
Abstract
The first version of the RLGame ecosystem, which features a collection of conventional Artificial Intelligence and Reinforcement Learning techniques for learning to play (and, actually, playing) a board game, was adopted for the development of the second version that supports Multiagent Reinforcement Learning and a sequence of games. We present an experimental comparison of a variety of algorithms which are available within the ecosystem and comment on the potential to investigate single-player vs multi-player scenarios, alongside some experimental results which suggest that loosely co-ordinated game play can be superior to fully co-ordinated game play.

Introduction
Reinforcement Learning (RL) is a branch of Machine Learning (ML) and of the wider field of Artificial Intelligence (AI). RL is based on the concept of employing an agent which perceives the current state of the environment and attempts to find the most efficient action to influence the state of the environment by evaluating a reward function [1].
AI has been successfully used in the development of strategy games [2, 3] with the minimax algorithm [4, 5] being considered as a benchmark. A pioneering attempt in self-learning techniques was demonstrated in checkers [6], but IBM’s Deep Blue made history by beating Yuri Kasparov, the reigning chess champion, in 1996 [7, 8, 9, 10]. Earlier work on backgammon [11] inspired the Deep Blue project while, recently, AlphaGo [12] and AlphaZero [13, 14] dominate the scene.
In parallel with AI developments, computing witnesses the proliferation of all kind of servers, since the first wide area networks (such as ARPANET and BITNET) appeared, including gaming servers too. Today, gaming servers are also widely deployed, with some notable examples in the Internet Chess Servers (ICS), Backgammon, Go, Othello [15, 16, 17]. Gaming servers are primarily aimed at entertainment, yet artificial intelligence researchers have long used them to train and evaluate their algorithms [18, 19].
ML has, for the past 2–3 decades, been steadily rising as the predominantly approach to using AI in strategy games. Sarsa, Temporal-Diference Learning – TD(λ), Monte Carlo and Eligibility Traces are fundamental techniques of RL approaches [1], with (sometimes) neural networks or linear/non-linear approximation functions being also used to estimate reward values in problems where the state-space if prohibitively large.
Multiagent Reinforcement Learning (MARL) [20] is an RL extension whereby multiple agents learn and act in a shared environment, with each of which using RL and individually perceiving the environment and deciding on a course of action, based on the reward function; agents, then, have also to select, among them, which individual action best promotes the group’s interest. This paper elaborates on how an existing RL gaming ecosystem has been adopted to explicitly allow for a variety of multi-agent where decisions are made at the individual level, though impact is felt at the team level.
Having invested substantial software engineering effort [21] in order to design and develop a working gaming ecosystem, which allows two players to fully interact with a variety of pre-developed algorithms, while at the same time being able to implement new playing and learning algorithms with relatively small effort, it was felt that the extra step to equip this ecosystem with a new view, namely that of a player as a “team of agents”, would be large enough from a conceptual point of view (to allow us to experiment with distributed approaches [22] to playing and learning) and, yet, small enough from a technical perspective, so as to make full use of the infrastructure we already had.
The rest of the paper consists of six sections. In the following section we briefly describe the basic game (RLGame) [23] we use as a workbench. We then review the development of the RLGame ecosystem [24]. In Section 4 we review the experimentation section on how individuals and teams perform in the ecosystem, whereas in Section 5 we conclude, before we present the relevant acknowledgements, in the last section.
RLGame description
RLGame is a strategy board game played by two players [23, 25, 26]. The environment of the game is a board divided into squares (see Fig. 1). The size of the board may be
RlGame board.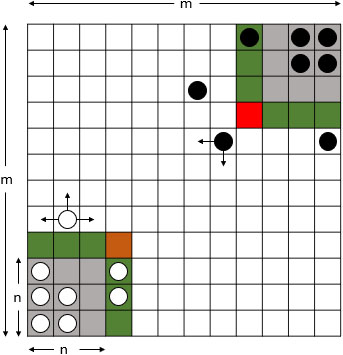
The first version of the RLGame Eco System [24] was developed in Java and consisted of three parts. The first part is the eco server, that provides the environment and the logic of the game on the network. It is also providing a basic chat service for the connected players. It runs as a web service and it is not depended on a particular operating system; it only requires a connected computer, a MySQL compatible database system and a Java 8 (or later) run time. The second part is the eco web client that provides the graphical interface of the virtual environment that the eco server creates. A web server is required for the web client to run over a network, but it can also run on a computer as a standalone web application. The third part is the eco avatar client which provides the interface that an avatar can use to connect to the eco server; it requires a connected computer and a Java run time. A built-in avatar is implemented for testing purposes using a basic RL algorithm. The server of the ecosystem requires a MySQL database that is used for keeping the players’ names, their credentials for connection to the ecosystem and their score. Figure 2 shows the architecture of the ecosystem as described above.
RLGame Ecosystem recommended architecture.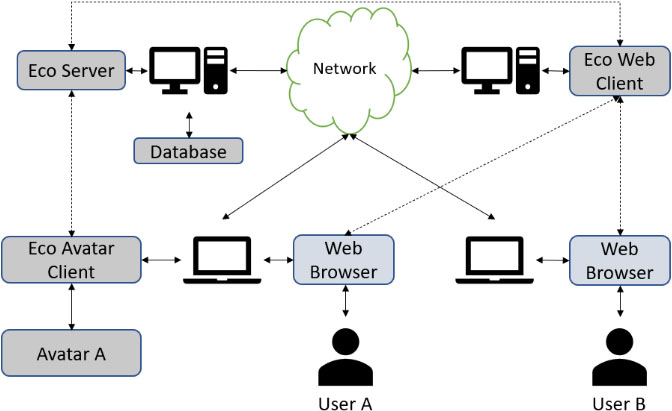
The second version of the ecosystem also includes a multi agent algorithm implementation a feature to allow a sequence of games between two avatars. The implementation of the games sequence feature allows the ecosystem to serve as a research workbench, as it supports experimentations between specially set-up avatars, for example between a simple RL algorithm and a MARL algorithm.
TD(
There is one binary neuron for each square of the board of the game, that indicates that the square is occupied, except for the squares of the two bases. The number of the neurons needed for this information is:
A binary neuron is used to indicate if a player has occupied the opposite’s player base. Four more neurons are needed to indicate the number of pawns that are still in the players’ base.
The total number of the neurons that are used in the input layer for the two players of the game is:
The number of the neurons used in the hidden layer is:
Finally, one neuron is used in the output layer which returns the approximation value [24].
Another approach is used for the calculation of the approximation value in the second version of the RLGame ecosystem, the linear function approximation, as it fits better with the game modeling. A multi layered feed forward infrastructure implemented to manage the neural networks with the ability to use a different activation function for each layer of the neural network [1].
An RL agent is implemented based on the Sarsa(λ) algorithm using eligibility traces [1, 27, 28] and linear function approximation. The RL agent includes the learning and movement selection mechanisms. The MARL agent uses as many instances of the above RL agent as the number of the player’s pawns of the current game. The goal of each of these RL agents is to investigate the best possible move it can perform and suggest it to the MARL agent that finally decides which of the proposed moves is the best.
RLGame Ecosystem architecture used for the experiments.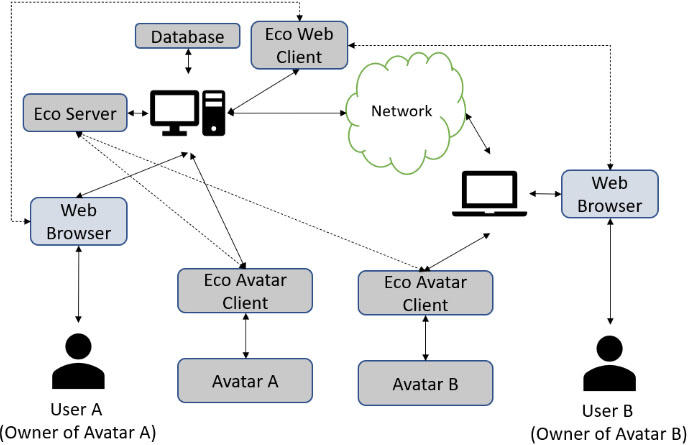
The functionality of the MARL algorithm is summarized as follows:
The MARL agent is informed the current state of the game. The MARL agent applies the appropriate transformations and informs each pawn’s instance of RL agent for the current state of the game. Each RL agent that is assigned to a pawn, suggests to the MARL agent the best movement, based on its training, accompanied by the value of the deviation of the suggested movement from the optimal movement. The MARL agent selects the best movement based on the smallest deviation value and uses that move for the game. The game, after the end of the current round, informs the MARL agent for the new state of the game and if there is a reward for the player. The MARL agent informs each pawn’s instance of RL agent for the new state of the game as well as the player’s reward, if any. The RL agent of the pawn that performed the movement updates its action-value function (based on the reward feedback).
We use the updated version of RLGame Ecosystem to experiment with a view to obtain data confirming the strength of the multiagent algorithm. The ecosystem architecture is shown in Fig. 3, with a server running on a Windows 10 machine alongside the RLGame eco web client and one RLGame avatar client; a competing RLGame avatar client was running on another Windows 10 machine connected to the same local network.
Experiments structure
The experimentation process ran in twelve batches, depending on the board size and the number of pawns each player processes. We used board sizes of 12x12, 9x9, or 6x6 squares and set the number of pawns to 8, 6 or 4. In each case the bases of the players were 2x2 squares.
Each experimentation batch was subdivided in four phases. The first phase ran for 1000 games in total to train the avatars with the basic RL algorithm, with each of the two avatars moving first in 500 games. This initial training does not affect the MARL algorithm in the next phase, which starts with no prior training, but has to face a trained avatar from the first phase. In that phase an untrained avatar using the MARL algorithm plays against a trained avatar using RL algorithm, so both a single RL Agent algorithm and a Multi Agent RL algorithm are trying to reach the same goal, competing against each other. We remind the reader that a single agent algorithm tries to do that by deciding each time the best move that a pawn may perform, whereas the MARL algorithm, in contrast, uses as many single agents as its remaining pawns, with each agent suggesting its best move and the MARL algorithm selecting and executing the best move, among those suggested by its agents. The two avatars competed for a further 1000 games with each avatar moving first in 500. Then, for the third phase the second avatar was also switched to the MARL algorithm. Finally, in the last phase, the algorithms of both avatars switched back to RL algorithm. It should be noted here that the training of the MARL algorithm is not used by the RL algorithm (in the fourth phase); this phase is included in the experiments to determine whether the training gained by the second avatar using the RL algorithm when opposing the first avatar with the MARL algorithm (in the second phase) affects the outcome of a game between two avatars using the RL algorithm. So, we have a total of 9 experimental combinations subdivided in 4 phases each; Fig. 4 highlights the workflow of the experimentation process with data acquired from experiment A-1 (as presented in Table 1).
The table presents the results of the experiments
The table presents the results of the experiments
Demonstration of the experimentation process.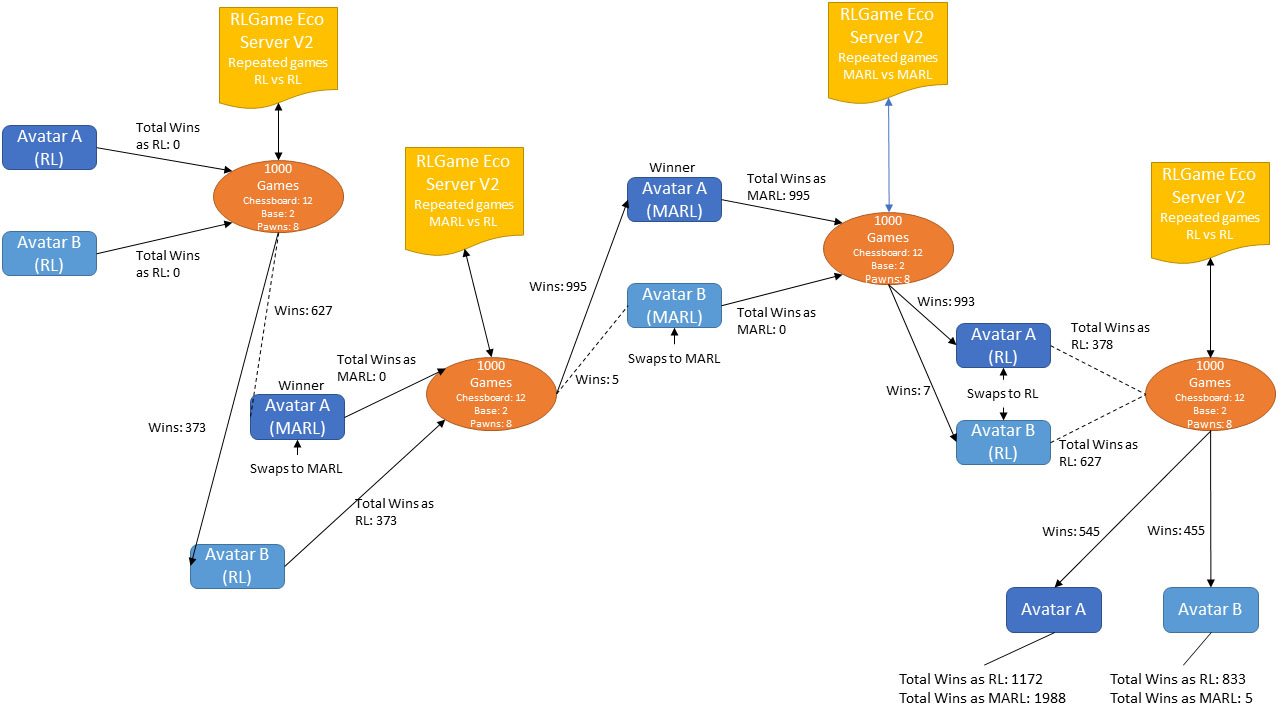
The RL parameters setup of the agent, an instance of which is used either of the RL algorithm or the MARL algorithm (one instance of the same RL agent for each pawn) are the following. The Learning Rate is set to
Results
In Table 1, we present the results of the experiments conducted. Each phase was divided into two parts, in each of which 500 games were played between the two avatars. The bold formatted cell contents in the column captioned as “Algorithm” indicating the algorithm that won the game lot. The red colored numbers in the columns captioned as “A-B”and “B-A” show the scores of the avatars for the 500 games as indicated by which avatar moved first. The bold formatted cell contents in the column captioned as “Sum” indicating the algorithm that won the game lot of 1,000 games.
Avatar-A was the host of the A-B games and respectively Avatar-B hosted the B-A games. As we can see the MARL algorithm was the winner in the most cases where the algorithm used from one or both opponents. RL algorithm won MARL algorithm only in the last experiment (designated as C-3) with a 6x6 board side and 4 pawns for each opponent. We can also see that in the most cases that MARL algorithm won, displaying an almost total dominance. In the last phase of each category, we can see that the wins of the two avatars are split and that the previous training of the second avatar against the MARL algorithm does not affect the outcome of the games.
The Evolution of experiment A-1.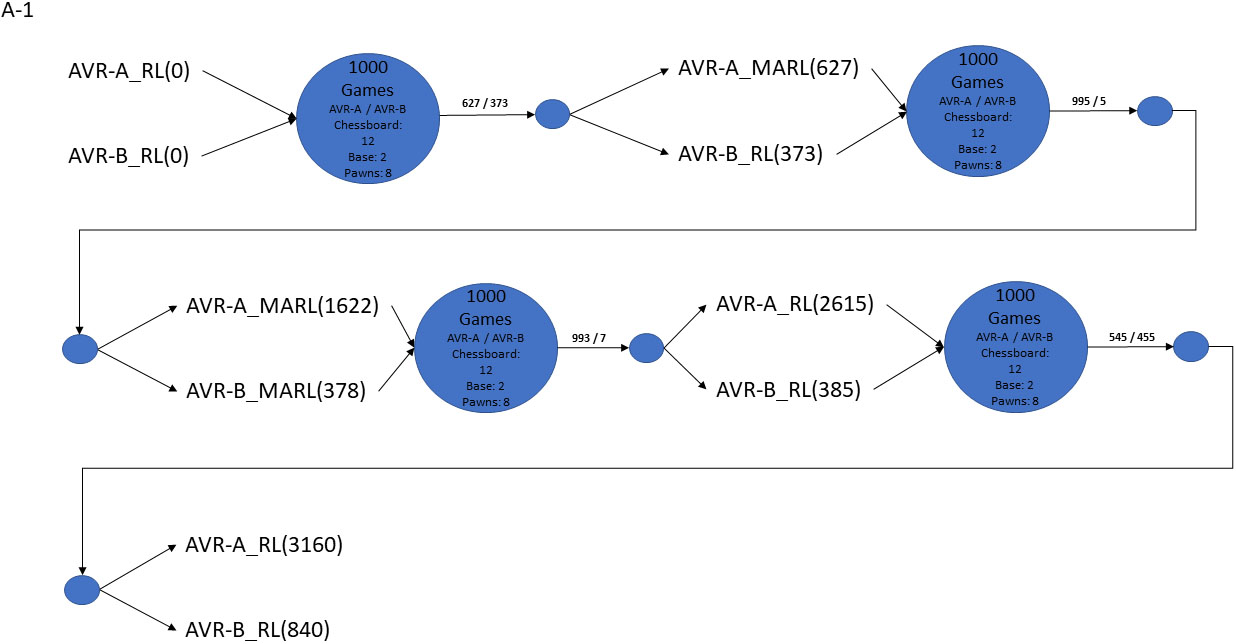
The table presents the results of the additional experiments
The Evolution of experiment C.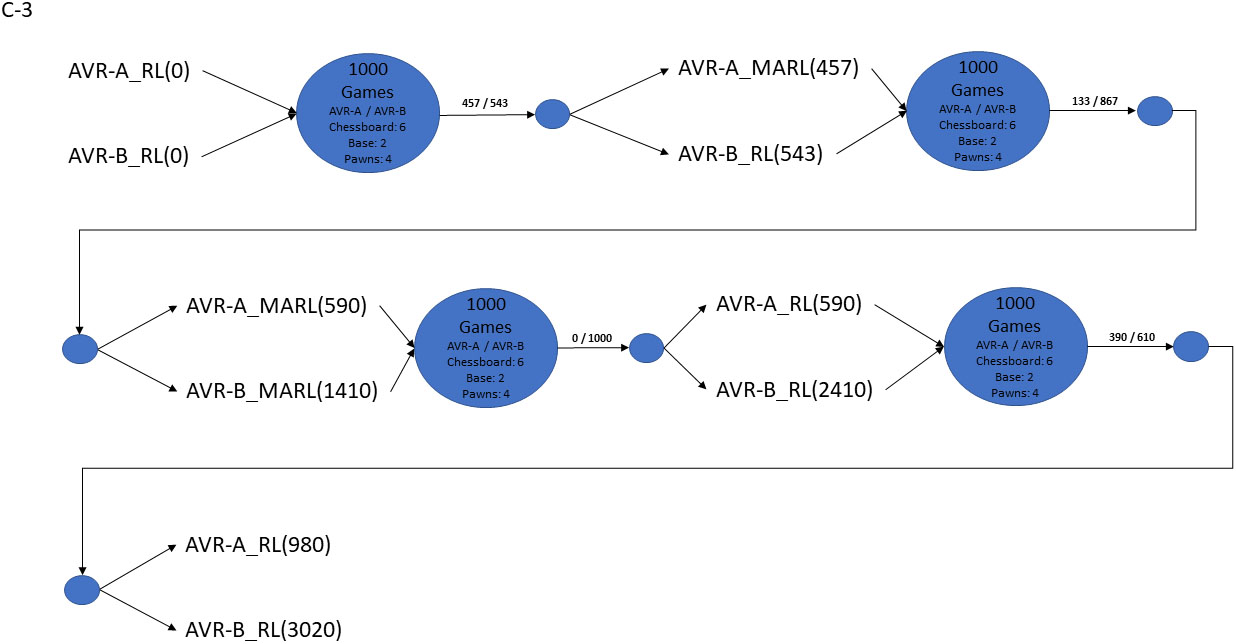
We explain in detail two cases of the experiments conducted. In the first phase of A-1 experiment Avatar A won Avatar B, while both avatars were using the RL algorithm. In the second phase the algorithm of Avatar A changed to MARL algorithm. The training that Avatar A gained from the first phase was not utilized in the MARL algorithm, so the untrained Avatar A played against a trained Avatar B which was using RL algorithm and finally Avatar A won by a wide margin. Figure 5 represents the evolution of the A-1 experiment, also showing the scores for each phase and the total score of the winnings for each avatar. As we can see in the third phase the algorithm of Avatar B switched to MARL algorithm thus the trained Avatar A with the MARL algorithm, won overwhelmingly the untrained Avatar B that was also using MARL algorithm. Finally in the fourth phase both avatars’ algorithms switched back to RL algorithm. In that case Avatar B had gained more training tackling the most powerful MARL algorithm in the second phase than the Avatar A, nevertheless Avatar A prevailed with a slight advantage, suggesting that RL training may require lengthier interactions.
In the first phase of experiment C-3 we note that Avatar B won Avatar A, with both avatars were using the RL algorithm. In the second phase the algorithm of Avatar A changed to MARL algorithm. The training that Avatar A gained from the first phase hadn’t any affect in the MARL algorithm, so the untrained Avatar A played against a trained Avatar which was using RL algorithm. The trained Avatar B won by a wide margin. Figure 6 shows the evolution of the C-3 experiment, also showing the scores for each phase and the total score of the winnings for each avatar. As you can see in the third phase the algorithm of Avatar B also switched to MARL algorithm. The untrained Avatar B with the MARL algorithm, won completely the trained Avatar A that was also using MARL algorithm. Finally in the fourth phase both avatars’ algorithms switched back to RL algorithm. In that case Avatar B had gained more training tackling and wining the most powerful MARL algorithm in the second phase than the Avatar A, Avatar B prevailed by a narrow margin in that phase.
Based on the overall outlook, it was surprising to see RL algorithm winning the MARL algorithm in C-3, so we repeated it with a total of 10,000 games. We present the results in Table 2 and note that the RL algorithm again beat the MARL algorithm, though less pronouncedly this time.
Additionally, we created two more experiments, D and E, to examine how the algorithms perform in completely different board setups. The board side for the experiment D was set to 15 squares as far as the player’s base was of 3 squares size. Respectively the board parameters for the experiment E were, board size: 18 squares, base size: 2 squares, pawns: 8. Results are also presented in Table 2 and it is evident that the MARL Algorithm beat the RL algorithm comfortably.
Conclusion
Our experiments showed that the avatar with the MARL algorithm comprehensively beat the RL algorithm, even when starting from a disadvantaged position (without training). There was a single exception, experiment C-3, which could merit a lengthier investigation to observe whether the MARL agent might be able, at some point, to reverse the game to its advantage. Apparently, a multi agent approach seems to be a powerful technique.
Since MARL techniques are based to a much larger extent (compared to conventional RL) on approximation techniques, we are keenly interested in investigating whether the aforementioned observations on MARL results would still hold while scaling-up the game dimensions (board and base size, as well as number of pawns), or pitting MARL against a conventional minimax algorithm (also implemented in the ecosystem), or against any new algorithm. The motivation is clear: since, in principle, distributed techniques are more expensive than centralized techniques, their resilience should come at the expense of some other interesting metric (for example, accuracy or effectiveness). As a result, this looks like a promising line of research which we intend to pursue.
Footnotes
Acknowledgments
The current RLGame ecosystem has been developed based on a succession of past dissertation projects and is a particularly useful tool for the study and implementation of ML algorithms, especially in RL. As its current version has been implemented with modern software development technologies, it (still) is easily scalable. The first version of the ecosystem supports gaming human vs human, human vs avatar, avatar vs avatar and can be found here