
Abstract
Today, with the development of internet technology, a new kind of social relations and interactions have been formed in the newly emerged social networks. Through social networks, the users can share different types of content, including personal information, text, image, video, music, poem, and other related information, which express their mental states, emotions, feelings, and thoughts. Thus, a new and essential aspect of human life is being formed in a virtual space in social networks, which must be explored from several viewpoints, such as mental disorders. Analyzing mental disorders according to the social network data can guide us to gain new approaches to improve the public health of the whole society. To this aim, developing mental health feature extraction (MHFE) methods in a social network is essential and is now becoming an active research area. Therefore, in this paper, a review of existing techniques and methods in MHFE is presented, and a comprehensive framework is provided to classify these approaches. Furthermore, to analyze and evaluate each approach in extraction methods, an appropriate set of functional criteria is proposed, which leads to a more accurate understanding and correct use of them.
Introduction
Mental health (MH) is the level of psychological well-being or an absence of mental illness. It is the state of someone who is “functioning at a satisfactory level of emotional and behavioral adjustment” From the perspective of positive psychology or holism, mental health may include an individual’s ability to enjoy life and create a balance between life activities and efforts to achieve psychological resilience [1].
Currently, monitoring symptoms of mental disorders such as depression is done by physicians in the office through self-assessment and interview-based methods. However, the shortage of mental health professionals and the limited resources available to physicians preclude close monitoring of symptoms, delay in optimal treatment, and consequently long-term suffering for patients. Inactive recording of behavioral data is recognized as a potential practical method for long-term monitoring of mental disorders. A combination of social network analysis and machine learning can provide an accurate and instantaneous measurement of the details of behavior and changes in mental disorders.
Social network analysis and especially the use of machine learning techniques can guide us to gain new approaches to improve the public health of the whole society by interventions that can be in the form of advertising, information links, online advice, or cognitive behavioral therapy. For example, Facebook intends to help users with suicidal risk in real-time [2].
A mental disorder is a set of disorders that are associated with a change in thinking, mood, or behavior in the form of distress or impairment in performance.Users with mental illness will disclose their symptoms on social networks or by membership in online forums, and they can be detected by monitoring user activities and discovering patterns in their online activities [3]. The process of exploring social networks is a subset of a large set of activities called Social Network Analysis (SNA), which, according to the structure and characteristics of this environment, is divided into two groups of general structural analysis and content analysis. The first group focuses on social networks from the links and structure point of view, and the second group focuses on the analysis of texts, images, and other possible content types [3, 4, 5].
Facebook, with about 1.7 billion active users per month, and Twitter, with about 310 million active accounts, are two of the largest social networks. Each of these social networks has produced massive data that can be used to explore significant patterns in user behavior [6]. Up to now, multiple measures have been considered to analyze social network user’s mental health, including activity, social capital, emotion, and linguistic style in participants’ Facebook data in prenatal and postnatal periods [7]. In addition to sufficient work being performed in mental health analysis in social networks, feature extraction is now becoming an active research area.
Mental health feature extraction (MHFE) is the process of finding the best features from a variety of existing features to analyze the mental health of individuals. This process is very important to guide us in a way to automate MH investigations and using artificial intelligence methods in this field. Furthermore, extending and improving existing MHFE methods causes better MH analysis. However, several mental health feature extraction techniques have been developed up to now but the lack of a survey will be felt for new researches. Hence, a new taxonomy might be urgent that leads to this paper. Besides, using each MHFE method requires appropriate criteria to understand its role in extraction methods’ functionality.
In this paper, a review of existing techniques and methods in MHFE is presented, and a comprehensive framework is provided to classify these approaches. Furthermore, to analyze and evaluate each approach in extraction methods, an appropriate functional criterion is proposed, which leads to a more accurate understanding and correct use of them. So the main contributions of this paper are based on two categories. First, a new taxonomy and classification of MHFE methods are presented. Second, proposing appropriate functional criteria to analyze and evaluate each approach.
The rest of the paper is as follows. In the second section, previous related works are provided. In the third section, the proposed MHFE framework is described. In the fourth section, the functional criteria for studying and analyzing the feature’s role are described. Finally, in the last part, the conclusion is presented and the future works are highlighted.
Related works
There are many activities in the field of feature extraction in social networks, and many researchers have presented review papers. For example, Chandrashekar and Sahin have presented a survey on feature extraction methods [8]. Molina et al. have also focused on the same topic but they also have presented an experimental evaluation of feature extraction methods [9]. Xue et al. have presented a survey on evolutionary computation methods to feature extraction [10]. Diaz-Chito et al. have presented an overview of incremental feature extraction methods based on linear subspaces [11]. Yıldız has focused on feature extraction in discrete space [12]. AlNuaimi et al. have presented a survey on streaming feature extraction algorithms for big data [13]. But to the best of our knowledge, there is no survey in the field of mental health feature extraction (MHFE) and the current paper is the first attempt to present an overall review of MHFE approaches.
However, intending to analyze mental health in the context of social networking and dealing with its challenges, some articles have attempted to provide a framework for improving efficiency by combining relevant resources. Wongkoblap et al. have presented a systematic review to determine the scope and limits of techniques that researchers have done to predict based on machine learning and review related issues [6]. Guntuku et al. have studied mental illness in the social network. Users with mental illness will disclose their symptoms on Twitter or by membership in online forums, and they can be detected by controlling users and discovering patterns in their language and online activities [3]. Choi et al. have presented important features for identifying the social support needs of users based on the knowledge gathered from survey data. This study also has provided guidelines for a technical framework that can be used to predict the social support needs of users based on raw data collected from online health social networks (OHSNs) [14]. Using Twitter posts, Choudhury et al. have quantified postpartum changes in 376 mothers along dimensions of social engagement, emotion, social network, and linguistic style [5]. Choudhury et al. have considered multiple measures including activity, social capital, emotion, and linguistic style in participants’ Facebook data in pre-and postnatal periods. This study includes detecting and predicting the onset of postpartum depression (PPD) [7]. Park et al. have focused on Facebook to discern any correlations between the platform’s features and users’ depressive symptoms [15]. Hu et al. have built both classification and regression models based on linguistic and behavioral features acquired from 10,102 social media users and showed that users’ depression could be predicted via social media [16]. Tsugawa et al. have extensively evaluated the effectiveness of using a user’s social media activities for estimating the degree of depression [17]. Liu and Zhu have utilized a deep learning algorithm to build a feature learning model for personality prediction, which could perform an unsupervised extraction of the Linguistic Representation Feature Vector (LRFV) activity without supervision from text actively published on the Sina microblog [18]. Pedersen has screened Twitter users for depression and PTSD with lexical decision lists [19]. Guan et al. have identified Chinese microblog users with high suicide probability using internet-based profiles and linguistic features [20]. Liu et al. have proposed to detect suicide risk on social media using a Chinese suicide dictionary [21]. Wu et al. have analyzed Facebook status updates to determine the extent to which users’ emotional expression predicted their SWB -specifically their self-reported satisfaction with life [22].
In conjunction with all the above studies, in the following sections of this paper, a comprehensive framework for MHFE methods is presented, and appropriate functional criteria to analyze and evaluate each approach is proposed.
Proposed MHFE framework
There are many techniques for extracting features that could be used to predict the mental health issues of social network users. In this paper, a comprehensive framework for feature set collection is presented based on a set of features that, according to studies, falls into four main groups: linguistic style, contextual, structural, and user features. Each of these classes has several sub-classes, which are separated bases on more details. In the following, the proposed framework is described based on each proposed class and its sub-classes. Figure 1 shows the proposed framework for MHFE.
The proposed framework for MHFE.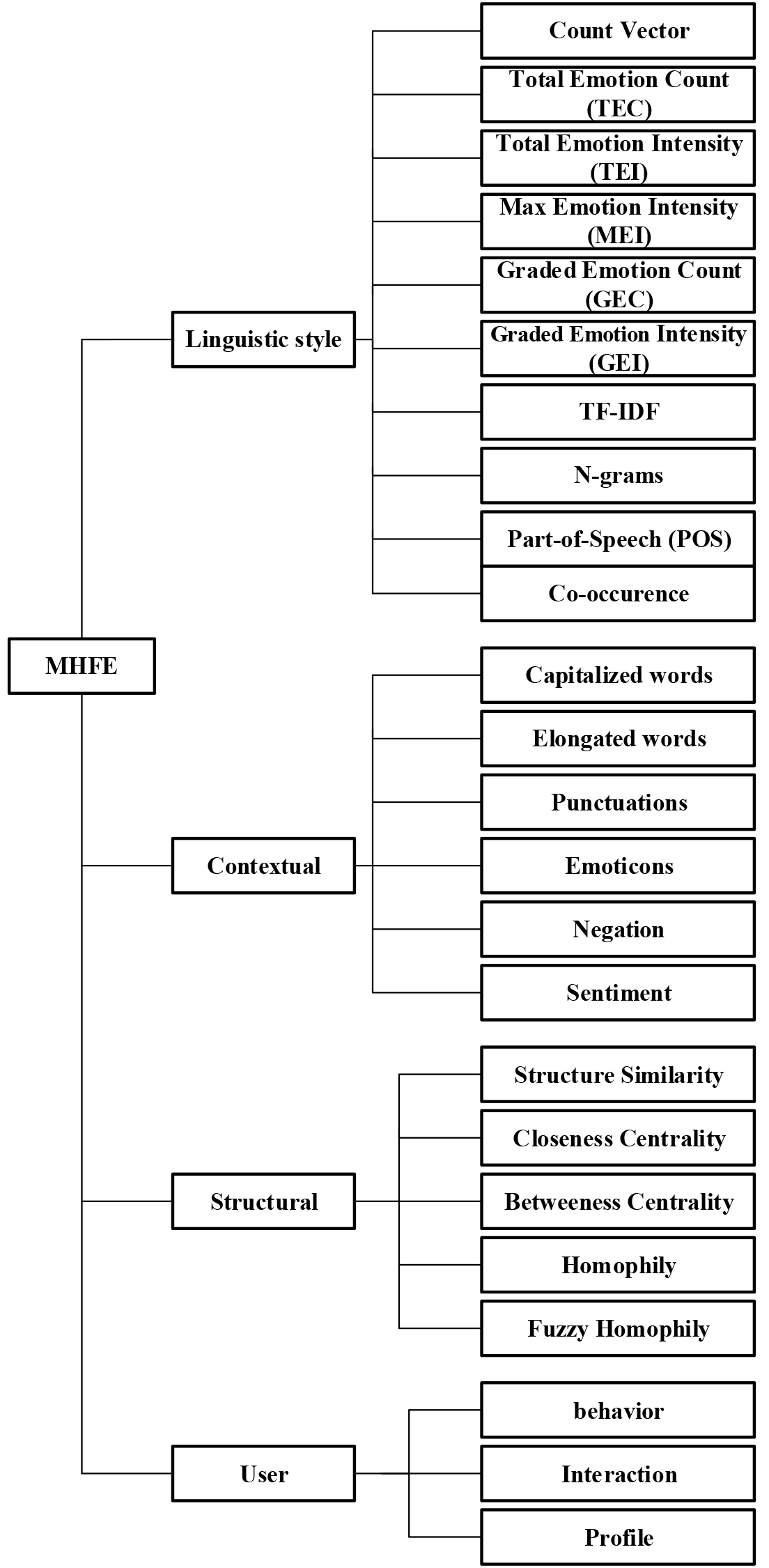
Many of the studied articles have analyzed the content of social networks [18, 20, 22, 23], and each considered a specific language for analysis. Most of these analyses are done in English and Japanese, and some Spanish and Korean. Different methods have been used to analyze linguistic features that are discussed later. These search methods are based on social network data to find the relationship between the uses of words with mental health features.
Count vector
Consider the count vector of a corpus named C consisting of D document
Now there may be quite a few variations while preparing the above matrix M. The variations will generally be in the way a dictionary is prepared.
Because in real-world applications, we might have a corpus that contains millions of documents. And with millions of documents, we can extract hundreds of millions of unique words. So basically, the matrix that will be prepared like above will be a very sparse one and inefficient for any computation. So an alternative to using every unique word as a dictionary element would be to pick, say top 10,000 words based on the frequency and then prepare a dictionary.
The way count is taken for each word. We may either take the frequency (number of times a word has appeared in the document) or the presence (has the word appeared in the document?) to be the entry in the count matrix M. But generally, the frequency method is preferred over the latter.
Figure 2 is a representational image of the matrix M for easy understanding.
matrix M in the count vector method.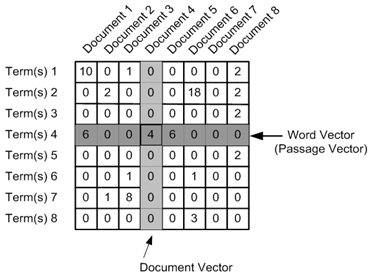
This feature captures the number of words in a document that associate with emotion. Given document d, its corresponding feature vector is denoted by
Where
Co-occurrence method with constant window [23].
An example of the co-occurrence matrix.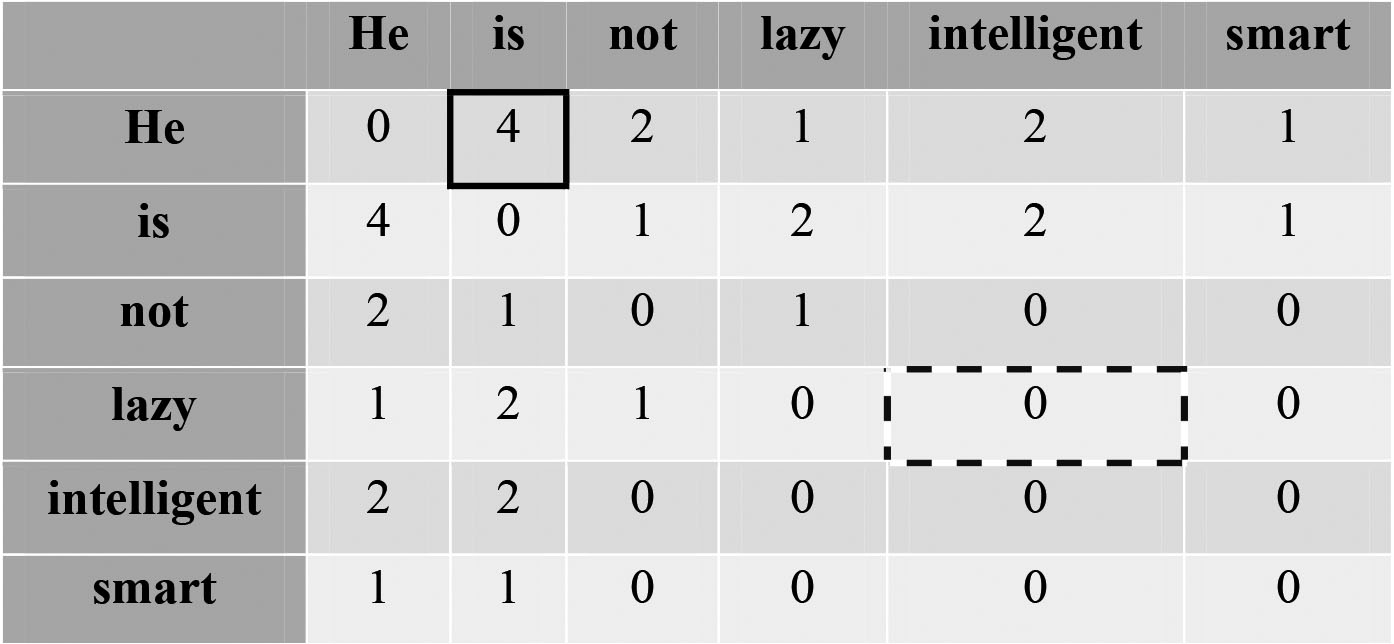
This is the sum of the emotion intensity scores of words present in a document. Unlike the coarse integer counts in TEC features, here, word-level emotion intensity scores offered by a domain-specific emotion lexicon (DSEL) are used to capture the emotional orientation of documents along with multiple emotion concepts (classes). Accordingly, the
Given a document d, and its corresponding feature vector
Both TEC and TEI consider all the words in a document regardless of the intensity with which they convey emotion. However, it is useful to understand the impact of high-intensity words on emotion classification. GEC is similar in principle to TEC, except that it only captures the number of words in a document that associate with emotion and over a threshold value. The GEC features extracted using the DSELs are for the above three thresholds. Given a document d, and its corresponding feature vector
Where
Given a document d, and its corresponding feature vector
Another method that is based on word frequency but differently performs counting is the TF-IDF method, which not only considers the occurrence of a word in a separate text but also in all corpus. Ideally, we want to reduce the weight of the words that are in most of the documentation and increase the importance of the words that are in the subset of the documentation.
If a word appears in all the documentation, it is likely that the word association with a specific document is low. But if it appears in a subset of the documentation, it’s probably the word is associated with the document appearing in it.
Individual Behavioral Patterns when Selecting UserNames [26].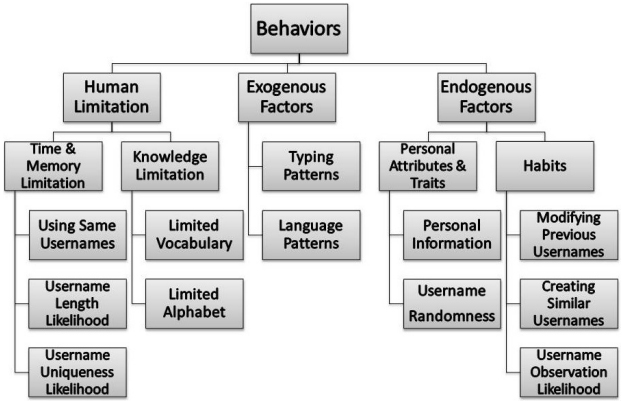
The co-occurrence main idea is that similar words tend to appear in the same context; for example, Apple and Mongo tend to appear in the text in which fruit is. Co-occurrence For the given text is a pair of words that say the number of times w1 and w2 appear together in the content window. The Content window is specified with number and direction. Figure 3 shows an example of a content window 2 (around) [22].
Words with a dashed box are a 2 (around) context window for the word ‘Fox’ and for calculating the co-occurrence, only these words will be counted. Now, let us take an example corpus to calculate a co-occurrence matrix.
Corpus
Let us understand this by seeing two examples in the table above Solid and the dashed box. Solid box- It is the number of times ‘He’ and ‘is’ have appeared in the context window two and it can be seen that the count turns out to be 4.
n-grams
N-gram model is a method of checking ‘n’ continuous words or sounds from a given sequence of text or speech. This model helps to predict the next item in a sequence. Unigram refers to n-gram of size 1, Bigram refers to n-gram of size 2, and Trigram refers to n-gram of size 3. Higher n-gram refers to four-gram, five-gram, and so on [24]. N-grams can reflect semantics that cannot be captured by looking at words individually.
Part-of-speech (POS)
Part-of-speech tagging on non-social media data sets is done using the Stanford POS tagger, whilst the Twitter NLP tool from Carnegie Mellon University was used for tagging social media data sets.
Contextual
Though standard words can convey the emotional intention of the author, additional expressions such as punctuation marks, emoticons are often used on social media to express emotions. Further sentiment-bearing words could indicate the emotion in the text and also alter its orientation from positive emotion (e.g., joy) to negative emotion (e.g., sadness) or vice versa. The following contextual features have been used in sentiment and emotion classification:
Capitalized words: This feature counts the number of words in a document with all upper case characters. Elongated words: This feature counts the number of words with characters repeated two, three, or four times. Punctuation: Emotions are intensified on social media using exclamation marks and question marks. Two features were included to model the occurrence of question marks and exclamation marks in a document. Emoticons: Emoticons are facial expressions captured pictorially and are often used on social media to convey emotions. A binary feature is designed to model the presence/absence of emoticons in a document. The emoticon list is adopted from earlier work in emotion classification. Negation: Though the role of negation is not extensively studied for emotion classification, following its usefulness for sentiment classification
An example of FOAF. Sentiment: An exhaustive list of positive and negative words is created by merging the aforementioned lexicons to extract sentiment features from the documents.

Behavior
Analysis of user behaviors and activities on the social network can also help to analyze user mental health.
User behavior trajectory refers to all the social behavior of a user exhibited on the platforms along the timeline, e.g., befriend, follow/unfollow, retweet, thumb-up/thumb-down, etc.
Both empirical and social behavior studies demonstrate that, over a sufficiently long period of time, a user’s social behavior exhibits a surprisingly high level of consistency across different platforms [25].
Most sites maintain the anonymity of users by allowing them to freely select usernames instead of their real identities, and also different websites employ different user-naming and authentication systems. In terms of information availability, usernames seem to be the minimum common factor available on all social media sites. Usernames are often alphanumeric strings or email addresses, without which users are incapable of joining sites. Selecting the usernames is a behavioral action that may have its behavioral patterns. Figure 5 depicts a summary of these behavioral patterns observed in individuals when selecting usernames [26].
As depicted in this figure, the behavior of username selection consists of human limitation, exogenous factors, and endogenous factors. The human limitation is mainly based on time & memory limitation and knowledge limitation. Endogenous factors are based on personal attributes & traits, and habits. Time & memory limitation is classified using the same usernames, username length likelihood, and username uniqueness likelihood. Knowledge limitation is classified into a limited vocabulary and limited alphabet. Exogenous factors are classified into typing patterns and language patterns. Personal attributes & traits are classified into personal information and username randomness. Finally, habits are classified as modifying previous usernames, creating similar usernames, and username observation likelihood.
Interaction
An approach that is mainly useful in discovering hidden relationships, communication, and the process of complex systems through mathematical and graphical techniques is network analysis. However, given the multiplicity of these methods, the use of SNA methods is complicated and confusing. To attempt to use the SNA methodology in health research issues [4], offers a categorization of SNA methods. Structural analysis; discrete-time intervals describe network topology, the role of specific nodes, communities, and subgroups in the network, and so on.
On social networks, the importance of knowing how many people can be used to discover the number of people exposed to mental disorders, as well as the discovery of hidden populations and social locations. Individual differences in personality construct sensitivity to social disconnection [27].
The similarity between users taking into account the tags they share can be calculated as defined below [28]:
where
Where
Features such as age, gender, geographic location, education, and general user profiles can also be used to analyze their mental health. In most articles that have been designed to analyze mental health, especially in social networks, to enhance the accuracy of the model, user profile features are combined with other features.
A username or display name is a string of numbers, characters, and letters. Intuitively, the longer the length of a common substring or common subsequence of a pair of the username or display name is, the more similar these two accounts are [29].
This is the short write-up / ‘bio’ / ‘about me’ which the user provides about himself [30].
It is a machine-readable semantic vocabulary describing people, their relationships, and activities. It is written in XML syntax and adopts the conventions of the Resource Description Framework (RDF) to define a set of attributes [31]. Default metrics to compute the similarity of each FOAF attribute is provided in Fig. 6.
Various techniques can be used to measure the similarity score between two textual/string values and can be grouped into two main categories:
Syntactic-based similarity approaches: provide exact or approximate lexicographical matching of two values. Using exact similarity techniques can lead to poor similarity results since frequent variations of a word exist and typing errors are common. Thus, approximate string matching techniques can be used to compute the distance between two values that have a limited number of different characters.
Semantic-based similarity approaches: are used to measure how two values, lexicographically different, are semantically similar.
Structural
Structure similarity
Given two users
The structure similarity is measured by two users’ common friends.
This measure requires considering the distance between two vertices
Given any three distinct vertices v, u and w, let
Homophily is defined as the tendency of individuals to become friends with those who are similar to themselves. The homophily concept can be considered a promising tool to analyze the structure of social networks. In other words, homophily is one of the most basic notions, which provides us an illustration of how a social network’s surrounding contexts can drive the formation of relationships [35].
Often, when we look at a network, such contexts capture some of the dominant features of its overall structure. Of course, there are strong interactions between intrinsic and contextual effects on the formation of any single link [35].
Suppose we have a network in which a p fraction of all individuals are male, and a q fraction of all individuals are female. Consider a given edge in this network. If we independently assign each node the gender male with probability p and the gender female with probability q, then both ends of the edge will be male with probability p 2, and both ends will be female with probability q 2. On the other hand, if the first end of the edge is male and the second end is female or vice versa, then we have a cross-gender edge, so this happens with probability 2pq. So we can summarize the test for homophily according to gender as follows:
Homophily Test: If the fraction of cross-gender edges is significantly less than 2pq, then there is evidence for homophily [35].
Homophily can help us to investigate the structural formation of social networks based on every feature. This concept can also be used to evaluate mental health features.
Fuzzy homophily
Fuzzy homophily is a fuzzy inference system that uses the distributions of attributes and inner links as input and infers the homophily measure as output. It is assumed that the attributes have only two values, for example, male and female. Therefore D1 is used for male distribution and D2 is used for female distribution. Similarly, L1 is male-to-male total links and L2 is female-to-female total links [36].
Fuzzy homophily is an attribute that compares two individual distributions and indicates relationships between two distributions, for example, male and female gender. It is based on fuzzy inference systems and demonstrates that relationships are normal or abnormal. It is clear that normal relations show mental health in that society, as abnormal relations show mental disorders in the gender field.
Fuzzy homophily [36].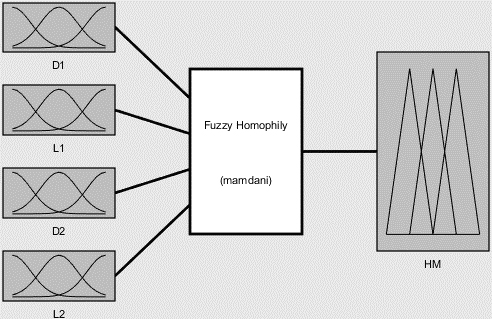
Criteria
Feature extraction is highly subjective and depends on the problem’s type. There is no generic feature extraction technique that works in all cases. Such as classifiers, it is not possible to say which the best technique for feature extraction or extraction is. It highly depends on the application [37]. In this section, we will introduce the five functional criteria to study and evaluation of the various techniques of mental health feature extraction in social networks: accuracy, speed, the function of each technique on the large data, the scalability of each technique, the generality of each for the overall analysis of the mental health of the individual in the social network and the computational complexity of them [20, 22, 24, 38].
Accuracy
According to this criterion, the accuracy of the model created based on the characteristics of the proposed method is calculated. This criterion is the ratio of the accurate prediction pf user mental disordering to all predictions, is shown in Eq. (13):
According to this criterion, the speed of extraction is calculated.
Where
Usually, a machine-learning algorithm or feature extraction method works well on small data and then extended to large data sets. At that time, a lot of problems occur such as the curse of dimensionality, processing time and computational complexity, and learning time increases exponentially. To overcome this problem, it is obvious that algorithms should also work well for large data sets.
Generality
According to this criterion, having general rather than specific validity of the feature will be depicted. In other words, a feature extraction algorithm must be valid for new data, which does not exist in previously trained data. This criterion prevents from over-training of the model.
Computational complexity
The computational complexity or simply complexity of an algorithm is the number of resources required for running it. The computational complexity of a problem is the minimum of the complexities of all possible algorithms for this problem [39].
Evaluation and discussion
In this section, we will evaluate mental health feature extraction methods based on a number of key challenges with their key advantage and disadvantage. This qualitative assessment determines how well these qualitative methods have been able to address the challenge that is labeled at three levels: High (H), Low (L), and Medium (M). This qualitative analysis of mental health features extraction methods based on key challenges is shown in Tables 1–3.
Proposed qualitative analysis of mental health features extraction for linguistics style methods based on key challenges
Proposed qualitative analysis of mental health features extraction for linguistics style methods based on key challenges
Proposed qualitative analysis of mental health features extraction for contextual and structural methods based on key challenges
Proposed qualitative analysis of mental health features extraction for user methods based on key challenges
A comprehensive taxonomy for MHFE techniques is needed to appropriate understanding and correct use of them. However, these techniques can be classified into several points of view. Furthermore, to analyze and evaluate each approach, several criteria are needed. In this paper, four classes and several sub-classes are proposed as a general framework and are evaluated qualitatively with the accuracy of the model based on the characteristics of the proposed technique, the speed of extraction, the scalability of each, the generality of each technique for the overall analysis of the mental health of the individual in the social network and the computational complexity.
Linguistic style considers a specific language for analysis and is based on the content of social networks, including Count Vector, TEC, TEI, MEI, GEC, GEI, TF-IDF, Co-occurrence, N-grams, and POS [18, 20, 22, 23]. Contextual class is consists of Capitalized Words, Elongated Words, Punctuation, Emoticons, Negation, and Sentiment [1, 2, 3, 4, 5, 7, 15, 16, 19]. User class is consist of Behavior [17, 18, 25], User-Name Selection [26], Interaction [27, 28], and Profile [29, 30, 31]. Structural class is consist of Structural Similarity [24, 32], Closeness Centrality [33], Between-Ness Centrality [34], and homophily [35, 36].
Count vector in the linguistic analysis at a moderate level in all metrics. Total Emotion Count (TEC) has a moderate accuracy, speed, scalability and generality is high and has low computational complexity. Total Emotion Intensity (TEI) is the same as TEC in accuracy, speed, and computational complexity but has high scalability and generality.
Max Emotion Intensity (MEI) has moderate accuracy and computational complexity and has high speed, scalability, and generality. Graded Emotion Count (GEC) and Graded Emotion Intensity (GEI) are the same in high accuracy and moderate speed, scalability, and generality but are against computational complexity, where GEC is high and GEI is moderate.
TF-IDF has a high score on accuracy, scalability, generality, and computational complexity but has a low speed.
The use of n-gram in linguistic analysis, because of needing very large statistical set, each of which contains a set of word vertices, with the relationships between them, challenges the accuracy and computational complexity at a high level, but in terms of scalability, and in terms of generality and speed is at a moderate level [24].
Part-of-Speech (POS) has a high score in accuracy, speed, scalability, and generality and a moderate score in computational complexity. Co-occurrence is the same as Count Vector except that in generality, which is high.
In the contextual category, Capitalized words and Elongated words are the same in low accuracy, generality, and computational complexity, high speed, and moderate generality. Punctuation and Emoticons are the same in high accuracy and scalability and moderate speed, generality, and computational complexity. Negation has moderate accuracy, speed, generality, and computational complexity, and high scalability. Sentiment has moderate accuracy, scalability, generality, and computational complexity, and low speed.
In the structural category, Structure Similarity and Between-ness Centrality are the same and have moderate accuracy, low speed, and high scalability, generality, and computational complexity. Closeness Centrality has high accuracy, generality, and computational complexity and has moderate speed and scalability. Homophily and fuzzy homophily are the same in moderate score in accuracy and generality and high score in scalability but are against in speed and computational complexity where respectively homophily has moderate and low scores while fuzzy homophily has low and moderate scores.
In user categories, there are three subcategories named behavior, interaction, and profile. User behavior trajectory has high accuracy, moderate speed, and scalability, and low generality and computational complexity. The Username selection has moderate accuracy, speed, and computational complexity and low scalability and generality. Tagging has high accuracy and computational complexity, low speed, and moderate scalability, and generality. The username has moderate accuracy and generality, high speed, and low scalability, and computational complexity. The Description has moderate accuracy, speed, and scalability, and high generality, and computational complexity. Finally, FOAF (Friend of a Friend) has high accuracy, scalability, and generality, low speed, and moderate computational complexity.
In this paper, a coherent framework is presented for feature extraction methods in social networking data related to the mental health of individuals, and the evaluation of each method is presented. Furthermore, by identifying and introducing these methods and their challenges, appropriate functional indicators are provided for analyzing feature extraction methods. Utilizing the proposed criteria to analyze different methods leads to a more accurate understanding of these methods and their proper use and the possibility of accurate comparison and evaluation of these techniques. What seems to be in this framework is the use of structural features of the network because of its high correlation with personality traits and the behaviors and interactions discovered on the social network and the combination of these features with linguistic features can challenge the accuracy and generality that is most important metrics in techniques of mental health analysis. Despite the efforts made in this research, there are still many challenges that need to be addressed by researchers in the future. Specifically, it is suggested that in the future, analytical methods as well as implementation using valid brand benchmarks to be used and each of the proposed methods and criteria to be re-evaluated.