
Abstract
Multi-Robot Task Allocation (MRTA) is a complex problem domain with the majority of problem representations categorized as NP-hard. Existing solution approaches handling dynamic MRTA scenarios do not consider the problem structure changes as a possible system dynamic. RoSTAM (Robust and Self-adaptive Task Allocation for Multi-robot teams) presents a novel approach to handle a variety of MRTA problem representations without any alterations to the task allocation framework. RoSTAM’s capabilities against a range of MRTA problem distributions have already been established. This paper further validates RoSTAM’s performance against the more conventional dynamics, such as robot failure and new task arrival, while performing allocations against two of the most frequently faced problem representations. The framework’s performance is evaluated against a state-of-the-art online auction scheme. The results validate RoSTAM’s capability to allocate tasks across a range of dynamics efficiently.
Keywords
Introduction
Multi-Robot Task Allocation (MRTA) as a paradigm deals with the efficient allocation of tasks to a team of robots for the successful completion of the mission on hand. Taxonomies classifying different MRTA problem distributions identify the majority of them as NP-hard and structurally distant from one another [1, 2]. The three axes based taxonomy presented in [1] represents the axes using two alphabet acronyms for each axis within the distribution such as ST for Single Task vs. MT for Multi-Task robots, SR for Single Robot vs. MR for Multi-Robot tasks, and finally, IA for Instantaneous (IA) vs. TA for Time extended Allocations. Individual problem distributions identified by the taxonomy are represented as combinations of these acronyms, such as ST-SR-TA where Single Task capable robots attempt Single Robot tasks in a Time extended Allocation manner. In this paper, these MRTA problem structures are referred to as problem distributions.
Many of the real-world multi-robot settings observe a significant amount of dynamics during operation. Conventionally, task allocation schemes are designed for static problem setups, where environmental variables such as team configuration and task requirements do not change throughout execution. Schemes designed for such static setups suffer against any dynamics within the system [3, 4]. Online planning methods adjust to environmental changes by reformulating their plans whenever necessary [3, 4, 5]. However, these online schemes are designed for situations where the environmental dynamics do not alter the underlying problem distribution. Changes in the underlying problem distribution can make the task allocation scheme completely inapplicable to the new scenario. Taking a firefighting situation as an example, the changes encountered can simply be due to fire expansion, needing more than one unmanned firefighting vehicle for task completion. Expanding an SR task to an MR task, hence changing the ST-SR-TA problem distribution to an ST-MR-TA distribution. It must be highlighted that these problem distributions can be mathematically and/or structurally distinct from one another [6]. This can render the task allocation scheme inapplicable to the changed scenario if it does not hold the capacity to handle the new problem distribution.
The aim behind RoSTAM (Robust and Self-adaptive Task Allocation for Multi-robot Teams) is to present a unified task allocation framework for quality task allocations across a variety of MRTA problem distribution and environmental dynamics. RoSTAM uses a metaheuristic-based design to achieve this task. Meta-heuristics such as Evolutionary Algorithms (EAs) have been used in the past for flexible solutions capable of solving a variety of problems [7] or variants of a single complex problem [8]. Furthermore, EAs have been used to provide solutions to dynamic problems [9, 10, 11], even in the MRTA domain [12]. However, there is a lack of solutions in the MRTA literature capable of making quality allocations across a variety of problem distributions.
This paper validates the adaptive capabilities of RoSTAM against a variety of changes in the environment across two of the most frequently faced MRTA problem distributions, namely the ST-SR-TA and the ST-MR-TA. An earlier study [6] has already demonstrated RoSTAM’s capability to work across a variety of MRTA problem distributions. However, RoSTAM’s capability to handle more conventional environmental changes, such as robot failure and new task arrival, has not been explored in depth. RoSTAM’s performance in this paper is benchmarked against a state-of-the-art online auction scheme inspired by [3, 5, 13]. RoSTAM exhibits better performance in all cases. It is worth noting that the enhanced performance is achieved without any fine-tuning of case-specific parameters generally required by meta-heuristics [14].
The rest of the paper is organized as follows. Section 2 reviews the existing literature and identifies the contributions made by this research. Section 3 provides the mathematical formulation of the problem on hand. Section 4 presents RoSTAM, whereas Section 5 provides the details of the online auction scheme used for benchmarking. Sections 6 and 7 discuss the experimental design used for the evaluation and the results of the experiments, respectively. Finally, Section 8 concludes the paper along with the future research directions.
Literature review
Task allocation strategies handling dynamic situations, such as new task arrivals and robot failures, use exact or approximate solution approaches for online planning. Exact mathematical solution approaches such as Integer Programming (IP) are favored due to high solution quality [15, 16]. A robust solution using IP for closed-loop discrete resource allocation problems has been proposed [17]. However, the heavy computational requirement of the multi-robot task allocation problem means that these approaches become impractical for even medium-sized problems [18] or unpredictable environments [16]. Furthermore, for exact solution approaches, certain mathematical preconditions must be satisfied, and each problem distribution has to be appropriately formulated before the allocations are performed. Hence, complicating the transition between MRTA problem distributions especially for online operations. To cater to these difficulties, approximate, heuristic, and meta-heuristic schemes are often utilized.
Within the heuristic approaches, auction/market-based schemes are the most popular choice for such dynamic systems [16, 19, 20]. Auctions take their inspiration from human auctions [21, 22], where bids are invited for all the available tasks. Any robot willing to attempt a particular task submits its bid based on the cost it is expected to incur while executing that task. Winning bids for each task are identified by the auctioneer and tasks are allocated to the best bid for each task.
In dynamic scenarios, auction-based schemes are initialized by computing a feasible task allocation plan. For any changes in the environment, the plans are recomputed by (a) rescheduling the already allocated tasks and allowing bidding for any newly arriving tasks [3, 5, 16] or (b) reallocating all the tasks from scratch [23]. Despite their wide acceptance, variations in solution quality have been observed for different auction-based schemes against simple environmental variations [24, 25]. These variations include, but are not restricted to, robot starting locations and task distribution within the environment [24, 25]. Hybrid techniques have been developed to cater to these challenges [24, 25]. However, these hybrid techniques need to train portfolio-based algorithm selection mechanisms to enable the selection of a suitable task allocation scheme from a variety of existing task allocation strategies.
Meta-heuristics are also popular task allocation schemes in MRTA due to their low mathematical requirements for problem formulation [26], close to optimal results, better scalability, and low time requirements [27]. Meta-heuristics, including Particle Swarm Optimization [28], Ant Colony Optimization [29], Genetic Algorithm (GA) [27], and Evolutionary Algorithm (EA) [11, 30] have often been utilized for efficient multi-robot task allocation. It must be highlighted that EAs, by and large, are considered similar to GAs except that EAs have phenotype representation of chromosomes, whereas GAs have genotype representation.
EAs are a popular choice when designing meta-heuristic based MRTA schemes. However, EA-based solutions for IA distributions [31] do not cater to the dynamics present in the environment. EA-based schemes handling TA allocations either explicitly consider a static environment [32] or make simplistic assumptions. One such frequently considered simplification is the total resource requirement of any dynamically arriving tasks always being less than the available robots in the team [33]. A unique GA-based solution is proposed for target allocation to unmanned aerial vehicles in dynamic environments [11]. However, the scheme works as an active planner against situations where fuzzy cost evaluations can be made for the uncertainties that exist in the environment. Later, task allocations are made utilizing those fuzzy evaluations.
This research analyzes the online capabilities of an existing EA-based task allocation framework named RoSTAM. The paper analyzes RoSTAM’s capability to handle a variety of environmental dynamics, including new task arrival, task expansions, robot failure, and changes in problem distribution during execution. All this is achieved against two of the most frequently faced MRTA problem distributions without allowing RoSTAM to make any structural changes throughout its operations. To the best of our knowledge, there is no existing online, meta-heuristic MRTA framework capable of adjusting to environmental changes and having the flexibility to work against a variety of problem distributions.
The paper builds upon earlier contributions made in the direction of formulating a unified framework for efficiently allocating tasks across multiple MRTA problem distributions [6]. The capability to seamlessly transition across multiple MRTA problem distributions has already been established in [6]. However, the findings in [6] are presented through a single case study and a comprehensive analysis of more conventional environmental variations was missing. Also, no comparisons were made against existing schemes. Within static setups, the capabilities of RoSTAM have also been tested against an exact task allocation scheme for the ST-SR-TA distribution [30] and against a GA and an auction-based scheme in [34] for the ST-SR-TA and ST-MR-TA problem distributions. Both of these analyses [30, 34] are performed against loosely coupled MR tasks. Being MR tasks, loosely coupled tasks do require services from multiple robots for completion. However, simultaneous execution from all the robots for task completion is not required. The framework has also been tested and its performance has been benchmarked against an auction-based scheme for tightly coupled ST-MR-TA operations [35]. Tightly coupled task instances, unlike loosely coupled MR tasks, require simultaneous execution from multiple robots for task completion. An enhancement of the framework for IA-based problem distributions was reported in [36] and the performance was compared against exact and heuristic solutions. It must be stated that throughout these analyses, heuristic-based auction schemes were found to be potentially the best existing scheme for comparison across multiple problem distributions due to their acceptable performance in all the test cases.
Problem formulation
Suppose there are
Hence, if
Where:
The schedule
The objective function is then to minimize the duration of the whole operation for the team by minimizing individual robot tour times as presented in Eq. (3).
The objective function only considers the commute times for fitness evaluation and does not consider the task execution times. This is motivated by the literature [15, 37]. A few assumptions taken in this work are given below:
The robots hold the execution capabilities of any task allocated to them. The framework handles efficient task allocation to the robot and does not concern task execution. The robots have perfect localization and can predict the cost of travel between locations. The study uses a homogeneous team of robots, thus the cost of travel between two tasks is uniform across all the robots. All the tasks must be allocated the appropriate number of robots as per their requirements. Any solution failing to allocate even a single task instance is deemed infeasible. Multiple instances of an MR task The tasks, even different instances of a single MR task, are not bounded by any precedence constraints and can be attempted in any order (loosely coupled).
RoSTAM targets the capability to efficiently allocate tasks across two of the most frequently used MRTA problem distributions while being able to handle environmental dynamics such as robot failure and new task arrivals. This substantially enhances the autonomous ability of multi-robot teams while handling a variety of environmental dynamics. This section provides an introduction to RoSTAM and its functional components. The components adopted from previous works [6, 30, 34, 35, 36] are presented briefly, while any features introduced into the framework for handling or supporting dynamic changes in the environment are explained in more detail.
EA design
RoSTAM employs an EA to allocate tasks among the robots. The EA utilizes a two-part chromosome structure for solution representation. A valid permutation of task IDs against the existing task instances is presented within the first part of the chromosome. Genes within this part of the chromosome use a decimal point notation to represent each task instance with a unique task ID. The second part of the chromosome hosts a count of individual robot allocations from within the permutation of tasks present in the first part of the chromosome.
RoSTAM’s two-part chromosome design.
The decimal notation-based gene values in the first part of the chromosome allow for the representation of both SR and MR tasks. A candidate solution is presented in Fig. 1 for easier reference. In Fig. 1 all task IDs having only X.1 representations, such as 1.1 and 6.1, are Single Robot (SR) tasks. Tasks having IDs of X.1 and more, such as 3.1, 3.2, and 3.3, are Multi-Robot (MR) tasks. RoSTAM creates multiple instances of an MR task against the multi-robot requirement of that task. Individual robot tours for each robot can be identified through the whole numbers present in the second part of the two-part chromosome representation. Thus, for Fig. 1, robot 1 attempts the first two tasks, robot 2 executes the next seven tasks, whereas robot 3 attempts the last three tasks from the permutation.
Pseudocode for RoSTAM and the basic structure of the EA used.
The first part of the chromosome encapsulating a permutation of all the tasks uses an Ordered Crossover (ORX) [38], whereas no crossovers are used for the second part of the chromosome. Inverse and Swap mutations are also randomly utilized for the first part of the chromosome. In contrast, Creep mutation is applied to the 2nd part of the chromosome. A detailed explanation of the chromosome design, along with crossover and mutation operators, is provided in [34] and must be consulted if required. Individual robot times are computed using a pre-computed cost matrix and Eq. (1). The overall fitness of the solution is then computed using Eq. (2). Figure 2 provides an overview of the organization of RoSTAM and the structure of the EA. The additional components introduced to handle dynamic changes in the environment, namely, population diversity, adaptive penalty function, and online plan reformulation are discussed next.
Pseudocode for Plan reformulation routine, responsible for adjusting the previous archived population as per the changes in the environment.
Dynamic EAs usually adapt individuals from the previous population to the new solution space when changes in the environment are discovered [10]. RoSTAM, on the completion of every task allocation cycle, saves the last population of solutions to be used as a seed value in case any reallocations are to be made. In the case of a re-initiation against a change in the environment, the archived population of solutions is pre-processed before being used as a seed. Figure 3 provides the pseudocode for the plan reformulation routine used by RoSTAM. A complete list of the pre-processing possibilities includes:
Removing and appropriately recording each robot’s attempted tasks from the population of solutions archived from RoSTAM’s last run. Withdrawing any failed robots from the solution pool and submitting their allocated, unattempted tasks to the unallocated tasks pool. Inserting any newly generated instances of the expanded tasks or any newly discovered tasks into the unallocated task pool. Incorporating any robot reinforcements into the solution representation.
As shown in Fig. 2, the re-initiations are handled as a conventional run of the task allocation routine. The only alteration is the use of a seed value for population initialization during any reallocations. Also, these re-initiations are not considered isolated events within the planning operation. Instead, the record of the already executed tasks by each robot is placed within each robot’s archive. This helps appropriately evaluate and penalize any future allocations made to the robots.
A candidate ST-MR-TA solution where multiple instances of an MR task are assigned to a single robot is penalized using an adaptive penalty function. The adaptive penalty function is utilized to allow RoSTAM to adjust to a large range of problem distributions and environmental scenarios. The adaptive penalty function initiates with a fixed value and adjusts its value in every generation as per the following conditions:
If the best solution from each of the previous 10 generations were:
All infeasible solutions, the penalty value is increased by 15% to drive the search towards the feasible regions. All feasible solutions, the penalty value is reduced by 15% to allow infeasible solutions a higher chance of survival. Had a mix of feasible and infeasible solutions, then the penalty value remained unaltered.
Pseudocode for the adaptive penalty function used by RoSTAM.
An adaptive penalty function supports RoSTAM towards its flexible behavior. It allows RoSTAM more flexibility to explore the feasible-infeasible boundaries within the solution space for any of the possible scenarios faced by the framework. Figure 4 provides the working flow of the adaptive penalty function used by RoSTAM.
Being an EA based task allocation framework, RoSTAM utilizes a population of solutions for exploring the solution landscape. As an intrinsic ability, EAs are designed to converge towards a single “fitter” solution [39]. This allows EAs to converge to potentially good solutions in the solution landscape. However, RoSTAM uses its population of solutions not only for extracting promising solutions but also for solution space profiling [26, 39]. This profiling helps RoSTAM make an informed start, in case of a rerun against potential changes. For online EAs, it becomes hard to come out of this single convergence point if the solution landscape experiences any changes and the previous population is used as a seed value for re-initiation [10]. In such implementations, population diversity measures are put in place to allow faster adaptation toward changes in the solution space [10]. Furthermore, adaptive EAs have the drawback of falling for locally optimum solutions in a complex solution space landscape [11].
To cater to these limitations in RoSTAM, an Artificial Immune System (AIS) [40] inspired mechanism similar to [11] is used to keep the population diversity alive. To reduce the possibility of converging to a local optimum and to ensure a healthy solution space profiling for any future re-initiations of the framework against environmental dynamics, 20% randomly generated new solutions are injected into the population in every generation to maintain population diversity. These new solutions randomly replace any existing solutions from within the population. It is ensured that the best solution from the existing generation is not replaced during this operation. In this manner, the framework is allowed the possibility of converging to good regions within the landscape using 80% of its population while the 20% newly injected solutions work towards keeping the population diversity alive.
It must be stated that all of the hyperparameters used for RoSTAM such as the introduction of 20% new solutions for population diversity, increment or decrement of 15% penalty value every 10 generations for adaptive penalty function, or on a broader level, use of specific penalty, crossover, and mutation operators to be used, have been reached through comprehensive preliminary experimentation.
Validation schemes
This section provides background information about the task allocation scheme implemented to validate RoSTAM’s performance against dynamic scenarios. RoSTAM is tested under a range of changes such as robot failure, new task arrival, task expansions, and possible problem distribution changes. Its performance across these dynamics is evaluated using a state-of-the-art auction scheme. The results validate RoSTAM’s capability to efficiently allocate tasks across a range of dynamics.
The majority of the online task allocation schemes in the MRTA literature use auction-based allocation mechanisms. Variants of Sequential auctions are usually preferred for such online allocations [3, 4, 5, 13, 23]. Sequential Single Item (SSI) auctions allocate one task per round against the lowest bid submitted; hence, undergoing
Visualization of SSI auction (a) Complete allocation, (b) Partial allocation and bid computation (cheapest insertion heuristic).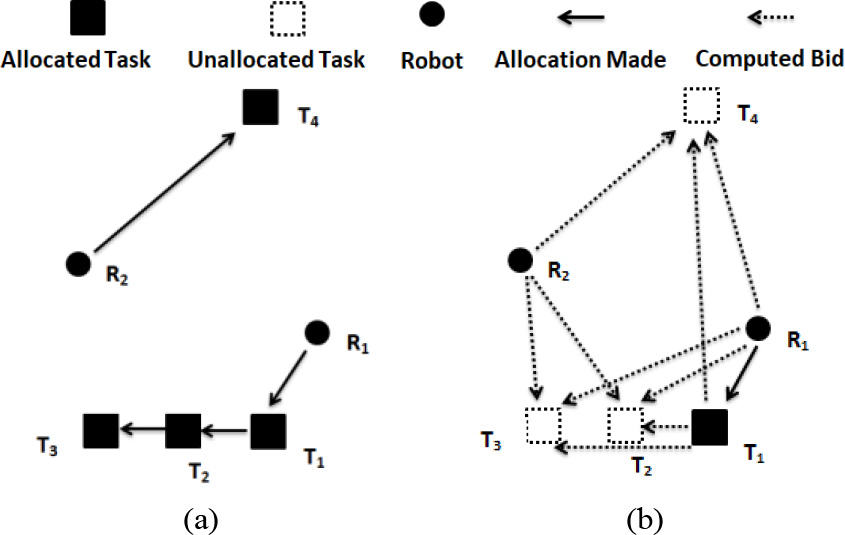
Pertaining to the aforementioned characteristics of auction mechanisms, an auction scheme inspired by [3, 5, 9] is implemented for validation against RoSTAM. The implemented auction scheme evaluates bids through Sequential Auctions for task allocations. Figure 5(a) provides an illustration of how SSI works for a four task, two robot scenario. The tasks are represented as
A more formal representation of the auction mechanism can be presented by considering
Utilizing the cheapest insertion heuristic, robot
Any changes in the environment trigger a global re-auction process for all the unattempted tasks. Global re-auctions are found to outperform local replanning against environmental dynamics [13]; however, they require greater computation compared to local replanning. Hence, as a benchmark, global replanning appears to be a better choice despite the computational overhead. The re-auction procedure followed against individual environmental changes is as follows:
Failed robots do not participate in the re-auction process. The re-auction process is initiated for new robots, robot failure, new tasks entering the system, or any existing task expanding and demanding more resources (MR task). Any expanding MR task is re-auctioned with all other unattempted tasks. However, robots that have already attempted previous instances of the MR task do not participate in the bidding process of the newly generated instances.
It must be reiterated that an in-depth analysis of RoSTAM’s performance across a variety of problem distributions in static setups has already been performed against exact, heuristic, and meta-heuristic schemes [6, 30, 34, 35, 36]. The auction-based scheme was found to be the most appropriate choice as a generic task allocation strategy and is used as a validation scheme for online operations.
This section describes the experiments conducted to test RoSTAM’s capability against a variety of environmental changes. The environmental changes were introduced for two of the most frequently faced MRTA task distributions, namely ST-SR-TA and ST-MR-TA. It is worth mentioning that IA-based executions do not face the challenge of plan readjustments and hence were not part of the experiments. RoSTAM’s performance was evaluated against a state-of-the-art auction mechanism. Different scenarios were developed to test situations such as robot failure, team expansion, robot re-initiation, task expansion, and new task introduction.
The evaluations were done against a range of problem sizes comprising 10, 15, 20, 25, 30, 35, 40, 45, and 50 tasks, with three random instances generated for each situation. Due to the stochastic nature of RoSTAM, its results were averaged over five runs for each instance. For example, for the 10 tasks case, three problem sets are randomly generated. These problem sets are referred to as problem sets a, b, and c. For each of these 3 problem sets, RoSTAM was made to allocate tasks five times to observe an average behavior. Thus, for the 10 tasks count a total of 15 runs (3 problem sets times 5 runs for each set) were performed to observe the average response of RoSTAM. On the other hand, the online auction scheme is run only once for each problem set a, b, and c due to its deterministic nature. The average of these three runs is reported as its performance for the 10 task cases. The experiments for the other task counts (15, 20, 25, 30, 35, 40, 45, and 50) are reported similarly.
Team sizes vary from 2–7 robots for different experiments. In terms of task requirements, any SR task demanded services from a single robot. However, the MR tasks demand 2–4 robots for completion, thus, creating multiple instances for a single task. This expands a problem size beyond its original task count. For example, one of the 50 task ST-MR cases summed up to a total of 137 task instances.
Experiment summary
Experiment summary
A summary of different experiments is provided below while a more detailed description is given in Table 1.
Experiment 1 – Static environment: All the tasks are known upfront with no dynamics present. Experiment 2 – Robot Failure: The team undergoes partial or complete robot failures during operation. Experiment 3 – Team Expansion and Failure: The team undergoes expansion along with partial or complete robot failures during operation. Experiment 4 – Dynamic Task Arrival: New task arrivals or expansion of already introduced tasks. Experiment 5 – Dynamic Task Arrival with Team Expansion and Robot Failure: New task arrival, task expansion, team expansion, and robot failures are encountered during operation.
For all the experiments, changes in the environment were handled in a periodic and stochastic manner. The terms are defined as follows:
Periodic Handling: Changes in the environment can occur at any instance but are only considered for plan inclusion during planned breaks. This depicts situations such as robot refueling or robot capacity constraints. The condition is referred to as event-based replanning in the rest of the paper. Stochastic Handling: Changes are to be entertained the moment they appear in the system. This condition is referred to as time-based replanning in the remainder of the paper.
For event-based replanning, robots are considered to have a fixed capacity of handling five tasks per period. RoSTAM, in each round, has to provide a complete allocation of all the unallocated tasks present in the environment. Once the plan formulation is completed, each robot is allocated the first five tasks from its computed plan as per the fixed robot capacity. The fixed robot capacity is also referred to as window size. In some cases, a robot may be assigned less than five tasks in a period by the task allocation mechanism as allocating at least five tasks is not mandatory. The system replans against any changes introduced in the environment right after assigning these five tasks to the robots.
Window based task allocation at the end of the task allocation cycle.
Figure 6 illustrates a single task allocation cycle for a 11 Task, 3 Robot solution with a 5 task window. The 11 tasks create up to 18 task instances due to some of the tasks being MR tasks. RoSTAM formulates a plan for all 18 task instances, without considering the allowed window size for each robot. Once the plan formulation is complete, allocations are then made at the end of the planning cycle as five tasks per robot from within the final formulated plan of each robot. The task windows for each robot are separately identified in Fig. 6. Any tasks that are outside the window are re-considered for allocation in the next cycle. As per Fig. 6, the last two tasks for robot 2, namely tasks 2.2 and 10.1, and the final task in the plan for robot 3, 10.2, fall outside the windows and are not allocated in the initial allocation cycle. RoSTAM will undergo replanning for these 3 tasks and then re-allocate them to the robots in the next round.
Time-based replanning also starts similarly to its event-driven counterpart. Once the initial plan formulation is completed, the robots commence operation as per the initial allocations. The changes are introduced in the environment at random time instances during execution and the scheme must replan against these changes immediately. Tasks that are already completed are not considered for future allocations.
To prove its robustness, RoSTAM’s parameters were kept constant throughout Experiments 1–5. The only exception was the population size and the number of allowed generations. Due to their simpler structure, ST-SR-TA cases had a population size of 50 chromosomes, while the number of generations was set to 1200 generations for the initial run and 1000 generations for any replanning instances. The more complex ST-MR-TA cases had a population of 100 solutions, while the number of generations was set to 2500 generations for the initial run and 2000 generations for replanning. Since the aim of the paper is to assess the impact and effectiveness of online allocations for RoSTAM, the paper did not simulate the movements of the robots involved in the exercise. Instead, the plan qualities for both RoSTAM and the online auction-based scheme were evaluated using precompiled cost matrices for each problem set against each task count. This decision is well motivated by the literature and similar evaluations are also adopted in [15, 23, 28].
Experiment 1, static environment
Average performance of RoSTAM and online auction for experiment 1, ST-SR-TA and ST-MR-TA distributions
Average performance of RoSTAM and online auction for experiment 1, ST-SR-TA and ST-MR-TA distributions
As highlighted in Table 1, no changes were introduced into the environment for the simplest of the experiments. The team comprised three robots for the ST-SR-TA and five robots for the ST-MR-TA distribution. Being a static task allocation problem, the initial allocations provided by the allocation schemes were treated as final. Table 2 gives the average performance comparison of RoSTAM and online auction for both the ST-SR-TA and ST-MR-TA problem distributions. Being a minimization problem, the lower the performance value of an allocation scheme, the better it is. As evident from the table, RoSTAM maintained a steady behavior and observed a clear advantage over the online auction scheme for both the problem distributions.
Experiment 2, robot failure and reintroduction – details of changes introduced in the system (event based)
Experiment 2, robot failure and reintroduction – details of changes introduced in the system (event based)
Experiment 2 describes a situation where the team undergoes partial or complete robot failure during the execution of tasks. Table 3 provides the breakdown of the environmental changes introduced during the experiment. As per the window size, the changes were introduced after five tasks were allocated to each active robot from the generated plan. For example, Row 2 of Table 3 for the ST-SR-TA problem distribution describes the following situation. Robot 2 failed after the completion of the initial five tasks allocated to it. By this time, the team had executed
Experiment 2, robot failure and reintroduction: Details of changes introduced in the system (time based)
For the time-based execution of the same experiment, Table 4 provides the details of the dynamics introduced for both the problem distributions. The dynamics were introduced at different time instances mentioned as time units, such as “5 mins” in the “Time Instant” column of the table. The entries in this column are additive, meaning that a “12 mins” entry after a “5 mins” entry translates to the change happening at 12 minutes after the operation commenced, and 7 minutes after the previous change was introduced (12–5
For the ST-MR-TA problem distribution, the changes identified in Table 4 can now be observed as the team started with 6 robots. The initial plan formulation was executed until 10 minutes into the execution. At this point Robot 4 failed, triggering a replanning for all the unattempted tasks. 20 minutes into the operation, another replanning was triggered without any changes in the environment. 25 minutes into the plan execution, Robot 4 became available whereas Robot 5 now failed. The remaining operation follows the same observations from Table 4.
Average performance of RoSTAM and online auction for experiment 2, ST-SR-TA distribution
The average performance of both RoSTAM and online auction for all ST-SR-TA, 10–50 tasks test cases combined, is presented in Table 5. The performance is recorded for both Event-driven and Time-based replanning. As per the table, RoSTAM was able to achieve better quality allocations and adjusted better to the dynamics compared to the online auction scheme. The online auction scheme was able to provide better allocations than RoSTAM for one instance each for the Event-Driven and Time-Based execution.
Average performance of RoSTAM and online auction for experiment 2, ST-MR-TA distribution
Similar to Table 5, Table 6 provides the average performance of RoSTAM and the online auction-based scheme for the ST-MR-TA distribution with robot failure and reintroduction. The performance gap between RoSTAM and online auction for both event and time-based variants is more defined for the ST-MR-TA distribution, with RoSTAM providing better allocations throughout the operation. Furthermore, RoSTAM appears to perform more consistently with a steady increase in solution costs against increasing task count. On the contrary, the online auction scheme appears to have a more random performance response towards an increasing task count.
For the online operations (Experiment 2 to 5) performance curves of both RoSTAM and online auction are also presented. These performance curves are plotted for a single 50 task case. The individual cases a, b, and c (as discussed in Section 6) are switched randomly between graphs. Also, alterations between time-based and event-based replanning structures have been made alternatively. The single 50 task cases used for the performance curves go through the same dynamics as presented for the experiment itself. As already discussed, RoSTAM’s performance is averaged over 5 runs due to its stochastic nature. Additionally, the standard deviations are also plotted for RoSTAM along with the average performance curves. Meanwhile, the auction-based performance is plotted against a single allocation cycle due to its deterministic nature. Similar behaviors were observed between the two allocation schemes for the task counts not presented.
50 Task performance curves for RoSTAM and online auction with robot failures for the ST-SR-TA distribution for event-based replanning.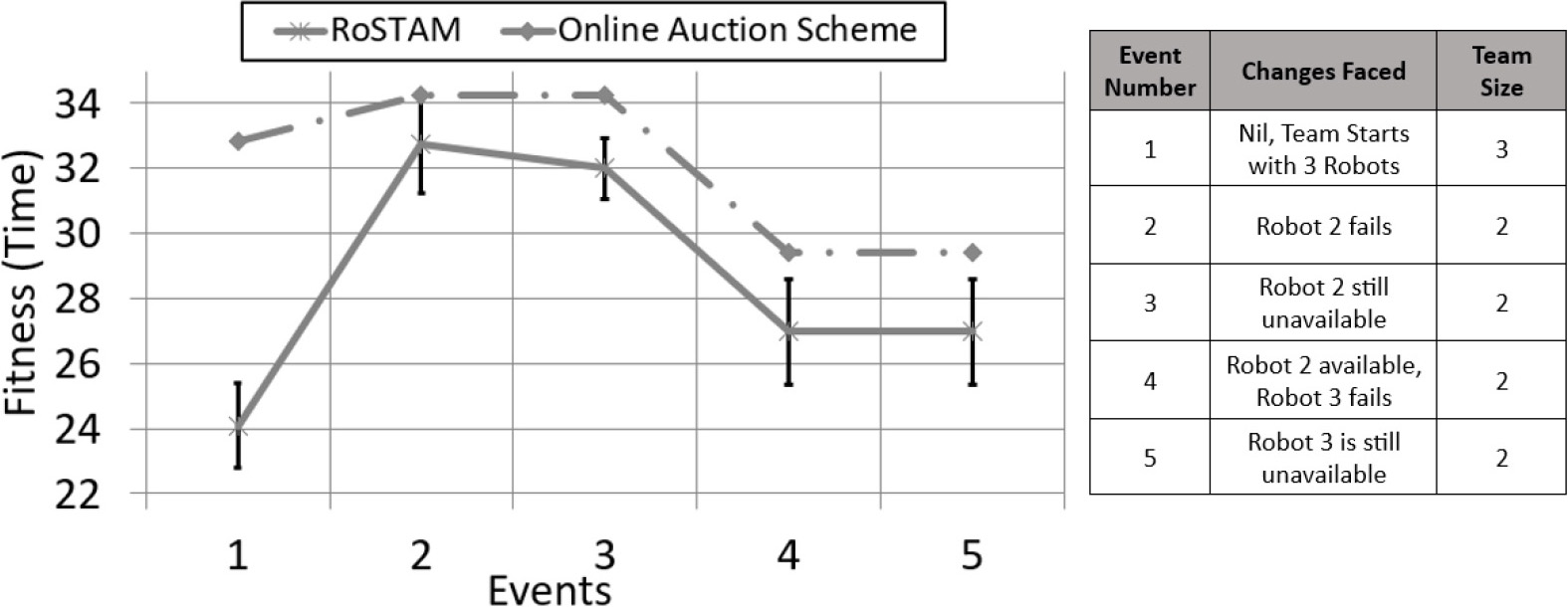
Figure 7 presents the performance graph for the ST-SR-TA execution of Experiment 2. The graph is plotted for the event-based replanning against 50 tasks. The figure is accompanied by a legend summarizing the dynamics faced during the experiment. These are the same environmental dynamics that are already presented in Table 3. As per Fig. 7, the planning starts with a team of 3 robots and 50 tasks. For the first event, RoSTAM presents a substantially better plan compared to SSI auction. From within this plan, up to 5 tasks were allocated to each robot. By Event 2, robot 2 fails and cannot work on any more tasks. After replanning, RoSTAM again comes out with a better plan compared to the auction-based scheme. With the allocations of up to 5 more tasks per available robot and robot 2 still unavailable, both the schemes again undergo replanning (Event 3). By Event 4, robot 2 is available for operation, whereas robot 3 fails. Robot 3 stays unavailable until the completion of operations (Event 5). All these replanning result in RoSTAM providing better solutions compared to the auction scheme.
50 Task performance curves for RoSTAM and online auction with robot failures for the ST-MR-TA distribution for time-based replanning.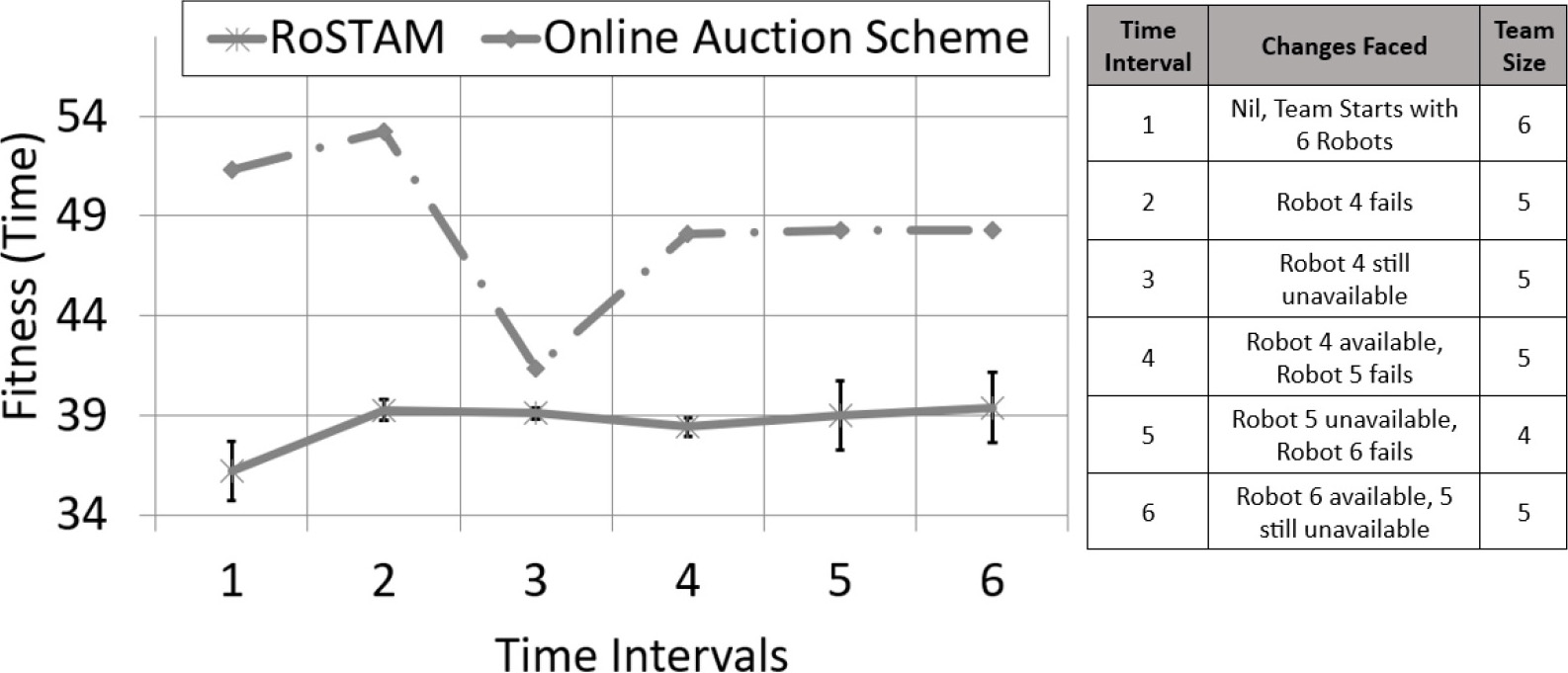
Figure 8 presents a single, 50 task, performance curve for the ST-MR-TA distributions against robot failures as presented in Table 4. The graph provides results for the time-based replanning instance. Similar to Fig. 7, a legend in Fig. 8 also summarizes all the time intervals and the environmental dynamics faced during them. These legends are not provided for any future performance curves and are only provided initially for easier comprehension.
The operations for Fig. 8 initiate with a team of 6 robots planning against the 50 Multi-Robot Tasks present. 10 minutes into the operation robot 4 fails, which remains so until the fourth time interval. By time interval 4, robot 4 becomes available while robot 5 fails. 35 minutes into the plan execution Robot 6 also fails triggering another replanning. This team configuration continues until the end of operations. As evident from the performance cures, RoSTAM comes out with a better plan compared to the auction-based scheme for all the replanning instances. Furthermore, the SSI encounters drastic fluctuations in solution quality throughout its operation. RoSTAM on the other hand, provides good quality solutions with even smaller standard deviations compared to the ST-SR-TA results.
Experiment 3, robot addition, failure, and re-introduction, details of changes introduced in the system
Experiment 3, robot addition, failure, and re-introduction, details of changes introduced in the system
Experiment 3 is designed as a relatively more complex scenario compared to Experiment 2. In this experiment, the task allocation frameworks had to cope with team expansion and robot failures during execution. Table 7 provides the breakdown of the dynamics introduced during the experiments. Only the time-based table representations are provided in Table 7 onwards for simpler narration.
Table 8 provides the average performance of RoSTAM and online auction for the ST-SR-TA problem distribution. A comparison between RoSTAM and online auction reveals that the auction-based scheme managed to meet RoSTAM’s solution quality in only one or two task counts in both distributions combined.
Average performance of RoSTAM and online auction for experiment 3, ST-SR-TA distribution
Average performance of RoSTAM and online auction for experiment 3, ST-MR-TA distribution
Experiment 4, task introduction and expansion, details of changes introduced in the system
Table 9 provides the Event and Time-based average performance comparison of the two schemes for the ST-MR-TA problem distribution for Experiment 3. RoSTAM seems to have a more comprehensive dominance in the ST-MR-TA distribution than the ST-SR-TA counterpart. Furthermore, the non-consistent increase in the task allocation cost of the online auction against increasing task counts becomes more prominent for the more complex case.
The single case performance curves for experiment 3 are presented in Figs 9 and 10 for the ST-SR-TA and ST-MR-TA distributions respectively. For both scenarios, RoSTAM appears to be the better allocation scheme. However, like Experiment 2, the performance difference seems to be more pronounced for the more complex ST-MR-TA problem distribution.
Experiment 4 shifted the focus from team-based changes to task-based dynamics. In Experiment 4, tasks ranging from 20% to 30% of the actual task count were hidden from the planner at startup and were incrementally introduced at future intervals. For the ST-MR-TA distribution, this percentage was applied to the total number of instances present against the MR type of tasks rather than the actual task count. Also, for the ST-MR-TA distribution, these experiments also depicted task expansion, occasionally causing the tasks to change from SR to MR tasks. As an example, consider task 12 as an MR task requiring 2 robots for completion. One of its instances, for example, 12.1, is hidden from the planner initially making task 12 appear as an SR task to the planner having only one instance, namely 12.2. At a later instance, when task instance 12.1 is introduced into the environment the task expands into an MR task. The newly introduced task instance should be allocated appropriately by the task allocation framework.
Average performance of RoSTAM and online auction for experiment 4, ST-SR-TA distribution
Average performance of RoSTAM and online auction for experiment 4, ST-SR-TA distribution
Average performance of RoSTAM and online auction for experiment 4, ST-MR-TA distribution
50 Task performance curves for RoSTAM and online auction with team expansion and robot failures for the ST-SR-TA distribution for event-based replanning.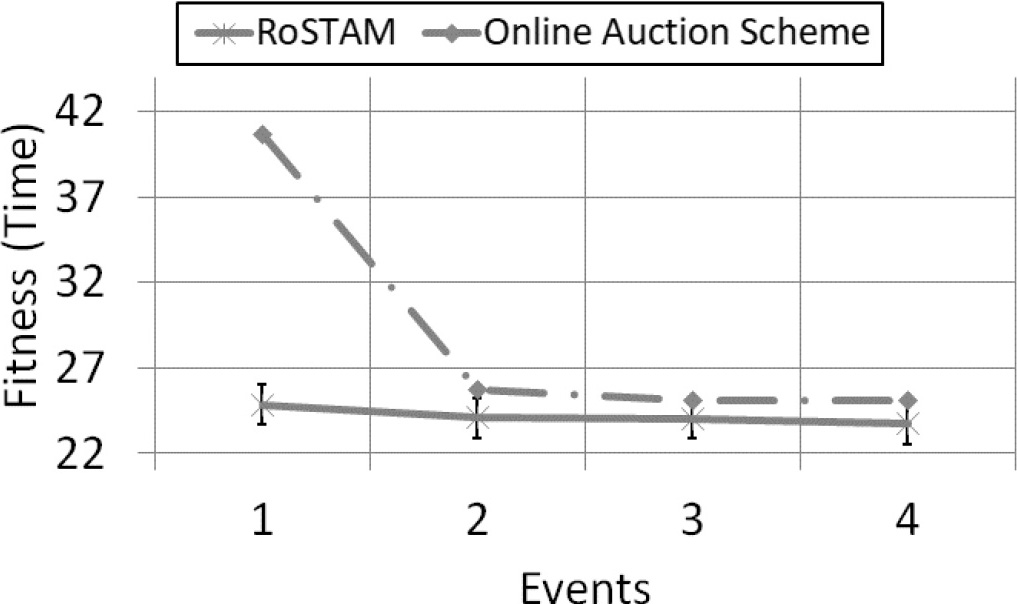
50 Task performance curves for RoSTAM and online auction with team expansion and robot failures for the ST-MR-TA distribution for time-based replanning.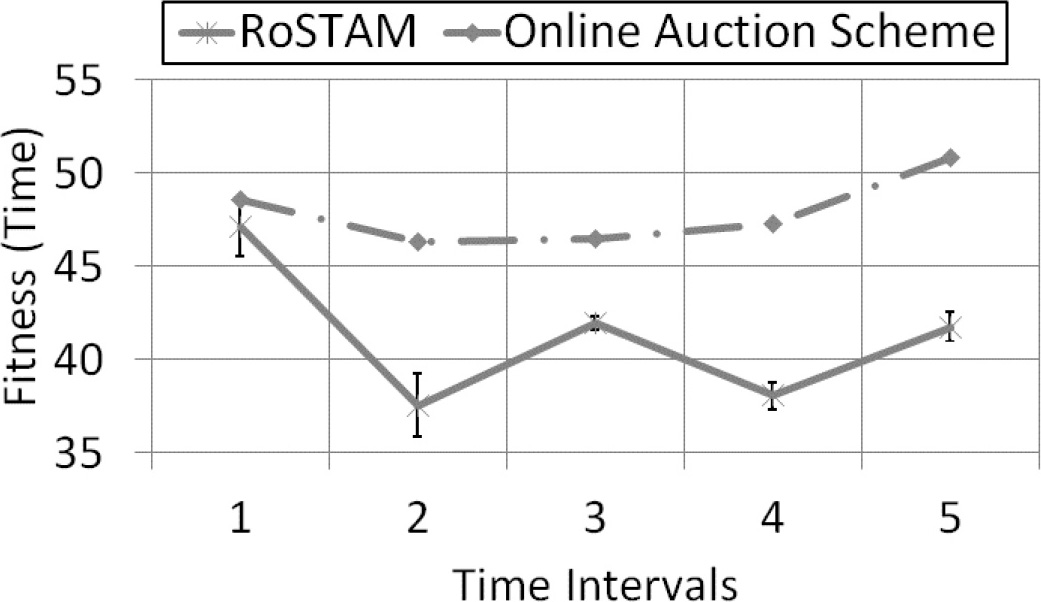
Table 10 provides the breakdown of the task arrivals for the experiments. These experiments were conducted for the 30–50 task cases as the smaller task counts did not allow many iterations to run before all tasks were completely allocated and executed deeming any new arrival of tasks to be handled as fresh initiation of the allocation framework.
The Event and Time-based average performance of the new task arrival experiment against the ST-SR-TA, and ST-MR-TA problem distributions are provided in Tables 11 and 12, respectively. The results identify RoSTAM as a better allocation scheme and a more consistent performer, experiencing a steady increase in allocation cost with increasing problem size. The online auction-based scheme demonstrates a more stochastic behavior than RoSTAM.
50 Task performance curves for RoSTAM and online auction with 20% new tasks arrival for the ST-SR-TA distribution for time-based replanning.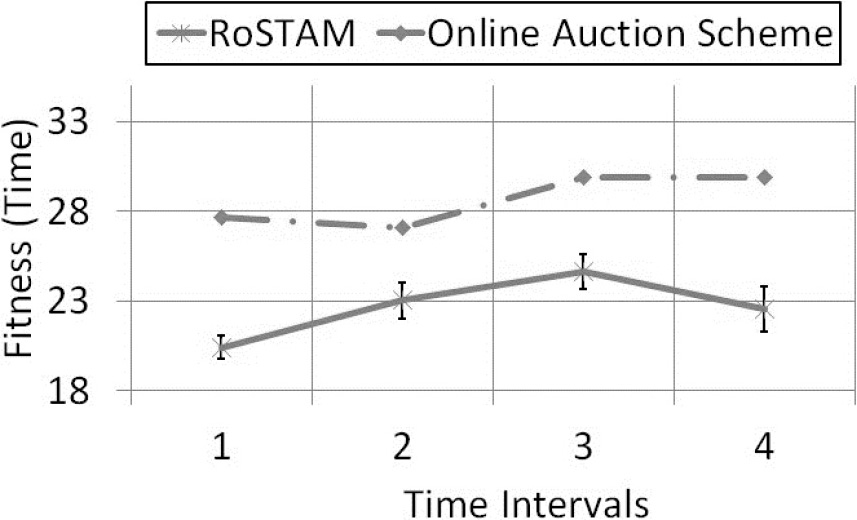
50 Task performance curves for RoSTAM and online auction with 30% new task arrivals for the ST-MR-TA distribution for event-based replanning.
Figures 11 and 12 present the single-case performance curves for Experiment 4. The curves are again plotted for a single 50 task case. For the ST-SR-TA distribution (Fig. 11) the curves are plotted against 20% tasks appearing as new tasks after initial allocations are complete. Whereas, for the ST-MR-TA distribution (Fig. 12) the curves are plotted with 30% tasks appearing as new tasks.
Experiment 5, task introduction and expansion, robot addition, failure, and re-introduction, details of changes introduced in the system
Experiment 5, task introduction and expansion, robot addition, failure, and re-introduction, details of changes introduced in the system
Experiment 5 depicted the most complex situations where the environment underwent both team and task-based changes. A detailed breakdown of the dynamics is presented in Table 13.
Average performance of RoSTAM and online auction for experiment 5, ST-SR-TA distribution event based
Average performance of RoSTAM and online auction for experiment 5, ST-MR-TA distribution event based
50 Task performance curves for RoSTAM and online auction with 30% new task arrivals, robot addition and failure, for the ST-SR-TA distribution for time-based replanning.
50 Task performance curves for RoSTAM and online auction with 30% new task arrivals, robot addition and failure, for the ST-MR-TA distribution for time-based replanning.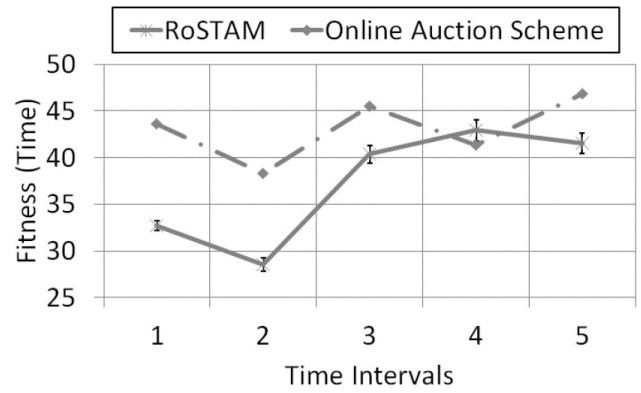
For the experiment, the overall behavior for RoSTAM and online auction against the ST-SR-TA and SR-MR-TA distributions is given by Tables 14 and 15, respectively. In all the cases, RoSTAM led in performance other than 1 instance. The instance was for the 45 tasks ST-SR-TA distribution. Finally, Figs 13 and 14 provide the single case performance curves of both the schemes for Experiment 5.
Comparison of average difference between RoSTAM and online auction for experiment 2 to 5 against ST-SR-TA problem distribution.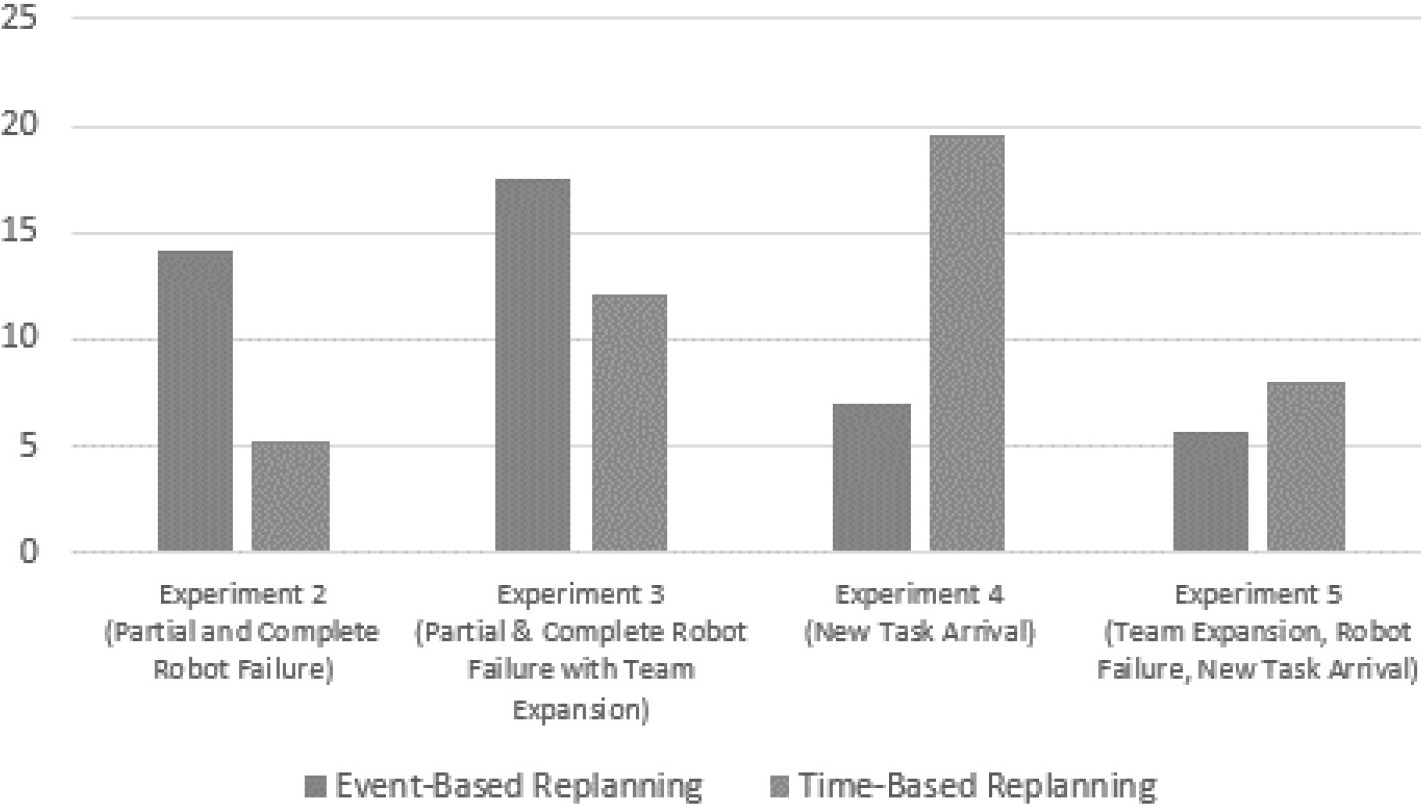
Comparison of average difference between RoSTAM and online auction for experiment 2 to 5 against ST-MR-TA problem distribution.
In addition to all the individual experiment results, Figs 15 and 16 provide a comparison of the average difference computed between RoSTAM and the online auction scheme across the 4 online experiments (Experiments 2 to 5). The plots are provided for both Event and Time-based replannings. Simultaneous analysis of all the average differences across experiments provides valuable insight into RoSTAM’s capability to handle environmental dynamics using event-based and time-based replanning methods. Figure 15provides the plot for the ST-SR-TA problem distribution, whereas Fig. 16 provides the comparison for the ST-MR-TA problem distribution. It can be observed from both figures that for the experiments involving team configuration changes (Experiments 2 and 3), the event-based replanning approach seems to provide a greater performance margin between the two allocation schemes. Whereas experiments involving changes in tasks (Experiments 4 and 5), the time-based replanning approach seems to provide the greater performance gap between RoSTAM and online auction.
In conclusion, this research presents RoSTAM, a novel task allocation framework for efficiently managing multi-robot teams in dynamic environments against two of the most frequently faced MRTA problem distributions. RoSTAM’s flexible design enables it to handle diverse MRTA task distributions while allowing it to adapt to more conventional environmental changes such as robot failure, team expansion, and new task arrivals, without any structural changes to its framework. This characteristic is vitally important to ensure complete planning autonomy in dynamic working environments especially with different problem distributions being mathematically and structurally distinct from one another.
The research also explores two formats of handling environmental dynamics, namely, event-based replanning and time interval-based replanning. The exploration revealed the existence of performance variations between different replanning techniques and different environmental dynamics. Comparative analysis against the online auction scheme validates all of the initial assumptions made about the framework.
Future work will focus on the parameter optimization of RoSTAM across all the problem distributions and environmental dynamics it can handle. Experiments will also be conducted to further elaborate the performance variation between event-based and time interval-based replanning. Another interesting exploration will be the use of other meta-heuristic schemes, such as Particle Swarm Optimization and Artificial Bee Colony, as an optimization tool for comparative analysis against EA design used for RoSTAM.