
Abstract
Abstract
This paper aims to incorporate a knowledge discovery technique into the Proximity-based Logic Programming paradigm in order to generate background knowledge (conceptual hierarchies) in a semi-automatic way which may lead to an efficient and desirable abstraction process among the symbols (representing concepts) from a first-order language and to the discovery of generalized relationship among them i.e. a logic-based framework with the capability of abstraction. This method makes use of the concept of λ-block characterizing the notion of equivalence when working with proximity relations. When the universe of discourse is composed of concepts which are related by proximity, the sets of λ-blocks extracted from that proximity relation can be seen as hierarchical sets of concepts grouped by abstraction level. Then, each group (forming a λ-block) can be labeled, with user help, by means of a more general descriptor in order to simulate a generalization process based on proximity. Thanks to this process, the system can learn concepts that were unknown initially and reply to queries that it was not able to answer. The novelty of this work is that it is the first time a method, with analogous features to the one aforementioned, is implemented inside a fuzzy logic programming framework. Certainly, in order to check the feasibility of the method, we have developed a software tool which have been integrated into the Bousi~Prolog system. Finally, this work presents a method to get a set of recommended abstract descriptors by using WordNet. This allows to improve the original generalization mechanism, helping the user in the task of selecting a convenient abstraction. Also, the overall method can be seen as a technique that facilitates the tuning of term ontologies.
Keywords
Introduction
A problem in many contexts, from science to everyday life, is to construct meaningful classifications of observed objects or situations. Such classifications facilitate human comprehension of the observational objects. Nowadays, this is a big problem because there exist settings (databases, knowledge-based systems, ontologies, complex graphs) in which it is required a large amount of data and knowledge to work successfully. Therefore, the construction of meaningful classifications can be an important feature in those frameworks in which the comprehension is mandatory in order to get a better use. Therefore, new research domains, such as data mining, data summarization and knowledge discovery have raised the interest of databases community [24]. On the other hand, experience has shown that a purely knowledge-driven approach, with the aim of formalizing problem-relevant human expert knowledge, is difficult, intricate and tedious. Indeed, it has shown that the traditional knowledge-driven approach can be completed by a data-driven one in a reasonable way [13]. One of the most important data-driven techniques is the Attribute-Oriented Induction (AOI, for short) [7].
AOI is a technique that allows classifications or abstractions from original data. This process consists of grouping of data, enabling hierarchical transformation of similar item-sets stores originally in a database at low level, into more abstract conceptual representations. It allows a better understanding of the source attribute-values into a generalized relation. Generalization of data records in the AOI approach is performed on an attribute-by-attribute basis, applying a separate concept hierarchy for each of the generalized attributes included in the relation [1]. The hierarchical character of induction provides analysts with the opportunity to view the source of information at multiple levels of abstraction, allowing them to progressively discover interesting data aggregations. For example, given the data set {“Sweden”, “Denmark”, “United Kingdom”, “Germany”, “France”, “Italy”, “Spain”, “Portugal”}, it can be performed a generalization process such that the original set is divided in the subgroups {“Sweden”, “Denmark”, “United Kingdom”}, {“Germany”, “France”} and {“Italy”, “Spain”, “Portugal”}, attending to a location criterion, and then, respectively assign them the more general descriptors: “Northern Europe”, “Western Europe”, and “Southern Europe”. Finally these concepts, in the new abstraction level, are also grouped and the more general descriptor “Europe” is assigned to the new aggregation.
In order to get a more flexible representation of real life dependencies fuzzy partitions and hierarchies were proposed. In particular, these were applied (together with linguistic variables) to tuples summarization in different ways [5, 32]. A fuzzy hierarchy reflects the degree with which a concept belongs to its direct abstract. In addition, more than one direct abstract of single concept is allowed during fuzzy induction. For example, given the data set {“emacs”, “vi”, “word”, “wright”, “excel”}, once again, it can be divided in the subgroups {“emacs”, “vi”}, {“vi”, “word”}, {“wright”, “excel”} and then performed a generalization process by assign them, attending to its utility, the more general descriptors: “text editor”, “word processor”, and “spreadsheet”. Note that, in this example, “vi” may belong to more than one subgroup, and with a membership degree different to 1.0; for example, “vi” ∈ “text editor” with 1.0 and “vi” ∈ “word processor” with 0.3.
Additionally, AOI was applied to the discovery of abstract knowledge in fuzzy relational databases. In that work similarity classes were used as grouping units and the hierarchy are defined by an expert. This process can be seen as a generalization process from the mined data selected according to a proximity-based criterion [1].
In this work, we aim to extend the scope of this mechanism and transfer it to a fuzzy logic programming framework that works with proximity relations 1 allowing the discovery of concepts starting from the proximity λ-blocks which characterize this kind of fuzzy relations (see Section 1).
The paper is organized as follows. Fuzzy Logic Programming is introduced in Section 2. The mathematical principles of proximity-based hierarchy are presented in Section 3. A Generic Approximation for the incorporation of Attributed-Oriented Induction technique in the Fuzzy Logic Programming paradigm is detailed in Section 4. The design and implementation of the KD∼Bousi software tool, which implements the generic approximation explained in the previous section, is explained in Section 5 and finally, we give our conclusions and future research lines in Section 6.
Proximity-based Logic Programming
Logic Programming is a declarative programming paradigm well suited for knowledge representation and the inference of new knowledge from old one. However, logic programming does not allow to represent and to manage vagueness in a natural way due to the lack of specific tools and, particularly, by its rigid query answering process. Moreover, Logic Programming is too rigid to model human perceptions. For example, imagine the following situation: someone tells us –“I like black women with light eyes”. On the other hand, I would know, hear or read that “Rihanna is a brunette girl with green eyes”, hence I could reason that this person likes Rihanna, however Logic Programming is not capable of inferring this same conclusion i.e. Logic Programming says “No.”, when it should say “yes”, “probably” or “maybe”. The main reason is that perceptions come from different people i.e. each person expresses his/her feelings and perceptions in a different way (although they are referring to the same things). Perceptions are represented by means of the words and sentences of natural language. However, natural language is vague, ambiguous and imprecise.
The first idea was to employ Fuzzy Logic [33] to enhance Logic Programming [18, 25], since fuzzy logic has been used to deal with vagueness and/or imprecision.
There is a vast number of proposals that study the integration of Fuzzy Logic into Logic Programming, but we can summarize them in two main lines of work: Extensions of Resolution and New Inference Mechanisms [10, 30] and Extensions of Unification [12, 29]. The first line of work has produced annotated logic programming languages which employ weights to deal with vagueness and imprecision. The second one has led to non-annotated logic programming languages adding fuzzy equations to the crisp facts, rules and goals (e.g: brunnete∼black=0.9). From a linguistic point of view, weights are not adequate because they are not presented in a natural language, nobody would say: “Rihanna is black with 0.7” or “Rihanna has light eyes with 0.7.” or “I like Rihanna with 0.4.”. On the other hand, extending unification implies that facts, rules and goals are non-annotated and hence the treatment of vagueness and imprecision can be performed in a more transparent way, circumscribing annotations to the body of proximity equations. This is an important feature when we want to treat perceptions and words in a linguistic way and, certainly, this was one of the aims that motivated the apparition of Proximity-based Logic Programming [15, 16 28].
A practical realization of this approach is Bousi~Prolog 2 [14], a fuzzy logic language where the classical unification algorithm used in logic programming has been replaced by a new algorithm based on proximity/similarity relations. Hence, its operational mechanism is a variant of the SLD resolution rule introduced in [25]. We have studied how to apply Bousi~Prolog for: flexible query answering, advanced pattern matching [28], information retrieval, where textual information is selected or analyzed using an ontology, text cataloging [26], flexible data bases, knowledge-base systems or approximate reasoning [28]. The following example helps to understand the main aspects of the syntax and semantics of this language.

In a standard Prolog system, if we ask about whether
However, it is sometimes possible that a problem is not completely modeled or it cannot respond to the requirements of the users. For example, in a database about people’s names and eye’s color, it would be reasonable to ask about people with “light” eyes. Therefore, if we ask about it, “?.-is_a(X,person), eye_color(X,light)”, the system fails. This is because the concept ‘light” is missing from the original set of proximity equations. A possible solution is to write down one by one each proximity equation establishing a relationship between each specific color and a generalized concept. But, if the number of equations is very large then it becomes a serious problem. On the other hand, the concept “light” is not the same for any user. Therefore, it is important to count on a mechanism which allows us to generate a set of generalized concepts from a set of specific ones. For example, fuzzy grouping “blue”, “green” and “gray” as ‘light”. In fact, relating concepts by their meaning, opens the door to managing linguistic phenomena based on those fuzzy relations. There are four types of fuzzy relations between concepts according to [27]: Positive fuzzy association ( synonymy) relates the concepts that have a similar fuzzy meaning in some contexts (for example, person → individual); Negative fuzzy association is a kind of antonymy which relates the concepts that are fuzzy complementary antonyms (for example, male → female, big → small); fuzzy generalization or generality is the selection of a concept, whose meaning includes another concept, as the generalization of that concept (for example, vehicle → car); Fuzzy specialization is the inverse of fuzzy generalization, this is to say, the choice of a concept which is a part of another one (for example, car → vehicle). In this work the spotlight becomes focused on the fuzzy generalization of concepts.
In a proximity/similarity-based logic programming framework, because of the use of proximity equations in order to relate concepts, we can extract new generalized knowledge from those proximity equations. To be specific, we are interested in the automation of this generalization process. Therefore the aim of this paper is to present a proximity-based generic method for the discovery of generalized knowledge in the framework of a fuzzy logic programming language with a weak unification procedure that uses proximity equations to model closeness, vagueness and/or imprecision. More precisely, we want to implement this method and to integrate it within the Bousi~Prolog system.
Providing the Bousi~Prolog system with this ability improves its operational mechanism, supporting inductive learning of new concepts and, hence, the power to infer new knowledge that the system was unable to infer initially. Then, this is an additional step towards the goal of consolidating Bousi~Prolog as a true programming language for soft computing, in general, and computing with words, in particular, since the generalization process is part of ordinary reasoning and a system aiming at to fit the computing with words agenda should manage these cognitive processes.
Proximity-based Hierarchy
In order to incorporate the attributed-oriented induction technique into the fuzzy logic programming paradigm we are going to propose a method which allows to generate a hierarchy of cluster in an automatic way i.e. performing a proximity-based clustering. This is based on the concept of λ-block characterizing the notion of equivalence when working with proximity relations. We obtain a proximity-based hierarchy which is representing the necessary background knowledge for the generalization process.
Note that, this hierarchy suggest a sequence of mappings from sets of concepts related by proximity to their corresponding higher level general descriptors and it is usually partially ordered from a general to specific ordering with the most general concept, usually defined by any reserved word, on the top of the hierarchy and the most specific concepts on the bottom of the hierarchy. We start defining some essential concepts on fuzzy relations.
A binary fuzzy relation on a (crisp) set U is a fuzzy subset on U × U (that is, a mapping U × U ⟶ [0, 1]). If cR is a fuzzy relation on U, the λ-cut cRλ = {tuplex, y ∣ cR (x, y) ≥ λ} (which is an ordinary relation on U). There are some important properties that fuzzy relations may have:
A proximity relation is a binary fuzzy relation which is reflexive and symmetric. A proximity relation is characterized by a set Λ = {λ 1, …, λ n } of approximation levels. We say that a value λ ∈ Λ is a cut value. A special, and well-known, type of proximity relations are similarity relations, which are nothing but transitive proximity relations. There exists a close relation between similarity relations and equivalence relations: the λ-cut of a similarity relation cR on U, cRλ, is an equivalence relation on U. Proximity relations are more complicated in this regard. For a proximity on a set U, the notion of equivalence class splits into two different concepts: the blocks and the classes of proximity. Given a proximity relation cR on a set U, a proximity block of level λ (or λ-block) is a subset of U such that the restriction of cR λ to this subset is a total relation, and maximal with this property. The effective computations of λ-blocks in a proximity relation is a difficult matter which is linked with the problem of finding all maximal cliques on an undirected graph [6]. However, several solutions have been proposed to solve it, for example we can cite [23].
On the other hand, the proximity class of level λ (or λ-Class) of an element x ∈ U is the subset cK λ (x) = {y ∈ U ∣ cR (x, y) ≥ λ} of those elements of U that are approximate to x (at a certain level λ). Note that, for the special case of a similarity relation, λ-blocks and λ-classes coalesce. Hence, in this case λ-blocks can be computed efficiently by computing the corresponding λ-classes. The following example illustrates the concept of λ-block in a proximity relation.
On the other hand, the classes of level 0.5 for each one of the elements are:
In this paper we are interested in proximity relations on syntactic domains representing concepts. When the universe of discourse is composed of concepts which are related under a particular abstraction criterion, a proximity relation can model the closeness of this concepts. Then, the sets of λ-blocks extracted from that proximity relation can be seen as sets of concepts grouped by abstraction criterion that form a hierarchy of abstraction levels. Then, each λ-block can be labeled by way of a more general descriptor in order to simulate a generalization process based on proximityrelations.
On the other hand, proximity measures can be automatically constructed by using Restricted Equivalence Functions (REFs) [2, 3]. REFs are very useful because they do not require the transitivity property. REFs have been employed in image processing, for example in order to obtain sequences of optimal thresholds in images with several objects [4].
More formally, a restricted equivalence function, f, is a mapping [0, 1] 2 ⟶ [0, 1] which satisfies the following conditions [2]:
f (x, y) = f (y, x) for all x, y ∈ [0, 1]
f (x, y) =1 if and only if x = 1
f (x, y) =0 if and only if x = 1 and y = 0 or x = 0 and y = 1
f (x, y) = f (c (x) , c (y)) for all x, y ∈ [0, 1], c being a strong negation. For all x,y,z ∈[0, 1], if x ≤ y ≤ z, then f (x, y) ≥ f (x, z) and f (y, z) ≥ f (x, z)
For example, g (x, y) =1 - |x - y| satisfies conditions (1)-(5) with c (x) =1 - x for all x ∈ [0, 1].
We can use REFs to automatically tuning proximity relations from the source equations defined by the users. With this aim, we have incorporated REFs as an option in the process of construction of a proximity-based hierarchy.
Certainly, we have implemented a technique based on REFs as part of the KD∼Bousi tool (see Section 5).
This inclusion provides us with two important benefices: (i) it allows us to generate new knowledge i.e. new proximity equations; (ii) it can be employed to generate additional proximity-based hierarchies allowing us to provide users with more alternatives.
In order to incorporate and implement REFs into our framework, we need to introduce the concept of proximity equation combination. This operation which is based on REFs is defined as follows.
Let cU be a syntactic domain. Given two proximity equations E
i
≡ x ∼ y = α
1 and E
j
≡ z ∼ w = α
2 with x, y, z, w ∈ cU and α
1, α
2 ∈ [0, 1]. The combination of two proximity equations E
i
and E
j
is a new proximity equation E
k
such that: if y = w then E
k
≡ x ∼ z = β; else if z = y then E
k
≡ x ∼ w = β; else if x = w then E
k
≡ y ∼ z = β; else if z = x then E
k
≡ y ∼ w = β.
where β = g (α 1, α 2) = (1 - |α 1 - α 2|). The operation of combination applied to a set of proximity equations allows us to obtain a set of equations based on REFs. These equations can be added to the original set. As result we obtain an extended set which can be used to generate a new proximity-based hierarchy.

A generic approximation
The management of a generalization process in the context of a fuzzy logic language based on weak unification pass through representing generalization in an explicit way by means of the addition of specific proximity equations. On the contrary, some difficulties may arise when launching queries where a generalization process is involved. For instance, considering Example 1, if we ask about people with “light” eyes, the system is unable to answer that query because the generalized information that green, blue or gray eyes are light eyes was notmodeled. A solution to this problem, as we are proposing, would be to produce the additional proximity equations by means of a semi-automatic generalization process able to classify concepts into groups on the basis of user choices identifying each concept with a more general descriptor.
In the sequel, we propose a method to handle the generalization process in the context of a proximity-based logic programing language. In order to do that, it is necessary an algorithm that could obtain proximity λ-blocks. Informally, a step by step definition of the method is as follows:(i) start from a set of proximity equations (defined by a user or taken from a thesaurus); (ii) generate a proximity or a similarity relation to suit; (iii) execute the algorithm to generate proximity λ-blocks 4 ; (iv) the concepts grouped by λ-blocks which are susceptible to generalization are labeled by means of a unique abstract descriptor identifying each one among the others (this step needs human intervention); (v) new proximity equations are generated, relating this new abstract descriptor with each element belonging to the generalized set described by that descriptor, thus completing a hierarchy level; (vi) the new set of proximity equations, characterizing a hierarchy of concepts, are loaded into a fuzzy logic programming system based on weak unification. Then, these new concepts can participate in the inference process allowing the programmer to launch queries on concepts that were initially unknown for the system and that have been generated semi-automatically.
The formalization of this method is detailed in the following. First, we define the Algorithm 1 that automatically computes a hierarchy of concepts from the set of proximity equations. This algorithm makes use of a function called generateProximityBlocks (Algorithm 2) which generates all blocks of a certain approximation level.

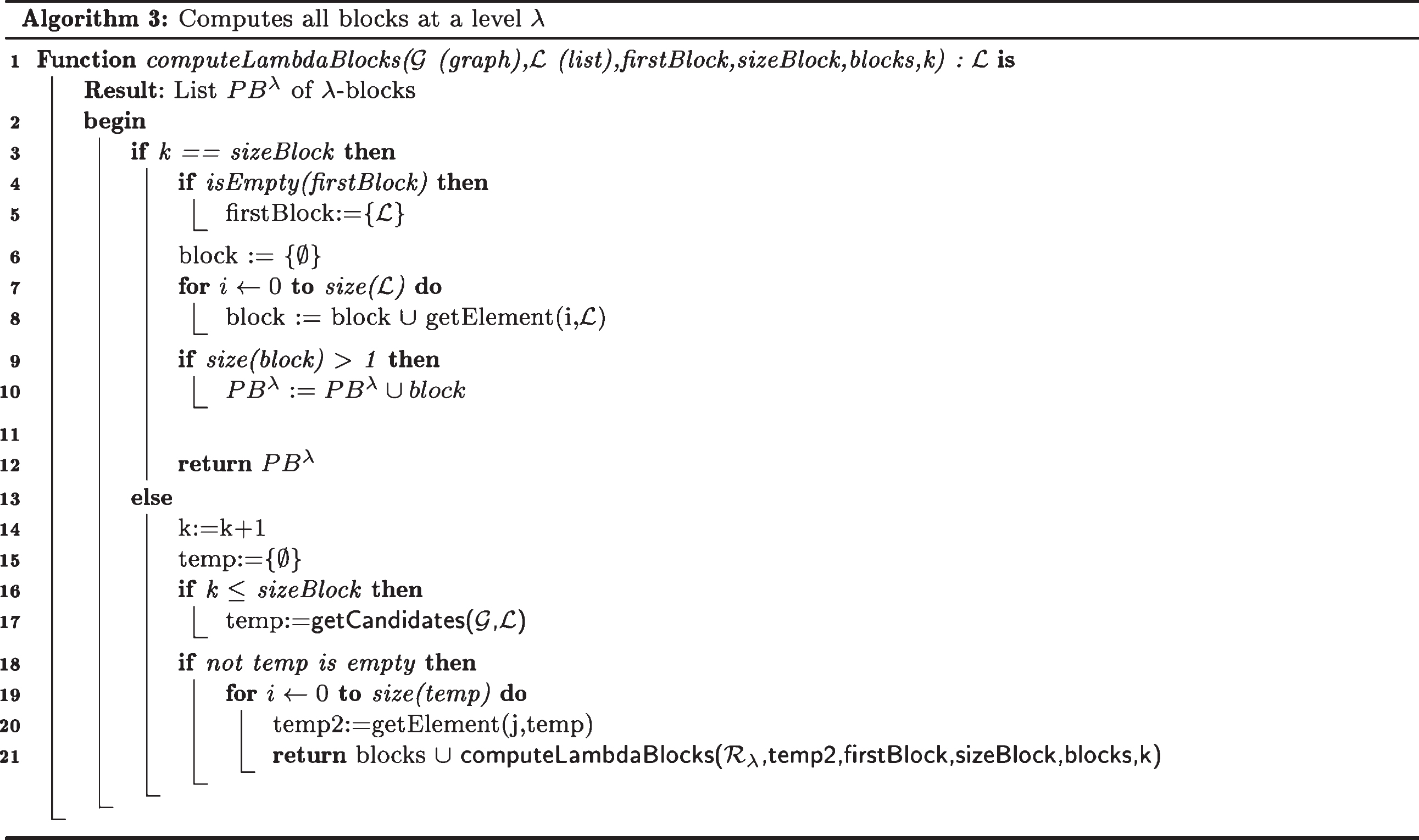
 This is based on a fuzzy and modified version of the well-known algorithm for finding all maximal cliques of an undirected graph [6]. To this end, several operations have to be performed: (i) creating a vector cV of elements for this level; (ii) generating a subgraph cG from cV and cRλ; (iii) initialization of several variables as firstBlock, sizeBlocks and blocks; and finally (iv) calling to computeLambdaBlocks function (Algorithm 3) in order to compute the blocks at this level. This function implements a backtracking algorithm (with pruning) that intends to solve the problem of computing all blocks at a level λ. Backtracking is used to solve problems where a sequence of objects, satisfying some constraint, has to be selected. In this case, the constraint is that all elements belonging to a (sub)graph are connected among them.
This is based on a fuzzy and modified version of the well-known algorithm for finding all maximal cliques of an undirected graph [6]. To this end, several operations have to be performed: (i) creating a vector cV of elements for this level; (ii) generating a subgraph cG from cV and cRλ; (iii) initialization of several variables as firstBlock, sizeBlocks and blocks; and finally (iv) calling to computeLambdaBlocks function (Algorithm 3) in order to compute the blocks at this level. This function implements a backtracking algorithm (with pruning) that intends to solve the problem of computing all blocks at a level λ. Backtracking is used to solve problems where a sequence of objects, satisfying some constraint, has to be selected. In this case, the constraint is that all elements belonging to a (sub)graph are connected among them.
The computeLambdaBlocks function employs the getCandidates function (Algorithm 4) in order to generate all groups of elements in the graph which could be candidates for being λ-blocks at a certain approximation level (For example, following with Example 1 a trace of execution for this function is shown in Table 1. Note that the empty candidates are not shown).
In summary, our algorithm works like a fuzzy clustering algorithm based on λ-cuts of cR, i.e., in each step cliques of elements connected by proximity are computed. The following items show the behavior of the initial steps of our method and Algorithm 1 for the particular case of Example 1: (i) A set Λ of proximity levels is created from a set of proximity equations. In this case: Λ = {0.8, 0.5, 0.2}; (ii) For each element participating in a proximity equation, it is adding to an array A. In this case: A = {black, brown, green, gray, blue}. Then, a graph G of dimension N × N (N being the length of the array) is created; (iii) Afterwards, a crisp subgraph G λ representing the λ-cut of cR is created, the idea is that two elements of A are connected at level λ if: G [i] [j] ≥ λ or G [j] [i] ≥ λ (i,j=1,…,N), hence a crisp subgraph at level λ is created. This is the input of a crisp all maximal clique algorithm which computes all maximal cliques (λ-blocks) at level λ. For instance, given the subgraph: G 0.8 =

{G [black] [brown] , G [green] [gray] , G [gray] [blue]}, the maximal cliques cC1 = {black, brown} , cC2 = {green, blue} , cC3 = {green, gray} are obtained; (iv) Finally, a hierarchy is built in each step by means of the corresponding λ-blocks as previously was described inAlgorithm 1.
Once we have got the hierarchy of proximity blocks cJ, the second step consists in the selection of some λ-block and the later labeling of it with an abstract descriptor d k . Then, for each element , we generate the proximity equation “e j ∼ d k = α jk ”, where the approximation degree α jk ≡ cR (e j , d k ) is computed as follows: i) the user selects a set R = {r 1, …, r n } of typical representative elements in that best fit the notion described by d k ; ii) , that is, an average of the closeness of e j w.r.t. the considered representative concepts of the block. Note that, if an element e j is related to the elements of a set D = {d 1, …, d m } of abstract descriptors, the approximation degree α jk should be normalized to the value , in order to fulfill the consistency criterion: .
Later, the set of proximity equations automatically generated can participate in the inference process of a fuzzy programing language based on weak unification.
Note that this technique can be seen as a generalization process where the user controls the selection of the most appropriate descriptor for a proximity λ-block. Furthermore, this method can be understood as an abstraction process which: (i) improves, by means of data summaries, the comprehension of the ontology defined by the proximity equations; and (ii) gives the user more freedom in order to define his own generalization. Finally observe that, when the proximity relation cR is a similarity, the notion of “proximity block”, used in the description of Algorithm 1, becomes a “similarity class” which can be computed moreefficiently.
KD∼Bousi: A Tool for discovery of abstract knowledge
In order to implement the generalization method described in the last section, a tool for Discovery of Abstract Knowledge (called KD∼Bousi 5 has been built. KD∼Bousi (see Fig. 3) has been integrated into the Bousi~Prolog system, although it can work independently. It allows the automation of the proximity λ-block generation process, facilitates the assignment of an abstract descriptor to each one of the groupings of concepts (selected by the user from the set of generated λ-blocks) and generates the corresponding proximity equations 6
The user of this tool has at his disposal graphical windows that facilitate the interaction with the system: The Hierarchy Displayer Window (1) that shows the structure of the generated hierarchy and allows the selection of a λ-block clicking on it. Once a λ-block is selected, its information will become available in the Descriptor Selection Window (2) which, in addition, has a text field box where the user can introduce the descriptor that is going to be linked with a group of concepts. After the choice of a descriptor, the user can, by pushing the button “Generate Equations”, generate the proximity equations which are displayed in the Equations Displayer Window (3). Finally, they can be loaded into the Bousi~Prolog system by pushing the button “Load Proximity Equations”.
Additionally, a new choice has been incorporated to the GUI Menu in order to enable the generation of proximity-based hierarchies by using REFs. When clicking on the button “Proximity Configuration”, a sub-choice called “By using REFs” appears. Then, if you click on it, a confirmation message inform you that the Restricted Equivalence Function option has been enabled.
The tool has been implemented in Java 7. For this task, two software layers have been built. A domain layer which is responsible for the hole functionality of the described method and it is composed by four classes: the Block class which is mainly a list of sets of blocks; the Level class composed of a list of objects belonging to the Block class, along with a field “degree” indicating the level; the Hierarchy class consists of a list of objects in the Level class, and the Generator class which implements a fuzzy extension of the clique algorithm [6]. The second layer is the representation layer. It has the function of implementing the graphical interface of the tool.
This tool has been integrated into the Bousi~Prolog system what allows it to employ the set of proximity equations generated in the attribute-oriented induction process in combination with the inference mechanism of the system. This feature is illustrated by the following example:
Induction based on WordNet
The method previously explained has an important limitation because the user has to intervene in the choice of descriptors. In practice, when generalizing attribute values, there are usually distinguished subsets of lower-level concepts that can be easily assigned to the particular abstract concept even by users who only have ordinary knowledge about generalized domain. However, at the same time the assignment of the other lower-level values is problematic even among experts [1]. In order to address this limitation we are going to use WordNet as “teacher” or “expert’. WordNet [11] is a lexical database which groups English words into sets of synonyms called synsets. It also provides short, general definitions, and records the various semantic relations between these synonym sets.
Thus, it is possible to know the meaning of a word and, at the same time, to associate it with other words using ontological relations like synonymy (which relates words with similar meanings), antonymy (which relates pairs of words whose meaning is in opposition), hypernymy (refers to words whose meaning include the meaning of more specific words; that is, refers to general concepts), hyponymy (is the opposite notion of hypernymy), and so on. In our case, the idea is to use WordNet to get a set of common hypernyms for all the elements belonging to a λ-block.
We informally describe an algorithm that automatically computes a set of recommended abstract descriptors from a λ-block of concepts:
First we select a λ-block. Then WordNet is employed to compute the hypernyms of each element in the lambda block, which are taken as seed-words. Next, the intersection of these sets of hypernyms is calculated. As a result we obtain a new set, formed by the hypernyms that the seed-words share in common. This new set is shown to the users as a list of recommended abstract descriptors, with the aim of assisting users in the selection of abstract descriptors.
The last algorithm has been implemented and incorporated to our system, allowing us to make the abstraction process easier for the users. However, note that the information provided by WordNet is not only useful to recommend a set of abstract descriptors, but also it could be very beneficial for knowledge representation because we could enhance the knowledge base inductively. In order to be able to use WordNet together with KD∼Bousi a tool for the connection with WordNet (called WN∼Bousi 7 has been built. This tool allows to consult synonyms, homonyms, hypernyms, homonyms and meronyms for each one of the symbols which are present in a Bousi~Prolog program.
Additionals applications
KD∼Bousi could give support in a wide variety of applications. For example, it could be used to recognize when symbols are polysemous and to obtain groups of representative symbols of the different meanings. Accrediting and resolving ambiguity is and important task in semantic processing. We could use KD∼Bousi in order to recognize relevant polysemy. Following [31], let G be a graph of words closely related to a seed-word w, and let G - w be a subgraph which results from the removal of the seed-node w. The connected components of the subgraph G - w are the meanings of the word w with respect to the graph G. As an illustrative example, consider a set of proximity equations modeling the relation of closeness between the symbols.

Once they have been loaded in the KD∼Bousi tool, a proximity-based hierarchy is computed. This is formed by two approximation levels (1.0 and 0.9) with four and two blocks respectively. In particular, the 0.9-blocks generated by our method are: and . Then, the removal of the “apple” node results in two separate components which represent the different meanings of “apple” in the program: fruit and computers.
Note also that, the use of proximity relations is an essential feature of our method since it provides us with a greater flexibility allowing that a symbol could belong to more than one partition. On the contrary, in a similarity-based framework a symbol only can belong to an unique class.
Conclusions and Future Work
In this paper, we have proposed and implemented a proximity-based generic method for the discovery of generalized knowledge in the context of a fuzzy logic programming language with a weak unification procedure based on proximity relations (or similarity relations more restrictively). The generalization method can be understood as modeling a knowledge abstraction process. In order to prove its feasibility, this method has been integrated as a tool into the Bousi~Prolog system. Thanks to the new tool we accomplish the goal of managing a generalization process, in a semi-automatic way, starting from the semantic knowledge represented by a set of proximity relations.
Some of the advantages of this proposal are: the learned descriptors are fixed once and used many times, adding new knowledge (this can be considered a learning process where the user teaches the system new concepts on the basis of the existing knowledge); block analysis (in alliance with other techniques) can contribute to ontology tuning and lead to a form of information comprehension; background knowledge (the so called hierarchy of concepts) is generated in a semi-automatic way; what gives users the freedom to define the most convenient generalization, that is, an user can select a possible descriptor (“learning with a human teacher”), or using WordNet (“learning with an artificial teacher”) what can be seen as “learning without a teacher” because the “teacher” is a software application.
However we can signal out possible limitations: i) the user has to intervene in the choice of descriptors, although he/she receives a considerable amount of assistance by the system; ii) block generation can be non-affordable in time, if you are working with a great amount of proximity equations.
Regarding future work lines, we want to make more flexible the automatic generation of proximity equations allowing, for example, to establish relations between general descriptors of the same abstraction level, that currently are disposed in a hierarchy (and only relate to descriptors of the superior/inferior level). On the other hand we would like to improve the efficiency of the block generation algorithm. All in all, we desire to continue enhancing the Bousi~Prolog system in order to transform it in a effective tool for the development of soft computing applications.
Acknowledgments
This work has been partially supported by FEDER and the Spanish Ministry of Economy and Competition under grant TIN2013-45732-C4-2-P and it is done in collaboration with the research group, SOMOS (Software - MOdelling - Science), funded by the Research Agency and the Graduate School of Management of the Bío-Bío University under grant 130415 GI/EF.
Footnotes
Although the paper focuses on proximity relations, it is valid for similarity relations too, since they are a special kind of proximity relations fulfilling the transitive property (See Section 3)
Bousi~Prolog is publicly available at the ![]() ">
http://dectau.uclm.es/bousi
">
http://dectau.uclm.es/bousi
For the sake of simplicity, in the examples, we omit the reflexive and the symmetric entries needed to complete a proximity relation
Note that, for the special case of similarity relations, λ-classes will be used instead of λ-blocks