
Abstract
Healthcare informatics is one of the major concern domains in the processing of medical imaging for the diagnosis and treatment of brain tumours all over the world. Timely diagnosis of abnormal structures in brain tumours helps the clinical applications, medicines, doctors etc. in processing and analysing the medical imaging. The multi-class image classification of brain tumours faces challenges such as the scaling of large dataset, training of image datasets, efficiency, accuracy etc. EfficientNetB3 neural network scales the images in three dimensions resulting in improved accuracy. The novel neural network framework utilizes the optimization of an ensembled architecture of EfficientNetB3 with U-Net for MRI images which applies a semantic segmentation model for pre-trained backbone networks. The proposed neural model operates on a substantial network which will adapt the robustness by capturing the extraction of features in the U-Net encoder. The decoder will be enabling pixel-level localization at the definite precision level by an average ensemble of segmentation models. The ensembled pre-trained models will provide better training and prediction of abnormal structures in MRI images and thresholds for multi-classification of medical image visualization. The proposed model results in mean accuracy of 99.24 on the Kaggle dataset with 3064 images with a mean Dice score coefficient (DSC) of 0.9124 which is being compared with two state-of-art neural models.
Keywords
Introduction
The initiation of deep learning models in the ground medical domain and clinical diagnosis aids in the enhanced medical procedures and improved decision-making with image visualization of medical image modalities. The illustrations of abnormal structures such as brain tumour cases all over the world are rising at a rapid rate for certain reasons such as age factors, chemical exposure, radiation etc. [1]. Nowadays, healthcare needs well-organized and reliable practices to analyse diseases such as cancer which reason of mortality worldwide for humans. The best practice for investigating and identifying tumours is MRI (Magnetic Resonance Imaging). Advanced level grades evaluate that in most cases third and fourth-stage tumours are harmful as these are developed in the brain at a rapid rate [2, 3]. In the underlying stage, the tumour does not spread much however in the later stage, there are chances of spreading to parts of the brain. Early diagnosis of a tumour is hence recommended as in the affected part of the brain, cells are destructive subsequently these cells might pass into the circulation systems of the brain and spread into the encircling cells. Consequently, it is imperative to identify the early phases of brain tumours with the most effective accuracy.
Brain MRI Images avail a technique for classification of tumours in multiple classes by means of data segmentation and image detection using models of deep neural networks. Multiclass image classification techniques applied on medical imaging modalities provide the diversity in the available dataset by the inclusion of image cropping, Flips, Gaussian filters, Principal Component Analysis (PCA), colour jittering etc. [4, 5]. and through these techniques capturing significant characteristics of original images can be done. The possibility of improvement in the data visualization entirely counts on the learning strategies and deep learning strategies including data augmentation diminishes the overfitting of the models by training the dataset This technique comprises one of the image pre-processing methods which are considered to be effective in training the dataset with extreme discriminative nature. The abnormality in the brain structure is diagnosed by experts by means of manual methodologies available i.e., visualizations like MRI scan. But the main problem arises when diagnosis by experts is quite time consuming, and more prone to errors. With rise in cases the exhaustiveness for diagnosis also increases and may lead to erroneous decision making, as this is not repeatable procedure so there may be variation in inter and intra reader in MRI scans.
Even though many distinguished approaches have been utilized in earlier works for analysing the abnormalities in MRI scans with fine results but still there is sufficient scope for multiple classes in improvised detection and higher accuracy for better diagnosis by experts. The proposed work provides the non-invasive method using a neural model which will segment and detect the type of tumour from multi classes with higher efficiency and accuracy. Although various existing convolutional neural models have been developed for T1-weighted CT-MRI images with average accuracy, it is still major apprehension leading to misdiagnosis [6, 7, 8, 9]. The proposed neural model will make medical image datasets efficient and affordable in a low-budget economy. The paper delivers following contributions to the existing literature:
It deals with the pre-processing of brain MRI images and further neural image augmentation is performed where the image dataset can be enhanced for training and testing. The proposed methodology encompasses the state-of-art approaches for ensembled EfficientNetB3 architecture with U-net to fine-tune the model for identification of multiple classes of tumours in MRI dataset. The next stage incorporates segmentation and detection of tumours which are further classified into three labelled classes where first-class meningioma tumors, second-class glioma and third-class pituitary tumor with optimization of parameters. The comparative analysis of the proposed model with competitive models of CNN models with the inclusion of fewer parameters.
The paper is classified into five sections, wherein Section 2 explains the literature review. Section 3 describes the material and method description which is utilized in the proposed work and Section 4 explains the proposed method and its results are discussed in Section 5. Section 6 concludes the proposed work with its future scope.
Several neural models have been utilized to segment tumours CT tumours in the brain using MRI scans. Image classification have been done on the multiple classes for identification of abnormalities in the structure which are discussed below in two categories.
Medical image augmentation strategies
Venu (2021) addresses the problem of misbalancing of datasets because of annotations and cost. For that reason, the data augmentation methodology generates the artificial medical images through the generative Adversarial approach called DCGAN (Deep Convolutional Generative adversarial network) with an FID score of 1.28. The experiment performed in the paper demonstrates that the neural network classifier has superior performance and the trained data is done on an augmented dataset [10]. Barrowclough (2021) projected the image segmentation for spline representations implicitly with a deep neural network. The experiment is based on a prediction of control points where the spline function is set on the segmentation boundary and quantitatively compute the standard metrics for loss function on different networks. The dice score was achieved for the average volumetric test with 92% on the medical dataset [11]. Chen (2019) in the paper, uses the co-teaching architecture in the network in command to train the networks based on mutually exclusive distributions of the training of the medical dataset. It further practices cross-validation to choose between the inputs which are selective. The disadvantage of this methodology is the only utilization of the subset for training purposes. The defined strategy improvises the parameters of generalization of neural networks with reference to real and synthetic world noises of training [12]. Yun (2019) introduces the CutMix strategy which arbitrarily cut the rectangular sections from an image and this will be based on masking where the two random images were mixed depending upon a binary mask with almost similar parameters [13].
Brain tumour segmentation and detection
Jia (2020) proposed the procedure for identification of tumours in brain MRIs using FAHS-SVM (Fully Automatic Heterogeneous Segmentation using Support Vector Machine) [14]. The regions for tumours can be recognized by utilizing classification data in a statistical manner and grouping of inherent medical image structure order. The regions for the tumour are defined spatially small beside the constant concerning medical image contented provided that suitable and robust information needs to be available for consequential segmentation. FAHS-SVM technique can accomplish promising segmentation of tumours in unification with a semi-supervised method underneath global and local accuracy structure. The performed experiments emphasise on multiparametric brain MRI indicating the identification of the precise location of the tumour correctly and rapidly. The proposed strategy detects the abnormality tissues in brain MRI and it is adequate for the enclosure of prime diagnostic and clinical specialists in the establishment of clinical decision systems. Rai (2020) experimented with using LU-Net convolution neural network in segmentation of brain MRIs in classifying it as without tumour and tumour. The implemented LU-Net model comprises of not so complex and low layered model from U-Net which specialises in medical image datasets. According to performed experiment, the segmentation and detection of brain MRI deliver the finest accuracy and outperformed the deep neural network models. The image dataset was pre-processed and then augmented before training validation and then the generated augmentations were compared with VGG-16 and LeNet neural models [15]. The level of performance of described neural models is being assessed with performance metrics like precision, recall, F-score, and specificity. The outcome displays that the proposed model surpasses other neural models with an accuracy of 98%. Krishnammal (2019) classified the tumour and localize it accurately through curvelet transform to show feature extraction smoothly and that too through high resolution laterally with the good direction. In the performed experiment using a k-means algorithm, it achieves 100% accuracy from the validation and training phase [16]. In CNN, the training phase requires more time as a large labelled image dataset is the primary condition for model training. The proposed model assesses that the GPU interface handles datasets with higher accuracies.
Bahrami (2020) proposed an efficient convolutional neural network model which comprises of U-Net model, Seg-net model with activation layer SeLU in order to achieve an efficient generation of MRI images. The quantitative approach i.e., MAE (mean absolute error), ME (Mean Error) determines the performance which is more promising as related to atlas-based methods [17]. Although, the efficient Convolution Neural Network deep learning model was assessed on the foundation of ground-truth CT (computed tomography) images along with those of generated synthetic Computed tomography (sCT) medical images using mean absolute error and mean error metrics where
Multiclass image classification of MRI images
Siva Raja (2020) experimented with hybrid autoencoders for classification for MRIs in order to eliminate the noise from MRI image. A non-local filter for mean is utilized after which Bayesian fuzzy clustered method for segmentation is applied to extract features using wavelets packets. It yields good accuracy but it took more time for computation which is inefficient procedure for larger datasets [21]. Kermi (2018) proposed U-Net architecture which is more accurate and automatic technique for purpose of segmentation of MRI medical imaging system. The proposed deep neural model was being trained to slice both Low Grade Glioma and High-grade Glioma volumes [22]. The main objective is to evaluate the parameters of network in order to minimize the loss function. The loss function uses Generalized dice loss and Weight Cross Entropy parameters states the issue of class imbalance in dataset. The duration of segmentation of brain MRI along with the associated components presented that the evaluation performance procedures approve those results obtained are alike to those which are obtained manually by experts even though proposed technique can be enhanced.
Yaniv (2020) proposed V-net architecture (three-dimensional) for Prostate segmentation in CT-MRI imaging which is mostly operative in memory management tasks and or parameters like Accuracy Dice. This prototype uses a macro-structure 3D network [23, 24, 25] constructed on a network over two paths, one is encoder and second being decoder. The architecture is trained by means of distinct loss function called as DSC (i.e., Dice Similarity Coefficient). In prostrate segmentation, the outcome will have 90% less learning parameters along with 90% fewer storage, showing that V-net Light network abridge complex structure three-dimensional segmentation tasks with limited resources available. Togacar (2020) introduces a BrainMRNET model which is a novel CNN architecture for image classification with accuracy of 96.05%. But the major issue with the given experiment is that they are showing good accuracy only for binary classification and for multi-class classification, model is not efficient [26]. Romera (2018) anticipated ERFNet methodology (Efficient Residual factorized Network) which operates factor convolutions over residual connections. They surveyed the method to route around 83 FPS in unique iteration of Titan X then 7 FPS (TX1 Jetson) embedded device in optimization [27]. Raghavendra (2022) proposed the framework using multi-layered stack probability belief classified network for malignant or benign tumour on BraTs image dataset yielding higher accuracy. The medical images are pre-processed using Anisotropic filters and blowing up contrast via histogram equalization. This method outperforms in identification of shape, location and size of multiple class of tumours [28]. Jemimma (2022) projected a novel approach called CWSCO that enabled CNN for the pre-processing of brain tumours by utilizing the noise removal and artifacts in MRI image. The approach applies fuzzy clustering for segmentation of tumuor using the wavelet and scattering transform for feature extraction. Afterwards, Deep CNN model is determined for tumuor classification which is being trained by CWSCO resulting in achieving specificity of 98.59% and accuracy of 95.52% [29].
Materials and methods
This section covers methodologies and the dataset description for the segmentation and detection of brain tumours in MRI images which will be further utilized in proposed methodology.
Dataset description
The Kaggle image dataset consists of CE-MRI brain images which are T1-weighted with approximate 3064 slices for 233 patients among which 1426 are gliomas, 930 pituitary and 708 are meningiomas tumours. The images in dataset have resolution 512
T1 weighted CT-MRI image.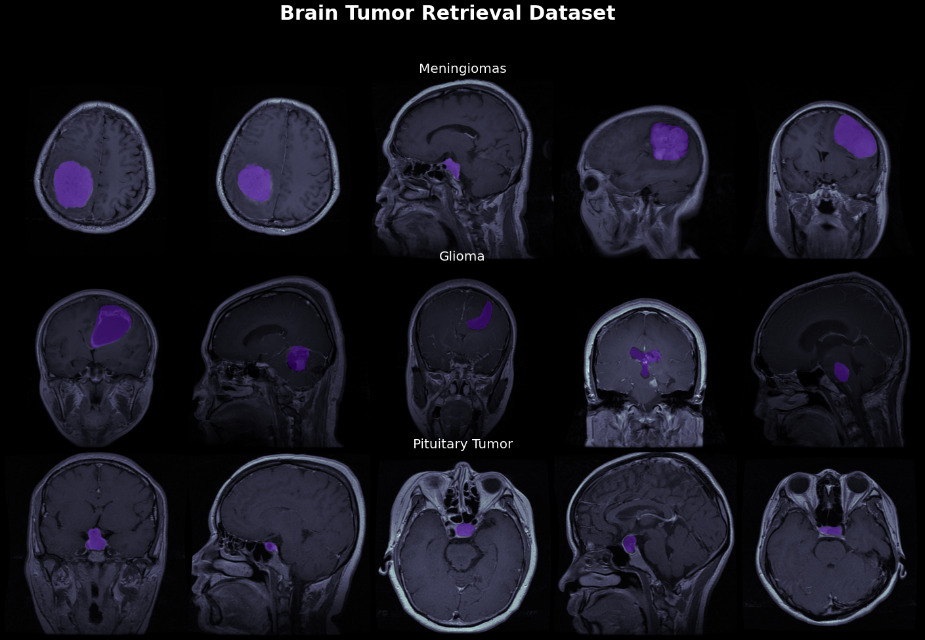
Flow diagram for EfficientNetB3 neural network.
Compound scaling with three dimensions for EfficientNet B3.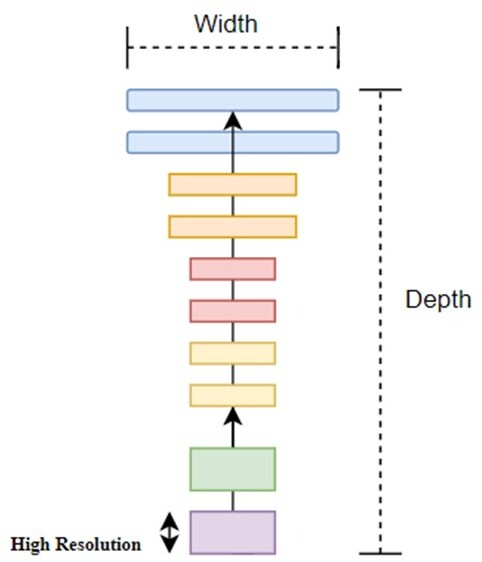
EfficientNet can be described as family of convolutional neural models which are pre-trained on ImageNet Database. The concept was proposed by Mingxing Tan of google research team in year 2019 in the conference paper titled “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” [31]. EfficientNet neural model is an entire baseline neural which will implemented in directive to attain maximum accuracy from image datasets. These are defined as backbone network which truly emphasize on image classification tasks. This architecture utilizes a novel semantic segmentation which is an end-to-end model. This model is basically lightweight model which uses AutoML framework in order to evolute the baseline B0 network and therefore scaling the dimensions for depth, resolutions and width using compound coefficient. These coefficients were then improvise ranging their models from B1 to B7 to attain the dominance over the existing neural models [32, 33, 34].
The EfficientNetB3 architecture is one of the recent scaling methods which works quite well on Mobilenets and Resnet neural models because of the effectivity in this baseline network which therefore leads to developing newer baseline network and scaling the family of the model of EfficientNetB3. As compared to previous neural models, EfficientNetB3 determines the GPipe accuracy via using less parameters as compared to others and run faster on inference. It has been determined that with similar number of FLOPS, the accuracy gets improved in this model. Also, the main reason behind this neural model is to develop CNN model to maintain fix cost of resources for GPU. EfficientNet are scaled to gain the maximum accuracy with same available resources on benchmarking datasets. Many neural models are scaled dimensionally on basis of depth or width, similarly (as shown in Fig. 2), this model will scale randomly which fine-tune parameters manually with altogether three dimensions including depth, width and resolution [35].
Compound scaling
This neural network also called as Efficient Convnet architecture utilizes a technique in its model which is called as compound coefficient which is valuable in uniformly scaling the model on each dimension for width (
Colaco et al. [36, 37] proposes compound scaling process which computes
where
where
Depth coefficients for scaling down the EfficientNet
To calculate the depth coefficient from Eq. (4), for scaling down predefined coefficients are defined as shown in Table 1 from the EfficientNet family with repetitive ceiling function by applying the coefficients 0.9 and 0.8 resulting in similar depth
To calculate the width and resolution coefficients from Eq. (5), constant ratios for all three dimensions need to be set with defined values where
Hyperparameters of the EfficientNetB3
The hyperparameters are set for the EfficientNet B3 architecture which are defined in Table 2 are as follows.
The intricacy of the neural model which rise the overfitting issues the image dataset in the proposed methodology can be bound by not fine tuning all the layers of neural network and for that SGD will be taken into consideration as an optimizer as it will utilize a single sample for probably one iteration which is though randomly selected for stability. The SGD decay is learning rate scheduler which is cast-off for stability convergence [40, 41]. All the layers of this architecture obtain gradient apprises during training i.e., weights of all layers are pre-trained which are formerly classified into diverse classes. So, the fine-tuning of the neural model is completely based on the differences in the distributed datasets, and for that SGD optimizer with SGD learning rate decay being settled as default.
U-Net is fully connected deep network which is essential in compliant in respect to input image with varied size and also in reducing the number of parameters for the neural model. With context to EfficientNet B3, the U-net will be trained from end-to-end method through which the output size of image will be quite similar to input image size. The encoder will be extracting features and capturing the context called as contraction path and decoder enables localization at precise level. The concatenation of encoder and decoder will use convolution of 3
Evaluation metrics
The network model for brain MRI segmentation and detection is entirely based on classification of pixels for meningioma, glioma and pituitary tumours. The EfficientNet B3 in U-Net architecture produces the hyper parameters for network output as binary image (for predicted mask) The network output would be one of the three classes each resulting in “1” for tumour and “0” for non tumour. To evaluate the network performance metrics for this model, the coefficients considered for images in dataset includes Mean loss, learning rate, Dice Score, accuracy (AUC), precision (Pr), recall (Re) [45, 46, 47]. The end-to-end semantic segmentation model will be evaluated on the mentioned metrics. The semantic segmentation will be average score of all mentioned parameters as shown in equation 6 and 7. The calculations for coefficients are done using formulas given in equation below:
TP stands for true positive, FP false positive, FN false negative. Based on these two equations,
where DSC is Dice Score Coefficient,
Equation (10) specifies the cosine annealing scheduler where
EfficientNet family classifies the medical image with enhanced accuracy and in the proposed methodology the neural model will be optimized with U-Net network for improved results for larger dataset.
Hybrid ensembled EfficientNetB3 with U-Net architecture
The EfficientNetB3 architecture illustrates layered description of the model in which first column indicated by ‘i’ shows the number of blocks in network and in column 2 function
Flow for hybrid ensembled EfficientNet B3 with U-Net neural model.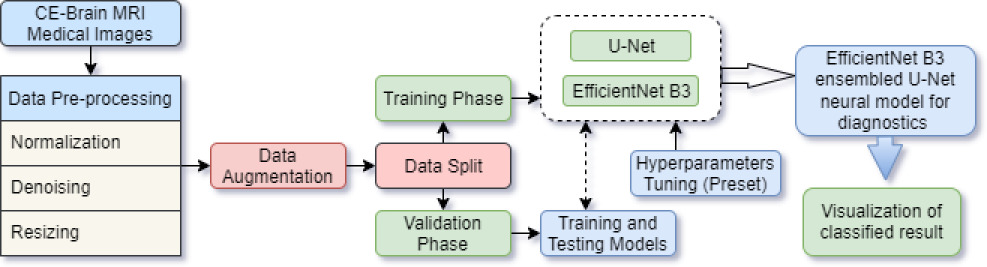
EfficientNetB3 ensembles from U-Net architecture pre-train the network robust model and powerful convolutional neural models. This will skip connections which will permit the localization for pixel level indeed as shown in Fig. 4. For purpose of segmentation in image dataset, test time augmentation is being applied in the test set which is then augmented with resizing and normalization. Average prediction will be computed based on the augmented images and also the output for segmented network will be considered as an image set with similar size for pixel input image linked to probability of fitting into defined class. In order to transform discrete masking of all classes of tumour for 0’s and 1’s, binary task classification with enumerator binary threshold will be applied. As discussed, in Eq. (11), pixel’s value will be customed based on threshold value and initially it will be set to zero.
Here, assuming Bin-TH (
Ensembled EfficientNet B3 with U-Net architecture for identification of Brain MRI images for 233 patients.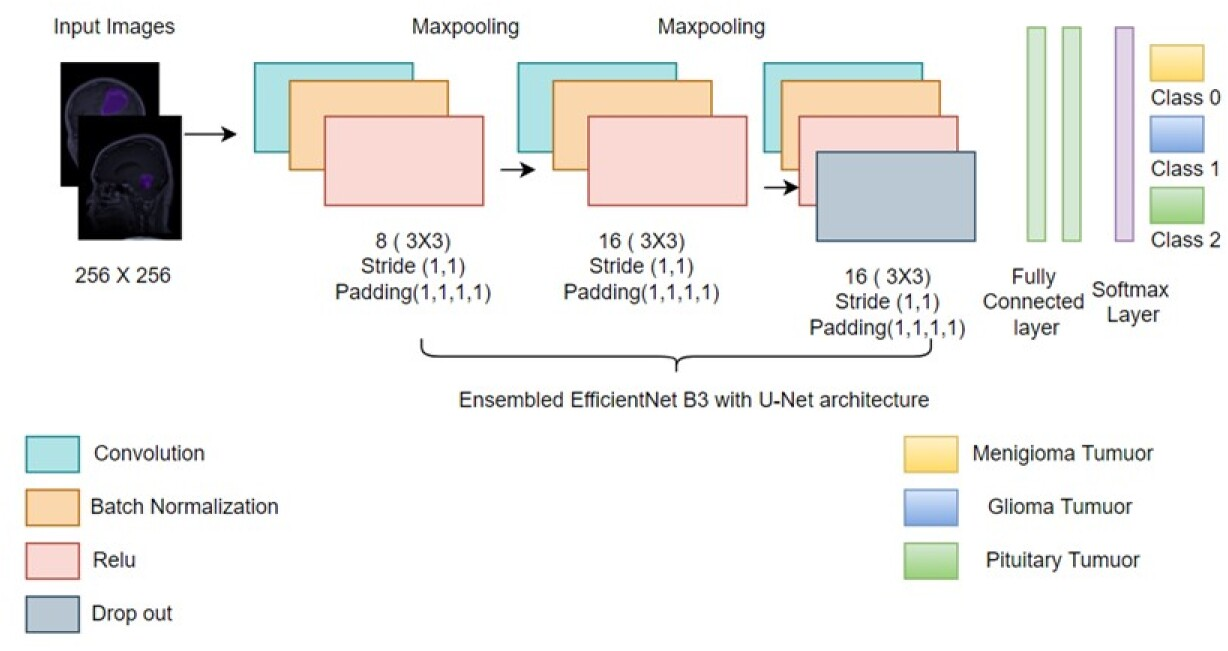
Architecture for EfficientNetB3 neural model with mobile inverted convolution blocks with Relu activation function and predefined filter size.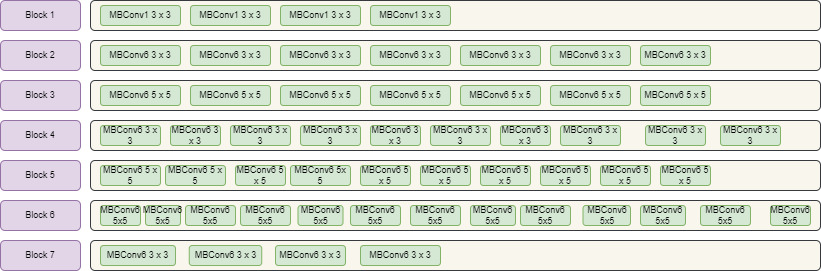
The investigation for metrics calculation of different parameters involved in segmentation and detection of Brain MRI images involves accuracy, DICE score, learning rate, precision and recall of the image dataset. The experimentations were attained through Python environment with OpenCV 2.0 on Windows 10. In the first process of image classification, image augmentation is to performed in order to increase the size of medical dataset. Various operations are performed on dataset which includes vertical flip, horizontal flip, grid distortion etc.
Training of deep neural model involves enormous supervised data for image dataset and in order to achieve this image set, specific training of network need to be done. The image dataset comprises of T1 weighted brain CE-MRI images. The image dataset has been labelled into three sections which comprises of glioma, pituitary and meningiomas tumour. Further these images will be partitioned into training, testing and validation set. The batch size sets to 10 and its pact trade-off between GPU memory and speed of training. Out of 3064 images, training set utilizes 2479 images and test set with 339 images with 246 images for validation set. The learning scheme of the proposed model is Adam optimizer (i.e., Adaptive moment estimation). Initially, learning rate of the implemented model is 0.0001 and it has reduction with defined factors to half in each iteration i.e., 0.5, 0.25 and then 0.125. The number of epochs conducted in training set is 29 with mean loss on validation and accuracy. The proposed model for convolutional neural network has been applied in Phyton through Tensorflow support.
In Fig. 6 , various blocks are defined with MBConvblocks predefined before applying model with 3
EfficientNet family has diverse variations for MBConv building blocks. While moving from upper family of this network , all the three parameters including depth , height and width increases along with its accuracy . EffcicinetNetB3 model outperforms accuracy from the given dataset and it is faster than other neural models. The architecture is divided into 7 blocks with varied MBCov Blocks including size of filter, strides and lastly number of channels as shown in Fig. 6.
Flow architecture for ensembled EfficientNetB3 with U-Net framework for segmentation and detection. The concatenation layer and Upconvolution2D layer includes under the decoder.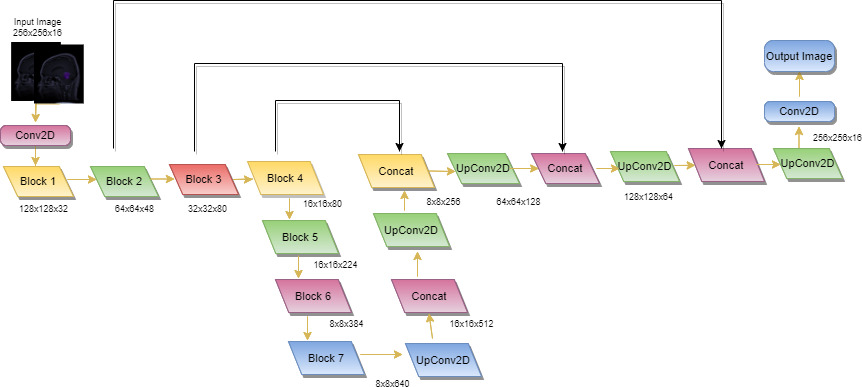
As U-Net architecture is proportional to the contracting path and when hyperparameters are fine-tuned with the EfficientNetB3 neural model so, it act as encoder in same scenario for contracting path as shown in Fig. 7. The role of decoder is to maintain a sequence of Upconv2D (UpConvolution) along with concatenation layer to get segmentation map. It will also describe the resolution of image, number of levels it will pass and channels it includes in forward process for each feature map. It will bilinearly unsampled (MBConv) feature mapping of former logit in encoder by factor of 2 and concatenate with encoder’s feature map with spatial resolution at later stage. In the further repeated process i.e., 3
Results
The investigation for metrics calculation of different parameters involved in segmentation and detection of Brain MRI images involves accuracy, DICE score, learning rate, precision and recall of the image dataset. The experimentations were attained through Python environment with OpenCV 2.0 on Windows 10. In the first process of image classification, image augmentation is to performed in order to increase the size of medical dataset. Various operations are performed on dataset which includes vertical flip, horizontal flip, grid distortion etc. Below are the results so obtained after implementing the augmentation on dataset as shown in Fig. 8.
In this classification process second phase consist of the parameters for mean values of accuracy, Dice score and mean loss in the image dataset. Table 3 shows the parameters achieved from dataset after pre-processing and segregating it on training and validation dataset.
Evaluation metrics for training and validation set for EfficientNetB3
Evaluation metrics for training and validation set for EfficientNetB3
Dice score correlation with threshold for the multi-class classification
Original and transformed image on masking for glioma tumour.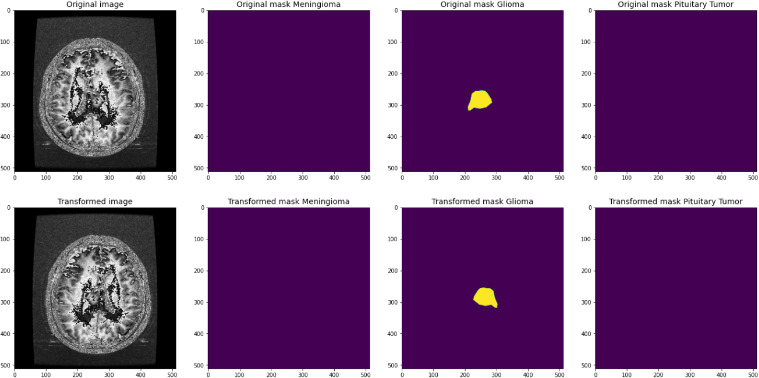
Experiments in its initial phase investigated the graph for loss with respect to number of epochs it went through on both training and validation procedures. The test set for training and validation is divided into 80% and 20% respectively. The graph in Fig. 8a is prepared between loss i.e., through the loss function and epoch to find the loss between train and test data. While in Fig. 8b justifies the Dice score for each epoch for the SGD (stochastic gradient descent) optimizer where the value of momentum set as 0.9. The network is being trained using SGD decay for learning rate with batch size of 16for EfficientNet B3-UNet model. The learning rate initially set as 0.001 where the values are updated with each iteration process in epoch with the cosine anneal scheduler as mentioned above initially set as 1e
(a) The first graph in the figure depicts the loss in the image dataset computed between epoch on x-axis and loss on y-axis. (b) The second graph depicts the dice score of entire image dataset. (c) The third graph shows the accuracy of the dataset. 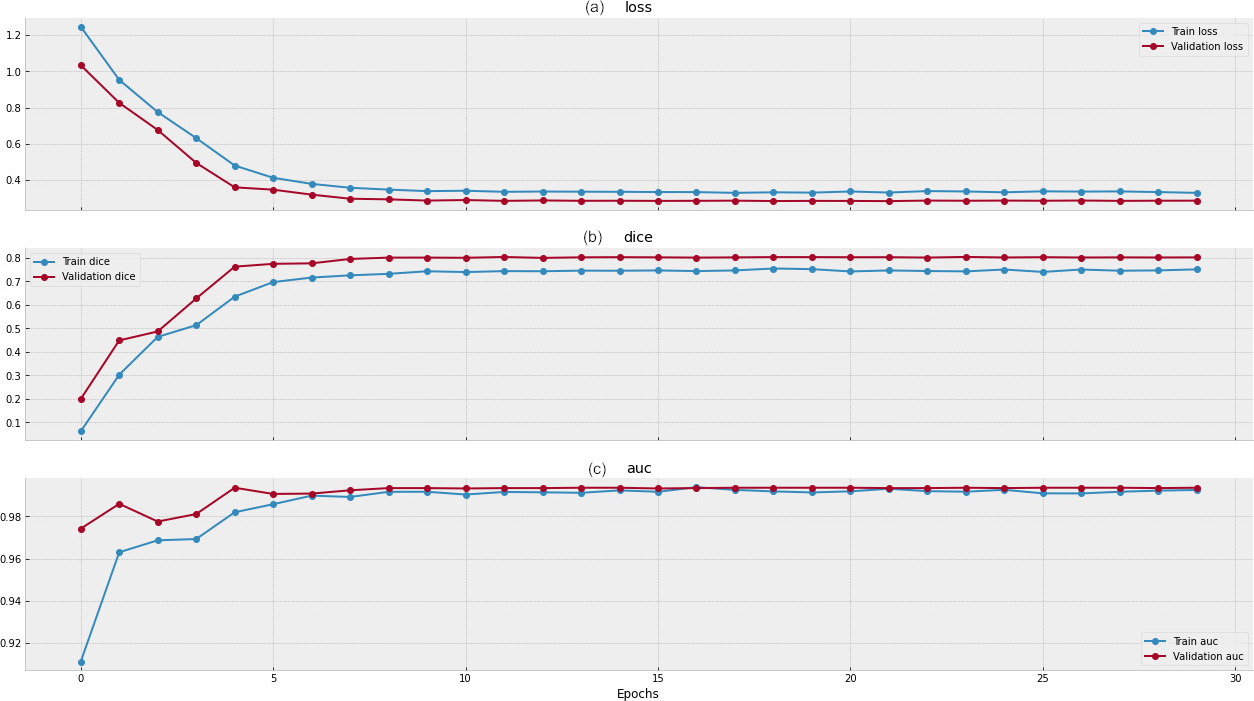
After training of MRI image dataset, dice score of each class will be evaluated based on the size of threshold in order to acquire the class inter-relationships for three classes where class 1 in given Table 3 represents meningioma tumour, class 2 represents glioma tumour and class 3 indicating pituitary tumour as shown in Table 4. This score will provide metrics for region which is being overlapped for the prediction of tumour for the class which it belongs based on size of threshold estimated. Hence, the score is considered as prospect for attribute of function of cost by replacing the class weights and though pixel maps are created to fine tune the hyperparameters of cross entropy.
In the below graphs, image classification models for each class of tumuor for proposed methodology were plotted for continuous output from each class to predict the membership of each one utilizing the threshold values. Each value of threshold points on the curve ranging from (
Dice coefficient score (DSC) for the multi-class classification for proposed model
(a) Threshold and minimum size on x-axis with dice on y-axis for class 1: meningioma tumuor; (b) class 2: glioma tumuor; (c) class 3: pituitary tumuor.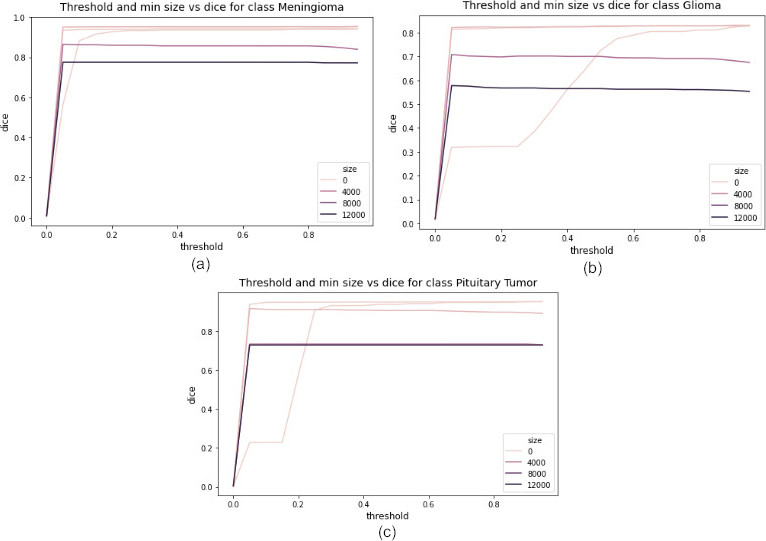
As shown in Fig. 10, the CE-MRI T1-wieghted brain images were evaluated through Dice coefficient based on each class in which class 1 meningioma tumour scores 95.345%, class 2: glioma tumour scores 83.178% and class 3: pituitary tumour 95.199 % and these scores were figured for the prediction with the fitted proposed model with 91.24% mean dice score for all three classes in the dataset after training as shown in Table 5.
The precision and recall curve generated through the proposed methodology by initiating class labels for predicting the probabilities over different thresholds. The measurement of accuracy for purpose of classification in the image dataset are done via precision-recall curve in the increasing order with precision defined on x-axis and recall defined on y-axis for entire range of value lie between 0 and 1. As shown in Fig. 11a, for the class meningioma precision calculated as 0.85 for selected recall threshold value. For glioma tumour and pituitary tumour in Fig. 9b and 9c, precision is 1.0 and recall as 0.99 for selected thresholds.
The proposed model was utilized in segmentation of the brain tumour from classified image for labelled data which has been estimated through the model and for 233 patients with 3064 MRI images U-net model ensembled with EfficientNet B3 model generates the corresponding mask of the tumour with respect to type of tumour and hence performing segmentation of tumour from MRI image. In Table 6, the tumours were mentioned with the corresponding their mask of MRI image defined class-wise. The section shows the results for class wise segmentation of tumours carried out in python on Windows 10 operating system and Intel Core i3 processor with 8 GB RAM. The images depicted the type of tumour through dice overlap and extracted area has been marked separately along with the segmented image.
Segmentation of the three classes of tumours shown in the columns
Metrics for fine-tuning the hyperparameters of neural models in the experiment
Comparative analysis of evaluation Parameters for neural models
Comparative analysis of DSC coefficient for neural models
Various experiments have been conducted with dissimilar configurations as shown in the table. The table showed numerous experiments with different parameters for training and validation. The first model utilizes the proposed methodology EfficientNet as the segmentation architecture for the backbone network. In the second model, ResNextU-Net neural model has been adopted cardinality to adjust the neural model via hyperparameters. It also utilizes the inception model to split and transform the medical image dataset. In the last model, U-Net architecture will allow the pre-trained neural networks which act as a backbone through encoders and up-sampling via decoders. The hyperparameters are fine-tuned in the table in all the neural networks taken into consideration for the experiments to obtain better accuracy. The parameters considered for experiments are the model’s optimisers, which will probably use samples for one iteration through random selection.
(a) Precision-Recall curve for class 1 meningioma tumour; (b) Precision-Recall curve for class 2 glioma tumuor; (c) Precision-Recall curve for class 3 pituitary tumour.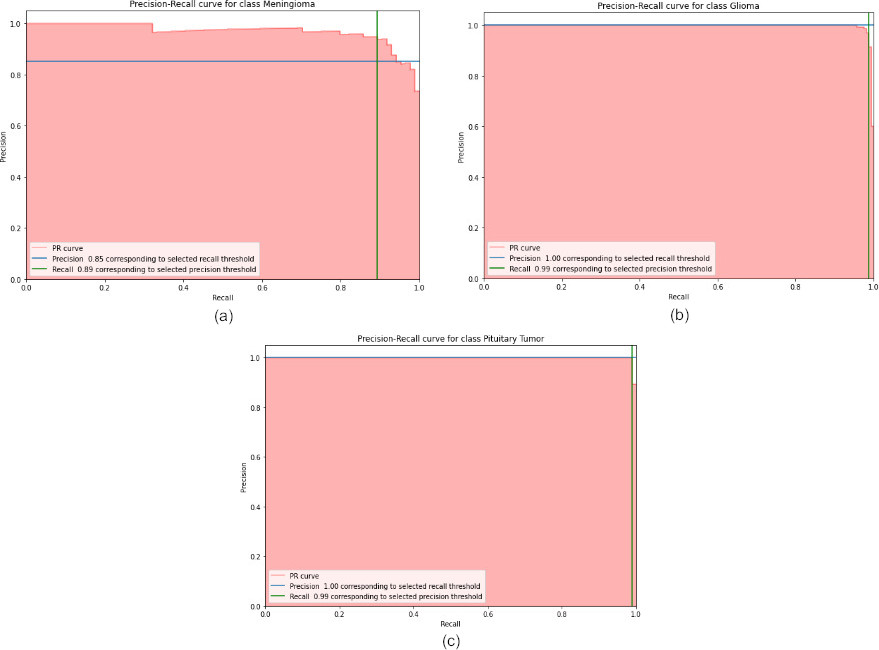
The LR scheduler, i.e., learning rate scheduler via training, reduces the learning rate in the pre-defined schedule and this hyperparameter is critical in terms of stability in a neural network. This decision parameter analyses the loss gradient which needs to be applied to the parameters which are currently in implementation to reduce the loss in the network. The learning rate for the neural model is increased linearly and each value of the LR scheduler is trained for given epochs for a range of values as shown in Table 7. The effective neural network training lies within the range of 0.0001–0.01 and afterwards loss for validation will be quite high for the network.
The Dice coefficient evaluated in this proposed architecture i.e., Ensembled EfficientNet with U-net architecture with other competitive neural models which signifies the positive correlation for segmentation of images in dataset. It will impart the maximum similarity between groundtruth image and predicted image ranging from 0 to 1 as shown in Table 9.
This paper proposed the EfficientNetB3 architecture ensembled with U-Net network which outperform the neural model on the medical image dataset. This methodology proposes a novel method for segmentation of tumour along with its classification in three classes including meningioma tumour, glioma tumour and pituitary tumour. This has been done using and encoder and decoder design which will be entirely rely on EfficientNet neural network which then will be added to feature encoder for proposed backbone structure along with U-Net (i.e., U-shape) network. This methodology utilizes the compound scaling to efficiently scale the dimensions of the MRI images in the open-source dataset. The model implements the utilization of augmentation and then accomplishing the metrics calculation using various training turns. The results of the model show the mean accuracy of 99.24% in the training set and 99.35% in validation set. The mean dice score of all three classes is 91.24% which can further be utilized for evaluation of the tumour segmentation in medical images. The EfficientNetB3 model scale through state-of-art accuracy with fine tuning of hyperparameters in the proposed model. This baseline network ensembled with one of the CNN architectures achieves maximum accuracy and reduced mean loss but it gets penalized with inference time which is quite slow in the computation because of which prediction times increases slightly. When in utilizing the capacity of memory in GPUs get increased, class imbalance problem may also rise due to multi modal dimensions as inputs in the proposed system. For this, in future work the proposed system can be extended with neural architecture like Resnet and Googlenet by fine tuning the parameters and allowing the spatial information to get embed in system itself. In next phase, experiments on improving positive predicted value in matrix during training on image dataset can be done in real scenarios in emerging technologies. As EfficientNet scales down the image via three dimensions so the dataset utilized in the proposed framework contains standard images of 3000 slices and in present scenario no dataset larger than this is available for implementation. In future, if larger dataset will be available then it can be trained for proposed framework to achieve better accuracy.