
Abstract
Given the ability of fuzzy systems to make decisions in uncertainties such as morphology, and the huge number of studies conducted on morphology, this study first suggests a fuzzy morphology; then, it discusses the effectiveness of types of N-gram labeling methods to identify the role of words in Persian compounds. To find the optimal labeling, then, a new hybrid method is expressed for N-gram labeling. In relation to compound sentences, two independent roles including subject, governing predicate, predicate, object and complement and dependent roles including noun, adverb, governing genitives, genitives, bending, retroactive, apposition, exclamation and annunciator are studied. To compare the success rate of the proposed fuzzy method, existing HMM (hidden Markov model) is studied to identify the role of words in three different label types. The results of this comparison showed that the success rates of hybrid labeling and Bi-gram labeling are closed in both models. Thus, these two methods have been successful in both morphological models compared to Uni-gram labeling. It is worth noting, the highest success rate was related to fuzzy morphology and Bi-gram labeling.
Introduction
There are effective studies on morphology through statistical methods such as HMM; however, there are fewer reports on application of fuzzy system for morphology, particularly compounds of Persian words. Hence, this paper presents a method based on fuzzy systems to decide on the role of words in sentences in Persian. This study is of great importance for three reasons: 1) most morphology studies do not identify the type of words in sentences, while this paper identifies the role of words in sentences; 2) the fuzzy system is used for morphology; and finally 3) this study evaluates three different types of N-gram labeling, in both the proposed fuzzy method and HMM comparison method. Three types of N-gram labeling include Uni-gram, Bi-gram and a combination of both. In the combined labeling method, the transition from analysis to synthesis is considered. While weight of the word formed by letters and the role of the word in the sentence are effective in decision. Finally, three methods Of labeling and their results are compared for two fuzzy models and HMM and the results [1, 29].
Related works
Studies in morphology are divided into three general categories of non-Persian and non-Arabic languages, Arabic language and Persian language. Hence, Russian researchers were pioneers in the range of non-Persian and non-Arabic languages. Russian peter (1933) began studies in this area [7]. Then, Kaplan (1950) used statistical methods for machine.
Translation [11]. Andrew Booth and Richard Richens (1952) studied morphological analyzer for use in mechanical dictionary. By 21 years of research in morphology, Dostert (1954), American University of Georgetown in cooperation with IBM could develop the first translation machine [5]. Over the years, the Russians had made significant progress in this area, so that Belskaya (1950’s) could develop the bilateral English-Russian algorithm of machine translation [6]. By developing the algorithm, the famous Russian linguist, Melcuk (1956) [34], could develop the first Russian translation machine. On the other hand, the closeness of alphabet, words and grammar of Arabic to Farsi, morphology of this language is specifically studied [8]. Guessoum and l-Sahmsi (2006) based their morphology studies on HMM. In 2007, Nürnberger used the statistical N_gram classes. Then, Sinane et al. (2008) developed this research. However, morphologists in the field of Arabic language conducted studied in relation to transparency of root words by eliminating suffixes and prefixes, most notably of which was started by Garside (1999) to Al-Ameed et al. (2005) [2, 12]. One of the studies done on Farsi morphology can be Asi and Haji-Abdolhoseyni (2000) who classified words based on similarity of neighbors. By different labeling methods, Raja et al. (2007) concluded that results of statistical methods are better than other methods. Bijan Khan et al. as well as Moradzadeh (2004) conducted research on disambiguation of homograph words. In (1994), Shamsfard (1975) implemented the Denna system in Natural Language Processing Laboratory, Sharif University of Technology, using Dependency Theory. Bateni (1995) could identify the original sentence and then change the type of the sentence by special arrangements. For the meaning of the words, Sharifi (1997) used artificial intelligence for machine translation [21, 24, 21, 24]. Hussein and Gol (2005) conducted studies on localization and development of applications in 14 Asian languages including Farsi [20].
Applications of keyword recognition are important and wide, including machine translation for which the role and meaning of words are extracted from the source language; then, their role and meaning are determined in the target language. Hence, the machine translation is considered necessary for morphology. Summarization is also another application, in which the main roles are recognized and words or roles which can be removed without causing any problem in the concept are removed; for example, Web Technology Laboratory of Ferdowsi University of Mashhad, Iran, implemented the summarization system called “Ijaz” (2012). However, there are other applications of morphology such as filtering, speech recognition, speech synthesis, categorization or text classification, indexing or document analysis to extract vocabulary and retrieving the text to match data and the query or document of which data is extracted. Other applications include information extraction, combination of text or documents and reporting.
Steps of morphology by HMM
In general, four types of morphology include:
The method compared to the suggested method (HMM) is a statistic method; hence, this section discusses HMM as the most prominent statistic method. Statistic morphological methods are composed of three general computational parts including labeling, HMM morphology and deciding on the results of HMM. Hence, this section first examines the labeling method used in HMM and then presents calculations of HMM for all cases; finally, decision is described to determine the role of words in the sentence [26, 29].
N-gram labeling
In general, there are two types of N-gram labeling, one uses letters forming the words for labeling and the other takes advantages of the type and the role of words in sentences for this purpose.
Labeling based on the letters forming the words
This type of labeling is the sum of repetition of N successive letters forming the word in each of the roles. In fact, labeling word based on the letters represents the weight of that word in each of the roles. In general, the formula for calculating the weight of words based on the forming letters by N-gram method is:
If any of the letters do not depend on any of the letters before or after, the labeling will be Uni-gram. If any of the letters depend on letter before or after, the labeling will be Bi-gram. If any of the letters depend on two letters before or after, labeling is tri-gram.
For example, three types of labeling for the word ‘ ’ /baran/, according to Equation 1 and in a special role, will be as shown Table 1 [2, 32].
’ /baran/, according to Equation 1 and in a special role, will be as shown Table 1 [2, 32].
In fact, this kind of labeling is based on the role of words and the roles of N words before or after. In other words, this type of labeling indicates the presence of any role before or after the other, in all words of a sentence. In this type of labeling, Equation 1 becomes:
In Equation (2), Where M is the number of words in the sentence and i is the number of that word.
For example, Table 2 presents the values of three Uni-gram, Bi-gram and Tri-gram labeling methods for the sentence ‘ ‘ /Ali zud amad/ ‘Ali soon come’ by hypothetical labels in the compound ‘subject, adverb, verb’.
‘ /Ali zud amad/ ‘Ali soon come’ by hypothetical labels in the compound ‘subject, adverb, verb’.
In recognition of the roles of compound words in Persian language, another labeling can be calculated from Equation 2. Therefore, two types of labeling can generally use this equation.
One calculable label examines the roles of the compound. This is detailed in Table 2.
Another type of labeling calculable by Equation 2 is interference of parsing in the compound. For example, assume the sentence ‘ ’ /Ali zud amad/ by hypothetical labels in the compound ‘subject, adverb, verb’ as well as the hypothetical labels in parsing ‘name, adjective, and verb’; the table of calculation would be as shown in Table 2 [5–8].
’ /Ali zud amad/ by hypothetical labels in the compound ‘subject, adverb, verb’ as well as the hypothetical labels in parsing ‘name, adjective, and verb’; the table of calculation would be as shown in Table 2 [5–8].
In this section, labeled methods used in fuzzy method and HMM method was investigated and compared and results of which are given in Table 3. The aim difference between three methods is in obtaining weight of words in the analysis and weight of letters constituting the words as well as combination of these cases in three methods of labeling [2, 32].
Uni-gram labeling
Results from Uni-gram labeling are set into two types of matrix, one as the state transition matrix, which actually suggests the role in the synthesis given state transition for each type of analysis and used as Uni-gram-tarkib. The other is the weight matrix (probability distribution of observations) of each word of the sentence in each of the roles. It is known as B-unigram-tarkib.
Bi-gram labeling
Calculations of Bi-gram can be in combination of three types, one Bi_gram_tarkib which is actually a distribution of state transition, indicating the occurrence of each role after the analysis in the i+1th place after any word in the i th place in 194 different wordings used for learning system.
The other Bi-gram labeling known as Bi-gram-kol indicates the occurrence of synthesis roles in the i+1th place after the role of i th word at 194 different wordings. Because there are two types of Bi-gram matrix in distribution of the state transition, and in the best case, multiplication of values of these two matrices provides the best output, Bi_gram_tarkib, Bi-gram-kol× is used as the matrix A or state transition matrix in Bi-gram labeling method.
The third type of Bi-gram is known as Matrix_B which is a different kind of probability distribution of observations (B), calculated by Bi-gram method, as shown in Table 1.
Combined labeling
The combined method integrates different types of Bi-gram and Uni-gram matrices by the best possible combination to consider the moment of transition from analysis to synthesis, as well as the succession of the roles after any other role and the roles after type. Thus, Table 3 presents these combinations [5–8].
HMM to recognize the role of vocabulary
Hidden Markov model uses computations of N-gram labeling method. One of the reasons for using N-gram outputs can be to consider the role of words in the order of their placement (state transition probability) and the weight of words formed by letters (observation probability) as well as the primary distribution probability.
Equation (3), the primary distribution probability is calculated by:
In fact, the primary distribution probability represents the probability that i th role of N role is the first word in the sentence. This is important because the order of the set of responses can be ignored if the probable presence of a role as the first word in the sentence is zero,
Table 4 shows the values of the primary probability distribution extracted from 194 types of different exploratory wordings of Persian grammar.
Equations (4), in fact, HMM is obtained from primary distribution probability π, B as the observation distribution probability and a state transition matrix.
Where N indicates the value of N-gram. B = P (w i |t i ), A1…NA = P (t i |ti-1) ad π can be calculated from Equations 1–3, respectively [4, 7].
For example, assume ‘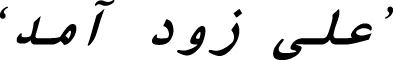 ’ /Ali zud amad/; to calculate the probability of occurrence of ‘governing predicate, predicate, verb’ by Bi-gram method, this hypothetical case of different states can be calculated by HMM as follows:
’ /Ali zud amad/; to calculate the probability of occurrence of ‘governing predicate, predicate, verb’ by Bi-gram method, this hypothetical case of different states can be calculated by HMM as follows:

In Equation (5), Where P(governing predicate,  /Ali/), P(predicate,
/Ali/), P(predicate, ) and or P(verb,
) and or P(verb,  /amad/) are separately a probability distribution of observations which can be calculated by equation 1, as shown in Table 1.
/amad/) are separately a probability distribution of observations which can be calculated by equation 1, as shown in Table 1.
Occurrence of
In Equations (6), Where occurrence of P(governing predicate) = π is the primary probability distribution. P(verb, predicate) and P(governing predicate, predicate) are two state transition expressions [3, 36].
By discussing the occurrence of each possible case of accepting the roles in the combination, it is time to make decision for roles of the words of input sentence. Hence, the Viterbi algorithm is a general algorithm covering all phases of HMM; finally, it is used to decide on the final output of the problem. //Given a Sentence of length n //Initialization δ1 (SoS) =1.0 δ1 (t) =0 for t ≠ SOS
//induction For i = 1 to n do For all tags t
j
do
× P (wi+1|t
j
)] ψi+1 (t
j
) = argmax1≤k≤T [δ
i
(t
k
) × P (t
j
|t
k
) × P (wi+1|t
j
)] end end //termination and path extraction Xn+1 = argmax1≤j≤Tδn+1 (t
j
) for j = n to 1 step - 1 do
X
j
= ψj+1 (xj+1) end p (P (X1, …, X
n
) = maxi≤j≤Tδn+1 (t
j
)
In the above algorithm, δ i (j) j (line 8) calculates the probability of the label j for the word i, i.e. the probability distribution of observations. In line 9, the most probable transition to label of the previous word, leading to label j of the current word (the probability of transition) is obtained. A line 12 to 16 calculates the values of HMM for possible paths. In line 17, the largest value of computations of the available paths is determined as output or outcome.
For example, Equation (7), exemplifies calculation of three test paths.

According to the Fig. 1, the number of paths which are investigated in combination of independent roles is 10word count and 17word count in dependent roles, because there are 10 labels in independent roles and 17 labels in dependent roles or unique or shared role between analysis and synthesis (e.g., verb, adjective).
Fuzzy method as multi-parametric method can eliminate ambiguities in the role of words in different belonging degrees which gives to words in different roles.
Since fuzzy set is a set in which the members have membership degree [1, 0], thus, using proposed fuzzy method for words in different roles, belonging degrees are calculated and using defuzzifier y center of gravity, ambiguity of word roles in the sentence is eliminated. Hence, features of the proposed method include as follows: Persian grammar rules in both the analysis and synthesis are used. Independent roles are separated from dependent roles. Weight of letters forming words also affect calculations. Due to using defuzzifier y Max (product), the effect of any lower value is less and the effect values are more. Defuzzifier center of gravity method is used for discrete values which can provide the nearest value as a result for the values out of global set. Because of the similarity in the rules of grammar and alphabet of Arabic and Farsi, this method can be used in the grammar of Arabic and other languages.
A fuzzy calculation consists of three steps:
Fuzzifier (Relation Matrix/ Membership Degree/μ A (x i ))
Fuzzifier used in this study is Max (product); it is noteworthy that other methods such as Max (min) or ordinary multiplication of two matrices, etc. can also be used. These calculations of Max (Product) are two two-dimensional matrices (8×24) and (number of word ×24), in which the number of words/analysis labels is 8 and the number of evaluated labels is 24.
Considering the three types of labeling discussed in Section 2.2, the Max (product) method Equation (8), will be as shown in Table 5.
Table 6 presents Max (product) calculations of fuzzification values for the sentence ‘ ’ /Ali zud amad/. This matrix is called Relation_tarkib.
’ /Ali zud amad/. This matrix is called Relation_tarkib.
Obviously, the shared roles such as proposition and verb which are not required to calculate have zero value [5–7, 17].
After Fuzzifier, as shown in Fig. 2, there are two steps of fundamental rules and inference engine. The fundamental rules are extracted from 194 different wordings of Persian grammar and 76,274 unique words. The vocabulary database is compiled by Analysis and Synthesis of Persian words (Pars Process), Genie Khan Vocabulary; in addition to these two, the Bank of Persian Language Reference Database version 3.0 was used for verbs and Naming Database of Census Organization of Iran was used for names [17, 23].
Inference engine
In fact, inference engine is all labeling methods discussed in Section 3.1. It is used in calculations of Fuzzifier, as shown in Table 5, and calculations described in Section 4.4. defuzzifier
An important decisive part of fuzzy calculations is its final stage and defuzzifier for deciding on fuzzy values obtained from Fuzzifier.
The Defuzzifier used in this study is the center of gravity. Considering the analysis which is the input and the input sentence, calculations of the center of gravity defuzzifier the fuzzy values to make decisions.
Equation (9), is the general formula for calculating the center of gravity.
In Equation (9), where μ A (x i ) is the membership degree, which is measured with three different types of labeling discussed in section 3.1. x i Is the occurrence of each role after the other role. Table 7 presents calculations of center of gravity using three different labeling methods. Also Equation (10), the number of words per sentence.
In general, the fuzzy calculation algorithm is as follows. It receives sentences and analyses them from the user It extracts matrices required It forms the possible states according to the number of words in the input sentence. It eliminates the impossible states It obtains Realation_tarkib matrix using the calculations given in Table 5. It obtains the center of gravity by one of the equations in Table 6. It repeats steps 5 and 6 for all possible scenarios. It obtains the largest center of gravity and displays in the output.
Let the input sentence be ‘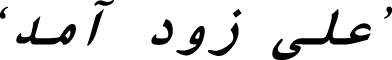 ’ /Ali zud amad/ and the input analysis be ‘
’ /Ali zud amad/ and the input analysis be ‘ ’ /Ali/: name,
’ /Ali/: name,  /zud/: adj,
/zud/: adj,  /amad/: Verb’; membership degree of the words can be extracted from Table 6.
/amad/: Verb’; membership degree of the words can be extracted from Table 6.
Therefore, the membership degree of the sentence,  /Ali/⟶ name = 0.427,
/Ali/⟶ name = 0.427,  /zud/ ⟶ adj. = 0.078,
/zud/ ⟶ adj. = 0.078,  /amad/ ⟶ Verb = 0.
/amad/ ⟶ Verb = 0.
Also, the percentage of repeat roles the following example in as a three-word sentence is: governing subject = 0.058, Adverb = 0.019 and verb = 0.274.
Thus, it is essential to calculate occurrence x i as xi1 and xi2. The former is occurrence of a role after another role and the latter is occurrence of a role after the type of the word. Therefore, x i = xi1 + xi2. Table 8 shows the value of xi1.
Values of xi2 are given in Table 9 for the sentence  /Ali zud amad/. It is noteworthy that these values and roles are hypothetical.
/Ali zud amad/. It is noteworthy that these values and roles are hypothetical.
Therefore, calculations of the membership degree discussed in the Section 3.1 will be the sum of two values in Bi-gram of the Relation_tarkib matrix, as shown in Equation (11).
Table 10 shows calculations of the center of gravity for three types of assumed role/ One assumed path(verb =  /amad/,predicate =
/amad/,predicate =  /zud/,subject =
/zud/,subject =  /Ali) of 10word count possible cases as independent roles and 17word count as dependent roles, as follows.
/Ali) of 10word count possible cases as independent roles and 17word count as dependent roles, as follows.
Finally, Max (as/the center of gravity) to output is sent as result [5–7, 23].
For comparison and evaluation of the system, 70 sentences with standard words and grammar as input and analysis/type of the words were inserted into the system; in fact, the results are 6 types of output in independent roles, 3 output is related to HMM with three types of labeling and 3 other outputs are related to the proposed fuzzy method by three other types of labeling discussed in Section 3.1. However, there are exactly the same numbers of outputs in dependent roles. To obtain analysis of the words of input sentence, tools of ‘natural language processing software’, Web Technology Laboratory, University of Mashhad, which has high accuracy, can be used. The main roles include subject (subject1 and subject2= governing predicate), predicate, object, verb and complement. The dependent roles include noun which is dependent on adj., genitive and governing genitive, dependent adverb, apposition, retroactive, bending, annunciator and exclamation [13, 27].
Equation (112 How to calculate the amount of success:
In Equation (13), 5 Number of independent role and 11 Number of dependent roles. These values can be achieved from Tables 14 and 15.
Equation (13), indicates the way of calculation of success average in dependent or independent roles.
Following calculation of average success level in dependent and independent roles groups, total success level for each of them is calculated using fuzzy method or HMM method with Equation (14).
For success of the results, the mean overall success in both independent and interdependent roles in the proposed fuzzy method and HMM method is shown in Table 11.
Figure 3 presents the different values of success in here types of labeling. It is observed that highest success percentage is related to fuzzy method and Bi-gram labeling type. Then it I related to fuzzy method and combined labeling type an then it goes to HMM method and combined labeling type as the third rank.
As noted in Fig. 3 and Tables 11, 12 presents the mean independent roles in the fuzzy system and HMM for three types of labeling.
Statements 12 and 13 were used for calculation of these values. Results suggest overall superiority of fuzzy method in all cases except HMM method and Uni-gram labeling type. Figure 4 shows different morphologies in three types of Uni-gram, Bi-gram and combined labeling in combined independent roles in both methods.
As shown in Fig. 4, highest percent of success is with fuzzy method and Bi-gram labeling type, then it goes to combined labeling type of this method, and HMM method and combined labeling type goes in third rank. Of course, difference between ranks 1 and 2 is about 1 percent, while different between second and third highest values is about 10 percent.
Table 13 presents success rate of three types of labeling in combined dependent roles in both models. In dependent roles, like independent values, highest percentage of success (66.55) is related to fuzzy method and second rank is related to this method with difference about 4% , and third rank goes to combined labeling of HMM method.
Figure 5 compares differences in success rate of three types of labeling in combined dependent roles by fuzzy method. As observed in Fig. 5, highest success percentage is related to fuzzy method and Bi-gram labeling type, and second rank goes to fuzzy method and combined labeling type. Third rank is related to HMM method and Uni-gram labeling type. Considering Tables 12 and 13, Uni-gram labeling type for HMM method is among 3 top ranks of success of dependent / independent roles.
Table 14 presents the success rate of combined independent roles in three types of labeling method. As observed in Table 14, highest value is related to fuzzy method and Uni-gram labeling, while it is not so in overall average, because their values of this column are smaller than 20% . However, in fuzzy method column and Bi-gram labeling, which has highest average, cases have above 60% success except for one case.
Figure 6 presents the success rate of combined independent roles in three types of labeling method.
As observed in Fig. 6, where 4 cases out of 5 causes in fuzzy method and Bi-gram labeling type have success between 63% –85 % , while Uni-gram labeling of this method shows lowest values except one case.
Table 15 presents the success rate of combined dependent roles in three types of labeling method.
As observed in Table 13, the column which has highest average success in dependent roles is fuzzy method column and Bi-gram labeling type as observed in values of this column, only 2 cases out of 11 cases have success between 20 to 30 % and other 9 cases have success above 40% . While Uni-gram column in fuzzy method has lowest percentage of success, except three cases, other cases have below 30% success.
Figure 7 presents the success rate of combined dependent roles in three types of labeling method.
As observed in the Fig. 7, difference of bars in three parts of fuzzy method in terms of Bi-gram labeling, fuzzy method in terms of combined labeling and HMM method in terms of Uni-gram labeling has lowest changes. These parts have highest values of success in total average [5–8].
In mean success rate of HMM method for both independent and dependent roles, the combined labeling is the best, while Bi-gram labeling is successful in fuzzy method. On the other hand, the greatest success rate of each labeling method belongs to fuzzy method and Bi-gram labeling. While, independent and dependent roles are separately examined. In independent fuzzy roles, the best method is Bi-gram labeling; while combined labeling is the best for HMM independent roles. For dependent fuzzy roles, the success belongs of Bi-gram labeling; while this value is equal for both combined labeling and Bi-gram in HMM. The main problem with these calculations is the heavy computations; hence, followings are recommended to reduce computations and increase the success rate of methods. Coupled roles must appear as couple in results. The N-gram method with N-order higher than Bi-gram can be used; Tri-gram can also be used in computations, particularly fuzzy calculations, because the Bi-gram method acts better than Uni-gram in fuzzy method. Occurrence of the words can be extracted in accordance to the number of words. Completion of types of Persian states is possible because the number of wording states used for training these models (194) may be higher; therefore, their addition will be effective on results. Another Defuzzifier method can also be tested. Another labeling method besides n-gram can be tested for future studies. The fuzzy method can be used for analysis of sentences. Overlapping roles in synthesis of words can be examined for future works. Application of combined methods such as rule-based method or memory-based method may reduce the computations. The roles connected to other roles can be considered in future works. For the fuzzy calculations, the primary cases such as HMM can be used to reduce the calculations.