
Abstract
The new and rising paradigm of cloud computing offers customers various possibilities of task computation based on their desires and choices. Customers receive services from cloud computing systems as a utility. Customers are enthusiastic about low-cost service availability and task completion times that are kept to be minimum. To achieve client fulfilment, the service provider must schedule the jobs to the right resources if the cloud server gets many user requests. The rapid growth in data volume necessitates petabytes processing of data each day. Unstructured, semi-structured, and structured data are all described in terms of their rapid growth and availability. In order to make correct and timely decisions, it must be processed appropriately. In this research, we present BWUJS (Black Widow Updated Jellyfish Search), a multi-objective hybrid optimization-based task scheduling algorithm. This work considers task generation from the Bigdata perspective. The clustering of tasks is performed via the Map Reduce framework with an Improved K-means clustering model. After task clustering, the task priority estimation is performed. Finally, the scheduling is performed via BWJSU based on certain constraints like priority, makespan, completion time, resource utilization, and degree of imbalance.
Introduction
Cloud computing [1, 2] is becoming more and more common in business, academia, and society due to the ubiquity of Internet connection and the big data’s increase in volume, velocity, and diversity through the Internet. Bigdata is produced by a variety of applications, including Facebook, Google, open-source websites, scientific research, business software, cloud computing, IoT devices, e-government software, bio-medical software, and many more. Even though it has a power and larger storage capacity than a typical organization, it nonetheless accurately depicts the data that has been systematically collected. Processing petabytes of data per day is necessary due to the quick increase in data volume [3]. Unstructured, semi-structured, and structured data are all described in terms of their rapid growth and availability. In order to make correct and timely decisions, it must be processed appropriately. As a result, processing and extracting this data is crucial to understanding the valuable insights it contains; this process is referred to as big data analytics.
Three different resource service types are offered by cloud computing [4, 5] as a business computing model: Paas, SaaS, and IaaS. Even though cloud computing focuses on numerous application programs and offers a variety of services, it still has resource and task management issues. Regarding the latter issue, a very important component of the relationship between user service quality and operating expenses, resource utilization rates, and cloud service stability is also present. As a result, the multi-objective task scheduling [6, 7] for cloud computing has a lot of theoretically significant and practical implications. Resources as well as their loads have a lot of dynamic and unpredictable components in the environment of cloud computing. For example, changes in time have an impact on the demand for resource nodes, and quarter, year, as well as holiday variations, also affect resource requests. These elements may also contribute to resource waste and a decline in service quality. Resources [8, 9] were wasted if the load of cloud resources was too low; on the other hand, if it is excessively high, the system’s service performance would be compromised. Task scheduling in cloud computing has been studied for the mentioned problems.
However, task scheduling is a significant issue in the cloud computing environment [10, 11] due to some factors, such as task completion time, the overall cost of finishing all users’ activities, power consumption, resource utilization, and fault tolerance. Although many task scheduling strategies including CR-PSO, SARO, EMVO, and so on are designed with many different optimization objectives, they frequently contribute to some common functional mechanism and make use of similar software engineering architecture when being put into practice. However, each scheduling method must have a new scheduling competency added individually, which is tedious, expensive, and error-prone. The ideal task-scheduling technique [12] cannot be determined by calculating all probable task-scheduling strategies for a secure cloud. Since task scheduling is an NP problem, it is not realistic to calculate all feasible task-scheduling techniques and select the optimum one for a safe cloud. A heuristic method can iterate and improve until it finds an optimal solution that is infinitesimally near the ideal one. So, one of the better approaches to tackle this kind of issue is a heuristic methodology. In order to provide optimal task scheduling under big data constraints in the cloud, we suggest a novel algorithm. The main contributions of this research are given below:
MapReduce framework is adopted to handle the big data, in which the improved K-Means clustering is introduced for the clustering of tasks. Optimal task scheduling is ensured by the introduced BWUJS optimization algorithm under the consideration of a set of constraints including priority, make span, completion time, resource utilization, and degree of imbalance.
The organization of the structure: A review of the state-of-the-art model is in Section 2. Task scheduling in the cloud computing system model is in Section 3. The suggested task scheduling model in the cloud is in Section 4. Proposed BWUJS validation is in Section 5. Section 6 includes the conclusion.
In 2021, Xueying Guo [13] suggested a fuzzy self-defence algorithm-based multi-objective task scheduling optimization model for cloud computing. The three main objectives of multi-objective task scheduling in the cloud computing platform were least time selection, degree of resource load balancing, and cost of performing the multi-objective work. The target function for multi-objective task scheduling in cloud computing platforms is evaluated using a theoretical framework that is developed.
In 2021, Kalka Dubey and S.C. Sharma [14] developed the CR-PSO method, a new hybrid task scheduling technique, for the distribution of numerous independent tasks across the available VM. By combining the optimal schedule series features in which the processing of tasks was done based on the deadline and demand, the traditional PSO and CRO were enhanced for quality improvement for factors including makespan, energy and cost.
In 2021, Reza NoorianTalouki et al. [15]. To solve the task scheduling issue of the dependent tasks inside the heterogeneous cloud computing platform, a novel task priority strategy has been presented, along with the application of task duplication methods. The current paper is unique in that it introduces a novel task scheduling mechanism, together with a new way for task prioritization and the use of practical task duplication tactics. This study employs the OCTd and OCTu processes to efficiently sort tasks into a list, and then it applies the HEFT-duplication method to accomplish task duplication, which greatly shortens the makespan.
In 2021, Wanneng Shu et al. [16] have suggested a SARO method based on the data centre’s peak energy use and the duration of task scheduling. The PDF of the task request queue’s overflow was explored to analyze the SARO model, and the suggested technique may be used to request a break in order to prevent network congestion from the task failure rate perspective.
In 2020, Sarah E. Shukri et al. [17] have suggested EMVO which is a better task scheduler for this work. The proposed EMVO is compared to the actual PSO and MVO frameworks in cloud platforms. The findings demonstrate that EMVO performs much better than both PSO as well as MVO algorithms for minimizing makespan time and maximizing resource consumption. The literature uses a variety of meta-heuristic methods, including MVO and PSO, for work scheduling in cloud environments.
In 2020, Longxin Zhang et al. [18] suggested an EPRD technique to reduce task scheduling time for process applications with precedence restrictions while still adhering to the end-to-end deadline requirement. Two processes make up this algorithm: a task priority queue is first created. A VM is then assigned to tasks based on its relative distance. The scheduling and VM utilization performance can be greatly enhanced using the suggested approach.
In 2020, Ding Ding et al. [19] suggested a QEEC with two stages: The M/M/S queuing technique, which assigns the incoming user requests to each server in a cloud, is implemented in the initial phase using a central task dispatcher. The second step begins with each server’s Q-learning assisted scheduler prioritizing all requests based on laxity and lifetime of the tasks. Then, it uses a policy that is always being updated to assign tasks to the VM, delivering incentives to encourage the assignments that can speed up task responses and utilize more CPU power on each server.
In 2020, S. Velliangiri et al. [20] developed HESGA to enhance task scheduling activity under the consideration of factors like load balancing, makespan, cost of multi-cloud, and resource utilization. The suggested approach combines the benefits of an electro-search and a genetic algorithm. The superior global optimal solutions are produced by the electro-search approach, whereas the better local optimal solutions are produced by the genetic algorithm.
Pros and cons of existing algorithms
Pros and cons of existing algorithms
Users like the cloud computing model because of its powerful processing capacity and practical services. Research on cloud data centre scheduling in a multi-cloud setting is currently focused on the difficulties posed by peak business demand. The following are some of the difficulties that the current task scheduling techniques (Table 1) that we studied in this research encounter: In the Fuzzy self-defence model [13], the adaptable assignment planning problem was very challenging to handle. The challenging cases of CR-PSO [14] were High power consumption and high turnaround time. In OCTd as well as the OCTu model [15], the power management problem was challenging. Optimal resource usage is challenging while employing the SARO model [16]. Premature convergence and lack of diversity problems were increased while using the EMVO model [17]. Enhancing security and energy saving was challenging in the EPRD method [18]. With some service nodes, evaluating QEEC [19] in a large-scale cloud environment was challenging. Less energy efficiency and less degree of imbalance were faced by the HESGA model [20].
Task scheduling in cloud computing: System model
Design of the task scheduling in cloud computing.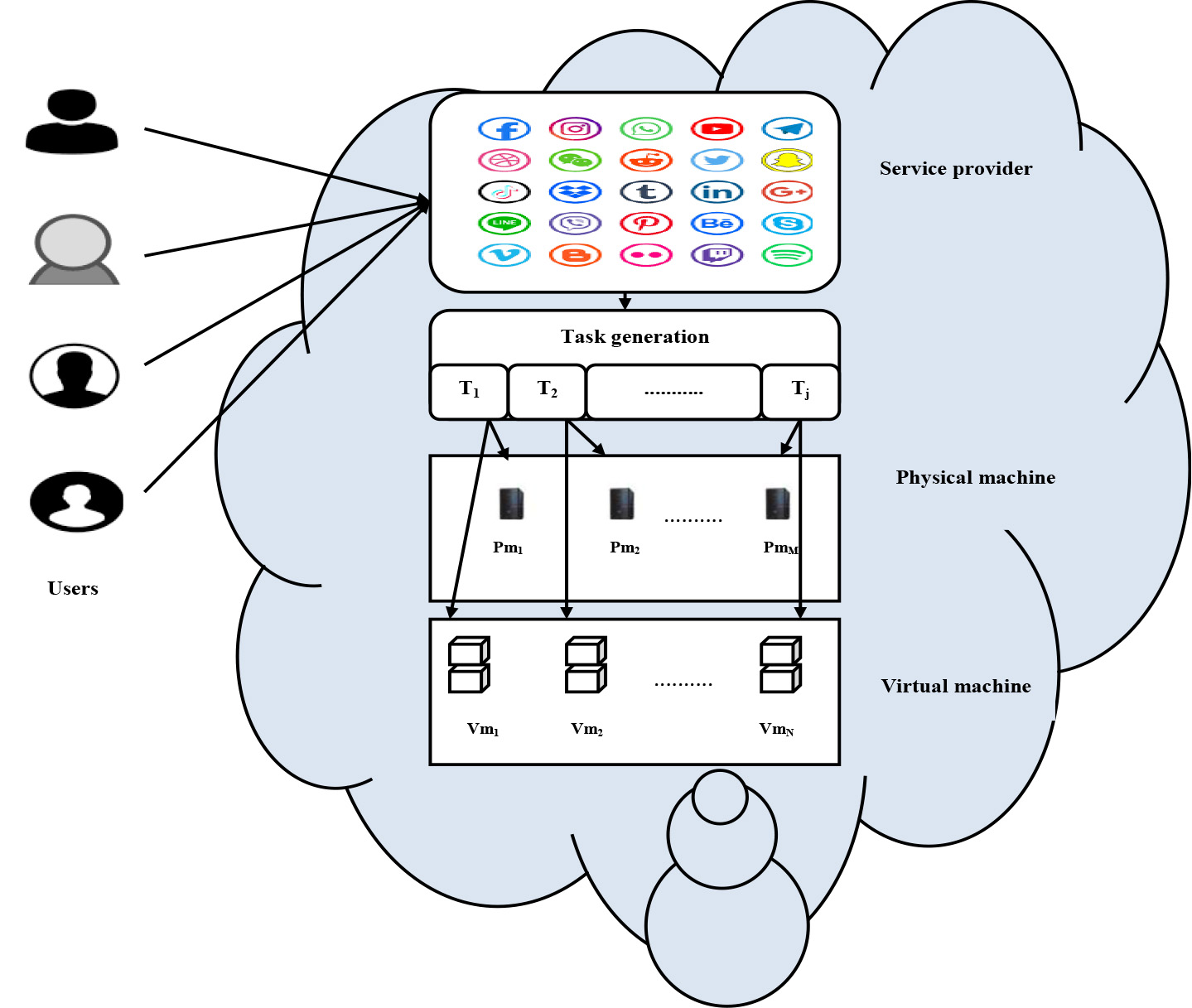
Let us consider the cloud
MapReduce frameworks for task clustering.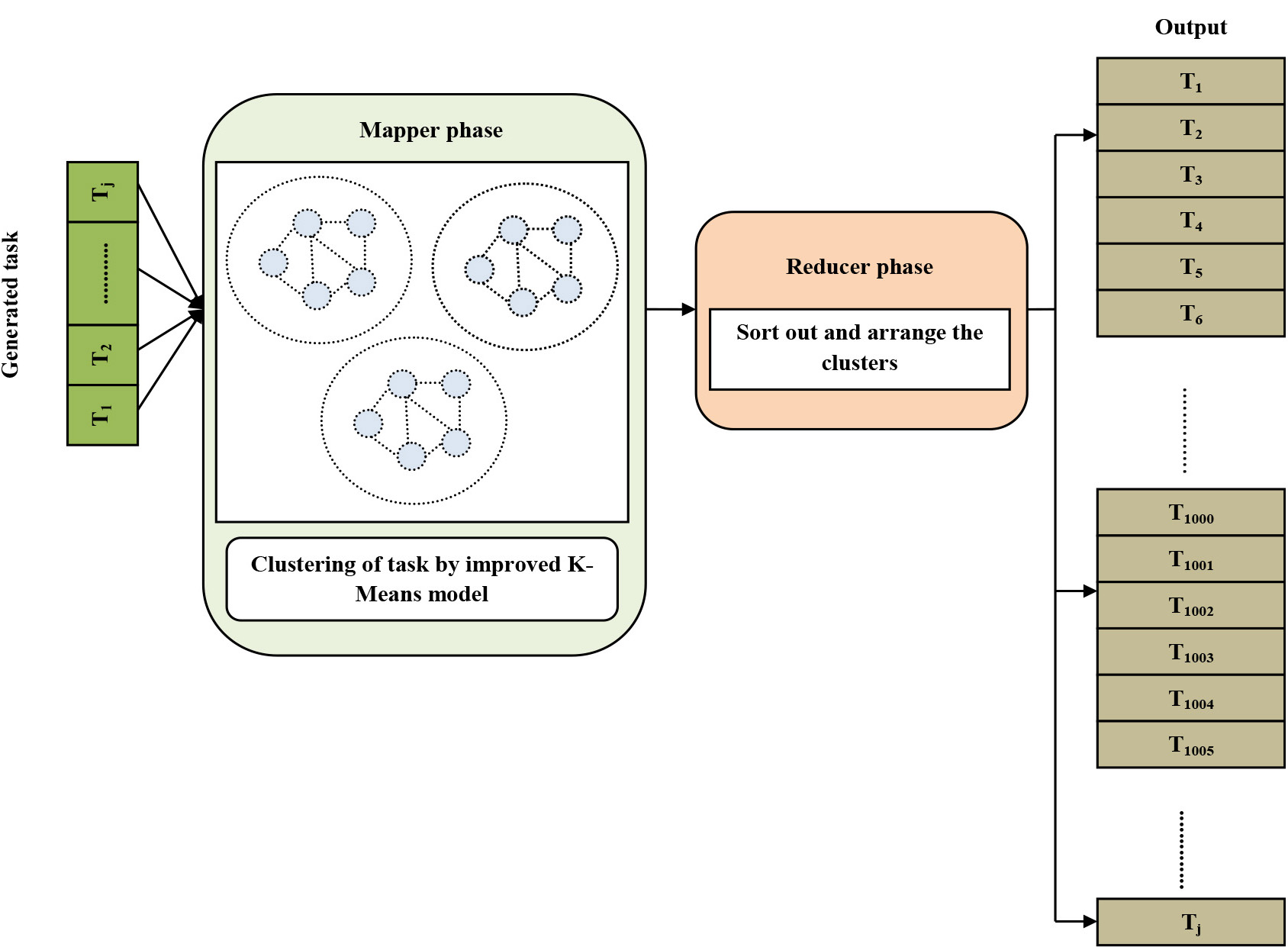
The proposed task scheduling is carried out in a manner that minimizes the completion time while managing the Bigdata. Here considering the dataset
Task generation Task clustering Estimation of task priority Scheduling
Initially, the task
Task clustering
In this phase, task
Mapper phase (Improved K-Means clustering)
In the mapper phase, a pair (key, values) is created by the map function in which the cluster member is considered as key and the task identification number is considered as value. The primary objective of the improved K-Means algorithm is to iteratively cluster the points while minimizing the total distance between each point and its associated cluster centroid. Following are the steps for this clustering process:
Three standards for algorithm termination
The newly created cluster centroid stays unchanged, its points stay in the same cluster, and its iterations reach their maximum. We can halt the procedure if the freshly created cluster centroid has not been altered. Even after numerous iterations, if overall clusters have centroid as same, then the model has not learned any newly generated patterns, and training should be terminated at this time. Another indication that training should be expressly ended is if, even after performing several iterations, these points remain in the same cluster. In this case, training should be terminated. We can finally end training after the specified iteration count has been reached. Suppose we assign the iterations count as 200. The procedure will go through 200 times before halting.
The output from the map phase i.e., pair is given to the reducer phase. In this reducer phase, for each cluster, we get pairs (key, values). As a result, each cluster contains a collection of task values.
Estimation of task priority [22]
In this phase, the physical machine
In cloud computing, task scheduling is the process of providing the best resources for a task execution while taking a number of constraints into account, including priority
The priority of each cluster is calculated in Eq. (7) . By using the cluster
The completion time of a process is the moment when it has finished running. Each task virtual machine wall time
Planning assumptions place a high priority on creating a timeline that limits the allocated work’s final completion time, also known as Makespan. It is calculated to the highest wall time of total blocks in
Resource usage is often the total amount of time the CPU is used to complete the specified task calculated as in Eq. (10).
The degree of imbalance in Eq. (11) measure the imbalance among the virtual machine
Solution encoding of proposed BWUJSoptimization model.
For optimal task scheduling, virtual machine
Initial population
For solving the optimization problem, the problem variable values must generate a suitable design for the present issue solution. Every Black widow spider displays the problem variable values. The design in this study should be viewed as an array for getting around the benchmark functions. A widow is
Before initialising the optimization model, generate the candidate widow matrix with
Proposed procreate
The parent pairs start to mate in order to reproduce the generation as new, parallel, and in nature because they are independent of one another. In the real world, a single mating generates about 1000 eggs, yet some spiderlings do make it and grow stronger. Now, in this process, children are made by employing
As per the proposed logic, the update equation of the procreate process is done in Eq. (15) by adding the JSO position update equation (Eq. (14)) and the conventional procreate process equation. In Eq. (14),
Repeating this process
Here,
Arithmetic crossover
As per the proposed concept, the solutions are also generated using Arithmetic crossover in Eq. (17) that combines the 2 parent chromosomes in a linear manner, where
Cannibalism
In this case, there are three different kinds of cannibalism. In the first, a female black widow consumes her partner during or after mating – a practice known as sexual cannibalism. Based on their degrees of fitness, we may use this algorithm to discern among males and women. Another type of cannibalism involves stronger spider lings eating their weak siblings. This algorithm includes a cannibalism rating that determines how many survivors are defined. There are sporadic reports of the third type of cannibalism, in which the young spiders devour their mother. The fitness rating serves as a gauge for spiderling strength and weakness. Algorithm 1 shows the pseudo code of the suggested BWUJS algorithm.
Constraints in database
Evaluation on BWUJS and the existing models for Big data task scheduling in cloud framework a) Completion time b) Degree of imbalance c) Fitness.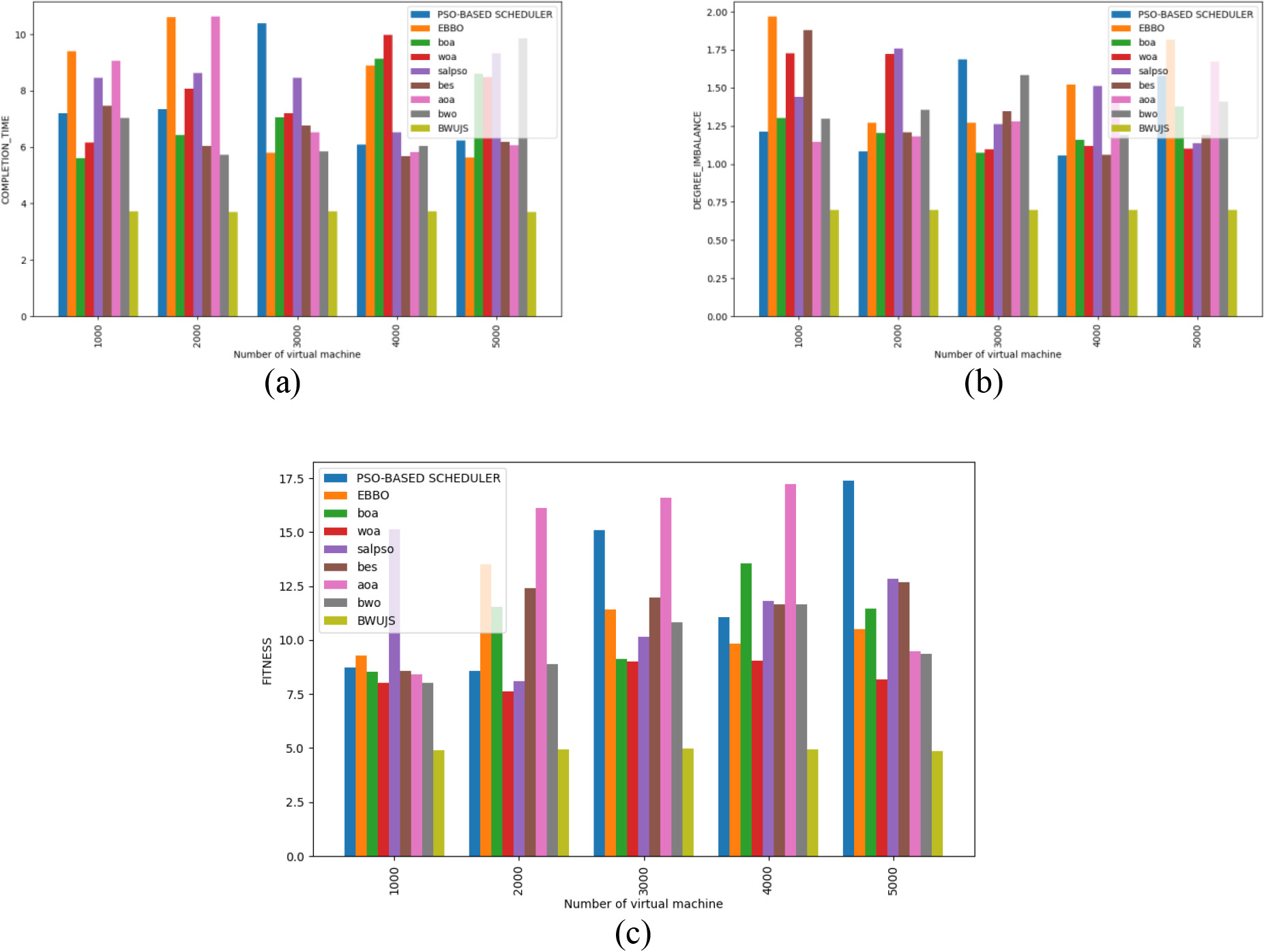
Simulation procedure
Python was used to execute the suggested large data task scheduling in the cloud architecture. The dataset was accumulated from [26]. The effectiveness of the BWUJS model was compared with the traditional schemes like PSO-BASED SCHEDULER [27], EBBO [28], BOA, WOA, SALPSO, BES, AOA and BWO, respectively. Further, the evaluation was carried out with regard to Completion time, Degree of imbalance, Fitness, Makespan, Priority and Resource utilization by altering the number of virtual machines (VM) from 1000–5000.
Dataset description
Table 2 represents the several criteria of the PM database. The PM database includes several criteria, including.
With the help of the PM database, the VM database is constructed. Additionally, it includes the same criteria as the PM.
Assessment on BWUJS and the conventional methods with respect to Completion Time, Degree of Imbalance and Fitness for big data task scheduling in cloud framework
The performance of the BWUJS is examined over the prior models ( PSO-based scheduler, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO) in terms of completion time, Degree of imbalance and fitness is represented in Fig. 4(a), 4(b) and 4(c). Further, the evaluation is done for a varied number of VMs. For optimal scheduling of tasks, the model should acquire the least completion time, Degree of Imbalance and fitness rate. For instance, the completion time of the BWUJS is 3.8743 in the 1000th VM, which is extremely lower than the conventional strategies, including, PSO-BASED SCHEDULER
Consequently, the highest fitness rate scored by the PSO-BASED SCHEDULER is 16.9783 for the VM 5000, whereas the lowest fitness rate attained by the BWUJS is 4.6872. Similarly, the BWUJS recorded a minimized fitness value than the other conventional strategies. Therefore, the low completion time, degree of imbalance and fitness rate is due to the introduction of a new optimal task scheduling process in the cloud via the BWUJS optimization strategy.
Assessment on BWUJS and the conventional methods with respect to Makespan, Resource Utilization and Priority for big data task scheduling in the cloud framework
Examination on BWUJS and the traditional methods for Big data task scheduling in cloud framework a) Makespan b) Resource utilization and c) Priority.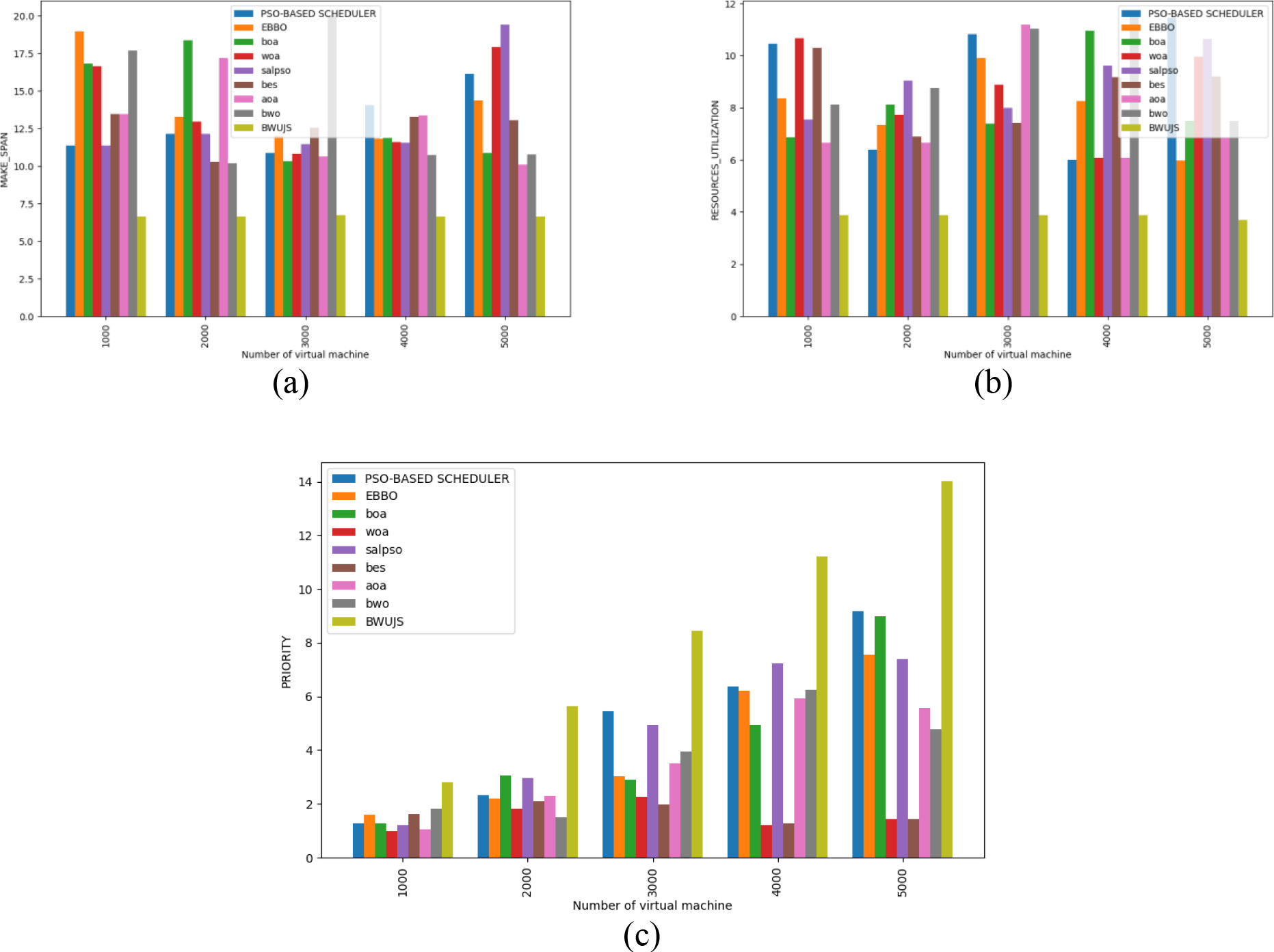
Figure 5(a), 5(b) and 5(c) show the analysis on makespan, resource utilization and priority of the BWUJS over the PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO for big data task scheduling in cloud framework. The model must accomplish minimal makespan and resource utilization with higher priority for big data task scheduling in the cloud framework. Moreover, the makespan of the BWUJS for the 3000th VM is 6.38, which is superior to PSO-BASED SCHEDULER (11.2693), EBBO (11.6578), BOA (9.8541), WOA (10.2463), SALPSO (10.5790), BES (11.8968) and BWO (19.9753), correspondingly. Furthermore, in the VM 4000, the BWUJS utilized fewer resources than the conventional methods, such as PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO, respectively. Finally, assessing Fig. 5(c), the BWUJS scored the highest priority rate in the 4000th VM than the 1000th VM. However, the BWUJS generated better findings than the other schemes in all the VMs. Mainly, the greatest priority obtained in the 5000th VM is 13.9846, whilst the conventional strategies hold the minimized priority ratings. Hence, the supremacy of the BWUJS is acquired for the big data task scheduling in the cloud framework using the hybrid optimization strategy.
(a) Convergence analysis on BWUJS and the conventional methods for Big data task scheduling in cloud framework (b) local optima versus global optima.
The convergence evaluation on BWUJS is assessed over the PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO for big data task scheduling in cloud architecture is exposed in Fig. 6. More efficient task scheduling can be provided by the model with a lower cost value and faster convergence. Likewise, the BWUJS gained the lowest cost rate over the conventional schemes. Further, the BWUJS attained the minimized cost value from the initial to the final iterations. Also, poor performance is observed in the AOA approach. Similarly, the BWUJS obtained the diminished cost rate (14.0758) from iteration 5 to 25, whereas the PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO gained the greatest cost rate. We have performed task scheduling in the cloud using hybrid optimization algorithms including BWO and JS have lowered the cost rate.
In Fig. 6(b) Instead of convergent toward global optima, all IML optimization algorithms do so toward local ones. An objective function’s highest local maximum is referred to as the global maximum, while it’s smallest local minimum is known as the global minimum.
Statistical analysis on BWUJS and the conventional methods for optimal task scheduling in the cloud with respect to completion time and degree of imbalance
Statistical evaluation on BWUJS and the conventional methods for optimal task scheduling in the cloud with respect to fitness, makespan
Statistical analysis on BWUJS and the conventional methods for optimal task scheduling in the cloud with respect to priority and resource utilization
Analysis on wilcoxon and friedman values
Analysis on wilcoxon and friedman values
Analysis on
Tables 3, 4 and 5 summarized the statistical analysis of the BWUJS computed over the PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO in terms of completion time, degree of imbalance, fitness, makespan, priority and resource utilization. For efficient scheduling of tasks, the BWUJS generated superior outcomes over the conventional approaches. Regarding the completion time analysis, the BWUJS acquired a completion time of 3.6888 under the mean statistical measure, meanwhile, the PSO-BASED SCHEDULER is 6.0900, EBBO is 5.6396, BOA is 5.5924, WOA is 6.1655, SALPSO is 6.5121, BES is 5.6692, AOA is 5.8169 and BWO is 5.7290, correspondingly. Moreover, the priority rate of the BWUJS for the median statistical measure is 15.6928, though the PSO-BASED SCHEDULER, EBBO, BOA, WOA, SALPSO, BES, AOA and BWO obtained the minimal priority value. Consequently, evaluating the worst statistical measure, the BWUJS scored Fitness
A non-parametric statistical test for repeated measurements data analysis is the Friedman test. A within-subject design is achieved by using the Friedman test, which is an extension of the wilcoxon signed rank test. Data having three or more correlated or recurring outcomes with non-normal distributions are employed for this type of analysis. The distribution remains constant throughout the series of measurements, according to the null hypothesis. Tables 6 and 7 represent the statistical test on wilcoxon, friedman,
Conclusion
Three levels make up the cloud computing task scheduling system: task, scheduling, and VM. Due to its direct impact on cloud performance, task scheduling was one of the most significant issues in the cloud computing environment. In this work, we developed BWUJS, a multi-objective hybrid optimization-based task scheduling algorithm. The task generation was the initial step of this research considering the big data perspective. The clustering of tasks was performed via the MapReduce framework with an Improved K-means clustering model. After task clustering, the task priority estimation was performed. Finally, the scheduling was performed via BWJSU based on certain constraints like priority, makespan, completion time, resource utilization, and degree of imbalance.
Footnotes
Nomenclature
| Abbreviation | Description |
| OCTd | Optimistic Cost Table downward |
| PaaS | Platform as a Service |
| HEFT | Heterogeneous Earliest Finish Time |
| EMVO | Enhanced version of the Multi-Verse Optimizer |
| PSO | Particle Swarm Optimization |
| OCTu | Optimistic Cost Table upward |
| EPRD | Efficient Priority And Relative Distance |
| QEEC | Q-learning-based task scheduling framework for energy-efficient cloud computing |
| MVO | Multi-Verse Optimizer |
| IaaS | Infrastructure as a Service |
| SaaS | Software as a Service |
| Abbreviation | Description |
| HESGA | Hybrid Electro Search with a genetic algorithm |
| VM | Virtual Machine |
| CR-PSO | Chemical Reaction Optimization-Particle Swarm Optimization |
| CRO | Chemical Reaction Optimization |
| PSO | Particle Swarm Optimization |
| SLR | Schedule Length Ratio |
| SARO | Strong Agile Response Optimization |
| IT | Information Technology |
| IoT | Internet of Things |
| Probability Density Function | |
| JSO | Jellyfish Search Optimizer |
| BWO | Black Widow Optimization |
| EBBO | Extended Biogeography-Based Optimization |