection has received a lot of attention in machine learning and data mining [3, 4]. Zamini and Hasheminejad [5] had an overview of the research on anomaly detection. They classified anomaly detection according to their application and then categorized their techniques. Furthermore, they discussed on differences among existing techniques in each specific category and described the advantages and disadvantages of each technique.
Data mining generally refers to the process of extracting useful rules from large stores of data. That is one of the technologies applied to intrusion detection. Rafsanjani and Varzaneh [6] introduced various data mining techniques used to implement an intrusion detection system. They reviewed some of the related studies focusing on data mining algorithms. Fuzzy rule-based systems have been successfully applied to various application areas. Fuzzy if-then rules are traditionally gained from human experts. Recently, various methods have been suggested for automatically generating and adjusting fuzzy if-then rules without using the aid of human experts [7, 8].
The remainder of the paper is organized as follows. Related works on intrusion detection is introduced in Section 2. In Section 3, the method used for designing FRBCS from numerical data is presented. In Section 4, the proposed method is explained. Simulation results on database KDD99Cup are given in Section 5. Finally, Section 6 gives concluding remarks.
Contributions of our paper
In recent years, finding an effective and suitable model in the field of intrusion detection has been considered as an important issue. Due to the importance of intrusion detection and considering the fact that data mining is one of the practical technologies which proposes a new pattern from data of mass networks, researchers have been focused on hybrid algorithms, fuzzy techniques, neural networks, genetic algorithm, and etc. Even though, the preceding approaches are able to produce acceptable models of intrusion detection, they could not reach the ideal result.
In this paper, the technique which has been used to detect intrusion in the computer network is based on Fuzzy Rule-Based Classification Systems (FRBCS) [9, 26]. In overall, finding a compressed set of if-then classification rules that are able to model the behavior of a system is the main obligation of a FRBCS. The first step of the proposed model is producing the rules that will be followed by selecting the best rules at the second step to reduce the complexity. In order to improve the classification rate, in this paper, an evolutionary approach is introduced for learning rule weights, which is evolved by genetic algorithm method [10, 11]. Afterwards, genetic algorithm is used to find the optimum weights which are able to increase the level of accuracy for classification.
According to the results of the proposed method, classifiers based on fuzzy rules have a lower false alarm rate in comparison with the other classifiers. Therefore, classifiers based on fuzzy rules are the best choice for systems with the goal of having the lowest number of false alarms.
Related works
Researchers have proposed various methods for detecting intrusions. Su [12] proposed a method to identify flooding attacks in real-time, based on anomaly detection by genetic weighted KNN (K-nearest-neighbor) classifiers. A genetic algorithm is used to train an optimal weight vector for features. An SVM-based intrusion detection system is presented in [13], one which combined a hierarchical clustering algorithm (BIRCH), a simple feature selection procedure, and the SVM (Support Vector Machines) method. This method is also evaluated using on the KDD 1999 datasets. Mabu et al. [14] proposed a novel fuzzy class-association-rule mining method based on genetic network programming (GNP) for detecting network intrusions which can be flexibly applied to both misuse and anomaly detection in network-intrusion-detection problems. A PSO-based optimized clustering method (IDCPSO) proposed in [15] to optimize the clustering results and obtain the optimal detection result. Boughaci et al. [16] proposed a fuzzy particle optimization algorithm (FPSO) for intrusion detection that works on a knowledge base modeled as a fuzzy rule if-then and improved by a PSO algorithm. Abadeh et al. [17] proposed a technique base on fuzzy genetic learning. Moreover, they suggested a new fitness function calls SRPP. A method to cascade k-Means clustering and the C4.5 decision tree methods proposed in [18] to classify anomalous and normal activities in a computer network. At the first stage, k-Means clustering is performed on training instances to obtain k disjoint clusters. In the second stage, the k-Means method is cascaded with the C4.5 by building decision trees using the instances in each k-Means cluster. Nadiammai and Hemalatha [19] proposed EDADT algorithm to reduce the space occupied by the dataset. So, it would be useful for the network administrator/manager to avoid the delay between the arrival and the detection time of the attacks respectively. Yang et al. [20] proposed a data-driven network intrusion detection system using fuzzy interpolation in an effort to address the aforementioned limitations. The experiment results demonstrated that the proposed method detect the unknown types of treats.
In [21], A novel strategy for intrusion detection in wireless sensor networks based on accurate neural models of specific attacks learned from network traffic data is proposed and evaluated. In 2020, Zhang et al. [22] presented a new network intrusion detection method based on Auto-Encoder network (AN) and long-term memory neural network (LSTM). AN is constructed by superimposing multiple auto-encoder networks to map high-dimensional data to low-dimensional space. Then the LSTM model optimizes the cell structure is used to extract features, train data and predict intrusion detection types. Alazzam et al. [23] proposed a wrapper feature selection algorithm for IDS based on pigeon inspired optimizer to utilize the selection process. They proposed a new method to binarize a continuous pigeon inspired optimizer.
Karthikeyan et al. [24] implemented a classifier ensemble based intrusion detection systems (CEBIDS) by combining feature level and data level techniques in WEKA tool with KDD cup’99 dataset. In [25], a clustering-based outlier detection (CBOD) approach is proposed for classifying normal and intrusive patterns. The proposed scheme extracts the most relevant features, then learns the normal pattern in the training data by forming clusters and identifies outliers in the testing data.
Generate of fuzzy If-Then rules
This paper uses a fuzzy rule-based classifier proposed in [26] which first fuzzy if-then rules are generated from numerical data. Then the generated rules are used as candidate rules. For an M-class problem in an
where
Fuzzy partitions of the domain interval [0, 1].
We define the compatibility grade of each training pattern
where
The support
The most common reasoning methods are single winner reasoning method and weighted vote reasoning method [28]. For classifying an input pattern
where
In analogy with the preceding approaches like [26], the proposed method stands for finding proper weights for rules. For the objective of improving the accuracy of fuzzy rule based classification systems, weights are considered for fuzzy rules. This paper uses genetic algorithm to find the most suitable weights for the rules. The process starts with generating initial random weights for initial fuzzy rules. Afterwards, suitable weights are found by genetic algorithm. The genetic algorithm considers the weight of each rule as an optimization parameter (gene). Regarding the definition of each gene, each individual in a population is composed of weights of all the rules. Also, an individual with the highest fitness will be selected as the final answer. Moreover, in this research, the accuracy of classification based on the fuzzy rules is considered as the fitness function. In the other words, the best class is identified for each input data and classes are classified accordingly. Finally, the accuracy of classification is calculated for both attack and normal data. This section details the proposed method.
Genetic algorithm
Genetic algorithms [10, 11, 29] by inheriting the process of natural evolution, such as inheritance, mutation, selection and genetic crossover, perform heuristic search and optimization practices and provide solutions to optimization problems, such as inheritance, mutation, selection and Genetic intersection that occurs during the marriage of parents to produce offspring. It is used to guide a method of evaluating a list of parameters that provide possible solutions to the problem (also called chromosomes or genomes) in this list of parameters. Evolution is an iterative process that usually starts from a random population. The population of each repeat is called a generation. These chromosomes are evaluated and a value of goodness or fitness is returned. Usually, the algorithm terminates either by producing the maximum number of generations, or by achieving acceptable fitness levels for the population. The genetic algorithm is sketched in Fig. 2.
The operation of a GA.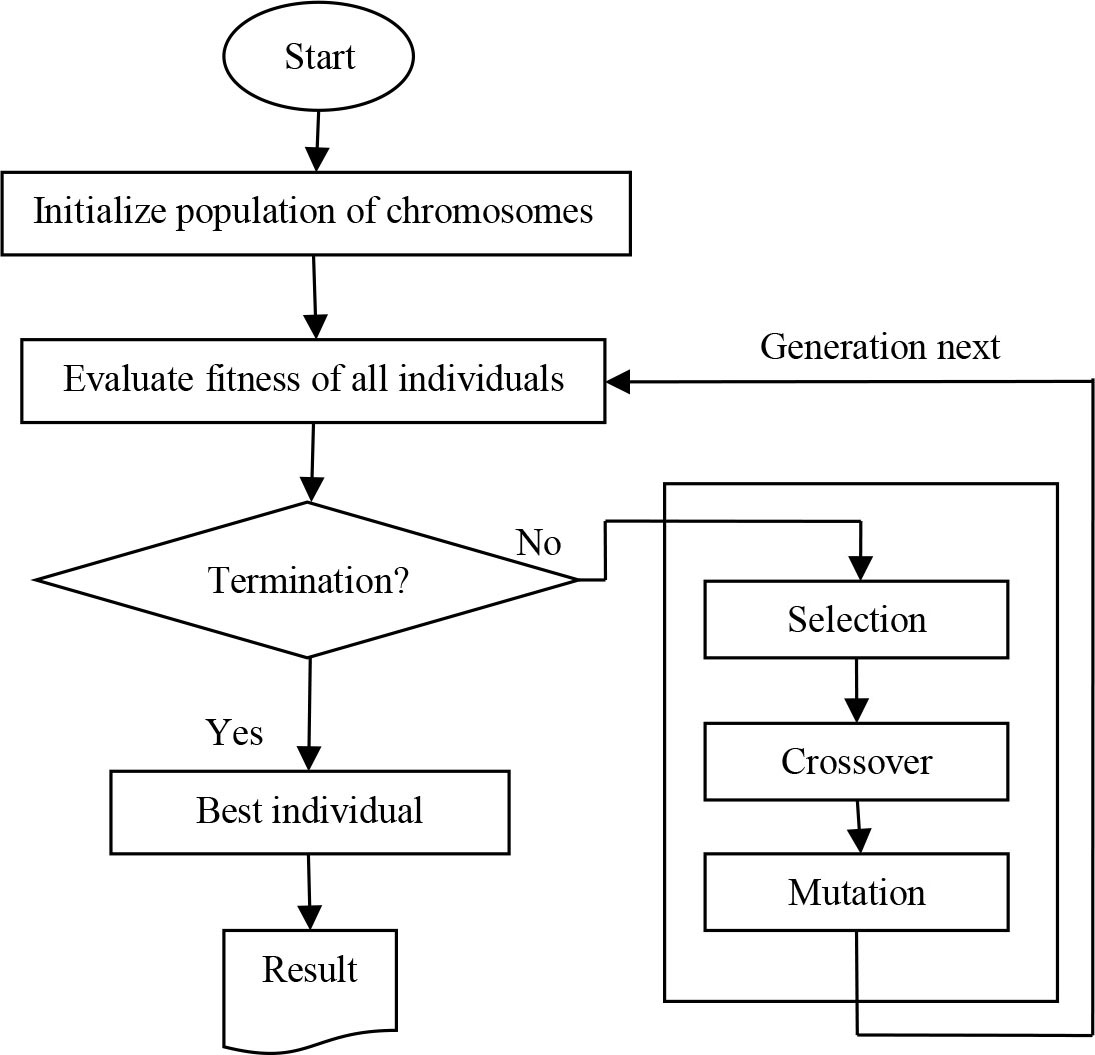
Initially, many individual solutions (chromosomes) are generated randomly to form an initial population. Individual solutions are selected using Roulette Wheel method through a fitness-based process, where fitter solutions (as measured by a fitness function) are typically more likely to be selected. The fitness value of the individual is the best accuracy. Next, a population of second-generation solutions is generated from the solutions selected through genetic operators: crossover and mutation. By producing a “child” solution using the above methods of One-point crossover and Generational replacement (mutation), a new solution is created which typically shares many of the characteristics of its “parents". New parents are selected for each new child, and the process continues until a new population of solutions of appropriate size is generated.
An overview of the proposed method.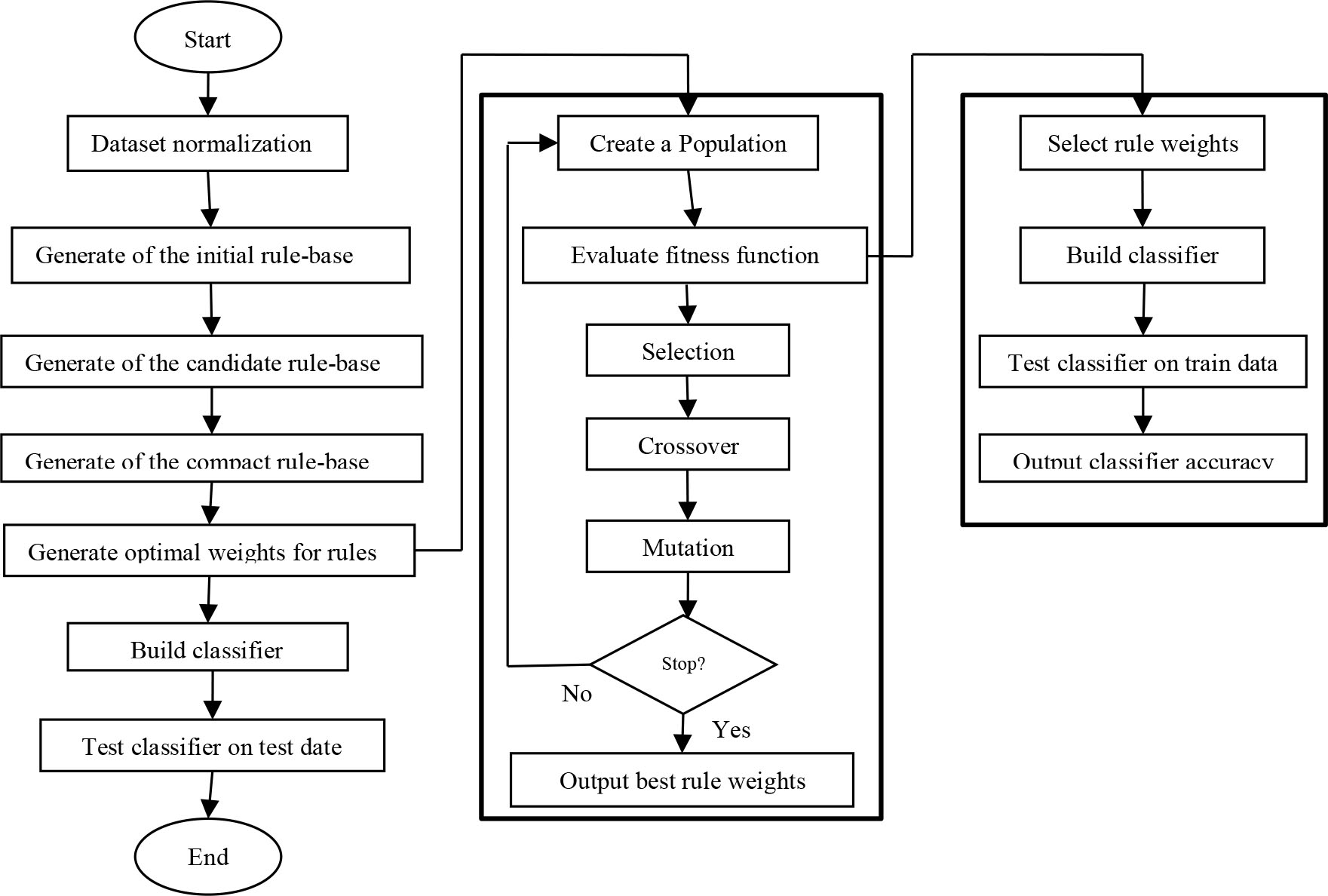
Initially, each feature of the data set is normalized. The normalization formula given in Eq. (8) is applied in order to set attribute numerical values in the range [0.0, 1.0].
where
To evaluate the performance of the proposed method, a series of experiments on a subset of the KDD CUP 1999 dataset are conducted. In these experiments, the proposed method is implemented and is evaluated and is made comparisons in order to validate the performance analysis of the proposed algorithm.
Dataset
In this section, the experimental dataset KDD99 [30] is discussed for intrusion detection. This data set prepared and managed by MIT Lincoln Labs. The dataset has 41 different attributes (32 continuous attributes and 9 discrete attributes) and 1 attack type label. The dataset contains about five million connection records as training data and about two million connection records as test data. Each data point represents either an attack or a normal connection. There are four categories of attacks, namely Denial of Service (DoS): making some computing or memory resources too busy to accept legitimate users access these resources, Probe (PRB): host and port scans to gather information or find known vulnerabilities, Remote to Local (R2L): unauthorized access from a remote machine in order to exploit machine’s vulnerabilities and User to Root (U2R): unauthorized access to local super user (root) privileges using system’s susceptibility [15].
In order to implement the proposed method, a subset of this large dataset is used as train and test datasets; hence 10,000 generated samples are selected randomly. Table 1 presents the distribution of classes in the dataset.
Results
In experiments, each item is described by 41 features which form a vector and normalized the train and test data sets, where each numerical value in the data set is normalized between 0 and 1. To construct a compact rule-base, 40 rules
Distribution of different classes in dataset
Distribution of different classes in dataset
Parameters setting for the genetic algorithm
Detection rate and False alarm rate obtained with different techniques
Comparison between detection rate obtained by different techniques.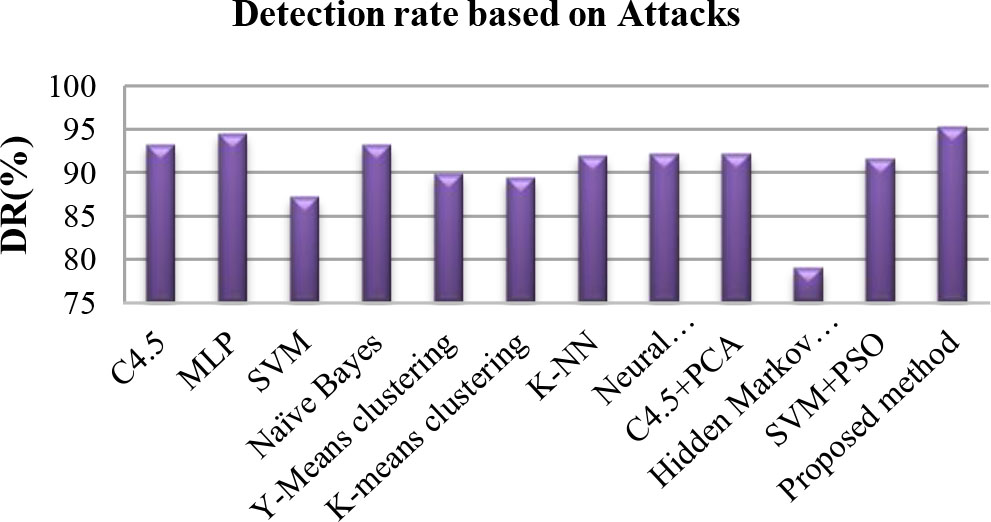
Comparison between false alarm rate obtained by different techniques.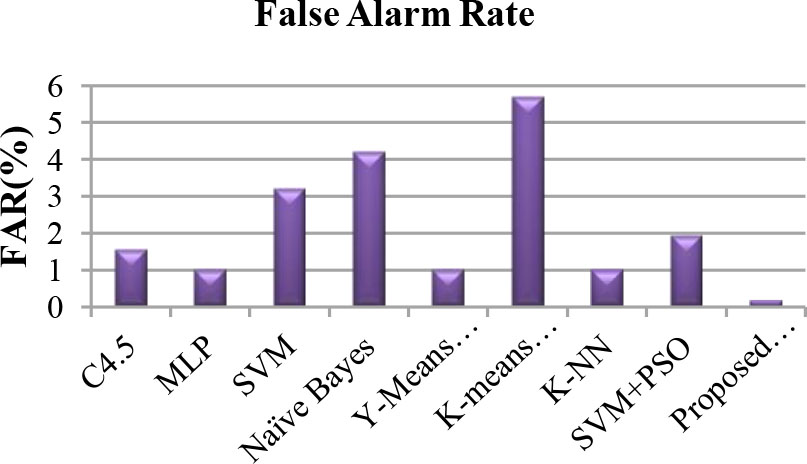
In this paper, a fuzzy rule-base classification system is used to find a compact set of fuzzy if-then classification rules. Then, a new method is proposed for rule weights specification witch this method is based on genetic algorithm. It is desirable for anomaly rule-based IDS to achieve high classification accuracy, the proposed method is an accurate and interpretable fuzzy system for intrusion detection. Moreover, KDD99 data set is used for conducting the experiments. Performance analysis is measured by using DR and FAR which are two important criteria for security systems. The simulation experiments compared with other algorithms prove that the proposed method obtains higher detection rate and lower FAR. We must be mentioned that no method is able to achieve the best performance on all criteria. Thus, it is necessary to use more than one performance measure to evaluate performance of intrusion detection systems. Our future work will focus on introducing a feature selection technique on intrusion detection dataset for identifying the most suitable feature subsets which may provide better results in the shortest time.