
Abstract
Depression has become one of the most common public health issues. Several people with depression rely on social media to express their grief. The text data generated by these users can be exploited to promote study in this area in order to detect early-stage depression and provide support. However, to develop a reliable automatic depression detection system, the social media text cannot be used directly as there is a lot of irrelevant, inaccurate, and noisy information available. Moreover, the basic preprocessing steps which are used with most of the machine learning models have limited functionality and thus lead to lots of information loss. This loss of information is not affordable especially in the domain of affective computing (mental health) for text. In this paper, we present various preprocessing techniques for depressive text, DPre, to obtain readable text from raw and noisy tweets. This method can help in minimizing the loss of information and expressions hidden in the raw tweet. Moreover, the processed and clean text will be ready to input into any machine learning algorithm. The readability of the processed text is evaluated and compared with raw tweets using four readability scores: Flesch Reading Score, Flesch_kincaid Score, the Coleman-Liau Index, and Dale_Chall Score. Compared to basic state-of-art preprocessing methods, the proposed method significantly improved the readability score.
Introduction
The problem of depression is fast becoming a major public health issue in the 21
Textual data analysis may provide the foundation for research in a wide range of domains, from science to engineering, health domain, decision-making process, and management to process control. Mood disorder, particularly depression has become one of the leading causes of suicidal attempts. With the rise of social media, things are moving fast. Many approaches integrating machine learning algorithms and text mining techniques have been developed in recent years to detect early signs of depression. Therefore, it is essential that information rendered to learning algorithms is prepared at a level that a large amount of correct information can be manipulated by machines. Higher readability has been linked to improved knowledge retention and understanding [13].
Over the last 10 years, there have been several significant advancements in the underlying algorithms and methodologies that have followed the exponential expansion in practical applications for machine learning. Also, there has been a significant increase in social media platforms such as Facebook, Twitter, etc. in recent years. These platforms provide enormous amounts of big data [4, 5]. These data may then be collected in massive quantities and used to train machine learning and deep learning algorithms that will help in decision-making for various purposes. The clean text data has a significant impact on the algorithm’s performance. The algorithm may behave unpredictably due to inconsistent or noisy data. Thus, if data is not preprocessed carefully, the performance may suffer and output will not be as expected. Improving the prediction of computational models’ readability and understandability in the data is the highest priority. The vocabulary used by the people on social media is very casual and friendly. Identifying the real meaning is difficult due to sporadic, short text type (eg. w8, gud, F9, etc.), a short length, and slang content of social media text. Social media textual data give rise to a variety of applications and these all require a large amount of processing [6].
Moreover, the basic preprocessing steps which are used with most machine learning model are not sufficient as it leads to lots of information loss. This loss of information is not affordable, especially in the domain of emotion and mental state recognition. Hence, in this paper, we propose various depressive text preprocessing techniques, DPre, (such as hypertext removal, special characters removal, slang words handling, contraction handling, segmentation of complex words, replacement of elongated words, spelling check, language translation, and negation handling) to make the raw and noisy tweets clean and ready to be fed to any machine learning algorithm. It improves the text’s readability and minimizes the loss of information and expressions hidden in the raw tweet. The readability of the processed text is compared with raw tweets using four readability scores: Flesch Reading Score, Flesch_kincaid Score, the Coleman-Liau Index, and Dale_Chall Score.
The rest of the paper is organized as follows. Section 2, presents the related work and Section 3 describes the standardization techniques used in preprocessing the text. Section 4 discusses the various performance measures and presents the comparative results. Finally, Section 5 brings the conclusions and scope for future work.
Related work
User-generated text dominates the social media platforms, which are both loud and sparse. As a result, data gathered from social media must be preprocessed to remove noise, otherwise it may result in information loss [7]. Several health domain kinds of research [8, 9] have been emerging with creative and distinct possibilities as well as with various concerns for researchers. In particular, user-generated content on social media and its network structures are creating a huge impact on the regulation of health services. Therefore, it is important to understand social media content in an accurate manner.
In recent years, several researchers proposed various approaches to integrate machine learning algorithms, NLP techniques as well as text mining techniques to detect the emotional state of the user at an early stage and prevent suicidal attempts using social media [10, 11, 12]. These approaches have proven to be successful and affordable when compared to traditional ways, as well as to decrease restrictions and help in clinical assessment in a more dynamic manner. Simultaneously, individuals are used to sharing their inner feelings or thoughts on social media. The vast corpus has a variety of information expressing emotions such as grief, frustration, and breakdowns, all of which might indicate depression.
Singh et al. [13] experimented with various preprocessing approaches on twitter data that showed improvement in model accuracy. They handle slang words by using an n-gram language model and substituting them with the correct word. They also performed the common preprocessing steps such as removal of special characters, punctuation, URLs, word segmentation, and spell checks. Often users express their opinions or emotions about an entity/product/topic by using emojis or emoticons. It has become increasingly popular on social media, eCommerce sites, and blogs. Fernández-Gavilanes M et al. [14] formed a newer emoji sentiment lexicon based on the definitions provided by emoji founders Emojipedia, as well as lexicon different versions. Ghag et al. [15] experimented with a movie dataset and evaluated the effects of removing commonly used words known as stopwords (such as “the”, “an”, “a”, and “of”) on various sentiment identification models. The authors found that deleting stopwords improves classification accuracy for the classic sentiment classifier. Schofield et al. [16] explored the impacts of preprocessing in sentiment classifiers. The author experimented with common preprocessing techniques such as stemming and stop word removal. The results are ineffective or have very little effect. The authors suggested that only standardized processing techniques would not help in understanding the text, rather preprocessing techniques must be defined as per the domain requirements.
Emojis are frequently treated as noise in semantic classification tasks, and they are often removed from the dataset during the pre-processing step [17]. Emojis, on the other hand, include semantic information due to their widespread use and variation. The research that has been done on using emojis for emotion analysis and sarcasm detection shows that using the semantic information they provide is advantageous [18, 19].
In another study, Phan et al. [20] investigated the use of tweets to detect real-time drug misuse. The authors used a dataset of registered and unregistered medications, as well as original content from 31,478 tweets. For this study, the authors used various machine learning techniques such as Naïve Bayes, Random Forest, and Support Vector Machine (SVM) classifiers for training. In this process, the authors do not use any preprocessing. The final model produced 74% of precision on unseen data. The constructed classifier has been put to the test. Later on, the proposed text preprocessing study comprised using TF-IDF (Term Frequency-Inverse Document Frequency) to represent the significance of a word in a specific post and enhance accuracy. In this study, they used Mechanical Turk to collect large volumes of data. Several studies [21, 22, 23] have been conducted on emotion categories (such as happy, sad, anger, joy, etc.) to identify emotions expressed in text with basic preprocessing steps and hence shown lower accuracy and precision. In [24], the VAD (valence, arousal, and dominance) values for each sentence are learned by training the EMO Bank dataset. This dataset is already annotated with VAD values. The authors applied the basic preprocessing task to the Twitter dataset and generated VAD scores using the trained model against each sentence. The results (R2 score) are not good for almost each regression model apart from the Random Forest. The findings interpret that due to the basic preprocessing step; the data was not properly cleaned, thus not learning the correct word embeddings and resulting in poor performance on the regression models.
In all the approaches discussed above, it is observed that before feeding the textual data to any machine learning model or word embedding techniques, the text should be as clean and understandable as possible, especially when working in the domain of emotion recognition or mental health. For instance, the word embedding techniques treat the word “please”, “plaese”, “pls”, “pleeeeeaase” and “plssssss” in different manners. Moreover, either they ignore the unmatched words or they generate different vectors for each of them. However, the tweeter wants to convey the same meaning while using any of these words. Also, when someone elongates a word or uses some native language word, that means he is emphasizing and hence, more intense sentiment or emotion is hidden. The following sections discussed various techniques to overcome the limitations and handle the observations.
Proposed framework: DPre
Language plays a key role in understanding the motive behind it. Therefore, it is important to understand the linguistic signals when constructing language technologies in various fields. Handling text is an important task, if not done correctly, it may lose the information. In the domain of affective computing for text, this loss of information is not affordable. Hence, to preserve all expressions hidden in the text, a number of preprocessing steps are proposed in the paper to clean the raw text decently. Subsequently, it makes the raw tweet more readable and ready for any machine learning algorithm. Moreover, it preserves most of the information and expression which are important in the domain of emotion recognition and mental health.
As illustrated in Fig. 1, DPre processes the tweets through a sequence of steps to remove all kinds of noise and make them clean. In this procedure, it uses a number of corpora/dictionaries/datasets such as NLTK word corpus [25], WordNet corpus [26], Slang word dictionary, Contraction word dictionary, Emojis/Emoticons dictionary, and Sentiment140 dataset [27]. Slang words, Contraction words, and Emojis/Emoticons dictionaries are created by collecting data from different online resources. The purpose of the research is to clean the tweets. Hence, we selected a dataset of 1.6 million tweets (Sentiment140 dataset) available on Kaggle. These tweets are annotated with 0 and 1 as negative and positive sentiment. We considered only tweets and ignored classes. However, the information about classes can be used to identify mood disorder patterns using psychological theories and machine learning techniques.
DPre: Pre-processing techniques for depressive text.
Using these corpora and dictionaries, DPre performs a number of steps such as hypertext removal, special characters removal, slang words handling, contraction handling, segmentation of complex words, replacement of elongated word, spelling check, language translation, and negation handling (as shown in Algorithm 1).
Algorithm 1: DPre(text): {t1=remove_hyperlinks(text) t2=remove_sp_char(t1) t3=change_slang(t2) t4=change_contractions(t3) t5=emojis(t4) t6=word_segment(t5) t7=change_elong_word(t6) t8=check_spell(t7) t9=lang_trans(t8) t10=handle_negation(t9) return return t10 }
Algorithm 2: remove_hyperlinks(text): {Check(text, ’http[s]?://\\S+’, \"\", Multiline = True) Check(text, ’www.\\S+’, \"\", Multiline = True) Check(text,’\\S+.com[/\\S+]*’, \"\", flags Multiline = True) }
Algorithm 3: remove_sp_char(text): {Create list bad_chars = [’;’, ’:’, ’!’, "*", "#", "@", "$", "%", "
Though in English, space or punctuation marks are treated as word boundary characters. Tweeters do not follow the formal English guidelines and sometimes multiple words are used together for hash-tag. For instance, the word “thedecisionwasfair" can be processed word-by-word as “the decision was fair”. Generally, # and @ associated words are multiword tokens. Nevertheless, these words cannot be ignored as they may have some affect (emotion) related information. Therefore, word segmentation is an important preprocessing step in high-level NLP tasks. The same has been implemented using dynamic programming based python API wordsegment. To reduce the time complexity, this function segment() is applied only if the word is not a valid word according to WordNet corpus and it consists of alphabets only.
For instance, let the input word is “@comeagainjen”.
After applying word segmentation, it becomes “come again jen”.
Algorithm 4: change_elong_word(text): { For each word in text: If word not in WordNet: If word contains only alphabets: Count consecutive occurrence frequency of each character & append the character in a list S and frequency in list S_count
For instance:
text = [“good mornnnninggggg everyone"]
S = [’m’, ’o’, ’r’, ’n’, ’i’, ’n’, ’g’]
S_count =[1, 1, 1, 4, 1, 1, 5]
k = 2 #as n and g are repeated more than 2 times
m = 2k = 4 #possible combinations
b=binary(m-1) =binary (3) = 11 # binary equivalent
So, 4 words are generated as
[1,1] ->[‘m’, ‘o’, ‘r’, ‘n’,‘n’, ‘i’, ‘n’, ‘g’,‘g’]
[1,0] ->[‘m’, ‘o’, ‘r’, ‘n’,‘n’, ‘i’, ‘n’, ‘g’]
[0,1] ->[‘m’, ‘o’, ‘r’, ‘n’,‘i’, ‘n’, ‘g’,‘g’]
[0,0] ->[‘m’, ‘o’, ‘r’, ‘n’, ‘i’, ‘n’, ‘g’]
Final combinations = [“mornningg”, “mornning”, “morningg”, “morning”]
After checking in WordNet, output obtained is “good morning everyone”
Algorithm 5: check_spell(text) {For each word in text: If word not in WordNet: If word contains only alphabets: newword = Spell_checker(word) text = replace(word, newword) }
Algorithm 6: lang_trans(text): {For each word in text: If word not in WordNet: If word contains only alphabets: If POS_TAG(word) is not NOUN: newword = language_translate(word)text = replace(word, newword) }
Algorithm 7: handle_negation(text) {If a sentence contains the word ‘not’: Flag = 0 For each word from occurrence of “not” till end of sentence: If subsequent word = Adjective (JJ) or Adverbs (RB) or Verb (VB): If antonym (subsequent word) exists: text = replace([“not”, subsequent word], antonym (subsequent word)) Flag = 1 else: n_w = obtain antonym(synonym( subsequent word)) text = replace([“not”, subsequent word], n_w) Flag = 1 If Flag==0: For each word from occurrence of “not” till start of sentence: If word = Adjective (JJ) or Adverbs (RB) or Verb (VB): If antonym (word) exists: text = replace([word, “not”], antonym (word)) Flag = 1 else: n_w = obtain antonym (synonym(word)) text = replace([word, “not"], n_w) Flag = 1 If Flag==0: Remove the sentence }
For instance, consider the following sentences:
Example 1:
Sentence: “Today my mood is not good”,
Tokenization: [‘Today’, ‘my’, ‘mood’, ‘is’, ‘not’, ‘good’]
POS Tagging: [(Today, NN), (my, PRP), (mood, NN), (is, VB), (not, RB), (good, ‘JJ’)]
Word after ‘not’: [good, ‘JJ’]
Antonym using WordNet: [‘evil’]
New Sentence: [Today my mood is evil]
Example 2:
Sentence “John likes the blue house not the at the end of the street”
Tokenization [‘John’, ‘likes’, ‘the’, ‘blue’, ‘house’, ‘not’, ‘the’,’ at’, ‘the’,’ end’, ‘of’, ‘the’,’ street’]
POS Tagging [(John, NNP), (Likes, VBZ), (the, DT), (blue, JJ), (House, NN), (not, RB),
(at, IN), (the, DT), ( end, NN), (of, IN), (the, DT), (street, NN)]
Word before ‘not’ is: [ Likes, VBZ]
Antonym using WordNet is [‘dislike’]
New Sentence [John dislike the blue house at the end of the street]
Example 3:
Sentence “I am not going to forgive him”
Tokenization [‘I’, ‘am’, ‘not’, ‘going’, ‘to’, ‘forgive’, ‘him’]
POS Tagging [(I, PRP), (am, VBP), (not, RB), (going, VB), (to, TO), (forgive, ‘VB’), (‘him’, ‘PRP’]
Word after ‘not’ and ‘going to’ is: [‘forgive’, ‘VB’]
Antonym using WordNet is [‘blame’]
New Sentence [I am going to blame him]
Table 1 presents excerpts of the clean text obtained after applying preprocessing step, DPre, as discussed above.
Excerpts of twitter dataset after preprocessing
Evaluation results of readability score for various categories of DPre
Assessment of readability parameters
A readability score can be used to assess the understanding of a text document. Flesch-Kincaid, Flesch Reading Ease, SMOG, Fry, Fog, and Dale-Chall are some of the most commonly used equations. Each of these formulae employs a different mathematical equation to calculate the required reading grade level for the reader to comprehend the written material [30]. We used four metrics to assess the document’s readability: Coleman-Liau index, Dale-Chall index, the Flesch Reading ease, and the Flesch Kincaid score. Below is a brief overview of these measurements.
For instance, if the Flesch Reading Score is 85, it indicates that a person can understand sentences with 85% ease or more.
For example, a text document with a 2.9 score on this test, would be considered understandable by anyone with a 2nd or 3rd-grade reading level.
Results were examined for 500 sentences in the Twitter dataset. A readability test on social media text provides an appropriate level of statistics that presents a significant level of insight into document reading level. The results displayed in Table 2, show a significant level of readability improvement in our dataset after applying DPre.
When data is fed into a learning algorithm, it needs to be presented in an easy-to-understand manner. As social media text is very noisy, first we need to handle preprocessing tasks. Its readability is checked so that clearer and more informative language vectors can be provided to the learning algorithm. Moreover, there is some restriction on the minimum number of words required for calculating the readability score. So, tweets are fed in a batch of 50 tweets each. Also, we created four categories for obtaining the results:
Category 1 – considers the raw tweets.
Category 2 – considers the text after applying hyperlink removal, special character removal, slang replacement, contraction replacement, Emojis/Emoticons replacement, and elongated word replacement.
Category 3 – considers the text after applying hyperlink removal, special character removal, slang replacement, contraction replacement, Emojis/Emoticons replacement, word segmentation, and elongated word replacement.
Category 4 – considers the text after applying all proposed preprocessing steps.
(A) Flesch Reading Ease (FRE) readability for each set of sentences. Lower scores indicate less readability. (B) Flesch Kincaid Score – Lower scores indicate high readability. (C) Coleman-Liau Score – Lower scores indicate high readability (D) Dale-Chall (DC) readability for each set. Higher scores indicate less readability.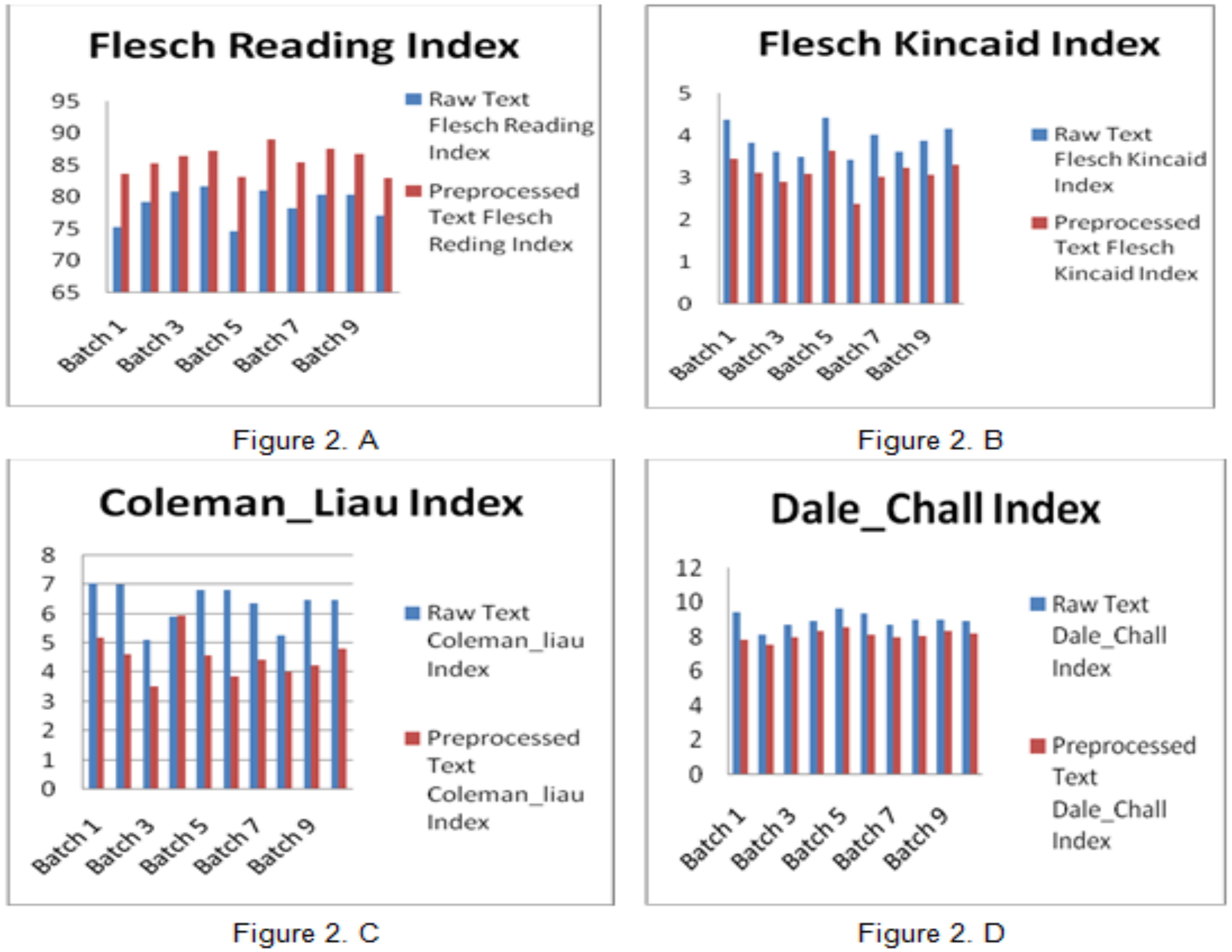
As shown in Fig. 2A–D, there is an increasing score for Flesch reading ease in the processed text while in the other three measures, the score is in decreasing pattern for the processed text. Therefore, readability improved if the Flesch reading score is high on the processed text and extremely readable if the rest measures score is less on processed text.
As a result, the textual data created by depressive users can be used and exploited appropriately in the development of systems for detecting depression. However, if such data is used without appropriate preparation, the results may be unacceptable. Hence, we conducted a comparison examination of several data preparation approaches in the depression dataset so that they can be used effectively in identifying depressive symptoms.
Often people who suffer from depression rely on informal or open forums, like social media, to communicate about their mental health state instead of seeking the expert help, maybe due to a sense of shame, humiliation or lack of understanding about the disease. As a result, the textual data created by these users can be used in the development of early-stage depression detection systems. Using such data without sufficient preparation is risky as social media text is extremely noisy. Because of the open platform, individuals use informal language such as slang and short abbreviations, etc., which makes it critical to efficiently preprocess the textual information, otherwise, the information generated by textual form on social media would be lost. However, such platforms are quite informative and therefore, essential to gaining an insight into an individual mental state or activity. This information may help clinicians and psychologists to make better-informed decisions and help people to take considerable and preventive measures from it.
In this paper, we have proposed high-level preprocessing techniques, DPre, such as hypertext removal, special characters removal, slang words handling, contraction handling, segmentation of complex words, replacement of elongated words, spelling check, language translation, and negation handling. It is observed that adequate preprocessing techniques play an important role in cleaning the text and improving the readability of the document. Better the understandability of the data and better the computational models’ performance. And, hence, it can help the patient, his relatives, and medical practitioner in a better way.
In future, we plan to use these preprocessing techniques with depression datasets with multidimensional feature sets. In order to achieve high accuracy in early-stage depression detection predictive models, other preprocessing approaches will be investigated as well.