
Abstract
Depth map estimation from a light-field camera is an interesting and challenging problem. Recent works have demonstrated many fascinating results based on different cues in light-field images. According to the characteristics of light-field spatial refocusing, we introduced a confidence -aware depth estimation method on the basis of multiple cues. In this paper, the focus/defocus cue of focal stack is estimated in Discrete Cosine Transform (DCT) domain. Based on photo-consistency metric and relevance analysis, the correspondence cue between different rays of a refocusing pixel is extracted. Then the edge confidence analysis is introduced as the depth and color discontinuity cues. In order to get refined depth map, an iterative graph cut optimization framework with label cost is used to integrate these aforementioned cues with their confidences. Experimental results showed that our method can achieve accurate depth maps, especially in the depth discontinuous areas.
Introduction
Light-field or plenoptic cameras can capture 4D spatio-angular information of light field [1, 2]. Compared with traditional cameras, this characteristic of light-filed cameras provides more helpful cues and information for visual analysis and understanding. An important benefit of light-field camera is multi-views or sub-apertures can be obtained from a single shot, so depth recovery from a single light-field image becomes an interesting and attractive task. However, being limited by the fundamental tradeoff between spatial and angular resolution [3], depth estimation using light-field camera still faces the challenges of robustness and accuracy. Many recent works focused on using different cues, such as focus/defocus and correspondence.
Comparisons of depth estimation results.
Inspired by the recent work [4], we propose a multiple cues confidence-aware depth estimation method. The main differences and our main contributions are:
A multiple-cue confidence-aware depth map optimization framework is proposed. It integrates multiple cues with confidence into a high-order multi-label graph cut optimization. Edge confidence is incorporated in our optimization framework as the depth and color discontinuity cues. It can improve the accuracy of depth map in depth discontinuous areas. A robust focus/defocus cue is estimated from focal stack by analyzing the alternating current (AC) coefficients calculated in DCT domain. Before the computing of correspondence cue, the possible occluded rays are excluded according to the photo-consistency metric and relevance analysis.
Figure 1 shows the better performance of our method compared with that of Tao et al. [4]. Figure 1a is the input central views of light-field images, Fig. 1b is the depth maps of Tao et al, and Fig. 1c is the depth maps by our method and the pseudo-color version are shown in Fig. 1d. Clearly, our depth maps are much clearer and more accurate.
Compared with traditional 2D image, light-field image implies many significant cues. Our work is related to depth recovery from light-field images that perhaps can be traced back to the research on focal stack extraction [5] and depth-of-field (DOF) extension [6].
Georgiev and Lumsdaine [7] estimated disparity maps by computing a normalized cross correlation between microlens images. Bishop and Favaro [8]proposed a Bayesian framework to reconstruct scene depth. Perwass and Wietzke [9] introduced a correspondence technique to estimate depth. Yu et al. [10] analyzed the 3D geometry of lines in a light field image and computed the disparity maps through line matching between the sub-aperture images. Tao et al. [4] showed how multiple cues like defocus and correspondence can be combined. Jeon et al. [11] estimated the multi-view stereo correspondences with sub-pixel accuracy using phase shift theorem. Lin et al. [12] described a technique to recover depth from a light field image based on focal stack symmetry analysis and their data consistency measure. References [13] and [14] introduced methods to measure or control DOF.
Inspired by Tao et al. [4], we integrate five depth cues (photo-consistency, defocus, correspondence, occlusion, depth discontinuity) into a multi-label graph cut optimization framework.
Multiple cues from focus stack
Ray gathering and computational refocusing capabilities are the unique characteristics of light-field camera. In light field imaging processing, rays with different directions are separated by microlens array (MLA), and then recorded by image sensor. Computational refocusing is a process of ray tracking. The rays, from different positions of the main lens plane, arrived at a pixel of a virtual refocusing plane can be tracked and computed. Ng et al. [1] discussed and derived the refocusing equation for light-field image. We rewrite it in discrete form and ignore the dilation factor:
where
To express easily, we define the central ray is a ray emitted from scene point and passing through the main lens optical center
In order to recover the depth map of scene, a focal stack is built by a set of virtual refocusing planes, and then we will find the best depth estimation of each scene point from the focal stack. For a scene point
Ray tracking and refocusing.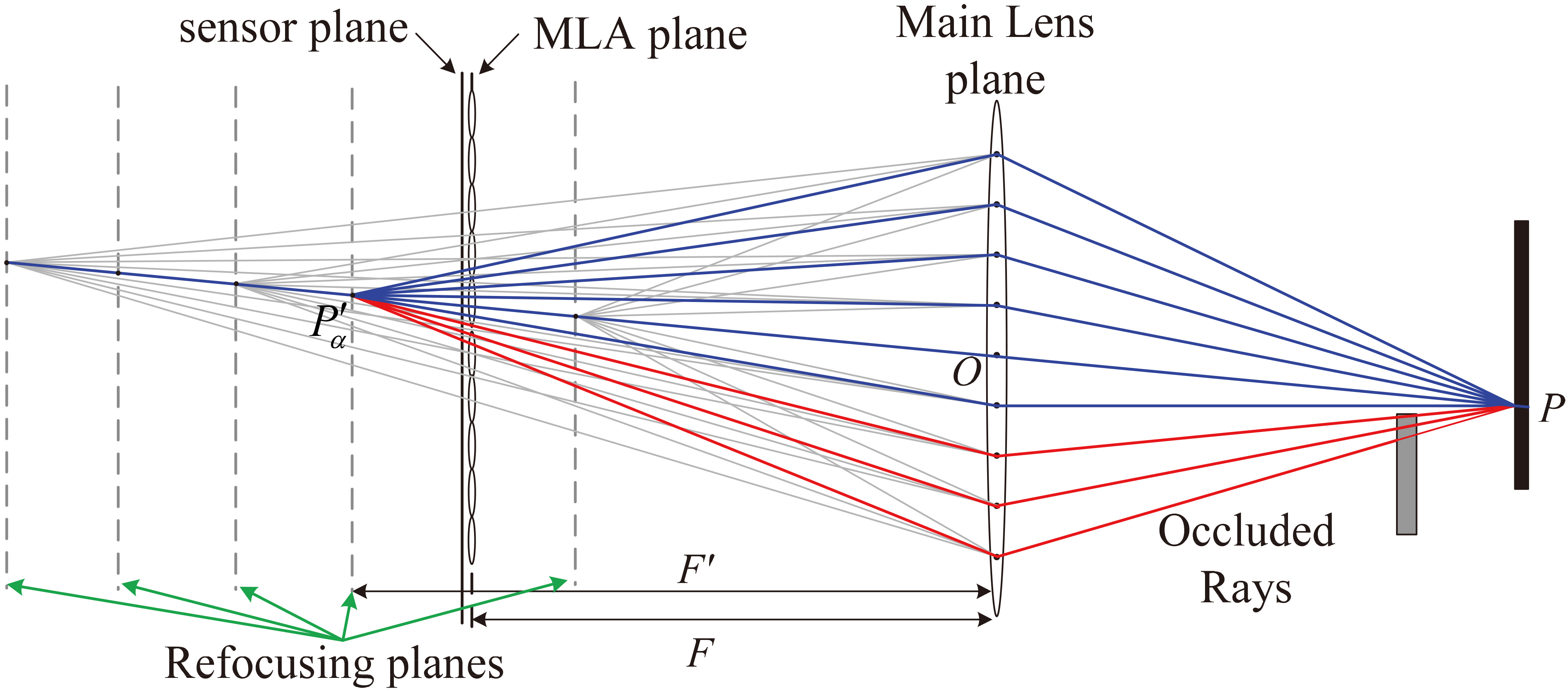
During the judgment of most in-focus position, we consider multiple cues as follows.
It is one of important cues and implied in most computer vision processing. It means all rays from the same scene point have the same radiation.
Defocus cue
In the focal stack, we have a group of images focused on different regions. Generally, the focused area is more informative, that means more details and the higher spatial frequency. The higher the spatial frequency, the higher the clarity of the image. We use the variance of AC coefficients of DCT block as the defocus metric. DCT-based metric is simple and efficient [15, 16] because it can achieve stable defocus metric without a lot of convolution calculations.
For a pixel
where
We find the
Without occlusion, all the rays converged at the most in-focus point should come from the same scene point, and should have same radiation according to the photo-consistency cue.
Considering the noises and the errors introduced in the refocusing process, we assume the radiation of all these converged rays should obey a narrow Gaussian distribution with small variance and its mean should close to the radiation of the central ray.
For a pixel
The correspondence metric can be written as follows,
We find the
Occlusion is generally caused by inevitable object overlapping and difficult to be detected in traditional computer vision tasks. Because photo-consistency cue doesn’t hold when occlusion occurs, the correspondence cue metric will not be correct. As shown in Fig. 2, the red rays are occluded by the gray object and should be excluded before the correspondence cue metric computation. In other words, the red rays are emitted from different points on the occlusion objects rather than from the scene point
Benefit from the characteristic of light-field that each ray is theoretically computable and traceable, we can propose a simple and efficient occlusion elimination method under the 3-sigma rule. It is not an occlusion detection method. It just uses an iterative hypothesis testing strategy for removing the outliers which is against the 3-sigma rule, and we consider those outliers include occluded rays. More specifically, we firstly compute the mean and variance from all the (
Depth discontinuities generally occur at object boundaries or occluding contours, and are reflected by edge pixels. We get the edge confidence map
Multiple-cue confidence-aware depth optimization framework
Our light-field depth estimation, as mentioned before, is to select a most suitable
where
Our data term integrates defocus metric and correspondence metric with the occlusion cue by estimating confidences as their weights. We use Peak Ratio to estimate the confidences of the defocus cue and correspondence cue, similar to the method proposed by Tao et al. [4].
Let
The cost of assigning the label
where
Our smooth term used here is a weighted Potts model,
where
where
where
Figure 3 shows some intermediate results of our method that are defocus metric, correspondence metric with the occlusion cue, edge confidence map and the final refined depth map, respectively.
The intermediate results of our method.
In our experiments, the refocusing plane parameter
We validate our method on real-world scenes taken by Lytro Illum camera. The size of light-field data is 15
Comparisons of depth estimation results between Tao’s method and ours.
Figure 4 shows the experimental results on our data with fine structures and occlusions. Tao’s method loses fine structures, because details are vulnerable to edges and noises. Our method not only preserves more details at depth discontinuities, but also performs more robust at the surface color/texture discontinuities.
Failure case: Large weak texture or textureless regions.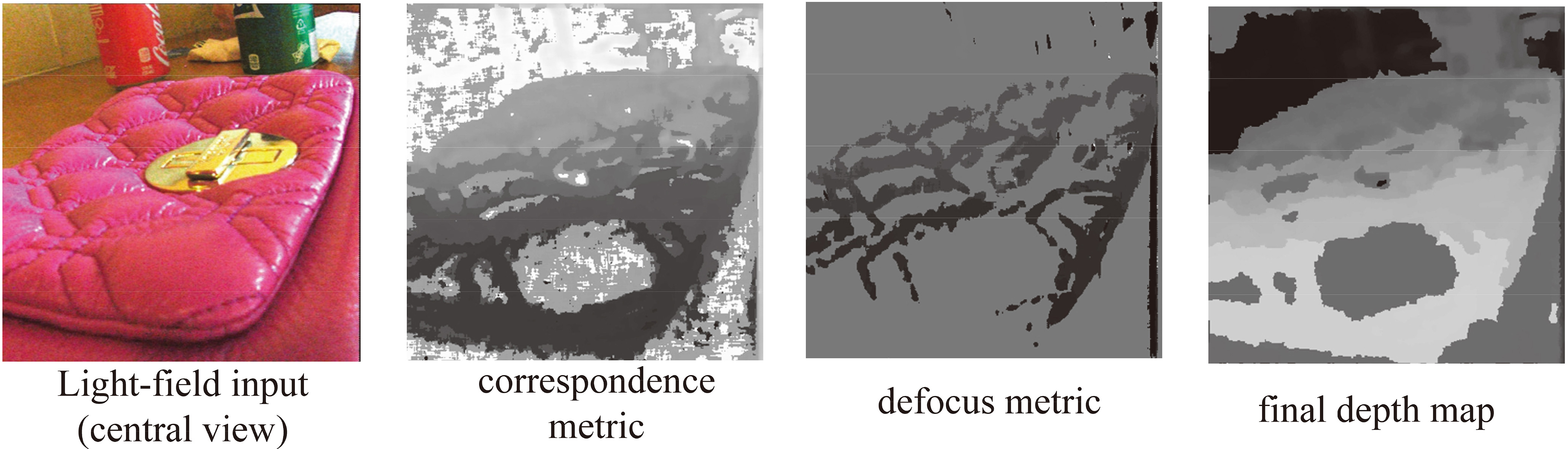
Since our defocus metric is based on the image detail information, it may fail to get good results of defocus metric in some large weak texture or textureless regions, as shown in Fig. 5.
Conclusions
In this paper, we introduced a multiple-cue and confidence-aware depth estimation method, which combines the focus/defocus cue, correspondence cue, and the edge confidence analysis together. In addition, a multi-label graph cuts optimization framework is applied to correct and refine the depth estimation of uncertain regions. Experiment results showed our method exhibits better performance in achieving accurate depth maps, especially in the depth discontinuous regions.
Conflict of interest
The authors confirm that this article content has no conflicts of interest.
Footnotes
Acknowledgments
This work is supported by Zhejiang Provincial Natural Science Foundation of China (No. LY15F01 0002), and the Key Project of Zhejiang Provincial Natural Science Foundation of China (No. LZ14F020003).