
Abstract
With the rapid growth of user-generated contents online, unsupervised methods which do not need to use labeled training data have become increasingly important in sentiment classification. But the performance of unsupervised methods is unsatisfactory. This is because sentence structure and ambiguity of sentiment intensity are usually ignored in existing unsupervised methods. To address these problems, we propose a multi-granularity fuzzy computing model which involves two innovations. Firstly, we come up with a multi-granularity computing method to compute sentiment intensity of reviews. To be specific, we deconstruct those reviews into three levels of language units—words, phrases and sentences, and consequently manage to compute the sentiment intensity of reviews by combining rule-based methods and statistic-based methods. Secondly, a fuzzy classifier is constructed to solve the ambiguity of sentiment intensity. Furthermore, two different self-supervised methods using pseudo-labeled training data are proposed to learn the optimum parameters of the fuzzy classifier. Experimental results in four different datasets prove that our model improves 6.25% more accuracy on average than the competitive baselines in sentiment classification of Chinese reviews.
Keywords
Introduction
With the continuous escalation of social networks such as Twitter, Facebook and various forums, user-generated contents such as feedback from consumers, status of social networking service (SNS) and micro-blogs are exploding on the Internet. With the great surge of subjective contents, how to mine opinions from them has become a new focus in the area of natural language processing (NLP) and web mining [1]. Since the early 2000s, as a specific category of text classification, sentiment classification has drawn increasing attention from researchers and become a fairly popular research topic in handling user-generated contents [2, 3].
Up to now, many researches have been conducted on sentiment classification of the subjective texts [4]. A subjective text is mainly classified into positive or negative polarity in document level of sentiment classification. For example, it is very reasonable to classify a produce review, which expresses an overall positive or negative opinion about the produce, into positive or negative polarity. In this paper, we focus on the document-level sentiment classification.
At present, there are mainly two types of methods in document-level sentiment classification, supervised methods and unsupervised methods [5]. Many supervised methods in topic classification have been applied to sentiment classification, but their performance is not satisfying [6]. Different from traditional topic classification [7], sentiment classification has been proved to be highly sensitive to the domain of data that are related to some certain subjects [8]. To improve the performance of sentiment classification, supervised methods insist that the domain of the training data should be consistent with that of the test data [9]. However, annotating data for each domain is rather costly. Thus, unsupervised methods are more desirable when it comes to efficiency and cost [10].
In existing unsupervised methods, there are mainly two problems. Firstly, when computing the sentiment intensity of reviews, only sentiment polarity or sentiment intensity of words and phrases is employed, sentence types and relations between sentences are seldom taken into account [11]. However, different sentence types and relations between sentences have different effects on sentiment of sentence. For example, declarative sentences and interrogative sentences which have the same contents may express an opposite polarity. Secondly, when performing sentiment classification according to sentiment intensity of reviews, sentiment classification is formulated as an either-or problem, the fuzziness of sentiment intensity is usually ignored [12]. However, it is difficult to distinguish two opposite sentiment polarities from the two reviews whose sentiment intensity is close to.
To solve these two problems, we propose a multi-granularity fuzzy computing model (MGFCM) for sentiment classification of reviews. Our contributions have mainly two points.
Firstly, a multi-granularity computing method, which computes sentiment intensity of reviews in terms of three levels of language component-words, phrases and sentences, is proposed. Specifically, we compute sentiment intensity of a review by merging the sentiment intensity of words, phrases and sentences in the review. On the word level, we distinguish two types of different sentiment words and propose corresponding methods for two types of different sentiment words. On the phrase level, we propose a method based on sliding window of fixed length to construct sentiment phrases and compute sentiment intensity of sentiment phrases. On the sentence level, we propose a rule-based method which considers three types of sentences and two types of logical relation between sentences.
Secondly, given the fuzziness of sentiment intensity, we construct a fuzzy classifier and a corresponding classification function of the fuzzy classifier by virtue of fuzzy sets and the principle of maximum membership degree. Furthermore, we propose two different self-supervised methods using pseudo-labeled training data to learn the parameters of the fuzzy classifier. Experience results prove the validity of both the two different methods.
This paper is organized as follows. Related studies are presented in Section 2. Section 3 casts light on the multi-granularity fuzzy computing model and the two key parts of it. In Section 4, a key sentiment morpheme lexicon (KSML) and a quantified whole sentiment lexicon (QWSL) are codified. In Section 5, the experimental results in four review datasets are analyzed to prove the performance of our model. Finally, the whole work is summarized and the final conclusions are drawn.
Related work
As a popular research topic in natural language processing and web mining, sentiment classification has been extensively studied since 2002 [1, 4]. Existing methods of sentiment classification are mainly divided into two categories: supervised methods and unsupervised methods [5]. The supervised methods include many traditional text classification methods, such as Naive Bayes [29], Support Vector Machine [30], and Neural Networks [31]. The unsupervised methods primarily include two key steps [12–15]. The first step is to compute the sentiment intensity of reviews. The second step is to achieve sentiment classification of the review according to sentiment intensity of reviews. Since our methods are unsupervised methods, next, we mainly introduce related work in unsupervised sentiment classification.
As the basis of unsupervised sentiment classification, identifying the polarity of sentiment words is a research focus. There are three mainstream types of methods for identifying the polarity of Chinese sentiment words. The first is a kind of thesaurus-based method which evaluates the similarity between the undetermined sentiment words and the known sentiment words for reference by their distances in thesaurus [16–18]. The second is a sort of corpus-based method which evaluates such similarity by statistical methods in corpus [18–20]. And the third is a type of morpheme-based method which directly calculates the sentiment intensity of the sentiment words, with that of the Chinese sentiment morphemes available [21–24].
After obtaining sentiment polarity of sentiment words, to compute the sentiment intensity of reviews, previous work tended to simply add up the sentiment polarity of each sentiment word or phrase in these reviews with a certain weight or proportion which was, by and large, determined by degree adverbs around each of them [11, 23]. Sentence types and relations between sentences are seldom taken into account in computing the sentiment intensity ofreviews.
Back to the second step, existing research implements sentiment classification of reviews by roughly comparing sentiment intensity of reviews with a single threshold “0”, which primarily left out the fuzzy region between sentiment categories [10–12, 23]. However, both the rule of thumb and the research in NLP indicate that sentiment intensity of reviews involves fuzziness [25–27], and it is not proper to identify the polarity of reviews by a rough either-or method.
However, there is still some previous research investigating the effect that fuzzy sets may have on sentiment classification [27, 32]. For example, Wang et al. proposed a unsupervised fuzzy computing model to identify the polarity of Chinese sentiment words [32]. Fu and Wang together invented an unsupervised method using fuzzy sets for sentiment classification of Chinese sentences [27]. Wang et al. developed an ensemble learning method, which is a supervised method, to predict sentiment intensity of consumers with an online sequential extreme learning machine and an intuitive fuzzy set [28].
What distinguishes our work from the previous is the multi-granularity fuzzy computing model we proposed. Our model mainly has two key steps. Firstly, when calculating the sentiment intensity of reviews, a multi-granularity computing method which uses three levels of language component-words, phrases and sentences is proposed. The multi-granularity computing method uses sentence types and relations between sentences, which are seldom taken into account in previous computing sentiment intensity of reviews. Secondly, when setting parameters of the unsupervised fuzzy classifier, two self-supervised methods are investigated. The two self-supervised methods use pseudo-labeled training data to avoid the unnecessary trouble of annotating data for each subject domain, as far as we know, which is unprecedented in setting the parameters of unsupervised sentiment classifiers.
Up to now, multi-granular fuzzy linguistic model has been applied successfully in areas such as information retrieval, recommender systems and decision making [33]. But as far as we know, multi-granular fuzzy linguistic model has not been applied in the sentiment classification of reviews. Different from the existing multi-granular fuzzy linguistic model, our proposed model is an unsupervised framework to implement sentiment classification of Chinese reviews. Our model uses three levels of language granularity-words, phrases and sentences to compute the sentiment intensity of reviews, and then identifies the sentiment polarity of reviews based fuzzy sets and sentiment intensity of reviews.
A multi-granularity fuzzy computing model
General framework of multi-granularity fuzzy computing model
The unsupervised methods primarily include two steps. The first step is to compute the sentiment intensity of reviews. In existing unsupervised methods, only sentiment polarity or sentiment intensity of words and phrases is employed by statistics-based methods, sentence types and relations between sentences are always ignored [11]. However, different sentence structures have different effects on sentiment polarity or sentiment intensity of sentence. The second step is to perform sentiment classification of review based on sentiment intensity of reviews. In existing unsupervised methods, sentiment classification is regarded as an either-or problem, and the fuzziness of sentiment intensity is usually ignored [12].
To solve the two problems, we propose a multi-granularity fuzzy computing model (MGFCM) for sentiment classification of reviews. The general framework of MGFCM is described in Fig. 1.
The general framework of MGFCM consists of three sections: review datasets (RD), key sentiemnt morpheme lexicon (KSML) and quantified whole sentiment lexicon (QWSL) as a whole, MGFCM. RD serves as test datasets to verify the performance of MGFCM. KSML and QWSL serve as basis thesaurus of MGFCM. While MGFCM is kernel composed of two key parts.
The first part of MGFCM involves a multi-granularity computing method for calculating sentiment intensity of reviews. Firstly, we break down reviews into three levels of language components by a top-down strategy. Then we adopt a bottom-up strategy to compute sentiment intensity si (w j ) of sentiment word w j , sentiment intensity si (p i ) of sentiment phrase p i and sentiment intensity si (s i ) of sentence s i . Finally, we compute sentiment intensity si (r i ) of review r i .
The second part of MGFCM is constructing a fuzzy classifier for sentiment classification of reviews. We firstly construct a classification function f k (si (r i )) of the fuzzy classifier, and then, we propose two self-supervised methods to learn the parameter k of f k (si (r i )).
The two key parts of MGFCM in detail are as follows.
Multi-granularity computing method
When computing sentiment intensity of reviews, the existing researches concentrate on merely the word level and the phrase level, without taking into account the sentence level. However, different sentence structures have different effects on sentiment polarity or sentiment intensity of sentence. So we propose a multi-granularity computing method, which calculates sentiment intensity of each language unit to sum the overall sentiment intensity of a single review. The whole process of the multi-granularity computing method is described in Fig. 2.
Computing methods on the word level
On the word level, we divide sentiment words into two categories, static sentiment words and active sentiment words. The static sentiment words consist of both words in and outside QWSL. The types of sentiment words and the corresponding method of computing sentiment intensity are shown in Table 1.
For static sentiment words belonging to QWSL, we gain their sentiment intensity by traversing the lexicon. For static sentiment words out of QWSL, we compute their sentiment intensity by statistic method based on morpheme. The specific process for computing sentiment intensity of static sentiment words outside QWSL is demonstrated as follows.
1. For each word w j which is outside QWSL, split the word into morphemes m ij .
2. For each morpheme m ij in word w j , traverse KSML. If morpheme m ij is included in KSML, we directly gain its sentiment intensity, otherwise, we appoint the sentiment intensity of morpheme m ij to be 0.
3. For each word w
j
, compute sentiment intensity si (w
j
) by equation (1).
Here number (m ij , w j ) is the number of morphemes m ij in sentiment words w j , si (m ij ) is the sentiment intensity of morpheme m ij .
As for active sentiment words, their sentiment intensity depends on the context. So, we compute sentiment intensity of active sentiment words by including the nearest neighbor in an unfixed length sliding window and in reference to sentiment consistency principle. The concrete steps are as follows.
1. For each active sentiment word w k , we obtain the initial sentiment intensity si initial (w k ) of w k by looking up active sentiment lexicon which is provided by Guohong Fu [27].
2. Using active sentiment word as midpoint, we employ an unfixed length sliding window to seek for forward sentiment words. The maximum of the unfixed length sliding window is the distance between active sentiment word and the beginning word of the sentence.
3. Compute the sentiment intensity of the activesentiment word according to sentiment intensity si (w
nearest
) of the nearest noun or adjective w
nearest
. The special method can be seen in (2).
For example, in the sentence like “The performance-cost ratio of the pad is high  ”, the initial intensity of active sentiment word “high
”, the initial intensity of active sentiment word “high  ” is 1. Since sentiment intensity of its front word “performance-cost ratio
” is 1. Since sentiment intensity of its front word “performance-cost ratio  ” is 0, we gain that sentiment intensity of “high
” is 0, we gain that sentiment intensity of “high  ” in this sentence is 1(1 × 1 =1) according to equation (2). On the contrary, in the sentence like “The risk of investing on the stock is high
” in this sentence is 1(1 × 1 =1) according to equation (2). On the contrary, in the sentence like “The risk of investing on the stock is high 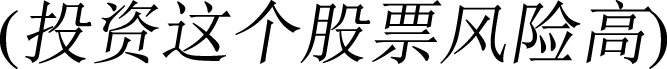 ”, the word “risk
”, the word “risk 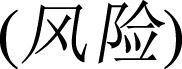 ” in the front of “high
” in the front of “high  ” owns a sentiment intensity of -1. Thus sentiment intensity of “high
” owns a sentiment intensity of -1. Thus sentiment intensity of “high  ” here is -1(-1 ×1 = -1) according to equation (2).
” here is -1(-1 ×1 = -1) according to equation (2).
Taking sentiment words as midpoints, we assemble the sentiment phrases with a sliding window of fixed length and some syntax rules. The size of the sliding window is 5 words. The specific rules are shown in Table 2.
When calculating sentiment intensity of sentiment phrases p
k
, we come up with the following equation to take into account the effect of adverbs.
Here class (adverb) is the type of adverb, α is the weighting coefficient of the degree adverb.
We divide the degree adverb into five kinds according to the degree and assigned to them different weighting factors. The levels of degree adverb and their weighting coefficients are defined in Table 3. We set β = 0.4 according to experience and prior knowledge in [12].
For example, in the sentence “The pad is very beautiful  ”, we construct sentiment phrase “very beautiful
”, we construct sentiment phrase “very beautiful  ” according to Table 2. The sentiment intensity of sentiment word “beautiful
” according to Table 2. The sentiment intensity of sentiment word “beautiful  “ is 1 by traversing the QWSL. The weighting coefficients of the degree adverbs “very
“ is 1 by traversing the QWSL. The weighting coefficients of the degree adverbs “very  ” is 1.6 (4 × 4 =1.6) based on Table 3. So, the sentiment intensity of the sentiment phrase “very beautiful
” is 1.6 (4 × 4 =1.6) based on Table 3. So, the sentiment intensity of the sentiment phrase “very beautiful  ” is 1.6 (1.6 × 1 =1.6) according to equation 3.
” is 1.6 (1.6 × 1 =1.6) according to equation 3.
On the sentence level, we consider different sentence patterns and relationships between sentences to deal with the sentiment intensity of sentences.
Firstly, we merge the sentiment intensity of each word and phrase to sum the overall sentiment intensity of a single sentence.
Secondly, according to punctuations, we segment reviews into different types of sentences, namely declarative sentences, interrogative sentences and exclamatory sentences. Then we adopt different strategy for sentence of each type. The specific strategies are shown in Table 4.
Based on linguistics knowledge, exclamatory sentence can strengthen the sentiment of sentence content. So, when computing the sentiment intensity of exclamatory sentence, we enhance the sentiment intensity of the sentence by assigning 2 to the weighted coefficient.
For example, in the exclamatory sentence “The pad is very beautiful!  ”, the sentiment intensity of the sentence “The pad is very beautiful
”, the sentiment intensity of the sentence “The pad is very beautiful  ” is 1.6 according to Section 3.2.2. The sentiment intensity of the exclamatory sentence “The pad is very beautiful!
” is 1.6 according to Section 3.2.2. The sentiment intensity of the exclamatory sentence “The pad is very beautiful!  ” is 3.2 (2 × 1.6 = 3.2) based on Table 4.
” is 3.2 (2 × 1.6 = 3.2) based on Table 4.
Thirdly, we analyze the logical relations between sentences by primarily extracting the conjunctions. We mainly process adversative and summary relations between sentences. The processing methods are shown in Table 5.
Based on experience and linguistics knowledge, summary sentence reflect the whole sentiment of reviews. So, when computing the sentiment intensity of summary sentence, we strengthen sentiment intensity of the sentence by assigning 2 to the weighted coefficient.
Constructing method of the fuzzy classifier
After obtaining the sentiment intensity of the reviews by the multi-granularity computing method, given the fuzziness of sentiment intensity, we construct a fuzzy classifier for sentiment classification of reviews and propose two self-supervised methods to learn the parameter of the fuzzy classifier. We first appoint sentiment categories as fuzzy sets, and then define some member functions of the sentiment categories. According to the principle of maximum membership degree in fuzzy sets, we build a classification function for the fuzzy classifier. Finally, we propose two self-supervised methods to learn the parameter of the classification function.
Designing the membership function of fuzzy sets
Due to the fuzziness of natural language, especially that of sentiment intensity, when estimating sentiment category of reviews, we adopt fuzzy sets other than Cantor-sets to describe sentiment categories.
With the existing review sets R = {r
i
} and sentiment intensity si (r
i
) of review r
i
, we can define the positive sentiment category of R as the fuzzy set P.
Here μ
P
(r
i
) is the membership function of r
i
belonging to the positive sentiment category P. we choose a semi-trapezoid function as the membership function of r
i
, which is presented in (5).
Here r i is a review, si (r i ) is the sentiment intensity of r i , α, β are adjustable parameters which determine the boundary of membership function.
Similarly, we define the negative sentiment category of R as the fuzzy set N.
Here μ
N
(r
i
) is the membership function of r
i
belonging to negative sentiment category. Also a semi-trapezoid function is chosen as the membership function of r
i
.
Here r i is a review, si (r i ) is the sentiment intensity of r i , α, β are adjustable parameters.
We need to set the values of parameters α, β to complete μ P (r i ) and μ N (r i ). After completing μ P (r i ) and μ N (r i ), according to the principle of maximum membership, we can identify the sentiment categories of reviews.
In order to decrease the number of parameters, after defining μ P (r i ) and μ N (r i ), we unite μ P (r i ) and μ N (r i ) into one classification function f k (si (r i )) of fuzzy classifier, according to the principle of maximum membership.
Here we define
We do not directly set the values of the two parameters α, β, but simplify the two parameters to one parameter k by f k (si (r i )), and only set the value of para-meter k.
After constructing the classification function of the fuzzy classifier, we come to setting the value of parameter k. At present, the unsupervised methods are mainstream methods for setting parameters in the classification function of fuzzy classifier, while supervised methods are customarily ignored through lack of labeled training data.
Parameter k directly determines the threshold of the fuzzy classifier. In order to get an ideal parameter, we propose two self-supervised methods to set the value of parameter k.
1. Self-supervised method based on the initial pseudo-labeled training datasets
In setting parameter k for the classification function of the fuzzy classifier, existing unsupervised methods use sentiment intensity of reviews and do without labeled training data, but the accuracy is far from satisfactory [27]. So we turn to the supervised methods. But there are two weaknesses in existing supervised methods. Firstly, labeled data as training data is indispensable. Secondly, the domain of training data related to some certain subject has to be consistent with that of test data, while annotating training data for each domain is very costly.
To overcome the two weaknesses, we develop two self-supervised methods, using pseudo-labeled training data, which is unprecedented. Details are as follows.
Firstly, for each review r i in review datasets RD = {r i }, we compute sentiment intensity si (r i ) of r i by the multi-granularity computing method which is presented in Section 3.2.
Secondly, for RD = {r i }, we reorder reviews in descending order of si (r i ), and therefore obtaining a new reviews sequence RD T = {r m }.
Thirdly, for the new reviews sequence RD T = {r m }, we appoint the number of positive reviews in RD T as N P (RD T ), the number of negative reviews in RD T as N N (RD T ) and the number of reviews in RD T as N (RD T ).
Fourthly, we pick out N
P
(RD
T
)/2.5 positive reviews and N
N
(RD
T
)/2.5 negative reviews from RD
T
= {r
m
} to form an initial positive training datasets PT _ RD
T
and an initial negative training datasets NT _ RD
T
. The method of constructing PT _ RD
T
and NT _ RD
T
is shown in (9) and (10).
Here l = 2.5.
Finally, we obtain the optimum value of parameter k by equation (11) in the initial pseudo-labeled train datasets.
Here l = 2.5, N P (RD T ) is the number of positive reviews in RD T , N N (RD T ) is the number of negative reviews in RD T and N (RD T ) is the number of reviews in RD T .
2. Self-supervised Method Based on the updated initial pseudo-labeled train datasets
The first four steps are similar to that of the self-supervised method above.
In the fifth step, we generate a SVM classifier through PT _ RD T and NT _ RD T , and we use the SVM classifier to classify the rest of RD T . If the sentiment intensity of a review is more than 0 and classification result of the review is positive according to the SVM classifier, we will add the review to PT _ RD T . If the sentiment intensity of a review is less than 0 and classification result of the review is negative by the SVM classifier, we will add the review to NT _ RD T . Finally, we obtain a new PT _ RD T and NT _ RD T .
In the sixth step, we repeat the fifth step with a new PT _ RD T and NT _ RD T . The iteration end until no new review is added to PT _ RD T and NT _ RD T .
Finally, we use equation (11) in the updated initial pseudo-labeled training datasets to obtain the optimum value of parameter k.
The value of parameters k in four different datasets are presented in Table 10 in part 5.2.
In existing Chinese sentiment lexicons, sentiment words are divided into two classes— positive and negative, sentiment intensity of sentiment words is not further quantified. In order to solve the problem, based on the existing three Chinese sentiment lexicons (Tsinghua University sentiment lexicon (TUSL), National Taiwan University sentiment lexicon (NTUSL) and Hownet), we at first construct a KSML, and then based on KSML, we construct a QWSL. The whole process of our method is showed in Fig. 3.
Our method includes three steps. The first step is to construct a key sentiment word set (KSWS) which consists of both positive key sentiment words set (P_KSWS) and negative key sentiment words set (N_KSWS). we propose a method to extract unambiguous P_KSWS and N_KSWS.
The second step is to construct a key sentiment morpheme lexicon (KSML) which consists of positive key sentiment morphemes list (P_KSML) and negative key sentiment morphemes list (N_KSML). We at first split each sentiment word in KSWS into morphemes, and then put morphemes together as key sentiment morpheme sets (KSMS). Then we compute the sentiment intensity of each morpheme in KSMS by statistic method.
The third step is to construct a quantified whole sentiment lexicon (QWSL) which consists of unambiguous positive whole sentiment lexicon (P_WSL) and negative whole sentiment lexicon (N_WSL). We firstly construct a whole sentiment word set (WSWS) by incorporating typical Chinese sentiment lexicon, and then compute sentiment intensity of each word in WSWS with morpheme in KSML. At last, we get a QWSL.
Constructing KSWS
When constructing KSWS, we notice the fact that there are some sentiment words whose polarities are ambiguous among different sentiment lexicons. With the existing three Chinese sentiment lexicons (SL i ) consisting of both positive sentiment words list (P _ SWL i ) and negative sentiment word list (N _ SWL i ), we get some sentiment words of which the polarity is ambiguous. Table 6 presents the number of the sentiment words whose polarities are ambiguous between P _ SWL i and N _ SWL i .
From Table 6, we can see that there are some sentiment words whose polarities are ambiguous between P _ SWL
i
and N _ SWL
i
, which demonstrates that polarity of sentiment words is not always consistent among different sentiment lexicons. So, we eliminate these ambiguous sentiment words from P _ SWL
i
and N _ SWL
i
. Finally, we construct KSWS by choosing the sentiment words which are unambiguous in polarity and at least included in two sentiment lexicons. The method of constructing KSWS is shown in (12)and (13).
Here i = {1, 2, 3}, j = {1, 2, 3}. The number of sentiment words in SL i and KSWS is presented in Table 7.
KSML is composed of sentiment morphemes and sentiment intensity of sentiment morphemes. There are mainly four key steps in constructing sentiment morphemes and computing sentiment intensity of sentiment morphemes.
1. For each word in KSWS, we split it into morphemes and consequently construct a key sentiment morpheme set (KSMS).
2. For each morpheme m
i
in KSMS, we calculate positive frequency f _ p (m
i
) of m
i
of appearing in P _ KSWS and negative frequency f _ n (m
i
) of m
i
of appearing in N _ KSWS of it in (14) and (15).
Here number (m i , P _ KSWS) is the number of positive sentiment words containing the morpheme m i , number (m i , N _ KSWS) is that of negative sentiment words that contain the morpheme m i , number (P _ KSWS) is the number of sentiment words in P _ KSWS, and number (N _ KSWS) is the number of sentiment words in N _ KSWS.
3. For each morpheme m
i
in KSMS, we compute positive sentiment intensity si _ p (m
i
) of m
i
and negative sentiment intensity si _ n (m
i
) of m
i
of it in (16) and (17).
4. With si _ p (m
i
) and si _ n (m
i
) of m
i
available, we compute sentiment intensity si (m
i
) of m
i
in (18).
We combine the three typical Chinese sentiment lexicons (TUSL, NTUSL and Hownet) into a quantified whole sentiment lexicon (QWSL). To ensure that the polarity of the sentiment words is unambiguous, we eliminate the sentiment words whose polarities are ambiguous in QWSL. The specific method of constructing QWSL is described as follows.
For each SL
i
which consists of P _ SWL
i
and N _ SWL
i
, we build unambiguous positive whole sentiment word set (P _ WSWS) and negative whole sentiment word set (N _ WSWS) according to (19) and (20).
Here i = {1, 2, 3}, j = {1, 2, 3}. After obtaining unambiguous whole sentiment word set (WSWS), For each word w
j
in WSWS, we compute sentiment intensity si (w
j
) of w
j
according to (21).
Here number (m i , w j ) is the number of the morpheme m i included in the sentiment words w j . The si (m i ) is the sentiment intensity of m i . Finally, w j and si (w j ) make up QWSL.
In this section, we firstly described the datasets and metric. Secondly, we discussed how to choose the optimum parameter k of MGFCM. Thirdly, we compared the performance of different methods and proved the efficiency of MGFCM. Fourthly, we employed the statistical significance tests of different methods. Finally, we discussed the effect that different parameter k have on the accuracy of MGFCM.
Datasets and metric
In order to prove the effectiveness of our model in different domains and unbalance datasets, we chose three balanced (books, hotels and notebooks) and one unbalanced datasets (hotels) from different domains as test datasets. The four datasets are provide by Songbo Tan (http://www.datatang.com/data/11936/). Each dataset consists of positive reviews and negative reviews. The four datasets is named after Books, Hotels, Notebooks and Hotels(U). The four datasets are summarized in Table 8.
Since our task is sentiment classification of reviews, we chose classification indicators: precision, recall, F1 measure and accuracy as metric. The four indicators are defined as follows.
Here R1, R2, W1, W2 are defined in Table 9.
To evaluate the overall performance of our model, we compared our model with existing methods on four different datasets. These methods are depicted as following:
MBSL: Method based on sentiment lexicon, which is presented in [10]. MBSL compute the sentiment intensity of reviews only using sentiment words and sentiment phrases. The sentiment intensity of sentiment words is gained by traversing sentiment lexicon. The sentiment intensity of sentiment phrases is gained by considering effect of negative adverb and degree adverb. After getting sentiment intensity of reviews, MBSL accomplishes sentiment classification by comparing sentiment intensity of reviews with threshold “0”.
MBSLFS: Method based on sentiment lexicon and fuzzy sets, which is presented in [27]. Similar to MBSL, MBSLFS computes the sentiment intensity of reviews only using sentiment words and sentiment phrases. After getting sentiment intensity of reviews, different from MBSL, MBSLFS accomplishes sentiment classification by comparing sentiment intensity of reviews with threshold “k”, which is used in sentiment classification of Chinese reviews.
MBMGC: Method based on multi-granularity computing which computes sentiment intensity of reviews by multi-granularity computing method and compares the sentiment intensity with only a single threshold “0”.
MBMGFCM1: Method based on multi-granularity fuzzy computing model which sets parameters by a self-supervised method using the initial pseudo-labeled train datasets.
MBMGFCM2: Method based on multi-granularity fuzzy computing model which sets parameters by a self-supervised method using the updated initial pseudo-labeled train datasets.
In order to further demonstrate the effect of our methods, we constructed a supervised method to learn parameter k of MGFCM. For each datasets, we randomly chose 40% reviews as training datasets, the rest 60% reviews as test datasets. And then, we used train datasets to learn parameter k of MGFCM and used test datasets to validate the performances of MGFCM. We repeated the experiments 10 times and report the results as the average of the 10 experiments. The method is depicted as following.
MBMGFCML: Method based on multi-granularity fuzzy computing model which sets parameters by using the labeled train datasets. The only difference between MBMGFCML and MBMGFCM1 is that MBMGFCML uses the labeled train datasets to estimate the parameter of fuzzy classifier, but MBMGFCM1 uses the initial pseudo-labeled train datasets.
We conducted different experiments with the four datasets to solve three problems.
1. How to set the parameter k in the classification function of the fuzzy classifier;
2. Studying the performance of our model in sentiment classification of reviews;
3. Analyzing the effect of different parameter k may have on the accuracy of our model;
In MGFCM, we have proposed two self-supervised methods to learn parameter k. One is a self-supervised method based on initial pseudo-labeled training datasets, the other one is a self-supervised method based on updated initial pseudo-labeled training datasets.
Firstly, we picked out 40% reviews from both ends of the descending list of reviews as the initial pseudo-labeled training datasets, and then we employed the two self-supervised methods mentioned in Section 3.3.3 to find the optimum value of parameter k. Finally, we obtained optimum parameters by the two self-supervised methods respectively. The special parameters are shown in Table 10.
Performance comparison of different methods
In order to verify performance of our model, we compared our model with MBSL, MBSLFS and MBMGFCML in four datasets. The experiment result is shown in Table 11 and Fig. 4.
From Table 11 and Fig. 4, we can see the value of the four classification indicators: precision,recall, F1 and the accuracy of MBMGC are higher than that of MBSL in four different datasets. The average accuracy of MBMGC and MBSL is 0.7748 and 0.7141 respectively on the four datasets. The MBMGC enjoys about 8.5% ((0.7748-0.7141)/0.7141) more accuracy than MBSL in sentiment classification of reviews, which proves that the multi-granularity computing method is more efficient and accurate than only taking into account sentiment polarity or sentiment intensity of words and phrases.
At the same time, we can see the accuracy of MBSLFS is higher than that of MBSL, and the accuracy of MBMGFCM1 and MBMGFCM2 is higher than that of MBMGC on the four different datasets. MBMGFCM1 and MBMGFCM2 improve about 3.77% ((0.8040-0.7748)/0.7748) and 4.48% ((0.8095-0.7748)/0.7748) more accuracy than MBMGC. This proves that sentiment classifiers based on a fuzzy set are more efficient than sentiment classifiers based on Cantor-sets.
The average accuracy of MBMGFCM1 and MBMGFCM2 is 0.8040 and 0.8095. MBMGFCM2 has 0.68% ((0.8095-0.8040)/0.8040) more accuracy than MBMGFCM1. This demonstrates that the self-supervised method based on the updated initial pseudo-labeled training datasets is superior to the self-supervised method based on the initial pseudo-labeled training datasets in setting the parameter k of MBMGFCM.
In Hotels datasets and Hotels(U) datasets, we can found that MBMGFCM1 only improves 0.28% ((0.7965-0.7943)/0.7943) and 0.35% ((0.823-0.8201)/0.8201) accuracy than MBMGC. But in Books datasets and Notebooks datasets, we can found that MBMGFCM1 improves 8.9% ((0.8073-0.741)/0.741) and 6.1% ((0.7893-0.7438)/0.7438) accuracy than MBMGC. This demonstrates that the performance of our methods is different in datasets from different domains. The reason is that distribution of sentiment words is diverse in different domains.
The average accuracy of MBMGFCML and MBMGFCM1 is 0.8048 and 0.8040. MBMGFCML has only improve 0.1% ((0.8048-0.8040)/0.8040) more accuracy than MBMGFCM1. This demonstrates that MBMGFCM1 with self-supervised is competitive with MBMGFCML using labeled training data. At the same time, we can see that MBMGFCM2 has 0.58% ((0.8095-0.8048)/0.8048) more accuracy than MBMGFCML. This demonstrates that MBMGFCM2 using more pseudo-labeled train data is superior to MBMGFCML using less labelel training data.
Statistical significance tests of different methods
In order to measure the statistical significance of our methods compared to other models, we firstly employed a chi-squared test among six different methods to compare the statistical significance of six different methods. The test results were shown in Table 12. And then, we respectively employed the chi-squared test between our methods and two baselines to compare the statistical significance of our methods and two baselines methods. The test results were shown in Table 13.
From Table 12, we can see , χ2 > in four different datasets, under α = 0.05 level, there are significant differences among the six different methods.
Furtherly, from Table 13, we can see , χ2 of our four methods (MBMGC, MBMGFCML, MBMGFCM1 and MBMGFCM2) and two baseline methods (MBSL and MBSLFS) is all greater than in four different datasets. Under α = 0.05 level, there are significant differences between our methods and two baseline methods.
Parameter optimization of MGFCM
In order to study the effect that a different parameter k may have on the accuracy of sentiment classification of reviews, we carried out some experiments using different values of parameter k in the four datasets. The results are presented in Fig. 5.
From Fig. 5, we know that the diffesrent parameter k plays different roles on the accuracy of sentiment classification. So we may get a different result if a different parameter k is chosen. But in general, MGFCM always enjoys higher accuracy than MBSL and MBSLFS.
Conclusion
In this paper, we propose a multi-granularity fuzzy computing model for sentiment classification of Chinese reviews. The contribution of our paper mainly involves two aspects. First, a multi-granularity computing method is contrived to compute sentiment intensity of reviews through synthesizing the language units of all levels. Second, given the fuzziness of sentiment intensity, a fuzzy classifier is built to facilitate sentiment classification of reviews. Furthermore, two self-supervised methods are designed to set an optimum parameter for the classification function of fuzzy classifier.
Acknowledgments
We thank Lei liu, Qing Cheng and the anonymous reviewers for helpful comments. This work was supported in part by the National Natural Science Foundation of China (U1405254, 61472092, 61402115, 61271392).