
Abstract
A threat to governments and the medical community globally are infectious illness outbreaks such as COVID-19, Spanish flu, and Ebola, which kill millions of people. Furthermore, because people are afraid to go to their employment, infectious diseases hinder economic progress. Therefore, it is imperative to implement interventions to lessen the spread of infectious diseases. From this angle, the practice of tracking contacts might be viewed as a mitigation strategy to stop the spread of contagious diseases. As this is going on, users’ trace data sets are growing exponentially larger over time, making it difficult to conduct contact tracing queries over them. In this paper, a novel Spark contact-tracing query processing method is proposed. This method determines if users are suspected cases by analyzing their paths based on two variables: nearby social distance and exposure time. Additionally, the developed method makes full use of the Spark framework to address scalability issues and effectively respond to contact tracing inquiries over a wide range of trajectories.
Keywords
Introduction
In December 2019, a significant Coronavirus disease (COVID-19) outbreak occurred primarily in Wuhan, China. As per the World Health Organization (WHO), COVID-19 is a highly contagious ailment that can affect many individuals globally. In response to the threat posed by the rare virus, the World Health Organization (WHO) issued a global emergency warning, urging individuals to adopt suitable preventive measures. According to a study conducted by the World Health Organization (WHO) in May 2020, it has been estimated that the COVID-19 pandemic has led to a mortality rate of 500,000 individuals, with an additional ten million currently grappling with the illness. The COVID-19 virus exhibits a high level of infectivity and possesses a relatively low threshold for transmission. Due to this rationale, governments across the globe implemented prolonged lockdown measures to curtail the transmission of the coronavirus. However, it is essential to note that these indicators have significantly impacted worldwide social and economic endeavors [1, 2].
The Spanish flu pandemic of 1918 caused a substantial loss of human life, estimated to be between 20 and 100 million individuals. This devastating mortality rate had profound economic consequences, leading to a notable decline in the Gross Domestic Product (GDP) in subsequent years. The COVID-19 pandemic is not the inaugural instance of a disease exerting a major influence on the overall well-being of the global population. The countries of Australia (3%), Canada (15%), the United Kingdom (17%), and the United States (11%) [3, 4]. In conclusion, the pandemic outbreak hinders economic growth and leads to immediate and lasting disruptions. The outbreak of the pandemic has resulted in significant changes in individuals’ behavior, notably inducing a sense of fear and apprehension towards attending work. Consequently, this fear has been observed to have a detrimental effect on productivity levels. The containment and mitigation of pandemic illnesses necessitate implementing rigorous measures and interventions. One strategy employed to mitigate the transmission of infectious diseases is the implementation of contact tracing. Additionally, governments and the medical industry use the contact tracing procedure to contain and monitor infectious disease outbreaks, locate their source, and implement efficient control measures. To enhance specificity, medical decision-makers can differentiate between contacts with high risk and those with low risk by initially examining the network of individuals who had been in contact with the infected patient during the disease’s incubation period. Semantic models of contact tracing enhance the examination of infectious behavior and potential transmission routes, thereby providing more accurate guidance for addressing significant pandemic challenges and administration. contacts. Besides, semantic models of contact tracing support the analysis of infection behavior and potential paths of disease spread which helps to make a better understanding of pandemic hot-spots, and reasoning, therefore these lead to accurate recommendations to tackle major pandemic issues and management.
This study proposes a methodology to identify individuals who may have been exposed to infected patients. Subsequently, based on the results of their examinations, these individuals can be categorized as either high-risk or low risk, prompting them to undergo the corresponding diagnostic testing. The proposed approach classifies individuals who encounter the infected patient into two distinct groups: (1) individuals who are close to the sick individual and (2) individuals who are in relative proximity. The observed sorting phenomenon can be attributed to two factors: (1) the length of time individuals was exposed to the stimulus and (2) their physical proximity to other individuals. Furthermore, this approach considers the incubation period as a crucial stage for contact tracing, wherein the identification and examination of all individuals who have been in contact with the infected individual are imperative. Moreover, this approach enables the tracking of both direct and indirect contacts [5, 6]. The goal of direct contact tracing, also known as first-order tracing, is to locate and monitor people in direct physical contact with the infected individual. It is recommended that these individuals be segregated from the broader populace and provided with specialized medical care. In the context of indirect contact tracing, also called iterative contact tracing, tracing is conducted iteratively (referred to as multi-level tracing), which entails examining the contacts’ contacts as well [5, 6].
The contact tracing procedure is initiated by gathering the trajectories of individuals who had close contact with the infected individual during incubation. The subsequent stage involves the method’s determination, based on the trajectories of which contacts have been potentially exposed to the infected patient and whether they satisfy the specified criteria for exposure time and social distance. The approach mentioned above provides the user with an alert containing information regarding suspicious contacts and their corresponding trajectories, prompting the user to engage in diagnostic testing promptly. The conventional methods for handling inquiries related to contact tracing prove inadequate due to their limited capacity to manage vast databases of trace records. To effectively manage the substantial volume of trace data, the proposed approach utilizes the GeoSpark [7]framework. GeoSpark is an extension to the Spark framework designed to conduct in-memory cluster computing. Its primary function is to enable the efficient analysis of vast quantities of spatial data. GeoSpark utilizes spatial data indexing components to partition the input Spatial RDD (Resilient Distributed Data sets) into grids and distribute these grids to multiple machines for parallel execution.
Contributions. We make the following contributions:
We develop a technique for addressing contact tracing inquiries over large data sets. We develop a method that differentiates between close contacts and proximate contacts who are exposed to the infected patient. We introduce two tracing modes; first-order tracing and iterative tracing to catch either low-risk contacts or high-risk contacts or both of them. We use GeoSpark as an in-memory cluster computing system to process enormous spatial data traces that are necessary for effectively responding to contact tracing inquiries. We confirm the scalability and interactive performance of the proposed solution by implementing a spatial data index (R-Tree) using Geo-Spark that divides the input Spatial RDD into grid segments using a grid structure and allots grids to machines for parallel processing. On actual datasets, we run thorough experiments. Experimental findings demonstrate that our approach accomplishes run-time optimizations.
Roadmap. The remainder of this paper is structured as follows. The previous research in the field of contact tracing is described in Section 2. The problem is properly defined in Section 3 together with all the foundational ideas. Section 4 details the suggested resolution. Our suggested solution is empirically assessed in Section 5. The paper is concluded in Section 6.
This section thoroughly examines earlier research on the contact tracing procedure. The three main topics covered in this paper are the value of contact tracing, contact tracing applications and unresolved issues in contact tracing procedures.
Importance of contact tracing
Various published studies have extensively examined the importance of contact-tracing mechanisms [8, 9, 10, 11, 12, 13, 14, 15, 16].
To identify potential cases of infection, various contact tracing techniques have been suggested in the literature, including random simulations and pairwise approximations, as discussed in [8]. These methods prioritize identifying and tracking individuals who have encountered each suspect during an investigation of disease transmission. This research establishes a significant correlation between the precision of contact tracing models and the disease reproduction ratio, thereby facilitating the identification and prompt treatment or isolation of infected and suspicious individuals by medical decision-makers.
The conceptual framework developed by [9], delineates the roles and responsibilities of individuals engaged in community monitoring initiatives to mitigate the transmission of the COVID-19 virus. The authors posit that implementing COVID-19 contact tracing and quarantine measures can effectively mitigate the spread of the disease through inhaling aerosolized droplets containing the virus, which are emitted through sneezing, coughing, or other means.
This paper elucidates the potential hazards associated with acquiring the Ebola virus. The transmission of the virus can occur via direct contact with bodily fluids that have been contaminated, with a particular emphasis on blood. Subsequently, the researchers examined the potential utilization of contact tracing to monitor individuals close to afflicted patients for 21 days. Consequently, a model of Ebola transmission was developed based on the contact-tracing process. Furthermore, this approach emphasizes the optimal timing for conducting contact tracing operations. The findings indicate that hospitalization and early contact identification can reduce the spread of an outbreak by 50 percent, in contrast to delayed identification, as reported in previous studies [10, 11, 12].
The authors delineate two models employing stochastic screening and contact monitoring as strategies to tackle the HIV pandemic. Two examples of models that demonstrate staged progression (SP) and differential infection (DI) are the staged progression model and the differential infection model. The DI model involves comparing individuals throughout the progression of disease transmission, while the SP model examines the temporal changes in affected individuals. The DI model demonstrates that the implementation of contact tracing strategies has the potential to decrease the overall magnitude of the epidemic by effectively isolating highly contagious individuals [13, 14, 15, 16].
In [17], analyze the effectiveness of contact tracing programs to identify their unique characteristics. The authors observed that the effectiveness of contact tracing within a community is contingent upon several variables, encompassing the prevalence of infected individuals, the frequency at which new cases undergo testing and isolation, the extent to which their contacts are traced and subjected to quarantine measures, the speed at which these contacts are isolated, and the efficacy of quarantines in curtailing subsequent transmission.
The predominant approach employed by various protocols and applications involves the utilization of forward tracing to notify individuals who have recently encountered confirmed cases. However, it is essential to note that contact tracing serves as the principal mechanism for mitigating the transmission of Covid-19. To enhance the management of outbreaks, the researchers in [18], propose a stochastic branching-process model that employs bidirectional tracking for the identification of individuals who have been infected.
Contact tracing applications and domain of use
Recently, there has been a notable emphasis on the expansion of contact tracing software to mitigate the spread of the illness. As a result, there has been an increase in the publication of scholarly works that put forth novel applications for contact tracing [19, 20, 21, 22, 23].
The Australian government has released a smartphone app called COVIDSafe [19, 20] in response to the global COVID-19 outbreak. The software provides timely notifications to individuals at risk of encountering the disease, enabling them to implement preventive measures proactively. In their study, the authors present cutting-edge peer-to-peer smartphone software, as described in [21], which enables contact tracing while preserving users’ privacy by abstaining from collecting personal information or location data. This application’s primary objective is to mitigate the transmission and proliferation of the COVID-19 pandemic effectively. The implementation of TraceTogether was initiated by the Singaporean government on March 20, 2020, to identify individuals who may have come into contact with patients diagnosed with COVID-19. Suppose a nearby user discloses their status as a COVID-19 patient. In that case, the application will promptly notify the Ministry of Health to facilitate the identification of individuals within their shared contact network who may be susceptible to the virus. This software employs Bluetooth technologies to locate individuals. Subsequently, the software establishes communication with said contacts and generates reports about the requisite subsequent actions [22].
In [24] have developed an advanced peer-to-peer smartphone application that effectively utilizes the capabilities of smartphone application technology for contact tracking. The authors emphasize the necessity of contact tracing as a strategy for managing the COVID-19 pandemic. The main aim of this study is to create a smartphone application for contact tracing that prioritizes privacy by refraining from gathering any personally identifiable information or location data from its users.
Background
The concepts related to the contact tracing method that will be employed in the remaining sections of the paper are presented in this section.
Overview
The contact tracing process is a tactic for monitoring and confirming the control of infectious illnesses. Additionally, since documenting the spread of infectious disease is this method’ primary goal, it begins by looking into previously identified cases and confirming their infection to anybody who recently had physical contact with the patients. Because of this, the spread of infectious diseases is reduced as a result of this procedure; like the COVID-19 epidemic [25, 26, 6, 27, 28, 29, 30, 31, 32].
The contact tracing process identifies two types of contacts that need to be tackled during the incubation period: high-risk contacts and low-risk contacts. The incubation period is the time from when someone is infected until symptoms develop. Indeed, the high-risk contacts are the closest contacts with the highest risk for infection, such as; household members and people who spend significant time together (meals, travel, work-spaces). While the low-risk contacts are asymptomatic people who are less infectious than people who develop symptoms.
Several parameters need to be measured along the contact tracing process, these parameters include: Risk of transmission, infection fatality ratio (IFR), Generation time, and Serial interval. Indeed, the Risk of transmission, is determined by; (1) Opportunities of infection to transmit (how many contacts do they have?), and (2) intensity of the contact (proximity, duration). While the IFR can be defined as the proportion of infected people who die. Moreover, the Generation time is the time from the infection in one generation to the time of infection in the next generation; for example, 5 days. This is a measure of how quickly the outbreak will grow.
Measuring the impact of contact tracing
The influence of the contact tracing technique is examined in this section.
Indeed, the Reproductive Number is used as an indicator that measures the impact of the contact tracing. More specifically, two parameters are used to evaluate the impact of contact tracing; (1) the basic reproductive number
The basic reproductive number
Basic reproductive number (
R0 example (10 cases infect 2.1 contacts)
Change from R0 to R as measure of impact.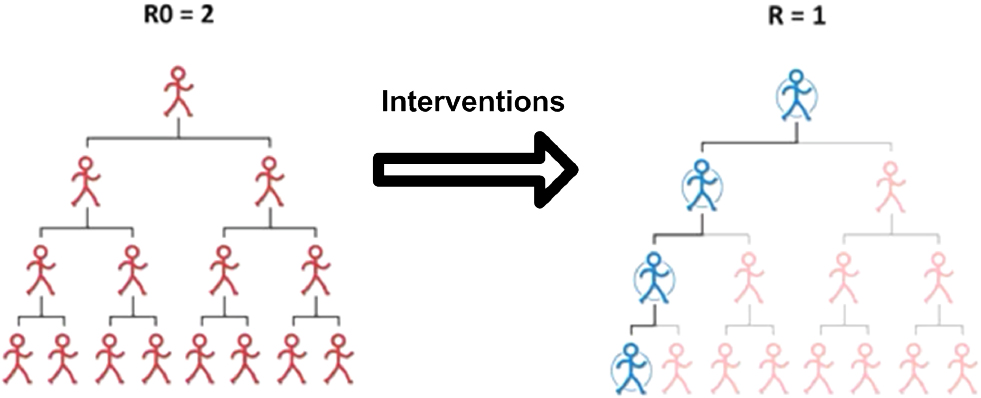
Reproductive number
This section presents the preliminary concepts that will be used throughout the rest of the paper.
Problem statement
This section presents the problem statement.
Given a tracing period
Range region.
This section presents the proposed solution for fetching a list of close and proximate contacts who are exposed to the infected patient and needs immediate diagnostic tests.
Main idea
The primary objective of this research is to identify and establish communication with all individuals who may have had contact with the infected individual during the incubation period. The individual initially assumes the role of the querying user by self-identifying as infected. Subsequently, the system initiates the retrieval of all movement trajectories linked to the individuals who had contact with the subject during the incubation period. In order to determine how close and for how long each person was exposed to the infected individual, the suggested solution analyzes the paths of each contact compared to the patient’s. After determining the proximity and duration of the contact, the solution can determine if the interaction qualifies as a potential case that necessitates immediate diagnostic testing. It should be noted that this service is specifically designed to handle contact tracing queries involving substantial amounts of contact data, with a focus on delivering prompt and precise responses.
Solution architecture
This section presents a detailed description of the proposed solution.
Solution architecture.
Utilizing the GeoSpark framework is crucial for effectively managing the storage and processing of extensive traces about infected patients and efficiently addressing inquiries related to contact tracing. GeoSpark utilizes a cluster computing platform to manage substantial volumes of geographic data effectively. By integrating GeoSpark into our proposed solution, we can address two significant challenges: storing extensive volumes of infected patients’ traces and efficiently handling contact-tracing requests. Given the substantial storage capacity of the underlying database, which can accommodate Petabytes of infected patient traces, it is evident that the proposed system can readily address the initial scalability obstacle. The second challenge involves providing an interactive performance wherein the queries related to contact tracing are promptly addressed within a time frame of less than one second.
Figure 4 depicts the GeoSpark architecture that is employed inside our proposed technique to answer contact tracing query, this architecture mainly consists of three major layers: (1) Apache Spark Layer, (2) Spatial Resilient Distributed Dataset (SRDD) Layer, and (3) Spatial Query Processing Layer.
Apache Spark Layer. The responsibility of the Apache Spark Layer is to provide the operations and functions that handle natively the tasks of loading/saving user’s traces from/to persistent storage. Unfortunately, Apache Spark layer as a standalone layer does not provide support for geometrical data and operations. Hence, GeoSpark comes with extra two layers to support the processing of large-scale spatial data and operations in Apache Spark. In this regard, GeoSpark provides a novel data abstraction to support geometrical and distance operations called spatial resilient distributed datasets (SRDDs) [33]. Indeed, SRDDs are collections of objects partitioned across a cluster of machines.
Spatial Resilient Distributed Dataset (SRDD) Layer. In this work, the proposed technique utilizes this SRDD Layer in indexing the trace data of the infected patients (SRDD Indexing) for fast retrieval, SRDD Indexing is performed using the R-Tree index. The index was built by balancing the query selectivity, indexing overhead (memory and time), and the quantity of spatial objects. Earlier, SRDD It is necessary to index an SRDD Partitioning phase. Partitioning SRDD, SRDD By establishing a global grid file for data partitioning and assigning each element in an SRDD to the same 2-Dimensional spatial grid space, one may partition all saved/loaded SRDDs. Finally, the proposed technique explores the power of the Spatial Query Processing Layer in providing a set of geometrical operations in identifying the boundaries around the infected patient’s trajectory and also in identifying the larger area that other nearby trajectories of other objects move inside as shown in Fig. 3. The boundaries identification is done through calling a function named MinimumBoundingRectangle() which is responsible for finding the minimum bounding rectangle for each infected object trajectory SRDD and finds a large minimum bounding rectangle that contains all of the other internal objects moving a nearby infected object. The large minimum bounding rectangle is commuted by adding
Spatial Query Processing Layer. This work utilizes the Spatial Query Processing Layer in performing spatial data queries that serve the answering finally of the contact-tracing query. First, the proposed technique runs the range query to get all trajectories of objects that fall inside the large rectangle in Fig. 3. After that, the proposed technique performs a distance join query between query object’s trajectories and other trajectories that fall in the large rectangle, if they overlap each other within
Contact tracing query processing steps.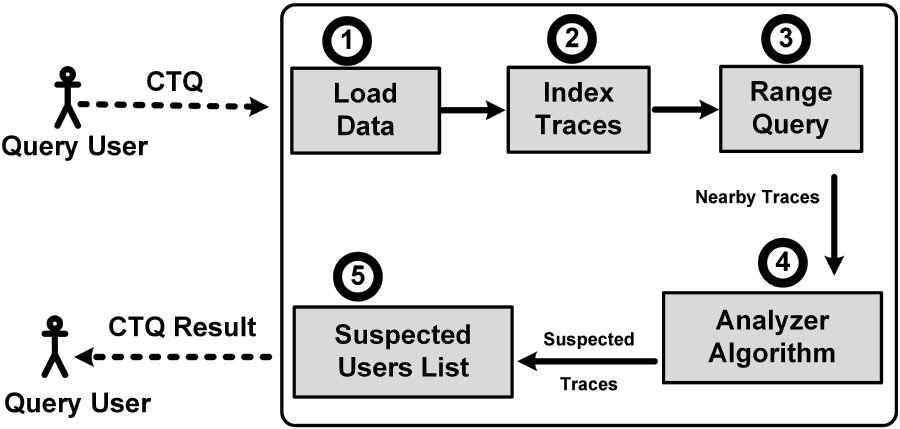
Figure 5 depicts the contact tracing query processing steps. First, the input to the system is the contact tracing query, the query date/time, and the user id. Second, the system gets all the traces that belongs to the querying user who poses the query, the traces are captured by the user id. Indeed, the traces are retrieved from the current query date/time to 14 days before the query date, in this work 14 days represents the incubation period of COVID-19 disease. After that, the system gets all traces of other individuals moved with the querying user within the period from the current query date/time to 14 days before the query date. All these traces are loaded to the GeoSpark memory for processing. Then, these traces are indexed using R-Tree [34] for fast retrieval. Furthermore, the system performs a range query to retrieve traces moved with querying users within a close area. Hence, these traces are inspected according to Algorithm 5 which will be explained in detail in Section 5.3. In the final step, the result of the query is a list of the traces of all suspected individuals.
From the privacy perspective, in this work, there is no store of any sensitive data like (name, address or social security number) related to the users that are traced during the contact tracing process, only User_Id for each user is used to link the user stored in the system with each trajectory.
The proposed inquiry illuminates significant concerns about the geographical location of data storage and the duration for which data is retained. The system retains users’ traces for 14 days, beginning when the trace file is generated. This temporal interval aligns with the recognized incubation period associated with the COVID-19 illness. Traces are recorded as flat files containing pairs of location data and corresponding timestamp values. When the system receives a contact tracing query (CTQ) from an infected patient (querying user), it initiates the collection of all relevant traces. These traces are then loaded into GeoSpark’s in-memory storage for use during the query processing phase. The contact tracing procedure is subsequently initiated on the loaded traces, producing the response to the CTQ as an output. The traces remain stored in memory as long as the time difference between the start DateTime and finish DateTime of the querying user is more significant than zero. In the subsequent section, we will delve into a comprehensive examination of the mechanism by which the system retrieves the interconnected traces associated with the inquiring user and the intricacies of the contact tracing process.
[t]
The primary algorithm that explains the whole functioning of the suggested solution is illustrated in this section. The three main steps of the suggested solution are briefly outlined as follows:
Step1: Set Boundaries for Query Object’s Trajectory. This phase entails the determination of an encompassing region around the trajectory of the query object, allowing for the easy acquisition of alternative trajectories within this area. The initial reference points for this enclosure are the point of origin and the final destination of the inquiring individual’s or object’s voyage, respectively. Subsequently, the coordinates mentioned above constrain the search object’s trajectory. The inner rectangle in Fig. 3 presents this step.
Step2: Recognize the Range Query Region. The next step is to expand the area around the path of the object being searched by adding the distance to all sides, resulting in a new, larger area that makes it easier to find all nearby items quickly. It is also important to carefully check all the paths within this area. The outer rectangle in Fig. 3 describes this step.
Step3: Extract Suspected Objects. All trajectories within the zone that Step 2 created are now part of the solution. Next, the overlapping distance is measured, and then the duration spent during that period is assessed. To do this, run a distance join operation between the query item’s trajectory and all other trajectories in the Step 2 area. Obtaining close contacts, either nearby or both, involves performing a distance join using two specified distances. The term “proximity distance identified” is utilized to ascertain the appropriate distance threshold for joining nearby contacts. In contrast, the term “thereabout distance identified” is employed to determine the distance threshold for joining even closer connections. Ultimately, the system will designate the object following this trajectory as a potential contact and alert the individual to conduct diagnostic tests if the duration of overlap between the object and the identified exposure time is equal to or exceeds the specified threshold. Additionally, the system will verify the successful integration of the retrieved trajectories with the query object through approximate or close proximity distances.
Pseudocode in Action. Algorithm 5 shows the proposed pseudo-code for the contact tracing solution. There are three input parameters for the algorithm, (a) Tracing Period
The algorithm returns a list of all suspected contacts either close or proximate contacts or both. First, the algorithm considers the query date as the date that will start tracing from it, so based on the query date and tracing period parameter, the algorithm identifies the start tracing date and end tracing date (lines 15–16). Then, the algorithm starts to iterate during the tracing period from start-tracing-date to end-tracing-date, in each daily date, the algorithm gets all trajectories that belong to the query object and other trajectories that belong to other objects located inside the range region on this day (lines 17–28). After that, the algorithm iterates over the query object’s trajectories retrieved on each tracing day, and started to investigate it against other trajectories moved with the query object on this day. The algorithm defines two types of distance to get close and proximate contacts, first
Moreover, the algorithm utilizes
Experiments
This section conducts an experimental analysis of our suggested solution and presents the findings.
Experimental environment
Dataset
The experiments carried out in this study primarily make use of a data set that is synthesis data gathered on real data set UJIIndoorLoc [35], which describes the indoor movements of human interactions inside the University of Jaume building. This data set consists of 1.1 billion records, each of which has the following characteristics: (1) Longitude, (2) Latitude, (3) Floor; which explains the altitude inside the building, (4) Building_Id; to identify the building, (5) Space_Id; to locate the area (office, corridor, classroom), (6) Relative position concerning space, it holds two values inside and outside (in front of the door), (7) User_Id; which denotes a special user identification, (8) Phone_Id; This is the identifier for the Android device and (9) Timestamp; which indicates the time the capture is made. These records show the user footprints inside the facility. These footprints come from
Environment settings
The GeoSpark cluster consists of eight worker nodes, each equipped with eight Intel Xeon Processors and 50 GB of registered RAM. Spark and Hadoop utilize these resources for implementation. All the modules encompassed within the Eclipse Intellij IDE are exclusively Java-based. Each test is run on a computer with a Windows 10 operating system, an Intel (R) Core (TM) central processor unit, and 32 gigabytes of random access memory.
Experimental assessment
We then present our results.
Exp1: Impact of Scalability using GeoSpark. As shown in Fig. 6, this experiment compares the GeoSpark against SpatialHadoop with respect to the increasing number of nodes in the cluster, the experiment runs the same range query over a big data-set of size 60 GB. SpatialHadoop [36] is a framework for Hadoop that supports spatial data; it enables users to run spatial SQL queries and conduct spatial operations, but it does not offer a thorough approach to query optimization. The cluster’s nodes are represented by the x-axis, and the time spent is shown on the y-axis. Overall, it is shown that expanding the cluster’s nodes will aid in cutting down on the total amount of time used. Also, it is observed that the GeoSpark consumes around 0.25 time consumed by SpatialHadoop in processing spatial queries. This is justified by the fact that GeoSpark loads the dataset containing the SRDDs from the storage system and cashes them in memory, enabling several memory-based spatial operations to be carried out over the SRDDs.
Impact of scalability using GeoSpark.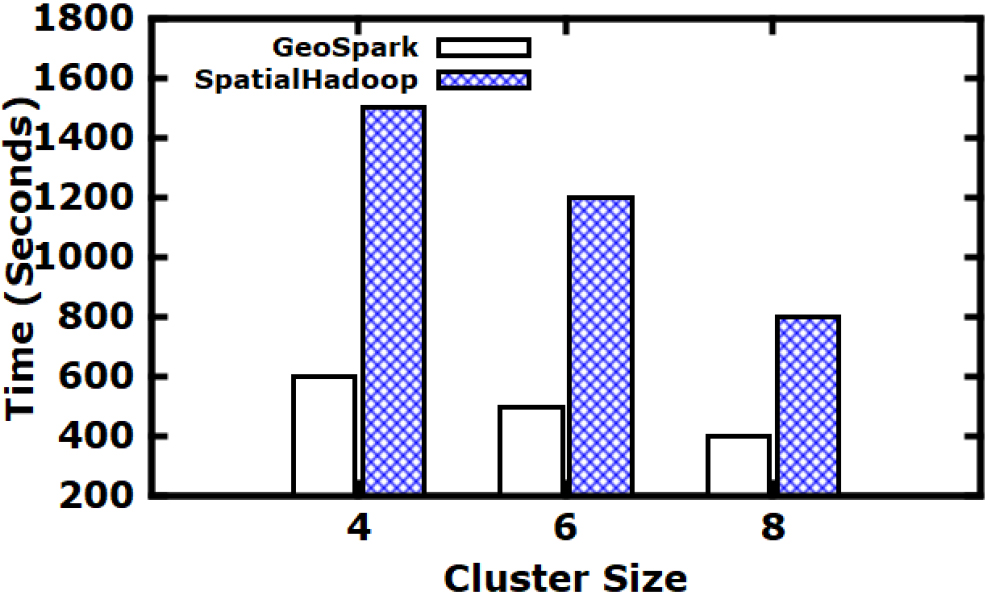
Exp2: Impact of Spatial Partitioning. In order to speed up a spatial join query, the fundamental goal of Spatial RDD (SRDD) partitioning is to group spatial items into the same partition based on their spatial proximity. This experiment measures the effect of various spatial partitioning types on range join queries using GeoSpark. Three distinct spatial partitioning techniques – KDB-Tree partitioning, Quad-Tree partitioning, and R-Tree partitioning – are compared in Fig. 7. On join queries, it was found that the KDB-Tree partitioning method consumed the least amount of local join time (KDB-LocalJoin), but that the QUAD-Tree and R-Tree methods both consumed additional time at rates that were 2.5 and 1.7 times slower than the KDB-Tree method, respectively. The reasoning behind this is that, compared to R-Tree and Quad-Tree portioning methods, KDB-Tree partitioning provides more load-balanced grid cells. Additionally, R-Tree does not always cover the entire space, and overflow data partition can happen [37, 38, 39].
Impact of spatial partitioning.
Exp3: Impact of Distance Join on Memory Usage. In this experiment, Fig. 8 evaluates the performance of spatial join queries concerning the proximity distance
Impact of range queries on memory utilization.
We next report our findings.
Exp4: Impact of varying
Impact of varying 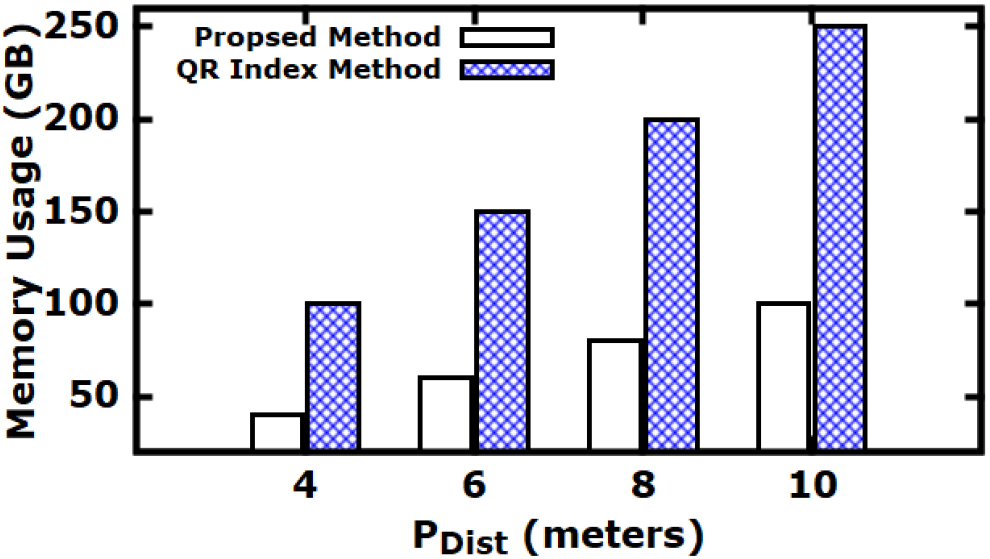
Exp5: Impact of varying
Impact of varying 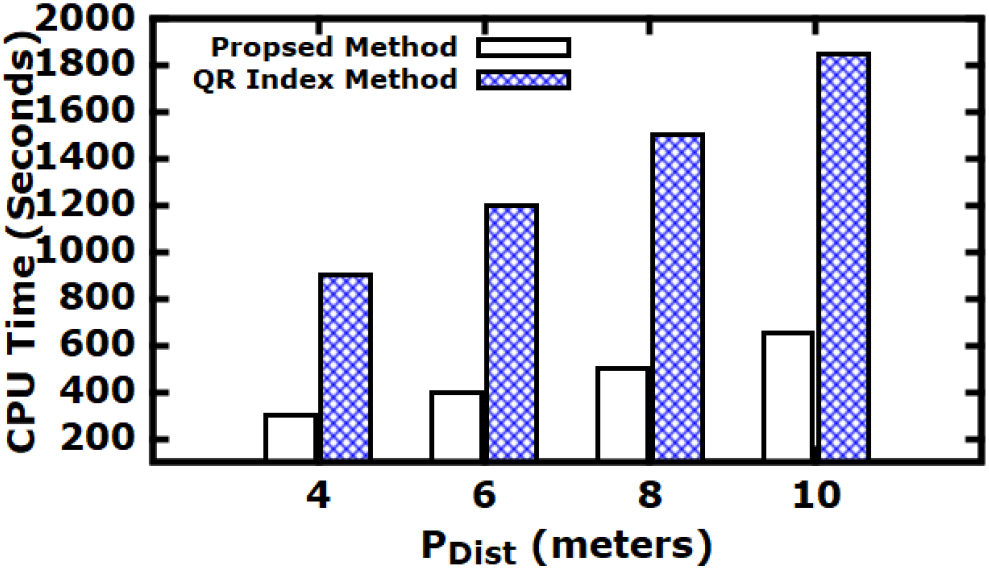
This research addresses the problem of the outbreak of infectious diseases, and how the interventions like contact tracing strategies can help in fighting the spread of these diseases. This research suggests a novel method to accomplish this goal, one that assesses contact tracing queries (CTQ) to identify all conceivable contacts who may have been exposed to the infected patient throughout the incubation period. More specifically, this technique starts the investigation process by getting the trajectories of contacts that moved in the same time and region with the infected patient, then inspects them against two factors; (1) exposure time, and (2) proximate social distance. By employing Apache Spark, the proposed technique can process CTQ over many trajectories and promptly return answers. The proposed technique’s effectiveness and scalability are demonstrated through experimental evaluation using large real data sets. Finally, the results discussed in the experiments section describe how the proposed system maintains scalability while contacts increase with optimizing performance overheads.