
Abstract
People explore specific services or information to accomplish their goals within a web system. Efficient visitors’ exploration routes must be defined as requirements to guide them through a good experience. In order to define these requirements, we focused on links from one object to another and developed a method named
Introduction
People explore specific services or information to accomplish their goals within a web system. In order to provide a good user experience in the web system, the most efficient visitors’ exploration routes must be defined as requirements. When a user begins her/his exploration from an object, their traced links between objects and target objects will remain as the breadcrumbs of a trail, in other words, the “Berrypicking” process [1]. We have to define the efficient breadcrumb trails as requirements in the requirement engineering process. We call the breadcrumbs’ trail, a traverse.
In this paper, we propose a method named
How can a traverse contribute to proper user experiences? This is because visitors do not click on links between objects at random, but click on links, as the thinking is that, the clicking action will bring them closer to the target object. If so, the traverse extracted from the ontology [2] that represents the meaning structure of the real world should be an itinerary close to the mental model of the visitors in the real world. We applied class diagrams to represent the ontology of the application domain. The roles of an association in class diagrams are diverted as a user group’s permissions. Hence, the associations in the ontology can represent visitors’ permitted activities; i.e. create, read, update, and delete. We also defined rules to interpret the class structure in order to extract traverses. Then, Traverser can infer and construct traverses with the added advantage of taking into account the visitor’s permitted activities.
In our previous study, we were able to get traverses from the conceptual model, in other words, the “ontology” of a web-based education management system, and further, find some missing links that were ignored by the real system [3].
The purpose of this study is to show the inferred results produced by Traverser tool, and how these inferred results can contribute to the eliciting requirements as itineraries for users. In this paper, we introduce inference rules to extract traverses from the ontology and, evaluate the effectiveness of Traverser.
The structure of this paper is as follows. In Section 2, we introduce related work. Section 3 gives an overview of the method Traverser. Section 4 shows the method semantics. Section 5 introduces
Related work
When it is anticipated that a wide range of various users will use the system, interviewing all kinds of users is not a viable solution. A persona is a typical user with a name, personal history, work, goals, and other properties, that provide the developers with an imagination or a rationale for the persona’s objectives or situational requirements for using the system [4]. Persona analysis is effectively applied to games [5], and smartphone apps [6]. However, it is hard to define personas for web shopping sites, because there are various users. In order to elicit requirements of various users, we need to analyze the users’ behavior more logically. Since an ontology has inference rules with knowledge, we can derive users’ behavior, and traverses, automatically.
In requirements engineering, a persona activity is defined as a scenario [7] or a user story [8]. Use case approach [9] is a more abstract approach. One of the advantages of these natural language approaches is that they are easy to read and can be understood by everyone, however it is difficult to apply them with the goal of contributing to the integrity of the requirements. In our method, the traverse is written in natural language, so that, end users can evaluate the traverses whether traverses correctly describes their requirements or not.
In the Robotic Process Automation (RPA) area, researchers utilize bot logs and process logs in order to elicit requirements for addressing exceptions and/or new opportunities for bot and process redesign [10]. Process mining is a way to explore new services or improve existing services, including web systems. [11]. If we apply the process mining approach, we explore the actor’s real traverses within the usage logs recorded after the system release, and extract scenarios where the actor gets lost in the process. This approach is effective after developing a system. If we can predict efficient traverses, we must define them as requirements before building a system. In our approach, requirements on the customer journey are elicited from the conceptual model that is defined in the early stage of the software development, rather than after the system release.
An ontology is defined as a structure of domain knowledge with objects and relations between objects. The ontology is interpreted to understand the domain with inference rules. Applying ontology is an important approach for requirements elicitation [12]. For example, Haruhiko Kaiya applied an ontology to find incompleteness of requirements [13]. According to improving the technologies of artificial intelligence, ontologies have come to be applied to various applications and/or engineering domains. In the semantic web, a computer understands the meaning described within a web page by interpreting the metadata of the web page using the ontology [14]. AI (Artificial Intelligence) chatbots are a typical example for our daily lives [15, 16]. Some AI chatbots can answer questions in natural language with a domain ontology.
In recent software development projects, requesters are expected to make significant contributions [17]. T. Rietz et al. developed a self-induction system called “Ladder Bot” [18], in which, Conversation Agents (CAs) mimic the capabilities of professional interviewers, allowing end users to define their needs and requirements. “Ladder Bot” may be effective for end users, but completeness issues remain. Since we developed a tool to extract traverses from the ontology automatically, traverses cover the scope of the model completely. We expect traverses to contribute to the completeness of requirements of users’ itineraries.
An ontology is a formal and explicit specification of a shared conceptualization [19]. A conceptual model is sometimes treated as an ontology. E. Insfr’an et al. applied conceptual models for the prediction and elicitation of requirements [20]. S. Nalchigar et al. also introduced a conceptual modeling framework by focusing on information systems that mainly manipulate data [21]. T. Nakatani et al. explored a method to predict requirements changes and find undefined requirements with a conceptual modeling technique [22]. K. Goto et al. developed an event list generation system by extracting scenarios from class diagrams [23]. These studies presented the effectiveness of a conceptual model in order to elicit requirements. In this paper, we introduce inference rules to construct traverses from an ontology. Furthermore, from the ontology, we extract traverses as requirements on efficient user experiences.
Overview of method traverser
Approach
The traverses are extracted from an ontology by tracing associations, aggregations, and inheritances by taking into account the actor’s permissions. Here is an example of a traverse.
An actor StandardStudent who accesses a/an Lecturer object can access(read) the Article objects from the Lecturer object.
UML class diagrams are utilized to represent the ontology. There may be another path for the actor to access the Lecturer object in the traverse example: it may be acceptable for the actor to use a search engine to find the Lecturer object. We added “open” and “closed” stereotypes to the ontology. These stereotypes indicate whether the objects of the class can be accessed from anywhere, or not.
Furthermore, we added an actor model that represents an actors’ permission inheritance structure, so that the permissions on each path can be defined for each actor. The report output from Traverser tool contains requirements in the form of a traverse.
Users of traverser
A process of Traverser requires the following two users:
A modeler A modeler has skills in object-oriented modeling techniques and knowledge of UML. A domain expert of the application domain Modeling techniques are not mandatory for the domain expert, but it is recommended to have the skills to understand class diagrams. Traverser tool helps domain experts understand traverses by presenting them in textual and animated styles. We will briefly introduce the tool in section 5.
The modeler and the domain expert work together in order to complete the ontology.
The process of Traverser is as follows:
A modeler builds an ontology with a domain expert. The domain expert defines actors’ groups within an actor model. The domain expert defines permissions for every actors’ category on every association/aggregation in the ontology. By picking up actors one by one, the expert analyzes the actor’s permissions for each association and/or aggregation. Traverser tool provides a dialog box as shown in Fig. 1 in order to define permissions.
A dialog box to define the permissions for an actor. The domain expert reviews the traverses that the tool extracted. The permitted traverses and prohibited traverses are output from the tool for each actor. The domain expert validates the traverses as requirements of the developing system. If the ontology or permissions are incorrect or needs to be updated, the modeler restarts from 1 or completes the process.

Semantics of an ontology for traverser
A metamodel of 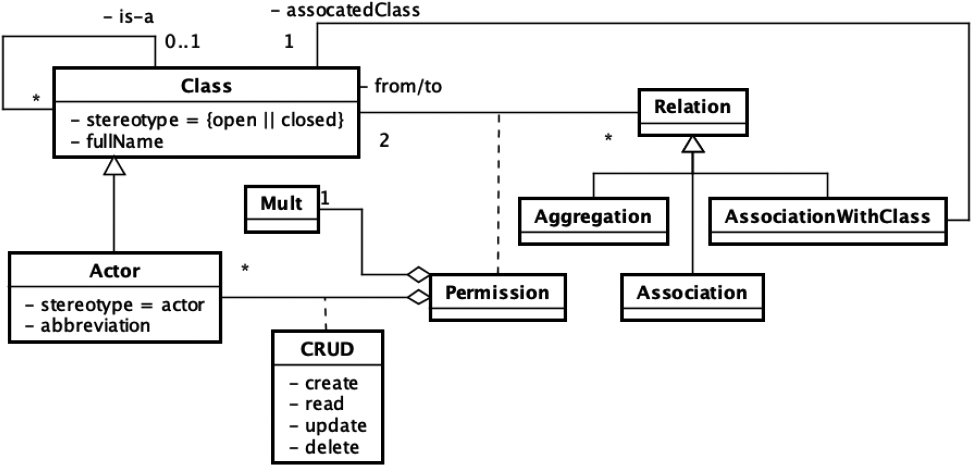
Figure 2 represents the metamodel of Traverser. It has the following elements.
Class: Class represents a concept. Each concept appears on a web page. However, it does not mean each concept should be implemented within one web page. In general, web pages contain multiple concepts, because of their usability and/or readability. How many concepts a web page consists of is a typical design issue. The scope of Traverser is, for example, to suggest a requirement that one access path has to be implemented within the system.
Traverser treats Class as a set of instances of the class.
Is-a: inheritance structure between classes.
where Actor: Actor is a visitor of a web system and is a subset of Class.
CRUD: It represents the accessing rights of actors. It is defined as a set of access rights.
Permission: a permission is defined on the edges of a relation to allow actors to access the object of a class.
It means that an actor is permitted to access with the rights defined in crud that is a subset of CRUD. Mult: It follows the semantics of “multiplicity” in UML. It represents a collection of values. The basic format of “multiplicity” is as follows:
If it has a fixed number, only Relation: Relation is a kind of association, aggregation, or association class in UML.
where
An example of an association-class.
Figure 3 is the example of a relation with an association class drawn with the Traverser tool. The figure represents two links
Traverses are generated by tracing relations between classes with actors’ permissions by taking into account the inheritance structure of classes. The rules of tracing the relationship within the ontology are as follows.
Ancestors, descendants, and relatives
Transitivity rule: if If there are inheritance relations, the traverse can transit via the relations.
Ancestors
Descendants
Relatives Permitted relation The permitted relation,
For Actor
Traverses sequence Traverser is a function from
The output of Traverser satisfies the following six conditions.
A traverse starts from a class of which stereotype is “open”, in other words, everyone can access the start class of the traverse from the web.
The output is a finite sequence of relations in which each relation occurs only once.
All relations appearing in the output are elements of
The from-element of the first relation of the traverse is a start class
The from-element of each relation in a traverse is equal to the to-element or the assocClass-element of the previous relation, or its relatives.
The traverse is terminated by the
or
The rules of traverse report A traverse report derived from relations within Traverse (a, x, c) where
If there are relations
An actor A who accesses a/an C object [or a/an Descend(C) object] …can access ( Each rel(From, To, Perms, Mult, Assoc) is used to generate the following statement by applying rules.
the To [object [or the Descend(To)
object] …from { Here is an example text that Traverser generated as a traverse.
An actor Administrator who accesses a/an Vehicle object or a/an ManagedVehicle object or a/an ShareableVehicle object can access(read) the VehicleTax objects from the Vehicle object.
Overview
Traverser tool1
Traverser tool is available at
Defining an ontology and an actor model. Extracting permitted traverses and prohibited traverses with regard to the actor’s access permissions from the ontology. Presenting traverses in text and graphic styles. Generating a summary of a use case description with name, actor, preconditions, and postconditions.
Modelers and domain experts review the generated traverses to verify whether any of the traverses contradict the requirements. Therefore, traverses should be presented in a style that is easy for non-technical people to read and understand.
Traverser tool was developed to support a review process with visualization styles. In the Traverser’s review process, reviewers are expected to read all of the concepts, actors, and their permissions. The traverses of actors with certain accessing rights are visualized in text and graphic styles. The graphical style presentation of traverses is shown in Fig. 4. In the figure, the traverses are presented as the reachable scope of an actor “non-member” who starts from SearchVehicleKey. We were able to get four traverses within the scope. The tool also gives us the traverses in a text style. One of the traverses is shown in a text style as follows.
The highlighted scope for Non-member with a read right from SearchVehicleKey.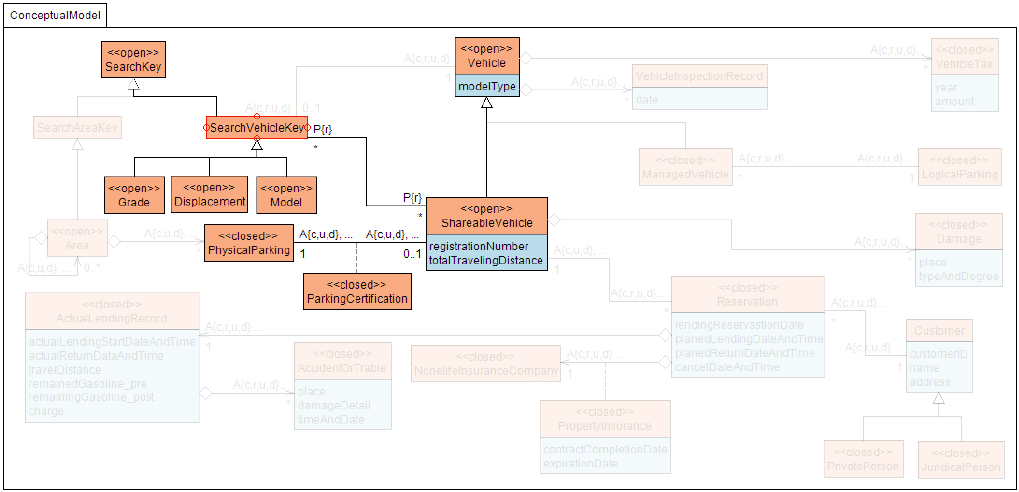
An actor Nonmember who accesses a/an SearchVehicleKey object or a/an Model object or a/an Grade object or a/an Displacement object can access(read) the ShareableVehicle objects from the SearchVehicleKey object, and the ParkingCertification objects from each ShareableVehicle object as association object.
Traverser tool generates requirements of the prohibition of actor’s access, so that the tool helps a domain expert eliminate errors of permissions and/or the structure of the ontology by reviewing the traverses. The requirement of prohibition accesses is similar to “inverse requirement” that Berry, D. et al. proposed [24]. The permitted and prohibited accessing requirements are as follows.
An actor Nonmember can access (read) the PhysicalParking object from the Area object. An actor Nonmember is prohibited from accessing (read, create, update, delete) the ManagedVehicle object from the LogicalParking object.
Overview of the experiments
The case of our experimental evaluation is a car-sharing management system (CSMS). The CSMS is designed as a web system to manage not only rental records, but also the state of the vehicles in three periods: i.e. (1) from when the company orders a vehicle to when it becomes available as a sharable vehicle, (2) when the vehicle is available as a sharable vehicle, and (3) from when the vehicle is no longer a sharable vehicle until it is removed from the database. Because vehicles are legally required to have a garage certificate in Japan, the CSMS has data of a parking lot for every vehicle. LogicalParking is the data of a logical parking lot within the system for the first and the third states of the vehicle. Therefore, instances of LogicalParking are managed electronically only by the staff of the car-sharing company, not at a specific address or physical parking lot.
The scope of the ontology covers the objects with the following functions.
Manage the conditions of each vehicle including its three states, scratches, insurance, as well as yearly tax payments. Manage the rental records of registered members. Manage reservations, as well as cancellations of applications. Provide data for searching the available sharable vehicles.
Figure 5 shows the ontology of the system.
The ontology of a car-sharing system (part) and its actor model.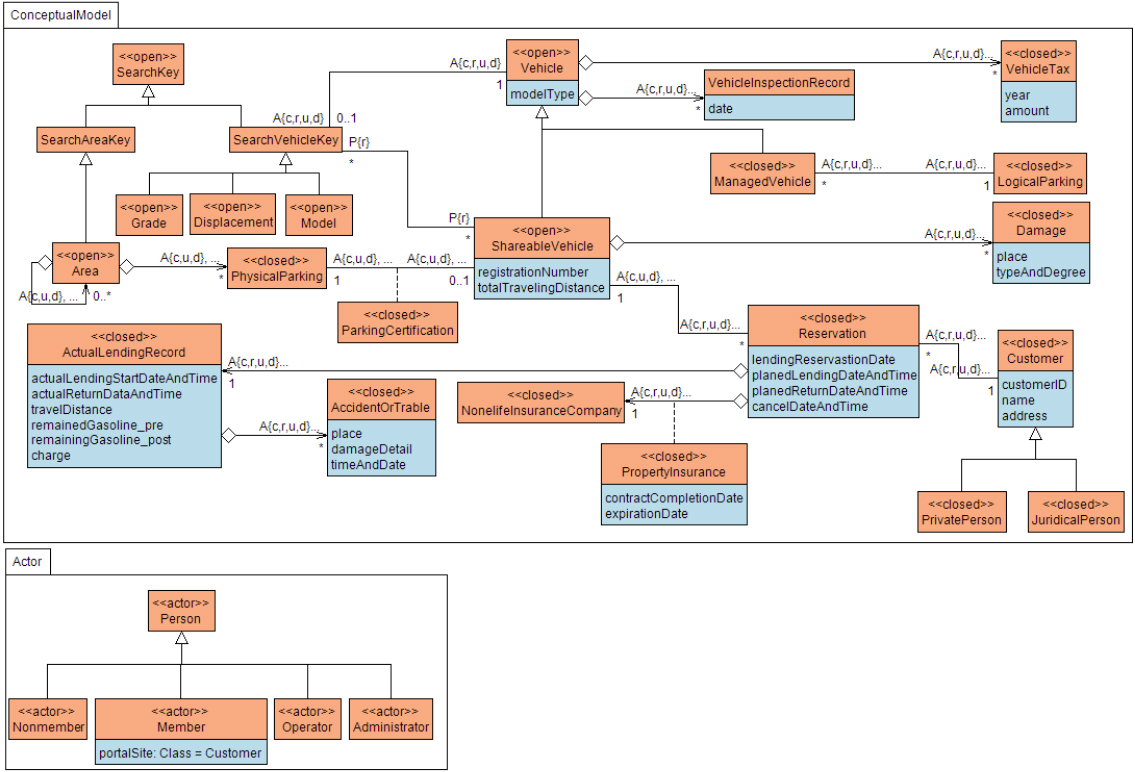
In order to answer the two research questions, the experiments are designed as follows.
Request a UML modeler and a domain expert for cooperation. Select two subjects of the experiments. Two subjects are joined to our research project in order to evaluate the effectiveness of Traverser. The first subject is the domain expert of the CSMS, and the application of Traverser. The other subject is a requirement analyst, and is assigned to apply use case analysis to elicit requirements. A domain expert lectures a UML modeler on the CSMS. After the lecture, the UML modeler provides a class diagram of the target system as an ontology. In order to eliminate any differences between subjects in the level of knowledge, we provide the complete ontology for the subjects. Therefore, the Traverser approach needs to come first. The ontology is built by the UML modeler and is reviewed by a domain expert. The first experiment: Traverser approach Prior to the experiment, we explain to the subject, who is the domain expert, the process of Traverser described in Section 5 and how to utilize Traverser tool. The domain expert defines permission information into the ontology with the Traverser tool. The ontology is reviewed by the expert with the traverses’ output from the tool. The subject repeatedly reviews and updates the model until the Traverser tool outputs the proper traverses, in other words, requirements. The final version of the ontology will be served to the second subject. The second experiment: use case approach In order to evaluate the effectiveness of Traverser, we chose the use case approach as the method for comparison. First of all, use case approach is a popular method in defining functional requirements. The traverses of visitors are also functional requirements. However, there is a difference in the perspective of requirements analysis between the two methods. In these two experiments, we reveal the weaknesses and strengths of the two methods. The subject of this experiment receives the ontology from the UML modeler. Note that, for the second subject, the provided ontology is a simple class model as it does not contain permissions data. After the question and answer session, the subject gets more information from general documents on the car-sharing business and defines use cases. Evaluation We evaluate the effectiveness of Traverser and its tool by comparing and analyzing the results of both experiments.
The domain expert had over ten years’ experience in developing the CSMS. First, he reviewed the ontology. Second, he defined an actor model and added permissions on each association in the ontology. For example, he selects the concept SearchKey to start the review and browses the visualized scope to review all the concepts, actors, and their permissions. Third, he reviewed the textual based traverses. He took eight hours to define the permissions and review both the allowed and prohibited traverses generated by the tool. During the experimentation, he reported defects to the UML modeler; e.g. errors in attributes, relationships between classes including associations and inheritances, as well as inconsistencies in the ontology with the real world. With reference to his report, the modeler updated the ontology within the hours prior to a web meeting with the domain expert. As we mentioned in Section 6.1, Fig. 5 shows the ontology as the final version of this experimentation. The ontology was provided to the following experiment after the permission data was deleted.
Finally, Traverser tool could output 76 requirements including prohibited requirements for each actor on a read permission. In total, we were able to get 304 requirements. Table 1 shows the number of read requirements extracted as traverses. Table 2 shows the number of traverses from SearchKey object for each actor.
The access requirements derived from traverses
The access requirements derived from traverses
The number of traverses from SearchKey object for each actor
The subject of this experiment had more than twenty years of experience in use cases and object-oriented methodologies. In defining use cases with reference to the ontology without permission data, he considered phenomena shared between the real world and the system world of use cases. He said that interaction between an actor and the system means sharing real-world phenomena. He defined the situation of use cases in consideration of shared phenomena [25]. Subjects spent approximately a week on the experiment. The functional requirements are told in the web meeting. Table 3 shows the major use cases and the shared phenomena with the real world and the system.
The major use cases and implied situation
The major use cases and implied situation
The requirements elicited by the subject were different requirements from the requirements generated by Traverser. The subject elicited functional requirements of the system and the conditions for those functions to operate appropriately. Though the number of requirements could not be quantitatively compared to the number of requirements extracted by Traverser tool, the requirements defined by the use case approach are qualitatively different from the requirements defined by the Traverser approach.
Weaknesses and strengths of traverser
The weaknesses and strengths of Traverser compared to the use case approach are as follows.
The strengths of Traverser
Because the traverses are written in natural language, it was easy for the domain experts to discover incorrect traverses. The ambiguities of traverses that come from the natural language are mitigated by the prohibited traverses. More than 300 requirements for “read permissions” alone could be elicited automatically. The precondition of a permitted action is incorporated within traverses for use case descriptions. Traverser provides preconditions for each use case that derived from traverses. The weaknesses of Traverser
The ontology of an application domain is mandatory to apply Traverser. However, the ontology can be built step by step by reviewing the extracted traverses. Traverser does not help analysts consider the real world around the requirements, because the tools automatically output the traverses from the ontology. Therefore, we cannot realize the situation when an actor reserves a shared vehicle in which the return of a shared vehicle is behind schedule with Traverser.
As analyzing the weaknesses and strengths of Traverser, Traverser can complement the use case approach.
One threat of internal validity is that the observed effectiveness of Traverser and its tool depends on the domain expert. Because the domain expert who participated in the experiment was able to read the ontology, he was able to review the ontology. However, in order to mitigate the threat, the tool provides two kinds of output, i.e. natural language based text and graphical styles. The domain expert reviewed traverses in the text style. Even if a domain expert cannot read a conceptual model, they can point out the defects of traverses written in natural language.
The threats of external validity
Is every engineer able to build the complete ontology? If the tool outputs wrong traverses, there are errors in the ontology. Thus, the tool will be able to help engineers fix errors within the ontology. There is however another threat. If the size of the ontology becomes too large, the number of traverses will explode. That being the case, if the size of the model does become too large, the ontology can be divided into smaller sized ontology as sub-ontologies.
Limitations of traverser
The Traverser approach has some limitations. Since the ontology is an abstract model, we cannot generate scenarios with concrete objects. The tool can generate only possible traverses as an ordered list of classes. An actor who is allowed to read a <<closed>> object is not defined well enough in the Traverser. Traverser only mentions permissions on associations/aggregations between classes, not the links between objects.
Conclusion
In this paper, we have proposed a method and a tool to extract traverses from a conceptual model, and an actors’ inheritance structure based on their permissions. The focus of our research was to solve a problem of web systems by defining requirements on “Berrypicking” activities. The novel point of our research is that we have introduced the structure of the conceptual model, and have developed Traverser tool, that can extract traverses from the conceptual model automatically. By experimental studies, we concluded that the method and tool can contribute to complementing the use case approach. In our future work, we will extend Traverser to generate use case descriptions and take into account the structure of the services based on the user experience.
Footnotes
Acknowledgments
We thank Mr. Hideo Goto and Prof. Taichi Nakamura who gave us insightful comments at National Institute of Informatics. We would also like to thank Mr. Terunobu Fujino for his cooperation in the experimental evaluation and Mr. Shigenori Takeda for giving us the opportunity to discuss the ontology. This work was supported by the president’s discretion of OUJ in 2018. This work has been also supported by JSPS KAKENHI Grant Number 19K11905 since 2019.