
Abstract
Big data analysis has gained immense attention throughout classical techniques, which connect in mining the hidden samples from huge data. To relieve computational complexity, the clustering technique is adapted as an imperative part. A novel model is devised for privacy preserved clustering of data with MapReduce framework. The aim is to devise an optimization technique for privacy preservation. The input data is acquired from various distributed sources. The data is further partitioned and fed to MapReduce framework, which consist of mapper and reducer. The mappers perform privacy preservation by encrypting the data with several functionalities, like encryption, Kronecker product and secret key. Here, the secret key generation is performed using proposed Chimp Grey Wolf Optimization (ChGWO) algorithm. The proposed ChGWO is developed by combining Chimp Optimization algorithm (ChOA), and Grey Wolf Optimizer (GWO). The fitness is newly developed considering utility and privacy. The privacy is Jaro Winkler similarity and utility is accuracy. Finally, the data clustering is carried out with the Deep Fuzzy Clustering (DFC). The proposed ChGWO offered enhanced efficiency with highest utility of 92.5%, highest privacy of 91.5% and highest random coefficient 65.9%.
Introduction
The big data indicates huge quantity of unstructured and structured data with increasing 2.5 Exabyte’s each data. The quick augmentation in data quantity is because of mobile data, YouTube, web-services, health care data, digital cameras, Global positioning system (GPS) signals, and social media, such as twitter and Facebook. In general, the big data are classified into variety, volume and velocity. Here, the volume refers quantity of data bigger than petabytes or Terabytes. The velocity indicates the data speed shared and variety indicates detonation of novel data kinds from mobile computing, social sites and machine devices. The big data is utilized for bringing modifications in society and business termed as big data analytics [9, 10, 5]. The big data involves huge database means which is impossible for generally utilized software applications for managing and processing the data in requisite time instance [13]. The Hadoop is an open-source cloud infrastructure for Apache Foundation that offers software programming model known as MapReduce and Hadoop distributed file system called as HDFS. The major feature of Hadoop is splitting of data and count of hosts and implementing application in parallel close to the needed data. The major parameters of Hadoop are that it is superfluous and consistent that as if you lost a machine, because of some failure, then it automatically replicates the data without operator. It is strong in data access and initially batch processing centric and made it simple to distributed applications with MapReduce model [11, 12, 14, 17, 18].
The security and privacy of big data has acquired huge attention in the research communities because of promising techniques, such as social networks, Cloud Computing and analytics engines [21]. The security in big data has acquired severe issues and gained the focus towards privacy preservation techniques [28, 19]. The infringement of privacy throughout the data aggregation and communication even in the deficiency of confidential information regarding the individuals as advanced data mining methods are effective. Thus, the privacy problems undergo an unparalleled growth based on diversity and importance [20]. The security represents the exercises to defend data and its assets in terms of processes, technology and training from the illegal access, and Destruction. The security concentrates on preserving the data from attacks and averts incorrect utilization of stole data for profit [22]. The clustering is a process wherein the data are set as clusters on the basis of data point’s similarity. The data in cluster contains huge similarity amongst each other while the data amongst cluster acquires low similarity [15, 16, 7].
Clustering is a technique utilized for splitting the input into group of specific sets. The same objects are imperative possessions for clustering the data. In various applications, the clustering is utilized that involves forensics, user comfort ability assessment and bioinformatics. The novel research termed as clustering protection had raise to address the privacy issue when the sharing of data is performed. The privacy in clustering certifies precise clustering result [2]. The clustering can be defined by integrating similar instances of database into similar group based on specific data features. For evaluating the criterion of clustering technique, the attributes, which are same to each other must be in same group. There exist four clustering techniques, like connectivity-assisted, centroid-assisted, density-assisted and distribution-assisted techniques [3]. Clustering is an unsupervised learning method for grouping same data of parameters. The aim of clustering is to discover basic sets in group of unlabelled huge database. The data clustering can be utilized in several research areas, like spatial databases, mining data, recognition of pattern, medical domain, Market analysis and web statistics [6]. The design of Deep Neural Networks (DNNs) can be utilized for transforming the data into more clustering because of inherent non-linear transformation. For the ease of explanation, a clustering technique with deep model is utilized. As the deep clustering is to learn a clustering-based representation, which is not apposite for classifying techniques based on clustering loss [23].
The goalis to design a technique for data clustering through the generation of optimal coefficient using proposed Chimp Grey Wolf Optimization (ChGWO). The input big data are acquired from the dataset and the data is partitioned and fed to MapReduce model that comprises mapper and reducer. In mappers, the privacy preservation of data is developed using various functionalities, such as encryption, Kronecker product and secret key where the optimal coefficients are evaluatedwith proposed ChGWO algorithm that is devised by combining ChOA, and GWO. The optimization utilizes fitness factor as privacy and utility where accuracy is utility and Jaro Winkler similarity is privacy. The data processed at each mapper are fused by merging process and fed to reducer phase where data clustering mechanism is carried out using DFC.
The major contributions of the paper is:
Proposed ChGWO for privacy preservation: The proposed ChGWO is devised for data clustering through the generation of optimal coefficient. The ChGWO is obtained by integrating GWO and ChOA. The optimization utilizes fitness factor as privacy and utility where accuracy is utility and Jaro Winkler similarity is privacy.
The organization of paper are, Section 2 comprises classical privacy preservation techniques, Section 3 devises proposedChGWOfor generating optimal secret key for privacy preservation, Section 4 portrays effectiveness of devised model, and Section 5 presents conclusion.
The acquisition of privacy preservation while sharing data from cluster is complicated process. To solve this problem, the owners of data should meet privacy needs and certify valid clustering outcomes. Thus, the issue and challenges of previous technique are considered as a motivation to develop a novel technique.
Literature survey
The eight conventional methods usingprivacy preserved clustering are illustrated with its advantages and issues. Banasode and Padamannavar [1] developed cryptographic technique for providing elevated security in big data with less time. Here, the decryption and encryption were considered using Indexed RSA (IRSA). In addition, the keywords were indexed prior to encryption. However, this technique did not perform security assessment with other attacks. To deal with other attacks, Bolla and Anandan [2] developed a Multi-Label Big Data Clustering with Privacy Protection Probability Linked Weight Optimization (MLBDC-PP-LWO) for privacy preserved data clustering. Here, the sensitive data was preserved by forming clusters. However, this technique did not utilize feature selection for increasing the privacy. To enhance privacy, Catak et al. [3] utilized homomorphic encryption for privacy preserved clustering using cloud model. The entities of system do not require high processing power as the power demanding process were done by cloud system provider. However, the method did not offer effective accuracy. To mitigate accuracy issues, Lekshmy and Abdul Rahiman [4] developed Privacy Preserving Distributed Data Mining. Here, a sanitization technique was utilized to enhance the privacy of user data. Moreover, a privacy-assisted fitness was devised by generating the optimum key. In addition, ABC technique was usedto encrypt huge data. However, if the loss of information is high, then it is complex for hackers to predict the data. To prevent information loss, Khan et al. [5] developed clustering-based privacy preservation probabilistic technique for dealing with big data in order to secure confidential data. The method attained minimal perturbation and high privacy. However, this technique caused overhead when there is huge data to process. Zou et al. [6] utilized k-means clustering with non-colluded Cloud Computing Service (CCS) for effective privacy preserved clustering of data. Here, the bulk copy program (bcp) encryption was utilized to encrypt the data records and the cryptosystem averts the CCS from generating beneficial data from ciphertexts. However, this technique did not adapt other security attributes. To involve security attributes, Kulkarni et al. [7] utilized MapReduce framework (MRF) and handled data arrived from various sources. Here, the mapper utilized Fractional Sparse Fuzzy C-Means (FrSparse FCM) for clustering and reducer utilized particle swarm optimisation-based whale optimisation algorithm (P-Whale) for optimum tuning. However, the method did not able to evaluate computation overhead. To deal with computational overhead issues, Kulkarni et al. [8] developed a method, namely FPWhale-MRF for clustering data with MapReduce. Here, the mapper utilized Fractional Tangential-Spherical Kernel clustering algorithm to evaluate cluster centroids. The reducer integrated the mapper output to discover the optimum centroids with P-Whale. However, the method did not consider all security factors.
Challenges
The problemsfaced by the previous privacy preservation strategies are enlisted.
Due to escalating attacks on re-discovery, the link from several locations of public data is not adequately secure to emulate the source subjects [2]. To secure data, information perturbation technique is commonly utilized by changing original information data, but it bought up several issues, like information misrepresentation and hence prompts to knowledge loss [4]. For dealing with information misrepresentation, a cryptographic technique [1] is utilized by offering elevated security in less time, but it failed to offer security assessment with various kinds of attacks. To deal with several attacks, the FrSparse FCM is utilized. However, due to huge quantity of big data, there exist huge data objects and it needs large time for processing. In addition, the majority of classical techniques needs time to process and suffered from huge computational complication [7]. The major issue of clustering big data is that this technique is heterogeneous, large and vibrant as key are accumulated from several sources without benchmark format.
Structure of privacy preserved clustering model using proposed ChGWO.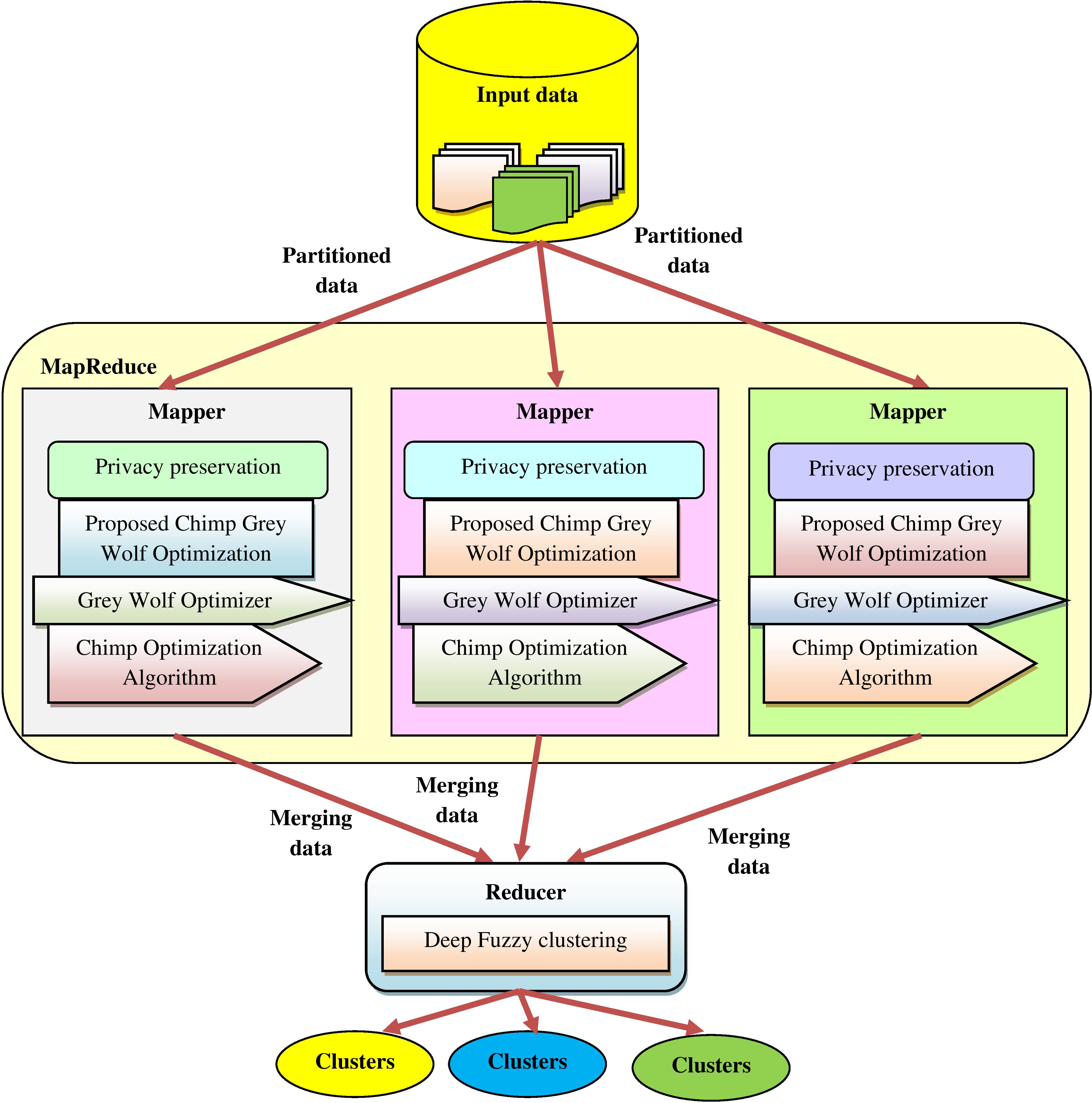
The data privacy is compromised throughout the process of data mining for extracting beneficial data. Due to huge security, the privacy became a major problem. The majority of privacy preserving techniques utilize data transformation for preserving the privacy of data, while controlling the data availability and became essential domain in information security. The goal is to devise a technique for data clustering by generating optimum coefficient with proposed ChGWO. At first, the inputted big data is attained from dataset, and the data is partitioned and subjected to MapReduce, which consist of mapper and reducer phase. In mappers, the privacy preservation of data is done by encrypting the data considering several functionalities, like encryption, Kronecker product and secret key where the optimal coefficients are computed using proposed ChGWO algorithm. Here, the proposed ChGWO is developed by combining ChOA [24], and GWO [25]. The fitness factor is newly devised considering accuracy and Jaro Winkler similarity. The obtained data is processed in each mapper and fused by merging process and subjected to reducer phase wherein the data clustering is performed using DFC. Figure 1 reveals structure of privacy preserved clustering model using proposed ChGWO.
Assume an input data is denoted as
where,
The data
where,
For reducing the time of computation and for controlling the dispersed data, this model used the MapReduce model wherein the computational problems are reduced by effectual secret key generation. The technique attained enhanced accuracy of classification by effective parallelism of server, which processes the big data partitions in parallel. The proposed model considers two steps for effective privacy preservation in which one is privacy preservation in mapper and second is clustering using proposed ChGWO. Here, the privacy preserved data clustering is carried out in MapReduce using proposed ChGWO. Here, the privacy preservation is done in mappers considering proposed ChGWO and the clustering is carried out in reducer using DFC.
Privacy preservation in mapper
Consider
Thus, input to
where,
Assume
Each mapper acquires the data and process the data, which is given as,
where,
Here, the variable
The privacy preserved data is given by,
where,
Here, the correlation between feature and class label is given by,
where,
The matrix to store the correlation values is given as,
where,
Here, the bilateral matrix is given by,
The Kronecker matrix is expressed as,
where,
The bilinear matrix is given as,
The privacy protected data is given as,
The retrieval key
The retrieved data is represented as,
where,
a) Solution encoding
The modelling of solution is done to define the solution of proposed ChGWOalgorithm. The solution representation helped in generating the optimal key. The solution vector consists of solutions with dimension 1
Solution vector of proposed ChGWO algorithm.
b) Fitness function
The fitness of proposed ChGWOis usedto discoveroptimum key. Thus, it is imperative to consider the attributes related to privacy protection on fitness function. The two imperative factors that generates optimal key are accuracy and Jaro Winkler distance. The end users who request data mustattain the data with highestfitness. Thus, the combination of accuracy and Jaro Winkler distance is described in fitness, and is expressed as,
where,
Here, the utility is accuracy that refers the nearness degree of computed value to original value, and is represented as,
where,
It is very beneficial in estimating the distance amongst two strings. The higher the value of Jaro Winkler distance, the more similar the strings are. It is useful to make effective decisions. The privacy is computed based on JaroWinkler distance wherein the distance is computed amongst original data
where,
where,
c) Generation of secret key with developed ChGWO
The secret key is produced using developedChGWO algorithm. Here, a GWO [25]is motivated from the grey wolves and imitate the quality of leadership. In GWO, four kinds of grey wolves are employed, namely alpha, beta, delta, and omega, which are adapted to provide the quality of leadership. Moreover, three major steps are adapted namely hunting; searching, attacking and encircling prey are executed. Meanwhile, ChOA [24] is inspired from the intellect of each individual and sexual inspiration among the chimps in offering group hunting. It is developed for preventing slow convergence speed by solving high-dimensional issues, such as learning algorithm. It assists ChOA to improve the stochastic behavior and process of optimization and reduced chance to trap in local minima. It effectually balances exploration and exploitation phases. The combination of ChOA and GWO assists to generate the global optimum solutions. The steps of proposed ChGWO is expressed as,
Step 1) Initialization
The foremost step is initialization of solution, and given by,
where,
Step 2) Determination of fitness
The fitness of each solution is determined using Eq. (18), and is already explained in Section 3.2.1b).
Step 3) Driving and chasing prey
According to ChOA [24], the prey hunting is performed with exploration and exploitation stages. For modelling the driving and chasing prey, the equation is modelled and the distance is given as,
where,
The chasing prey is formulated as,
where,
where,
The coefficient vector is given by,
where,
Assume
The GWO algorithm offersimproved accuracy with effectualdetection of attack. According to GWO [25], the update equation is given by,
where,
where,
Assume
Assume
Now substitute Eq. (35) in Eq. (29),
Thus, the final update equation of proposed ChGWO is given as,
Step 4) Attacking behaviour
For modelling the chimp behaviour, it is supposed that first attacker, driver, barrier and chaser are well-versed concerning position of prey. Thus, four optimum solutions are expressed as,
where,
Each best solution are described as,
where,
where,
where,
where,
The distance of each solution is given as,
where,
Step 5) Prey attacking
Here, the chimps attack prey and end hunt as soon as prey terminates its movement. For precisely modelling attacking behaviour,
Step 6) Searching for pray
Amongst chimps, the exploration is done withchimp’s position. It diverges for seeking the prey and accumulates to attack the prey.
Step 7) Social incentive
To attain social meet and pertinent social motivation in final phase causes the chimps for releasing hunting abilities. To model this behaviour, there is a probability to choose among normal update method or chaotic model to update chimp position, and is given by,
where,
Step 8) Re-evaluation update equation withfitness: The fitness of newposition is re-calculatedin whichoptimal key is attained.
Step 9) Terminate: The best solutions are developed in iterative manneruntil maximal iterations is acquired. The pseudo code of developed ChGWO is examined in Table 1.
Thus, the privacy preserved data obtained from the proposed ChGWO is given by
The clustering of privacy preserved data is done using DFC [27] in reducer denoted as
where,
where,
Pseudo code of developed ChGWO
Architecture of Mapper and reduce phase for privacy-preserved data clustering.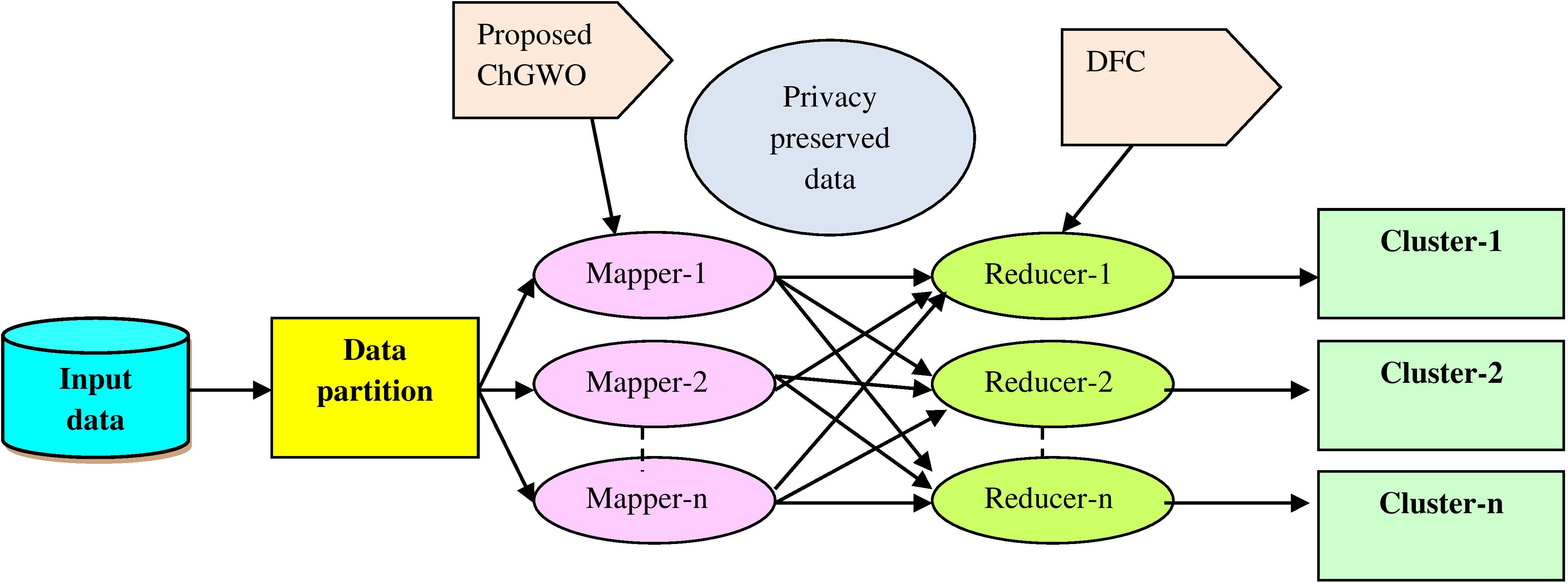
The pseudo labels
The loss function of KL-divergence is given by,
The graph regularization is expressed as,
Here,
where,
Let the clusters obtained by DFC for clustering the privacy preserved data is expressed as,
where,
Figure 3 reveals the architecture of Mapper and reduce phase for clustering the privacy preserved data. For reducing the time taken for evaluation and to handle the dispersed data, the study utilizes MapReduce model that solves complexity problem and computational problems. The two main functions of MapReduce include the map and reduce function which takes input data as pertinent patterns and group intermediary data of mappers to generate clustered output. At first, the input data is provided to the MapReduce framework wherein the partitioning of data is done and fed to mappers wherein the privacy preservation is done using proposed ChGWO and the reducer performs clustering using DFC.
Results and discussion
The efficiency of developed ChGWO is devised with privacy, utility and random coefficient by altering training data.
Experimental set-up
The execution of devised ChGWO is carried out in Python with PC with 2 GB RAM, Windows 10 OS, and Intel i3 core processor.
Dataset description
The analysis is performed with MHEALTH Dataset [26]. This dataset comprises standard methods that deal with the behaviour of human considering multimodal body sensing. Here, the dataset is multivariate in nature. The number of instances is 120 with 23 attributes. The number of webhits attained is 126925. The attribute is real in nature with certain attributes that includes standing still, sitting and relaxing, and Lying down.
Evaluation measures
The evaluation measures considered for the assessment are as follows.
Privacy: It is already described in Section 3.2.1b). Utility: It is already described in Section 3.2.1b). Random coefficient: It refers the similarity amongst two clusters by adapting all pairs of samples. It is also defined as the percentage of precise decisions made by the technique and is given by,
Where,
The assessment of proposed ChGWO is done by varying the size of population and iteration. Here, the assessment is done considering privacy, utility and random coefficient.
Assessment of proposed ChGWO with population size using (a) utility, (b) privacy, (c) random coefficient.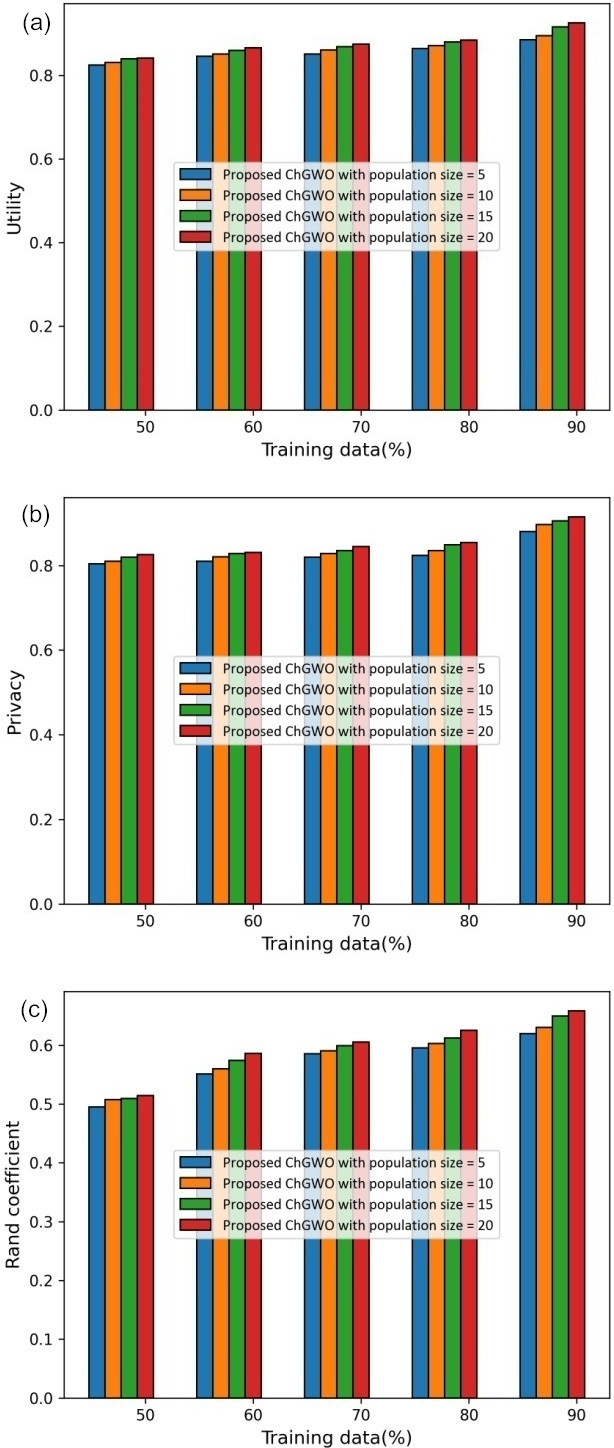
Figure 4 displays assessment of ChGWO with population size. Here, the assessment with utility is displayed in Fig. 4a. For 50% training data, the utility calculated by proposed ChGWO with population size
Assessment by altering iteration
Assessment of proposed ChGWO by altering iteration using (a) utility, (b) privacy, (c) random coefficient.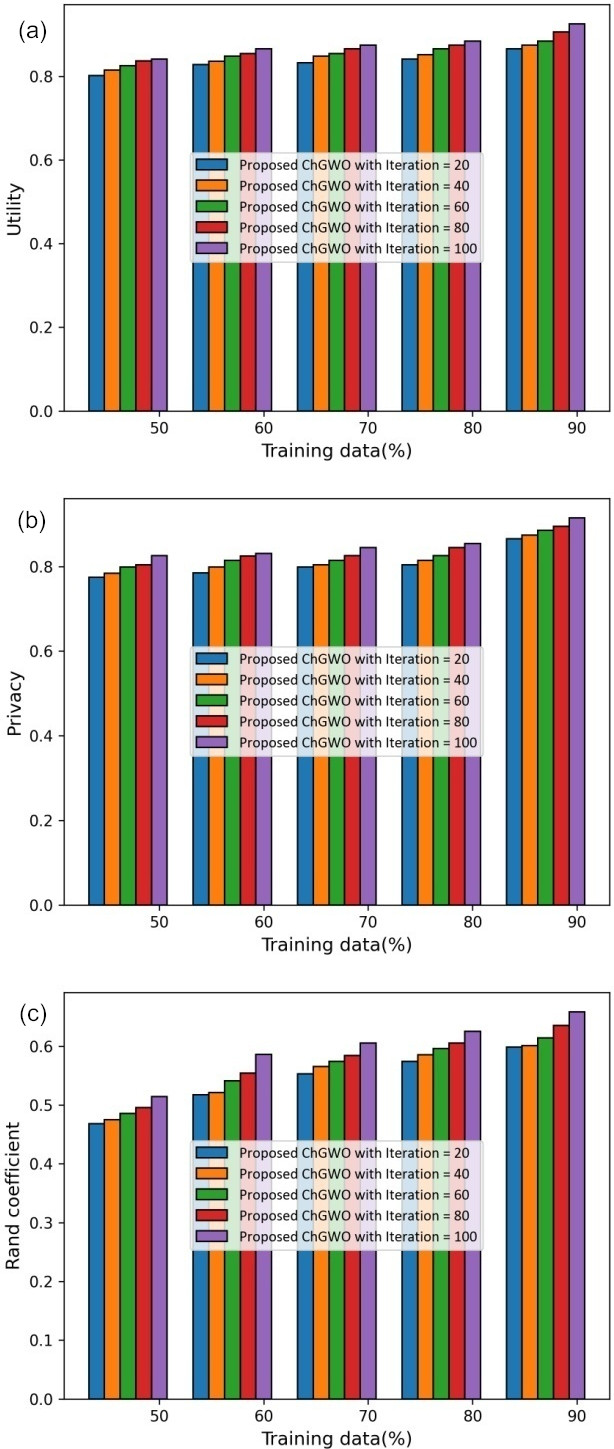
Assessment of techniques with (a) utility, (b) privacy, (c) random coefficient.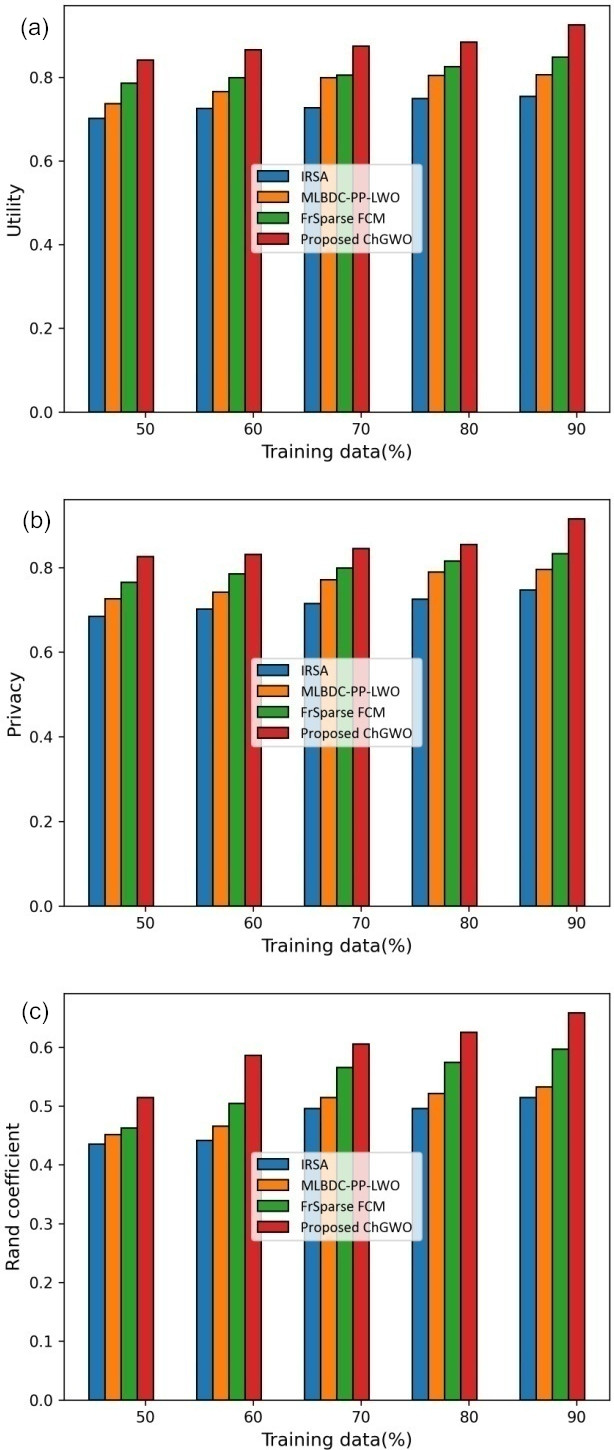
The assessment of proposed ChGWO with iteration is revealed in Fig. 5. Here, the assessment considering the utility is revealed in Fig. 5a. When training data is 50%, the utility calculated by proposed ChGWO with iteration
Also, when training data is 90%, the privacy calculated by proposed ChGWO with iteration
The assessment with random coefficient is revealed in Fig. 5c. When training data is 50%, the random coefficient calculated by proposed ChGWO with iteration
The strategies considered for assessment includes IRSA [1], MLBDC-PP-LWO [2], FrSparse FCM [7], and proposed ChGWO.
Comparative analysis
Figure 6 displays assessment by altering training data. Here, the assessment with utility is revealed in Fig. 6a. For 50% training data, the utility calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.701, 0.737, 0.785, and 0.841. Also, for 90% training data, the utility calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.754, 0.806, 0.848, and 0.925 and the performance improvement with respect to proposed ChGWO is 18.486%, 12.864%, 8.324%. The assessment with privacy is displayed in Fig. 6b. For 50% training data, the privacy calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.685, 0.726, 0.765, and 0.825. Also, for 90% training data, the privacy calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.747, 0.796, 0.833, and 0.915 and performance improved with respect to proposed ChGWO are 18.36%, 13.00%, 8.961%. The assessment with random coefficient is revealed in Fig. 6c. For 50% training data, the random coefficient calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.435, 0.451, 0.463, and 0.514. Also, for 90% training data, the random coefficient calculated by IRSA, MLBDC-PP-LWO, FrSparse FCM, and proposed ChGWO are 0.514, 0.533, 0.597, and 0.659 and the performance improved with respect to proposed ChGWO are 22.003%, 19.119%, 9.408%.
Comparative assessment
Comparative assessment
Table 2 discusses the comparative assessment by altering training data using utility, random coefficient, and privacy. The highest utility of 0.925 is measured by proposed ChGWO while the utility attained by classical IRSA, MLBDC-PP-LWO, FrSparse FCM are 0.754, 0.806, 0.848. The high utility reveals that the proposed ChGWO is effective in extracting data that has high importance. The highest privacy of 0.915 is measured by proposed ChGWO while the privacy attained by classical IRSA, MLBDC-PP-LWO, FrSparse FCM are 0.747, 0.796, 0.833. The high privacy exposes that the proposed ChGWO is effective in encrypting the data and thereby produces elevated privacy. The highest random coefficient of 0.659 is measured by proposed ChGWO while the random coefficient attained by classical IRSA, MLBDC-PP-LWO, FrSparse FCM are 0.514, 0.533, 0.597. The DFC helps to attain elevated random coefficient by effectively identifying the similarity amongst the clusters.
Conclusion
To mitigate computational complexities of big data, the clustering technique is adapted as an imperative part. Here, a novel technique is developed for privacy preserved data clustering using MapReduce model. The goal is to develop optimization technique for privacy preservation. Here, the input data is attained from several types of distributed sources. The data is then partitioned and subjected to MapReduce model, which contains mapper and reducer. The mappers are utilized to perform privacy preservation by encrypting the data with several functionalities, like encryption, Kronecker product and secret key. Here, the secret key generation is done with proposed ChGWO algorithm. The proposed ChGWO is developed by combining ChOA, and GWO. The fitness function is newly developed with privacy and utility factor. Here, the privacy represents Jaro Winkler similarity and utility depicts accuracy. At last, the clustering of data is carried out using the DFC. The proposed ChGWO performed effectual privacy preserved data clustering with MapReduce framework. The proposed ChGWO offered enhanced efficiency with highest utility of 92.5%, highest privacy of 91.5% and highest random coefficient 65.9%. In future, other database can be adapted to validate feasibility of devised model.