
Abstract
In response to the difficulties in integrating multimodal data and insufficient model generalization ability in traditional cross-modal knowledge transfer, this article used the Transformer model to explore it in the new generation learning space. Firstly, the article analyzed the processing methods of data and models in cross-modal knowledge transfer, and explored the application of Transformer models in the learning space. This model used natural language processing to represent and extract textual features, Mel Frequency Cepstral Coefficients (MFCCs) to represent and extract audio features, and Faster R-CNN (Faster Region-based Convolutional Neural Network) to represent and extract image features. The article also discussed the implementation process of the Transformer model functionality. The experiment used data from four datasets, including Quora Question Pairs, to test the performance of the model’s cross-modal knowledge transfer through intelligent question answering and task analysis. In single type data testing, the accuracy and recall of the model in this article were better than the comparison model in the three types of data. The highest accuracy and recall in the test set were 91% and 93%, respectively. In the most challenging multimodal intelligent question answering test, the speech-image question answering method achieved an accuracy rate of 89% in answering open questions, indicating that the model had good multimodal data fusion ability. In the analysis experiment of 6 homework prone knowledge points on images with text annotations, the induction accuracy reached 85%, indicating that the model had strong generalization ability. The experimental results showed that the Transformer model had good cross-modal knowledge transfer performance, providing a reference for subsequent research on cross-modal knowledge transfer in the new generation learning space.
Keywords
Introduction
With the development of society, various forms of information are becoming more and more complex, and the way of knowledge transmission is constantly improving. From the initial transmission of language to text, and then to images and videos, the ways in which human knowledge is transmitted are becoming more and more diverse, and various forms of knowledge are constantly merging. However, the traditional cross-modal knowledge transfer methods face difficulties in integrating multi-modal data and model generalization ability, which greatly limits the efficiency and learning effect of knowledge transfer. To address these challenges, this study introduces the Transformer model to explore its cross-modal knowledge transfer capability in the next-generation learning space.
In the context of cross-modal knowledge transfer, the processing of text, audio and image features is crucial. In this article, text features are represented and extracted by natural language processing, audio features are represented and extracted by MFCC, and image features are represented and extracted by fast regional CNN. Through these techniques, this article aims to solve the problems of difficult integration of multi-modal data and insufficient model generalization ability, so as to improve the efficiency and learning effect of knowledge transfer.
The experimental part uses four datasets, including Quora question pairs, to test the model’s performance in intelligent question answering and task analysis. In the single type data test, the accuracy and recall rate of the model in the three types of data are superior to the comparison model, and the highest accuracy and recall rate in the test set are 91% and 93%, respectively. In the most challenging multimodal intelligence question answering test, the voice-image question answering method achieved 89% accuracy in answering open questions, showing the model’s good ability in multimodal data fusion. In six knowledge point analysis experiments on images containing text annotations, the induction accuracy reaches 85%, which indicates that the model has strong generalization ability. The experimental results show that Transformer model has good performance in cross-modal knowledge transfer, which provides a reference for subsequent research on cross-modal knowledge transfer in a new generation of learning space. Main contribution of this paper are as below.
Introduction of Transformer model: The Transformer model is introduced for the first time in cross-modal knowledge transfer, and its advantages in processing sequence data and multi-head attention mechanism are utilized to improve the generalization ability and knowledge fusion efficiency of the model. Multi-modal feature processing: Text, audio and image features are successfully represented and extracted through natural language processing, Mel Frequency Cepstral Coefficients and fast regional convolutional neural network technology, providing an effective solution for the integration of multi-modal data. Experimental verification: Four data sets including Quora question pairs were used to verify the performance of the model in intelligent question answering and task analysis, showing the superiority in single type data and multi-modal data fusion. Generalization ability analysis: The strong generalization ability of the model is proved in the experiment of knowledge point analysis on the image containing text comments, which provides a reliable basis for practical application.
In order to improve the efficiency of cross-modal knowledge transfer, many scholars have conducted their own research. The first step in cross-modal knowledge transfer is to integrate multimodal data, and some scholars have explored multimodal data fusion [1, 2, 3]. Sleeman IV WC [4] proposed a new classification method to describe and compare multimodal classification models, analyzed the challenges of current multimodal data sets, and discussed future research directions. Windsor E [5] proposed a long and short-term memory (LSTM) model based on multi-modal fusion, which realized efficient prediction of USD/RMB exchange rate by combining market indicators and investor sentiment. Shi Q [6] developed a soft robot sensing system that combines ultrasonic sensors and flexible triboelectric sensors to achieve efficient remote target location and recognition through multi-modal data fusion. Peng B [7] proposed a rotating machinery fault diagnosis method based on deep residual neural network (DRNN) and multi-modal data fusion, which significantly improved the effects of feature learning, model training, anti-noise, fault tolerance and fault diagnosis. Chen L [8] et al. proposed cross-modal emotion extraction to train models that utilize the fundamental frequency of electroglottal signals, achieving a balance between model complexity and performance. Wang Y [9] proposed a high-dimensional sparse hash framework for cross-modal retrieval, which successfully improved the accuracy and efficiency advantages of search frameworks. Although scholars have conducted research on various aspects of cross-modal knowledge transfer, the difficulty of integrating multimodal data has not been resolved.
The Transformer model is a sequence generation model based on multi-head attention mechanism. The initial Transformer model was applied in machine translation tasks. As scholars deepen their understanding of it, it has played an important role in many fields such as image, video, and audio [10, 11, 12]. Zhang Q [13] proposed a transformer that achieves better performance than baseline and representative models in multiple computer vision tasks by introducing multi-scale features and local inductive bias. Chu Y [14] proposed the TransMut framework to predict the binding of polypeptides to HLA through the TransPHLA model and automatically optimize mutant peptides using the AOMP program, thus improving the efficiency and accuracy of vaccine design. Lu X [15] used the GeT model based on Ghost convolution and Transformer network for the diagnosis of grape leaf pests and diseases, realizing efficient deep semantic feature extraction, significantly improving the accuracy and processing speed, and providing an effective benchmark for grape leaf diagnosis in the field. Baid G [16] improved the accuracy of DNA sequence correction with its gap-aware Transformer encoder, significantly reducing read errors compared to traditional methods, and improving the yield and genome assembly quality of PacBio HiFi reads. Chen Ke [17] et al. proposed a text sentiment analysis method based on sentiment lexicons and Transformers, which can fully utilize the feature information of sentiment lexicons to help better encode sentiment words. Mohammadi Farsani R [18] et al. proposed a Transformer neural network based on self attention, which had special ability in predicting time series problems. Widmann T [19] et al. compared the performance of different models and highlighted the advantages of the new Transformer based model. Wang Chencheng [20] et al. used a Transformer model based on multi-head attention mechanism as the error correction model and proposed a dynamic residual structure that dynamically combined the outputs of different neural modules to enhance the model’s ability to capture semantic information.
Application of transformer model
Cross-modal knowledge transfer
For different modalities of information, using the Transformer model for knowledge transfer requires a series of processing steps. Figure 1 summarizes the way the Transformer model handles data and models in cross-modal knowledge transfer.
Processing method of data and model.
Figure 1 shows the processing method of cross-modal knowledge transfer. For multimodal information data, such as text data, image data, and audio data, it is necessary to preprocess them and convert them into a format that can be uniformly processed by the Transformer model, and then extract their features in different ways. The attention mechanism in the Transformer model can be applied to the fusion of different modal features, which is to enhance the understanding of information between various modalities during model training. In cross-modal information transfer, the multi-head attention mechanism of the Transformer model can enable the model to learn the semantic correlation between different modal information, which is also the main process of knowledge transfer. For model processing, it is first necessary to model according to the requirements of the task. Common tasks include text-image search, which requires the fusion of features from both text and image data for modeling, or the judgment of emotions expressed in a video. This task requires the fusion of image and audio features for modeling. After completing the training of the model, it is necessary to evaluate it. If it meets the set requirements, such as accuracy and recall, and performs well, it can be applied.
The Transformer model faces challenges in practical applications. High computing cost, processing long sequence data, difficulty in processing sparse data and lack of domain knowledge are the limitations. Taking these factors into consideration, it is crucial to select the right scenario and customize the model.
In the new generation of learning space, the Transformer model has a wide range of ways to achieve knowledge transfer. For example, for personalized learning recommendations, the Transformer model analyzes students’ notes, grades, study habits, and so on. Based on the analysis results, more suitable and interesting learning materials are recommended to students; based on students’ written or spoken questions, the Transformer model constructs natural language understanding and generation, which can intelligently answer students’ questions, provide corresponding reference materials and answer difficult questions; based on the homework submitted by students, errors in the homework are analyzed in the form of text or images, and knowledge points related to easy and frequent mistakes are summarized, providing teaching direction for the teacher. In the above applications, the Transformer model processes multimodal data such as text, images, and speech according to different requirements, providing students with an efficient and accurate cross-modal knowledge transfer process.
The adaptability of the model is reflected in its ability to be customized according to the needs of different tasks. In personalized learning recommendation, the model analyzes students’ notes, grades and study habits to recommend appropriate learning materials. In intelligent question answering, the model builds natural language understanding and generation capabilities to answer students’ questions; In homework analysis, the model analyzes the homework submitted by students, identifies errors and summarizes error-prone knowledge points, and provides teaching guidance for teachers.
Data representation and feature extraction
This article refines the data representation and feature extraction process of cross-modal knowledge transfer in Transformer model through the following steps: advanced natural language processing technology is used to conduct in-depth text analysis, and pre-trained word embedding model is used to extract text features. The audio data were preprocessed and converted in frequency domain, and MFCC characteristics were obtained by using Mel filter banks and cepstrum analysis. Faster R-CNN was used to extract regional features from image data. Then, using the multi-head attention mechanism of the Transformer model, features of different modes are integrated. Finally, the model is optimized to improve the accuracy and generalization ability of the model.
This article uses Natural Language Processing (NLP) to extract the main parts of text. NLP [21, 22] is a branch of artificial intelligence primarily used for processing human language, which plays an important role in text feature extraction. By capturing the structural relationship between words, Transformer model can better understand the semantics and structure of text, and improve the accuracy and efficiency of text feature extraction. Figure 2is a schematic diagram of the results of NLP analysis of a paragraph structure.
Schematic diagram of NLP analysis structure.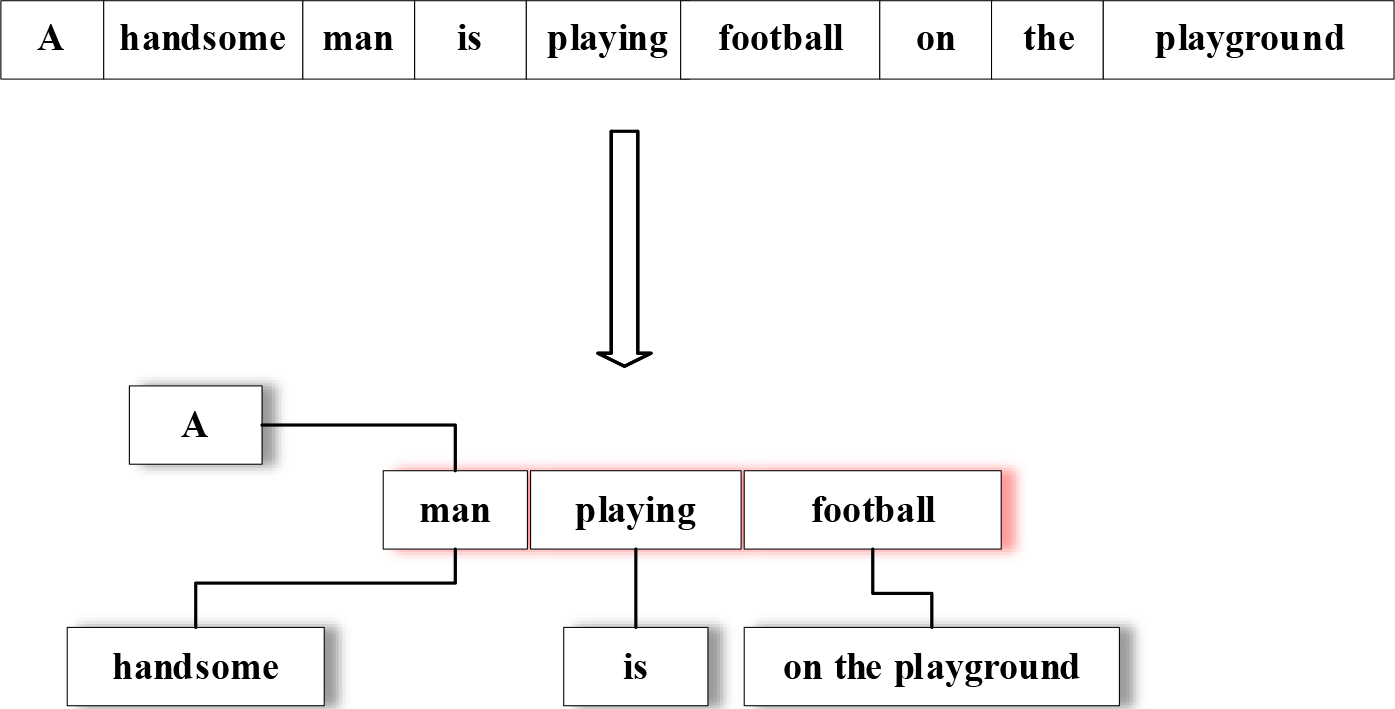
Figure 2 shows the structural analysis results of NLP for a paragraph of text. The original text is: “A handsome man is playing football on the playground”. After NLP analysis, the main content of this paragraph has been simplified to “man playing football”. All other text is used to modify the main content of this paragraph. This processing helps the model accelerate its understanding of textual information. The main content of the text is used as the text embedded in the Transformer model. Assuming
Among them,
The Transformer model extracts features from
All feature vectors in the feature set
Speech features are usually divided into prosodic features and sound quality features. Rhythmic features are non personality traits that exist in each person’s way of expression. The prosodic features include elements such as energy, resonance peaks, pitch, and speech duration, reflecting the dynamic expression characteristics of a speech. These elements change based on the emotions of the speaker at the time, the environment they are in, and their subjective consciousness. When the speaker is in a joyful state, the energy in the speech would increase, and the resonance peak may be relatively stable; when emotionally excited, the pace of speech would increase and the voice would become loud. When the speaker is in a noisy environment, he can express himself by increasing his volume. In theatrical performance, actors achieve expressive effects that conform to the plot by changing the rhythm of language, which is a subjective manifestation of phonology.
The sound quality characteristics are personalized features that are related to each individual’s physiological structure. Everyone’s vocal cords, mouth, throat, and other parts are unique, and the production and resonance of sound are different. Sound quality features are also the main features of personalized recognition, with specific applications including voiceprint locks, voice authentication, etc. In the process of knowledge transfer, sound quality features can effectively distinguish the specific identity of students and provide more targeted answers.
To describe speech data, frequency domain analysis is generally used, and Fourier transform [23, 24] is used to perform spectral analysis on speech. A segment of speech is decomposed into several single frequency waveforms. The spectral features are mainly composed of linear prediction coefficients and cepstral analysis, and the feature representation method used in this article is Mel Frequency Cepstral Coefficients (MFCC).
MFCC [25] utilizes the non-linear correspondence between Mel frequency and Hertz frequency, and calculates their correspondence. The calculation method for MKCC is:
Among them,
Audio and Mel spectrogram.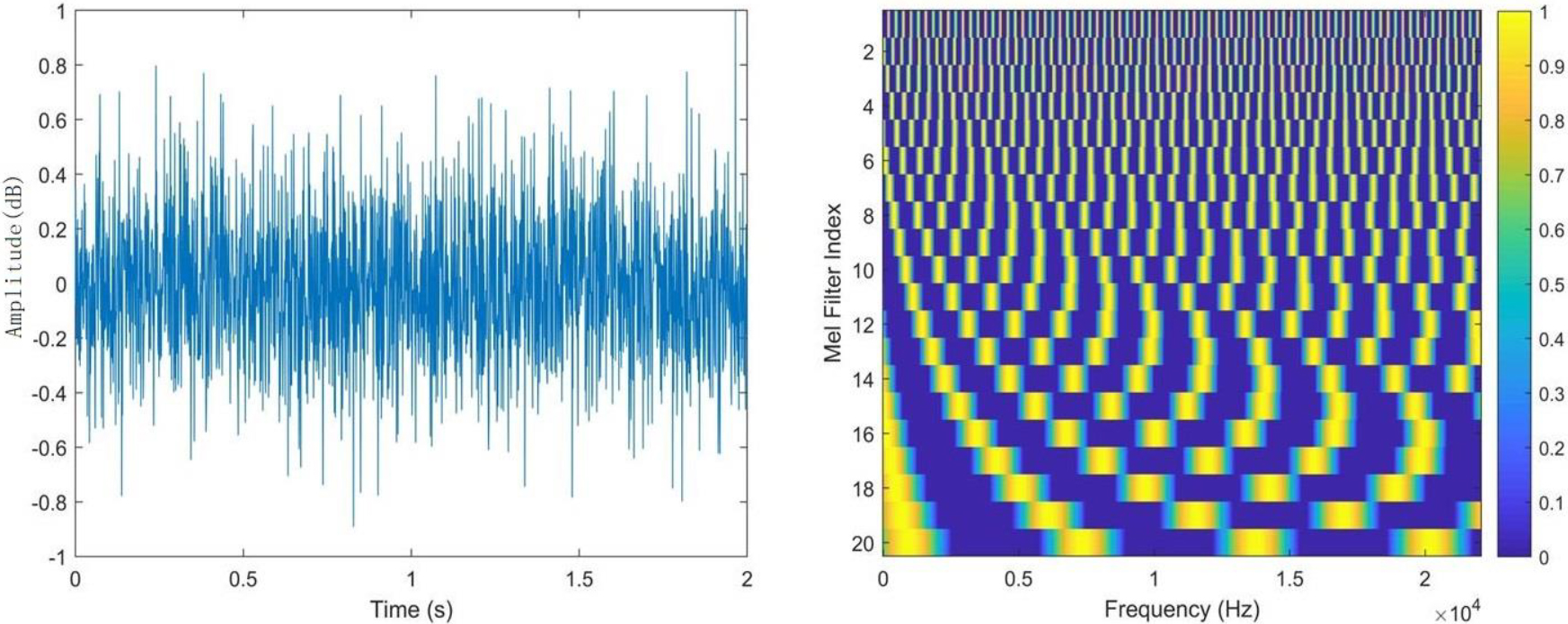
The left figure in Fig. 3 shows the waveform of a certain audio signal, showing the image of the amplitude of this audio signal changing over time. The right image is the Mel spectrogram, with the y-axis representing the index of the Mel filter. It represents the number of the filter bank on a specific Mel frequency scale and does not have a unit itself. Each color band represents a separate Mel filter, which is distributed at intervals throughout the entire image. The Mel spectrogram can effectively extract features from speech data. MFCC simulates human ear perception to extract audio features critical to speech recognition, which has good computational efficiency and noise robustness. However, they are limited in high-frequency resolution and fast audio change capture, and are sensitive to parameter selection.
Selecting the right MFCC parameters is crucial for extracting effective audio features. The key parameters include the number of filters, window length, frame shift and gauss coefficient. The number of filters determines the frequency resolution, while the window length and frame shift affect the time resolution and the coverage of the audio signal. Gauss processing can enhance the stability of features.
For feature extraction of image data, this article chooses to use Faster R-CNN to perform preliminary feature region selection on the image. Faster R-CNN [26, 27] was chosen for its high accuracy in target detection and robustness to multi-scale targets. Compared to YOLO (You Only Look Once), it is more accurate. Compared with R-CNN (Region-based Convolutional Neural Network), it significantly improves speed through regional proposal networks. These characteristics make it an ideal choice for image feature extraction in multimodal learning space. Figure 4 shows some examples of Faster R-CNN detection applications.
Faster R-CNN detection results.
The images in Fig. 4 are all sourced from the Roboflow Universe platform, displaying the results of vehicle recognition, building frontal recognition, cherry leaf recognition, and other detection methods. For images that require feature extraction, the Faster R-CNN is first used for region feature partitioning, and then feature vectors are extracted. The feature vectors are placed in the embedding layer for processing, and in the embedding layer, the feature vectors are dimensionally reduced from high dimensions to 512 dimensions. ReLU [28, 29] (Rectified Linear Unit) function is used to enhance the nonlinear expression ability of the feature vector after dimensionality reduction, and its calculation formula is as follows:
The ReLU function is used to reduce the risk of gradient disappearance, and the Dropout layer reduces overfitting and improves the performance of the Transformer model. Finally, the generated vectors are used as input vectors in the Transformer encoder for training.
After extracting the features of text, speech, and image, they all enter the encoder of the Transformer model for unified training. All features need to be fused before training. Feature fusion mainly utilizes the multi-head attention mechanism of each layer of the Transformer model encoder to weight and fuse feature vectors of different modalities. The query vector, key vector, and value vector of the feature vector are set to
Among them,
When calculating the value of multi-head attention, it is normalized by Softmax and then multiplied by the value vector to obtain the weight value of multi-head attention. Finally, the obtained weight values are weighted and fused with the corresponding feature vectors, resulting in the fusion vector
In the feature weighted fusion process through multi-head attention mechanism, the model pays attention to the relationships between various modalities of data, generates semantic connections, and improves the model’s ability to express data, which is information transmission.
Datasets
According to the task requirements, this experiment used the natural language processing dataset Quora Question Pairs, annotation information dataset AI2D, multimodal dataset Visual Question Answering, and speech dataset VQA-Voice. Data sets are selected based on their relevance and diversity to the experimental target. The Quora Question Pairs dataset is chosen because it contains rich question pairs and is close to real-world application scenarios to train the model to understand and answer the student’s questions. AI2D datasets focus on job analysis, helping models identify errors and error-prone knowledge points. Visual Question Answering data sets enhance a model’s ability to process multimodal information by answering questions in combination with text and images. The VQA-Voice dataset focuses on voice question answering, providing the model with the ability to process voice input. The comprehensive use of these data sets ensures the comprehensiveness and practicality of the model in the multimodal knowledge transfer task.
Performance test result.
This experiment was conducted on the Windows 10 operating system, with a deep learning framework of Pytorch, a Central Processing Unit (CPU) model of Intel i9-9900k, a graphics card model of Nvidia 2080Ti, and a running memory of 32GB.
In the training parameter settings, the learning rate was set to 0.0005; the number of iterations was set to 20; the Dropout value was set to 0.2; the optimization function used the Adam function [30].
Experimental process and results
Firstly, the basic performance of the model was tested, and three algorithms, Support Vector Machine (SVM) [31], Naive Bayes Classifier, and Random Forest [32], were introduced for comparison in the experiment. Due to the fact that some of the algorithm models mentioned above do not have the ability to handle cross-modal data, the three types of data, namely text, speech, and image, were tested separately. The experiment selected 5000 text Q&A, 2000 speech Q&A, and 3000 image Q&A in four datasets. The training and testing sets were tested in a 1:1 ratio. The obtained results are shown in Fig. 5.
Questioning test results.
Job analysis test results.
Figure 5 shows the performance of each model in the training and testing sets. It can be observed that the overall performance of each model in the test set was better than that in the training set, both in terms of accuracy and recall. Among the three types of data, the Transformer model performed the best, with accuracy rates of 0.91, 0.87, and 0.88 for text, speech, and image in the test set, and recall rates of 0.91, 0.90, and 0.93, respectively. The Naive Bayes classifier had poor overall performance, with no data exceeding 0.8 in the test set. The results show that the Transformer model performs well on various types of data, while naive Bayes classifiers generally perform poorly. In addition, differences in the model’s performance on the training set and the test set were also observed, indicating the importance of the model’s generalization performance. Further study of this performance volatility may help optimize model performance and address challenges in different data modes.
In order to test the Transformer model’s ability to integrate multimodal data, the experiment asked questions about the model. There were two types of questioning methods: text questioning and speech questioning, and the model was explicitly required to answer in the form of text or images. There were three types of problems: factual problems, reasoning problems, and open-ended problems. Fact questions are questions with clear answers, such as “what is the standard gravitational acceleration” or “who was the first person to manufacture an airplane”; inference questions are questions that require explanation, such as “why ice floats on the water surface”; open questions are a type of question that tests the creativity and understanding of a model, such as “what is the biggest challenge you may encounter in the next year of learning?”. Three types of questions were labeled as A, B, and C, and the accuracy and time of the model’s answer were tested. The obtained results are shown in Fig. 6.
Figure 6 shows the results of questioning the model. Among them, subgraphs (a), (b), (c), and (d) represent the question answering methods of text-text, text-image, speech-text, and speech-image, respectively. In the text-text question answering method, the model had a very high accuracy rate for three types of questions, which were 99%, 98%, and 99%, respectively. In the text-image question answering method, the response times for the three types of questions were 1.87s, 2.14s, and 3.64s, respectively. Among the four questioning methods, the most challenging one was the speech-image question answering method, which greatly tested the model’s ability to integrate multimodal information. In this experiment, the accuracy of the model in answering three questions was 91%, 91%, and 89%, with response times of 2.36s, 3.64s, and 6.54s, respectively. The experimental data showed a decrease compared to other questioning methods, but the accuracy remained around 90%, indicating that the model has good multimodal data fusion ability and has good answer accuracy for questioning data of different modalities, effectively completing knowledge transfer.
In order to test the generalization ability of the model, different types of assignments were inputted into the model as data, including six types: mathematics, physics, chemistry, biology, history, and art. The data of text, images, and images with text annotations were tested separately and labeled as E, F, and G. The accuracy of the model’s induction of error prone knowledge points was calculated, and the accuracy was determined by the teacher manually judging whether the results are accurate. The obtained results are shown in Fig. 7.
Figure 7 shows the accuracy of the model’s induction of error prone knowledge points in task analysis for three modal data as the number of task types increases. Overall, with the increase of homework types, the accuracy of induction showed varying degrees of decline. In textual modal data, the induction accuracy of one task type reached 99%, but when it increased to six types, it decreased to 96%. The image modality decreased from 98% to 91%. In the image mode of text annotation, when the number of task types increased to 5, the induction accuracy was already below 90%, and when there were 6, it dropped to 85%. Although the accuracy was less than 90%, 85% was an excellent number for multimodal task analysis. According to the experimental results, as the types of tasks increase, it shows strong generalization ability and adaptability. This shows that the model has excellent performance and potential in multimodal task analysis, which can effectively process new types of job data and promote students’ knowledge transfer.
In the new generation of learning space, cross-modal knowledge transfer is of great significance in improving student performance and helping teachers summarize knowledge points. This article used the Transformer model, combined with natural language processing and Faster R-CNN technologies, to achieve knowledge transfer to students through intelligent question answering and homework analysis. The experimental results showed that the model proposed in this article not only performed better than other models in testing with single-mode data, but also had good accuracy in answering multimodal questions. In the analysis of multiple types of homework, the accuracy of knowledge point induction is good, reflecting the model’s good generalization ability. The innovation point of this article is that it proposes an innovative method of multi-modal data fusion, and demonstrates the efficiency and effectiveness of Transformer model in processing comprehensive information, which is an extension of its application field. The limitation of the experiment is that in the analysis of multi type tasks with text annotated images, the accuracy of some experiments did not reach over 90%. It is hoped to improve the results here to the ideal level through training on more types of datasets in the future.
Data availability statement
The data of this paper can be obtained through the email to the authors.
Funding
There is no funding information for the work in this paper.
Footnotes
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this work.