
Abstract
Many factors affect the precision and accuracy of location data. These factors include, but not limited to, environmental obstructions (e.g., high buildings and forests), hardware issues (e.g., malfunctioning and poor calibration), and privacy concerns (e.g., users denying consent to fine-grained location tracking). These factors lead to uncertainty about users’ location which in turn affects the quality of location-aware services. This paper proposes a novel framework called UMove, which stands for uncertain movements, to manage the trajectory of moving objects under location uncertainty. The UMove framework employs the connectivity (i.e., links between edges) and constraints (i.e., travel time and distance) on road network graphs to reduce the uncertainty of the object’s past, present, and projected locations. To accomplish this, UMove incorporates (i) a set-based pruning algorithm to reduce or eliminate uncertainty from imprecise trajectories; and (ii) a wrapper that can extend user-defined probability models designed to predict future locations of moving objects under uncertainty. Intensive experimental evaluations based on real data sets of GPS trajectories collected by Didi Chuxing in China prove the efficiency of the proposed UMove framework. In terms of accuracy, for past exact-location inference, UMove achieves rates from 88% to 97% for uncertain regions with sizes of 75 meters and 25 meters respectively; for future exact-location inference, accuracy rates reach up to 72% and 82% for 75 meters and 25 meters of uncertain regions.
Keywords
Introduction
The exponential rise in GPS-enabled smartphones has sparked an increase in location-based services including navigation, movement analysis, and market ads [1, 2]. In fact, the majority of current location models used by these services measure any mistakes or discrepancies between the GPS location that is recorded and the actual location [3, 4]. During the recent pandemic of Covid-19 and in similar health-related applications, contact tracing queries deal with location uncertainty in users’ trajectories as an essential task in order to identify those individuals who might have been in close proximity to an infected person [5, 6]. In crime monitoring, jurisdictions use tracking devices, e.g., ankle bracelets, to control how long a suspect person can stay outside their allowed region. This is an application of geofencing [7, 8] that requires real-time processing for the trajectories of the tracked person. Unmanaged uncertainty in the reported locations from these bracelets can be dangerous to places or people that might be the target of the tracked criminal [9]. Another example; is if a user wants to locate available taxi cabs nearby from his home on a rainy day, due to imprecise location, the user will walk very long distances to locate taxi cabs.
For these reasons, the issue of location uncertainty has received considerable attention and needs to be assessed to make location-based services work efficiently and in an accurate manner. This has increased the demand for location-aware services [10, 11, 12] to manage ambiguous location data to satisfy users and application needs. For example, in the sales sector and marketing activities, reports highlighted that the total number of sales outlets increased from 221 to 289 visited outlets when the impacts of location data uncertainty were eliminated [13, 14, 15, 16]. In the health sector, physicians need accurate information about patients’ walking distances. Handling location uncertainty in evaluating these distances helps in exposure evaluation and diagnostics [17].
This paper addresses the problem of managing uncertainty for trajectories of moving objects.
Indeed, managing uncertainty in the context of the paper means extracting a user’s precise location from an uncertain set of points (trajectories) expressed as latitude, longitude, and timestamp.
The absence of accurate position information (specific latitude and longitude), which is what this study refers to as uncertainty, is what causes an object’s location to be represented by an imprecise circular zone. Actually, several real-life cases represent the absence of accurate position and location information such as when the moving object located inside an area without strong access to GPS satellite signals such as driving in a tunnel, moving in an indoor garage building or the GPS hardware itself sending noisy readings due to hardware/software malfunction or GPS spoofing.
For this purpose, this paper suggests the UMove framework, which enables the refining of an object’s movements as incoming imprecise location data are received and more accurate inference of the past, present, and future positions of the moving objects. Indeed, this paper is an extension of the work done in [18].
The management and querying of moving objects under position uncertainty are difficult and time-consuming. The potential effectiveness of the suggested work may be impacted by the size of the unclear region that represents a possible placement for an object and the density of the road network. We must take into consideration a sizable number of potential places for the moving object as a result of both of these considerations. The metadata gleaned from the road network graph may also play a role. A road network graph that is too simple might not include enough details to allow for correct inference, forcing us to make educated guesses instead. The ability to to narrow down the potential courses for a particular moving object by using information such as edge type, such as a highway or bike track. Lack of continuity in an object’s trajectory could be another problem. If an item does not follow a continuous trajectory or a significant number of location updates are lost, UMove may function poorly or not at all. This is because it does not refine piece-wise trajectories.
Existing methods for finding the positions of ambiguous moving objects may be inaccurate or have slow performance [19, 20, 21]. Objects’ future trajectories are frequently not predicted by models that examine their past motions. Similarly, models that facilitate queries about the future frequently ignore the recent past. Techniques that support predictive and uncertain location inquiries frequently call for a substantial amount of historical data, which is often difficult to get due to concerns about privacy or confidentiality or simply a dearth of data, as in rural areas. Although vehicles restricted to road networks are typically the inspiration for such models, other models do not often take advantage of the limits of road networks.
There are only two main areas of concentration for this paper. Every time a location update is made, potential historical locations are first filtered and improved. Following that, the potential present locations are reduced using the revised historical movements. In spite of the inaccurate location data, future motions are secondarily estimated using the current or most recent locations with a high degree of accuracy.
A point and a radius spanning a region serve as representations for the moving object’s approximate starting location at the start of a trip. One way to query an object’s historical trajectory is to use the imprecise areas that indicate where it was and is at the beginning of a trip. The object’s most recent imprecise region is used to estimate an object’s future movements in predictive inquiries. There is always a collection of nodes indicating an object’s potential position at any one time since moving objects with ambiguous locations are being indexed.
A probability model assigns probabilities to the nodes in the newly imprecise portion of the object’s travel with future updates. The road network’s probability of transit along edges between the oldest and newest imprecise regions can be calculated using position updates that are not exact. The list of potential nodes the object might have previously passed through is then narrowed down using these probabilities. As nodes may be removed throughout the pruning process, and of course, the probability and edge weight functions may have a substantial impact on the outcome of the pruning process, a number of factors may affect this model in practice.
To help with prediction, information from the underlying road network and data refined from the earlier potential locations are employed. Because fewer total nodes need to be accounted for, trimming historical nodes enables more accurate forecasts of future movements. Additionally, a flexible solution is possible because the probability model for predictive questions can be altered in accordance with user requirements. The contributions in this paper are summarized below:
Develop the UMove framework to manage trajectories with uncertain locations. Describe a probability model that is employed to enhance past/current motions and predict with high accuracy future positions. Utilize a real-world dataset to carry out a thorough experimental evaluation to show the utility of our suggested UMove framework.
The present research and how UMove fits within the field of moving object query processing are described in the parts that follow. Problem specification, algorithms, and examples are then presented. Finally, the experimental evaluations demonstrating the effectiveness of UMove and conclusion.
Roadmap: The rest of this paper is organized as follows. Section 2 presents an overview of related work. Section 3 describes preliminary knowledge and definitions. Section 4 describes the problem definition. The section 5 presents the proposed weight and probability model. The proposed solution is presented in Section 6. Section 7 presents our experimental results. Finally, Section 8 concludes the paper.
This section summarizes the previous studies that have already been done to address the issue of anticipating the future movements of a moving object and dealing with location uncertainty.
The study of movement prediction has received a great deal of attention. Some tactics make use of motion functions [22, 23]. Even though functions can be intricate, there are times when they don’t correspond to how objects move. These methods don’t support prediction in uncertain situations.
In order to forecast future movements, the predictive tree uses road networks and assumes that the shortest path of travel would be taken. It does not take uncertainty into account [24]. Future motions are another goal of the mobility concept. This method makes use of a large database of past trajectory data [25]. The R*-Tree bases the prediction model on work done on R-trees [26]. By creating spatial histograms that represent item movement, the adaptive multi-dimensional histogram enables past, present, and predicted searches [27]. The TPR*-Tree builds on previous work on the TPR tree and uses a new set of insertion and deletion algorithms to try and tackle the problem of movement prediction [26, 28]. These methods don’t take uncertainty in shifting object location data into consideration. The method proposed in [29] uses modified R-trees to facilitate querying moving objects in uncertain environments. This approach uses specialised query filtering techniques and probability density functions to represent objects.
The approaches listed below enable predictive queries with uncertainty. To help with the prediction of moving objects under uncertainty, one method uses location and velocity constraints [30]. The UTR-Tree creates an index structure on top of R-trees to facilitate uncertain predictive queries [31]. This approach tackles uncertainty that arises during movement between precise location updates, whereas this paper assumes there is no precise location data at all. The U-tree uses rectangles that are probabilistically limited to represent an object’s uncertain location and to aid in the trimming process. This strategy encourages inquiring in the face of uncertainty [32].
Another model that attempts to address the issue of anticipating enquiries is PLM. Adjacency matrices generated from the topology of the road network are used in this method [33]. A system called Panda allows for general predictive object querying [34]. This method ignores the limitations of the road network and models movement on Euclidean space. A spatial object known as a representative trajectory is created to record movements within pertinent areas, which are subsequently enhanced and applied to forecast future motions [35]. These methods don’t deal with uncertainty. Later, the location uncertainity is handled in [36] with the assumption that objects move on euclidean space.
When evaluating range queries under uncertainty, the uncertain trajectory hierarchy index structure uses time-dependent probability distribution functions [37]. Predictive queries are not supported by this structure.
SubSyn proposed in [38] predicts the final location of moving objects when there aren’t many historical trajectories available. However, neither the trajectory an object might follow to get there nor the handling of uncertainty are provided by this method.
In [39], the authors proposed a probabilistic trajectory prediction model that describes the uncertainty in future positions along the ship trajectories by continuous probability distributions. The ship motion prediction is decomposed into lateral and longitudinal directions, and position probabilities are calculated along these two directions. A data-driven non-parametric Bayesian model based on a Gaussian Process is proposed to describe the lateral motion uncertainty, while the longitudinal uncertainty results from the uncertainty on the ship acceleration along the route.
Trajectories prediction of road agents is fundamental for self-driving cars. Trajectory prediction contains many sources of uncertainty in data and modeling. In [40], the authors proposed a new framework named Uncertainty Quantification Network (UQnet) to systematically quantify sources of uncertainty. Moreover, the proposed framework approximates the spatial distribution of an agent’s future position.
Work proposed in [41, 42, 43, 44] employs hidden Markov models to foretell the location that will be visited next. Another work proposed in [45] uses Markov chains to forecast the position of the following object. However, in these methods, uncertainty is not taken into account. In [46], the authors employ Markov-chains to model trajectories for prediction and making use of temporal information. While uncertainty is considered in this paper, the definition differs from the one in this paper; i.e. the uncertainty which arises in between location updates rather than the uncertainty which is present within the location updates. There is a description of yet another method using Markov chains in [47]. This method simplifies nearest-neighbor queries in the presence of uncertainty, but since it uses Euclidean space to simulate movement, it ignores road network restrictions.
In [48], for the purpose of forecasting object trajectories, the authors use fuzzy-LSTM networks. The procedure outlined in [49] suggests using Continuous Time Bayesian Networks and supplementary algorithms to forecast the paths of moving objects. In [50], by using a mobility model, the authors suggest a method called InferTra to forecast the trajectories of moving objects. These techniques do not take into account inaccurate location data and need a lot of data to be effective.
The mobility forecasting system outlined in [51] uses Dempster-theory Shafer’s but does not deal with uncertainty. For this strategy to work, a sizable amount of historical data is not necessary. The project mentioned in [52] models uncertainty by restricting the placement of an object to a specified range of locations. The users are able to do range queries using this uncertainty model. The method does not take into account the constraints of a road network graph and instead applies Euclidean space and velocity constraints.
For moving objects with unknown locations, the IPAC-NN tree described in [53] makes nearest-neighbor queries easier. It supports nearest neighbour searches while modelling uncertainty via shared cylinders that represent trajectory.
For resolving location-based range queries under uncertainty, see the solution suggested in [54]. The intersection between the query region and an object’s unsure region is assessed by the authors using the Minkowski sum to help with pruning. The limitations of the road network, however, are not taken into consideration by this method.
In [55], a method for responding to nearest-neighbor requests when there is uncertainty is described. The method filters closest neighbours using R-trees. The final response is then assessed using probabilistic verifiers. The limitations of a road network graph are not taken into account in this method.
The use of Gaussian-distribution based management of uncertainty has been discussed in [56, 57]. In [56, 57], the suggested solutions respond to queries regarding probabilistic range and nearest neighbours under location uncertainty.
The UMove differentiates itself from other studies in (1) handling various types of queries that deal with moving objects located under imprecise locations, and (2) it handles the predication of moving objects in imprecise locations under all circumstance; such predict an object’s location at a given time in the future or infer a precise location for a moving object at a given time in the past. Additionally, UMove considers the constraints of the underlying road-network graph, and (3) the UMove makes use of data from earlier uncertain location updates to enhance and improve later inferences.
Preliminaries
This section looks into the supported queries and problem definition. A few terms with definitions that will be used in the text are listed below.
Uncertainty is characterised as a lack of specific location information. Instead, it is presumed that the information at hand refers to a vague area or position where a moving object might be at any given time. One way to think about the region’s size, which is determined by its radius, is as an indicator of uncertainty. In other words, the more or less certain we are of an object’s potential state, depending on how small or vast the reach of an imprecise region is.
Imprecise location
Steps/Updates are notifications of movement that we receive from moving objects. Each update
Regions
Predictive tree(s) are data structures covered in [24] which are applied to predictions about moving objects. A predictive tree’s nodes are connected to appropriate predictive regions at each level.
Given a road network graph
This work supports the following queries: Historical Queries aim to infer a precise location for a moving object at a given time in the past. The time range is limited by the earliest recorded update (first region). Predictive Queries aim to predict an object’s location at a given time in the future. We constantly modify and enhance the probability of properly guessing the future location using historical trajectories as location updates are received and the object approaches the prediction period. These searches provide a node (or set of nodes) that are anticipated to be the object’s position at the specified time together with their probability as their results. Ultimately, the goal is to achieve a meaningful degree of precision for both query types.
UMove: Weight function and probability model
Mainly, this section presents the UMove built-in weight function and the user-defined probability models within its framework. The UMove employs the historical height function to locate the precise location in the past, and UMove employs a predictive probability model to anticipate the object’s future location based on previous uncertain movements. The built-in function utilizes the road network graph, objects’ movements time updates, and network constraints to factor these variables into an equation. The weight function
Historical weight function
The probability of each node within the new zone are impacted by the edges that connect the two regions as an object moves between uncertain regions. Because nodes in the first area do not inherit edges, their weights are either uniform or undefined. As the object advances along its trajectory, subsequent regions in the trajectory inherit edges associated to earlier regions. The real trajectory can be established with greater accuracy by calculating and fine-tuning the edge weights between the most recent and the prior inaccurate regions. A weight function example is provided below.
Given consecutive regions
It makes sense to assume that an object would have travelled to and from two nodes if the inferred travel time between them is close to the actual time needed to move between them. Therefore, the edge that connects these nodes should be assigned with a lower weight. Therefore, it is more likely that the object will travel along the edge with the lowest weight.
The predictive tree suggested in [24] is used by the UMove predictive probability model.
Given that the location information for moving items is precise, the predictive tree enables the calculation of prediction probabilities for moving objects. In contrast, when the location of a moving object is uncertain, we represent it by an area made up of several nodes that indicate potential locations for the object. We build numerous prediction trees with roots at each of these nodes (in the unknown zone), and from each of these root nodes, the trees branch out to all potential nodes that can be reached. It is assumed in [24] that the object follows the shortest path.
Predictive tree (P-tree) is an index structured to answer predictive queries on moving objects traveled through the road network. It helps to answer different types of common queries such as range, point, and various aggregate queries. This proves that the P-tree owns a generic infrastructure. Additionally, the P-tree frequently updates the probabilistic prediction of the next location relevant to the objects in a dynamic and incremental manner during their movements in the road network. Figure 1 depicts how the predictive trees are integrated within the basic data structures layout to facilitate the processing of predictive queries over moving objects.
Predictive tree index structure.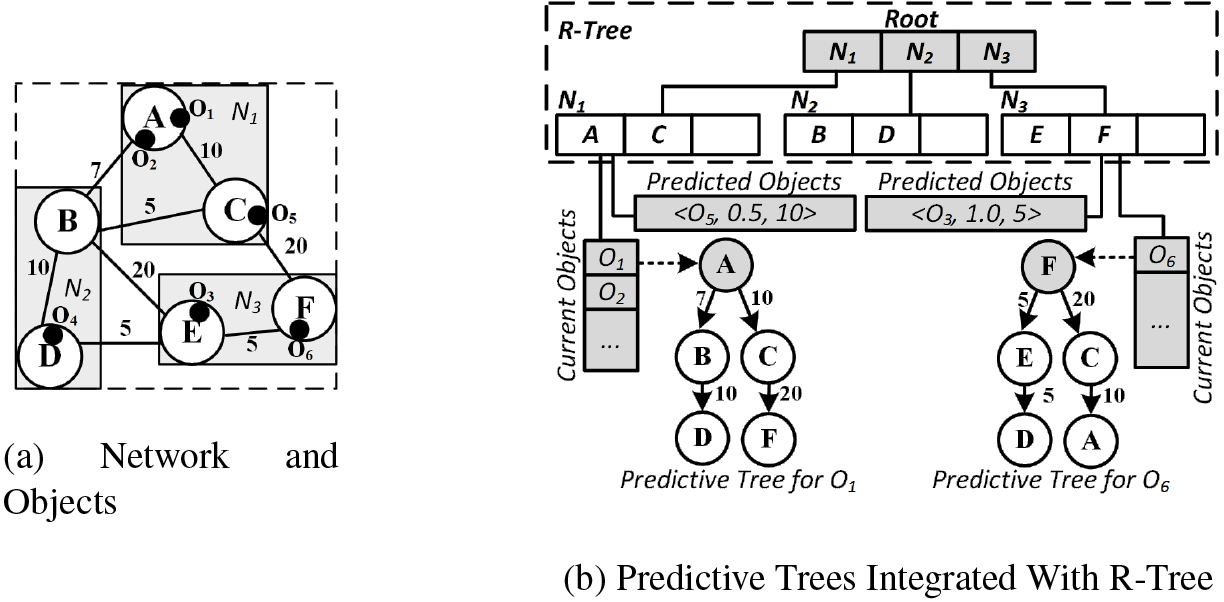
We follow this approach and inject a custom wrapper that takes in a user-given probability model and makes use of the refined historical regions and the resulting possible trajectories in conjunction with the leaf nodes of the predictive trees in order to identify possible future paths.
Algorithm 6.5 gives the procedures to predict the
The UMove framework has the following steps: (1) handle location updates, (2) prune historical regions, (3) Manage of predictive trees, (4) query past locations, and (5) query future locations.
Handle location updates
In algorithm 1, the pseudo-code for managing location changes is described. As a first stage in the process of removing unnecessary historical nodes from an object’s trajectory, this approach also updates the historically uncertain regions. It accepts as input
The newest inaccurate region’s available nodes are first obtained. On the initial location update, the created region is returned and all accessible nodes are viewed as potential locations for the moving object. A reference to every node in the prior region is generated if we are not on the first update (line 6). Then, a set comprising all of the preceding nodes’ descendants (nodes connected to outgoing edges) is generated by iterating through the prior nodes. Only nodes that have a direct connection to one or more nodes in the previous region are taken into account when reducing the number of nodes in the current region in line 11. A predetermined intersection with the offspring of the preceding region is used to achieve this.
By applying a set intersection between a node’s children and the latest nodes, the loop in line 14 iterates over the nodes in the previous region and determines whether it has a link to one or more nodes in the latest region. It is added to a group of obsolete parent nodes if it has no children because it lacks a continuous path to the most recent area. However, a node from the previous area is added to a list of valid parents if it has a connection to the most recent region, making it a valid parent.
By having incoming edges from one or more nodes in the prior region, the nodes in the newest regions now need to include references to their respective parent nodes. Line 22 applies a set intersection between all incoming edges to that node and the set of valid parents computed previously as we iterate over the nodes inside the most recent area. After all the new nodes have been filtered and have parental references, a new entry is added to the list of regions called
Before returning the newly created region, the prior regions are pruned and further refined using the set of obsolete parents to limit the object’s potential trajectory. The steps to iteratively prune outmoded nodes from the historical regions are described in the Algorithm 2.
Prune historical regions
As a moving object transitions from one uncertain location to another, the prior trajectory is refined by pruning the previous regions. As a result, the number of potential nodes that could represent the position of an object is reduced.
Utilizing regional presence and edge connectivity to manage uncertainty.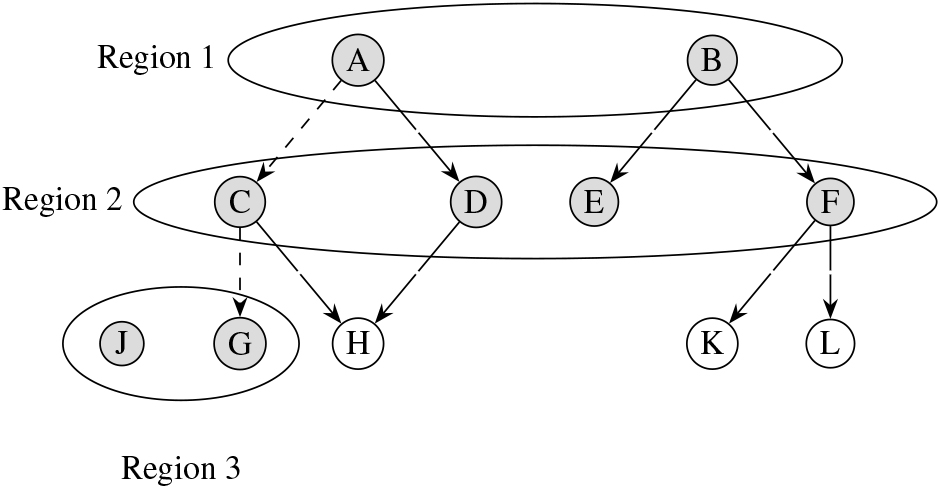
Figure 2 depicts the beginning state of the regions for an understandable explanation. The top level, where the first erroneous location was received, corresponds, and its nodes are highlighted in grey. Nodes from the following level are located in the following ambiguous region. It is significant to observe that the second-level nodes are not only connected to one another but also highlighted to denote their location within the area. There is now no need for pruning because every node in the region still has continuity with nodes in the prior region. Some nodes that retain continuity are marked in the final level; in this case, node
Using the Algorithm 6.1 described before, the nodes
[ht]
The process for iteratively trimming inactive nodes in earlier regions is described below. This function accepts a set of obsolete nodes
We start by eliminating all citations to the out-of-date nodes from the specified region. Then we determine if we are in the first region or the highest level by checking the base case. If the base case fails, we establish a fresh set of nodes that are no longer useful, which we shall populate before recursive pruning.
Then, we cycle through the nodes that are no longer relevant
To facilitate predictive queries, We employ a collection of prediction trees with nodes rooted in the most recent inaccurate region. The user-defined depth of the extended trees indicates how many steps in the future they intend to forecast. We continue to hone the predicting trees as the object travels along its trajectory and approaches the projected step [24].
As we receive location updates from the moving object, the pseudo-code outlined below assists in maintaining and updating the set of prediction trees (s). A set of uncertain regions
[ht]
To begin, we fill the lookup table PTrees with all of the p-tree nodes’ roots. Keep in mind that these trees indicate the predicative trajectories based on the erroneous position that was previously provided. Then, we compile all the nodes within the most recent ambiguous region. In line 3, we check to see whether rNodes is empty, which would indicate that this is the initial update. In that case, we would fill PTrees with all of the nodes that are currently accessible in the most recent region and expand them appropriately.
In line 9, a set of vNodes is populated if we are not on the first update. All nodes in the most recent area that are accessible from the prior region are included in this set. In other words, the only nodes that are taken into account as genuine are those that directly connect to the preceding ambiguous position. After that, we re-initialize PTrees and fill it with fresh p-trees rooted at each of the still-valible nodes inside the most recent doubtful zone. After that, PTrees is returned. Keep in mind that the user and the number of steps or time units in the future one may wish to predict movements rely on how the p-trees are expanded.
Query past locations
We define a recursive breadth-first traversal through the historical trajectories to query a set of possible trajectories the moving-object could have traveled through in algorithm 6.4. The algorithm takes in as input the past uncertain regions
The base case triggers if the region index is 0, meaning we are at the earliest known region the object is thought to be in; then, we return a list of the nodes in that region as ordered sets. This indicates that this is all we have for the trajectory of the moving object at the first uncertain region. If we are not at the earliest region, we acquire the historical trajectories for the previous regions recursively. Then for each of these trajectories, we append the nodes in the current region if they share edges between them. If a node from a given region shares edges with two previous nodes, then two trajectories with different end-point will be created; i.e. in line 11 of the algorithm, a copy of the past trajectory is created and the node in the current region is appended to the copy.
Figure 3 provides some background behind algorithm 6.4. Starting at region 3, we recursively move up to the first region and the trajectory would be
Set of historical regions.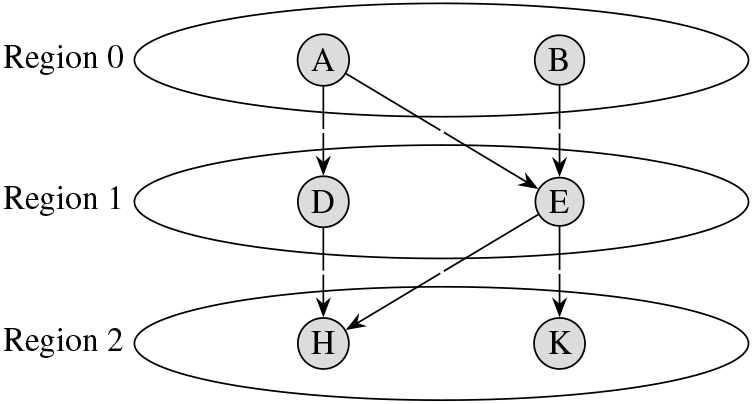
The algorithms and steps explored thus far allow UMove to refine past trajectories and decrease the degree of uncertainty. Using this information, in conjunction to the predictive trees, we can infer and answers queries about an object’s future movements. In algorithm 6.5, the steps to answer predictive queries under uncertainty using user-defined probability model are described.
We take in as input a probability model
Experimental evaluation
In this section, we examine the accuracy and efficiency of our work using experimental data derived from actual GPS trajectories from Chengdu, China.
Experimental setup
Taxi trajectory data from Chengdu, China, donated by DiDi Chuxing GAIA Open Dataset Initiative was used to conduct the research experiments [58, 59]. This dataset represented vehicle trajectory data gathered by Didi Chuxing in Chengdu, China.
For security concerns, the personal information included inside the data set has been processed anonymously.
Moreover, the dataset includes recorded car-hailing order information for end-user trips from 7-November-2016 to 13-November-2016 which represents 250k records of trips, sorted by the date-time. Indeed, trips with travel distances of less than 400 meters were trimmed from our tests. This dataset includes uncertainties such as inaccuracies in location due to GPS signal loss in urban canyons, multipath effects where signals bounce off buildings causing errors, and varying signal quality due to weather conditions or satellite positioning.
In this paper, the accuracy and performance evaluations are done. The objective of accuracy evaluation is to measure the correctness of an UMove. It specifically refers to the proportion of true results in the total number of cases examined. This evaluation relates to how accurately UMove produces the expected output given a set of inputs. On the other side, the objective of performance evaluation is to assess the overall effectiveness and efficiency of UMove. It can include measures like resource consumption, scalability, and robustness.
We used over 200k unique trips for accuracy evaluations and 50k trajectories for performance evaluations. The accuracy is measured in terms of location precision. The road network was implemented on top of a KD tree, and we used a decision tree for the predictive probability model. The algorithms were implemented in .NET Core and were run on a laptop with an i7-8550U and 8 GB of RAM.
Historical refinements and query processing
In this section, we explore the effectiveness of our work when it comes to managing past trajectories. We show how our work performs when handling uncertainty in the past and how this reflects on historical queries.
To measure the uncertainty of a given region, we look at how many nodes in that region serve as a possible location for the moving object. For our experiments, we only looked at the latest uncertain region as that is likely to be the most uncertain as regions farther in the past have gone through more steps of refinement as updates were received.
Managing historical locations.
In Fig. 4a, we see the number of nodes within a historical region decrease over time with more updates; this is due to the pruning of obsolete nodes and iterative refinement. And as updates are received we only consider nodes with continuous edges to previous regions. Even with uncertain regions with a radius of 75 meters, our solution on average narrowed down to one node where the moving object may have been.
For the accuracy measurements, we selected the trajectory returned by algorithm 6.4 that had the the highest probability. In Fig. 4b; the accuracy rates for historical queries in the latest region go up as we receive more updates. Even when querying regions with radius of 75 meters we are able to achieve a 91% accuracy rates after 4 updates due to the iterative pruning and refinement of historical trajectories.
Figure 5a illustrates the accuracy of predictive queries of varying steps in the future. The predictive queries were carried out for 1 to 5 steps in the future from an object’s latest region. The prediction model used was a decision tree. In 5b, the vanilla predictive tree’s performance under uncertainty is outlined.
Accuracy rates for predictive queries.
For regions with radius of 25 meters, UMove achieve on average 83% accuracy for 1-step predictions. With a region size of 100 meters, this drops down to 63%. The accuracy rate also suffers when we are predicting far ahead into the future because of the large number of leaf nodes in the predictive trees and the associated uncertainty. On the other hand, the vanilla predictive tree fails to reach above 50% for even 1-step prediction with regions of 25 meters.
To measure the resource overhead of our work, we take a look at memory consumption when dealing with many moving objects in parallel, we also consider the average time to prune historical regions, and build predictive trees with regards to the number of location updates and explore how the pruning process affects the overall performance and the handling of updates.
In Fig. 6 we compare the memory consumption between UMove and the vanilla predictive tree when maintaining 50,000 moving object trajectories with uncertain region size of 100 meters and predictive depth of 5.
Memory consumption for maintenance of 50,000 uncertain trajectories.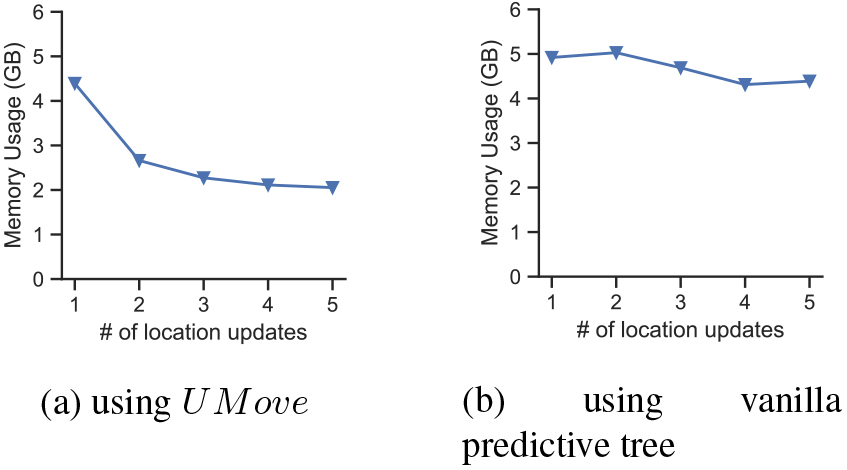
In Fig. 6a, UMove starts off consuming about 4.5 GB of system memory which then tapers off to around 2 GB as updates are received. This is due to pruning of obsolete nodes which eliminate historical uncertainty; this also allows for predictive regions with less noise which also effects the resource consumption. In Fig. 6a we see a slightly higher initial memory consumption but the numbers remain high for the lifetime of the moving object due to lack of pruning and high degree of uncertainty which requires more nodes which have to be accounted for.
In Fig. 7, we look at how the refinement process affects run-time and node distributions in the predictive regions; we describe the number of leaf nodes, and time taken to process location updates as more updates are received for predictive regions of different depth.
Relation between the time taken to rebuild predictive trees and number of nodes at the 
We measure the performance of UMove with predictive trees of different depths and explore how this varies as we receive updates. In Fig. 7a and b respectively, the number of leaf nodes and the time taken to process an update starts high which then tapers off to a constant as we receive updates. This is because initially, the degree of uncertainty is high. As we reduce the degree of uncertainty through pruning and refinement, with each update, the predictive trees become less ambiguous at the root thereby reducing the number of leaf nodes and time. For shallow predictive trees of depth one, we see the time taken to process an update remains around 30 microseconds. Region size has little impact at this stage. For trees with more depth, the initial time to process an update is quite high as is the number of leaf nodes. At this stage, region size seems to have an impact as well. However, after the second or third update, while the number of nodes and process time remains higher than the shallower trees, they taper off to a constant and the effect of the region is almost non-existent.
To sum up, the experiment results confirmed that the pruning and refinement algorithms are very effective at not just reducing uncertainty but also eliminating it and allowing for near-precise historical location queries. Moreover, the predictive queries achieve higher accuracy rates for lower predictive depths and region sizes. From the resource usage evaluations perspective, results provide that our UMove framework is efficient in memory consumption compared to state-of-the-art existing techniques and continue to improve with further pruning.
Conclusion and future work
In location-aware systems, managing the location of moving objects with inaccurate data continues to be a significant and difficult task. Additionally, as GPS-enabled devices proliferate, there is a greater demand for predictive analysis of moving items for applications such as location-based recommendation systems, marketing, ride-sharing services, and traffic management and forecasting systems. To manage moving objects’ past and future trajectories under uncertainty, this study suggests the UMove framework. Our method is scalable and effective since it can be refined iteratively to drastically reduce the number of nodes in an imprecise region. A thorough experimental evaluation of the suggested UMove framework’s correctness, effectiveness, and scalability using actual moving object trajectories has been conducted.
In future work, some factors must be considered; like parallel processing or distributed computing approaches for pruning algorithms to enhance the efficiency of UMove. A stress test and load test using JMeter, or Load runner can be done, and the test results report is shared in the results. Besides, other tests can be done that present different factors that will impact the UMove solution. Another point that can be addressed is interoperability and how external systems integrate with UMove to benefit from its features.