
Abstract
The rapid development of biometric methods and their implementation in practice has led to the widespread attacks called spoofing, which are purely biometric vulnerabilities, but are not used in conjunction with other IT security solutions. Although biometric recognition as a branch of computer science dates back to the 1960s, attacks on biometric systems have become more sophisticated since the 2010s due to great advances in pattern recognition. It should be noted that face recognition is the most attractive topic for deceiving recognition systems. Popular presentation attacks, such as print, replay and mask attacks, have demonstrated a high security risk for SOTA face recognition systems. Many Presentation Attack Detection (PAD) methods (also known as face anti-spoofing methods or countermeasures) have been proposed that can automatically detect and mitigate such targeted attacks. The article presents a systematic survey in face anti-spoofing with prognostic trends in this research area. A brief description of 16 outstanding previous surveys on the face PAD field is mentioned, from which it is possible to trace how this scientific topic has developed. SOTA in PAD provides an analysis of a wide range of the PAD methods, which are categorized into two unbalanced groups: digital (feature-based) and physical (sensor-based) methods. Generalization of deep learning methods as a recent trend aimed at improving recognition results requires special attention. This survey presents five types of generalization such as transfer learning, anomaly detection, few-shot and zero-shot learning, auxiliary supervision, and multi-spectral methods. A summary of over than 40 existing 2D/3D face spoofing databases is a guideline for those who want to select databases for experiments. One can also find a description of performance evaluation metrics and testing protocols. In addition, we discuss trends and perspectives in the emerging field of facial biometrics.
Keywords
Introduction
Automated face recognition systems have found use in various applications due to their obvious advantages over other biometric modalities, especially in applications such as checking-in and mobile payments. There are many commercial face recognition systems, for example, SmartGate from the Australian Border Force and New Zealand Customs Service, which compares the face of the traveller with the data in the e-passport microchip, Skynet system capable for scanning the entire Chinese population in one second and the world population in two seconds, the Indian National Automated Facial Recognition System (AFRS) designed for security purposes, etc. Such advances have been made possible by the enormous efforts of researchers in the field of facial recognition. As a result, SaaS (Software as a Service)-based facial recognition engines, self-hosted REST (REpresentational State Transfer) API solutions and open-source frameworks and libraries are available to users as facial recognition services. However, the issues of how to protect any face recognition system from intruders remain open, since the motivation for intruders is high as long as it is possible to create facial artefacts inexpensively and easily carry out an attack.
Vulnerabilities in face recognition systems can affect various components. According to the International Standard ISO/IEC 30107-1:2016 [1], nine types of attacks have been reported on Data Capture Module (sensor), Signal Processing Module, Data Store, Comparison Module, and Decision Module, as well as transmission channels between them: (1) attack on sensor, (2) modify biometric sample, (3) override signal processor, (4) modify probe, (5) override comparator, (6) override or modify database, (7) modify biometric reference, (8) modify score, and (9) override decision. Capture device, data transmission and data store are the three main points for a targeted attack. Currently, attacks on the sensor, called presentation attacks, are classified as “direct attacks” (human attacks) and “indirect attacks” (artificial attacks).
The ISO/IEC 30107 standard consists of three parts. Part 1 (Framework) provides the foundation for PAD by defining the terms and establishing a framework with which presentation attacks can be specified and detected. Part 2 (Data Formats) defines data formats for conveying the type of approach used in biometric presentation attack detection and for conveying the results of presentation attack detection methods. Part 3 (Test Methodology) establishes principles and methods for performance assessment of presentation attack detection algorithms. As one can see, the field of research is very wide and cannot be a subject of one article. Here we will focus on the PAD field.
The main terms from the ISO/IEC DIS 30107-3 standard [2] are listed below:
“Artefact” is an artificial object or representation presenting a copy of biometric characteristics or synthetic biometric patterns. “Liveness” is the quality or state of being alive, made evident by anatomical characteristics, involuntary reactions or physiological functions, or voluntary reactions or subject behaviours. “Liveness detection” is the measurement and analysis of anatomical characteristics or involuntary or voluntary reactions, in order to determine if a biometric sample is being captured from a living subject present at the point of capture. Liveness detection methods are a subset of presentation attack detection methods. “Normal presentation” is an interaction of the biometric capture subject and the biometric data capture subsystem in the fashion intended by the policy of the biometric system. Any type of presentation that is not an attack is considered a “normal presentation”. “Presentation attack” is a presentation to the biometric data capture subsystem with the goal of interfering with the operation of the biometric system. Presentation attack can be implemented through a number of methods, e.g. artefact, mutilations, replay, etc. Presentation attacks may have a number of goals, e.g. impersonation or not being recognized. Biometric systems may not be able to differentiate between biometric presentation attacks with the goal of interfering with the systems operation and non-conformant presentations. “Presentation attack detection” is an automated determination of a presentation attack. PAD cannot infer the subject’s intent. In fact it may be impossible to derive that difference from the data capture process or acquired sample. “Presentation attack instrument” is a biometric characteristic or object used in a presentation attack. The set of presentation attack instrument includes artefacts but would also include lifeless biometric characteristics or altered biometric characteristics that are used in an attack.
Presentation attack is a process in which a user can attack a facial recognition system by masquerading as a registered user and thereby gaining illegal access and benefits or trying to avoid being recognized. Presentation attacks are classified into print, replay and masking attacks. The most difficult cases are the attacks with the help of professional masking or professional makeup. Print attacks are based on a single printed photo, a photo from a smartphone or laptop. It should be noted that sometimes user cuts holes in the printed photo for eyes, nose and mouth, providing a partial liveliness of his/her face. This is the easiest way to fool the facial recognition system for many users. The main difficulty in detecting a fake image is the lack of temporal information. Replay attacks provide a short clip with a “live” face. In general, many algorithms are focused on determining the liveliness of a face using various cues.
Depending on the sensors used, the PAD methods are divided into digital and physical domains. Physical domain explores remote physiological signals (e.g., remote Photo Plethysmo Graphy (rPPG) [3, 4, 5]), which makes them less attractive in practice. Currently, digital domain occupies the largest area of research. Methods in both domains have evolved from traditional methods based on hand-crafted features [6, 7, 8, 9, 10, 11] to deep learning methods [12, 13, 14, 15, 16, 17] as well as hybrid methods [18, 19, 20, 21]. Human liveness cues play the important role in PAD. Many algorithms are based on eye-blinking detection [22, 23], face and head movement [24, 25] (e.g., nodding and smiling), or gaze tracking [26, 27, 28]. An original interpretation was proposed in [29], when the authors applied appropriate nonlinear adjustment and hair geometry to amplify the contrast between real faces and attacks using simple Convolutional Neural Network (CNN).
Since 2013, it has been shown that adversarial attacks lead to incorrect classification by deep learning models. This is a serious weakness of deep learning models that provoked an appearance of specific toolboxes (like Foolbox), which contain many SOTA adversarial attacks. Adversarial attacks are usually referred to as digital domain attacks and physical domain attacks. Digital domain attacks generate adversarial facial images using queries, geometric transformations, and examples created by generative adversarial networks. As a rule, the intruders do not have the possibility to directly feed a distorted image into the system, and digital images with adversarial perturbation are always captured by cameras or sensors. Year after year, the adversarial attacks work with more realistic setting, exacerbating the security problem. Adversarial attacks in the physical domain, such as printed glasses or skin stickers, take up less space but are just as successful. It should be noted that face spoofing protection is a multi-tasking problem that includes face recognition, emotion assessment, and aging assessment.
Since 2014, many outstanding surveys have been published. Some of them are presented in Table 1.
Previous surveys on the PAD field (multi-modalities include vision, near-infrared, thermal, depth, multispectral short wave infrared, and polarized imaging or imaging received by specialized light field-based or flash sensors)
With the dominance of deep learning models, evaluation protocols are an important component of learning and a source of improved accuracy. The two traditional protocols, inter-database and inter-database (or cross-database), have been extensively explored in previous surveys (see Table 1). However, the PAD methods have the uncertain gaps between training and testing conditions. This means that, in practice, the trained models can be used in several specific domains and must be robust to various types of attacks. Recently, two additional protocols, called unseen domain generalization [48, 49, 50, 51, 52, 53] and unknown PAD [54, 55, 56, 57, 58], have been actively researched.
The major contributions of this study can be summarized as follows:
Extended taxonomy of presentation attacks is introduced. Lambertian modeling for PAD supports future research within a sensor-based approach. Due to the fact that deep learning has dramatically improved the SOTA performance for many computer vision tasks, this survey examines the evolution and research opportunities of deep learning and hybrid (hand-crafted A comparison of over than 40 public databases classified by various types of presentation attacks is presented. Perspectives on learning are assessed over two main practical protocols (i.e., intra-database and inter-database. The SOTA methods are considered with various application scenarios (e.g., unseen domain generalization and unknown attack detection).
The structure of this survey is as follows. Section 2 introduces the research background, including the taxonomy of presentation attacks and Lambertian modeling. Section 3 addresses SOTA for both digital (feature-based) and physical (sensor-based) PAD methods. A generalization of deep learning methods is discussed in Section 4. Section 5 presents more than 40 databases with normal and attacked images and videos. Performance evaluation metrics and testing protocols are considered in Section 6. Section 7 includes a discussion about trends and perspectives for the PAD field. Finally, conclusions are given in Section 8.
As mentioned in [30], the new security biometric paradigm “forget about cards and passwords, you are your own key” is very attractive to end users, but requires highly accurate techniques in image processing, computer vision and machine learning methods to improve the performance of biometric systems. However, the following implementations have demonstrated the major drawback of biometrics: “Biometric traits are not secrets”. In the last decade, intensive investigations have been focused on the study of direct or spoofing attacks. Spoofing deals with fingerprints, face, iris, voice, or even DNA previously obtained from public data. Spoofing is a purely biometric vulnerability, involving artificially produced artefacts or mimicking the behaviour of genuine individuals. Spoofing is not shared with other IT security solutions and is studies in disciplines such as machine learning, pattern recognition and image processing. Currently, the question of biometric system vulnerability is not discussed – it is accepted, but the main issue is the robustness of the biometric system to spoofing attacks and the necessary countermeasures. Hereinafter, we consider taxonomy of presentation attacks (Section 2.1) and Lambertian modeling (Section 2.2).
Taxonomy of presentation attacks
Any of the presentation attacks is aimed at creating a facial artefact. According to ISO/IEC 30107-1, the biometric characteristic or object is termed the Presentation Attack Instrument (PAI) [1]. The PAI is broadly classified into two types: artificial and human. Artificial PAI refer to an artificial means of generating the PAI, and it is classified as complete artificial PAI (print photograph, video, 3D mask, etc.) and partial artificial PAI (for example, partially visible face or sunglasses). Human PAI involve the human characteristics, such as lifeless, altered (by cosmetic surgery), non-conformant (facial expression), coerced (the use of the face of an unconscious human), and conformant (zero-effort impostor attempts).
Jain et al. [59] classified artificial attacks against biometric systems into two large groups:
Zero-effort (indirect or accidental) attacks, when the biometric traits of an intruder may be sufficiently similar to a legitimately enrolled individual. Zero-effort attacks try to take advantage of the False Acceptance Rate (FAR). This situation is largely a problem of discriminative methods. Adversarial (direct or intentional) attacks, when an intruder is able to masquerade as a registered individual, using physical or digital artefacts of a legitimately registered user. Another scenario is when an individual deliberately manipulates his/her biometric trait in order to avoid detection by an automated biometric system.
Also, when supporting a biometric system, it is necessary to take into account some objective attacks: circumvention of system, repudiation in access, collusion between individuals, coercion, Denial of Service (DoS), etc.
The ISO/IEC 30107 standard introduced the term “presentation attacks” instead of direct attacks as: “Presentation of an artefact or human characteristic to the biometric capture subsystem in a fashion that could interfere with the intended policy of the biometric system” [60].
The most ancient practice to avoid being recognized is the use of masks or facial disguises, which can be associated with 3D attacks. However, artificial facial recognition systems often capture image or video that is interpreted as a 2D space rather than a 3D representation of a person. That is why relatively cheap 2D spoofing attacks are more popular compared to 3D spoofing attacks, causing a lot of attention to development of 2D PAD methods.
If an intruder tries to trick face recognition system into impersonation, such attacks are called impersonation attacks. If a person uses tricks to avoid being recognized by the system, but not necessarily by impersonating a legitimate user, then this type of presentation attacks is called an obfuscation attack. Whether the attack is impersonation or obfuscation depends on the intruder’s goal: an intruder can use any type of presentation attack.
Presentation attacks may be classified into two groups: 2D spoofs and 3D spoofs, as shown in Fig. 1. 2D spoofs include print (image) attacks, replay (video) attacks and adversarial attacks, while 3D spoofs involve mask attacks and disguises.
Taxonomy of face spoofing attacks.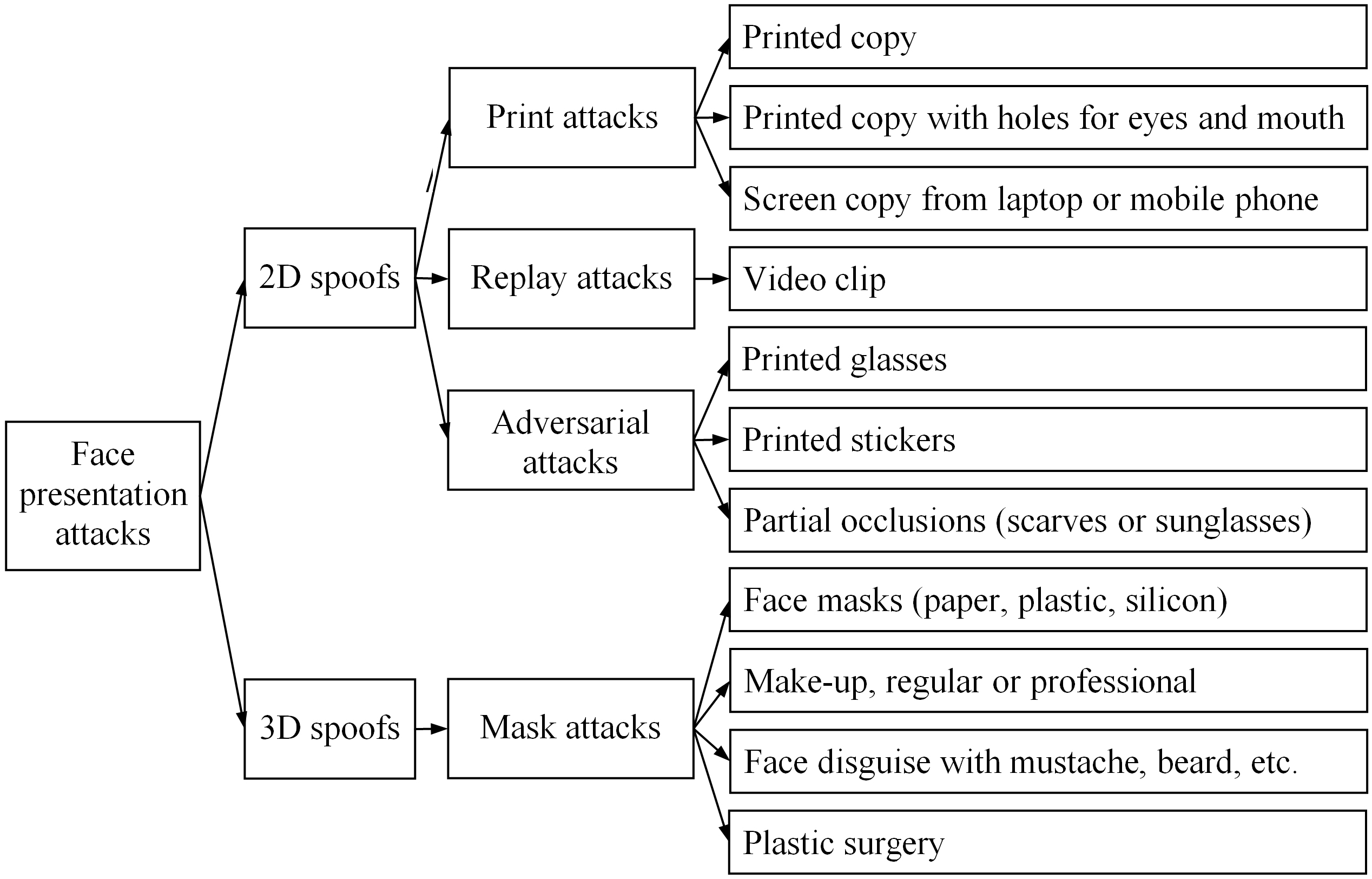
Print attack means representing a photograph of the genuine user to a face recognition system. Photograph may be taken from social networks, the Internet or captured by a digital camera without the consent of the genuine user. Photograph can be printed on a paper (printed copy) or is displayed on the screen of a mobile phone or a tablet (digital-photo attacks). Advanced type of image attack is the use of high resolution printed photographs with holes for the eyes and mouth (photographic masks), when the intruder can blink and move his/her lips.
Replay attacks represent a video clip of the genuine user captured by any digital device (mobile phone, tablet or laptop). This type of attacks is a more sophisticated version of the print attacks and involves richer spatio-temporal information instead of the spatial information of a still image. Objectively, replay attacks are harder to detect because of the genuine temporal information. Adversarial attacks are of a more recent type, when some wearable things become the source of the spoof. They aim to deceive deep neural networks.
Mask attacks are among to the most complex, as they provide the complete 3D structure of the face. Thus, the use of depth cues cannot be a solution to prevent print and replay attacks presented on flat surfaces. In the previous decade, this type of attacks was much less common that 2D spoofs due to expensive silicon masks. Nowadays, the situation has changed: some companies provide 3D face models at a reasonable price, and self-manufacturing a face mask is also becoming more feasible and easier thanks to relatively cheap 3D scanners, scanning software and 3D printers.
The PAD methods can be implemented at the level of sensors (hardware-based) and at the level of features (software-based). Currently, they are shifted to software-based methods. The PAD methods are often addressed by well-known facial cues [61], such as motion (blinking of eyes), involuntary movements of parts of face and head, surface texture of the skin, and the depth information of the head. Ming et al. [40] proposed a topology of facial PAD methods based on cues, including liveness cue-based methods (motion cue-based and rPPG-based), texture cue-based methods (static and dynamic), 3D geometric cue-based methods (3D shape and pseudo-depth map), multiple cues-based methods (different combinations of liveness, texture and 3D geometry), and methods using new trends (Neural Architecture Search (NAS), zero-shot learning, domain adaption, etc.). The latter methods are driven by the development of deep learning models. All groups of methods mentioned above are effective against print and replay attacks, while rPPG-based, dynamic texture-based and liveness
In literature, 2D PAD methods are more highlighted and developed due to the large number of publicly available databases. Mask attacks began to be systematically studied only after the appearance of the first mask-specific database [62]. The COVID-19 pandemic has made an additional contribution – facial recognition using a medical mask, as well as mask attacks. It is also worth noting that a special case is the recognition of twins, which may refer to a zero-effort attack.
Many PAD methods are based on the intuitive idea that the fake image passes twice through the camera system and once through the print system. This implies more serious distortion of the fake image relative to the real image, or in other words, a lower quality of the fake image. It should be noted that the first databases included obviously distorted fake images, and relatively simple algorithms based on hand-crafted features could distinguish them. Nowadays, the situation has changed fundamentally, and databases collect only high-quality fake images and video clips. Even printed images have good resolution thanks to modern printers.
Tan et al. [7] were the first who identified the importance of Lambertian modeling for face anti-spoofing. They obtained rough approximations of illuminance and reflectance parts. Further, in some publications, attention was paid to the mathematical formulation of the PAD task [63, 64, 65]. However, most authors prefer to deal with the consequences of the physical representation and do not take into account the Lambertian modeling. This can be explained by the fact that the difference in reflectance between real and fake images or frames can be captured by special sensors, but not by the most common RGB-cameras. Moreover, modern databases provide high-quality fake images and video clips. This has led to the failure of many algorithms with hand-crafted features and provokes the search for multiple cues in various modalities.
According to the Lambertian reflectance assumption, the face surface is modeled as the ideal diffuse reflectors [18]. In other words, Lambert’s cosine law describes the intensity of a face image
where
Equation (1) can be rewritten for real image
Due to the fact that the lighting conditions during the capture of real and fake images or video sequences are unknown, various authors make additional assumptions. Thus, Tan et al. [7] supposed that the differences between the human skin and a photograph (or a video clip) can be made evident by comparing their surface properties under the same lighting conditions (
where
The color distortion analysis of the print and display (or replay) artefacts were simulated in the same manner as Eq. (4), but with the additional color distortion factors of printing and digital display conversion. Then chromatic co-occurrences of Local Binary Patterns (LBPs) were calculated based on the chrominance and luminance components of bona fide faces and facial artefacts under various luminance conditions and cameras. Such estimates were used as sub-classifiers for the ensemble learning method.
It should be noted that adversarial attacks are modeled differently, using an adversarial example perturbation by adding random noise to image (digital adversarial attack) [68] or showing special glasses, stickers, hats, etc., on the photo (objective adversarial attack) [69].
The PAD field has a short but colorful history since the 1990s. The current common terminology has been formed by relevant standards, image processing, machine learning, and available devices. This is not to say that this process is close to completion, because the usual competition between developers and intruders continues. It is also worth noting that PAD is a challenging area of research accordance with the aspects listed below:
Complex outdoor illumination. Aging of individuals. Difficulties in classifying the liveness features of genuine and fake videos. Some subjects like glasses which cause reflection, printed glasses, and stickers are a challenge for face spoof detection. Make-up can be successfully used to perform direct attacks. Recognition of a person after plastic surgery is still an open problem for facial authentication. Recognition of twins is a very specific and unsolved problem.
Currently, PAD methods can be categorized into two unbalanced groups: digital (feature-based) and physical (sensor-based) PAD methods. The last ones require specific devices, provide other biometric features in addition to facial features and serve as cues of liveness.
Digital PAD methods provide a wide variety of approaches – traditional, deep learning and hybrid. In this survey, we will focus on the last two approaches due to their trending superiority since the 2010s, discussing methods for print attack detection (Section 3.1.1), replay attack detection (Section 3.1.2), adversarial attack detection (Section 3.1.3), 3D mask PAD methods (Section 3.1.4), and detection of disguised, makeup, plastic surgery attacks, and morphing attacks (Section 3.1.5).
Print attack detection
Methods for print attack detection belong to dynamic and static approaches. The dynamic approach assumes that a still photograph is recorded as a short video, while static approach analyzes a still photograph as a single snapshot.
Printed photos were the first instrument to fool the face recognition system. The first algorithms analyzed a still photograph in temporal domain in order to confirm or reject a person’s identification. Some of these methods were based on motion detection in specific face regions, such as eye blinking, changes of mimic wrinkles near the mouth or involuntary lip movement [23]. Other methods detected face and head gestures (for example, nodding, smiling, changing gaze directions) [27]. The third group of methods analyzed foreground/background motion correlation using optical flow between the consequence still images [70, 71]. These methods are highly effective for detecting print attacks, but useful against replay attacks.
To overcome this shortcoming, some dynamic liveness detection techniques have been proposed to detect replay attacks, such as using 3D facial structure by analyzing multiple 2D images [72], context-based analysis (background and foreground motion) [73], evaluating noise produced during the recapture [74], or employing face texture dynamic analysis [75].
Dynamic-based PAD methods can be applied in systems where only a single face image of the user is available (passport related applications). Also not all frames are suitable for analysis, and real-time application is questionable. Such shortcomings limit the application of this approach in practice, but sometimes it provides better accuracy than static-based PAD methods.
Analysis of a still photograph is more attractive because it is faster overall. Most of the static methods analyze the texture of the face using various image processing algorithms, traditional and deep learning. Traditional methods have been based on the Fourier spectrum, multiple difference of Gaussian filters, LBPs, Gabor wavelets, histogram oriented gradients, and so on.
Nguyen et al. [76] proposed to use the hybrid features as a combination of handcrafted and deep features against print attacks including cut photos. Multi-level local binary patterns were used to measure the skin details on face region, such as edges, corners, and blobs by extracting a 3732-component feature vector. The VGG-19 model provided a binary classification: “real” and “presentation attack” images, forming a 4096-component feature vector. The high dimensionality of the common feature vector necessitated the use of the principal component analysis followed by the Support Vector Machine (SVM) classifier. For samples from the NUAA database and the CASIA database, the ACER values reached 11.247% and 2.174%, respectively.
However, the accuracy of these methods can suffer due to different illumination conditions, and other cues are usually used in conjunction with them.
Replay attack detection
Replay attack means playing a short video of an authorized user on a digital device such as mobile phone, laptop or tablet. The intruder is standing in front of the camera of face biometric system. Thus, the replay attack provides dynamic biometric features, in other words, the motion of the user. This type of attack is also possible due to the easy access to a person’s video in social networks.
Patel et al. [77] integrated deep texture features and eye-blink cue as countermeasures against replay and print presentation attacks. The CaffeNet model (with 5 convolution layers and 3 fully connected layers) was used as a backbone in the architecture with two branches, one for face texture analysis and the other for whole frame texture analysis. The generic-to-specific transfer learning scheme was designed to train the network due to the small sizes of existing face spoof databases. Such approach resulted in 13.8% of the Half Total Error Rate (HTER). Eye difference images between successive frames were calculated by cropping the regions of the left and right eyes separately to 40–50 pixels. The voting scheme was then used to generate a decision per video clip. After the eye-blink cue was fused with the deep texture features, HTER on replay attacks achieved 12.4%.
Feng et al. [78] estimated image quality cues provided by shearlet decomposition and averaged motion cues as the dense optical flows of face video and scene video to detect replay and 3D mask attacks. Then these three types of cues were fused using a hierarchical neural network to improve the generalization ability for both 2D and 3D spoofing detection. The REPLAY-ATTACK database and the 3D-MAD database were used in the experiments. With a bottleneck feature fusion, this method achieved a HTER of 0% on the 3D-MAD database.
The FASNet, which followed the VGG-16 architecture, was pre-trained with transfer learning to detect replay and mask attacks [79]. The top layers of the VGG-16 model were changed to perform the binary classification for the anti-spoofing task. The FASNet reached an HTER of 1.2% and 0.00% on the REPLAY-ATTACK database and the 3D-MAD database, respectively.
Dynamic liveness cues are often used in practice. Eye-blinking, chin and lip movement as a multiple-motion-cue-based method was developed in [80]. Bekhouche et al. [81] proposed spatiotemporal CNN with pyramid bottleneck blocks for eye blinking detection in a wild scenario. Killioğlu et al. [82] presented liveness detection method based on pupil tracking. Application of rPPG signals helps to estimate pulse or heart rate [3, 83, 84], or skin blood flow [85].
Chen et al. [86] suggested a three-way classification to distinguish real face, fake face and background for detecting the print and relay attacks. They designed face anti-spoofing region-based convolutional neural network based on Faster region-based CNN with addition of a Crystal Loss function to the original multi-task loss function. Also, the Retinex-based LBPs were presented to handle the different illumination conditions in face spoofing detection. These two detectors were further cascaded and achieved promising performances on the CASIA-FASD, REPLAY-ATTACK and OULU-NPU databases. In continuation of this direction, Peng et al. [87] proposed a two-stream vision transformers framework based on transfer learning, where the outputs of the RGB stream and the multi-scale Retinex with color restoration stream were fused by self-attention fusion module. The output of the fusion features was then classified by the softmax function as a live or spoof face in the video. Experiments on OULU-NPU, CASIA-MFSD and REPLAY-ATTACK databases have shown that this approach outperforms many methods in intra-database testing and provides good generalization performance in cross-database testing. Yu et al. [20] extended the central difference CNN to a multimodal version, exploring three modalities (RGB, depth and infrared). The CASIA-SURF CeFA, a large-scale cross-ethnicity face anti-spoofing database, was used in experiments.
Rehman et al. [88] enhanced the discriminative ability of deep features in face PAD, adding a perturbation layer (a learnable preprocessing layer for low-level deep features). In other words, the authors induced the information of the hand-crafted features into the deep features of a selected layer in CNN, called perturbation layer. Their experiments showed that the face PAD performance was improved in both intra-database and cross-database scenarios using CASIA, REPLAY-ATTACK and OULU-NPU databases.
Cai et al. [89] proposed two-branch framework based on CNN and Recurrent Neural network (RNN) to extract both global and local information, respectively, based on a single frame. For patch selection for RNN processing, they adopted deep reinforcement learning, which overperformed the max SoftMax scores (denoted as the MAX-SCORES method) and the method of selecting patches randomly (denoted as the RANDOM method). Six publicly available face presentation attack databases including CASIA, IDIAP REPLAY-ATTACK, MSU Mobile, OULU-NPU, SiW, and Rose-Youtu databases, were utilized in the experiments.
Roy et al. [90] employed a bi-directional feature pyramid network based on the EfficientDet detection architecture. In addition, they leveraged the properties of 2D Fourier spectra by adding an auxiliary branch in their baseline network. The results were tested on the OULU-NPU and REPLAY-Mobile databases. Karmakar et al. [91] proposed to detect the spontaneous facial micro-expressions by analyzing the higher frequency in multidimensional Fourier transform. This method has been applied for detecting replay attacks to distinguish between live and fake facial video streams.
Li et al. [92] detected replay and 3D mask attacks based on differences of motion direction and intensity, as well as differences of texture information between live and fake faces. The proposed architecture included optical flow and texture module, two attention modules (channel attention and region attention), and CNN network. Attention modules generated the corresponding maps, which were fed into the CNN network for feature extraction and image sequence classification. Yu et al. [93] developed a novel deep forgery detector called Patch-DFD based on facial patch mapping and bilinear interpolation with max-pooling operation. Then 5 fixed size feature maps were fused by a local voting strategy. Method has been tested against replay attacks on DeepfakeTIMIT, Celeb-DF (v2), and FaceForensics
Muhammad et al. [94] attempted to generalize the detection of print attacks and replay attack by proposing a temporal sequence sampling method to accumulate appearance and dynamic information of video sequences into single RGB images. First, the input video was divided into
Adversarial attack detection
Szegedy et al. [95] were the first who demonstrated that deep learning models are vulnerable to adversarial (small, often quasi-imperceptible perturbations) examples, when the original samples are taken from the data distribution. Deep learning-based face recognition systems are no exception: they are vulnerable to adversarial attacks from both the digital and physical domains. Adversarial attacks have recently emerged that aim to mislead a classifier in a deep learning-based face recognition system [96]. These perturbations are physically imperceptible to human vision, generating synthetic images by adversarial methods [97]. Perturbations are utilized in two modes “no target” (hiding the identity of the user) and “dodging” (accessing the identity of the target user).
The method of 3D printing glasses to create physical attacks is a widespread adversarial attack [69, 98]. Zhou et al. [99] proposed an infrared-based stealthy facial morphing of the subject using “infrared lighting cap”. Nguyen et al. [100] developed a more convenient method to create adversarial attacks using light projections, using a commercially available webcam and a projector. The proposed method generated a digital adversary template using one or more target images available to the intruder, and this digital sample was then projected onto the opponent’s face in the physical area to either impersonate the target (impersonation) or avoid recognition (obfuscation).
Countermeasures against adversarial attacks can be roughly divided into two groups: rectification methods and methods for adversarial detection. Rectification methods increase the robustness of the system [101], while methods for adversarial detection analyze the behavior of the model, detecting anomalous events [102]. The robustness of a model can be increased via adversarial training or regularization methods that train deep learning models. Detection subsystems are often implemented as binary detectors that distinguish genuine and adversarial inputs. A recent detection method based on predictions has shown a good trade-off between detection efficiency and attack resistance [103]. It is based on a k-NN scheme or several RBF-SVMs applied to specific layers of a deep neural network, in other words, to intermediate representations. Massoli et al. [104] captured the evolution of the features extracted from the input at intermediate layers, created a trajectory in feature space, and analyzed the behavior of the original samples and the manipulated samples. A series of experiments, including a realistic scenario with a face recognition system, showed a high degree of resilience against adversarial attacks.
Deb et al. [105] proposed a new self-supervised adversarial defense framework called FaceGuard that can automatically detect, localize, and purify a wide variety of adversarial faces without using pre-computed adversarial training samples.
3D mask PAD methods
Most existing PAD methods proposed for 2D fake surfaces are useless for detecting 3D masks because the 3D mask usually looks more like human skin [61]. Even photographic masks with cut out areas of the eyes and mouth can deceive the recognition system.
Face mask materials can be divided into rigid/non-rigid or soft/flexible [106]. Relatively inexpensive rigid masks can be made from paper, resin or plastic. Soft masks often use latex and silicone materials. They are close to reproducing the color and texture of human skin and can adapt to different sizes, shapes and movements of the face. Currently, some mask materials, which are used in the manufacture of 3D masks, can accurately match the topology of the face, making 3D mask attack detection increasingly difficult and sometimes impossible [107]. Thus, the production of ThatsMyFace mask requires 3D reconstruction and 3D printing techniques to create a custom face mask. At that time, the RealF mask based on the three-Dimension Photo Form (3DPF) technique looks very similar as the genuine face. Advances in manufacturing 3D masks make the 3D mask attack very popular in practice.
Existing 3D mask PAD methods find the difference between real face skin and mask materials. They work at the digital level (texture based, shape based, and deep features based methods) and sensor level (the reflectance/multispectral properties based and other cues/liveness based methods, see in Section 3.2).
Texture based methods utilize various types of LBPs in conjunction with Linear Discriminant Analysis (LDA) [61], linear SVM [108], Euclidean distance classifier [109] and other similar classifiers. Agarwal et al. [110] suggested to use Haralick texture features and got good results on 2D/3D mask spoofing databases including 3DMAD database.
Shape-based methods extract discriminative features using image transformation, shape descriptors or reconstructing geometry cues. Kose et al. [111] described 3D face shape with warping parameters and extracted LBP features on 2D images and 2.5D depth maps for mask attack detection. Tang and Chen [112] used principal curvature measures and meshedSIFT-based features [113] to describe the 3D triangular mesh surface of the face. Hamdan and Mokhtar [114] applied the angular radial transformation to extract shape features from the RGB images, which were then passed to a Maximum Likelihood (ML) classifier. The same authors combined the Legendre moment invariant decomposition of the RGB image with the LDA projection, also using the ML classifier [115]. Wang et al. [116] reconstructed depth cues from RGB images using a 3D morphable model and then looked for the geometry differences between real faces and masks based on the extracted normal features.
One of the first works in deep feature based methods investigated iris, face and fingerprint modalities, trying to optimize a three-layered CNN architecture and filter optimization [117]. The 3DMAD database was one of nine databases (3 for iris, 2 for face and 4 for fingerprints) used in the experiments. This approach was too broad and inefficient, despite the high reported results. Lecena et al. [79] presented a pre-trained modified VGG-16 model (called as FAS-Net) for recognizing photo, video or mask attacks using only static features. The approach was tested on the REPLAY-ATTACK and 3DMAD public databases. On the REPLAY-ATTACK database the accuracy achieved 99.04% and HTER 1.20%. For the 3DMAD, the accuracy was of 100.00% and HTER 0.00%. Manjani et al. [118] collected a Silicone Mask Attack Database (SMAD) (see Section 3.3) and proposed a multilevel deep dictionary for the face PAD. The feature learning was independent of knowledge of attack types and did not exploit particular distinguishing attributes. The algorithm encoded the features of the presented samples from low to high level using SVM as a classifier. Experiments were performed on the SMAD, 3DMAD, CASIA-FASD, UVAD, and REPLAY-ATTACK databases, showing promising results in both intra-database and cross-database protocols.
Liu and Kumar [119] tested 5 CNN architectures and Siamese CNN on their own dataset including a total 13 different 3D face masked subjects and 9 different real subjects. Visible and Near-InfraRed (NIR) images were collected. Experimental results have shown that the NIR image can provide better performance than visible image based images. At the same time, the multispectral imaging provided better performance than using visible and NIR images separately. Shao et al. [120] developed a novel feature learning model to learn discriminative deep dynamic textures for 3D mask face anti-spoofing. The main assumption is that a real face displays different facial motion patterns compared to the 3D mask. These subtle facial motions can be captured by convolutional layers, forming multiple deep dynamic textures. The proposed joint discriminative learning strategy was further incorporated in the learning model to jointly learn the spatial- and channel-discriminability of the deep dynamic textures. Intra-database and cross-database evaluation on the 3DMAD database and their own supplementary dataset indicated the efficiency and robustness of the proposed method.
Chen et al. [121] developed a multi-modal dynamics fusion network for 3D face mask anti-spoofing. Dynamic texture and shape clues were encoded with a two-branch deep CNN model at different rates and intervals for a more comprehensive description. Various poses were also considered. This approach has been evaluated on the 3DMAD, HKBU-MARs V1 and SMAD public benchmarks. Birla and Gupta [122] developed the PATRON system, which utilized the respiration rate extracted from video and face alignment to detect 3D mask attack. The authors applied multi-kurtosis optimization to extract the respiratory signal from the resultant temporal signals. The experiments with samples from the public database HKBU-MARsV1
Furthermore, some methods tried to combine deep learning based features with hand-craft features and achieved outstanding results in mask spoofing detection [120]. This strategy can adaptively weight the learned features to make better discriminative deep dynamic textures more meaningful.
Detection of disguised, makeup, plastic surgery attacks, and morphing attacks
Disguised, makeup and plastic surgery are direct attacks, intentionally or unintentionally impersonate or obfuscate. Unintentional disguises include sunglasses, hats, or scarves. Disguised parts of the face can significantly interfere with recognition [123]. Disguise attacks are used in border crossing and airport security applications [124]. Easily available and cheaper makeup is similar to disguised attacks, but is harder to identify as it closely resembles the real face [125].
Facial plastic surgery is divided into two categories – reconstructive and cosmetic. Reconstructive facial plastic surgery corrects anomalies in facial features, while cosmetic facial plastic surgery improves the visual aspect of facial structures and characteristics. After undergoing cosmetic surgery, a person may attempt to fake a facial biometric system, which would be a plastic surgery attack. After plastic surgery, regions of the face, including the nose, eyes, lips, ears, or bone structure, are reshaped to obtain the desired appearance or as a result of some disease treatment surgeries [31]. In this case, biometric data must be updated in the database of the recognition system.
Facial automated border control systems at airports and seaports, which are widely deployed in many countries, compare the gate image and the biometric reference with the passenger’s electronic machine readable travel document chip, computing a similarity score [126]. The fact that the original biometric reference is not stored in a special database provokes a new type of presentation attacks called morphing attacks, which involves two or more persons. First, an intruder (e.g., a wanted fugitive) and an accomplice (e.g., a citizen) take their own face photos and create a morphed face image with two captured photos. Second, they improve the visual quality of the morphed face image by optimizing the morphing parameters and using some post-processing operations to reduce the blending artefacts. Third, they evaluate the morphed face image using publicly available face verification engines, and the accomplice applies for a passport by using the morphed image and the accomplice’s own personal information. As a result, the intruder may cross an automated border control system using an accomplice’s electronic machine readable travel document. Peng et al. [127] proposed to detect a face morphing based on the watchlist as reference. This recognition scheme is traditional and is aimed at comparing facial feature vectors from a suspect image and the biometric reference contained in the watchlist. The authors wrote that their approach has better generalization ability to unseen types of face morphing attacks and morphing parameters than existing methods. They investigated the variations in facial expressions, face angles, and image qualities using their own collected database for face morphing attacks.
Physical PAD methods
The number of PAD physical methods is incomparable with the number of software approaches. They analyze Lambertian reflections, infrared or near infrared images, depth, thermal imaging [128], detection of the facial vein pattern [129], or other biometric cues such as heartbeat, pulse, etc., which require special devices at the hardware level and data fusion at the software level. Special hardware rely on structured-light 3D sensors, Time of Flight (ToF) sensors, NIR sensors, thermal sensors, etc. 3D sensors provide depth maps that help distinguish between the 3D face and 2D planar attacks [130]. NIR sensors easily detect replay attacks due to the almost uniformly dark of electronic displays under NIR illumination [83], while thermal sensors detect the characteristic temperature distribution for living faces [131]. Virtually all special sensors have higher performance, but they have not yet been widely adopted by the public due to their high cost.
Ciftci et al. [4] introduced FakeCatcher, a fake portrait video detector based on biological signals. FakeCatcher used the biological signals hidden in portrait videos as a descriptor of authenticity. G channel-based PPG signals from different facial parts (left cheek, right cheek, and mid-region) were applied to generate signal maps and then fed into CNN inputs.
The most of physical PAD methods are used against 3D mask attacks. Reflectance/multispectral properties based detection methods were the earliest studies in 3D mask spoofing detection. Kim et al. [132] compared the distributions of albedo values for illumination of various wavelengths of different facial skins and mask materials (silicon, latex, and skin jell), classifying 2D feature vectors by Fisher’s linear discriminant. Zhang et al. [133] measured the albedo curves of skins and non-skin materials using two discriminative wavelengths (1450 nm and 850 nm) to detect fake photo, video or mask. Steiner et al. [134] integrated multispectral Short-Wave InfraRed (SWIR) skin authentication into face verification system and created a public database called BRSU Skin/Face/Spoof, which includes RGB and SWIR images.
SWIR data has not been widely used in face recognition tasks, but this technique can be very useful for detecting 3D mask attacks. In [135], it was shown that for water absorption peaks are around 1430 nm, and this behavior is particularly suitable for the detection of non-skin material. Because of this, the skin and eyes of a person in the SWIR spectrum appear very dark. Heusch et al. [136] demonstrated that a combination of different modalities (visible, NIR, thermal and depth), as well as on a SVM-based classifier acting on SWIR image differences provides superior performance. Two different models (the multi-channel CNN and the multi-channel deep pixel-wise binary supervision network) were used, corresponding to early fusion and late fusion strategies. It is worth noting that these authors have collected the new High-Quality Wide Multi-Channel Attack (HQ-WMCA) database, using five sensors for five modalities (color, NIR, SWIR, thermal, and depth).
Generally speaking, methods based on other cues of real faces for liveness detection use three types of cues: thermal signatures [131], pulse or heartbeat signals [137] and gaze information [28].
Generalization of deep learning methods
As mentioned Abdullakutty et al. [45], generalization of deep learning methods is a recent trend aimed at improving recognition results on those samples that the deep learning model did not see during training. The generalization methods follow a single class classification as opposed to earlier PAD models which followed a binary classification and include five types: transfer learning (Section 4.1), anomaly detection (Section 4.2), few-shot and zero-shot learning (Section 4.3), auxiliary supervision (Section 4.4), and multi-spectral methods (Section 4.5).
Transfer learning with domain generalization and domain adaptation
Domain generalization methods for PAD extract common differentiation features to improve generalization. However, it is difficult to find a compact and generalized feature space for fake faces due to the wide variety of fake face distributions from different domains. Jia et al. [51] proposed an end-to-end single-side domain generalization framework to improve the generalization ability of PAD by making the feature distribution of the real faces compact, while the feature distribution of the fake faces of different domains became more separated. Spatial and temporal auxiliary supervision was based on face depth as spatial cues and rPPG signals (pulse) as temporal cues. Autoencoders can be used to align the distributions of source domains for generalized features [138]. Shao et al. [48] exploited the shared and discriminative data across multiple PAD domains to automatically search and learn a generalized feature space. Their multi-adversarial deep domain generalization was performed under a dual-force triplet-mining constraint, but not as end-to-end solution.
Chen et al. [139] introduced a novel camera invariant face anti-spoofing model, which consists of two branches: the feature invariant branch and the feature discrimination augmentation branch. This model was evaluated on four face anti-spoofing databases: CASIA-FASD, REPLAY-ATTACK, OULU-NPU and MSU-MFSD with good intra-database and cross-database results.
Liu et al. [140] proposed a framework for extracting domain-invariant features via adversarial learning and combining low-rank decomposition methods to detect replay attacks. This approach improved the model’s generalization ability to unseen scenarios. The extensive experiments demonstrated that the proposed method achieved SOTA results on four public databases, including CASIA-MFSD, MSU-MFSD, REPLAY-ATTACK, and OULU-NPU.
Domain adaptation methods minimize the distribution discrepancy between source and target domain by using unlabeled target data [141, 142, 143]. These methods explicitly explore the relationship among multiple source domains without gaining access to any target data through unseen attacks. Most of the traditional domain adaptation methods focus on minimizing the distribution discrepancies across multiple source domains to extract domain-invariant features. Thus, Wang et al. [144] proposed an unsupervised domain adaptation with disentangled representation approach to improve the generalization capability of PAD into new scenarios. El-Din et al. [145] proposed a novel end-to-end domain adaptation-based architecture utilizing deep embedding clustering of target domain to generalize face PAD. Jia et al. [146] proposed a unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing. Two modules were developed: one module to minimize the marginal distribution between the source and the target domains to extract domain-invariant features, and another module to make the features of the same class compact.
Anomaly detection
The PAD statement can be formulated in such a way that genuine face images are considered normal samples, while all possible attacks form the anomalous sample space. The main hypothesis is that the genuine face class has lower variance in the feature distribution and forms a close cluster. At the same time, attacks have a higher variance and can be considered as anomalies in the feature space. Any samples outside the margin of the genuine cluster are considered anomalies, e.g. the attacks. Thus, unseen attacks can be detected more accurate.
Even through many PAD methods are based on the binary classifiers, they have some disadvantages, mentioned below, with respect to the one-class classifiers approach:
Building a decision boundary between classes is a non-trivial task. The generalization of two-class classifiers in the presence of novel or unseen attacks is low. Difficulties in collecting training databases for binary classifiers, especially 3D mask databases [54]. Spoofing attacks are not predictable due to their nature or capture devices. Client-specific solutions cannot be applied to methods with binary classifiers [147].
Nikisins et al. [148] proposed a face PAD system interpreting print and replay attacks as anomaly detection. A One-Class Classification (OCC) problem was solved using image quality measures and a Gaussian Mixture Model trained to represent the probability distribution of bona-fide samples. A challenging aggregated database composed of three publicly available databases (REPLAY-ATTACK, REPLAY-Mobile and MSU-MFSD) was introduced.
Fatemifar et al. [149] investigated the client specific models in the context of anomaly detection, as opposite to the first study of using client-specific information for spoofing detection proposed in [150]. They used four one-class anomaly detectors based on support vector data description, sparse representation based classifier, the Mahalanobis distance, and a Gaussian mixture model. Experiments involving three spoofing databases (REPLAY-ATTACK, REPLAY-Mobile, and Rose-Youtu) confirmed the merits of the client-specific anomaly detection approach. In the further study [151], new score normalisation method was proposed to normalise the output of individual outlier detectors before fusion. Li et al. [152] proposed a CNN-based method for face anti-spoofing against unseen type of attacks as a one-class classification. They developed a distance-based loss function (hypersphere loss function) and organized the training process as an end-to-end supervision. Hypersphere loss function identified the attacks directly without using an additional classifier. Feng et al. [153] proposed a framework consisting of a spoof cue generator and an auxiliary classifier. The generator minimized the spoof cues of live samples, while an auxiliary classifier served as a spoof cue amplifier to make the spoof cues more discriminative.
Anomaly-based detectors based on genuine-access data only have generalization performance advantages over binary spoofing attack detection methods. Fatemifar et al. [154, 155] leveraged the fusion of multiple anomaly classifiers using weighted averaging. Their novel three-stage optimisation method combined a hybrid optimisation method using genetic algorithm and pattern search to explore the weight space, a two-sided score normalisation method to improve the anomaly detection performance, and an ensemble pruning method to improve the generalisation performance. In addition, client-specific information was incorporated to train the proposed model. Experiments with REPLAY-ATTACK, REPLAY-Mobile and Rose-Youtu databases have demonstrated the effectiveness of SOTA anomaly-based and multiclass approaches.
Pérez-Cabo et al. [156] introduced anomaly detection strategy based on deep metric learning using just still images. For regularization, they used a triplet focal loss in the form of a “metric softmax” loss and obtained promising experimental results. Baweja et al. [157] presented another deep-learning solution for anomaly detection, in which both classifier and feature representations are learned together end-to-end. For this purpose, they introduced a pseudo-negative class, which was modeled using a Gaussian distribution followed by the application of pair-wise confusion loss to further regularize the training process. This approach was tested on four publicly available databases: REPLAY-ATTACK, Rose-Youtu, OULU-NPU, and SiW databases. Favorskaya and Pakhirka [158] have built visual maps aimed at finding specific visual anomalies caused by print and replay attacks, using a hybrid approach with creating the visual maps by traditional methods and deep learning for better generalization of the final result.
Few-shot learning is the process of learning from few samples with the supervised data (labeled target samples). Few-shot learning is especially useful when training requires large scale databases. When the number of labeled samples for target class is zero, few-shot learning is called zero-shot learning. Therefore, zero-shot learning is very suitable for detecting unseen or novel attacks. Few-shot learning aims at learning from very few instances from unseen categories, while zero-shot learning requires recognition unseen categories by learning only from the description or semantic information of these unseen categories.
However, currently few-shot and zero-shot learning for the PAD methods is underdeveloped. It should be noted that existing few-shot learning methods often use prior knowledge from one single modality, while zero-shot learning methods frequently explore multi-modality data [159].
Liu et al. [55] investigated the problem of zero-shot face anti-spoofing for 13 types of spoof attacks, including print, replay, 3D mask, makeup, and so on. The proposed deep tree network divided the spoof samples into the most similar spoof clusters (semantic sub-groups) without supervision and also studied the features in a hierarchical way. Each tree node consists of a convolutional residual unit, which is a block with convolutional layers and the short-cut connection. Tree routing unit defines a node routing function to route a data sample to one of the child nodes according to the largest data variation. The leaf node consists of a supervised feature learning module, which concatenates classification supervision and pixel-wise supervision to learn spoofing features.
Qin et al. [160] proposed a novel adaptive inner-update meta face anti-spoofing method to tackle a zero- and few-shot learning problem through meta-learning inspired by the model-agnostic meta-learning [161]. Meta-learner is focused on unseen attack detection by training on predefined genuine and fake facial images and providing better discrimination. First, the proposed method was trained by a meta-learner on zero- and few-shot PAD training tasks simultaneously. Second, an adaptive inner-update strategy improved the performance. The authors also proposed three zero- and few-shot PAD benchmarks and conducted experiments on both the proposed benchmarks and existing zero-shot protocols.
Auxiliary methods
The auxiliary estimation models are trained with some reliable auxiliary information, which is no longer a simple binary label. Auxiliary information has the advantage that it can be better generalized to the PAD task, and it does help to distinguish fake images from bona fide images. Depth, rPPG, reflection, noise, and disparity are the main auxiliary features.
Atoum et al. [13] were the first to consider the estimated face depth as a training signal. They suggested a two-stream CNN-based face anti-spoofing method for detecting print and replay attacks. A deep end-to-end network was used as the patch-based CNN stream, extracting scores of randomly extracted facial patches. A fully convolutional network estimated the depth of a face image, assuming that a print or replay presentation attack has a flat depth map, while live faces contain a normal face depth. The outputs of the both streams were fused for the final solution. The proposed method was evaluated using three benchmark databases: CASIA-MFSD, MSU-USSA, and REPLAY-ATTACK, achieving HTER values 2.27%, 0.21%, and 0.72%, respectively. Later these authors proposed a method for estimating the dense depth map for a live or spoof face image for mobile PAD scenarios [162]. Rehman et al. [163] studied the dynamic disparity features for depth estimation by introducing a disparity layer within CNN. This approach was tested on a collected stereo camera-based face anti-spoofing database.
Liu et al. [14] focused on the known spoof patterns across spatial and temporal domains rather than cues extraction to detect print and replay attacks. Their network combined the CNN and RNN architectures in a coherent way. The CNN part supervised for differences in depth maps and extracted feature maps in parallel. Then the depth map and the feature map were aligned with the proposed non-rigid registration layer. The RNN part was trained with the aligned maps and the rPPG supervision. The Average Classification Error Rate (ACER) in cross testing reached 10–14%.
Niu et al. [164] introduced the real-time rPPG method for continuous heart rate measurement from facial videos. The proposed multi-patch ROI strategy removed outlier signals followed by spatio-temporal analysis, replacing binary labels to supervise the CNN and RNN, respectively. Such auxiliary information is often used for reliable classification.
Lin et al. [84] proposed a generalized method exploiting both rPPG and texture features in terms of 2D and 3D mask attacks. The rPPG information in the form of multi-scale long-term statistical spectral features with variant granularities was incorporated with contextual patch-based CNN. This method has been tested to detect all three attack types using 3DMAD, HKBU-MARs V1, MSU-MFSD, CASIA-FASD, and OULU-NPU databases.
Jourabloo et al. [165] simulated noise patterns as auxiliary information by decomposing a spoof face into a spoof noise and a live face, and then using the spoof noise for classification. Such decomposition is based on the hypothesis that a spoof image can be generated by a bona fide image with multiplicative noise and additive noise. However, noise modeling is inefficient due to the lack of ground truth information. Xu et al. [166] proposed using the bona fide image of the corresponding subject as a type of ground truth in the training set. For this purpose, a metric-learned end-to-end network was developed to simulate face spoofing noise. Yang et al. [16] developed a spatio-temporal anti-spoofing network that extracted both global temporal and local spatial cues to distinguish live faces versus spoof faces.
Wang et al. [167] developed a new method to estimate depth information from multiple RGB frames, efficiently encoding spatiotemporal information for replay attack detection. Optical flow guided feature blocks take single-frame features from two consecutive frames to estimate short-term motion. The extracted features are then fed into the convolution gated recurrent units to obtain long-term motion information and output the residual of single-frame facial depth. The combined estimated multi-frame depth maps were supervised by the depth loss and binary loss. Four databases OULU-NPU, SiW, CASIA-MFSD, and REPLAY-ATTACK were used in the experiments. Intra-testing of the OULU-NPU database and the SiW database reached 9.2% and 3.1% ACER, respectively, while cross-testing between the CASIA-MFSD database and the REPLAY-ATTACK database yielded 17.5%, and 24.0% HTER, respectively.
George and Marcel [168] used pixel-wise binary supervision instead of using synthesized depth values as an auxiliary features. Furthermore, both binary and pixel-wise binary supervision was used by adding a fully connected layer on top of the pixel-wise map to protect against replay attacks. Kim et al. [169] proposed to apply a depth map and a reflection map as bipartite auxiliary supervision for PAD task. The developed bipartite auxiliary supervision network extracted and fused these auxiliary features to detect presentation attacks, in particular print and replay attacks.
Yu et al. [17] introduced a Central Difference Convolutional Network (CDCN), in which central difference convolution was able to extract the invariant detailed spoofing features, such as lattice artefacts. They proposed an extended version of CDCN consisting of the searched backbone network and multi-scale attention fusion module for aggregating the multilevel central difference convolutional features. These authors also presented a multi-modal variant using two fusion strategies for three modalities (RGB, depth and infrared) [20]. Yu et al. [19] proposed a bilateral convolutional network capturing intrinsic material-based patterns via aggregating multi-level bilateral macro- and micro-information. Thus, traditional bilateral filtering was integrated with deep network. Multilevel feature refinement module in the form of a three-head supervision combined depth (shape), reflection and patch (texture) information.
Multi-spectral methods
Most direct attacks are carried out using visible range sensors as the easiest way to fool any facial recognition system. This means that a sensor operating in different range can provide more cues for the PAD methods. Thus, the SWIR camera can be successfully used to detect 3D mask attacks [134]. As mentioned in [37], four different modalities are often used for this purpose, i.e. the visible range, SWIR, Mid-Wave InfraRed (MWIR), and Long-Wave InfraRed (LWIR). As is well known, the infrared spectrum consists of active (NIR and SWIR) and passive (also called thermal) (MWIR and LWIR) IR ranges. The NIR face images detect illumination direction changes and help in low-light conditions, while the SWIR range is suited for surveillance. Passive or thermal IR range is emission dominant, and thermal images capture thermal signatures of the skin tissue.
Nikisins et al. [170] proposed a multi-channel face PAD approach based on three types of devices. They created a stack of gray-scale, NIR, and depth facial images or a stack of images of facial features and then applied a set of pre-trained multi-channel encoders and a multi-layer perceptron for classification. For training multi-channel CNN with three modalities, they used the domain adaptation technique, transferring the knowledge of facial appearance from RGB to multi-channel domain.
Jiang et al. [171] presented a dataset of paired visible and NIR images with distance, pose, expression and session variations for print and 3D mask attacks. They also developed a multilevel CNN processing paired visible and NIR images. Multispectral data (color imagery, NIR imagery and thermal imagery) against the custom silicone mask attacks was used in [172]. Wang et al. [173] demonstrated that their end-to-end CNN with four branches with RGB, depth, IR, and fusion modal inputs, exploiting multi-modal fusion approach via spatial and channel attention overperformed other CNNs for detecting print attack. Jiang et al. [174] proposed a novel multiple categories image translation generative adversarial network that generated corresponding NIR images for visible live and spoof face images instead of using near-infrared equipment. Liveness detection using NIR and RGB images is also a popular approach to detect replay attacks [175].
George et al. [176] developed a multi-channel CNN (color, infrared, depth, and thermal channels) using transfer learning from a pre-trained face recognition network LightCNN. They also created a Wide Multi-Channel presentation Attack (WMCA) database that captures by multiple devices and channels and contains a wide variety of 2D and 3D presentation attacks. A two stream CNN that worked in RGB space and multi-scale Retinex as an illumination-invariant space has been proposed to detect print and replay attacks over both intra-database and inter-database protocols in [177].
Castelblanco et al. [178] investigated two dynamic face-authentication challenges (the camera close-up and head-rotation) to solve the task of liveness detection and face verification. A set of neural-network models based on the CNN and Siamese neural network architectures has been proposed. Their own dataset of 177 live videos recorded by 41 different subjects included multiple types of media-based attacks (printed- attacks, screen-attacks, 3D masks, videos acquired from public social media, deep fakes), for a total of 243 attacks in uncontrolled scenarios.
Databases
Databases have been collected since 2010, and are generally classified as 2D and 3D databases. Only a few databases contain data for one type of presentation attack (print or make-up). Thus, Tables 2 and 3 provide a summary of the existing and best-known 2D face spoofing databases (including print and replay attacks) and 3D face spoofing databases (including mask, make-up, and disguise attacks), respectively.
Performance evaluation metrics and testing protocols
A brief discussion of evaluation metrics and testing protocols appropriate for the PAD task is presented in Section 6.1 and Section 6.2, respectively.
Evaluation metrics
Anjos et al. [207] proposed to use Half Total Error Rate (HTER) as an evaluation metric for various PAD methods in 2011. Like any recognition system, the PAD system has two types of errors: false rejection, when the real accesses are rejected, and false acceptance, when the attacks are accepted. The HTER metric combines the False Rejection Rate (FRR) and the False Acceptance Rate (FAR) as follows:
where FAR and FRR are defined as
A summary of the existing 2D face spoofing databases (print, replay, mask as additional)
A summary of the existing 3D face spoofing databases (mask, makeup, disguise)
Here and further, TP is the true positives (the accepted real accesses), TN is the true negatives (the rejected attacks), FP is the false positives (the accepted attacks), and FN is the false negatives (the rejected real accesses).
The TP, TN, FP and FN values are calculated using model parameters based on a selected threshold achieving Equal Error Rate (EER) on the validation set, the selected threshold for which FRR
However, the performance is now most often reported using the metrics defined in the standard ISO/IEC JTC1 SC37 “Biometrics. Information technology – biometric presentation attack detection – Part 3: testing and reporting” [208]. This standard introduced three levels of the PAD evaluation:
PAD subsystem evaluation. Data capture subsystem evaluation. Full system evaluation.
For the PAD subsystems evaluation, two different metrics are used [1]: Attack Presentation Classification Error Rate (APCER) and Bona fide Presentation Classification Error Rate (BPCER).
The APCER for a given Presentation Attack Instrument Species (PAIS) is defined as the proportion of attack presentations using the same PAIS incorrectly classified as bona fide presentations at the PAD subsystem in a specific scenario and calculated as follows:
where
The BPCER is defined as the proportion of bona fide presentations incorrectly classified as presentation attacks at the PAD subsystem in a specific scenario and calculated as follows:
where
The APCER and BPCER correspond to FAR and FRR, respectively. Similar to HTER, the Average Classification Error Rate (ACER) is defined as the mean of APCER and BPCER:
In addition to the scalar HTER and ACER values, the Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC) are also commonly used to evaluate the performance of the PAD methods. The latter two have the advantage that they can provide a global evaluation of the model’s performances over different values of the parameter set. The ROC and AUC characteristics have the advantage that they provide a global estimate of the performance of the model for different values of a set of parameters.
Data capture subsystem evaluations are based on biometric sensors that may or may not include a PAD subsystem. These performance metrics include:
Data Capture attack presentation classification error rate (Data Capture-APCER) as the proportion of attack presentations using the same PAIS that are incorrectly classified as bona fide presentations at the data capture subsystem in a specific scenario. Data Capture bona fide presentation classification error rate (Data Capture-BPCER) as the proportion of bona fide presentations that are incorrectly classified as presentation attacks at the data capture subsystem in a specific scenario.
Full system evaluations include comparison subsystem results in addition to the two previous evaluations, which can be interpreted in both verification and identification scenarios. These evaluations are as follows:
Verification scenario. In the case of attack samples, the performance is measured using the Impostor Attack Presentation Match Rate (IAPMR), which is defined for a full system evaluation of a verification system as the proportion of impostor attack presentations using the same PAIS in which the target reference is matched. Identification scenario. In the case of attack samples, the performance is measured using Impostor Attack Presentation Identification Rate (IAPIR). The IAPIR is defined as the proportion of impostor attack presentations using the same PAIS in which the targeted reference identifier is among the identifiers returned or at least one identifier is returned by the system.
PAD based on traditional methods failed to perform consistently across databases despite testing the same database under different conditions. Also the performance of the chosen method is highly dependent on the attacks and the case under considered. A combination of several complementary algorithms helps to achieve the best results. PAD based on deep learning methods have the same problems, but at different level, which has led to the term “protocols” aiming at fundamentally improving generalizability.
The existing evaluation protocols in the literature [182] include two main protocols: intra-database and inter-database (cross-database) testing protocols. However, sometimes perspectives on learning are assessed over four practical protocols (i.e., intra-database – intra-type, inter-database – intra-type, intra-database – inter-type, and inter-database – inter-type). The intra-database testing protocol splits all the data available into training and test data, while the inter-database testing protocol uses the data of one database for the system design and other databases for testing. Thus, the generalization is improved. These evaluation protocols are suitable for the binary classification task, but fail to address the one classification task. To achieve good generalization capacity, protocols for one classification task can be modified in different ways. For example, intra-database performance evaluation involved training the data associated with the two spoofing attacks plus normal data, and then testing against the third type of attack [54]. The inter-database testing scenario can also train data from two databases and tested on a third database. Variations of such inter-based testing protocols are presented in [50, 57].
A Generalization Representation over Aggregated Datasets for Generalized Presentation Attack Detection (GRAD-GPAD) framework has been proposed as a novel paradigm of data collection in [209]. These authors introduced several types of protocols, including Grandtest, Cross-Dataset, One-PAI, Unseen Attacks (Cross-PAI), and Unseen Capture Devices with two additional protocols: Cross-Face Resolution and Cross-Conditions. The leave-one-out testing protocols were formulated in [55] and applied to data from on SiW-M database.
Trends and perspectives
Let us summarize the SOTA of the existing PAD methods and formulate some trends and perspectives.
1. Face recognition is an integral part of biometrics after iris and fingerprint recognition. Generally speaking, face recognition systems do not require special devices and official permission to take pictures or videos, which has led to the widespread use of these systems in practice. And then there were attempts to deceive the automatic facial recognition system. Thus, the first PAD methods have been developed since the 1990s. Advances in hardware and software are making face recognition systems, 2D/3D attacks, and PAD methods more and more sophisticated. At the same time, face recognition in the wild remains a fundamental problem given the challenges of illumination, personality and existing sensors.
The PAD methods have evolved as traditional, deep learning based and hybrid, just like other branches of computer vision. The PAD methods are categorized into two unbalanced groups: digital (feature-based) and physical (sensor-based) PAD methods. Many current PAD methods aim to prevent attacks of the same type, but using multiple cues of liveness. However, an intruder can use several types of attacks, and a face recognition system must be protected from any type of attack. This means that the PAD methods should be generalized in the future.
At present, attacks are divided into 2D and 3D attacks, which lead to the development of 2D/3D PAD methods. Experimental results show that sometimes 2D methods can be effectively used to prevent 3D attacks (mask attacks). Thus, the entire family of 2D, 2.5D (2D
The problem of the generalization abilities of data-driven models, which is common in the field of computer vision, remains relevant for facial PAD.
2. Databases play a significant role in training and testing deep learning models. Creating a face PAD databases with sufficient samples and variability is still very time-consuming and costly due to the fact that collecting presentation attacks and PAIs is nearly impossible in the wild compared to collecting a face database. Databases have improved their qualitative and quantitative parameters in such a way that some early PAD methods cannot provide good accuracy results when trained on modern databases. Also, some deep learning based methods achieve outstanding accuracy results in one database, reaching 0% HTER values, but fail in another database or when using different protocols. Typically, the database does not include many subjects (several dozen) and 10–100 times more samples captured in different sessions. Databases collected in 2016–2019 contain 3–5 thousand samples (images or short videos), which is not much for deep learning training. In this situation, the two ways are recommended: the first way is to use the augmentation techniques that have become more intelligent in recent years, and the second way is to collect very large databases with different types of attacks and real world variations, as we see in 2020–2022. Due to limited training data and a large gap between different types of attacks, it is still necessary to study the generalization of PAD methods in cross-database protocols.
Many databases have samples for various types of presentation attacks (multi-databases). At the same time, in other databases there are samples for an exclusive type of presentation attacks (mono-databases). Databases that store information about print and replay presentation attacks are considered general databases, while 3D mask spoofing databases are regarded as special ones, more complicated and high-cost. Information on databases containing samples with physical attacks is scarce.
Some databases, especially 3D mask spoofing databases, contain data with less realistic attacks that reduce false match rate to zero and are not promising for practice [115]. This fact indicates the need to generalize the results obtained using appropriate testing protocols. A type like “unknown attack” is especially challenging.
Another issue is that different data collection processes result in different qualities of spoofed samples. This fact is especially important for 3D mask spoofing databases, since mask production, sample recording process and training and testing protocols directly determine the quality of the data collected.
3. Deep learning has initiated progressive changes in the PAD methods because traditional methods do not take into account the intrinsic distribution relationship among different domains and extract discriminative features with bias, which leads to poor generalization to unseen domains. Various deep learning models have been proposed to detect unseen attacks. Recently, binary classification problem has been reformulated as the OCC task with the goal of accurately classifying a genuine face and considering all others as attacks. The OCC-based methods include in particular, domain generalization, anomaly detection, and zero-shot and few shot learning, which improve generalization and unseen attack detection. Generally speaking, generalization in facial PAD is one of the main trends, but in an early stage of research. It involves several techniques such as transfer learning with domain generalization and domain adaptation, anomaly detection, few-shot and zero-shot learning, auxiliary methods, and multi-spectral methods [45].
4. Recently, new types of face presentation attacks have emerged. We can mention adversarial attacks and morphing attacks. Adversarial examples are a serious threat to deep learning models because they impose significant restrictions, especially in sensitive applications. Despite the efforts of the scientific community to train robust neural networks, a well-informed intruder usually succeeds in finding ways to attack the model. Another major problem is the detection of manipulated inputs. Compared to adversarial learning, the detection of adversarial attacks has some advantages, for example, it does not require retraining of the model and the development of new learning strategies. Morphing attacks suppose that an intruder (e.g., a wanted fugitive) and an accomplice (e.g., a citizen) can deceive automated border control systems at airports and seaports, manipulating with images and the accomplice’s own personal information.
5. Early research in PAD were focused on one or two attack types (mostly print and replay attacks). However, intruders are creating new and new attacks, often joint attacks of different types. This requires more research to detect joint attacks. Thus, FaceGuard [105] proposed a generalizable defense against 6 adversarial attack types. The Diverse Fake Face Dataset (DFFD) [210] included 7 digital manipulation attack types from 4 categories. Deb et al. [211] detected 25 attack types known in literature (6 adversarial, 6 digital manipulation, and 13 spoof attacks) using a novel unified face attack detection framework called UniFAD.
Conclusions
This systematic survey presents taxonomy of presentation attacks in the digital and physical domains. Special attention is paid to deep learning methods for face PAD, as since 2013 technology of face recognition has shifted towards deep learning. This fact caused additional type of attacks called digital and objective adversarial attacks against deep learning models. Recent researches have led to another problem – the generalization of deep learning methods. Five types of generalization are discussed. More than 40 databases are briefly reviewed, including normal and attacked images and videos for all types of attacks. This survey also highlights metrics and testing protocols, as well as trends and perspectives in the PAD field.