
Abstract
Influence maximization (IM) in dynamic social networks is an optimization problem to analyze the changes in social networks for different periods. However, the existing IM methods ignore the context propagation of interaction behaviors among users. Hence, context-based IM in multiplex networks is proposed here. Initially, multiplex networks along with their contextual data are taken as input. Community detection is performed for the network using the Wilcoxon Hypothesized K-Means (WH-KMA) algorithm. From the detected communities, the homogeneous network is used for extracting network topological features, and the heterogeneous networks are used for influence path analysis based on which the node connections are weighted. Then, the influence-path-based features along with contextual features are extracted. These extracted features are given for the link prediction model using the Parametric Probability Theory-based Long Short-Term Memory (PPT-LSTM) model. Finally, from the network graph, the most influencing nodes are identified using the Linear Scaling based Clique (LS-Clique) detection algorithm. The experimental outcomes reveal that the proposed model achieves an enhanced performance.
Keywords
Introduction
In today’s world, the daily lives of individuals have undergone significant changes due to the rapid evolution of online social networks. These platforms facilitate a range of activities, including communication, idea-sharing, friendship-building, and news consumption among the population [1, 2]. A significant degree of resemblance between friends is seen in social networks. Similar behaviour, interests, and hobbies show how people are more similar. Influence is the process of affecting another person in such a way that the affected person resembles like the influential person. In other words, influence tends to bring friends closer together. Influencers are the users who have positive or negative impact on another user’s opinion. But in large social network its challenging task to determine, “which nodes are influential nodes?”. Influence Analysis is an emerging field of study in online social networks (OSN) research which evaluates user connections to discover top-k influential nodes in the social network. Influence analysis on social data is performed to locate and assess influential nodes.
User interactions within OSN plays a crucial role in the swift and widespread dissemination of specific information, making them valuable tools for companies engaged in product marketing [3]. Social media interaction represents communication network where every person is node and communication is link between nodes. The communication link establishes between nodes if they do actions like, follow, share etc. In social media interaction in spreading messages across social networks every node not carry equal influence [4, 5]. Consequently, users who exhibit heightened activity, influence, and significance due to their behavior or social connections become pivotal in facilitating the rapid spread of messages [6]. The challenge lies in identifying such influential user groups or seed nodes to maximize information propagation is defined as the “Influence Maximization problem” in social networks [7]. In social influence analysis, link prediction predicts a user’s social behavior and influence propagation. The links between nodes may vary due to changes in the actions. So when researchers study social network evolution, the temporal changes in the association, and the effect of different associations need to be addressed. Network dynamics and temporal variations are key obstacle in maximizing influence [8]. This specific problem to analyze existing network snapshots to predict future links is termed as the dynamic link prediction problem. This prediction problem can be formulated as, consider the network as graph NG (V, E) where V is the set of network nodes and E is the set of network links to other nodes in the network. If a network snapshot is taken at time t0 with a set of existing links E, the dynamic link prediction task is to discover the new links in the network at time t1. The process of opinion formation is often portrayed as a dynamic interaction, where individual’s opinions evolve dynamically based on their interactions with peers [9].
In social influence analysis, the data is analyzed to identify network nodes which can maximize information spread. The link prediction techniques is to predict undisclosed links and anticipate future connections based on existing connections. Forecasting new connections relies on various factors such as observable links between network nodes, node attributes, network structure, topology, and nodal attributes [10].
In existing influence maximization (IM) methods, static link prediction takes the current network snapshot of a specific time for analysis, and discovers the new possible links. Here network evolution is not considered during link prediction [11, 12]. Consequently, the use of static social networks for studying information propagation in dynamic social networks tends to yield suboptimal seed identification. But the network keeps changing which can affect the association of links [13]. In score based approach, the similarity score of future link prediction is computed by applying similarity scores of node pairs. The distance of each node is computed with respect to the closest centroid. The learning-based approach uses the structure, and topological features to predict the links. The topological features and similarity score consider the static homogeneous snapshot of the network which lacks a temporal aspect. Existing approaches have used a homogeneous network where the network consists of the same type of node and the same type of association. However, users may be associated with different types of network nodes with different types of associations.
While some studies have addressed the dynamic nature of networks, none have specifically focused on the contextual features of multiplex networks for effective seed generation [14]. Existing IM methods ignore the context propagation of interaction behaviors among users. And it varies according to the user’s interest so dynamic link prediction is the recent trend in research.
Literature survey
Li et al. selected the key influencers using an agent-based evolutionary approach. The model identified an influencer set using the adaptive solution optimizer. Proposed system outperformed existing algorithms. However, convergence speed of the influence spread model was lower under the changing environment [15]. Zhang et al. introduced an IM model based on prediction and replacement. The model predicted the upcoming network snapshot and adopted a replacement algorithm to select seed nodes. Experimental results were very promising. However, the model was limited to the issues related to multilayer networks [16]. Liu et al. offered attributed IM by applying the features of the user’s group and their emotions. The seed candidate sets were located using the influencer user discovery algorithm. Proposed system results demonstrated the efficiency of the algorithm in influence maximization. The ignorance of context-based influence diffusion degraded the model performance for effective seed generation [17].
Wang et al. identified the influence maximizing node sets by the moth-flame optimization method. Experimental results indicated the approach was effective but still, the removal of weakly connected nodes resulted in suboptimal seed generation [18]. Zhang et al. presented an IM method based on community detection in networks. To find the set of influential nodes greedy algorithm with the sub-modular property-based approach was used. Finally, experimental results demonstrated effectiveness of the proposed system in influence maximization. However, proposed system lacks the consideration of user behavior and social tie factors [19].
Wang et al. analyzed the node coverage gains to present an IM approach. The node coverage gain measured on the overlapping communities was used for seed point selection. The experiments demonstrated that the approach achieved competitive influence spread. However, the model required more running time in topological field construction [20]. Olivares et al. developed an IM model through the Linear Threshold (LT) model. The optimization model was used for seed selection. Results suggest that the solution properly solved harder instances. The swarm intelligence method was not adapted to the binary domain, which increased the execution time of the model [21].
Noemi Gasko et al. proposed Shapley Influence Maximization Extremal Optimization approach where Independent cascade (IC) model is used to select influential nodes in set of cascade. The effectiveness of proposed algorithm is shown with the comparative analysis. The proposed work extention is discussed with the hybrid approach of algorithms with heuristic information [22]. Saeed Nasehi Moghaddam et al. provided novel approach to identify the influence node which can be solution of CELF algorithm by incorporating parameter tuning strategy for diffusion models. The results are compared with 16 genetic algorithms and provided optimal solution. The dynamic network is not captured by proposed system [23]. Inder Khatri et al. applied discretization of the nature-inspired Harris’ Hawks Optimization meta-heuristic algorithm for community detection and identified the set of seed nodes. The work is analysed with different social networks. The community detection improved the result so in this paper proposed work included community detection for identifying seed nodes [24].
Venkatakrishna et al. devised K
The scope of the work can be extented to locate influence in multi-entity competitive online social networks [28]. Guoyao Rao et al. implemented
Problem statement
Various methods developed in the literature have the following shortcomings,
Existing work lacks the incorporation of the contextual features along with a multiplex network for effective seed generation. Existing work lacks in the consideration of the dynamic nature of the network so it’s difficult to identify the optimum solution in dynamic networks. Link prediction between two nodes is complicated due to the presence of different types of nodes and links in a multiplex network. Discovering people with similar interests according to their structural properties is an important issue in dynamic networks.
The proposed model has the following contributions as,
For seed generation, contextual features-based IM in a multiplex network is introduced. To find the optimal seed set for IM, the dynamic nature of the network is considered. To make link prediction easier in a multiplex network, the influence path analysis-based link prediction is used. To discover people with similar interests, community detection is performed in different ways with the consideration of social media data.
In this paper Section 1 provides introduction of influence maximization and enlightens the motivation of research work. Section 2 deals with the literature survey done in the research trends and work done in the area of influence maximization. Section 3 gives details of proposed system implementation. Section 4 provides detailed insights into the outcomes of the proposed methodology as applied in experimental work. Section 5 concludes the study and outlines future research plan.
This paper presents a context-based framework to find influence spreader nodes. The context-based IM model in multiplex networks is shown in Fig. 1. The different methods used for various steps in the proposed system are shown in the Fig. 1. Initially, multiplex networks along with their contextual data are taken as input. Community detection is performed for the network using the WH-KMA algorithm. From the detected communities, the homogeneous network is used for extracting network topological features, and the heterogeneous networks are used for influence path analysis based on which the node connections are weighted. Then, the influence-path-based features along with contextual features are extracted. These extracted features were given for the link prediction model using the PPT-LSTM model. Finally, from the network graph, the most influencing nodes i.e seed nodes are identified using the LS-Clique detection algorithm. The detail description of each block presented in the Fig. 1 is given in the following subsections.
System architecture of the proposed methodology.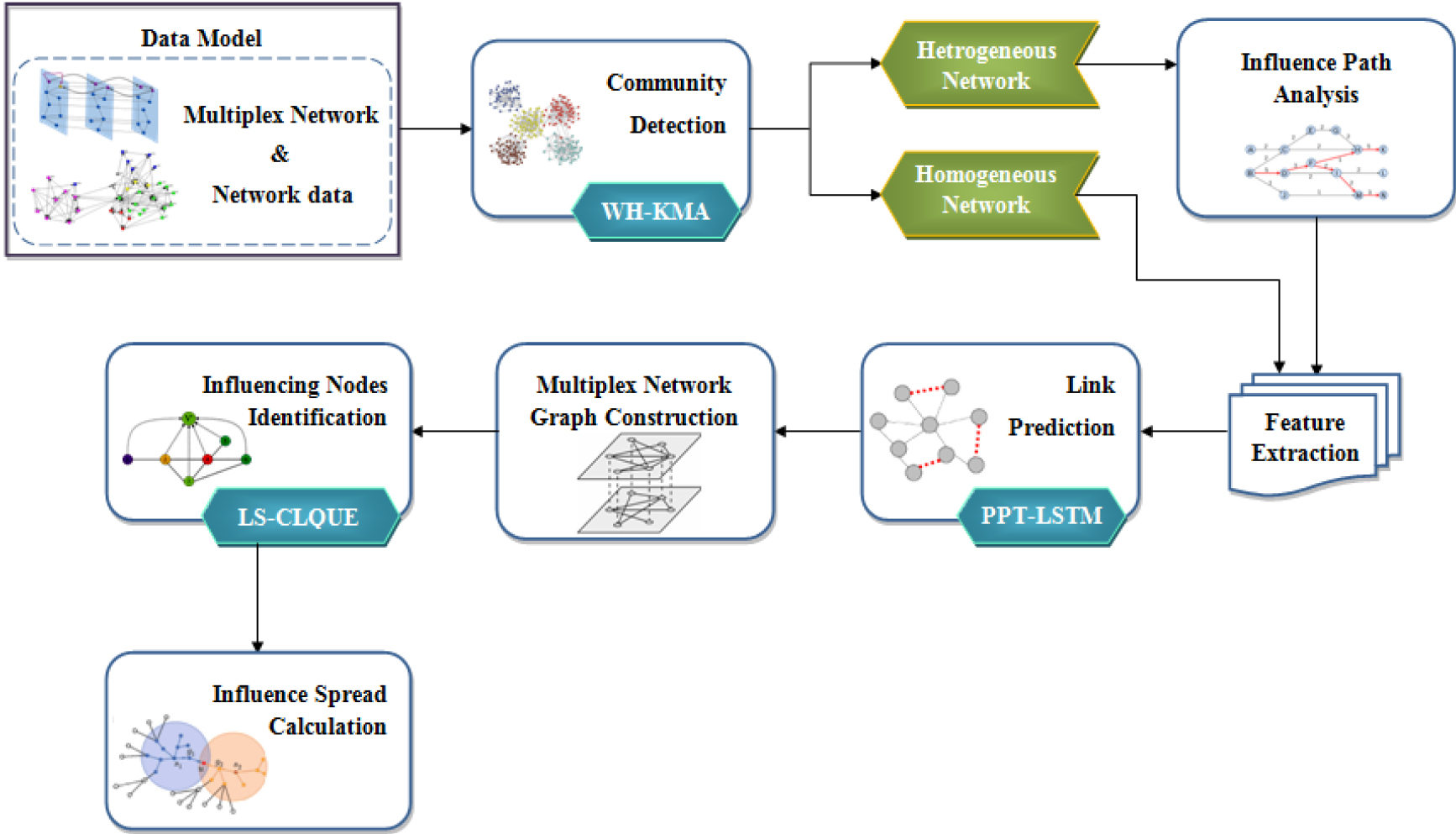
Influence maximization framework in single-layer networks has limitations, as users are associated with various multiple social networks. The proposed data model incorporates the multiplex social network and the network data as input where each node is treated as an individual user and the connection between them is represented as an edge to form the network as a multigraph. The multiplex network is used to estimate the comprehensive influence ability of influential nodes in different network layers. Interlayer edges in multiplex networks can only link nodes that in various layers represent the same actor. Thus, sets of interactions between the same (or a similar set) of entities (followers, followees, etc.) are generally represented by multiplex networks. The use of multiplex networks is beneficial in terms of incorporating heterogeneous influence propagation, combining structural and behavioral information, adapting different strategies, and also modeling different types of relationships. The IM in a multiplex network is expected to have good spreading ability in each layer of the network.
Initial network graph
Initial network graph shows how the network was structured. The initial network graph is the base network architecture that is used for future analysis or algorithms when it comes to impact maximization or any other activity involving networks. The initial network graph for n layers and m network graph is is modelled as
Where,
In order to achieve context-aware IM, social media network data
Where,
Community detection in social network analysis discover categories or communities of nodes within a network which are closely connected. Community identification techniques reveal the organization of nodes in complex networks and provide insights regarding node interactions and relationships. After modelling the network structure, community detection is performed to find nodes with common interests using the Wilcoxon Hypothesized K-Means (WH-KMA) algorithm. The K-means algorithm is selected for its faster computation on large data. However, due to placement of cluster centroid in a spherical manner leads to inaccurate clustering results. It merges different underlying clusters into one cluster and gives misleading clustering of the data. Hence, the clustered data are validated by using the WH technique.
Step 1: Initially, the number of communities
Step 2: In the next step, the
Step 3: Then, the distance between each node
The Euclidean distance
Where,
Step 4: Then, the new centroid is calculated by taking the average of all data points and the clustered data is evaluated using the WH by Eq. (7)
Where,
The WH-based indexing process compares all the related samples in a single community to rank the equality of each sample. Hence, the final community structures is obtained by Eq. (8),
Where,
From the community structures, the local communities are considered as homogeneous networks, and the global and core communities as heterogeneous networks.
Influence path analysis is used for investigation of the influence spread propagation in the network by studying the paths. The goal of path analysis is to understand the sequence of contacts or transmissions that lead to the nodes in the network adopting a behavior. Influence path analysis can shed light on the mechanisms of influence propagation, identification of influential nodes or pathways, and offer tactics for increasing influence spread. The influence path analysis using the meta-path indicates different types of interactions among different kinds of nodes. To ease link prediction, the influence path analysis of a heterogeneous network is carried out, which accounts for intra-community and inter-community meta-path propagation. The inter-community meta-path propagation is computed using Eq. (9) which represents common information shared by the same user
The intra-community meta-path propagation is computed using Eq. (10) which refers common information shared by two different users
Based on this, the link between two nodes is weighted to find link importance in the network.
The link importance
Where,
In feature extraction from
Where,
In social influence analysis, link prediction predicts users social behavior and analyze dynamic propagation of influence spread to infer more accurate influence network based on current structure and additional node and edge parameters. The feature vector
Architecture of PPT-LSTM.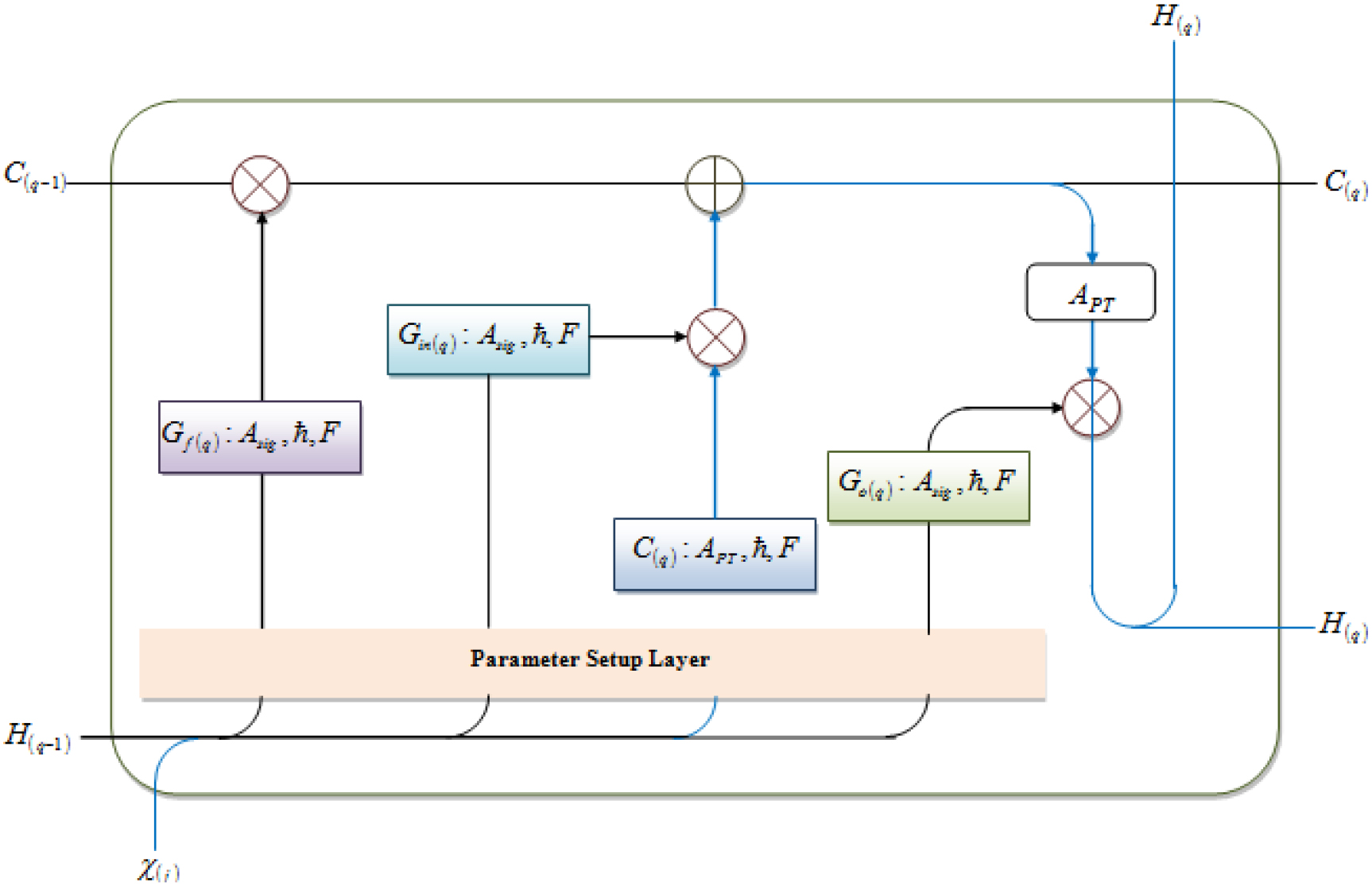
The PPT-LSTM consists of two recurrent features, such as hidden state and cell state. At the current time step
Where,
Hence, the new cell state and hidden states are expressed by Eqs (17)–(19),
Where,
Finally, using the forecasted mutual features between the unconnected nodes, such as mutual connections, user mentions count, favourites, followers, friends, etc., from PPT-LSTM, the edges that are expected to be added to the network are predicted. With the prediction result the network graph updated for the time
Cliques are fully linked subgraphs in which every node is directly connected to every other node. Clique is selected for its efficiency in terms of both execution time and accuracy. But, the existing algorithm suffers to find an accurate group due to too much of estimations for the irrelevant cell size to a set of very high values. Therefore, the values in the high range are normalized using the linear scaling technique. Linear Scaling based Clique (LS-Clique) is an algorithm that uses cliques to find influential nodes by applying functional characteristics of cliques. From the graph
Step 1: If
Step 2: Equation (20) is used to find the nodes
Step 3: Set of cliques
Where,
Step 4: The set of cliques
Where,
Step 5: The steps are continued until all graph nodes
In this way, the influencing nodes i.e seed nodes are selected recursively according to the dynamic change in the network and recommended for the network for IM.
The real-time social network datasets for twitter, instagram and facebook are used for the implementation of proposed algorithms.
Dataset description
The data for the experimental work were collected from different social platform datasets, such as Instagram, Facebook, and Twitter [14, 15, 16, 17, 18, 19]. Instagram social media data for the IM task consists of users, with 70,409 nodes/users, and 1,007,107 edges/connections (followees and followers). The Twitter data is collected through the streaming API available online. The Twitter dataset includes 75,460 twitterers, 1,02,426 tweets, and 1,22,276 retweets in addition to the twitterers posted at once, retweeted at once, and twitterers engaged in both tweeting and retweeting. The Facebook dataset contains the details of friendship-relationship networks among 93 users connected together by as many as 323 links in the social network, the nodes, and links.
Performance analysis
Here, the outcomes attained for the proposed context-based IM model are contrasted with the existing methods.
Figure 3 compares the community detection accuracy of proposed WH-KMA and existing KMA, Fuzzy C-Means (FCM), Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) and Clustering Large Applications (CLARA) methods. The community detection accuracy of the proposed model is 97.51%, which is higher as compared to the existing methods. The analysis states that the WH technique well distinguished the grouped data.
Analysis of community detection time
Analysis of community detection time
Performance comparison of proposed WH-KMA.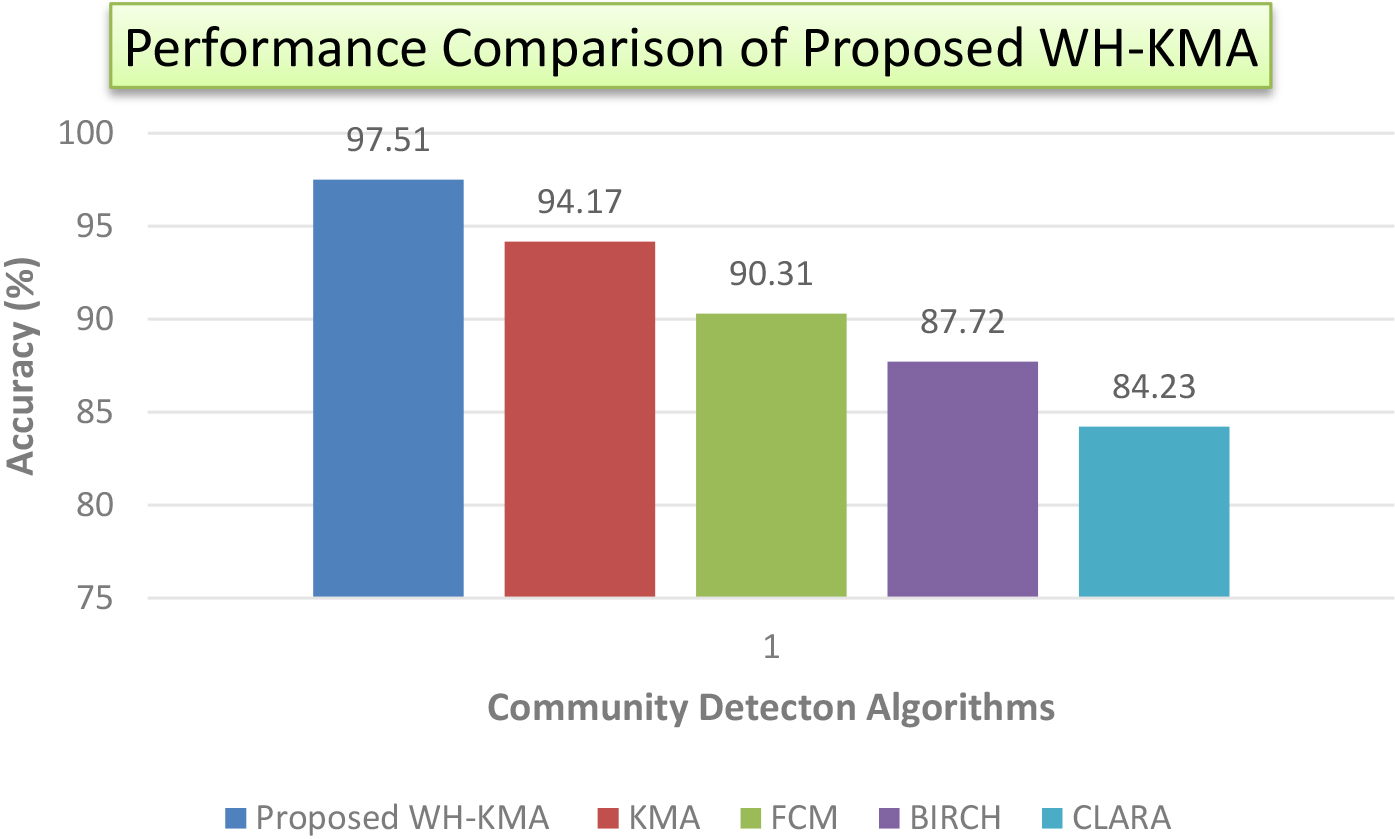
Performance comparison of proposed PPT-LSTM.
Table 1 compares the community detection time of the proposed WH-KMA and existing community detection algorithms. While analysing Table 1, it is observed that time taken by the proposed WH-KMA is decreased by 2821 ms than KMA. Therefore, the identification of communities with the parallel evaluation of the goodness of split using the WH technique minimized the community detection time of the proposed model.
Figure 4 shows comparative analysis of the proposed PPT-LSTM, LSTM, Convolution Neural Network (CNN), Recurrent Neural Network (RNN), and Artificial Neural Network (ANN) in terms of accuracy, precision, recall, F-measure, and specificity. While analyzing the accuracy and specificity, the results attained by the proposed model are improved by 1.39% and 4.05% than the existing methods. Therefore, reduction of parameters using the PPT technique well supported the backpropagation process to learn more relevant data.
Analysis of training time
Table 2 shows the model training time of the proposed PPT-LSTM and existing LSTM, CNN, RNN, and ANN methods. While comparing, the training time of the proposed model is decreased by 4.01 ms than the LSTM as well as less than other techniques. Hence, the reduction of parameters in the desirable sense to minimize the loss using the PPT technique, minimized the training time of the proposed context-based IM model.
Comparison of influence spread.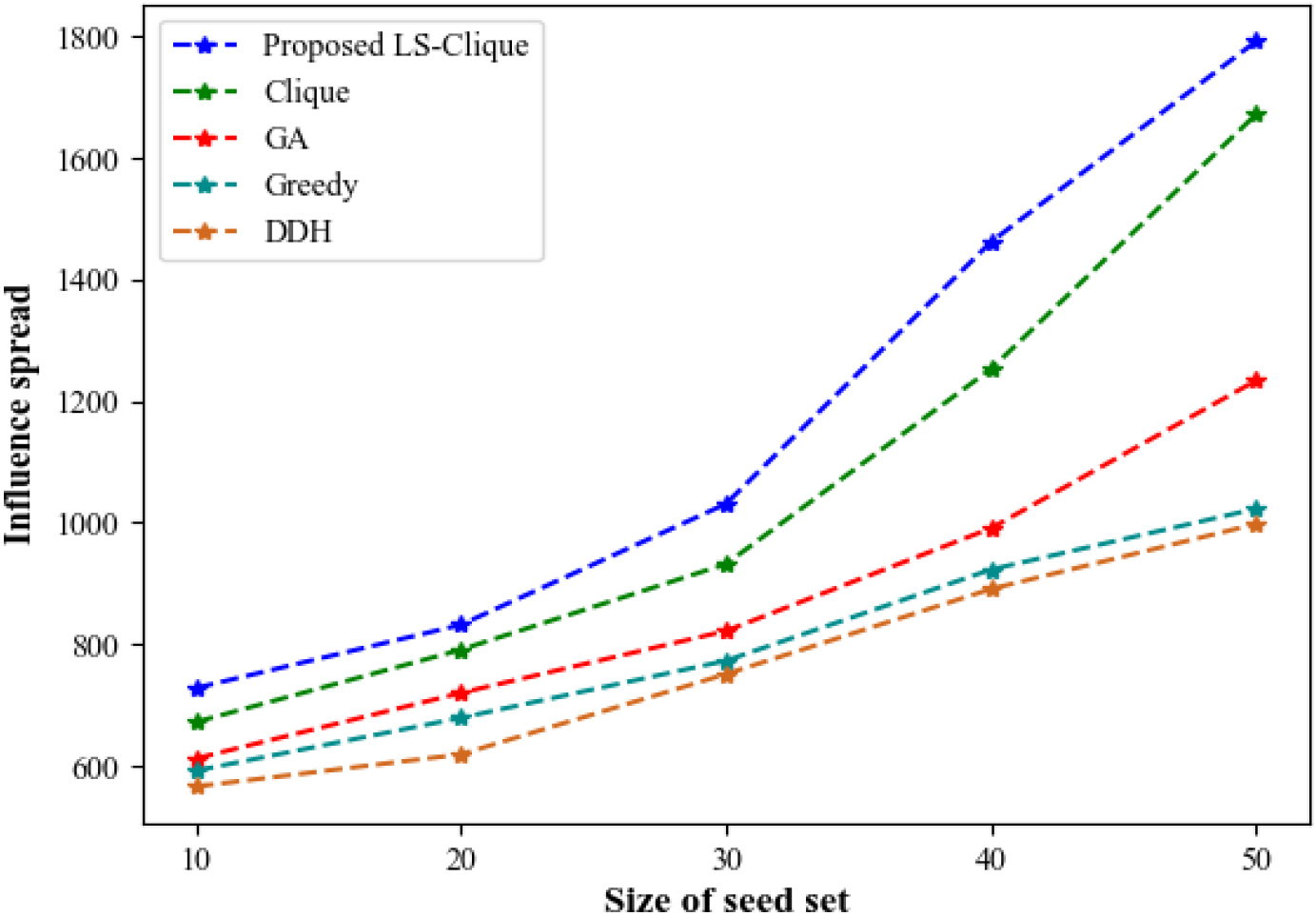
Comparative analysis of proposed LS-Clique of (a) Twitter (b) Facebook and (c) Instagram.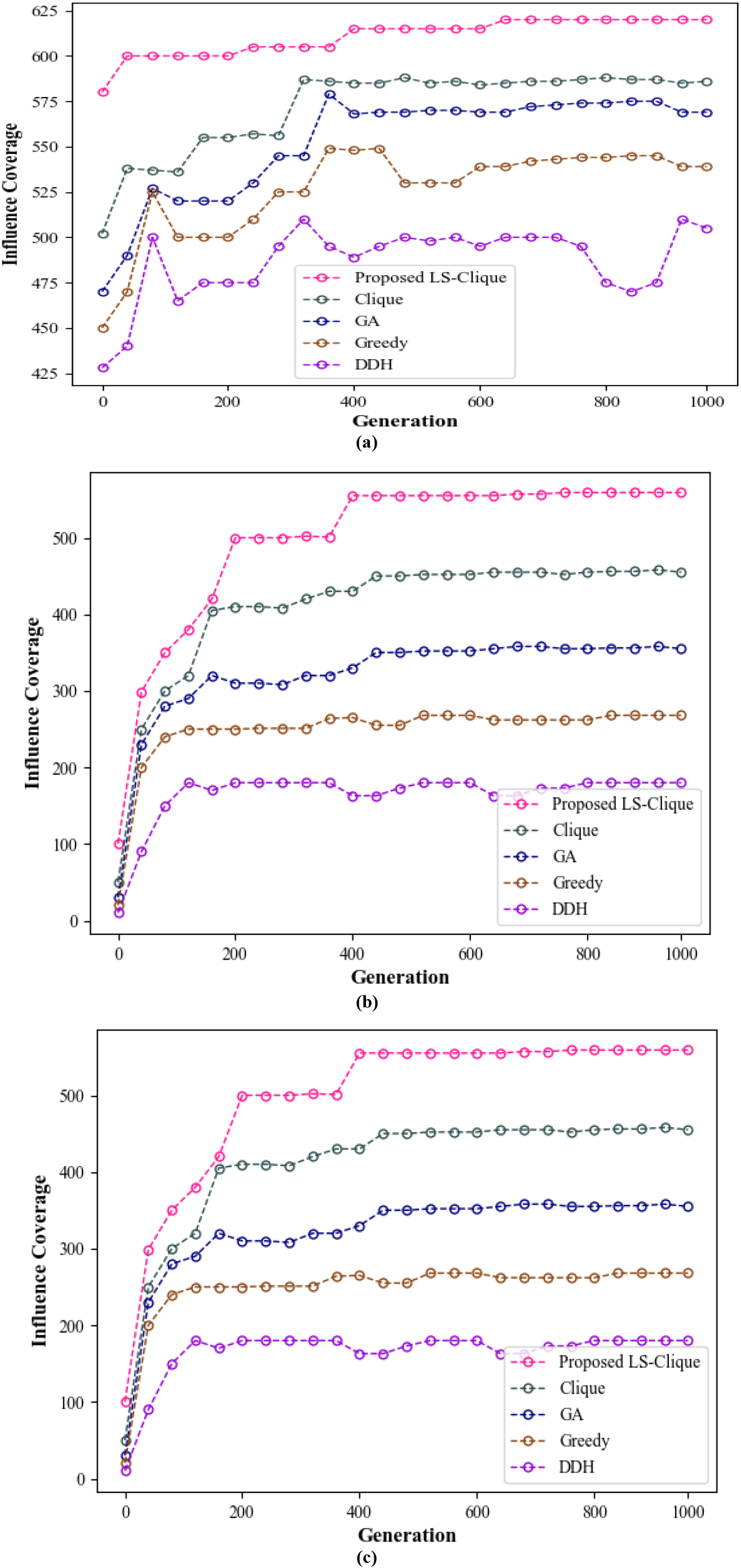
Analysis of running time.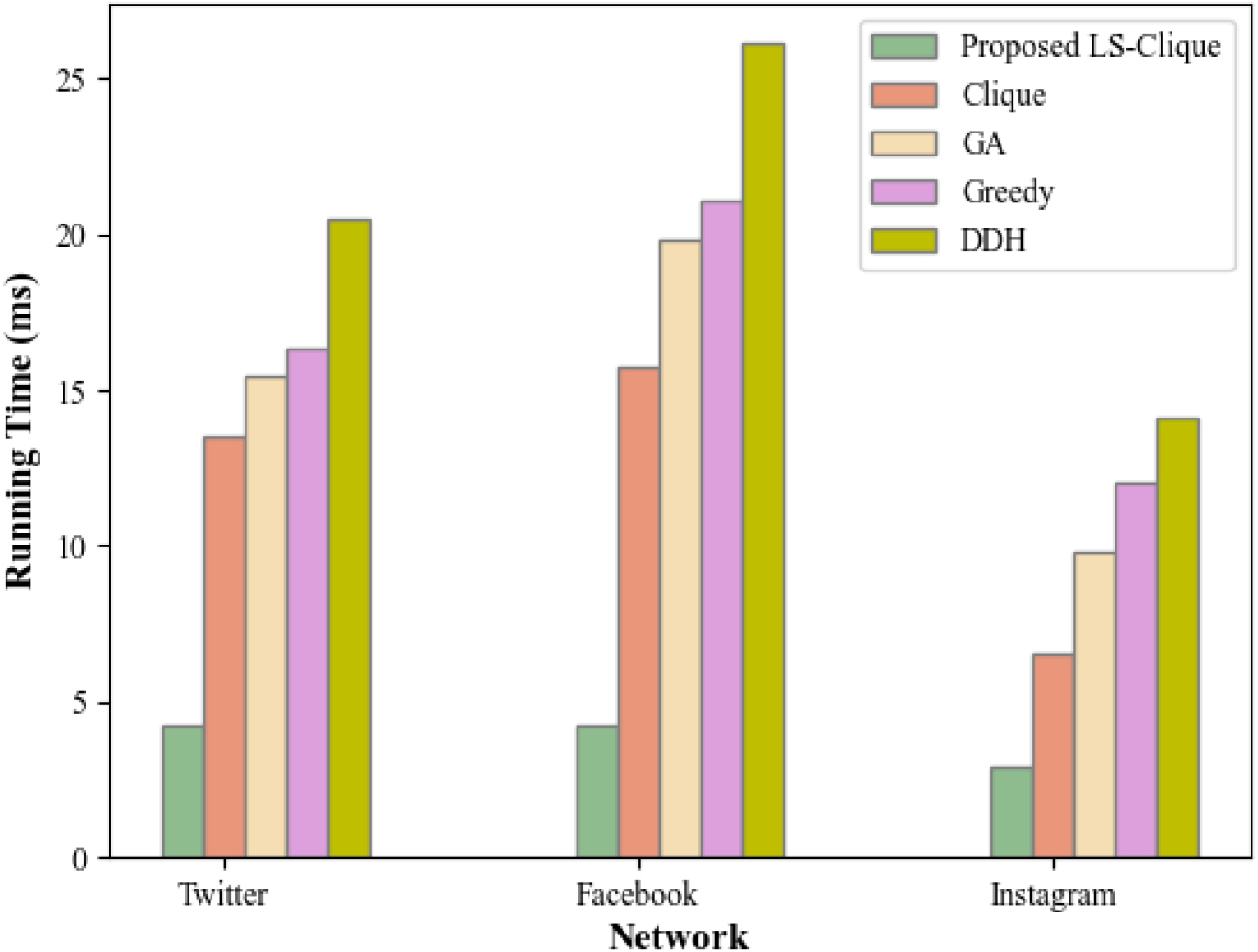
Comparative analysis of influence spread of proposed LS-Clique IM model with existing IM model.
Figure 5 analyses the achieved influence spread of proposed LS-Clique and existing Clique, Genetic Algorithm (GA), Greedy, and Degree Discount Heuristic (DDH) methods for the seed size at interval of 10 upto 50 iteration. In comparison with the existing methods, the influence spread by the proposed LS-Clique algorithm is maximum. This indicates that the separate feature analysis of heterogeneous and homogeneous networks improved the performance of the proposed context-based IM model.
Figure 6 shows the influence coverage attained by the proposed LS-Clique and existing IM model for Twitter, Facebook, and Instagram social media networks. The influence coverage of proposed LS-Clique algorithm outperforms the existing approaches under various node generation. Thus, the community detection-based network analysis improved the quality of the proposed context-based IM model.
Figure 7 analyses the execution run time of the proposed LS-Clique and existing models for three different network data, Twitter, Facebook, and Instagram. The running time attained by the proposed context-based IM model is 4.214 s (Twitter), 4.21 s (Facebook), and 2.91 s (Instagram), which is minimum than the existing methods. This indicates that periodic estimation of network snapshots, continuous updation of influencing nodes, and reduction of enlarged graphical ranges using the LS technique significantly minimized the execution run time of the proposed context-based IM model.
Figure 8 analyses the influence spread of proposed LS-Clique IM model with existing IM models developed by Li et al. [14], Liu et al. [16], Zhang et al. [15], and Wang et al. [19] in Section 2. The analyses are done for a maximum node set of size 50. While comparing the existing methods, the influence spread attained by the proposed model is maximum. The consideration of contextual features from the network nodes and the effective link prediction through different ways of community detection proves the effectiveness of the proposed context-based IM model.
In this paper influence maximization model framework is based on context propagation in a multiplex network. The WH-KMA-based community detection, PPT-LSTM-based link prediction, and LS-Clique-based IM are the three significant contributions of the proposed context-based influence maximization model framework. The proposed model is implemented using the social media datasets collected for three different networks, namely Twitter, Facebook, and Instagram. Experimental analysis is done to evaluate the performance of the proposed context-based IM model including influence spread, coverage, running time analysis of LS-Clique, link prediction performance of PPT-LSTM, and community detection analysis of WH-KMA. In the experimental analysis, the proposed PPT-LSTM, WH-KMA, and LS-Clique techniques are contrasted with the existing methods. Separate feature analysis of heterogeneous and homogeneous networks, periodic estimation of network snapshots, continuous updation of influencing nodes, and reduction of enlarged graphical ranges using the LS technique significantly minimized the execution run time of the proposed context-based IM model. The consideration of contextual features from the network nodes and the effective link prediction through different ways of community detection proves the effectiveness of the proposed context-based IM model. The experimental outcomes reveal that the proposed context-based IM model achieves an enhanced performance and faster than the state-of-the-art algorithms in a dynamic environment. In the future, the work can be extended to assess the scalability in providing approximation bound on IM.
Footnotes
Declaration of competing interest
The authors certify that there are no conflicts of interest in the subject matter discussed in this manuscript.