
Abstract
According to the article, locating moisture within the walls of buildings using electrical impedance tomography is discussed in detail. The algorithmic approach, whose role is to convert the input measurements into images, received excellent attention during the development process. Numerous models have been trained to generate tomographic images based on individual pixels in a given image based on machine learning methods. An array of categorisation data was then generated, which enabled the development of a classification model to solve the problem of optimal model selection for a given point on the screen. It was achieved in this manner by developing a pixel-oriented ensemble model (POE), the goal of which is to provide tomographic reconstructions of at least the same quality as homogeneous algorithmic approaches. Artificial neural networks (ANN), linear regression (LR), and the long short-term memory network (LSTM) were employed in the current research to get homogeneous machine learning results. An image reconstruction algorithm such as the ANN or the LR reconstructs the image pixel by pixel, which means that a different prediction model is trained for each image pixel. In the case of LSTM, a single network is responsible for creating the entire image. Then, using the POE algorithm, the best reconstruction method was fitted to each pixel of the output image while considering the measurement scenario provided to the program. As a result, each measurement consequences in a unique assignment of reconstructive procedures to individual pixels, which is different for each measurement. It is the capacity to maximise the selection of a prediction model while considering both a given pixel and a specific measurement vector that distinguishes the provided POE concept from other approaches.
Keywords
Introduction
The research described in this paper is motivated by the need to improve the methods of imaging the walls’ interior to detect areas of increased humidity. The most common reasons for damp walls caused by water infiltration from the outside are inadequate insulation and foundations, roof leakage, an inadequate rainwater drainage system, and deficiencies in sheet metal work. The primary cause of moisture problems inside a building is inadequate thermal insulation of the walls, which allows moisture to accumulate and not be discharged to the outside. In the winter, moisture condenses on frozen walls due to the warmer indoor air. Additionally, inadequate ventilation of the rooms may result in residual moisture, which creates an unpleasant microclimate that is unhealthy for the occupants. Inadequate foundation insulation frequently results in moisture penetration into the walls. It occurs due to poorly drained ground or rainwater seeping through horizontal or vertical insulation leaks. Changes in groundwater levels may occur due to a capillary rise of moisture from the ground or as a result of direct or indirect rainwater action. Water that has permeated the wall during the winter months freezes, increasing the volume. It may result in the collapse of the building’s foundations and partitions. In general, groundwater is not chemically neutral. It contains dissolved substances, most frequently chlorides, sulphates, and nitrates, potentially toxic chemically. Capillary rise allows water with dissolved compounds to reach the higher parts of the walls, causing salt blooms, discolouration, peeling of paint coatings, and plaster peeling. Chemical corrosion may be caused by dissolved chemical substances from the ground or, for example, from preparations protecting the roof truss. Corrosion caused by biological organisms is just as dangerous.
Additionally, the damp walls (both inside and outside) provide an ideal environment for the growth of fungi and mould. All of this contributes to the walls’ unsightliness. Additionally, the materials that comprise the structure of the building, i.e., the so-called biodeterioration of concrete, glass, bricks, mortars, and wood, among others, Moisture in building walls affect the health of occupants, as the presence of mould and fungi in rooms can cause allergies and respiratory diseases.
The currently used methods of measuring the moisture inside the porous brick walls enable point measurements. However, there are no methods to visualise the moisture distribution inside the walls [1]. With the help of tomography, it can create 2D and 3D models from the measurements. Moisture remaining inside the walls of buildings has many negative effects, which concern both the material, construction, aesthetic, and ecological spheres and issues related to the health of people staying in damp rooms [2,3]. The adverse effects include a decrease in the thermal insulation of wet materials, a decrease in the strength of materials and the load-bearing capacity of masonry structural elements, biological corrosion, erosive processes associated with salt-action, an increase in repair costs, and an increased risk of respiratory diseases [3–5].
Electrical impedance tomography (EIT) is a type of tomography suitable for creating visualisations of moisture areas in walls [6]. This feature distinguishes tomography from known point methods, e.g., gravimetric, dielectric or microwave [7]. The gravimetric method as an invasive method is considered the most accurate, but it is a destructive method. For this reason, it cannot be used, for example, in historical buildings that are subject to legal protection. The element that distinguishes tomography from other methods is the goal it pursues. Therefore, the purpose of tomography is not to precisely (in per cent) determine the water content at individual points of the tested wall. Instead, tomography enables the imaging of wet areas against a dry background. Apart from the software, it needs a high-quality tomograph consisting of electrodes and electronic systems to perform tomographic reconstructions. There are many kinds of tomography, such as computed tomography (CT) [8], electrical capacitance tomography (ECT) [9–14], electrical resistivity tomography (ERT) [15–17], X-rays [18], ultrasound [19], magnetism [20–22], visible light [23], etc. This work deals with software that transforms measurement data into the colours of pixels (finite elements) that make up the reconstruction images. This problem is called ill-posed [24,25]. From the algorithmic point of view, tomography uses direct and iterative methods, often related to machine learning. The direct methods include Total Variation [26], Level Set [27], Gauss-Newton with Tikhonov or Laplace regularisation [3], and others. Machine learning methods include Logistic Regression [28], Elastic Net [3,26], Least Absolute Shrinkage and Selection Operator (Lasso) [3], Linear Regression and Least-Angle Regression (LARS) [3], Artificial Neural Networks (ANN) [3,26], sparse Bayesian learning (SBL) [25,29,30], etc.
The research aimed to develop an effective method for detecting moisture inside walls. We created an original, heterogeneous method of transforming electrical impedance tomography (EIT) measurements into images of moisture distribution [26]. The course of the research included the performance of validation measurements on an authentic brick wall. The way of performing validation measurements using direct and indirect point methods is presented in article [2] in Section 2.2.. Validation Measurements. Then the Pixel-Oriented Ensemble (POE) method was designed, and the machine learning model was trained. Three homogeneous regression models were trained: ANN, LR, and LSTM. Then the classification neural network model was trained. In the last stage, reconstruction images were generated based on simulation data, and the hybrid POE method was compared with homogeneous methods. Known quantitative indicators were used for comparison.
Materials and methods
Data preparation and validation
The traditional approach to developing mathematical models considers forward problems, which in the case of electrical tomography means determining the values of voltage measurements made on the wall surface using the known electrical conductivity of the tested object. Tomography’s purpose is quite the opposite. It determines the electrical conductivity of individual components within the monitored object using surface measurements. It is an ill-posed problem because it may be impossible to find a true solution due to insufficient or excessive data. Inverse problems are frequently ill-posed problems, and their resolution requires regularization methods or machine learning. The generalized Laplace equation can be used to represent the following EIT forward problem:
Suppose that F defines a transformation function from inputs x to the set of outputs y, such that F (x) = y. The inverse problem is to use the (most often noisy) data obtained from a non-linear or linear F function to reconstruct (recover) some set of unknown parameters of the x model. Unfortunately, this kind of inverse mapping or function usually does not exist. Therefore, a series of numerical approximations must be made to find the closest solution. Furthermore, if the inverse problem does not depend continuously on the data, it will be very sensitive to changes in boundary measurements. This condition leads to wrongly posed inverse problems. Contrary to the well-posed EIT forward problem, the inverse EIT problem is severely ill-posed and extremely sensitive to small disruptions in the data boundary. For this reason, even a moderately noisy data set can make it difficult to find meaningful solutions [31].
Corresponding algorithms were developed to train machine learning-based models. The Eidors toolbox and the finite element method were used [32,33]. A training set of 14152 observations was generated. The input vector contained 96 measurements equivalent to the voltage drops between the specific electrode pairs. 16 specially designed electrodes are placed linearly on a metal strip. The spatial image is created on 4955 elements (pixels) finite element mesh. The same training data was used to train all the models considered in this research. The method of preparing the simulation data has been described in detail in publication [3] in Section 2.1.. Selected Hardware Issues, Sample Models, and Reconstructions.
Figure 1 shows one of the 14152 generated cases used to train the predictive system. A wall sector in Fig. 1a contains a random piece of moisture. Thanks to the variety of colors on the finite element mesh, the wet part is visible. On the vertical axis of Fig. 1b, we see the input vector values (measurements) expressed in arbitrary units, which are closely correlated with the voltages measured between the individual pairs of electrodes. The 4955 conductivity values are assigned to 96 voltage-like measurements called arbitrary units. The arbitrary units change in the range (−0.02 ÷ +0.06) as the polarity of the electrodes changes during individual measurements. The value of each measurement was increased by adding Gaussian noise with a standard deviation of 4%. The image’s finite elements (pixels) have 1 for the background (drywall) or 10 for the moist wall.

A sample training measurement case generated with the Eidors toolbox: (a) – a wall section with a wet upper part; (b) – 96 measurement values corresponding to the wet section.
The parameters of the simulation algorithm were validated based on actual measurements performed on a specially designed test stand (Fig. 2).

EIT measurement station. A metal strip with EIT electrodes was placed against the brick wall. On the right side, one can see the tomograph on the chair.
An artificial neural network was used in the research, and strictly speaking, it was a multilayer perceptron. The network consisted of 96 input measurements, 10 neurons in the hidden layer, and one in the output layer. Since the spatial tomographic image consisted of 4955 finite elements (pixels), this number of single-output neural networks (96 −10 −1) × 4955 was trained. All neural networks were identical in structure. Randomised observations in the training set were applied before each training process. The Levenberg-Marquardt algorithm was used to train the network. Two network quality assessment criteria were used during the training process: mean square error (MSE) and regression (R-value). The hyperbolic tangent transfer function in the hidden and output layers was used. The early stopping method was used to prevent overfitting the neural network. This method consists of the fact that the training process is stopped if, after 6 successive iterations, the MSE error for the validation set does not decrease. Figure 3 shows the learning process through the mean squared error values for the validation, testing, and training sets.
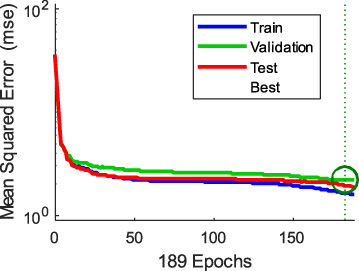
Training ANN for a randomly selected pixel. The best validation performance is 2.1965 at epoch 183.
The shape of all 3 curves resembles a hyperbola. The minor errors characterise the training blue line. The test and validation lines are slightly more error-prone, but the differences are insignificant. All this proves a minimal risk of overfitting the network and, thus, the trained model’s high quality and ability to generalise. The entire set of cases has been divided into 3 sets: training, validation, and testing, in the proportion of 70:15:15. It means that the training set consisted of 9906 cases, and the validation and test sets each had 2123 cases.
Another homogeneous machine learning method was linear regression LR. The 96-dimensional vector of input data was optimised using the LR technique. The learner used it as a support vector machine. The model also uses regularisation for Lasso (Least Absolute Shrinkage and Selection Operator). The algorithm adds the absolute magnitude of the coefficient to the loss function as a penalty component. The Lasso cost function is defined by formula (1)
For the LSTM network, the same proportion of the dataset division was used as in the case of ANN, i.e., 70:15:15 (training, validation, and testing sets). Since the “early stopping” method was not used for LSTM, and thus there was no need to use the validation set, this set was added to the training set. So, the training set used to train the LSTM network was enlarged to 12029 cases. Unlike the previous two models, the LSTM was trained in one process for all 4955 pixels of the image at once. The morphology of the LSTM network enables the processing of a large number of variables and hyperparameters, which made this approach possible. The model of the LSTM network used is shown in Fig. 4. The same set of observations was used to train the LSTM network as for the ANN and LR models. The parameters of the LSTM neural network used to convert measurements to output image pixels are listed in Table 1. Two bi-directional LSTM (BiLSTM) layers with 200 hidden units each comprise the LSTM model. Previous experiments have demonstrated that fewer hidden units degrade the network’s quality while increasing the number of hidden units and adding new layers prolongs the learning process but does not increase the LSTM network’s efficiency.

The model of the LSTM network.
In the LSTM model, the sequence input is the first/initial layer. Following that is the BiLSTM bidirectional layer [34]. BiLSTM is unique because it learns positive and negative long-term correlations between signal time steps or sequence data (feedback). These interactions are critical when the network must learn throughout the entire duration of the full-time series. The third layer aims to normalise the data to prevent the model from overfitting. BiLSTM’s fourth layer is identical to the second, and its fifth layer is entirely connected. This layer multiplies the weight vector by the numeric input values and adds the bias vector. The final, sixth regression layer generates the data for the tomographic image’s 4955 pixels.
LSTM structure – the weights, biases, and states assigned to each layer of the LSTM model
Figures 5 and 6 show the learning flow of the LSTM network. Figure 5 shows the evolution of the root mean square error (RMSE) error value. Figure 6 shows the same process in the context of the Loss function value.
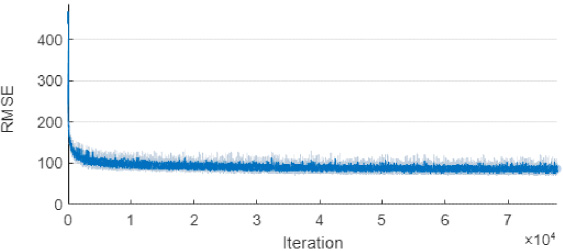
Training progress of the LSTM through the RMSE indicator.
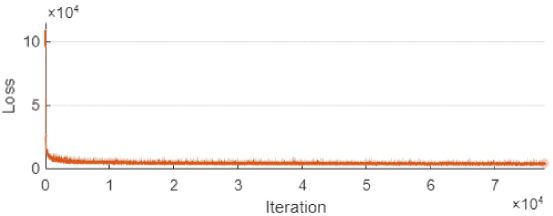
Training progress of the LSTM through the Loss indicator.
The RMSE is calculated according to the formula
The values of both indicators are influenced by the numerical value of individual outputs, which exemplarily assume binary values of 1 or 10. Low conductance (value 1) is determined by dry areas, and high (value 10) by wet areas. Undoubtedly, both graphs’ regular, hyperbolic shapes are a testimony to the correct course of learning and a prediction of no overfitting. A network trained in this way should have the ability to generalise the tomographic problems.
The POE concept is oriented towards selecting a model that generates a response based on the measurement vector and the pixel number in the image. In the case under consideration, the measurement vector consists of 96 values that are different for each measurement case. Earlier studies have shown that depending on the measurement vector, individual pixels should be predicted using different models because the differences in the measurement vector result in a preference for different machine learning methods. In the case discussed here, the classification model selects a method from the three available (previously trained) methods: ANN, LR, and LSTM.
The key here is to train the classification model. For this purpose, three response matrices were generated for 1000 randomly selected observations. Each matrix has a dimension of 1000 × 4955. Then, using the known patterns from the simulation set, the deviations for each pixel from 1000 observations were calculated, and the method (category) characterised by the minimum deviation was selected. Figure 7 shows the general workflow of the pixel-oriented ensemble (POE) method. In this way, the training set for the classification neural network was created, with 96 regression inputs and 3 output classes. For example, class 1 indicated a preference for AR, class 2 – LR, and class 3 – LSTM. Finally, the data prepared in this way was used to train the classification model of the neural network. As a result, the accuracy level of the classification model has reached 92%. In Fig. 7, Method I (OR) means the shallow neural network trained for classification.

The general principle of the pixel-oriented ensemble (POE) method.
The POE method is composed in such a way as to use the best reconstructions for specific pixels based on specific measurement vectors, choosing from several homogeneous methods. In our case, there are three homogeneous methods: ANN, LR and LSTM. All three homogeneous methods were trained on the same training set. In addition, the LSTM was trained using even more training cases by attaching the validation set to the training set. Therefore, in order to train the classifier (ANN classification network), the task of which is to select one of the three homogeneous methods (ANN, LR or LSTM) for a specific measurement vector (96 inputs) and each of the 4955 pixels of the image, a special training set had to be prepared. The inputs to this training set were the same measurement vectors used to train homogeneous regression models (ANN, LR and LSTM).
On the other hand, the output was classified and indicated one of the three methods (ANN, LR or LSTM), optimal for a given case and pixel (i.e. it generated the best result among all three homogeneous methods). In order to prepare such a classification training set, it was first necessary to obtain the results of the reconstruction for all cases included in the training set, using all three homogeneous methods. For example, if the training set for the classification model was 1000 cases, the output image’s resolution is 4955 pixels, and the number of homogeneous methods included in the POE is 3. Preparing the training set for the ANN classifier requires 14,865,000 (1000 observations × 3 methods × image resolution 4955) reconstruction. With such data, you can compare the results for 1000 measurements and choose the best (out of 3) method for every 4955 pixels, thus creating a training set for the classification model.
Figure 8 shows the preparation process and operation of the POE method.
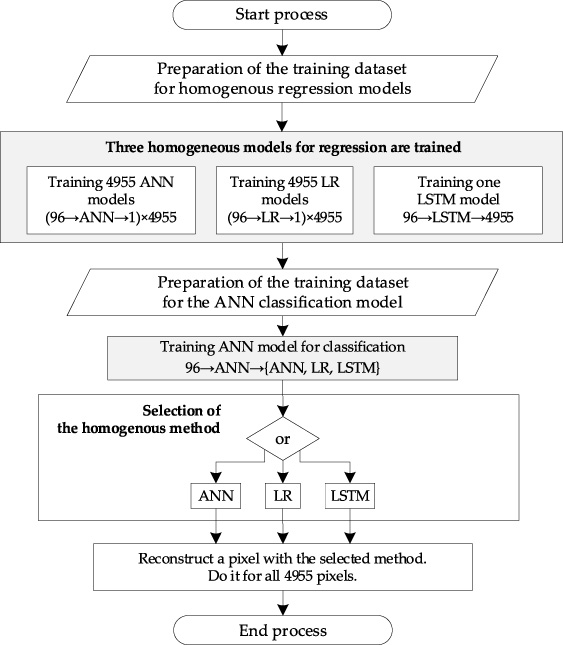
The flowchart of new concept (POE) modelling.
Figure 9 shows the proportional number of choices of individual methods for individual pixels in the context of 1000 random measurement cases. The most frequently used method was ANN (52%). LSTM (41%) was in second place. The least frequently chosen method was LR (7%).

The proportions of the classification of homogeneous methods within the POE concept for 1000 randomly selected measurement cases.
In order to objectively compare the four methods, 4 commonly used criteria/indicators were used: root mean square error (RMSE), normalised mean square error (NMSE), relative image error (RIE), and image correlation coefficient (ICC). The RMSE formula has already been given. NMSE is calculated according to the formula
Reconstruction quality indicators for individual methods
Reconstruction quality indicators for individual methods
Figure 10 compares 3D reconstructions obtained with ANN, LR, LSTM and POE methods. Three different cases of a damp wall were selected for the method comparison. In the first line of the figure, there are reference images (patterns). The following lines contain reconstructions made using ANN, LR, LSTM methods and the new POE concept.
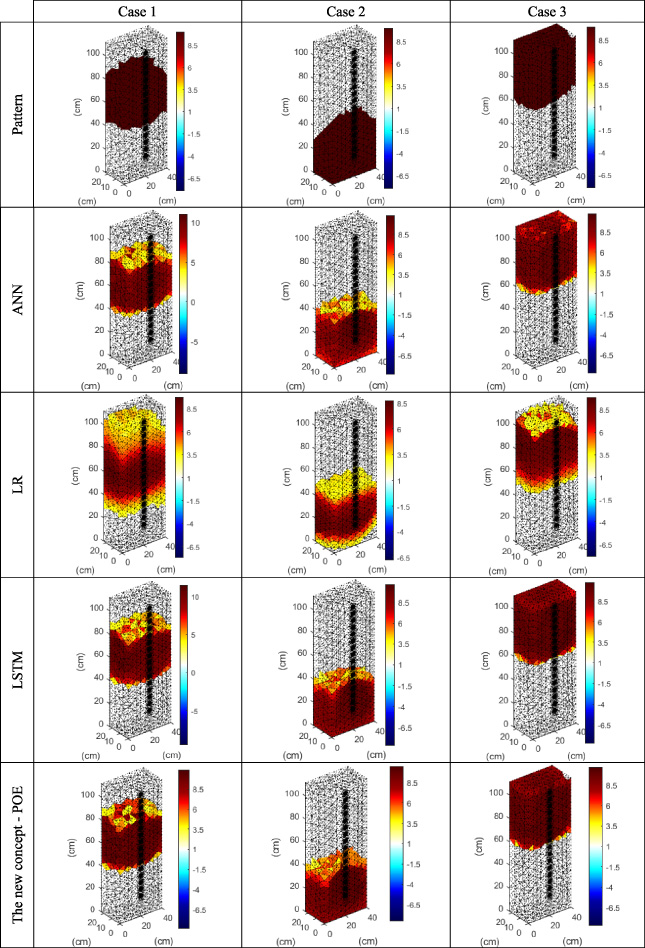
Comparison of 3D reconstructions obtained with ANN, LR, LSTM and POE methods.
The visual comparison is not prescriptive and burdened with the bias of subjective assessment, but it is visible that the LR reconstructions are worse than the others. In the case of ANN and LSTM methods, the differences are less noticeable and less obvious.
The article presents the concept of using a hybrid machine learning method, which guarantees better results than any of the homogeneous methods included in the pixel-oriented ensemble (POE) system thanks to training many models. The concept was applied to imaging the moisture inside a brick wall by solving the inverse problem in electrical impedance tomography. The high quality of the reconstruction was confirmed by comparing the images generated by the three components (homogeneous) methods of ANN, LR and LSTM and POE. All the methods presented, including POE, enable spatial visualisation of the moisture distribution inside the wall. It is a fundamental difference compared to the classical methods that test the humidity only at selected wall points. The comparison of error indicators and personal observation confirmed the high effectiveness of the new concept. Future research will focus on sequencing the moisture expansion processes inside porous materials, which will increase the effectiveness of tomographic methods.