
Abstract
A curriculum sequence represents a match between learners’ preferences, needs, and surroundings from one side, and the learning content characteristics and the pedagogical requirements from the other side. The curriculum sequence adaptation problem (CSA) is considered as an important issue in adaptive and personalized learning field. It concerns the dynamic generation of a personal optimal learning path for a specific learner. This problem has gained an increased research interest in the last decade, and heuristics and meta-heuristics are usually used to solve it. In this direction, this paper summarizes existing works and presents a novel GA-based approach modeled as an objective optimization problem to deal with this problem. The experimental results from simulations showed that the proposed GA could outperform particle swarm optimization (PSO) and a random search approach in many simulated datasets. Moreover, from a pedagogical perspective, positive learners’ feedback and high acceptance towards the proposed approach is indicated.
Introduction
Curriculum sequence Adaptation (CSA) problem is a crucial task in the field of adaptive learning, since the way learning resources are sequenced affects the learning outcomes, and accordingly, the efficiency and effectiveness of the adaptive learning system. The main issue here is to find the optimal path through massive learning resources, according to some information obtained from the profile, the situation and the environment of the current learner [1, 3].
CSA problem is considered by several researchers as a combinatorial optimization problem because it is not only impossible for instructors to scheme the fitting learning paths for learners, but also difficult and time-consuming for learners to scheme their fitting curriculum sequence by themselves. The learner’s contextual features are integrated in the problem formulation as constraints and increasing in their number increases significantly the accuracy of the adaptation but also the complexity of the problem. Contrary to the majority of works that have opted to reduce the complexity of the problem to the detriment of the quality of the adaptation, we have opted for integrating a relatively a larger number of contextual dimensions than other works within this field [3, 4]. The complexity that may occur in this case will be tackled by distributing these contextual constraints between two stages of adaptation, concepts sequence adaptation and Learning objects sequence adaptation. The first stage insures the suitability between the selected concepts and the learner’s target and his/her previous knowledge. The second one aims at selecting from each concept the Learning object that best meet the learner’s features.
The application of evolutionary approaches in construction of optimal curriculum sequences shows that evolutionary algorithms are suitable for generating tailored content. Among the proposed methods we can mention those based on ant colony optimization (ACO), particles swarm optimization (PSO), artificial immune systems and genetic algorithms (GAs). To this direction, this work presents a novel Genetic algorithm, which not only reduces the search space size and increases search efficiency but also it is more explicit in finding the best composition for a specific learner by generating higher quality recommendations.
Our approach is compared with other heuristic algorithms and a random search method. From the experimental results, it can be concluded that the proposed algorithm shows high adaptability and efficiency in the curriculum sequence adaptation.
The remainder of this paper is organized as follows; Section 2 briefly reviews the basic concept of the problem and related works. Section 3 explains the method applied to handle the LPA problem. Section 4 presents the proposed genetic algorithm. Section 5 analyzes the Simulation experimental results of the proposed GA performed on nine simulated datasets and conducts an empirical experiment to evaluate the pedagogical feedback and finally, a conclusion and some perspectives are given in Section 6.
Summary of some works for solving CSA problem
Summary of some works for solving CSA problem
Adaptive curriculum sequence
Definition
Adaptive learning systems have the ability to replace teachers and other forms of tutor/learner assistance and using various methods including Curriculum Sequencing or learning path generation [1]. This becomes even more important for adult learners and lifelong learners, who prefer a self-guided learning process.
Curriculum sequence represents a sequence of learning objects (LOs). Selecting proper LO to compose a suitable learning path for learners is a complex task especially considering a set of constraints related to the current learner such as learner’s available limited time, his/her preferable format, knowledge level, previous performance, learning targets etc. [48]. Furthermore, the generation of an adapted curriculum sequence has to respect the logical sequence between the knowledge elements.
Related works
CSA problem has gained increased research interest in the last decade [49, 3]. According to several surveys within this field [1, 29, 32, 39], the techniques used to implement a solution for the CSA problem could be classified into two main categories: non-evolutionary computation-based techniques and evolutionary computation-based one.
Firstly, ontology-based reasoning techniques are proposed in several works [33, 9, 34, 36]. The reasoning is performed in terms of SWRL rules (Semantic Web Rule Language). The drawback of this approach is their inappropriateness to reasoning with uncertainty [10]. This problem can be tackled by combining various reasoning models that may include Probabilistic, Fuzzy logic [9] and Greedy algorithm [36]. Furthermore, ontology design requires knowledge engineering and is generally time-consuming [11]. Within the same category, graph-based techniques have been widely used, among these algorithms we can mention: the first-search depth (DFS) [37], binary integer programming and adaptive shortest path algorithm [38]. However, according to [6] there has been no formal model for discussing curriculum sequencing problems based on graph theory.
Evolutionary Computing (EC) is based on the Darwinian principles of natural selection. Some points distinguish the EC techniques from other solutions and promote them to be flexible and robust techniques with satisfactory performance: first, their ability to preserve the diversity of the population, which has a great impact on dealing with large search spaces, and also allow the escape from local optima [1].
According to [1] Evolutionary computation approaches have a great impact on the generation of adaptive curriculum sequences. Genetic algorithms (GA), Ant colony optimization (ACO) and Particles swarm optimization (PSO) are the most used algorithms within this category.
In the context of solving the CSA problem, ACO acts as a graph in which learning materials are nodes and students are ants walking on the edges seeking to find the best path in accordance with their contextual attributes [49, 40].
The Particle Swarm Optimization (PSO) method has been also used to solve the combinatorial optimization problems by having a population of candidate solutions, called particles, and moving these particles around in the search space using a simple objective function over the particle’s position and velocity. Each particle’s movement is influenced by its local best-known position and oriented toward the global best positions [49]. In the context of CSA problem, a particle refers to a candidate curriculum sequence.
One of the techniques found in the literature for solving CSA problems is genetic algorithm (GA), which is a search heuristic that is inspired by Charles Darwin’s theory of natural evolution. This algorithm reflects the process of natural selection where the fittest individuals are selected for reproduction in order to produce offspring of the next generation [41].
In comparison to PSO, GA is less computationally intensive and generates high-quality solutions [17], Contrary to that, PSO was found to be less stable and the execution time increased exponentially when the search space contained a large number of learning objects [12]. ACO algorithm performs better in learning path regulation but it is hard to organize a large quantity of learning resources into a foraging graph, and pheromone is not convenient to represent the large number of constraints [17]. GA is easy to be implemented and it is effective to solve learning resources sequencing. However, GA faces the problems of parameters setting and operators’ selection [17]. For example, the inappropriate parameter designs of crossover, mutation and recombination often make the evolutionary process uncertain and even out of control. The proposed genetic algorithm not only reduces the search space size and increases search efficiency but also it is more explicit in finding the best composition for a specific learner.
Table 1 above presents a brief description of a set of works that belong to both categories of approaches.
Domain knowledge structure
Domain knowledge structure is presented in this section through a set of related definitions:
Knowledge domain structure.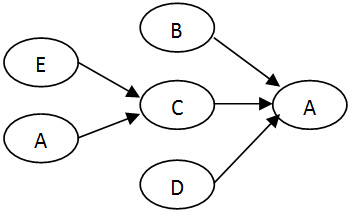
LOs are described, in their metadata, by the concept of which they represent along with their format, difficulty level, and other parameters. This organization enables the location of the right LO that fits into the desired curriculum sequence [1]. Table 2 Bellow represents an example of LO metadata.
Sample LO metadata
In adaptive learning environment, learners’ attributes affect the selection and sequence of LOs. So learners’ context modeling is the basic and vital step for adaptation [17].
Dey [20] defined the context as “any information that can be used to characterize the situation of an entity. An entity is a person, place or object that is considered relevant to the interaction between a user and an application”.
Context model.
Hierarchical design implemented in Protégé (Excerpt).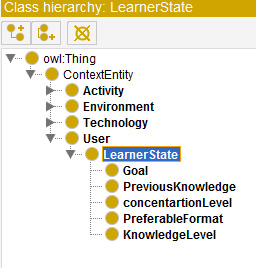
Adaptive learning systems make use of context information to match the form of presentation, structure, and selection of learning content to a learner’s individual preferences, previous knowledge, learning goals, physical situation, environmental characteristics and other information that constitute what we call a learner’s context model.
Given that the contextual features are numerous and varied, the literature has shown that each work uses a subset of these features, the selection is made based on the learning scenario set by the designer of the context-aware application [3]. In our work, we have integrated a relatively a larger number of contextual features, presented as follow:
The learner’s goal: Each learner has specific target to perform to achieve a particular task. There may be several paths from the start knowledge unit to the target knowledge unit. The learner’s previous knowledge: is a set of concepts that are previously studied by the current learner, they are depicted as {C1, C2, The learner’s preferable format: describe learner’s preference for media type [24, 23]. The learner’s planning time: a good system has to recommend successful curriculum sequences with respect to the time constraint [23]. The learner’s Knowledge level: is the learner’s level of education. Each learner acquires a specific level of knowledge about a specific topic. It is important for the adaptation process to evaluate each learner’s background knowledge (Beginner/Medium/Advanced). The learner’s concentration level: the type of adaptation has to be supported by pedagogical theories that can enhance the learning experience [25].
In order to provide learning content more adaptively, under an organized curriculum sequence it must be managed in semantic way. Ontology is one of web semantic technologies the most known in all fields specially in education. They represent knowledge so as to be perceptible to the machine and human [43].
According to several studies in the field of context modeling [46, 47], Ontology-based modeling is a leading technique, which can represent context efficiently. It supports the process of adaptation and improves the capabilities of adaptive learning system [3]. Based on Ontology’s, a system could possess the ability to build semantic context description, context reasoning, knowledge sharing, context classifications, context dependency [22, 15]. In this paper, we exploited the ontology to represent the learners’ characteristics. In fact, the ontology used in this work is extracted from a generic ontology defined in our previous work [3].
Material preliminaries
To effectively compose adaptive curriculum sequence for different learners, several factors that affect learning efficiency and performance should be considered. These factors are grouped in three models as follows.
Learner’s context modeling
K Learners are presented as U
{Goal
{PF
{KL
tli,
tui,
{CL
Concepts modeling
M Concepts are presented as {C
Pre-List is a set of concepts that have to be learned before C
LO modeling
N Learning objects (LOs) are presented as {X
{C
{F
F
{Dur
{DL
Mapping rules
Mapping rules
{CoL
The proposed process of generating an adapted curriculum sequence is composed of two stages: The concepts sequencing stage and the LOs sequencing one:
Stage 1: Concepts sequencing The pre-requisite relationships among concepts are an important step toward the organization of knowledge for adaptation and personalization purposes. In this context, simplest concepts that are requirements to address more complex concepts should be exploited for effective automatic learning path generation systems [48]. The concept sequencing stage is responsible of generating a personalized concepts sequence adapted to the learner’s target, his/her previous knowledge and the pre-requisites relationships defined between the core concepts that constitute the domain knowledge. This first stage aims at selecting from a large repository of core concepts a sub-set composed of the concept-target and a set of core concepts related to the target by pre-requisite relationships. These concepts are filtered by the previous knowledge of the learner (Learner Knowledge base) to eliminate all concepts that have already been mastered. To meet the requirements above, we have implanted the algorithm presented below, which is inspired from [24]. The resulted personalized concepts sequence will be the outcome of the first stage and the input of the second stage. Stage 2: LOs sequencing
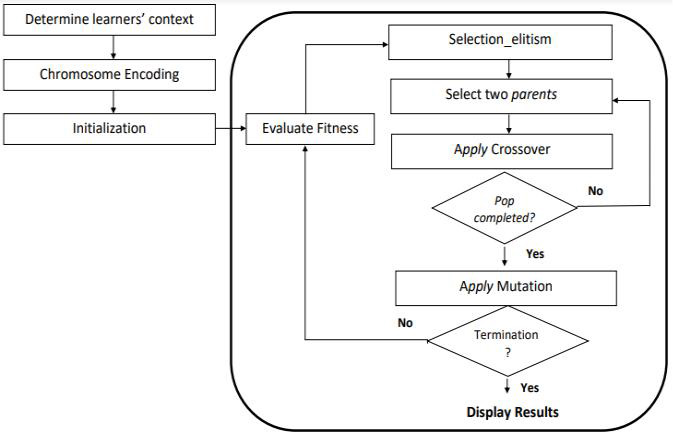
Flow chart of the proposed GA.
Chromosome encoding. In the second stage, a personalized curriculum evolution model based on GA is proposed. We assume that, only one LO is picked from each concept within the concept sequence resulted from the first stage, based on the mapping rules that relate the LOs metadata attributes with the contextual features of the current learner. A set of mapping rules that aim to insure a maximum suitability between the learner’s context and the LOs metadata is illustrated in Table 3.
Algorithm associated to Stage 1
Target-set
Sets
WhileTarget-set’s pre-requisites are not all satisfied
with the learner’s Knowledge base
PreSet
Target-set pre-requisites
Sets appends PreSet
Target-set
End While
Display all the sets contained in Sets from the last one to the first one.
Genetic algorithm GA proposed by Holland (1975) is a population-based search technique that performs well in relation to approximating to the optimal solution, where it simulates the evolutionary theory to search the problem space, including the selection (favour the survival of better individuals), crossover (recombine individual features), and mutation (create new individuals). After the initialization (initialize the individual status), GA repeats the selection, crossover, and mutation until the terminal condition is met. Importantly, chromosome encoding (determine the code of feasible solution) and fitness evaluation (determine the individual quality) are two keys in GAs’ applications [26].
While that the first stage of the learning process presented above is based on the separation between the concepts and the LOs sequencing, which reduces the search space size, the GA performed in the second stage not only increases search efficiency but also it is more explicit in finding the best composition for a specific learner in lesser time, this is first based on, a good chromosome encoding which allows a significant reduction in the chromosome size. Second, a simple and extensible definition of the objective function, which allows to easily integrating more contextual features and finally, a studied parameterization of genetic operators which generate higher quality recommendations. The flow chart of the proposed GA is presented in Fig. 4.
Determine learner’s context. The first step is to determine the learners’ context based on which the curriculum sequence adaptation is performed. This is crucial for structuring adequate solutions achieving better learning outcomes. The context used in this work is described earlier, in Section 2.
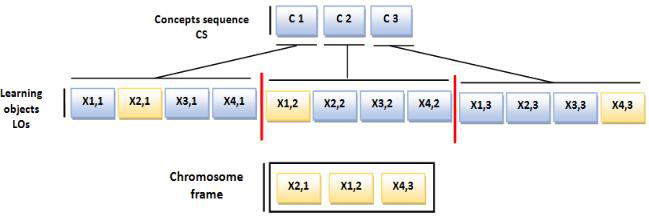
Chromosome encoding. To perform the genetic algorithm, it is essential to encode the candidate solutions of the CSA problem into a set of chromosomes. The quality of this step highly affects the success of the search.
A learning path is represented by a single individual. Each gene represents the identifier assigned to a LO (see Fig. 5). The order of appearance of genes in an individual respects the order of their concepts in the sequence of concepts results from the first stage of adaptation.
The LO’s identifier is denoted X
Let us assume that CS is the concepts sequence with M concepts. We assume also that from each concept C
Initial population. The algorithm is started by generating an initial population that consists of a certain number of feasible encoded solutions. This number of solutions refers to population size and it remains constant during the GA procedure. The initial population pop is produced using a random method in order to ensure the diversity of population and improve the convergence to the best solution. We assume that each individual in the population is initialized according to two rules. First, only one LO from each concept of the concept sequence generated in the first stage of the learning process is selected randomly, this rule is imposed to reduce the learner’s cognitive overload. Second, the LOs that constitute the final candidate curriculum sequence have to preserve the same order of their corresponding concepts in the predefined concepts sequence.
Fitness Evaluation. The fitness function assigns a value to each chromosome determining the suitability between the metadata attributes of each LO in the chromosome, from one side and the corresponding learner’s context features from the other side. We attempt to model the CSA problem as an Objective optimization problem where the Learner’s context features and the LOs characteristics are taken as constraints. The scope of this function is to minimize the average difference between the two sides as it is shown below:
LOS: LO’s Sequence is the candidate solution to be evaluated by the Objective Function. LOSi
Ctx: is the current learner’s context vector, it’s depicted as:
Wi denotes the objective function weights that can be used to adjust the Ratio of
Crossover.
Mutation.
Selection_Elitism. In order to preserve the fittest chromosomes in every generation, an elitism selection is employed. Thus, a small proportion of the best chromosomes is duplicated to the next generation. This strategy guarantees that the best chromosome of a population will be better or at least equal to the best chromosome of previous population. Moreover, it does not lead the algorithm to converge prematurely as the elitism percentage is chosen to be too small. The elitism percentage of this approach is set to 0.1. The population of the elite chromosomes Pop_Elite is copied into the next population New_pop.
Selection. Selection operator consists of selecting the most suitable chromosomes to be inserted into a mating pool. In our genetic algorithm, two mates are chosen randomly, one from the elite population Pop_Elite and the second from the entire population pop. Repetition in the selection of a mate is allowed and therefore an individual can produce more than one offspring.
Crossover. Crossover operator is applied to the two parents selected previously. For each gene in the chromosome parent, the i-th allele ci of the offspring c takes on the value of the i-th allele of the elite parent with probability elite_probability (Ep) and the value of the i-th allele of the non-elite parent with probability 1 – Ep.
In this way, the offspring is more likely to inherit characteristics of the elite parent than those of the non-elite parent (see Fig. 6).
Mutation. The first particularity of the proposed mutation is that, it’s performed by exchanging one random gene with another random gene that belongs to the same concept; this condition is imposed to preserve the concepts’ sequence order (see Fig. 7) The mutation rate is suggested to be very small to preserve the population coverage. The mutation, it is set to 0.1.
Simulated datasets
GA Parameters tuning
The pseudo code of the proposed GA is presented below:
GENERATE AN INITIAL POPULATION POP
FOR EACH ITERATION
CALCULATE THE FITNESS OF POP
Display the Best Fitness
Pop_Elite
chromosomes from Pop New_pop
Repeat
Select a random chromosome elite from Pop_Elite
Select a random chromosome non_elite from Pop
For
Generate a random number
If
the
the value of the
parent
Else
the
the value of the
elite parent
End For
Insert the offspring
Until New_Pop reaches pop_size
For each Chromosome in New_Pop
Generate random number rm
If rm
Select a random gene
Replace the selected gene by another gene (LO)
that belongs to the same group (concept)
End if
End for
Pop
EndFOR
To validate the proposed genetic algorithm, an evaluation process was conducted analyzing both the computational results by measuring the algorithm performance and the pedagogical ones by measuring learners’ acceptability.
Objective performance evaluation
To validate the viability of the proposed GA, several experiments were conducted on 12 Datasets (Table 4).
The implementation environments are presented as follows
Operating system: Windows 7 pack1 CPU: Intel i3-9100T 3.70 GHz RAM: 4GO Programming language: Python
The 12 datasets listed in Table 4 are created by simulation. The number of concepts, in the 12 datasets varies between 10, 20, 30 and 40 while the number of LOs for each concept is 10, 30 and 50. Furthermore, the values of LOs metadata are generated randomly within the value intervals of each LO attribute defined in Section 2.
The GA settings affect strongly the algorithm performance, resulting the generation of an optimal curriculum sequence in a short time. Towards this end, the GA parameters were set through the emulator experiments and empirical value. For example, in order to determine the value of a parameter, the program is run 20 times varying each time the values attributed to this parameter, whereas the others were fixed (see Fig. 8).
Tuning of GA settings.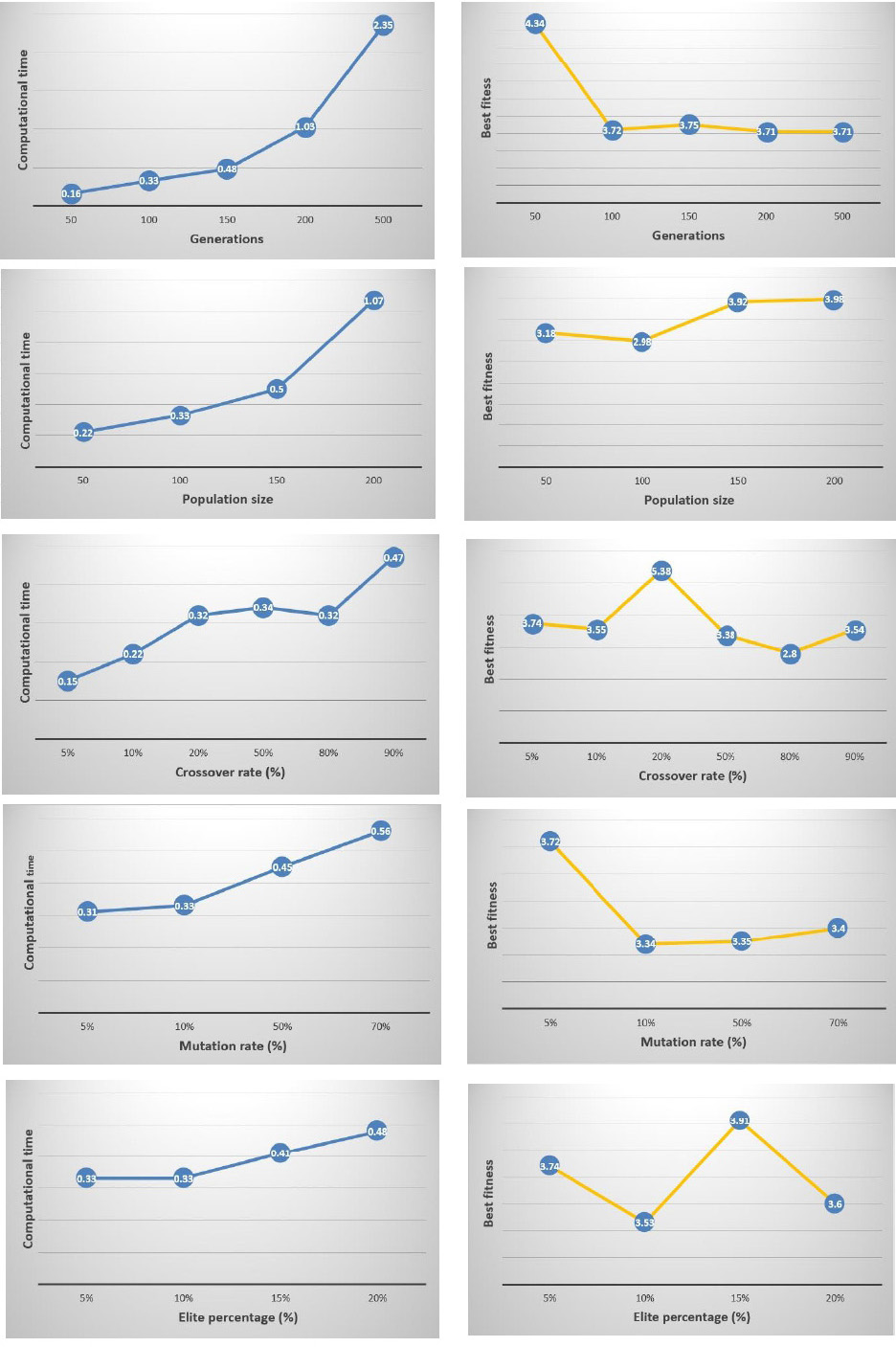
Table 5 illustrates the parameters used for testing, whereas the best settings emerged from the experiments are marked in bold. All experiments run on the same hardware configuration to ensure a fair comparison. .
When increasing the number of generations, the fitness value is improved, whereas the execution time is increasing as well. However, it is worth mentioning that the fitness value seems to gain non-significant improvement when the generations exceed 200. Thus, a number of generations around 100 is selected.
Regarding population size, it is noted that the best compromise between fitness and computational time is associated to a population with 100 chromosomes. Varying the crossover probability called in our work Elite probability, the algorithm behaves well when it is reaches 80%. Over this value, the computation time becomes very important and the evolution of the fitness value becomes more and more stable. For, the rate of 80% is selected as the optimal crossover probability.
Mutation rate in our problem is set to 10% because it is noted that when we increase it more than this value, we increase significantly the execution time and at the same time, the best fitness value is not really improved.
Finally, the experiment shows that the GA performance is improved from a value of 10% of the Elite_percentage parameter. However, higher rate than 10% does not improve the fitness value, whereas it increases computational time.
On the other hand, the parameter settings of PSO, such as learning factors, refer to experiment, empirical value and problem scale [14]. Table 6 presents the final settings of the proposed GA.
Final parameters of the proposed GA
The influence of the number of LOs on the Fitness value. A. a. Dataset 1 – b. Dataset 2 – c. Dataset 3. B. a. Dataset 4 – b. Dataset 5 – c. Dataset 6. C. a. Dataset 7 – b. Dataset 8 – c. Dataset 9. D. a. Dataset 10 – b. Dataset 11 – c. Dataset 12.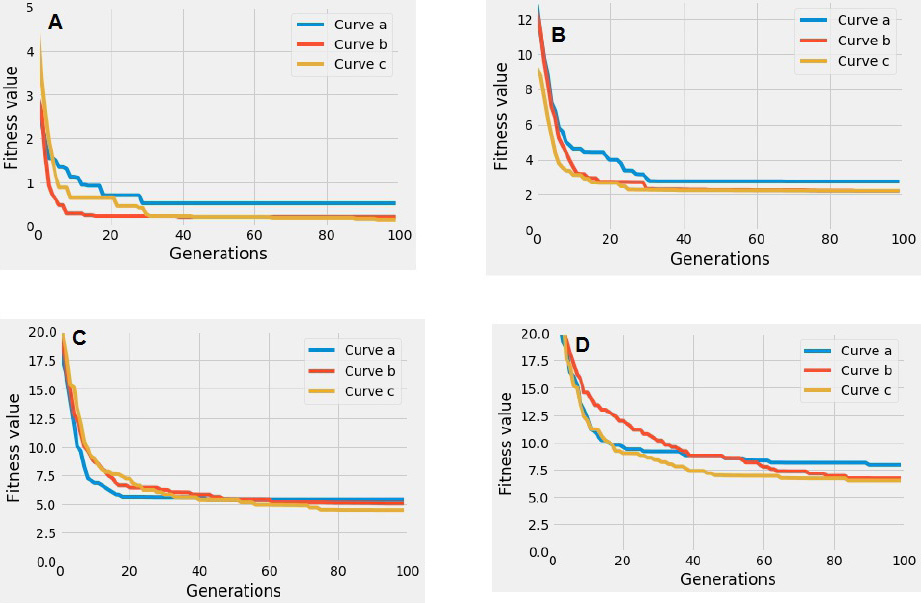
To study the influence of the number of LOs on the best fitness value, we devise the parameters presented in Table 6 and we apply different numbers of LOs with a fixed number of concepts. Figure 8 shows the convergence curves of the proposed GA applied on 4 groups of Datasets: Group A with 10 concepts, Group B with 20 concepts, Group C with 30 concepts, and finally Group D with 40 concepts. The four Datasets groups used the same collection of LOs values, 10, 30, 50 within each concept. The experiment is applied over 100 generations. The generation number is the abscissa and the Best fitness value is the ordinate in which a lower fitness value means that the solution is closer to the optimal solution and then more adapted to the current learner’s context. We conclude from the that, as the number of LO increases, the fitness value becomes optimal (see Fig. 9).
Simulation experimental results
Simulation experimental results
Comparison of the convergence process of the proposed GA with a standards version of PSO. A. Dataset 1; B. Dataset 2; C. Dataset 3; D. Dataset 4; E. Dataset 5; F. Dataset 6; G. Dataset 7; H. Dataset 8; I. Dataset 9; J. Dataset 10; K. Dataset 11; L. Dataset 12.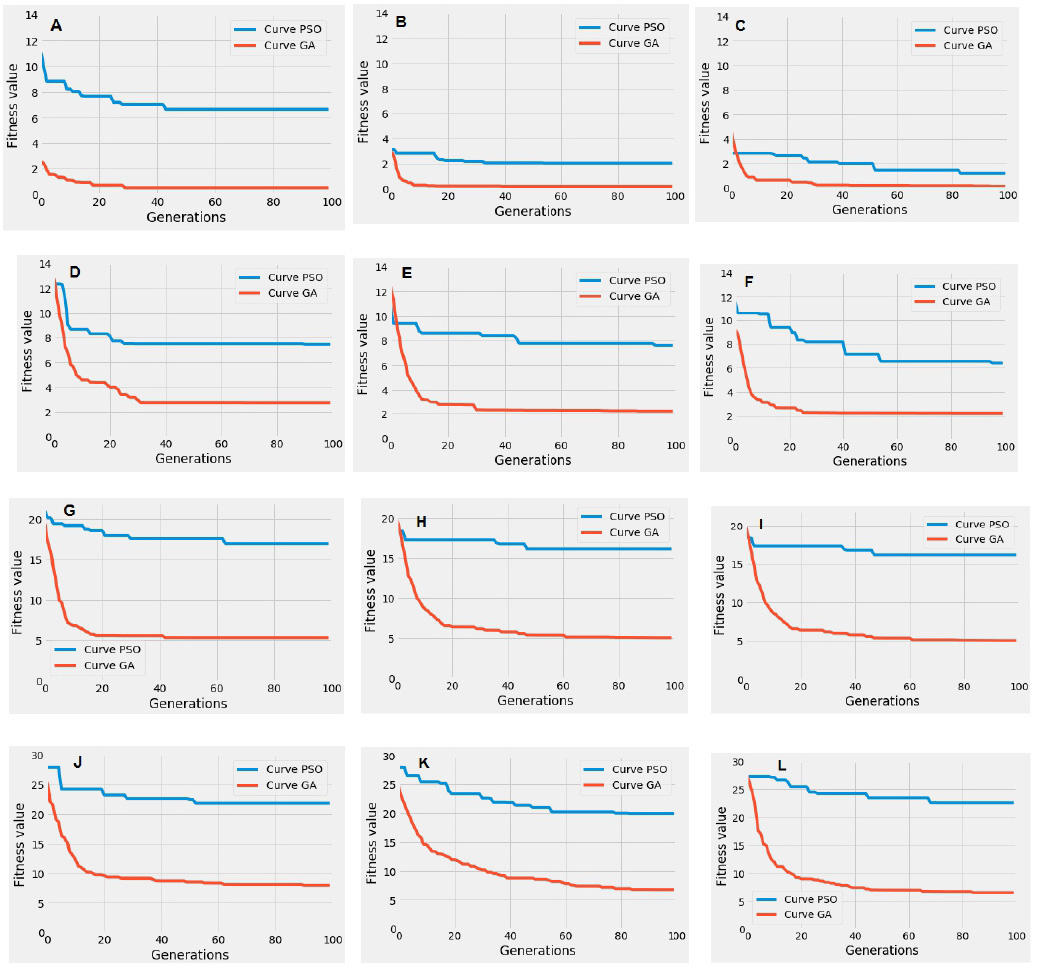
Empirical evaluation.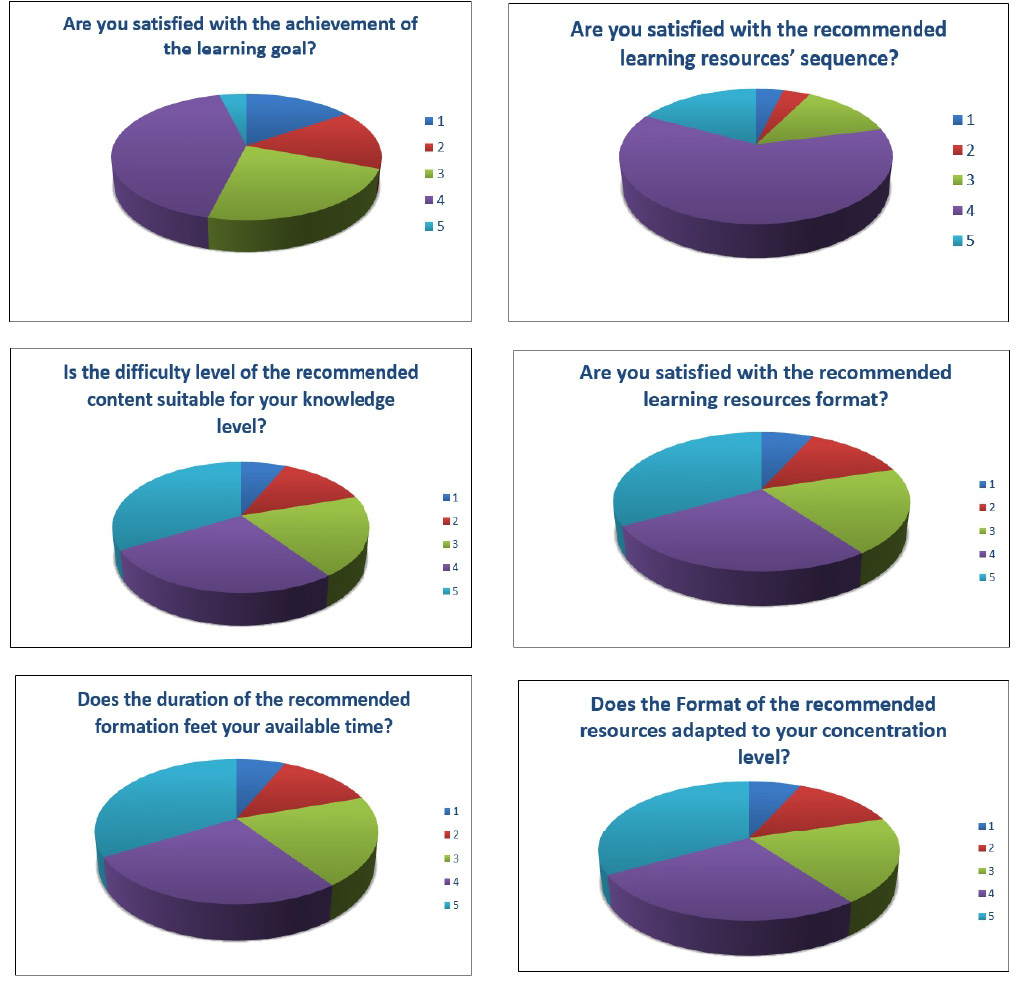
To study the convergence performance of our algorithm, several simulation experiments were conducted to compare it with two other approaches, the first one is a standard version of PSO executed 20 times on the 12 datasets presented in Table 4 to reduce the randomness of the algorithm’s implementation. The second approach is a random search approach, which is simple and fast but it has large stochastic volatility. The number of generations and population size are the same as GA. It is worth mentioning that, the fitness function, the LO and the learner’s context models of PSO are the same used in our GA-based approach.
Figure 10 illustrates the average of 20 executed results of PSO and the proposed GA approaches on 12 datasets, performed through 100 generations of the evolutionary process. We can notice from Figure 10 that in the 12 convergence curves, the GA curve was always below the PSO curve, which means that our proposed GA converges better than PSO; for instance in Fig. 10A, The GA convergence curve drops from 2.56 to 0.52, while the PSO algorithm drops from 11.06 to 6.67. We can get the same conclusion from the other convergence curves.
From these results, we can conclude that our approach outperforms PSO and the random search approach and it significantly increases the search efficiency.
Table 7 records the BF, which is the best fitness result of the 20 experiments, AF the average result of the 20 experiments, and SD, which indicates the fluctuation of the results. The presented results show that the two evolutionary algorithms significantly enhance the search performance compared to the random approach. Because the random approach has the worst AF and BF and more obvious fluctuations, it constitutes a very bad choice for the curriculum sequence adaptation problem.
We can notice also from Table 7 that, in the 12 datasets, AF and BF of our GA outperform the results of the two other approaches by providing better global optimization ability. The application of the simulation experiment has proven that the proposed GA can get a satisfactory solution to problems with different scales, which satisfies the requirements of most real-life applications of adaptive curriculum sequencing problems.
The standard deviation study is integrated in this work to observe the quality of the fitness values. Table 7 depicts the results for the GA, the PSO algorithms and the random search approach, which indicates that the standard deviation of the proposed algorithm is much lower than the two other approaches. That is, a good indicator that the quality of fitness value derived by our GA is more stable compared to PSO and the random approach.
Empirical evaluation
From pedagogical perspective, learners were asked to complete a questionnaire to express their attitude towards their learning experience. Thus, a likert scale questionnaire was delivered to them in order to rank their experience selecting 1 to 5 point scales i.e. from low to high respectively.
To evaluate the learner’s satisfaction, seven questions are asked:
The results are very encouraging, indicating a positive attitude towards the proposed GA-based approach (Fig. 11).
Conclusion and perspectives
This work focused attention on generating an adapted curriculum sequence according to the learners’ context, which is an NP-hard combination problem.
The proposed approach is based on two levels of adaptations: the first level consists of carrying out a concepts sequencing that aims at generating an adapted concepts sequence according to the learner’s target, his/her previous knowledge and the pre-requisites relations between the learning concepts. The second level of adaptation uses a GA-based algorithm to generate the final curriculum sequence which best meet the learner’s contextual requirements.
Experiments on 12 simulated datasets show that the proposed algorithm gives promising results. From a pedagogical perspective, positive learners’ feedback and high acceptance towards the proposed approach is indicated.
In future work, we will focus on the semantic representation of the domain knowledge and the improvement of the algorithm’s performance.
Footnotes
Acknowledgments
The authors wish to pay their sincere gratitude to Prof. Amer Draa for his expert suggestions and for his assistance.