
Abstract
The surge in modern information has led to a significant increase in text complexity. To meet the needs of various fields for effective information extraction, research on text complexity grading urgently is urgently needed. The study uses the Flesh-Kincaid Grade Level (FKGL) model to extract language features, selects English textbooks as training corpus, and introduces the Graph Convolutional Network of Attention Mechanism (GCN_ATT) model of attention mechanism to construct a text complexity grading model. The research results indicated that in the 10-fold crossover experiment, GCN_ATT’s accuracy, recall, and F1 all reached over 88%. Compared to multi class logistic regression models, GCN_ATT’s various performance indicators were approximately 2% to 3% higher. Meanwhile, GCN_ ATT’s F1 standard deviation decreased by 0.7% and 1.78% compared to the other two models. In addition, GCN_ATT’s fluctuation range of recall and accuracy was less than 20%, a decrease of 12% and 18% compared to the ordered multi classification regression model. Explanation based on GCN_ATT’s text complexity grading has higher accuracy and more stable performance, providing an effective method reference for current text complexity grading problems.
Introduction
The growth of the Internet era has led to the increasing complexity of text information. As one of the basic tasks in language processing, text classification plays a crucial role in modern information processing. The traditional classification method is to manually classify according to established classification standards, but now it is no longer able to adapt to the rapid growth of information in the information age, and is gradually being phased out. By the 1990s, text classification methods based on machine learning and deep learning emerged and achieved relatively good classification results [1]. These algorithm models consist of two parts: Feature engineering and Classifier. Among them, feature engineering refers to the process of converting text into mathematical form of feature matrices, and classifier mainly includes graph neural algorithm, graph convolutional network (GCN), convolutional neural network, etc. The text classification method of machine learning has improved the classification accuracy to a certain extent, but there are problems such as the lack of representativeness in feature extraction during model construction [2]. In addition, the text information of several commonly used text classification methods is independent of each other, and now many texts have citation relationships between them, which leads to a certain negative impact on the accuracy of text classification. Therefore, the study introduces the Graph Convolutional Network of Attention mechanism (GCN_ATT) model, combined with more representative feature extraction methods and training corpus, and applies it to the establishment of text complexity models [3] to achieve better practical application results in text complexity grading.
Related works
With the arrival of the information age, the amount of information has grown rapidly. Text classification has great significance for real life, and domestic and foreign researchers have conducted relevant research on it. Liu Y et al. explored the impact of text complexity on translation difficulty, using the Likert scale to assess cognitive load, and using the NASA-TLX scale to assess. The results showed that the complexity measured by readability and non-literal meaning was consistent with the evaluation results of translation difficulty [4]. To explore the post editing process of neural machine translation paradigm, researchers such as Jia Y evaluated the output quality of NMT systems from English to Chinese, and the results proved that the text fluency and accuracy of NMT translation were better than other systems [5]. Aydın S proposed a method for complex emotional labeling to address the problem of discrete emotion classification caused by emotional videos. This method estimated the phase locking value of the left and right hemispheres by using the long-term and short-term memory network to observe the nine discrete emotions of clustering. The results showed that the classification accuracy of this algorithm was as high as 98% [6]. To explore the longitudinal language development trends of college students, Biber D’s team proposed a corpus-based method for long-term tracking of college student groups and collecting language features of subject writing. The results showed that phrase complexity has important guiding significance in academia [7]. Scholars such as Zhao Y designed an asymmetric denoising method to address the issue of traditional sequences overly relying on the number of parallel sentences. This method added different noises during encoder modeling, and the results showed that it effectively simplified the unsupervised model and enhances the competitiveness of the simplified system [8].
Chen W compared the quality of articles written by two classes of students after participating in collaborative writing activities to explore the benefits of second language collaborative writing activities for individual text writing. The results showed that the personal creative accuracy and quality of students who participated in the activity were better than those who did not participate in the practice [9]. On the basis of morphological complexity, researchers such as Lee JD proposed the morphological complexity index. This index mainly assisted native Italian and non-native English speakers in writing argumentative papers, and the results showed that there was no correlation between morphological complexity and other complexity measures [10]. Adhariani D’s team designed techniques such as reading ease to evaluate the readability of sustainability reports to investigate their readability. The results indicated that this method was beneficial for evaluating the readability of sustainable development reports and was easy to read and understand [11]. Katarya R’s team developed a new product recommendation system, CapsMF, to address the filtering and screening issues of a large amount of online information. The system utilized a new neural network architecture to optimize the text analysis model, and the results showed that the performance of the text analysis model using this system was significantly better than other models [12]. To distinguish the literariness of different novels, scholars such as Van Cranenburg A proposed a machine learning method, which divided the text into blocks and used neural file embedding to create vector space to predict the literary rating of novels. The results showed that this method had strong feasibility [13].
In summary, researchers have proposed many effective text classification techniques for various fields, and also introduced machine learning algorithms to improve the accuracy of text classification. However, the current algorithms are not precise enough for feature extraction in the model, which affects the accuracy of classification. Therefore, the model still needs further optimization.
Text complexity granularity classification based on language feature neural network
Text classification based on GCN
Text classification refers to the process of associating target text with one or more categories based on the characteristics of the text within a pre-defined classification system. The complexity grading of text belongs to the category of text classification, which constructs a classification model by learning language features from corpus of different complexity levels to determine which complexity level the text belongs to [14]. The study introduces classification of GCN based on deep learning algorithms and applies it to text complexity classification. The GCN model is shown in Fig. 1.
GCN model.
The construction of GCN model for text classification requires the establishment of adjacency matrix and feature matrix. The adjacency matrix represents the weight of edges between each point [15]. The characteristic matrix refers to the node vector matrix representing the attributes of each node. The initialization vector of each node will be used as an identity matrix. Its representation is shown in Eq. (1).
In Eq. (1),
In Eq. (2),
In Eq. (3),
In Eq. (4),
In Eq. (5),
In Eq. (6),
Skip gram model and CBOW model structure.
In Fig. 2,
In Eq. (7),
In Eq. (8),
The Skip gram model has a similar structure to CBOW, but the prediction direction is opposite. It mainly infers surrounding words based on the current input words. The calculation is shown in Eq. (10).
In Eq. (10),
GCN_ATT schematic diagram.
In Eq. (11),
In Eq. (12),
In Eq. (13),
The above steps are repeated to gather information from all nodes in the text to obtain a new feature matrix, as shown in Eq. (15).
In Eq. (15),
The purpose of constructing a text complexity grading model is to enable the target text content to be understood by machines and determine which complexity level the target text should belong to based on its displayed features. The specific steps are to first use appropriate text processing tools to extract language features that represent the complexity of the target text, and then perform principal component analysis to reduce dimensionality and optimize them. Then, a set of reasonably graded textbooks is selected as the training corpus for constructing the model. Finally, the best algorithm is selected by comparing the actual calculation results of several commonly used algorithms, and based on the training data of this algorithm, a hierarchical model is established and performance evaluation is conducted [18]. The specific steps are shown in Fig. 4.
Steps for building a text complexity grading model.
The research introduces text processing software TAALES, TAASSC, and TAACO to extract the complexity features of the vocabulary, syntax, and discourse dimensions of the target text. At the same time, BNC baby is used as a reference corpus, and principal component analysis is used to provide corresponding indicators for various software for dimensionality reduction processing. Because the distribution of indicators of normal distribution is too sparse in the paper, the study first judges the data distribution state through the nonparametric Kolmogorov-Smirnov test and removes indicators of normal distribution. Then, multicollinearity test is performed on the remaining indicators to delete the highly relevant indicators to ensure the diversity of test variables. Finally, Kaiser Meyer Olkin (KMO) and Barlet sphericity are used to test the remaining indicators and complete the screening and extraction of principal components [19]. The selection of training corpus has a great impact on the performance of the model, and the higher its representativeness, the better the performance of the model. The research requires that the selected corpus must have reliable sources, standardized language, and accurately reflect differences in complexity. At the same time, the text complexity of the training corpus needs to increase step by step, and multiple texts with the same complexity level should have consistency. In addition, the size of the training corpus should not be too small, otherwise it will affect the effectiveness of the training results. The study selects the textbook New Concept English for analysis, and its unit clustering tree diagram is shown in Fig. 5.
New Concept English unit clustering tree diagram.
In Fig. 5, the left and right numbers on the node represent two
Text complexity grading is actually a text classification problem. Traditional classification methods include ordered multi classification regression and multi class logistic regression, which first make assumptions about the model data, then mathematically derive these assumptions, and finally obtain the model formula. The assumptions about the model directly determine its usability, making it relatively complex to operate. The different neural network is mainly from the objective point of view, using the idea of bionics to imitate the human brain to build models. The model structure can be seen as a nonlinear superposition of multiple linear regression models, which transforms the originally nonlinear problem into an approximately linear problem through layers of nonlinear changes. The study selects New Concept English for training and divides the texts of volumes 2, 3, and 4 into three complexity levels. The research involves the concurrent extraction of language features from text while performing dimensionality reduction. This is achieved by utilizing multi class logistic regression, ordered multi classification regression, and GCN_ATT algorithm. Additionally, a complex nonlinear function is fitted from features to level target values [20].
Model evaluation plays a key role in natural language processing. The study uses a 10-fold cross validation method to test the actual application effectiveness of the model. The specific steps are to first sort the 201 texts in the New Concept English into 3 levels based on complexity, and randomly divide them into 10 mutually exclusive subsets. Then, one subset each time is selected as one training set, and the union of the remaining nine subsets as another training set. The operation is repeated 10 times, and finally the mean of these 10 test data can be obtained. The specific process is shown in Fig. 6.
To construct a better performance text complexity grading model, the study first verified the effectiveness of text language readability features. The study used BFSU-HugeMind Readability Analyzer 2.0 to calculate six readability formulas, namely Automated Readability Index (ARI), Flesh Kincaid Grade Level (FKGL), Flesh Reading Ease Score (FRE), SMOG index, Gunning Fog index, Coleman-Liau index, and Coh-Metrix L2 Readability (RD2). At the same time, New Concept English was set as the training corpus, and after summarizing the readability indicators mentioned above, it was sequentially used as input features to construct a text complexity grading model. The performance indicators obtained through 10-fold cross validation are shown in Table 1.
Performance analysis of different readability indicators
Performance analysis of different readability indicators
10 fold cross validation flowchart.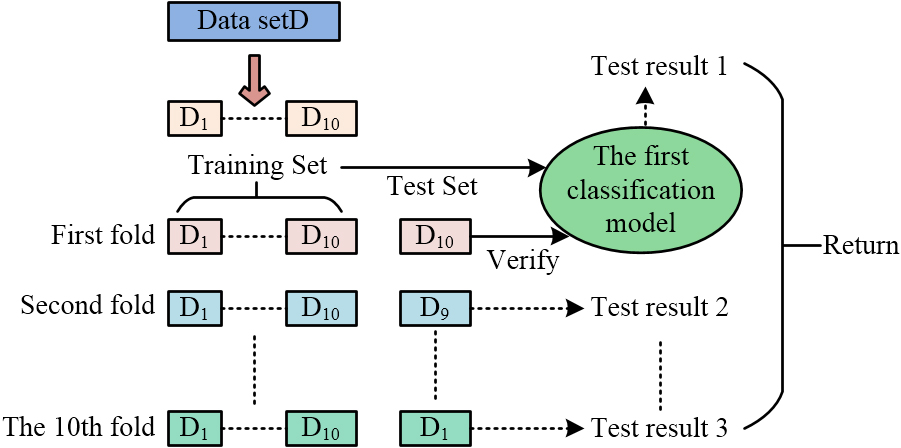
In Table 1, compared to other readability formulas, the FKGL model had the highest accuracy, recall, and F1 value, reaching 75.23%, 70.69%, and 70.92% with the lowest standard deviation of F1 value being 8.21%. This indicated that the FKGL model had the best performance and stronger stability. The RDL2 model could accurately distinguish 59% of reading materials, which was significantly better than the FKGL model. However, its training corpus was generally non academic news texts, so the results of various indicators of the RDL2 model were not ideal. Due to the fact that the target corpus of the study is English textbook texts, factors such as sentence length and word length had a significant impact on the grading of textbook texts.
Corresponding performance tests were conducted on the algorithm model of the text complexity grading model in the experiment to verify its effectiveness. The specific experimental parameters were a sliding window size of 40 and a step size of 5. The embedding dimension value of words was 200, and dropout was set to 0.6. Each round of training was limited to a maximum of 400 times, and training stopped after ten rounds. The study selected several common text classification models, including CCN-rand and Bi_LSTM, TextGCN, and GCN_ATT models. And the model performance was compared with the F1 value and accuracy reflected on the 20NG and MR datasets. The experimental results are shown in Fig. 7.
F1 value and accuracy of different models on the dataset.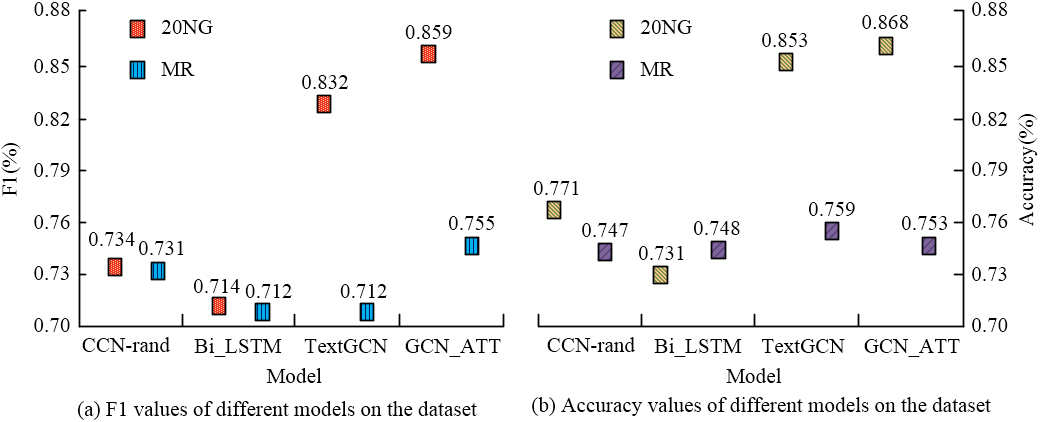
The influence of different factors on the accuracy of experimental results.
As shown in Fig. 7, compared to other models, GCN_ATT model had significant advantages in F1 values and accuracy on both datasets. Among them, on the 20NG dataset, The F1 of GCN_ATT was as high as 85.9%, with an accuracy of 86.8%, which was 14.5% and 13.7% higher than Bi_LSTM. In the MR dataset, the highest F1 value of this model was 75.5%, 4.3% higher than the TextGCN model. The study continued to conduct experimental validation on factors that may affect the accuracy of text classification. The validation results are shown in Fig. 8.
In Fig. 8a, before the sliding window size reaches 40, the accuracy of text classification increased with the increase of the window, reaching a maximum of 94.6%. But when it exceeded 40, the accuracy began to decline. The effective text information increased with the increase of the window, but when it exceeded a certain limit, the feature extraction effect would be affected. Therefore, it was necessary to select a sliding window of appropriate size to ensure that the training can proceed in an orderly manner. In Fig. 8b, there is a certain fluctuation in the accuracy of text classification. When the embedding dimension of text words was 200, the accuracy of text classification reached the maximum value of 94.28%. When it exceeded 200, the accuracy showed a downward trend. Within a certain range, the increase in word embedding dimension increased the effective information of the text. But exceeding a certain range would have a negative impact on the information aggregation performance of GCN, leading to a decrease in accuracy. As shown in Fig. 8c, as the number of convolutional layers increased, the accuracy of text classification showed a downward trend. The increase in the number of layers could improve computational accuracy for forward propagation, but it also led to an increase in computational complexity. For back-propagation, due to the long waiting time, the probability of overfitting phenomenon would increase significantly, thus affecting the final result. Therefore, the model generally selected 2 layers as the number of convolutional layers for research.
The study further utilized three algorithms for a 10 fold crossover experiment, namely GCN_ATT, multi class logistic regression, and ordered multi classification regression. Among them, the language input features of the text complexity grading model included 1 text length, 3 discourse complexity, 6 lexical complexity, and 9 syntactic complexity. At the same time, the input dataset was divided into 10 equal parts according to three text complexity levels, followed by 10-fold cross validation and comparison of the average performance of the three algorithms. The recall rate, accuracy, F1 value, and standard deviation of each model are shown in Fig. 9.
Comparison of 10 fold crossover performance of three models.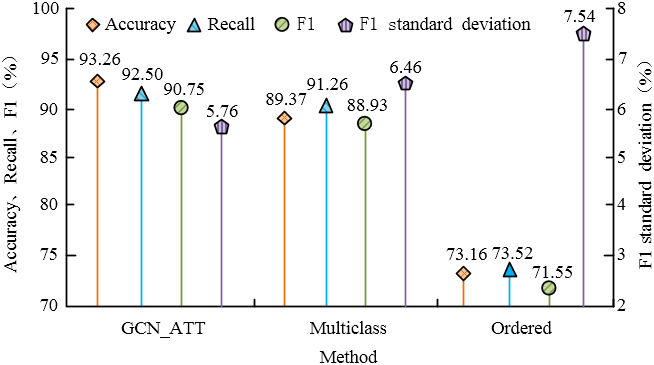
As shown in Fig. 9, the performance of the ordered multi classification regression model was relatively weak, with none of the three indicators reaching 74%. The performance of GCN_ATT and multi class logistic regression was stronger, with indicators exceeding 88%. The performance advantages of these two models were mainly reflected in the fact that each dependent variable in the model was not affected by the position of the segmentation point. In addition, compared to multi class logistic regression models, the performance indicators of GCN_ATT were approximately 2% to 3% higher. Meanwhile, the F1 standard deviation was an indicator that reflected the volatility of the model. The larger the SD, the greater the volatility of the model, and its performance was also more unstable. Compared with multi class logistic regression and ordered multi classification regression models, the F1 standard deviation of the GCN_ATT model was reduced by 0.7 and 1.78. The performance comparison of the 10-fold cross validation model is shown in Fig. 10.
Comparison of 10 fold cross validation model performance.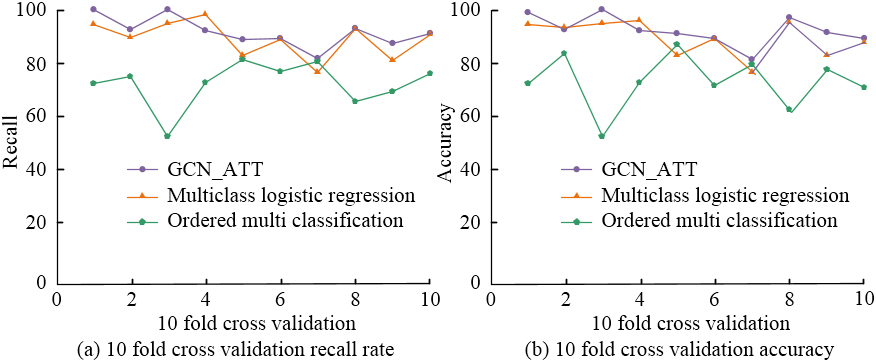
As can be intuitively seen from Fig. 10, the accuracy and recall of the GCN_ATT model were higher than the other two models in 10 validations. Meanwhile, the ordered multi classification regression model had the highest volatility, with a maximum range of 30% for recall and 38% for accuracy, indicating extremely unstable performance. The fluctuation range of recall and accuracy of the GCN_ATT model was less than 20%, indicating its superior stability. Continuing research on the error analysis of confusion matrix between GCN_ATT model and multi class logistic regression model is shown in Fig. 11.
Model classification result confusion matrix.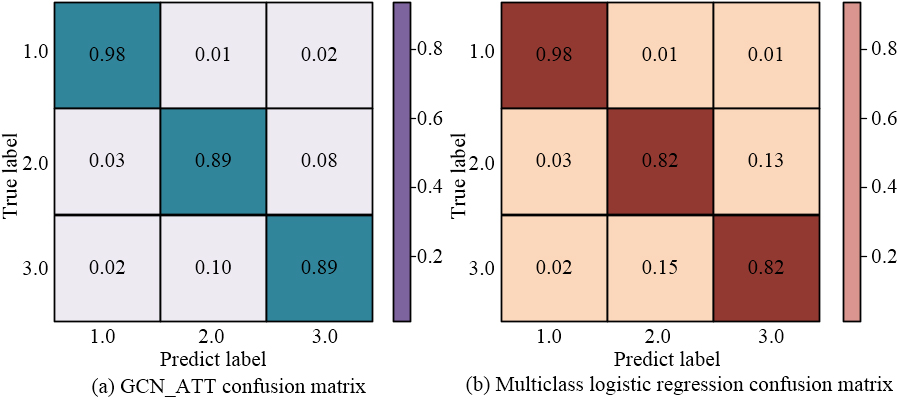
As shown in Fig. 11, compared to GCN_ATT model, the multi classification regression model was only 0.82 in terms of imprecise text judgment for levels 2 and 3. Among them, the target text with incorrect judgments mostly belonged to the explanatory style. And GCN_ATT classified it into the correct level when predicting levels, thus avoiding judgment errors, resulting in a stable result of 0.89. The complexity grading model established by GCN_ATT was less susceptible to the influence of the target text style than the multi class logistic regression model. By comparing the performance indicators of the three algorithm models, GCN_ATT model had higher calculation accuracy, stronger stability, and better performance.
The construction of a language model is conducive to measuring and evaluating text complexity. The study selected New Concept English as the training corpus and develops a text complexity grading model based on GCN_ATT neural network algorithm. The experimental results showed that in the validation experiment of text language feature sets, compared with other readability formulas, the FKGL model had the highest accuracy, recall, and F1 values, reaching 75.23%, 70.69%, and 70.92%. At the same time, its F1 value had the lowest standard deviation, only 8.21%. In the comparison experiment of F1 value and accuracy on the 20NG and MR datasets, F1 value of the GCN_ATT model reached 85.9% and 75.5%, which were 2.7% and 4.3% higher than those of the TextGCN model. Meanwhile, the accuracy of the model reached 86.8% and 75.3%, 13.7% and 0.5% higher compared to Bi_LSTM model. In the experiment to verify the factors that affected the accuracy of text classification, the highest accuracy was 94.6% when the sliding window was 40, and the maximum accuracy of text classification was 94.28% when the embedding dimension of text words was 200. In addition, the accuracy of text classification decreased as the number of convolutional layers increased. In the error analysis experiment of confusion matrix, the accuracy of GCN_ATT in text judgment at levels 2 and 3 was stable at 0.89, 0.07 higher than the multi classification regression model. GCN_ATT model had high accuracy and excellent performance in text complexity grading. However, its drawbacks are relatively complex operations and high computational complexity, so further improvement is needed.