
Abstract
In modern day Psychiatric analysis, Epileptic Seizures are considered as one of the most dreadful disorders of the human brain that drastically affects the neurological activity of the brain for a short duration of time. Thus, seizure detection before its actual occurrence is quintessential to ensure that the right kind of preventive treatment is given to the patient. The predictive analysis is carried out in the preictal state of the Epileptic Seizure that corresponds to the state that commences a couple of minutes before the onset of the seizure. In this paper, the average value of prediction time is restricted to 23.4 minutes for a total of 23 subjects. This paper intends to compare the accuracy of three different predictive models, namely – Logistic Regression, Decision Trees and XGBoost Classifier based on the study of Electroencephalogram (EEG) signals and determine which model has the highest rate of detection of Epileptic Seizure.
Keywords
Introduction
Neurological disorders have been on the rise in the past few decades at an alarming rate and affect millions of people worldwide every year. Neurological disorders are the diseases that are responsible for the breakdown of the human nervous system that includes the nerves, spinal cord and the brain. Alzheimer’s, epilepsy, migraine etc. are a few of the most prominent of the diseases. Among them, Epilepsy [1] is the neurological disorder that is the number two most prevailing in the world. As per the WHO, more than 50 million people all across the globe are affected by epilepsy and 6 million deaths per year are caused by stroke. Thus, it is clear that epileptic seizures are a major neurological health concern throughout the world. Although there is no cure that can treat epilepsy permanently, there are various methods through which health experts detect and diagnose epilepsy.
Epilepsy can be recognised by the sudden seizures [2] experienced by the patient without any warnings that leave the patient convulsing, cause muscle pain and spasms and lose consciousness. Epilepsy is most prominent in the elderly over the age of 65 but is also commonly seen in children who show autistic behaviour. It has also been found that people with certain genes are more susceptible to epilepsy, though finding relations between genes of brain and epilepsy is very complex and in fact, not possible at all for some forms of epilepsy. Another common cause of epilepsy is an infection in the brain. Curing such infections often results in the formation of scars inside the brain and makes the person more prone to epilepsy. Epilepsy can be categorised into four types based on the type of seizure one experiences. They are namely: Generalised epilepsy, Focal Epilepsy, Generalised and Focal epilepsy and Unknown Epilepsy. Generalised epilepsy affects a major portion of the brain’s electrical signals and often causes unconsciousness. Focal epilepsy is epilepsy that only affects a certain portion of the brain. The third category is where the patient has both of the epilepsies together. Unknown epilepsy is the type where it is known that the patient has seizures but the type of epilepsy cannot be determined.
Past studies about application of AI in detection of emotion, heart rate and Parkinson’s disease [3, 4, 5] have shown that no method exists which guarantees the hundred percent successful detection of any disease using machine learning technique as within every proposed method there may exists some form of errors. Hence, there exist wide variety of parameters and their combination which can be used for reliable seizure detection and therefore need for finding the most accurate models and selecting features which yield best results will be always there. Thus, this study aims to test the accuracy by training and testing sample dataset of 178 features of EEG signal, using same dataset to test and compare different machine learning models so as to find algorithms having highest AUC score and finally to test the how different learning method i.e., logistic regression, ensemble learning and tree-based method performs for these kinds of detections.
For this study, the predictive analysis of the dataset is done by deploying specific prediction models, that are studied under the domain of Machine Learning. Machine Learning has similar origins as to the field of AI and is used to make systems perform tasks that they are not exclusively programmed for. Machine learning has various applications in AI, designing of digital control systems and, as in this case, prediction and forecasting. The main contributions of authors are as follows.
The paper aims to devise a method to detect the occurrence of an epileptic seizure by training machine learning [6] algorithms using a sample dataset of 178 features of the EEG signals [7]. The Extreme gradient boost method is proposed for detection of epileptic seizure with improved accuracy. The results of the proposed technique have been compared with Logistic Regression and Decision trees for investigation of its effectiveness.
The paper has been organised in the following sections – Related work tells the research and experimental work that has been done until now. In this section, different methods have been used which are broadly classified into linear and non-linear techniques and the different number of features, channels, their combinations along with different processing and pre-processing procedures and different ML algorithms have been used for classification.
The dataset that is taken into consideration for carrying out the predictive analysis is taken from the UCI Machine Learning Repository. The data corresponds to multivariate time series data, comprising of a total of 178 features, that are observed over one categorical variable, for a total of 11,500 number of instances. In the dataset, every numerical value corresponds to a neurological pulsating voltage signal of different degrees that are recorded at different instantsof time. The dataset comprises of five different classes of data, depicted by classes – A, B, C, D, E, each class consisting of 100 single-channel EEG signalsegments, that are recorded for a total time duration of 23.4 seconds. For the classes A and B, different segments of EEG signals were recorded for a total of five neurologically healthy persons by deploying the scheme of placing the standard electrode. In the case of class A, it was ensured that people are in a conscious state ensuring that their eyes were opened, while in class B, the people were conscious making sure that their eyes were closed. For the classes C, D and E, the data is recorded in archived format by performing the presurgical diagnosis of the EEG signals. This data is recorded in the case of five different patients, who were subjected to complete control of the seizures and subsequent diagnosis of theirzone of epilepsy was performed. In the case of class C, the data was collected during the formation process of Hippocampal on the opposite hemisphere of the neurological brain, while the class D of data was recorded during the zone of Epilepsy [34].
It is to be noted that the data taken into consideration has been pre-processed and reorganised, in reference to the original dataset on the UCI online machine learning repository [35]. Each class of data – A, B, C, D and E are represented in digital format, in the form of 4097 different data points. These data points are furthermore divided into 23 different chunks of data whose distribution is performed along 178 time – feature readings of neurological voltage pulsating signals. Henceforth, creating 5 different classes of data for 100 individual EEG signal data segments leads to the creation of 11,500 instances of data. The distribution of data in chunks of 23 data elements refers to the fact that 23 different electrodes are deployed during the recording process of the EEG signals.
From this, we derive an attribute that represents the output in the form of different classes.
For these patients, the recording of the EEG signals was performed during the activity of seizures, corresponding to Ictal data. In this case, the data elements are recorded from the zone of Epilepsy of the patient’s brain and subsequently, tumours are identified. This class corresponds to the patients for whom, the data elements are recorded from the non-epileptic part or the healthy part of the brain in achieved formats and subsequent tumours are detected and located. It is used to represent healthy people who are acting as volunteers (data class – B), for whom, the EEG signal activity is recorded in perfectly normal conditions with their eyes closed. This class represents healthy people serving as a volunteer (data class – A), and for those, the activity of the EEG signals is recorded in a perfectly normal environment with their eyes open.
It should be noted that the data is recorded in a time-series or time-stamp format, corresponding to neurological pulsating voltage signals, depicted in the unit of microvolts. These signals are recorded at different time instances in correspondence to 178 different attributes. After performing meticulous exploration of the raw dataset, it was discovered that there were no missing elements in the dataset.
As discussed in the previous section, the onset of the epileptic seizures can be predicted a few minutes before the onset of seizures based on the Electroencephalography of the person concerned. This prediction is done by studying the neural activity of the brain with the help of recordings taken from Electroencephalography (EEG) combined with the Machine learning techniques.
Electroencephalography (EEG) is a monitoring method to study the electrophysiological activity of the brain. It records the electrical activity of the brain non-invasively by measuring the voltage fluctuations due to the flow of ionic current within the neural mesh. The voltage difference from the two sides of the brain is recorded over time and graphically displaced representing a proportional measure of activity. The EEG data is represented as a continuous-time series waveform representing the voltage fluctuations in microvolts. Though the recording is taken by placing small metal plates as electrodes on the surface of the brain, the waveforms recorded are influenced by neural activities going deep within the cortex [23].
The Electrodes are placed at specifically designated parts of the scalp and the recordings are measured with respect to the reference electrodes placed individually or preconfigured cap. With the invent of Analog to digital converter these analogue signals can now be recorded, displaced and processed for further evaluation. These digital machines give an edge over the conventional analogue machines as they are useful only for continuous pattern analysis, moreover, the waveform generated is displaced in the groups [24, 25].
The ionic potential across the neural membranes is responsible for normal neural activity. The potential across the diffusion membrane exist due to the efflux of potassium ion to establish the electrochemical equilibrium. This membrane potential resulting from the electrophysiological activity of the brain give rise to brain waves. These brain waves are recorded by the Electroencephalography (EEG) [22, 23]. The signal generated hasa sinusoidal waveform witha peak-to-peak voltage having a magnitude of 0.5 up to 100 microvolts in the healthy human brain. These waves are grouped into four categories viz. 1) Delta: 0.5 to 4 Hz, 2) Theta: 4 to 8 Hz, 3) Alfa: 8 to 13 Hz and 4) Beta: all greater than 13 Hz [20, 21].
EEG has a wide span in clinical application and Epilepsy being the most common one [21]. Interpretation of EEG is a highly complex process involving multi-disciplinary expertise and involves many decision-making steps [21]. It is due to the fact that a similar pattern may result due to different reasons or unrelated patterns may indicate the same reason. Irregular EEG pattern may or may not indicative of epileptic seizures.
EEG pattern in an epileptic seizer can be categorised into four stages viz. 1) The preictal state, the state which is a precursor to the onset of a seizure, 2) The ictal state, the second state that coincides with the onset of a seizure, 3) The postictal state, it is the state that comes after the ictal stateand 4) Interictal state, the state that starts after the end of postictal of first seizures and ends before the onset of the preictal state of second seizures.
Comparison of machine learning models for the prediction of epileptic seizures
Comparison of machine learning models for the prediction of epileptic seizures
The detection of the preictal state gives us sufficient time before the seizure occurs. It starts some moments before the onset of seizure [26]. For this purpose, many researchers have tried classification for differentiating the preictal and the ictal state, Pre-processing of EEG signal with an aim to increase SN ration and use the use of modern techniques like feature extraction plays a vital role in reliable prediction. Various researchers have tried to combine multiple features into a feature vector with an aim to improve the models.
In the recent literature we can find references to various seizure detection method that are broadly categorized into five linear domains such as frequency domain [36], time-domain [37], EMD – empirical mode decomposition [38], wavelet domain (time-frequency) [39], and rational transform domain [40] and other non-linear domains such as HOS – higher-order spectra [41], information theory and entropy [42], Lyapunov exponent [43], and intrinsic mode functions (IMF) [44] for detecting epileptic seizures through EEG signals analysis using Machine learning (ML) frameworks. Non-linear methods have shown higher potential in detecting epileptic seizures rather linear methods since EEG are known to have more non-linear feature.
Whereas other literature hadtried to use a different number of features, channels, different methods and different ML algorithms, such as spectral power features [26], wavelet method [27], univariate linear features extraction [28], expansion of features [29], zero-crossing technique [30].
It has been observed through the comparative study of different researches that, there is no reliable method for selection of channels and EEG signal processing. Table 1 shows a comparative view of various methods, machine learning models trained on the basis of different number of seizures, number of subjects, Number of features, EEG Channel, type of EEG data, false-positive rates, average sensitivity.
The Data is collected for processing through the method of EEG, or Electroencephalography [9]. EEG refers to the process of observing the electrical signals generated by human brain when millions of neurons fire up simultaneously at a particular part of the brain and in a similar rhythm or pattern. This electrical activity of the brain that has recognisable behavioural pattern is usually associated with certain body actions and thus can be processed to predict the response of the body in advance. Electroencephalography records these signals in the form of the amplitude of their voltage.
Normally, this electrical activity of the brain shows a similar pattern for most of the people and only differs in case of any abnormality in the body or brain. Hence detecting these unusual patterns in brain activity can help in identifying the various neurological disorders that a person may be afflicted with. The paper proposes a method of using the EEG as inputs to predicting the chances of a seizure at any given time by using machine learning, specifically, logistical regression, decision tree and extreme gradient boosting. The aim is to use these techniques to successfully predict the occurrence of a seizure and observe the accuracy of prediction to find the best possible technique of all the ones discussed here. The relevant theory regarding the working of the three techniques is discussed below.
The input signals received from the EEG are processed in the time domain [10] and then passed through the predictor model for analysis. It gives valuable information like features with the most impact on the occurrence of a seizure, the true and false positive rates and their area under the curve, etc. that are then used for feature selection and judging the accuracy of the models. The graphical representation of methodology is shown in Fig. 1.
Steps for detection of epileptic seizures.
One of the benefits of using the extreme gradient boost is that it has the important functionality of feature selection. What it does is that it allots a score to all the features that tell how important that feature is in ascertaining the output. The score is calculated by the amount of increase in performance due to the attribute split point for each decision tree and multiplied by the number of observations for that particular node. Then the average of this score is taken over all the decision trees.
The overall accuracy [11] of the prediction is judged by finding out the true and false positive rates and carrying out further calculations [12]. The true positive rate signifies the rate of the correct affirmative predictions that are made by the model whereas the false positive rate tells the rate of incorrect affirmative predictions made by the model.
Accuracy can then be found out using this data. Accuracy can be defined as ratio of correct observations to all the observations made by the model. In this case, as per definition:
This can be further divided based on the nature of the prediction whether it is affirmative or negative:
where
Positive feature importance score – XGBoost Classifier.
The value of accuracy always is less than 1, or equal to 1 in the case of 100% accuracy, which is practically highly unlikely and may be due to overfitting. Also, while useful, the accuracy alone does not give us the full picture of the performance of the prediction model. There might be the case when only one type of true value (either positive or negative) may have a good prediction but the other not so good. But accuracy alone won’t be able to detect this. Hence, we use multiple different approaches [9] to ensure the best results. One such method is finding the AUC (Area Under the Curve) and ROC (Receiver Operating Characteristics) respectively [14]. Positive feature importance score is presented for XGBoost model in Fig. 2.
ROC prediction curve.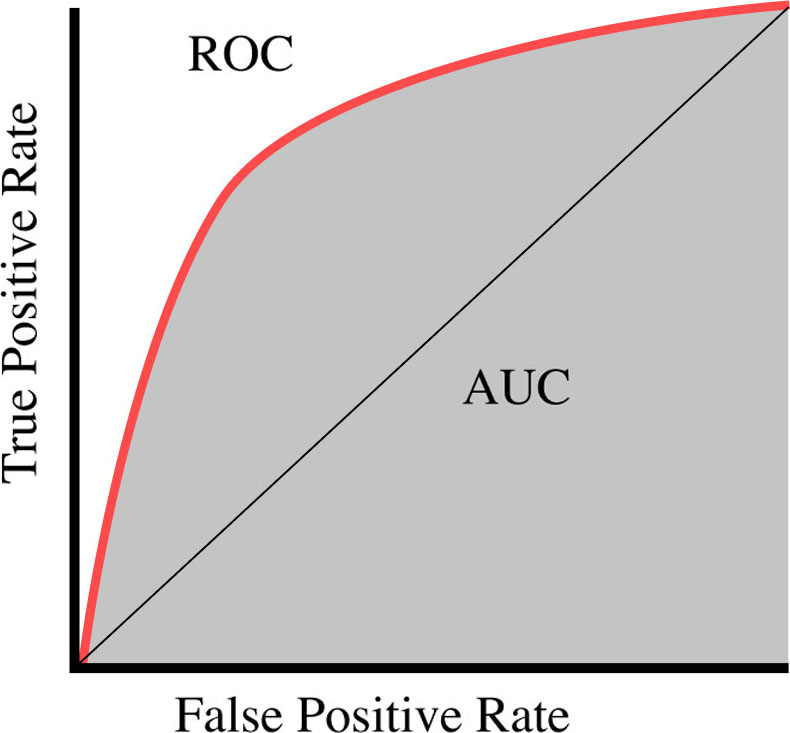
This AUC-ROC curve is used for analysing the performance of the classification techniques in various stages, represented for proposed work in Fig. 3. A higher value of AUC means that the model can differentiate between the different classes much more sharply. This is especially useful for binary classification problems.
Some defining features of the curve are:
The model which has AUC of 1 is considered to be an accurate one, whereas the model with AUC of 0.5 is considered the worst. Interestingly, the model that has AUC of 0 means that it is complementing the actual output, that is, the prediction is the opposite of the true value in all the cases.
Logistic regression [15] is a machine learning technique whose objective in our paper is to perform binary classification of data. Binary classification means dividing data into two classes. For example, for testing a patient to be diabetic or not we denote a patient being diabetic by 1 or 0 for not diabetic. Thus 2 classes are denoted here by 1 and 0. Now by using the logistic regression algorithm we are training our machine learning model and trying to classify data in either of the two classes as accurately as possible.
Logistic regression is similar to linear regression technique as they both are used to perform classification. The significant differences between the two lies in the way they both model the data. In Logistic regression, the data is modelled as binary values whereas in linear regression the data is modelled as a continuous numeric value. Another key difference is, in the case of linear regression there is a linear relationship between dependent and independent variables whereas there is no such dependency in logistic regression. Linear regression uses a straight line to classify data whereas logistic regression uses sigmoidal function [16] to do the classification.
Linear Regression
where,
Sigmoid Function
where,
Usually, Logistic regression performs better than linear regression in solving classification problems especially when there are outlier points in the dataset. These outlier points may affect the overall prediction accuracy of linear regression.
Figure 4 above is a sample of the logistic regression model [17].
Logistic regression model.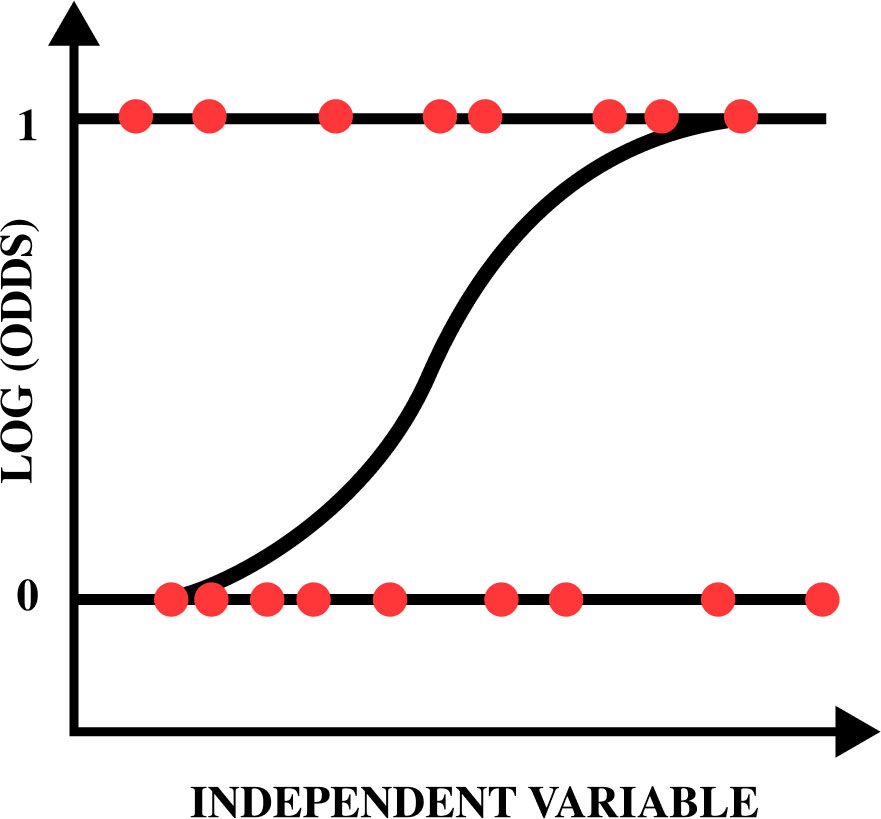
Calculate the weighted sum of inputs by using the equation below:
Here, This
where Now we need to find the probability of a person having a seizure which is given by substituting the value of the log of the odds in the sigmoidal function given below:
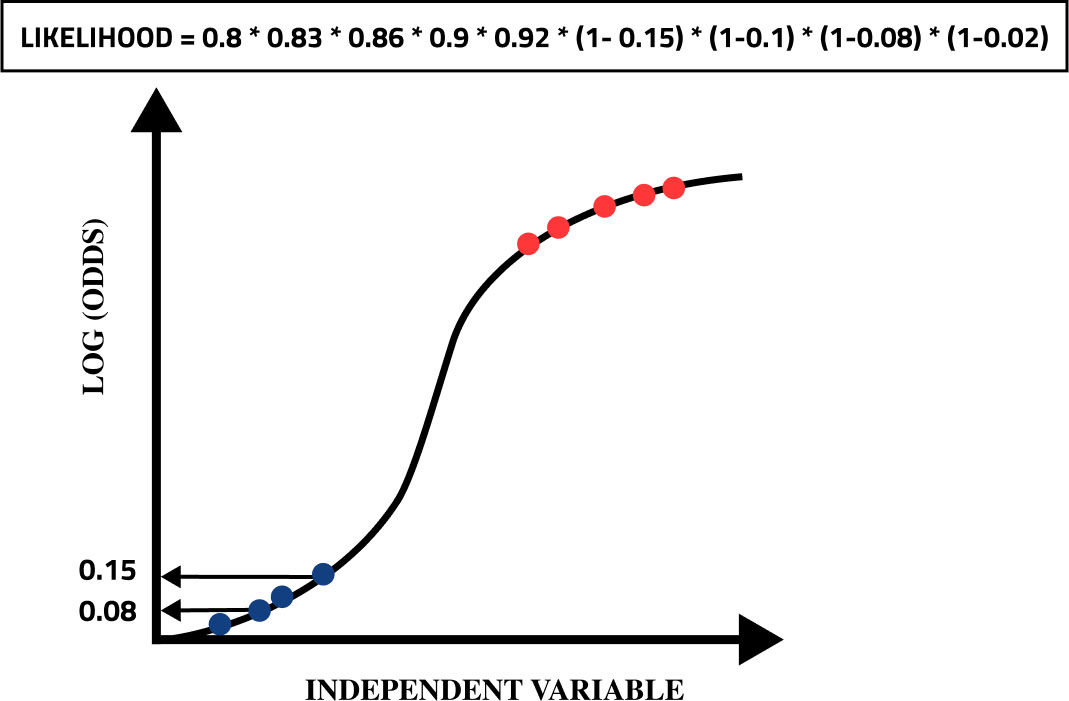
Now after finding the probabilities of a person having a seizure or not, we need to select a sigmoidal function that best fits our data. For this, we need to train our machine learning model using techniques like Gradient Descent, Maximum likelihood etc. In maximum likelihood technique, we include the chances of people who have a seizure and those who don’t have a seizure. The value of likelihood is found by the product of each value.
Denoting likelihoods of people.
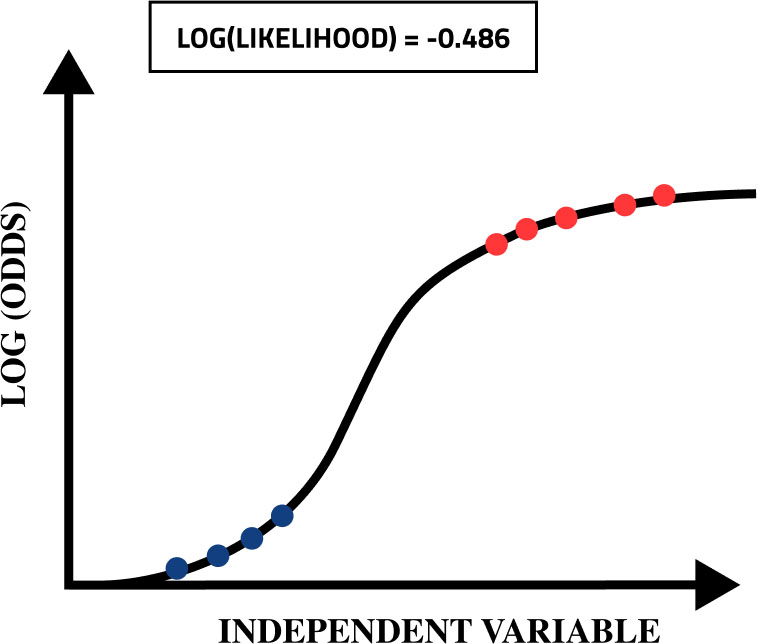
Value of likelihood for a particular line. On taking Log of the likelihood we end up with the following likelihood, presented in Figs 5 and 6. We will keep on repeating the entire process for different lines and find the value of likelihood for each line. The line which is providing the maximum value of likelihood is chosen. Upon training the logistic regression model using the maximum likelihood technique, we can check the accuracy of the model by calculating the errors after predicting the data of some people having epilepsy or not.
Decision Tree [36] is a modern classification algorithm implemented in the domain of Machine Learning and Data Science based on the Supervised Learning Algorithmic Model. This algorithm can be deployed to solve modern computational problems that involve predicting data trends with the help of advanced Regression and Classification techniques. The core structure depicting this algorithm resembles the structure of a tree comprising of different nodes. All these nodes in a Decision Tree are used to describe a statement pertaining to a certain condition. Interconnection of these nodes is made possible with the help of branches, which serve the purpose of depicting the results to the statements represented by the decision tree nodes. The execution of the algorithm commences from the topmost node, also known as the Root node, and finishes when the execution reaches the Bottom-most node, also known as the Leaf Node. Once all the attributes pertaining to the upper nodes are executed, the final decision made by the algorithm is represented by the Leaf Node. In this sense, the Leaf node is also called the Terminal Node. In comparison to conventional Machine Learning Algorithms, this technique is significantly preferable in terms of parameters like algorithmic accuracy and algorithmic stability and its interpretation in comparison to other techniques is far easier. Diagrammatical representation is given in Fig. 7.
Diagrammatic representation of a decision tree.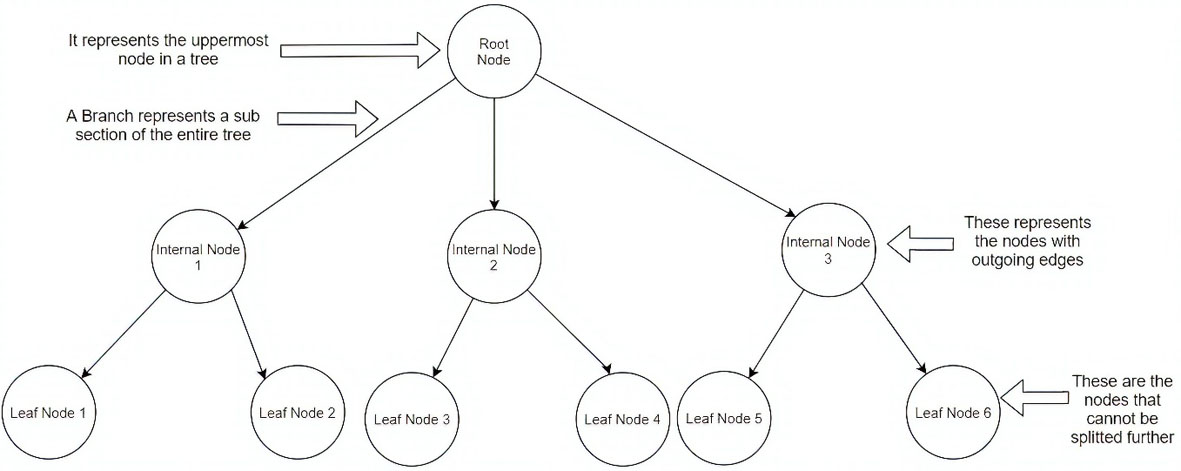
Steps involved in building a Decision Tree model [36] are as follows:
The first step of the building process involves a meticulous inspection of the dataset and based on that, deciding which elements of the dataset can be considered as the Root Node of the decision tree. The second step deals with dividing the dataset into different subsets to create subsequent datasets that are available for training and testing the algorithm. The third step involves validating that every single subset should depict homogenous values corresponding to every individual element. The last step of the building process involves the repeated execution of the aforementioned steps until the Terminal Nodes corresponding to all the branches of the decision tree is determined. Henceforth, the nodes at the terminal depicts the Predicted values.
Extreme Gradient boost also known as XGBoostis a highly efficient and scalable implementation ofthe gradient boosting package. The XGBoost offers better scalability and has the capability to perform parallel and distributed computing offering faster learning and model exploration. This newly introduced package offers various objective functions including Ranking, Classifier and Regression.
With its advantage of adjustable parameters, XGBoost can make predictions on the set of defined standard features and offers better results than other machine learning models. The package contains a linear model and tree learning algorithm [32].
XGBoost algorithm as an implementation of gradient boosted decision tree.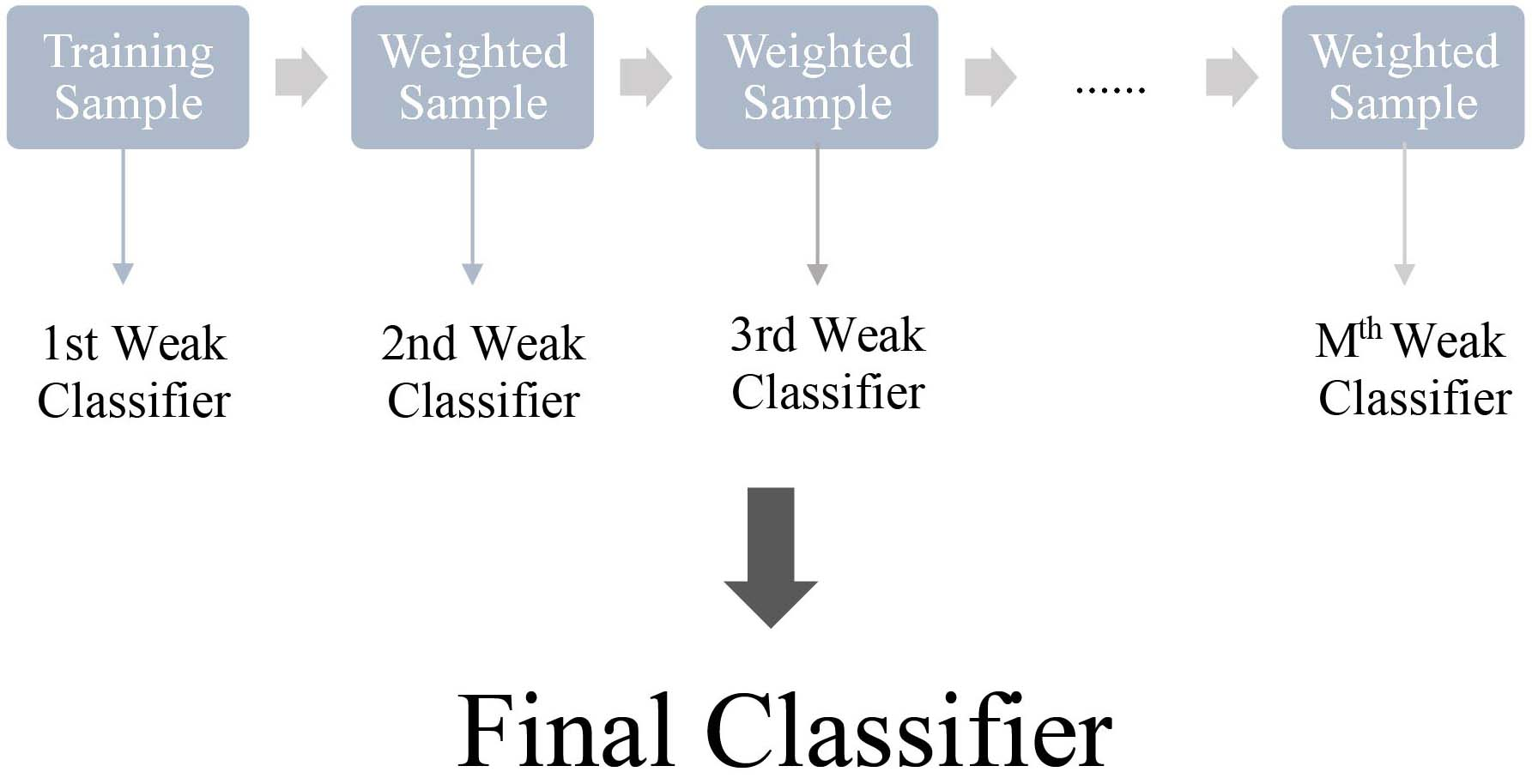
XGBoost is based ensemble learning method, which generates an ensemble model by the iterative cycle of predictions as presented in Fig. 8. In this model, a naive model is used to start the cycle as we need initial predictions. Even if these predictions are wildly inaccurate, subsequent cycles can address these errors. To make predictions, predictions from all the previous models are used to build a new model [33].
New predictions are based upon the model having previously added predictions. These predictions are then used to calculate errors, build into a model and added to the ensemble. These iterations are performed until the residuals from the previous model are reduced as much as possible. Figure 9 depicts the flow chart for XGBoost model.
Flow Chart representing XGBoost algorithm.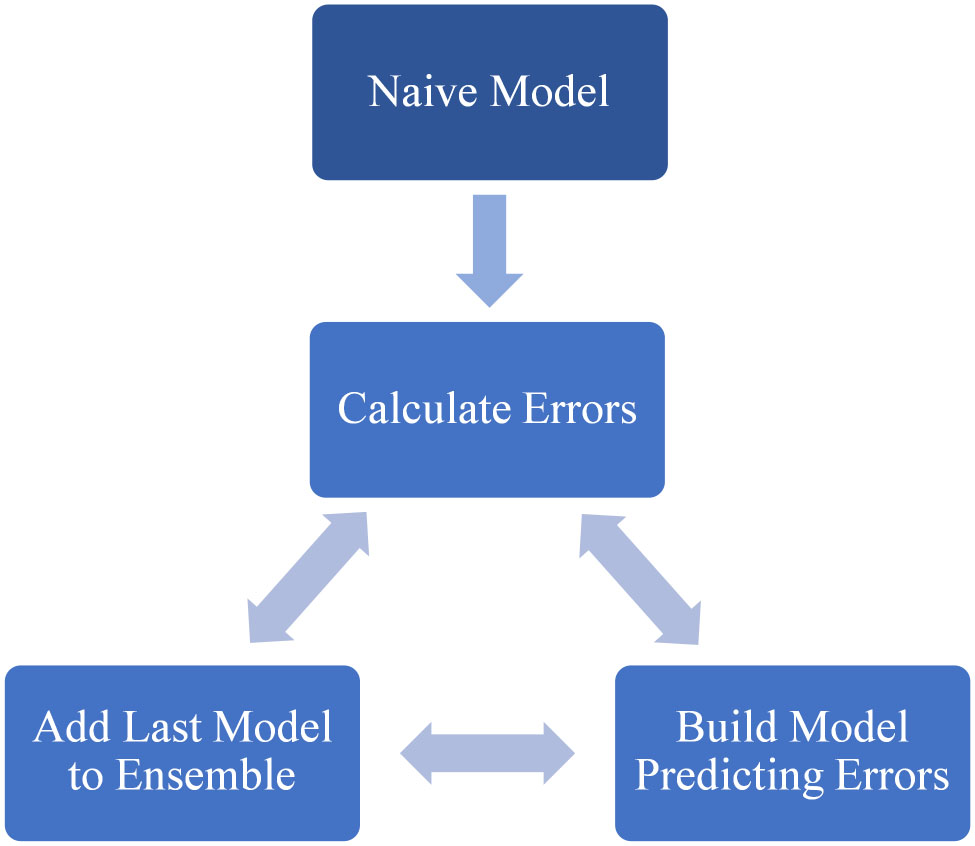
AUC Score comparison for 3 different classification techniques.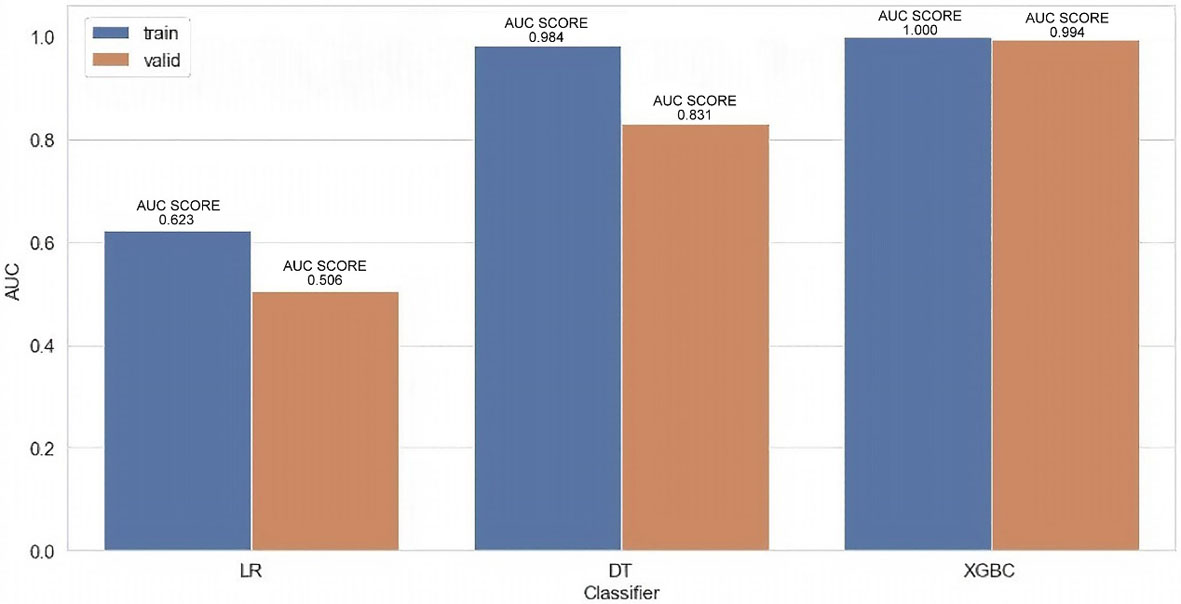
ROC Curve for XGBoost classification algorithm.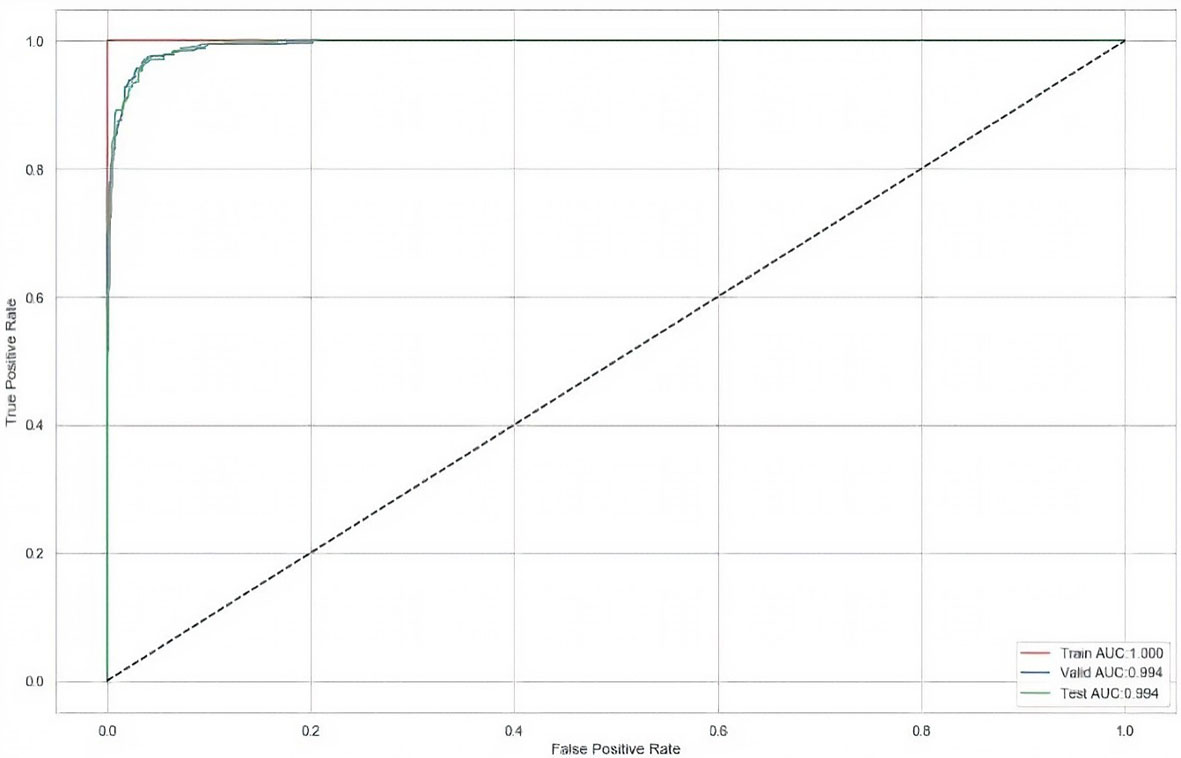
There are three stems in boosting using ensemble learning technique:
A target variable A new model Now,
The residuals of
We try to minimise the residual as much as possible by performing iterations up to
The functions created in previous models do not get disturbed by the additive learners. Instead, they impart information to bring down the errors.
Here,
The results of different binary classification algorithms are depicted with the help of AUC Scores for different classification techniques. AUC Scores are significant when it comes to the analysis of different classification techniques due to the fact that they represent the degree of separability of the algorithm. In other words, it tells the degree up to which the classification model is correctly able to distinguish between different classes.
The Fig. 10 represents the AUC score comparison for 3 different binary classification techniques, namely – Logistic Regression (as a classifier), Decision Tree classifier and XGBoost Classifier. For better analysis, the dataset is divided into 2 separate subsets of data – Training Data and Validation Data. For both these subsets of data, it is visible that the XGBoost Classification technique produces the highest value of the AUC score, thus depicting a higher degree of separability.
Table 2 shows a comparative view of AUC scores of the training data and validation data for Logistic Regression, Decision Tree classifier and XGBoost Classifier.
AUC score of the training and validation data for different machine learning models used
AUC score of the training and validation data for different machine learning models used
The ROC (Receiver Operating Characteristic) as shown in Fig. 11, Curve is plotted between two algorithmic parameters namely, the True Positive Rate and False Positive Rate for a specified classification technique. The area under this curve is calculated for determining the AUC Score of a classification algorithm. In the above figure, the ROC curve is plotted for the XGBoost Binary Classification Algorithm. The AUC scores obtained for the Training, Validation and Testing Datasets are 1.00, 0.994 and 0.994 respectively. From this information, we can infer that the XGBoost Classification algorithm is 99.4% correct in the prediction of the positive classes in the testing dataset.
This paper entails the accuracy of the predictive models namely XGBOOST, LR and DT for the detection of epileptic seizures based on the study of EEG signals. In the proposed work, XGBOOST model have been implemented to analyse the EEG readings and automatically classify the patient as having epilepsy or not. The results of XGBOOST have compared with LR and DT model for investigation of effectiveness of the proposed method. In the case of classification problems, we have compared the classification ability of different ML techniques using AUC score. Technique which is having more AUC score is said to have better classification ability. On comparing the AUC score of all the techniques, we concluded that XGBoost is the best technique to classify the given data with the AUC score 0.994. This study can be extended in future by using extra tree classifier, addition of more parameters and implementation latest machine learning techniques for improving the accuracy to detect epilepsy.