
Abstract
Feature selection is a crucial stage in the design of a computer-aided classification system for breast cancer diagnosis. The main objective of the proposed research design is to discover the use of multi-objective particle swarm optimization (MOPSO) and Nondominated sorting genetic algorithm-III (NSGA-III) for feature selection in digital mammography. The Pareto-optimal fronts generated by MOPSO and NSGA-III for two conflicting objective functions are used to select optimal features. An artificial neural network (ANN) is used to compute the fitness of objective functions. The importance of features selected by MOPSO and NSGA-III are assessed using artificial neural networks. The experimental results show that MOPSO based optimization is superior to NSGA-III. MOPSO achieves high accuracy with a 55% feature reduction. MOPSO based feature selection and classification deliver an efficiency of 97.54% with 98.22% sensitivity, 96.82% specificity, 0.9508 Cohen’s kappa coefficient, and area under curve
Keywords
Introduction
Breast cancer is one of the leading causes of death in women’s all over the world. At Present, no one has discovered any technique for the avoidance of breast disease, so recognition of malignant growth in its initial stage is significant. Mammography is perhaps the best tool available for the discovery of breast malignancy in its primary stage. The radiologist analyses breast malignant growth by examining mammograms, although studying of mammograms is a difficult task. So a tissue is removed for clinical assessment utilizing a biopsy method for testing the presence or absence of cancer. The available statistics show that 10%–30% of cancerous/noncancerous lesions misinterpreted by the radiologist [1]. The problem of misinterpretation could be minimized with the use of computer-aided diagnosis (CADx) systems. These systems act as a second pursuer for the radiologist to improve the diagnosis and minimize the death rate. The design and development of such a classification system require relevant features for the training. These features are obtained from mammograms. The Features extracted from mammograms can be irrelevant or exceptionally correlated with each other, so feature selection methods are used to obtain relevant features with high discriminatory power [2, 3]. The studies show that the predictive ability of the classification system highly depends on feature selection. So, to improve the predictive power of the classifier the proposed methodology uses Multi-objective particle swarm optimization (MOPSO) and Nondominated sorting genetic algorithm-III (NSGA-III) for feature selection. An ANN is used as a classifier to classify the masses.
The remainder of the paper composed of: a review of related work is presented in Section 2. The proposed research methodology in Section 3. Results and discussions presented in Section 4, comparative analysis of proposed work in Section 5, and the conclusion of work in Section 6.
Related work
In recent years multi-objective approaches are extensively studied for feature selection and classification of various medical datasets. A brief overview of these techniques used in some recent applications presented below.
Habib et al. [4] proposed a Multi-objective particle swarm optimization (MOPSO) technique for feature selection. The methodology was tested on several medical datasets. The results show that MOPSO is better than both Multi-objective Nondominated sorting algorithm-II (NSGA-II) and Multi-objective evolutionary algorithm based on decomposition (MOEA/D). A survey on recently proposed machine learning algorithms for data processing, classification, clustering, and association rules are presented in Alexandropoulos et al. [5]. The hybrid optimization method for feature selection based on Salp swarm (SA) with particle swarm optimization (PSO) is presented in Ibrahim et al. [6]. The performance of the method tested over two experimental series. In the first, it is compared with similar approaches using benchmarking functions, and in the second-best set of features are evaluated using different UCI databases.
Manohar et al. [7] proposed a binary PSO based feature selection method with a fuzzy support vector machine (FSVM) for the diagnosis of schizophrenia disorder in MR brain images. The proposed method assessed on the database of the National Alliance for Medical Image Computing (NAMIC). The authors prove that BPSO-FSVM is superior to BPSO-SVM.
Agarwalla et al. [8] present a feature selection method for the cancer database. The authors use Multi-objective MOBPSO with a blended Laplacian operator to avoid the problem of local trapping. Results show that the proposed methodology selects relevant features (genes) that are useful for the classification of cancer.
Amoozegar et al. [9] proposed a feature selection method. It uses Multi-objective PSO with feature elitism. In this method features in the archive set are first ranked based on their frequencies. Then these feature ranks are used to guide the particles and refine the archive set. Zhang et al. [10] proposed a multi-objective particle swarm optimization method for cost-based feature selection in classification. An objective of the proposed method is to generate Pareto front of Nondominated solutions. The searching capability of the proposed method is improved by incorporating probability-based encoding, hybrid operator, and external archive along with crowding distance and Pareto domination relationship to PSO.
Taghanaki et al. [11] proposed a Pareto-optimal Multi-objective dimensionality reduction deep auto-encoder for mammography classification. The results of the proposed methodology show that Pareto optimal Multi-objective optimization generates more discriminative features that will improve classifier performance than traditional auto-encoders.
Dioşan et al. [12] proposed a multi-objective approach for breast cancer classification using multi-expression programming. The proposed method uses image features like a histogram of oriented gradients and kernel descriptors for breast cancer classification.
Xue et al. [13] proposed a Multi-objective PSO approach for feature selection. The proposed method investigates two Multi-objective PSO methods; first based on Nondominated sorting and second based on the idea of crowding, mutation, and dominance. These methods compared with two conventional feature selection methods and three evolutionary multi-objective algorithms on 12 benchmark datasets. Results show that the second method is superior to all the algorithms.
Hamdan et al. [14] proposed a feature selection method based on Nondominated sorting genetic algorithm-II (NSGA-II). The technique uses two objective functions, the number of features and classification error for finding feature sets. The method is tested on five UCI databases.
Annavarapu et al. [15] proposed a MOBPSO based method feature selection in cancer microarray data. The scheme uses two objective functions cardinality of feature subsets and unique features of those selected subsets. The proposed methodology tested on benchmark gene expression datasets.
Proposed methodology.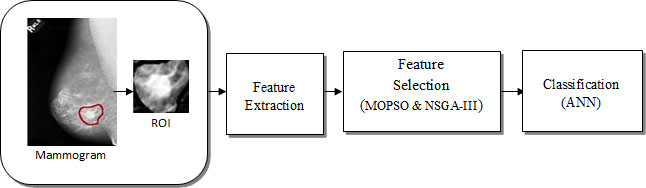
Zhu et al. [16] proposed a multi-objective scheme using NSGAIII for feature selection in the intrusion detection system. The author further suggested an improved NSGAIII (I-NSGAIII) scheme based on niche preservation procedures. Results show that the I-NSGAIII achieves both higher classification accuracy and minimal computational complexity. Sohrabi and Tajik [17] proposed a Multi-objective feature selection scheme for warfarin dose prediction. The method uses NSGAII and MOPSO with an artificial neural network (ANN). Results show that MOPSO is better than NSGAII. Jain and Deb [18] proposed a multi-objective scheme to solve constrained problems. The author extended NSGA-III and MOEA/D to solve generic constrained multi-objective problems. In earlier work author used these algorithms to solve unconstrained (with box limited alone) problems [19]. Outcomes of constrained NSGA-III and constrained MOEA/D show an edge of the previous especially in tackling issues having countless objectives.
Raj et al. [20] presented a Deep Learning model for feature selection and classification of medical images. The proposed technique is applied for the classification of lung cancer, brain image, and Alzheimer’s disease. An Opposition-based Crow Search (OCS) algorithm was used to reduce the feature space.
Gupta and Ahlawat [21] proposed a modified Binary Bat algorithm for feature selection. The performance of the proposed algorithm is compared with the original Binary Bat algorithm. The authors claim that the modified binary Bat algorithm is better than the original Binary Bat algorithm.
Arora et al. [22] proposed an ensemble-based method for feature selection. The method is evaluated using ten publicly available datasets and compared its performance with Decision Tree, Logistic Regression, K-nearest neighbours (KNN), and Random Forest classifiers.
Gupta et al. [23] presented a modified crow search algorithm for selecting the relevant features that are useful for the development of any software. The authors conclude that the proposed algorithm is better than existing algorithms.
Dash and Misra [24] proposed a Pareto differential evaluation technique for feature selection and classification in microarray data. Optimal features are selected with the use of a wrapper based differential evaluation technique. The significance of features selected is tested with the use of ANN, naïve Bayesian, SVM, and KNN classifiers. In recent years [25, 26, 27, 28, 29, 30] proposed methods for feature selection and classification in medical datasets.
When reviving the literature, we found that researchers implemented NSGA-III for solving problems other than digital mammography, and very few applied MOPSO for mammography. The promising findings of MOPSO and NSGA-III in other fields inspire us to use these algorithms to solve the mammography problem.
The proposed research methodology comprises two main stages. In the first stage, we utilized MOPSO and NSGA-III as feature selection algorithms. In the second stage, features were chosen by MOPSO, and NSGA-III is used to characterize suspicious lesion into benign and malignant using ANN. A review of the proposed procedure is as presented in Fig. 1.
Feature selection
In the proposed methodology, mammogram images first segmented using morphological and watershed transformations to obtain the region of interest (ROI). Each ROI represents a segmented mass. Then 25 features based on intensity (six), texture (eleven), and shape (eight) are obtained from each ROI. The six (F1–F6) intensity-based features are average gray level, average contrast, smoothness, skewness, uniformity, and entropy1. The eleven texture-based features obtained from the gray-level co-occurrence matrix are: Energy, entropy2, contrast, mean, std. deviation, variance, correlation, homogeneity, sum average, sum variance and sum entropy. Similarly, the eight shape-based features obtained from the shape of ROI are: area, perimeter, compactness, normalized std. deviation, area ratio, contour roughness, normalized residual value, and the overlapping ratio [31].
Feature selection is an essential step of any classification system that eliminates irrelevant, redundant, or noisy features. A feature set with a large number of an immaterial or unnecessary feature may degrade the prediction power of the classifier. That is why optimal feature selection is essential. It helps to minimize the computational overheads and improve the predictive power of the classifier [32, 33]. The detailed description of objective functions and feature selection using two methods namely MOPSO and NSGA-III presented in the following sections.
Multi-objective functions
Problems that involve two or more contradictory objectives are called multi-objective optimization problems. These problems have many solutions, called Pareto-optimal solutions. These Pareto-optimal solutions are Nondominated solutions. The multi-objective problem be formulated as-
Suppose, decision variables are represented by a vector
As discussed above, the objective of feature selection is to reduce the dimensionality of feature space that will increase the predictive power of classifiers as compared to the use of all features. In the proposed methodology, two conflicting objectives, Ratio of Features selected (RF) and classifier performance (MSE), are used. Both the objective function should be minimized. An ANN is utilizing to compute the fitness of objective functions.
The first objective function RF computed as shown in Eq. (1) below-
where NF is the number of features selected by the classification algorithm, and S is the total number of features.
The second objective function, Mean Squared Error (MSE) is defined in Eq. (2) as shown below-
where
Particle swarm optimization (PSO) is a widely used bio-inspired algorithm developed by Eberhart and Kennedy in 1995 [34]. It is an optimization technique based on the social behavior of birds flock. In this method, each possible solution to the problem is represented as a particle moving in the search space, and the location of the particle represents the optimal solution. During each iteration of the algorithm, the adaptable velocity vector used to modify the populations of each particle as well as to favor the best-performing individual.
The MOPSO algorithm proposed by Coello and Lechunga [35], based on the idea of the repository. The particles use the pool to deposit their flight experience, after each generation in the repository. The repository is used by the particle to identify a leader who will guide the search. The fundamental objective of MOPSO is to solve multi-objective problems where the goal is to select Pareto optimal solutions. The PSO and MOPSO update particle velocity and position in the same way. The velocity and location of the
In the above equations, the velocity of the particle represented by ‘
MOPSO Algorithm
Load dataset# It consists of 651 samples.
Initialize MOPSO parameters # number of generations # population size # number of decision variables # local and global learning paramters # Repository size # Mutation parameter
Define objective functions:
Create initial population (
Compute the fitness of initial population for two objective functions
Determine personal best and domination from initial population
Forfordoend loop # iteration
iteration
Forfordoend loop # K
Select the leader from repository
Update velocity of
Update the position of the particle with the use of Eq. (2)
Maintain the particles within the search space
Evaluate the fitness of particles in the population
Updated the Personal_best Pareto dominance
Update the repository with all nondominated solutions
Remove any dominated member from the repository
Generate the Pareto optimal front
Select the optimal features
NSGA-III Algorithm
Load dataset #It consist of 651 samples.
Initialize NSGA-III parameters # Number of generation # Population size # Crossover probability # Mutation parameter
Define objective functions:
Create the initial population (
Compute the fitness of initial population using two objective functions
Sort and select the population using nondominated sorting with reference point
Forfordoend loop # iteration
iteration
Perform mutation operation and evaluate the fitness of the generated population.
Merge the current population with the population generated by crossover and mutation
Sort and select the population using nondominated sorting with a reference point
Generate the Pareto optimal front
Select the optimal features
The multi-objective NSGA-III is proposed by Deb and Jain in 2013 [36]. The basic structure of NSGA-III is analogous to the original NSGA-II [37] with a substantial change in the selection operator. In NSGA-III, the following approaches are used instead of crowding distance operators.
NSGA-III uses the same domination princple [38] as used by NSGA-II for the identification of nondominated fronts. The Multi-objective NSGA-III ensures diversity in selected solutions with the use of predefined reference points. These reference points are widely distributed over normalized hyperplane; also, the selected solutions are widely distributed on or near the Pareto optimal front. In NSGA-III each population member is adaptively normalized. Once the population is normalized, each member of the population is associated with a referencing point. NSGA-III uses a method to protect the niches. The niche preservation strategy aims to identify one entity with one reference point. After this process, the new population is generated by performing crossover and mutation operations. The Multi-objective NSGA-III for feature selection is presented in Algorithm 3.1.2.
The proposed methodology uses an artificial neural network for the classification of mammograms. The artificial neural net based on the neural structure of the brain. It consists of highly interconnected nodes called neurons with an ability to learn and adopt. This helps the network to address a large number of problems. In general, supervised and unsupervised training methods utilized for training the system.
In this article, a Multilayer Perceptron (MLP) is used for the classification of breast lesions into benign and malignant. MLP is also called as feed-forward neural network because in this network, data flows only in the forward direction. It generally consists of three layers: input, hidden and output [39]. The neuron at each layer is connected to every other neuron at the next layer via a weighted link. The network trained using a pair of input-output samples. The training of the system halted when the MSE values quit diminishing and when there is an increase in the MSE values, which means that over-training [40, 41]. Once the ANN trained, its performance evaluated with the help of unseen data.
Pareto-optimal fronts of MOPSO and NSGA-III.
A total of 651 (337 malignant and 314 benign) mammogram images are collected from the digital database for screening mammography (DDSM) and employ to determine the efficiency of the suggested methods [42, 43].
Performance evaluation of mopso and NSGA-III
As examined in Sections 3.1.2 and 3.1.3, MOPSO, and NSGA-III are used to choose the best features from a set of 25 features extracted from each segmented ROI. The parameter’s value used by the selection algorithms is as shown in Table 1.
MOPSO and NSGA-III parameters
MOPSO and NSGA-III parameters
The Selection of optimal features by both MOPSO and NSGA-III depends on the minimization of two objective functions; the ratio of features selected (RF), and the mean squared error (MSE). The Pareto optimal fronts generated by MOPSO and NSGA-III for the iterations; 25, 30, 40, 50 and 100 are as shown in Fig. 2.
The subset of optimal features selected by MOPSO from Pareto-optimal fronts based on two objective functions shown in Table 2. One can observe from Table 2; MOPSO selects five feature sets (F1 to F5). The feature set F1 appear to be best with 11 features. These features are selected based on two objective values MSE and RF as 0.154183 and 0.44. Similarly, the subset of features selected by NSGA-III from Pareto-optimal fronts based on two objective functions shown in Table 3. From Table 3; one can see that NSGA-III select five feature sets (F1 to F5). The feature set F1 appear to be best with 12 features. These features are selected based on two objective values MSE and RF as 0.149308 and 0.48.
Features selected by MOPSO method
Features selected by NSGA-III method
The accuracy of features selected by both MOPSO and NSGA-III algorithms is shown in Fig. 3. From Fig. 3 we can observe that the features selected by MOPSO achieve a classification accuracy of 97.54% for feature set-1, 96.46% for feature set-2, 96.13% for feature set-3, 96.15% for feature set-4 and 96.77% for the feature set-5 respectively. Similarly, features selected by NSGA-III achieve a classification accuracy of 97.08% for feature set-1, 96% for feature set-2, 96.31% for feature set-3, 96% for feature set-4 and 95.85% for the feature set -5 respectively.
From, the above discussion we can observe that, feature set F1 appear to be the best-performing feature set for both MOPSO and NSGA-III. It accomplishes the most exceptional classification accuracy (or minimum error) while keeping the most modest number of features. Although feature set F1 of MOPSO appear to be best when compared with feature set F1 of NSGA-III. The feature set F1 selected by MOPSO removes 55% of irrelevant features. It reduces the dimensionality of original feature set from 25 features to 11 features. The features of F1 selected by MOPSO and NSGA-III that contribute to achieving high performance is as shown in Tables 4 and 5 respectively.
Features of MOPSO-F1
Features of NSGA-III-F1
Accuracy of features selected by MOPSO and NSGA-III.
Frequency of features selected.
The frequency of features selected by MOPSO and NSGA-III for all iterations is as shown in Fig. 4. One can observe from Fig. 4, 6
The importance and relevance of features selected by MOPSO and NSGA-III is evaluated using the ANN classifier, discussed in the following section.
The performance of the classifier is evaluated using some statistical parameters, as shown in Eqs (5) to (11) below:
where,
The feature sets, MOPSO-F1 and NSGA-F1, are utilized for training and testing of artificial neural network classifiers. An input data consist of 651 samples, partitioned as 70% samples utilize to train the network and the remaining 30% utilize to test the network. The proposed feed-forward neural network comprises three layers namely input layers, hidden layer, and output layers. The number of nodes at input layers varies with input data (feature variables). The proposed method uses ten hidden nodes and two output nodes (for the benign and malignant category). The Bayesian regularization strategy that updates the weight and bias values, as indicated by the Levenberg-Marquardt technique, is used to train the ANN. The network trained for 1000 epochs. The performance of the ANN evaluated against various statistical parameters is as shown in Fig. 5.
Performance of ANN.
One can see from Fig. 5, for a whole dataset containing 25 features, ANN achieves an accuracy of 92.31% with 93.47% sensitivity and 91.08% specificity, and for MOPSO feature set, ANN accomplishes the highest accuracy of 97.54% with 97.92% sensitivity and 96.18% specificity. For NSGA-III feature set, ANN achieves an accuracy of 96.18% with 97.92% sensitivity and 96.18% specificity.
The comparative analysis of type-I and type-II errors is as shown in Fig. 6. From Fig. 6, one can see that the type-I error (FPR) or false alarm for the entire dataset, MOPSO and NSGA-III is 8.91%, 3.18%, and 3.82% respectively while type-II error (FNR) for the entire dataset, MOPSO, and NSGA-III is 6.52%, 1.78%, and 2.07% respectively.
The area under the curve for MOPSO, NSGA-III and the entire dataset
Type-I and Type-II error.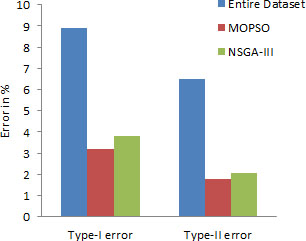
Comparison of F-Score and Cohen’s Kappa coefficient.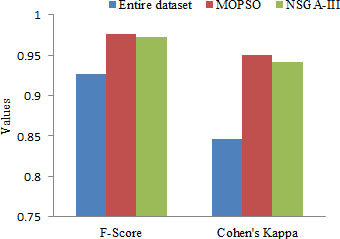
Comparison with performance reported in related work
So, as far as accuracy, sensitivity, specificity, type-I, and type-II errors are concerned MOPSO feature set is outperformed both the entire dataset and NSGA-III. MOPSO improves the efficiency of ANN by 5.23% over whole dataset.
To assess the model performance more rigorously the two important parameters; F-score and Cohen’s kappa coefficient are used. The results for both the parameters are as shown in Fig. 7. The parameter F-score is used to measure the test accuracy of the binary classification. It is the harmonic mean of precision and recall. From Fig. 7, one can observe that F-score for the entire dataset, MOPSO, and NSGA-III features are 0.9262, 0.9765, and 0.9720 respectively. Results produce by MOPSO is better than both the entire dataset and NSGA-III features.
One more vital parameter to evaluate the model performance is Cohen’s kappa coefficient [44] as shown in Fig. 7. It was adopted as a test of psychological behavioral consensus between the observers. Cohen’s Kappa first aim was to measure the degree of agreement or disagreement between at least two individuals that observed a similar phenomenon. It can take values from 0 to 1. If its value is
Comparison of ROC curves of the entire dataset, MOPSO and NSGA-III.
The receiver operating characteristics (ROC) curve used to determine the accurate accuracy of medical diagnostic tests. It is a plot between Sensitivity and 1-Specificity. The values of the curve lie in the range of ‘0’ and ‘1’. The predictive model is said to be 100% accurate if the area under the curve is equal to ‘1’ [45]. The area under the ROC curve is measured using high performing feature sets of MOPSO, NSGA-III and the entire dataset. The ROC curve for MOPSO, NSGAIII and the entire dataset is as shown in Fig. 8, and the area under the curve as shown in Table 6.
One can see from Table 6, an area under the ROC curve with 95% Confidence Interval (C.I.) for MOPSO, NSGA-III and the entire dataset is
Comparative analysis of proposed work
The results of the proposed MOPSO and NSGA-III techniques were compared with some related works, as appeared in Table 7. From Table 7, we can see that the proposed MOPSO and NSGA-III methods are superior to the techniques presented in similar work. The performance of given work is marginally lower than the method proposed by [11] when compared with accuracy. Even though the performance is slightly moderate, the methods provided in the article are better. The reason is that the technique presented by [11] evaluated using accuracy parameter while proposed methods are rigorously evaluated using accuracy, F-score, Cohen’s Kappa coefficient, and area under the ROC curve.
The complexity of both MOPSO and NSGA-III is
With this, we conclude that both MOPSO and NSGA-III give off an impression of being the best techniques, while the performance of MOPSO is marginally better than NSGA-III. The NSGA-III method is implemented first time for solving digital mammography problem. Both techniques presented in the article achieve high accuracy with minimum number of features. These methods help to improve breast cancer findings and reduce the death rate.
Conclusion
The proposed article investigates multi-objective techniques for feature selection and classification in digital mammography. The methodology uses multi-objective particle swarm optimization and Nondominated sorting genetic algorithm-III for feature selection. The optimal features are selected from Pareto-optimal fronts generated by MOPSO and NSGA-III for two conflicting objective functions; the number of selected features and the mean squared error. The chosen feature sets used to train and test artificial neural network classifiers. The significance of MOPSO and NSGA-III features are evaluated using statistical parameters; sensitivity, specificity, accuracy, F-score and Cohen’s kappa coefficient. The test results show that MOPSO outperforms NSGA-III strategy. The proposed system can assist in improving breast cancer diagnosis and reduce the death rate. Further, this work could be extended by implementing hybrid multi-objective techniques where the parameters of multi-objective techniques are tuned with the use of a basic evolutionary technique to achieve better performance.