
Abstract
A novel task scheduling algorithm called Merge Tasks and Predict Earliest Finish Time (MTPEFT) has been proposed for static task scheduling in a heterogeneous computing environment. The algorithm merges tasks satisfying constraints and assigns the best processor for the node that has at least one immediate successor as the critical node, thereby effectively reducing the schedule length without increasing the algorithm time complexity. Experiments regarding aspects of randomly generated graphs and real-world application graphs are performed, and comparisons are made based on the scheduling length ratio, robustness and frequency of the best result. The results show that the MTPEFT algorithm outperforms the PEFT, CPOP and HEFT algorithms in terms of the schedule length ratio, frequency of the best result and robustness while maintaining the same time complexity.
Keywords
Introduction
A heterogeneous computing system (HCS) is a computation platform composed of diverse computing resources which are interconnected by a high-speed network to execute parallel and distributed applications [1]. The key of obtaining high performance in HCS, which is generally addressed by task scheduling, is to efficiently map an application on the available resources. Task scheduling aims to assign tasks to processors and to sequentially execute so that the precedence requirements are satisfied and the minimum schedule length is achieved [1, 2, 3, 4, 5]. However, the task scheduling problem in general is NP-complete [1, 6]. Thus, the task scheduling problem has been extensively studied and various heuristics have been presented in the literature [3, 4, 5, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]. These heuristics are classified into a variety of categories, such as list scheduling algorithms, task-duplication scheduling algorithms and task-clustering scheduling algorithms.
List scheduling algorithms basically consists of two phases: a task prioritizing phase, where an ordered list is constructed by assigning a priority to each task in a given directed acyclic graph (DAG), and a processor selection phase, where each task from this ordered list is assigned to the processor that minimizes the predefined cost function. The basic idea of task-duplication scheduling algorithms is to try to duplicate the parents of the current selected task onto the selected processor or onto another processor, aiming to reduce or optimize the task finish time [6, 22]. The basic idea of task-clustering scheduling algorithms is to try to schedule tasks which have high communication cost onto the same processor, so as to reduce the dependency waiting time. The task-clustering scheduling uses a clustering method [23, 24] to map all of the tasks of a given task graph to clusters and assigns processors for these clusters. The main weakness of task-duplication scheduling algorithms is that they often require higher time complexity and a large amount of processor resources. The task-clustering scheduling algorithms may sacrifice the parallelism between tasks during reducing the dependency waiting time. Therefore, the trade-off between maximizing parallelism and minimizing communication delay should be taken into consideration when designing the clustering method [25]. List scheduling algorithms are widely used since they generated good scheduling results with less complexity which is generally quadratic in relation to the number of tasks. The heterogeneous earliest finish time (HEFT) [20, 21], Critical Path On a Processor (CPOP) [21] and Predict earliest finish time (PEFT) [10] have a complexity of
The HEFT algorithm is widely used because of its low algorithm complexity and its producing relative shorter scheduling length. In [26], the authors compared 20 types of heuristics and found that HEFT [20, 21] performs best in terms of robustness and schedule length. But the HEFT algorithm does not account for heavily communicating tasks and the parent critical tasks which determine the DAG scheduling time.
The PEFT algorithm outperforms the HEFT algorithm in terms of the scheduling length ratio and frequency of the best result while with the same time complexity. But the algorithm does not take into account the parent critical tasks, which decide the DAG scheduling time.
In this paper, based on both task-clustering techniques and list scheduling approach for HCS, a synthesized heuristic task scheduling algorithm called Merge Tasks and Predict Earliest Finish Time (MTPEFT) has been developed, aiming to outperform the HEFT, CPOP and PEFT algorithms in terms of the schedule length ratio, robustness and frequency of the best results while with the same time complexity.
The contributions of this paper mainly include: 1) A new scheduling algorithm with lower time complexity is proposed; 2) MTPEFT merges tasks satisfying constraints before task scheduling. 3) MTPEFT takes the impact on the critical task of its parent into consideration; 4) MTPEFT takes the impact of current task assignment on its children into account; 5) Results from randomly generated and real-world application graphs are presented.
The remainder of this paper is organized as follows: the task scheduling problem is introduced in Section 2; the description of the MTPEFT algorithm is made in Section 3; and the experiment results and conclusions are provided in Sections 4 and 5, respectively.
Task-scheduling problem
In the static task scheduling application for HCS, the application can be represented by a DAG as shown in Fig. 1, defined by tuple
The HCS is represented by a set
Table 1 shows the computation costs matrix
Computation time matrix
Application DAG.
where
The following will present some common attributes for task scheduling and these attributes will be referred to in the forthcoming sections.
Makespan [10, 21] (or schedule length): It is the finish time of the last task in the scheduled DAG, i.e.
where Critical Path (CP) [21]: The CP of a DAG is the longest path from the entry task to the exit task in the DAG. The length of this path CP is the sum of the computation costs of the nodes and inter-node communication costs along the path. The lower bound of the schedule length is the minimum critical path length (
where
where
where Critical Node [21] (CN): Is a node where the sum value of
OCT [10]: Denotes a matrix in which the rows indicate the number of tasks and the columns indicate the number of processors, and when task
where
In this section, we introduce a brief survey of task scheduling algorithms.
Classical examples of list scheduling algorithms have been presented in [3, 4, 5, 10, 12, 15, 19, 20, 21]. The heterogeneous earliest finish time (HEFT) [20, 21] and Critical Path On a Processor (CPOP) [21] have been proposed when there are few research results from heterogeneous environments. HEFT and CPOP are designed as 2 phases: a task prioritizing phase and processor selection phase. In the task prioritizing phase, the HEFT uses a recursive procedure to calculate an upward rank for each task priority, and then generates a list in order of descending upward rank value. Compared with the HEFT, the CPOP uses different attributes to set the task priorities. The CPOP adopts the sum of the upward and downward ranks as each task priority. In the second phase, the HEFT assigns the “best” processor for each task according to the sequence in the order list, which can minimize the task completion time. Compared with the HEFT, the CPOP uses a different policy to determine the “best” processor for each selected task. The selected task will be scheduled on the critical path processor if it is on the critical path, otherwise it will be assigned to a processor according to HEFT. Fast Load Balancing (FLB) [19] reduces the time complexity of HEFT. However, the scheduling result from FLB is worse than that of HEFT for irregular task graphs and higher processor heterogeneities [10]. Rather than assigning priorities to the tasks, heterogeneous critical parent trees (HCPT) [3] proposes a new mechanism to construct the scheduling list. High Performance Task Scheduling (HPS) [5] has three phases which are level sorting, task prioritization, and processor selection. Performance Effective Task Scheduling (PETS) [4] has the same three phases as HPS. The Lookahead algorithm [12] improves upon the processor selection strategy of HEFT. To select a processor for the current task not only relies on the completion time of the current task, but also the information about the impact of the schedule decision on the allocation of current task child nodes. The Longest Dynamic Critical Path (LDCP) [15] needs to construct a DAG for each processor and must update it when a task is scheduled. Improvement heterogeneous earliest finish time (IHEFT) [22] changes the task’s upward weight calculation method to obtain a better task list by changing the task’s upward weight calculation method. Predict earliest finish time (PEFT) [10] has the same two phases as HEFT, which are only based on an optimistic cost table (OCT).
Classical examples of task duplication heuristics have been presented in [8, 11, 13, 17]. The main weakness of task-duplication scheduling algorithms is that they often require higher time complexity and a large amount of processor resources. In addition, combining duplication strategy with DVS technique two scheduling algorithms have been proposed in [27, 28] to reduce energy consumption. The algorithms presented in [29, 30] are designed to balance the energy and performance.
Classic task clustering algorithms [9, 18] are mainly applicable to homogeneous systems. Algorithms for heterogeneous systems have been proposed in [7, 14]; however, these algorithms have limitations in systems with a high degree of heterogeneity [10]. Two novel algorithms were proposed in [31, 32] to reduce energy under the condition of no increasing makespan.
An example of schedule.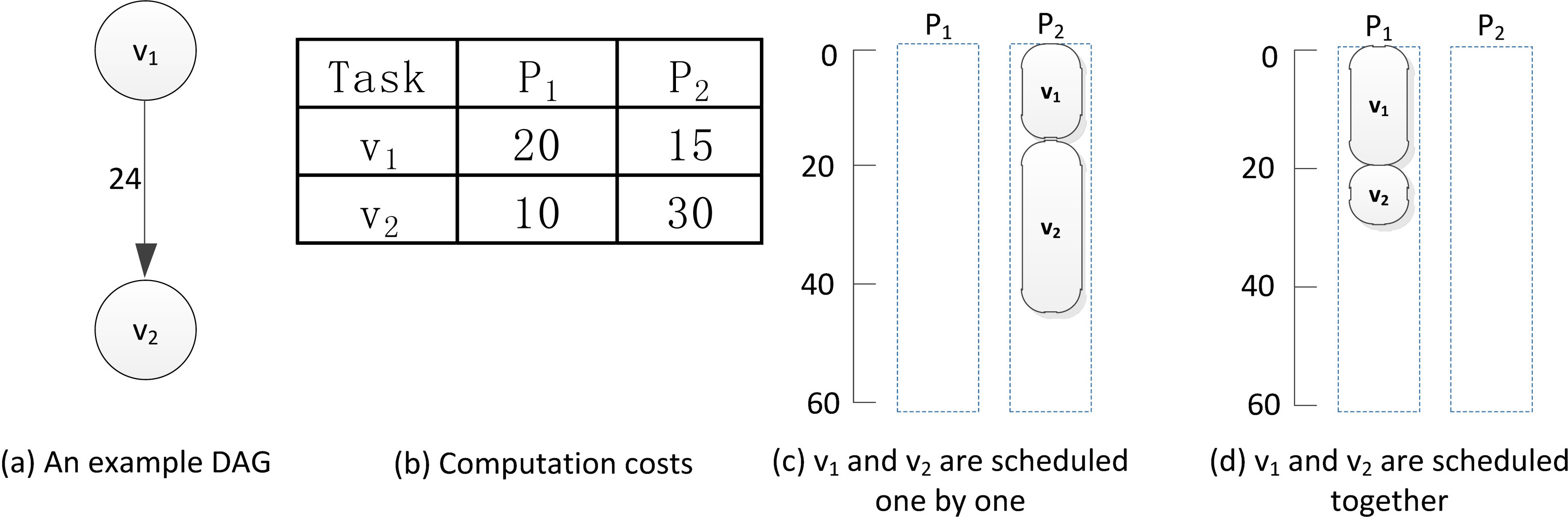
In this section, a new task scheduling algorithm for a bounded number of heterogeneous processors is introduced, called MTPEFT. The algorithm consists of three phases, namely, task merging, task prioritization, and processor selection.
In the task merging phase, MTPEFT attempts to merge tasks and minimizes communications among tasks so that it can reduce the schedule length. In the processor selection, MTPEFT assigns parents of a CN onto processors with earliest finish time (EFT), which may advance the earliest start time of the CN to reduce the schedule length. In addition, to select a processor for the current task, MTPEFT considers information not only about the EFT of the current task but also the impact of the chosen processor on the path length from the current task’s child nodes to the exit node.
The MTPEFT algorithm will be explained in details in the following sections.
The phases of MTPEFT
Task merging
Assume that task
Aiming at these problems, our algrithm proposes a task merging strategy which is described as follows.
Tasks in the DAG graph will be merged together if they satisfy the merging constraints, and they will be processed as a whole in the following task prioritization and processor selection phases. Merging constraints of tasks are as follows:
where:
For example, Fig. 3 obtained from merging tasks satisfying constraint in Fig. 1.
After merging the DAG in Fig. 1.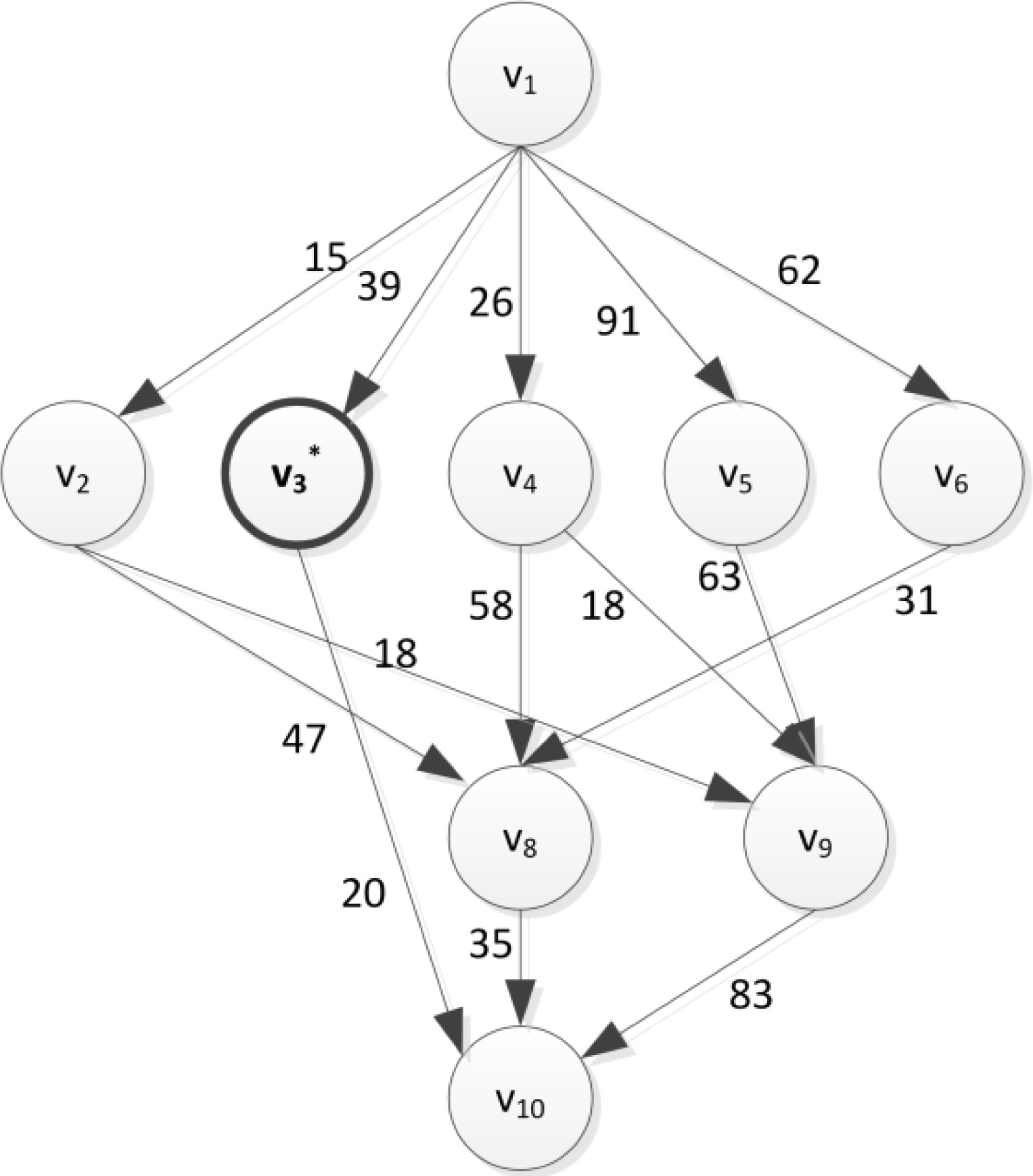
In the task prioritization phase, priorities of each node are computed and assigned with
Processor selection phase
To select a processor for a task, the earliest finish time of the task on each processor will be first calculated. The insertion-based policy is applied for computing EFT and the possibility of inserting tasks in the earliest idle time slot between two scheduled tasks on the identical processor should be taken into consideration.
The idle time slot should be at least capable of computation cost of the task to be scheduled and also scheduling on this idle time slot should preserve precedence constraints.
Then the
If the current task is the parent of a CN, the value of
Finally, select the processor with the minimum
This processor selection policy shortens the schedule length from two ways. First, if the current task has an immediate successor that is a CN (namely, the current task is the parent of a CN), the current task is assigned to the processor that achieves the EFT, which may advance the earliest start time of critical tasks to reduce the schedule length. Second, if the current task is not the parent of a critical task, the task is assigned to a processor not only based on the EFT of the current task but also the predicted impact of the chosen processor on the path length from the current task’s child nodes to the exit nodes. Therefore, although the finish time of the chosen processor is not always the earliest, this policy ensures a shorter finish time for the tasks which reduces the schedule length.
The pseudo code of MTPEFT is shown as Algorithm 1.
In the algorithm, tasks that satisfy the merging conditions are first merged in Lines 1–5. Second CNP,
The time complexities of each step in the algorithm are as follows:
The time complexity of tasks merging is For calculating CNP of all the tasks, there is For calculating For calculating OCT of all the tasks, there is For assigning processors to all the tasks, there is
Therefore, the general time complexity of MTPEFT is
Table 2 shows the values of OCT,
Figure 4 shows the scheduling result of the DAG graph in Fig. 1 by algorithms of MTPEFT, PEFT, HEFT and CPOP. The scheduling length of MTPEFT is 153, which is shorter than those of PEFT, HEFT and CPOP (183, 202 and 207, respectively).
In this section, a comparison among MTPEFT, HEFT, CPOP and PEFT will be conducted from aspects of randomly generated DAGs and real-world application graphs. The primary comparison metrics are offered first.
Comparison metrics
To compare the algorithms, three metrices have been defined as following.
Schedule produced by the MTPEFT algorithm in each iteration
The bold emphasis indicates that the processor is assigned based on EFT, EFT
Schedules of the DAG In Fig. 1 with (a) MTPEFT (Makespan 
Number of Occurrences of Better Quality of Schedules (NOBQS)
The NOBQS is the percentages of better, equal and worse schedule lengths generated by one algorithm compared to another algorithm.
Slack
Slack [10, 33] is a measure of the robustness of the schedules which shows the uncertainty in the task processing time produced by an algorithm and can be defined as
where
In this section, the generation method of random graphs applied in the experiments is presented and the performance of the MTPEFT, HEFT, CPOP and PEFT algorithms are compared.
Random graph generator
A composite DAG generator [10, 34] is adopted as the random graph generator in this paper and its primary parameters are as follows:
fat: Affects the height and width of the DAG; the width in each level is defined by a uniform distribution that equals
density: Determines the number of edges between the two levels of the DAG;
regularity: Determines the uniformity of task numbers in every level; a lower value indicates that there is a dissimilarity of task numbers among levels;
jump: Distance of an edge from level
Different DAG structures are established by setting different parameter values to the generator. The following arguments are used to calculate the computation and communication costs.
For randomly generated DAGs: (a) average SLR for different numbers of tasks. The bars represent the 95% confidence intervals of the mean. (b) average slack for different numbers of tasks.
.CCR (ratio of communication to computation): The rate between the sum of the edge weights and the sum of the node weights in a DAG;
In the experiments, arguments below are used for generating random graph.
Accurately 117,504 DAGs are generated by these arguments combinations, and for each DAG, 20 random graphs are generated with the same structure but with different node and edge weights. Thus, the total number of DAGs comes up to 2,350,080.
For randomly generated DAGs, the average SLR and the average slack for different numbers of tasks are shown in Fig. 5a and b respectively.
Compared to the HEFT algorithm, when the task quantity is 10, the average SLR of the MTPEFT algorithm is 15% lower than that of the HEFT algorithm, and when the number of tasks reaches 100 and 400, the decrement percentages decrease to 8.4% and 6.6%, respectively. This implies that the effect of key child nodes on scheduling decisions for parent nodes decrease for an increasing number of tasks. Meanwhile, the MTPEFT algorithm achieves smaller average slack than that of the HEFT algorithm with different task quantities. Compared with the PEFT and CPOP algorithm, the MTPEFT algorithm also obtains lower average SLR and average slack. Thus compared to the CPOP, HEFT and PEFT algorithms the MTPEFT algorithm does not only make improvement on SLR, but also achieves better robustness. For random graphs, CPOP is the worst algorithm. This is because CPOP just schedules all critical nodes to the key processor without considering the impact of non-critical nodes’ being assigned to the key processor and parents of a critical node on the earliest start time of critical nodes.
Figure 6a presents the average SLR of the algorithms for CCR values of [0.1, 0.5, 0.8, 1, 2, 5, 8, 10]. The MTPEFT algorithm outperforms the other algorithms in terms of the average SLR for random task graphs with various values of CCR. The average SLRs for different heterogeneity values is illustrated in Fig. 6b. The average SLR obtained by the MTPEFT algorithm is smaller than those of the CPOP, HEFT and PEFT algorithms by (7.9%, 3.8%, 3.7%), (7.5%, 4.4%, 3.8%), (8.7%, 5%, 4%), (9.8%, 5.7%, 4.2%), (12.0%, 6.7%, 4.4%) and (21.8%, 13.6%, 4.5%) when the heterogeneity value is equal to 0.1, 0.2, 0.5, 0.8, 1 and 2, respectively.
Table 4 lists the percentage of better, equal, and worse scheduling lengths generated by MTPEFT compared to other algorithms. Compared with the CPOP, HEFT and PEFT algorithm, the MTPEFT algorithm gets better performance in 87%, 82% and 67% during scheduling, equivalent performance in 3%, 6% and 21% of scheduling, and worse performance in 10%, 12% and 12% of scheduling, respectively.
Pairwise schedule length comparison of the scheduling algorithms
Pairwise schedule length comparison of the scheduling algorithms
For randomly generated DAGs: (a) Average SLR for different CCRs. The bars represent the 95% confidence intervals of the mean. (b) Average SLR for different heterogeneous values. The bars represent the 95% confidence intervals of the mean.
In addition to randomly generated task graphs, application graphs of three real-world problems are also considered: Fast Fourier Transform [21], Montage [35] and LIGO [36]. In these graphs, the values of CCRs,
Fast Fourier Transform (FFT) if composed of recursive calls and butterfly operation. The number of FFT points (n) decides the number of tasks, meaning that there are
For the Fast Fourier Transform DAGs: (a) Average SLR for different heterogeneous values. The bars represent the 95% confidence intervals of the mean. (b) Average SLR for different CCRs. The bars represent the 95% confidence intervals of the mean.
The comparisons of the average SLRs for different levels of heterogeneity and for different CCRs are shown in Fig. 7a and b respectively. The experiment analysis indicates that the average SLRs of the MTPEFT algorithm are 1.4%, 1.8%, 3.2%, 5.5%, 7.2% and 17.8% smaller than those of the HEFT algorithm and 2.6%, 2.8%, 3.1%, 5.0%, 5.5% and 5.8% smaller than those of the PEFT algorithm when the heterogeneity values are 0.1, 0.2, 0.5, 0.75, 1 and 2, respectively. For different CCRs, the MTPEFT algorithm obtains smaller average SLR than those of the HEFT and PEFT algorithms. In this type of application, the results obtained by MTPEFT algorithm were similar to those obtained by CPOP algorithm.
The second real-world application DAG is the Montage task DAG with the task number of 25. The combination of CCRs,
The comparisons of average SLRs for different levels of heterogeneity and different CCRs are illustrated in Fig. 8a and b. The experiment analysis tells that, when the heterogeneities take values 0.1, 0.2, 0.5, 0.75, 1 and 2, the average SLRs of the MTPEFT algorithm are respectively 12.7%, 13.0%, 13.7%, 14.7%, 15.0% and 23.2% smaller than those of the HEFT algorithm, respectively 8.3%, 9.2%, 10.5%, 11.0%, 11.7% and 17.9% smaller than those of the HEFT algorithm, and respectively 4.7%, 5.2%, 4.9%, 5.0%, 4.3% and 4.0% smaller than those of the PEFT algorithm. For different CCRs, the MTPEFT algorithm obtains smaller average SLR than those of the CPOP, HEFT and PEFT algorithms.
For Montage DAGs: (a) Average SLR for different heterogeneous values. The bars represent the 95% confidence intervals of the mean. (b) Average SLR for different CCRs. The bars represent the 95% confidence intervals of the mean.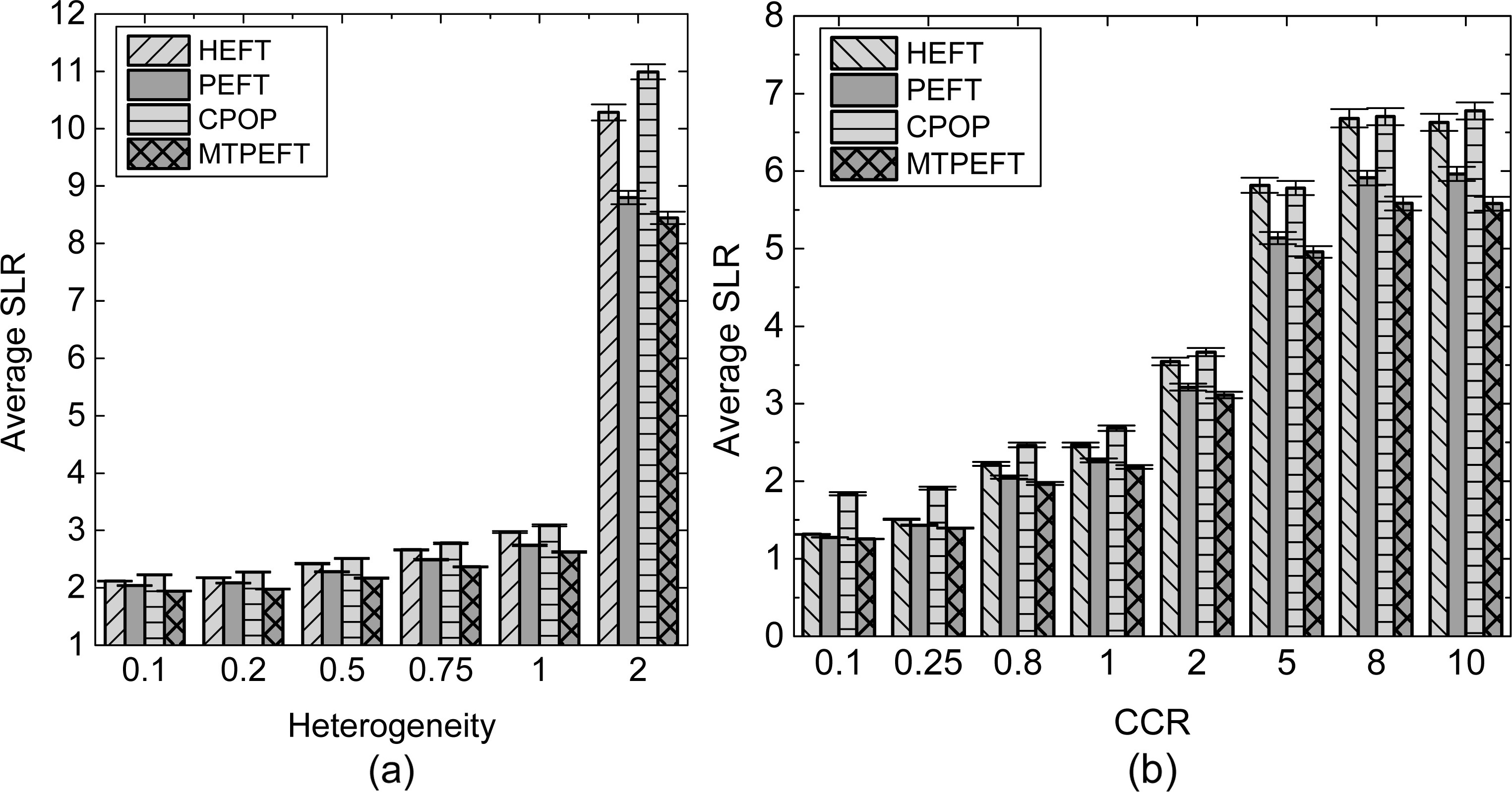
For LIGO DAGs: (a) Average SLR for different heterogeneous values. The bars represent the 95% confidence intervals of the mean. (b) Average SLR for different CCRs. The bars represent the 95% confidence intervals of the mean.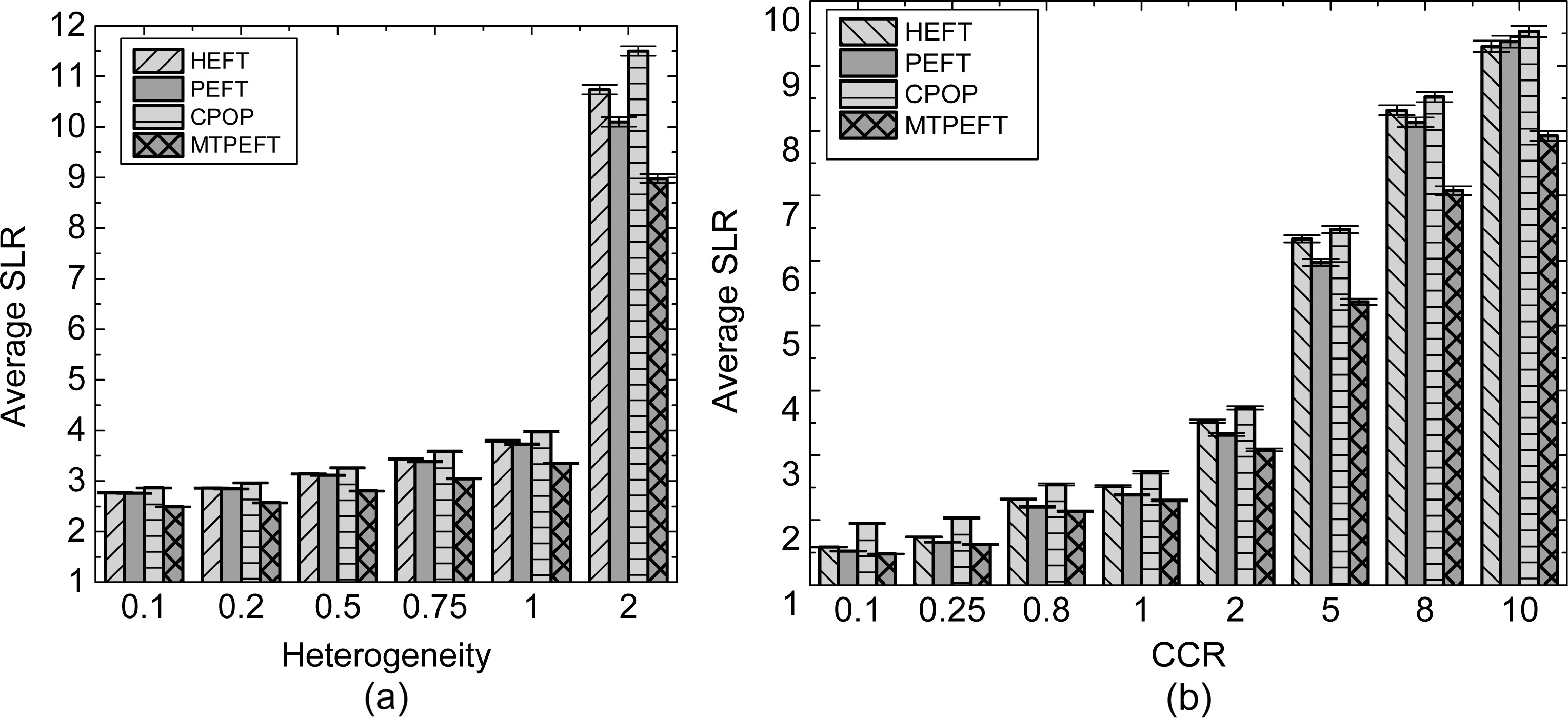
The thrid real-world application DAG is the LIGO task DAG with the task number of 30 and 50. The combination of CCRs,
Figure 9 presents the average SLR as different parameters. In this type of application, MTPEFT obtains preferable SLR values than those of other algorithms. Particularly the higher
Conclusions
We have proposed a new task scheduling algorithm, MTPEFT with quadratic time complexity for heterogeneous computing systems. The MTPEFT algorithm first merges tasks that satisfy constraints, then assigns priority for each task, and finally selects a processor for each task. In the processor selection phase, the impact of the parent task on the critical task is considered, and each parent is assigned to the processor that minimizes the EFT, which may advance the earliest start time of the critical task and improve scheduling performance. In the meantime, to select a processor for the current task which does not contain sub-task as critical task, the impact of the assignment on all children of the current task is taken into account. In this manner, the completion time for the selected processor to complete the current task is not always the earliest, but it ensures shorter finish time for the tasks in the following steps, which consequently reduce the scheduling length of the DAG.
Our algorithm has the same time complexity as CPOP, HEFT and PEFT algorithms but performs better. Regarding schedule length, the MTPEFT algorithm achieved more favorable results than the HEFT and PEFT algorithms in randomly graphs when the number of tasks ranges from 10 to 300. The robustness of the MTPEFT algorithm is also better than those of CPOP, HEFT and PEFT algorithms. In addition, the MTPEFT algorithm outperformed CPOP, HEFT and PEFT algorithms in terms of the frequency of the best results. The MTPEFT algorithm also outperformed HEFT and PEFT algorithms on real-world application graphs.
In our future work, we intend to extend the algorithm by taking Quality of Service parameters such as cost, reliability and energy into consideration.
Conflict of interest
The authors confirm that this article content has no conflicts of interest.
Footnotes
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (Grant No. 61402183 and 61070015), Guangdong Provincial Science and Technology Projects (Grant Nos. 2014B090901028, 2014B010117001, 2014A010103022 and 2014A010103008), and Fundamental Research Funds for the Central Universities, SCUT (No. x2jsD2153930 ).