
Abstract
Background:
Disease progression prediction based on neuroimaging biomarkers is vital in Alzheimer’s disease (AD) research. Convolutional neural networks (CNN) have been proved to be powerful for various computer vision research by refining reliable and high-level feature maps from image patches.
Objective:
A key challenge in applying CNN to neuroimaging research is the limited labeled samples with high dimensional features. Another challenge is how to improve the prediction accuracy by joint analysis of multiple data sources (i.e., multiple time points or multiple biomarkers). To address these two challenges, we propose a novel multi-task learning framework based on CNN.
Methods:
First, we pre-trained CNN on the ImageNet dataset and transferred the knowledge from the pre-trained model to neuroimaging representation. We used this deep model as feature extractor to generate high-level feature maps of different tasks. Then a novel unsupervised learning method, termed Multi-task Stochastic Coordinate Coding (MSCC), was proposed for learning sparse features of multi-task feature maps by using shared and individual dictionaries. Finally, Lasso regression was performed on these multi-task sparse features to predict AD progression measured by the Mini-Mental State Examination (MMSE) and the Alzheimer’s Disease Assessment Scale cognitive subscale (ADAS-Cog).
Results:
We applied this novel CNN-MSCC system on the Alzheimer’s Disease Neuroimaging Initiative dataset to predict future MMSE/ADAS-Cog scales. We found our method achieved superior performances compared with seven other methods.
Conclusion:
Our work may add new insights into data augmentation and multi-task deep model research and facilitate the adoption of deep models in neuroimaging research.
Keywords
INTRODUCTION
Alzheimer’s disease (AD) is the most prevalent neurodegenerative brain disease worldwide [1, 2]. Clinical trial failures in symptomatic patients have led to the belief that capturing brain changes and therapeutically intervening at earlier disease stages would be more likely to achieve disease modification [3]. Various modalities of biomarkers have been used for early identification of brain changes related to AD and its earlier symptomatic stage, mild cognitive impairment (MCI), including the brain structural atrophy measured by magnetic resonance imaging (MRI) [4–6], metabolic alterations in the brain measured by fluorodeoxyglucose positron emission tomography (FDG-PET) [7, 8], and pathological amyloid depositions measured through cerebrospinal fluid (CSF) and amyloid-PET [3, 9]. Of these, abnormal structural MRI is considered as a typical marker of neurodegeneration and retains a close relationship with cognitive performance through the clinical phases of MCI and dementia [3]. MRI is more widely available, less invasive, and more affordable for clinical applications than other imaging biomarker modalities. To date, the inevitable deformations of hippocampus, ventricle, and cortical thickness are well captured by structural MRI (Fig. 1) [10–13]. Prior work [3, 14–16], including our own study in a cognitively unimpaired brain imaging cohort (Arizona APOE cohort) [10], indicated that MRI hippocampal atrophy accelerates 20 + years prior to incident to MCI. Thus, structural MRI is promising as a potential preclinical AD biomarker. However, MRI biometrics do not yet reliably predict diagnosis and prognosis in early AD stages especially in individual patients [2, 17–20, 2, 17–20].

Three promising brain structure measures of the structural MR images used for clinical diagnosis of Alzheimer’s disease: (a) Hippocampal contractions; (b) Ventricle expansions; (c) Cortical thickness reductions.
Convolutional neural networks (CNN) are capable of learning comprehensive feature maps from images [21]. CNN has been successfully applied to a variety of computer vision and medical imaging applications including image classification [22], segmentation [23], and disease diagnosis [24]. It has the potential to improve the predictability of AD progression [21]. Li et al. [25] proposed a CNN framework for early prognosis of AD dementia based on the baseline hippocampal MRI data, and demonstrated improved performance for predicting progression to AD dementia. However, there are still few CNN studies on modeling AD progression. One issue is the limited training data in the AD research domain while transfer learning has been proven to be a highly effective technique for limited medical image analysis. Kermany et al. [26] successfully applied CNN with transfer learning to classify images for macular degeneration and diabetic retinopathy and distinguish bacterial and viral pneumonia on chest X-rays. Xu et al. [27] designed a deep model of CNN with transfer learning and achieved a good performance in distinguishing histopathology images of low and high tumor mutational burden patients. CNN with transfer learning, therefore, has potential for AD dementia diagnostic modeling based on MR images.
After using CNNs with transfer learning, we confront an additional challenge that is high dimensional feature maps derived from small number of individual biomarkers based on MR images. To address this so called “large p, small n” problem, sparse coding has been applied. Sparse coding is an effective way of learning a small number of basis vectors termed dictionary to represent high dimensional features effectively and concisely [28–30]. However traditional dictionary learning algorithms confront challenges of handling very large training sets or dynamic training data changing over time, such as MR image sequences accompanying AD progression [30]. Studies of [17, 31–33] demonstrated that joint analysis of multi-tasks (i.e., multiple time points or biomarkers) improved the prediction performance and may be used for tracking AD progression.
To track AD progression measured by cognitive scores, Zhang and Shen [18] proposed Multi-Modal Multi-Task learning to jointly predict multiple variables from multi-modal data. However, they excluded conditions of missing values in both modalities and tasks. The study of [17] proposed Multi-Task Learning formulations by considering the prediction at each time point as a task. It demonstrated that Multi-Task Learning outperformed single-task learning algorithms including ridge regression and Lasso for AD progression. However, their approaches treated dictionary learning for all tasks in the same manner, which was suboptimal for modeling AD progression. To address the above two issues, our previous study [32] proposed a two-stage Multi-task Stochastic Coordinate Coding (MSCC), stage 1 involved multi-source dictionary learning to utilize the common and individual sparse features in multi-tasks. In stage 2, a Multi-Task Learning method was developed to solve the missing values issue. Experimental results demonstrated that MSCC had an improved prediction accuracy and speed efficiency for future AD clinical score predictions compared to other similar algorithms.
To explore the statistical power of the combination of CNN with transfer learning and multi-task sparse coding, we developed an advanced deep model CNN-MSCC to predict AD progression measured by the Mini-Mental State Examination (MMSE) [34] and the Alzheimer’s Disease Assessment Scale cognitive subscale (ADAS-Cog) [35] scores using multi-task imaging biomarkers. We hypothesized that our system may produce accurate AD progression modeling results while offering the flexibility to work with structural imaging features from both longitudinal data and multiple regions-of-interest (ROIs). To validate our hypothesis, we designed two sets of experiments where we applied our framework to study the structural MRI data from Alzheimer Disease Neuroimaging Initiative (ADNI) [36, 37] and compared our approach with seven other similar methods. In Experimental I, we aimed to use longitudinal (baseline, 6-months, 12-months) hippocampal structural measures to predict MMSE/ADAS-Cog scales of 24-months subjects. In Experiment II, we applied the proposed framework on three kinds of baseline structural features (hippocampal morphometry, lateral ventricular morphometry, and cortical thickness) to predict MMSE/ADAS-Cog scales of varied time points (6-months, 12-months, and 24-months).
MATERIALS AND METHODS
Subjects
Data for testing the performances of our proposed framework and comparison methods were obtained from the ADNI database (http://adni.loni.usc.edu). The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI is to test whether biological markers such as serial MRI and positron emission tomography (PET), combined with clinical and neuropsychological assessment can measure the progression of MCI and early AD. The structural MR images were acquired from 1.5T scanners. The raw MR images and MMSE/ADAS-Cog scales were downloaded from the public ADNI website (http://adni.loni.usc.edu/).
In this work, all of these performance comparison analysis have been conducted on ADNI-I dataset which including 837 subjects, the selection criteria can refer our previous study [38], the identification numbers of subjects were included in Supplementary Material A. There were 837 baseline subjects between 68–82 years of age, 733 subjects in the 6th months, and 676 subjects in the 12th months, and 544 subjects in the 24th months. There were 814 baseline subjects having MMSE/ADAS-Cog scores, including 1) 186 AD subjects: baseline MMSE scores between 20–26, 2) 399 MCI subjects: baseline MMSE scores between 24–30, and 3) 229 cognitive unimpaired (CU) subjects: baseline MMSE scores between 24–30. The demographics of subjects used in our experiments are shown in Table 1.
Demographic characteristics and longitudinal neuropsychological scores of the subjects
AD, Alzheimer’s disease; CU, cognitive unimpaired; MCI, mild cognitive impairment; MMSE, Mini-Mental State Examination; ADAS-Cog, Alzheimer’s Disease Assessment Scale-Cognitive Subscale.
Proposed pipeline
In this section, we introduce the CNN-MSCC framework which predicts future MMSE/ADAS-Cog based on previous image patches from multiple time points or multiple ROIs. We pre-trained the CNN model on the ImageNet dataset [22, 39]. Surface measures of hippocampi, lateral ventricle, and cortical thickness were estimated from individual structural MR images [6, 40]. Surface maps were first constructed for these ROIs, and image patches were further extracted from these surface maps [29, 42]. With the transfer learning strategy, the pre-trained CNN network was adopted as a feature extractor for the following multi-task learning process (i.e., different time points or ROIs) [31]. We further employed MSCC to conduct the multi-task learning to simultaneously refine sparse features and dictionaries [32]. Finally, we employed the sparse codes generated from MSCC to perform the Lasso and predict the future MMSE/ADAS-Cog scores [43]. The entire pipeline of our proposed framework is illustrated in Fig. 2.
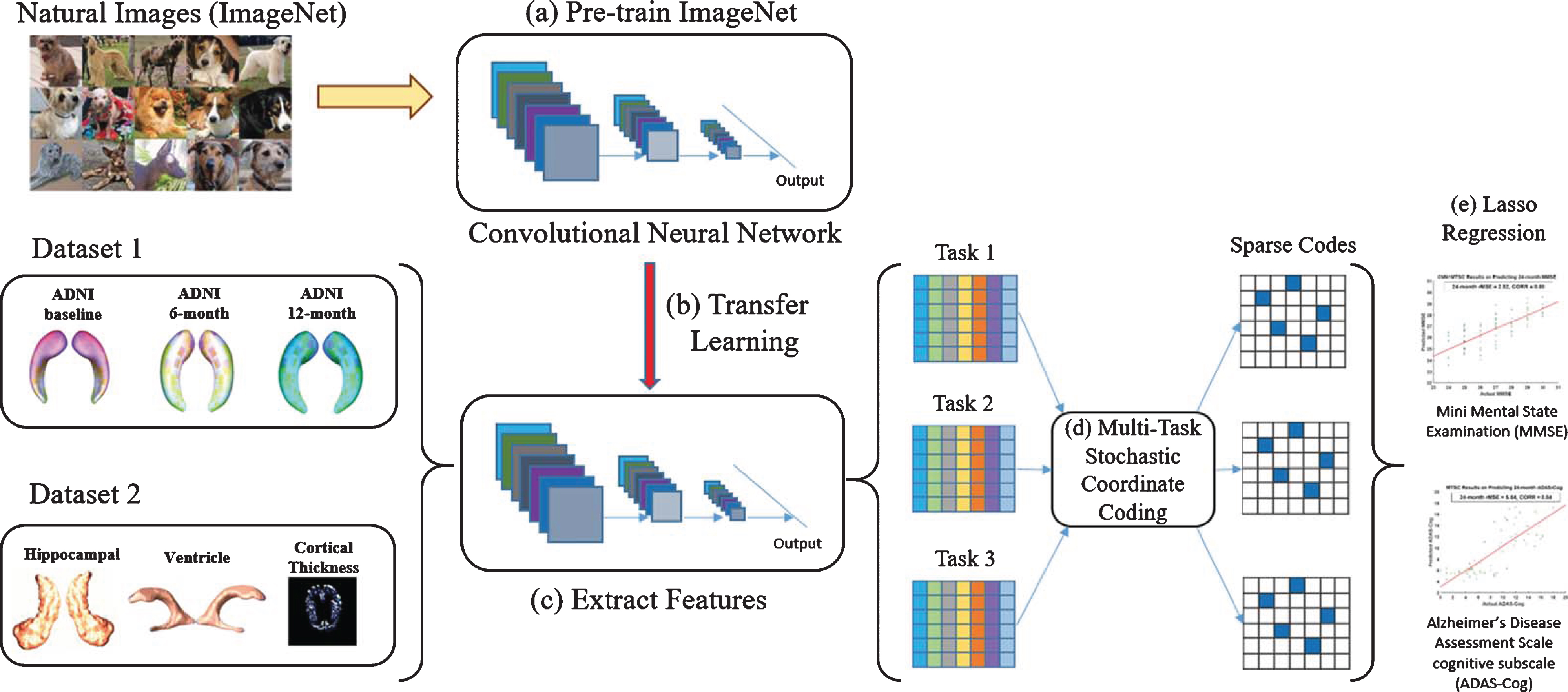
An illustration of the proposed CNN-MSCC framework. The CNN model was pre-trained on the ImageNet dataset (a). The pre-trained model was modified as a feature extractor for brain structural MR image patches based on transfer learning strategy (b) and deep feature maps were extracted from varied structural measures or time slots (c). MSCC was adopted to generate the sparse features from deep feature maps (d). Finally, Lasso regression was applied on the sparse features to predict future MMSE and ADAS-Cog scores (e).
MR image preprocessing
Hippocampal surfaces were firstly segmented and reconstructed from individual MR images using FIRST software [44] and marching cube method [45]. Then, we computed hippocampal conformal grids on the Euclidean domain with holomorphic 1-form functions [46]. With these conformal grids, we transferred the original 3D hippocampal structure into 2D vertex-based features. The benefit of the conformal parameterization is that it helped compute both surface intrinsic and extrinsic geometry features, and dramatically simplified the implementation of surface fluid registration algorithm [47]. We further applied the inverse consistent surface fluid registration method to register hippocampal surfaces across subjects. After the surface registration, we introduced consistent image-grid like mesh structures on all hippocampal surfaces, for each subject, a 90,000-dimensional mesh structure represented mTBM of the hippocampal (HP) surfaces. To reduce the high mesh dimension, we can treat the surface-based feature structure as the pixel-grid and build patch structures. Quadrilateral patches were adopted here to improve the computational efficiency. Specifically, with the rectangular surface parameterization obtained in our surface fluid registration [47], taking advantage of the regular grid-like mesh structure, we randomly generated a number of square windows (50 × 50 vertices) on each registered surface to obtain a collection of small surface patches with different amounts of overlaps. We choose 132 patches on each hippocampus because it will cover all the vertices on each side of hippocampus. The procedure is in fact equivalent to applying a low-pass filter on the original meshes. As a result, the geometrical structures are still present while surface feature variances are reduced. We performed the same procedure to compute patches on both lateral ventricular and cortical surfaces. Finally, we represent the original bilateral hippocampal surface features with 264 overlapping patches [29]. It is worth noting that even though we randomly select patches on all subjects, because of the registered surfaces, the patches we select in each task are in fixed locations on each hippocampus. Figure 3 shows an example of patch selection on a pair of the hippocampal surfaces. As these patches are allowed to overlap, a vertex may be contained in several patches. The zoom-in windows in Fig. 3 show overlapping areas of selected patches. In this way, we can still keep the surface spatial structure and learn the mesh structures.
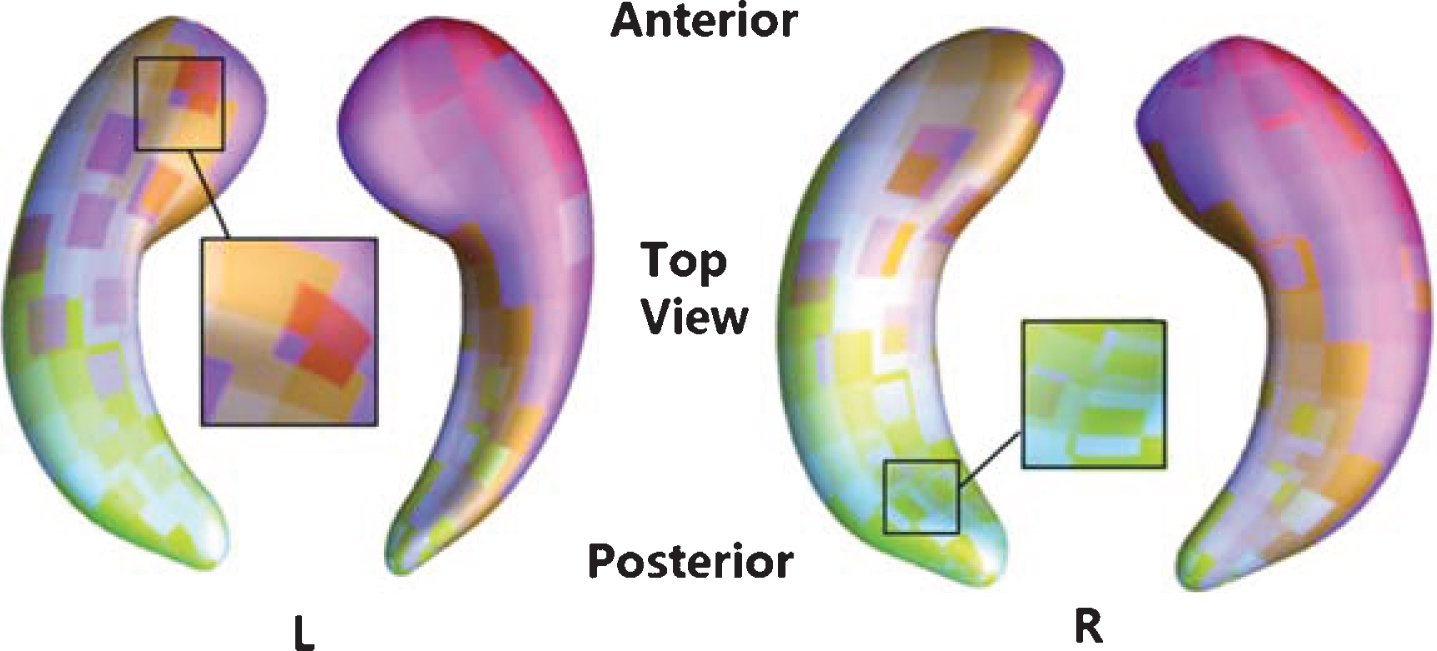
Visualization of selected surface patches on a pair of the hippocampal surfaces. In this figure, we show some randomly selected surface patches with different amounts of overlapping. The zoom-in pictures show some overlapping areas between surface patches. We generate a series of square windows on each side of hippocampus.
Further, we created surface mesh models of the lateral ventricles using our multi-atlas fluid image alignment (MAFIA) method that combines multiple fluid registrations to boost accuracy [48]. To model the lateral ventricular surfaces, we automatically located and introduced three cuts, based on the topology of the lateral ventricles, in which several horns are joined together at the ventricular “atrium” or “trigone” [6]. With the holomorphic flow segmentation method, each lateral ventricular surface was automatically partitioned into three pieces [46]. These three pieces are roughly three horns of the lateral ventricle: anterior horn, posterior horn, and inferior horn. The surface segmentation was done by tracing curves that went through the zero point and had equal parameter coordinates. Then we registered each segmented surface of the lateral ventricular surfaces across subjects using constrained harmonic maps and computed mTBM features. For each subject, a 308,247-dimensional mTBM statistics were computed from registered ventricular surfaces. We randomly generated a number of square windows (50×50) on each registered surface to obtain a collection of small surface patches with different amounts of overlaps, 1,713 image patches on each ventricular surface were chosen.
We adopted FreeSurfer [40] to compute cortical thickness on each point of cortical surfaces. For calculating cortical thickness, MR images were segmented into white matter and pial cortical surfaces using FreeSurfer. Then the cortical thickness was computed by deforming the white matter surface to the pial surface. The deformation distance was taken as the cortical thickness. A spherical parameterization for each pial surface was also produced with FreeSurfer. The spherical parameter surface and weighted spherical harmonics [49] were further used to register pial surfaces across subjects and each subject had the same dimension (161,800) cortical thickness. Finally, the spherical parameter surface was the canonical space from which patches were selected. Similar to our prior work [41], we computed circular patches on the cortical surface. Specifically, 1,798 patches of individual cortical thickness were chosen.
Among the three processing pipelines, FreeSurfer is publicly available and we have published our pipelines to compute both hippocampal and ventricular surface features on our web site (http://gsl.lab.asu.edu/software/). In the next section, we will take image patches extracted from the above three kinds of biomarkers as the input of the proposed CNN-MSCC method.
CNN with transfer learning
The architecture of a general CNN consists of the input layer, the output layer, and hidden layers between input and output layers. The input to the CNN is an image, and the outputs are class categories such as dementia or non-dementia. The hidden layers of a CNN consist of convolutional layers, pooling layers, fully connected layers, normalized layers, and activation function [50]. Convolutional layers are the necessary part of CNN and make a convolution operation on the input image, emulating an individual neuron perception of visual stimuli. Each unit (neuron) in a subsequent convolutional layer has local shift-invariant inter-connections with its receptive units in the preceding layer. These connections are trained by the back-propagating (BP) algorithm [51]. Pooling layers was introduced into the CNN for down-sampling outputs of the prior layer with max-pooling or average-pooling strategy [52]. Fully connected layers are usually added at the end of CNN where every neuron in fully connected neurons connects every neuron in the previous layer for generating a distribution over classes [53]. The sample size of neuroimaging data is typically small compared to those in computer vision, so transfer learning is proposed to overcome this problem. One strategy of transfer learning [26] is as follows: 1) using a feed-forward approach to fix the optimized weights in the lower levels (convolutional and pooling layers) trained from general images with large size; 2) retraining the upper levels (fully connected layers) with the BP algorithm; 3) using the fine-tuned CNN to perform medical image analysis.
Our first goal here is to explore whether the transfer learning framework of CNN can be generalized to biological image studies. In this study, we took AlexNet structure [22] as the initial CNN model, which contains 7 layers, including convolutional layers with fixed filter sizes (see Table 2). We employed rectified non-linearity, max-pooling on each layer in this model. We pre-trained the CNN model on the ImageNet dataset [54], containing millions of labeled natural images with thousands of categories, and removed the last fully-connected layer (this layer’s outputs are the 1000 class scores for a different task like ImageNet). The transferred CNN was used to extract high-level features from rescaled and resized brain surface patches of the training data. Finally, the fine-tuned CNN were used to refine feature maps of surface-based biomarkers of the test set [37]. We implemented the CNN model using the Caffe toolbox [55]. The network was trained on an Intel (R) Xeon (R) 48-core machine, with 2.50 GHZ processors, 256 GB of globally addressable memory, and a single Nvidia Tesla K40 GPU.
The architecture of pre-trained CNN used in this study
Multi-task stochastic coordinate coding
Feature maps from CNN are fed to our proposed MSCC algorithm. Given feature maps from T different tasks: {X1, X2, …, X
T
}, our objective is to learn a set of sparse codes {Z1, Z2,…, Z
T
} for each task where
Another solution is to construct the subjects {X
For the subject feature matrix X
The initialization of dictionaries in MSCC is critical to the entire learning process. We propose a random patch method to initialize the dictionaries from different tasks. The main idea is to randomly select l image patches from n subjects {x1, x2,…, x
n
} to construct
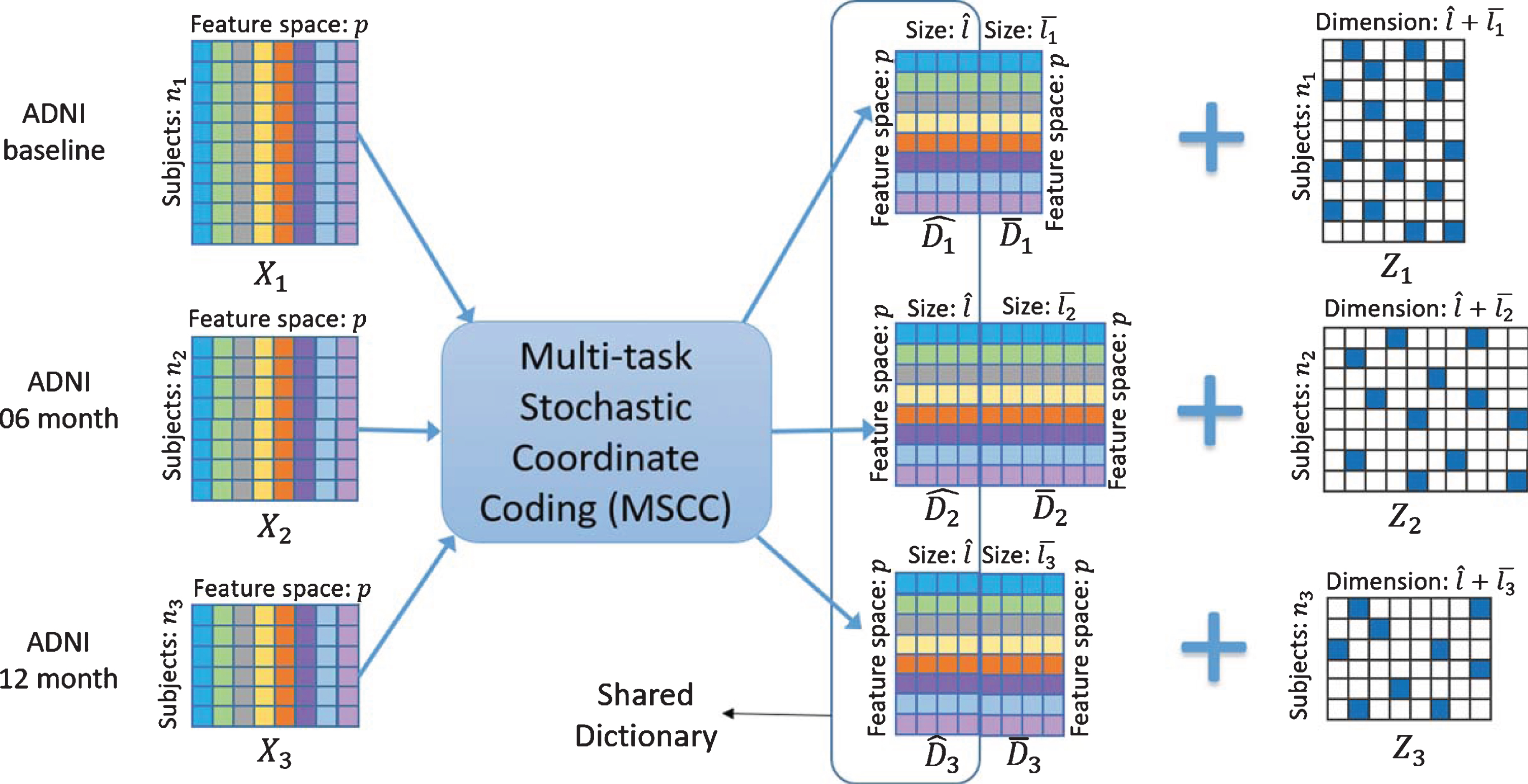
Illustration of the learning process of MSCC on ADNI datasets from multiple tasks.
After initializing dictionary D
t
for each time point, we set all the sparse codes Z
t
to be zero in the beginning. The key steps of MSCC are summarized in
After we pick an image patch x t (i) from the sample x t at the time point t, we fix the dictionary and update the sparse codes by following the ODL method [30]. Then the optimization problem we need to solve becomes the following equation:
It is known as the Lasso problem [43]. Coordinate descent [58] is known as one of the state-of-the-art methods for solving this problem. In this study, we perform the CCD to optimize Eq. (2). Empirically, the iteration may take thousands of steps to converge. It is time-consuming in the optimization process of dictionary learning. However, we observe that after a few steps, the support of the coordinates, i.e., the locations of the non-zero entries in Z
t
(i), becomes very stable, usually after less than ten steps. In this study, we perform P steps CCD to generate the non-zero index set Perform P steps CCD to update the locations of the non-zero entries Perform S steps CCD to update the
The detailed optimization procedure [32, 61] is reported in Supplementary Material B.
Performance evaluation protocol
To evaluate the proposed framework, we randomly split the data into training and testing sets using an 8 : 2 ratio, i.e., models were constructed on 80% of the data and evaluated on the remaining 20% of the data. We also used 10-fold cross validation to select key parameters and avoid data bias during the training. Lastly, we evaluated the overall prediction performance using normalized mean square error (nMSE), weighted correlation coefficient (wR), and root mean square error (rMSE) for task-specific regression performance measures [17]. The three performance measures are defined as follows:
For nMSE and wR, Y
i
is the ground truth of target task i and CNN-R: CNN learned surface feature without transfer learning, followed by Lasso regression. MSCC-R: The proposed multi-task dictionary learning algorithm followed by Lasso regression. OLSC-R: The single-task dictionary learning [30] followed by Lasso regression. cFSGL: A multi-task algorithm called convex fused sparse group Lasso [17]. L21: A multi-task algorithm called L2,1, norm regularization with least square loss [62]. Lasso: A single task method called Lasso regression [43]. Ridge: A single task method called Ridge regression [63].
Paired sample t-test was applied to compare performances (rMSE/nMSE and wR) between CNN-MSCC and seven other similar methods [64] and the statistical p values were corrected for false discovery rate (FDR) [65].
RESULTS
This section explains how to configure key parameters of the proposed system CNN-MSCC and provides performance comparisons between CNN-MSCC and other state-of-the-art methods.
We designed two different experiments to validate our proposed CNN-MSCC framework. In the first experiment (Experiment I), we applied CNN-MSCC to predict MMSE/ADAS-Cog scores of 24-months using HP image patches of baseline, 6-months, and 12-months. In the second experiment (Experiment II), we applied the CNN-MSCC to predict MMSE/ADAS-Cog scales of multi-time slots (6-months, 12-months, and 24-months) using image patches of baseline multi-ROIs (hippocampal/ventricle mTBM and cortical thickness). Comparison analyses were performed between CNN-MSCC and seven other similar methods in each experiment. To fit the pre-trained CNN model, patches of size 50×50 are extracted and resized to size of 227*227 input sample. There are either HP patches from multi-time slots (Experiment I) or three kinds of baseline structural patches (Experiment II). The image patch amount of each time point and structural measure are shown in Table 3.
The image patch amounts of two experimental datasets
Key parameter estimation
In this work, we estimate two key parameters of CNN-MSCC on longitudinal HP image patches and then use the optimized parameters throughout the paper.
The first key parameter is the amount pre-trained CNN layers for transferring learning. In this work, we aimed to get feature maps related with AD from image patch-based features using the well pre-trained CNN. With the transfer learning technique, the AlexNet architecture pre-trained on the ImageNet dataset [66] was tested on longitudinal HP image patches. CNN consists of multiple layers of feature maps, and each layer is a different representation of the input data. We used the HP image patches of three time points (baseline, 6-months, and 12-months) as inputs to predict MMSE/ADAS-Cog scales of 24-months. We studied their performances when working with different network layers (detailed in Table 2) of CNN-MSCC.
To verify the role of MSCC part, we also compared the performance of CNN-MSCC with the performance without MSCC part (CNN-R). The results are provided in Fig. 5. We observed that both CNN-MSCC and CNN-R with 6 network layers outperformed the others measured by rMSE. The discriminative power increases from the 4 to 6 layers, and then drops afterwards as the depth of network increases. One reasonable explanation about this observation is the lower layers do not fully capture the surface features and the higher layers captured features that overfit to the training image patches. Therefore, in this paper, we used the 6th layer’s features (4096) as the number of rows for all the dictionaries. Additionally, we also noted that CNN-MSCC outperformed CNN-R with different layer settings. It indicates that MSCC part helps to improve the prediction performance.

Comparison of 24-months’ MMSE/ADAS-Cog prediction models with different CNN layers (both with and without MSCC part—CNN-MSCC versus CNN-R), in terms of root mean square error (rMSE) on hippocampal patches of baseline, 6-months, and 12-months. MMSE, Mini-Mental State Examination; ADAS-Cog, Alzheimer’s Disease Assessment Scale-Cognitive Subscale; CNN, Convolutional Neural Network; MSCC, Multi-task Stochastic Coordinate Coding; CNN-R, CNN-Regression.
The second key parameter is the proportions of common and individual parts in the dictionary of MSCC algorithm. The dictionary of MSCC algorithm includes common and individual parts for considering the constant and varied features of multi-task learning. It is necessary to evaluate the optimal proportions of the two parts in the dictionary. We still used the longitudinal HP image patches of three time points (baseline, 6-months, and 12-months) as inputs to predict MMSE/ADAS-Cog scales of 24-months and adopted 6-layers of CNN in the proposed algorithm. We set the dictionary size to be 2000 and partitioned the dictionary by different proportions: 250 : 1750, 500 : 1500, 1000 : 1000, 1500 : 500, and 1750 : 250, where the left number is the size of common part while the right number is the size of individual part for each dictionary. To verify the role of CNN part of the proposed method, we also calculated the performance of an algorithm MSCC-R without the CNN part. Figure 6 shows the rMSEs as the performance measures of two methods MSCC-R and CNN-MSCC on the longitudinal HP data. The rMSEs of MMSE/ADAS-Cog scales are lowest when we divide the dictionary in half. So, in all experiments, we use the ratio of 1000 : 1000 as the proportion of common and individual parts for all the dictionaries. Additionally, we observed that CNN-MSCC outperformed MSCC-R with different dictionary proportion settings. This indicates that CNN part also helps to improve the prediction performance. So, the combination of optimized CNN and MSCC is expected to have a promising performance on AD progression prediction. In the follow-up experiments, we will further validate this expectation.
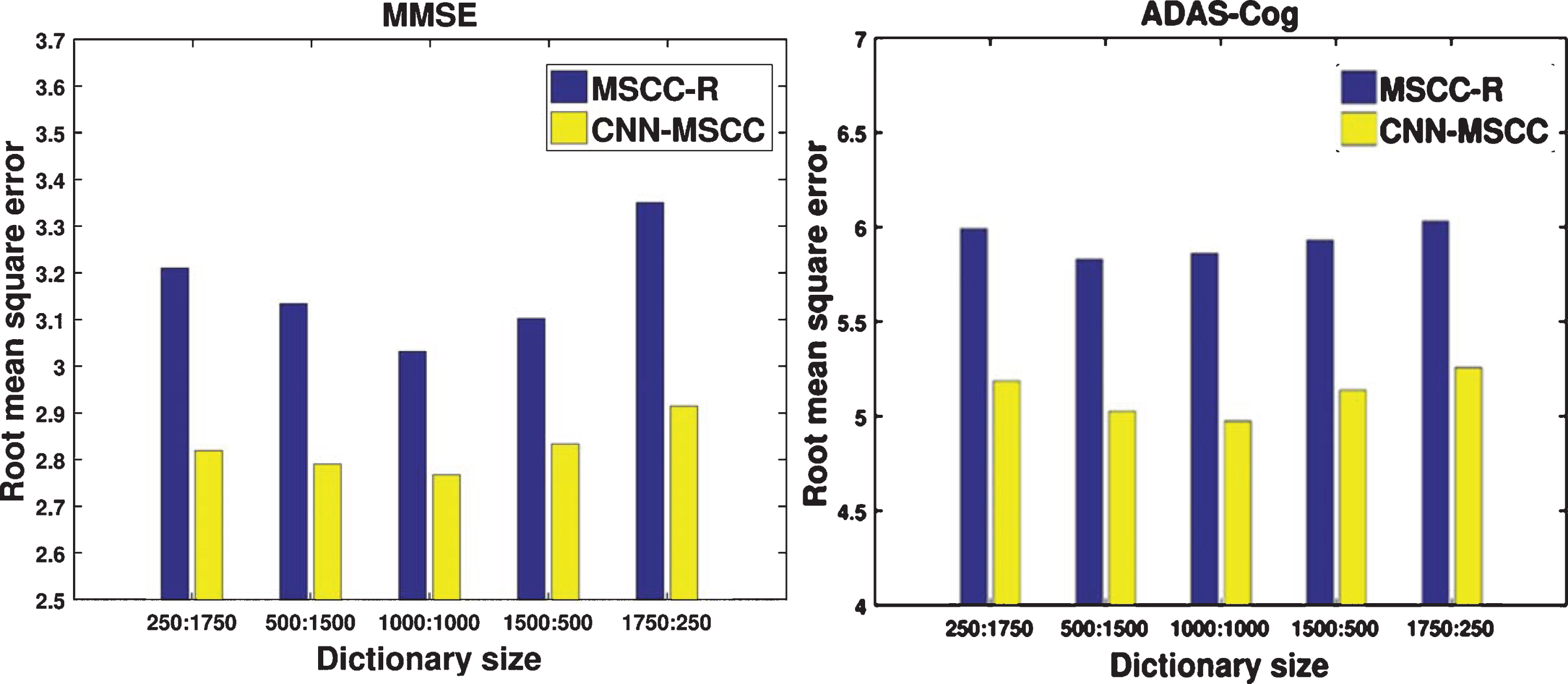
Comparison of 24-months’ MMSE/ADAS-Cog prediction performances with different dictionary settings of MSCC, in terms of root mean square error (rMSE) on hippocampal patches of baseline, 6-months and 12-months. MMSE, Mini-Mental State Examination; ADAS-Cog, Alzheimer’s Disease Assessment Scale-Cognitive Subscale; CNN, Convolutional Neural Network; MSCC-R, Multi-task Stochastic Coordinate Coding Regression.
Experiment I: CNN-MSCC on longitudinal HP surface patch features
Studies demonstrate that the hippocampal structure is a primary biomarker in the longitudinal structural MRI analysis of AD progression [11, 67–70] and significant hippocampal deformations related with AD pathology can be detected even before observing obviously lower MMSE/ADAS-Cog scores [10, 72]. In Experiment I, we used previous longitudinal HP patches (baseline, 6-months, and 12-months) to predict future MMSE/ADAS-Cog scales at the 24-months point. Image patches with size 50×50 were extracted from individual hippocampal mTBM feature maps of three tasks (baseline, 6-months, and 12-months), and we had 220968, 193512, and 178464 individual HP image patches for three tasks respectively. Using these image patches as the input of CNN-MSCC, we got three sets of feature sparse codes of baseline, 6-months, and 12-months. We used individual 12-months sparse codes learned by CNN-MSCC as Lasso design matrices to train and test the 24-months MMSE/ADAS-Cog scales with 8 : 2 subjects ratio, because the 12-months sparse codes contain both common features along with time points (baseline, 6-months, and 12-months) and task-specific features of 12-months. Figure 7 shows scatter plots of CNN-MSCC for the predicted values versus the actual values for MMSE/ADAS-Cog on the testing data.
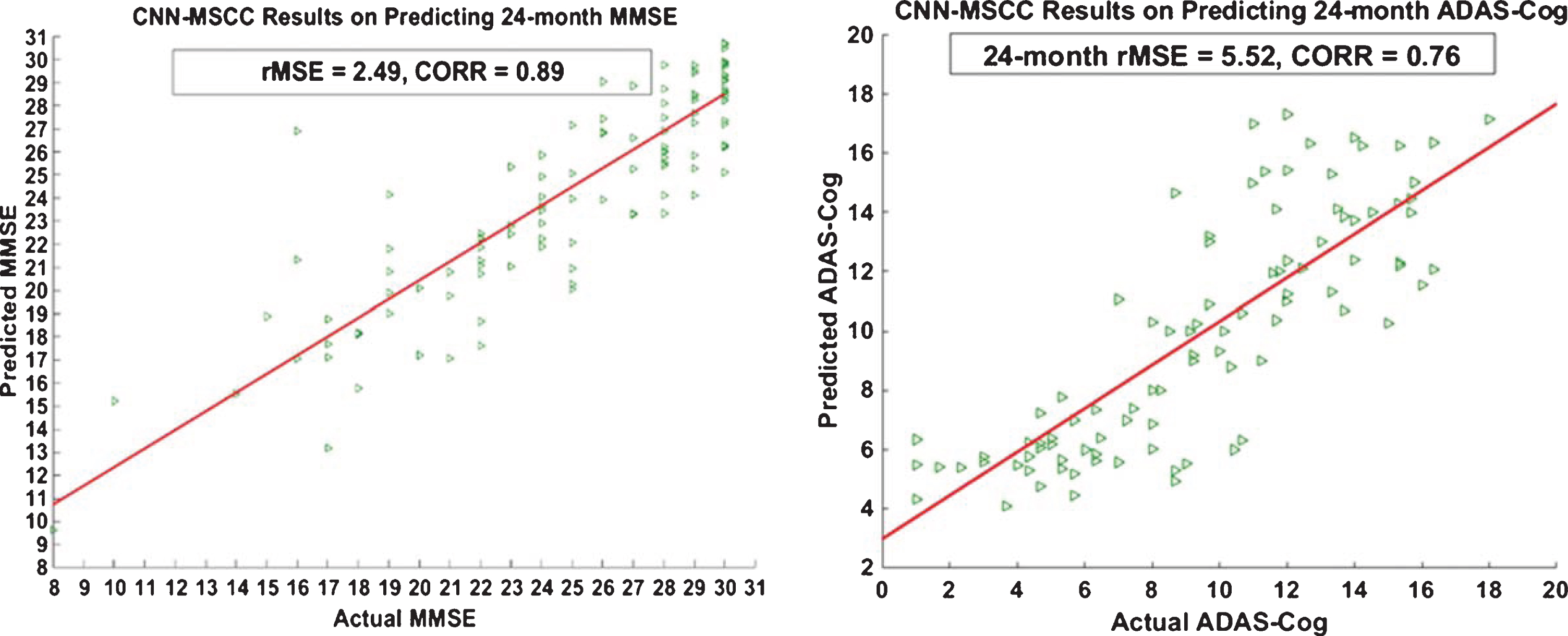
Scatter plots of actual versus predicted MMSE/ADAS-cog values of 24-months using CNN-MSCC based on hippocampal patches of baseline, 6-months, and 12-months. MMSE, Mini-Mental State Examination; ADAS-Cog, Alzheimer’s Disease Assessment Scale-Cognitive Subscale; CNN, Convolutional Neural Network; MSCC, Multi-task Stochastic Coordinate Coding; rMSE, root mean square error; CORR, Correlation coefficients.
To estimate the performance of CNN-MSCC on this application, we randomly split the training data and testing data as the 8 : 2 ratio and ran 40 iterations of each method, then we could apply paired sample t-test with lower-tailed hypothesis to compare the rMSEs performances of CNN-MSCC with seven other similar methods on the longitudinal HP dataset. All the p values were corrected by FDR. The rMSEs of 24-months MMSE/ADAS-Cog scale predictions are shown in Fig. 8. Statistical results indicate that, for MMSE scale predictions, CNN-MSCC has significantly smaller rMSEs (p < 0.05) compared to CNN-R, OLSC-R, cFSGL, L21, Lasso, and Ridge, while there is no significant rMSEs difference (p = 0.3459) for CNN-MSCC versus MSCC-R. For ADAS-Cog scale predictions, CNN-MSCC has significantly smaller rMSEs (p < 0.05) compared to all the other methods. All the eight methods demonstrate that the rMSEs of MMSE predictions are better than ADAS-Cog prediction.
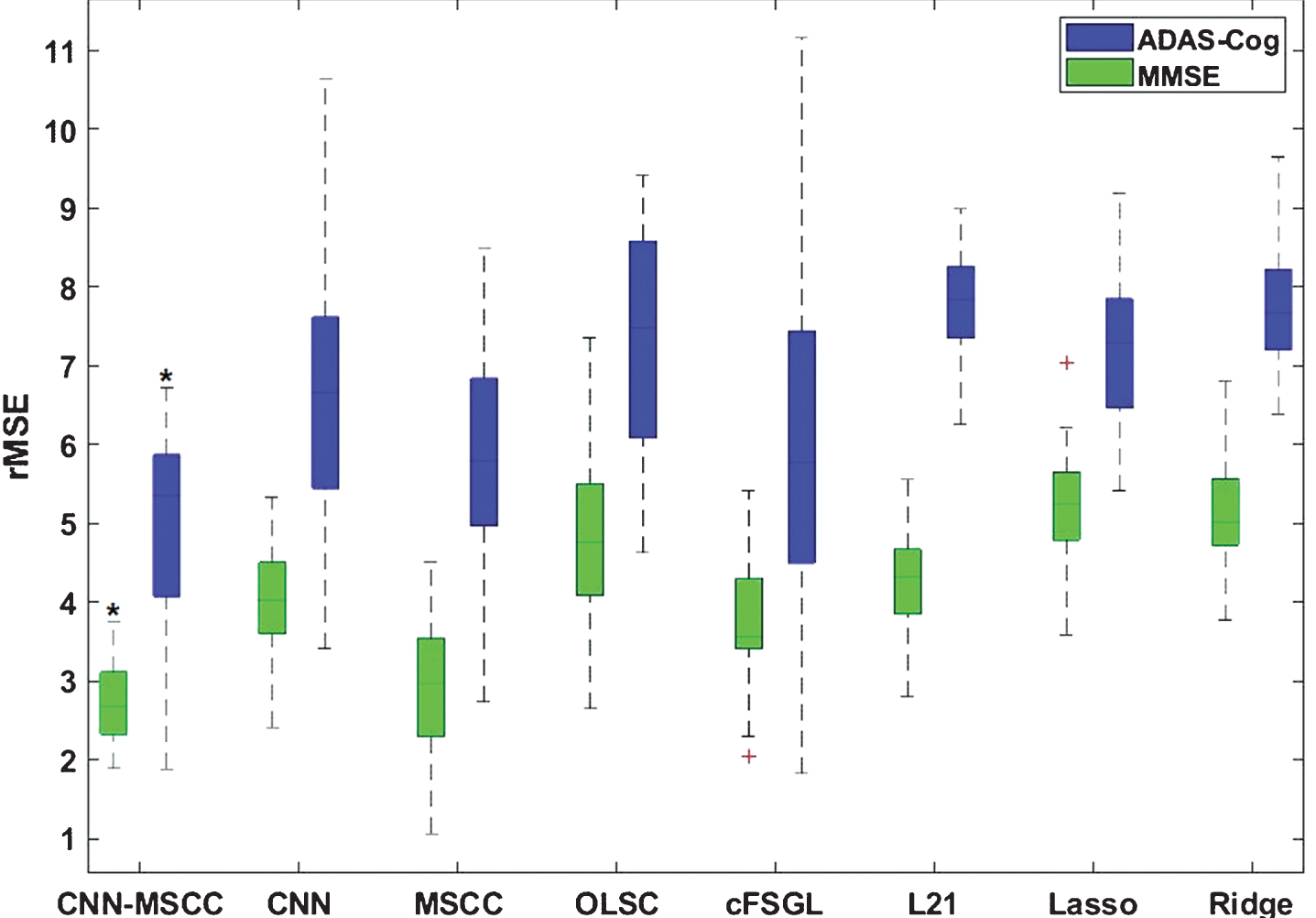
Comparison analysis of our proposed method and seven other similar methods on 24-months MMSE/ADAS-Cog scale prediction performances using hippocampal image patches of baseline, 6-months, and 12-months in terms of root mean square error (rMSE). Paired sample t-test was applied to estimate the significant outperformances of the proposed method CNN-MSCC. The asterisk above green boxplot shows that, for MMSE scale predictions, CNN-MSCC has significantly smaller (p < 0.05, corrected) rMSEs compared to CNN-R, OLSC-R, cFSGL, L21, Lasso, and Ridge, while there is no significant rMSEs difference for the contrast of CNN-MSCC versus MSCC-R. The asterisk above blue boxplot shows that, for ADAS-Cog scale predictions, CNN-MSCC has significantly smaller rMSEs (p < 0.05, corrected) compared to all other methods.
Experiment II: CNN-MSCC on multiple baseline cortical structural surface patch features
Ventricular mTBM and cortical thickness are another two important biomarkers for tracking the AD progression [6, 73]. In Experiment II, we used the baseline structural image patches, including hippocampal mTBM features, ventricular mTBM features, and cortical thickness of 837 subjects to predict the MMSE/ADAS-Cog variations of future time points (6-months, 12-months, and 24-months). After preprocessing these MRI data, we have 220968, 2867562, and 1504926 individual image patches corresponding to three kinds of baseline structural measures respectively. Using the CNN-MSCC framework, we got three sets of feature sparse codes. Since each subject has three sparse codes, we combined these three sparse codes as Lasso design matrix to train and test the 6-months, 12-months, and 24-months MMSE/ADAS-Cog scales with 8 : 2 subjects’ ratio. This process was repeated 40 times. Figure 9 shows the boxplots of wRs between the predicted and the actual MMSE/ADAS-Cog scales of 6-months, 12-months, and 24-months. Using paired t-test with higher-tailed hypothesis between wRs of different time points, we found wRs on MMSE/ADAS-Cog score predictions of 24-months are significantly higher (p < 0.05) than wRs of 6-months and 12-months. These improved wRs on 24-months benefited from MSCC method to iteratively learn features from previous time points.

Weighted correlation coefficient (wR) between predicted and actual MMSE/ADAS-Cog scales of 6-months, 12-months, and 24-months (M06, M12, and M24) on testing data using CNN-MSCC based on baseline multi-cortical image batches. Paired sample t-test was applied to estimate the significant outperformances on MMSE/ADAS-Cog scale predictions of 24-months. The asterisks above blue boxplots show that wRs on MMSE/ADAS-cog score predictions of 24-months are significantly higher (p < 0.05) than wRs of 6-months and 12-months.
Then we further compared our results with those of seven other state-of-the-art methods on the baseline multi-cortical dataset. Similarly, as in previous experiments, we randomly split the baseline training data and testing data as the 8 : 2 ratio and ran 40 iterations of each method, then we could apply paired sample t-test with lower-tailed hypothesis to compare the rMSE/nMSE performances and with higher-tailed hypothesis to compare wR performances of CNN-MSCC with seven other similar methods. Figure 10 shows the comparison results of our proposed method and seven other similar methods on longitudinal MMSE/ADAS-Cog prediction performances using baseline image patches of multiple ROIs in terms of normalized mean square error (nMSE, see Fig. 10a), weighted correlation coefficient (wR, see Fig. 10b) and root mean square error (rMSE, see Fig. 10c) at 6-months, 12-months, and 24-months (M06, M12, and M24). With paired sample t-test and FDR correction, we observed CNN-MSCC significantly outperform other similar methods with smaller (p < 0.05, corrected) rMSEs/nMSEs and higher (p < 0.05, corrected) wRs on future MMSE/ADAS-Cog scale predictions. Additionally, all the methods show apparently lower nMSE/rMSE when predict MMSE scales compared to predict ADAS-Cog scales. That is, neuroimaging features have closer relationship with MMSE scales compared to ADAS-Cog scales. These results support our hypothesis that a combination of features from multiple ROIs may enhance the statistical power in future cognitive measure regression.
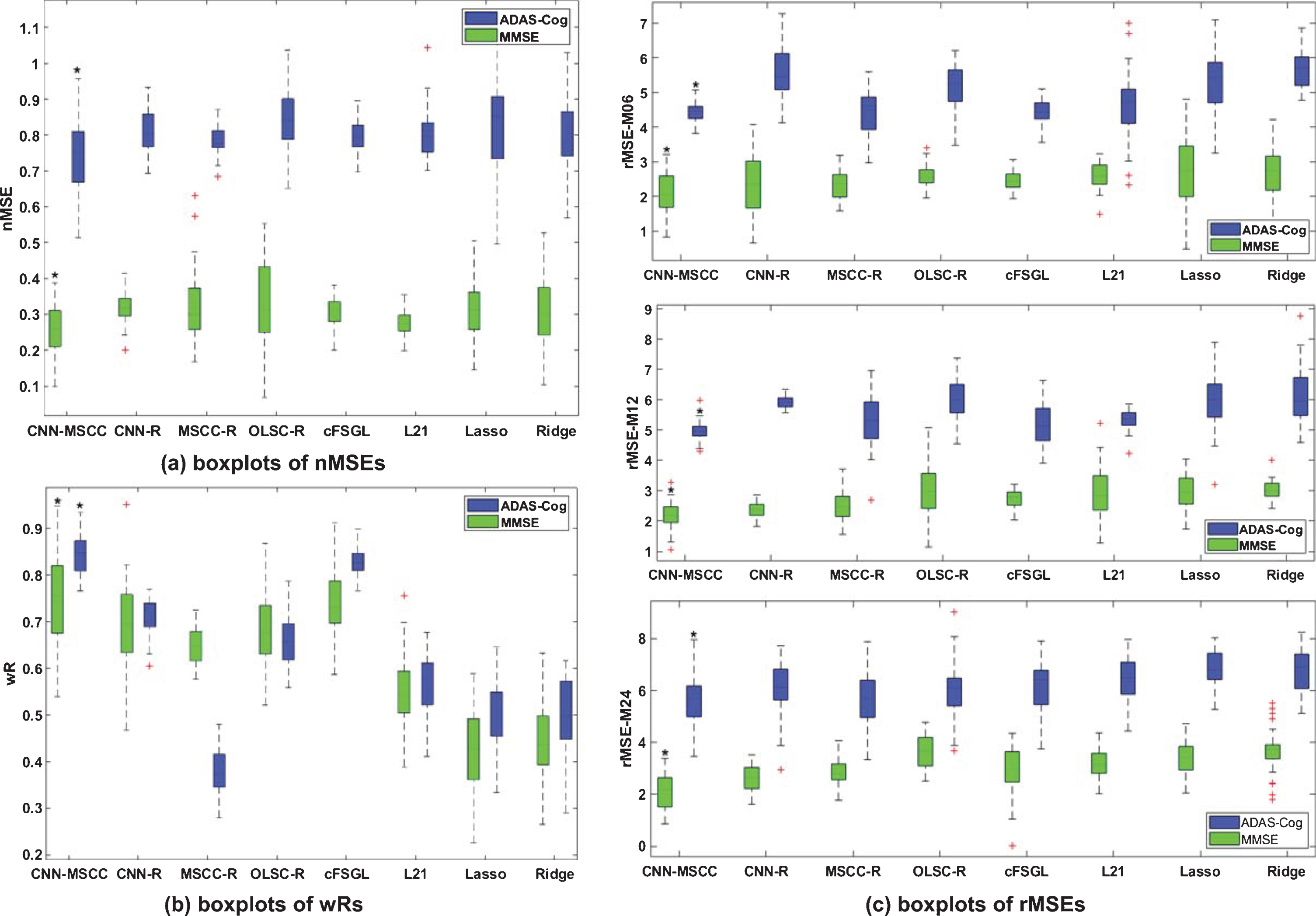
Comparison analysis of CNN-MSCC and seven other similar methods on longitudinal MMSE/ADAS-Cog prediction performances using baseline image patches of multiple ROIs in terms of normalized mean square error (nMSE) (a), weighted correlation coefficient (wR) (b), and root mean square error (rMSE) at 6-months, 12-months, and 24-months (M06, M12, and M24) (c). The asterisks above green boxplots and blue boxplots show that, for MMSE/ADAS-Cog scale predictions, CNN-MSCC has significantly smaller nMSEs/rMSEs (p < 0.05, corrected), and larger wRs (p < 0.05, corrected) compared to all other seven similar methods.
Sex/gender is one of the strongest predictors of AD, and women have twofold increased risk of AD than men after 65 years old [74, 75]. We applied CNN-MSCC to predict future MMSE/ADAS-Cog scales of males and females using baseline multi-task biomarkers. Paired sample t-test was applied to estimate performance differences between male and female groups. We observe that the female group has significantly smaller rMSEs (p < 0.05) on MMSE/ADAS-Cog scale predictions at 6-months compared to the male group, while no statistical difference is observed on rMSEs with 12-months and 24-months prediction and the overall nMSE and wR values (see Fig. 11). It may demonstrate that CNN-MSCC has a slightly higher effect size to predict female MMSE/ADAS-Cog scales than the male group. Our research show that female may have stronger connections between structural changes and future cognitive decline. It may provide some evidence supporting the existing research [74–76] that reported the female is more vulnerable to AD than the male.
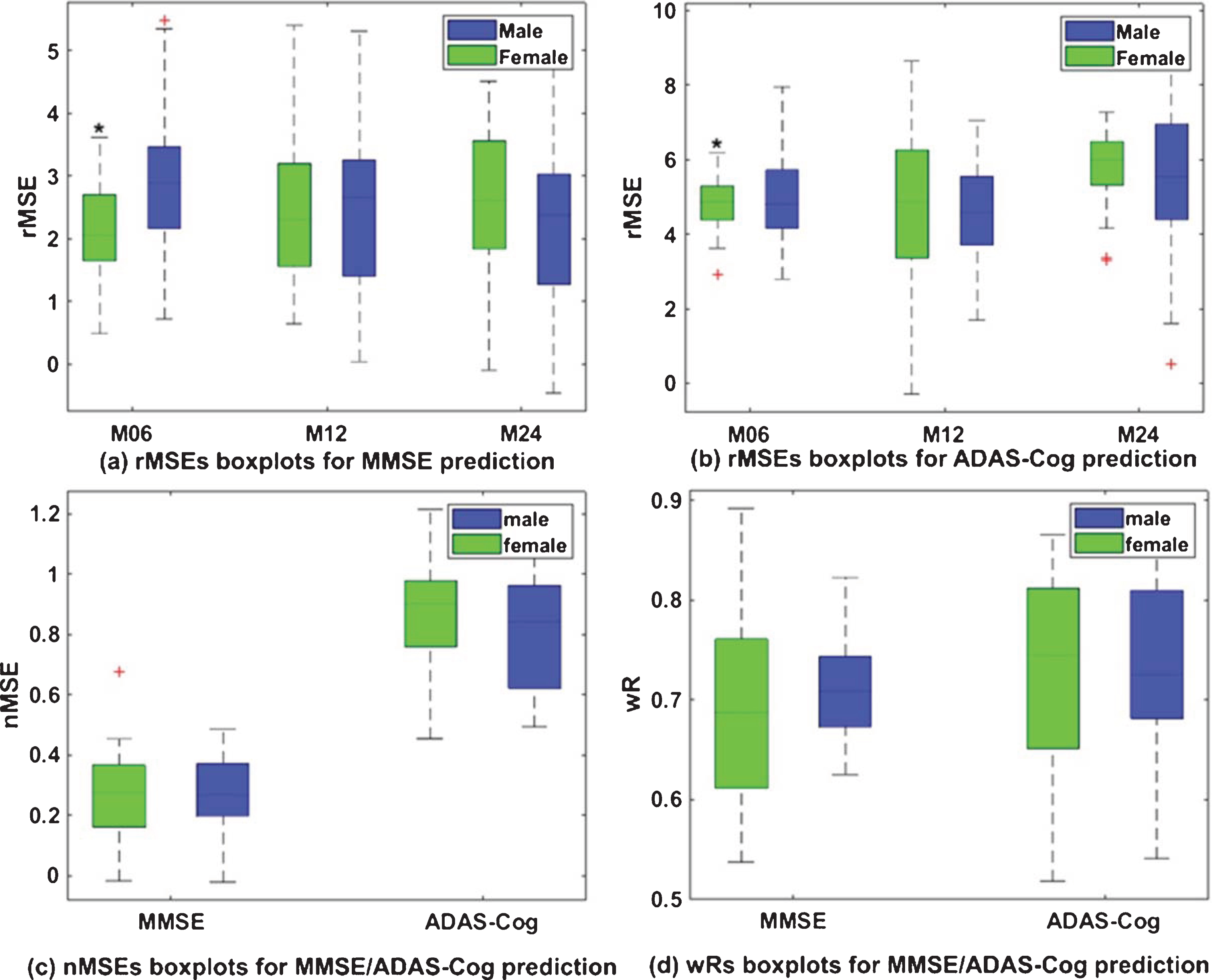
MMSE/ADAS-Cog prediction performances of male and female groups using the proposed CNN-MSCC method and baseline patches of multiple ROIs in terms of root mean square error (rMSE) at 6-months, 12-months, and 24-months (a) and (b), normalized mean square error (nMSE) (c), and weighted correlation coefficient (wR) (d). The asterisks above green boxplots in (a) and (b) show that female group have significantly smaller rMSEs (p < 0.05) on MMSE/ADAS-Cog scale predictions at 6-months compared to the male group.
DISCUSSION
This work has two main findings. First, we have demonstrated a novel system that integrates deep transfer learning and multi-task sparse coding research for enhanced AD progression modeling. CNN [24, 25] is good at extracting accurate neuroimaging characteristics of special neurodegenerative disease and the extracted neuroimaging features are in a high dimension as opposed to small sample size as known as “large p, small n” problem. While our proposed multi-task learning method MSCC can represent these high dimensional features and jointly analyze multi-task sparse features. One of the major discoveries of the current work is that the integration of both methods achieves improved statistical power. To the best of our knowledge, CNN-MSCC is the first deep model transfer learning from the large scale annotated natural images to brain surface statistics. Second, the surface mTBM, which is computed from the conformal grid and carries rich information on local surface geometry, is applicable to deep models for AD progressive prediction. Although surface-based morphometry achieved great success in population-based analyses to discover the general trend of disease burden and progression [6, 77–79], few studies have investigated the use of surface-based morphometry features for brain disease diagnosis on an individual basis [80–82]. This work validated the feasibility of surface mTBM [83], as imaging biomarkers for prediction of future MMSE/ADAS-Cog scales decline. This discovery is in line with several of our prior studies [6, 80]. The newly combined surface statistics practically encode a great deal of neighboring intrinsic geometry information that would otherwise be inaccessible or overlooked. The surface-based computer-aided diagnosis research may become more powerful by adopting these patch analysis-based multivariate statistics.
CNNs are considered as one of the most successful deep models for identifying, classifying, and quantifying patterns in medical images [53, 84]. There are still relatively few CNN studies on AD diagnosis due to limited training data. Transfer learning technique has proven to be a highly effective technique for addressing a lack of data in AD research domain and it leverages data from another domain. ImageNet includes millions of labeled natural images [54]. However, because of the substantial differences between natural and medical images, transfer learning is unsuitable to be applied directly [66]. Studies of [26, 66] demonstrated that fine-tuning the transferred CNNs on medical images could decrease overfitting of the pre-trained CNNs and was a practical way to reach the best performance for the medical image application at hand. Therefore, in this study, we pre-trained CNN structures on ImageNet database. After we pre-trained the CNN model on the ImageNet dataset, we removed the last fully connected layer (this layer’s outputs are the 1000 class scores for ImageNet). The dimension of ImageNet image is 227*227*3, while the dimension of our mTBM patch features is 50*50*3. We rescaled the surface mesh features to 227*227*3. Then the CNN on the surface mesh features was fine-tuned. Our results demonstrate that the transferred CNNs with optimal layers are capable to extract higher level features from image-patches of biomarkers and gain performance improvement for AD progressing modeling.
After using CNN with transfer learning technique, image patches of biomarkers were transformed to high dimensional feature maps. On one hand, to address the problem of high dimensional feature maps derived from small number of image patches, it is necessary to apply the sparse coding method to generate a small number of basis vectors termed dictionary to represent high dimensional features effectively and concisely [30, 85]. On the other hand, multi-task sparse features contain complementary information for tracking AD progression measured by MMSE/ADAS-Cog scales [17, 18], so we need to effectively integrate these features together. Previous studies concatenated different kinds of features into a longer feature vector or applied multi-task learning method to fuse them together [18]. The study of [86, 87] reported that multi-task learning method performed better than feature concatenation method. However, if there is no latent common information shared by the same subject during different time points [17], only one dictionary from multiple-kernel method is not enough to show the variation among features from different time points. To address this challenge, we integrate the idea of multi-task learning into the online dictionary learning method [17, 88] and propose the novel dictionary learning algorithm MSCC to learn multi-task sparse codes of subjects.
In our proposed model, we innovatively introduce the common part of dictionaries to capture the interrelationships between multi-task learning. As expected, CNN-MSCC outperformed several similar methods. To verify the common part role of multi-task dictionary, we tested the performances of CNN-MSCC versus CNN-separate task stochastic coordinate coding (CNN-STSC) that is without the common dictionary part. As shown in Fig. 12, CNN-MSCC with common dictionary part outperforms CNN-STSC without common dictionary part with significantly smaller rMSEs (p < 0.05) on MMSE scale predictions at three time points, with significantly smaller rMSEs (p < 0.05) on ADAS-Cog scale predictions at 6-months and 12-months, and with significantly larger wRs (p < 0.05) on ADAS-Cog scale predictions. The experimental results validated the gained statistical power by adding the common part of dictionaries. However, we did not observe significant rMSE differences on ADAS-Cog scale predictions at 24-months. Neither did we have significant nMSE differences on MMSE/ADAS-Cog scale predictions, nor significant wRs differences on MMSE scale predictions. MMSE/ADAS-Cog scale predictions of 6-months are based on the common and individual sparse features at baseline, while MMSE/ADAS-Cog scales of 12-months are based on the updated common sparse features along with time points (baseline and 6-months) and task-specific features of 6-months. Similarly, MMSE/ADAS-Cog scales of 24-months are based on the updated common sparse features along with time points (baseline, 6-months, and 12-months) and task-specific features of 12-months. This accumulate learning capability makes the prediction performances at 6-months, 12-months, and 24-months stable.
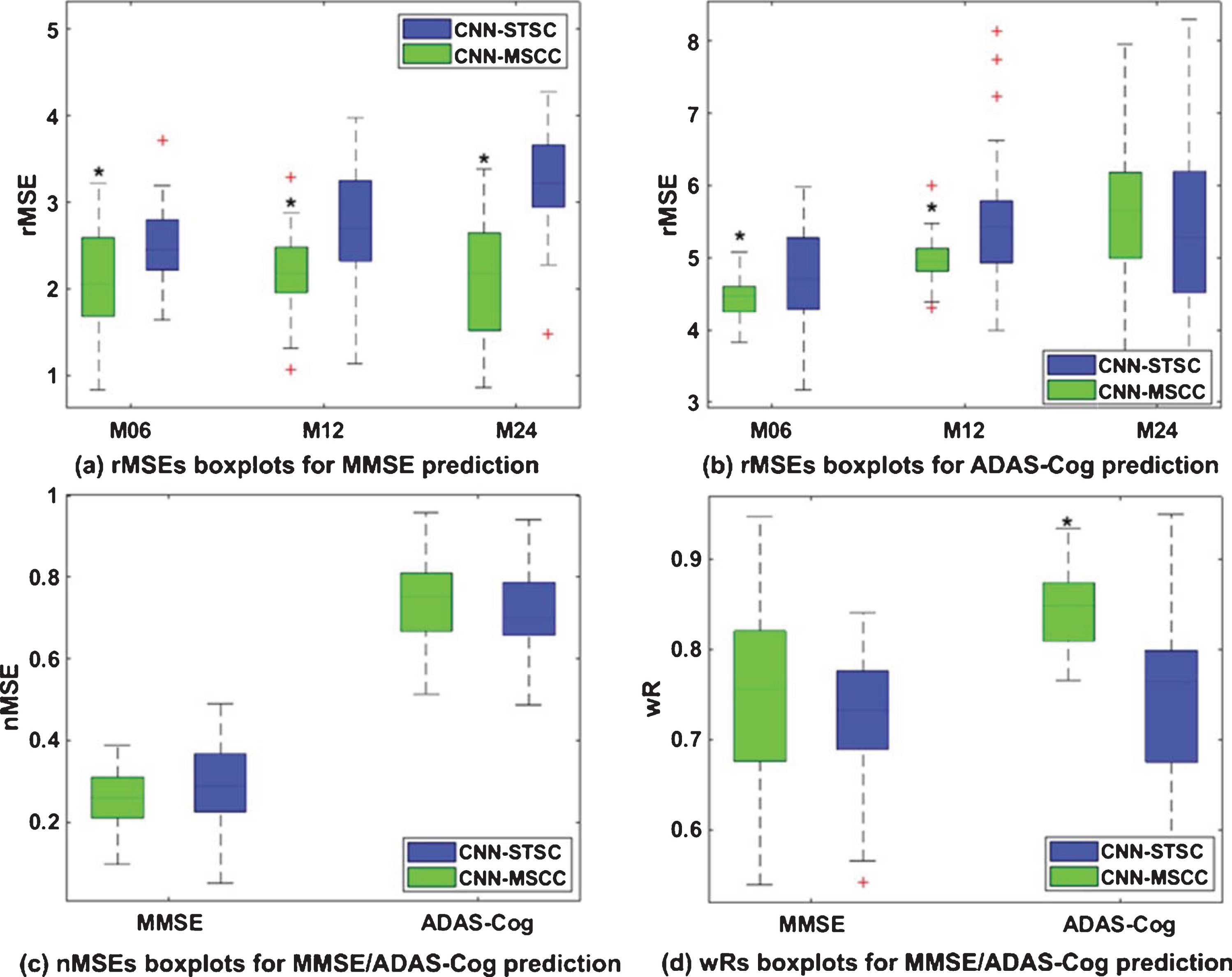
MMSE/ADAS-Cog prediction performances of CNN-MSCC and CNN-STSC on baseline patches of multiple ROIs in terms of root mean square error (rMSE) at 6-months, 12-months, and 24-months (a) and (b), normalized mean square error (nMSE) (c), and weighted correlation coefficient (wR) (d). The asterisks above green boxplots in (a) show that CNN-MSCC has significantly smaller rMSEs (p < 0.05) on MMSE scale predictions at three time points compared to CNN-STSC. The asterisks above green boxplots in (b) show that CNN-MSCC has significantly smaller rMSEs (p < 0.05) on ADAS-Cog scale predictions at 6-months and 12-months compared to CNN-STSC. The asterisk above the green boxplot in (d) shows that CNN-MSCC has significantly larger wRs (p < 0.05) on ADAS-Cog scale predictions compared to CNN-STSC.
Despite the promising experimental results, four caveats remain. First, this work aims to propose one comprehensive framework which includes CNN structure for image feature extractions, multi-task sparse coding algorithm for feature fusions and Lasso regression model for future cognitive scale predictions. We select AlexNet as the CNN part, the proposed automatic system outperformed 7 similar methods. In future work we would like to make comparison analysis of our proposed CNN-MSCC system based on kinds of well-known CNN structures, e.g., [89, 90], and expect the performance will be further improved. Second, transfer learning is still empirical and it lacks theoretical interpretations about what to transfer, how to transfer, and when to transfer [91]. It is still a mystery that machine learning systems can work on brain images while they were trained in other image domains. Even so, our work still demonstrated that the optimized CNN-MSCC model may extract reliable features for AD progression prediction and validate the feasibility to apply deep models on surface-based neuroimaging features. Third, as one of the useful data augmentation methods, transfer learning is not the only one to apply deep models in a small size dataset. Other ongoing methods, such as one-short/few shot learning, horizontal flips, random crops, and principal component analysis (PCA) are also promising ways to go [92–96]. These strategies have been shown to capture important characteristics of natural and medical images. In our future work, we will keep exploring other data augmentation techniques to build deep neural networks with our surface features and compare their performances with the current transfer learning strategy. Fourth, our current model does not consider the temporal information, another work from our group enforces the sparsity of the sparse codebook representation by representing neighboring feature resemblance to improve the smoothness of prediction over the longitudinal neighboring time points. In future work, we will try to study the integration of the resemblant model with CNN and compare its performance with our current results.
Conclusions
This study proposed a novel deep learning system, CNN-MSCC, for AD clinical score predictions using multi-task image patches. By leveraging the transfer learning, we were able to apply a pre-trained CNN models to study brain images. We also innovatively proposed a multi-task stochastic coordinate coding (MSCC) algorithm for the multi-task learning which may integrate patched-based brain surface features from longitudinal or multiple ROIs. Our preliminary experimental results and performance analyses showed that our proposed system may outperform other similar methods and showed a promising accuracy for future MMSE/ADAS-Cog scale predictions. The proposed system may aid in expediting the diagnosis of AD progression, facilitating earlier clinical intervention and resulting in improved clinical outcomes.
In future, we will continue our deep model-based brain imaging research [97], optimize our methods and investigate their capability on longitudinal brain multimodality imaging datasets. There are various opportunities to generalize and enhance our current study for AD research. For example, there are many other neuroimaging biomarkers from modalities such as PET, functional MRI, magnetoencephalography, and electroencephalogram, which have been widely studied for AD diagnosis [98–100]. Since our proposed system is capable to refine and fuse features from multi-task biomarkers so we may also fuse these data in our system. The current work applied the proposed CNN-MSCC model to predict AD progression measured by MMSE/ADAS-Cog scales successfully. We may investigate more AD clinical assessments, such as Functional Assessment Questionnaire, the Clock Test, and the Rey Auditory Verbal Learning Test [101]. The gained experience may shed new lights the correlation between brain images and various AD clinical assessments and eventually help set up standards for subject recruitments in AD clinical trials [102].
Footnotes
ACKNOWLEDGMENTS
Algorithm development and image analysis for this study was funded, in part, by the National Institute on Aging (RF1AG051710 to QD, JZ and YW, R01EB025032 to NL and YW, R01AG031581 and P30AG19610 to RJC), the National Science Foundation (IIS-1421165 to JZ and YW), and Arizona Alzheimer’s Consortium. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Tesla K40 GPU used for this research.
Data collection and sharing for this project was funded by the ADNI (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (http://www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.