
Abstract
In a piece of music, repeating patterns can be easily identified by human beings. Theoretically, similarities between repeating patterns and non-repeating patterns should be different. In this paper, we study similarities of patterns based on fingerprint features. According to the analysis results, we also present a relevant method to detect repeating patterns. Evaluations on some of familiar songs indicate that our method is promising.
Introduction
Many musical pieces generally show prominently repetitive structure. These repeating patterns are readily comprehended and commonly regarded as one of the most expressive and representative parts in music objects. Consequently, repeating pattern is commonly used to further analyze music, such as themes [1], motifs [2, 3, 4], structure analysis [5, 6, 7], music thumbnail [7, 8] and so on.
In order to discover repeating patterns, a lot of algorithms [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] have been proposed. According to types of feature data, techniques for discovering repeating patterns can be categorized into two types: alphabetic and numeric. character techniques first convert music signal into symbolization representation by a series of processing and then apply some techniques relevant to string matching to discover repeating patterns; and numerical techniques mainly process the numeric data by employing the similarity measure to detect a similar data or segment and further extracting repeating patterns from these data or segments by treatments of refinements.
However, previous works mainly focus on selecting features, improving accuracy, reducing the complexity of time and space, and so on. But, few literatures have been published about studying the similarity distribution of patterns. Actually, repeating pattern could be distinguished by human beings, and they should have explicit structures relative to non-repeating patterns. In this paper, the main aim is to study similarities of patterns. Though, durations of repeating patterns usually show tremendous variations from a few seconds to a few minutes, so it is very difficult to directly analyze as a whole. In literature [15], 256 subsequent sub-fingerprints as a basic unit were used to identify a song. This motivates us to exploit fixed-length blocks instead of patterns for analyzing similarities. According to analysis results, a related approach is also proposed to find repeating pattern and finally experiments are performed to evaluate.
The remainder of this paper is organized as follows. Section 2 introduces extraction of features; in Section 3, we analyze similarities; Section 4 detects repeating patterns; experiments and analyses are performed in Section 5; finally, we conclude in Section 6.
Scheme of Haitsma and Kalker’s audio fingerprint extraction.
What features are used mainly depends on actual applications. In this paper, we mainly focus on similar melody. In fact, the perception of repetitions is generally based on melody, which is related to note similarity. It is proved that there features [16, 17] such as Fourier Coefficients, Frequency Cepstral Coefficients, Spectral Flatness, Sharpness, CQT [5], fingerprint [15], etc., could express the perceptual features well. Here the concept of audio fingerprint can be considered as a short summary of a clip of music by exploiting fingerprint function to generate a feature sequence.
In addition, it was indicated that Haitsma and Kalker’s [15] fingerprint feature could represent the music notes more accurately and were robust against signal degradations. Therefore, it is very suitable in our research. Here we briefly review the extraction of the features as shown in Fig. 1.
Firstly, the audio signal is segmented into overlapping frames. The overlap factor of 31/32 is used to allow 5.8 milliseconds off with respect to the real frame boundaries and assure that even in the worst cases, both the query sub-fingerprints and the sub-fingerprints of the same clip in database are still very similar. Beside, each frame is weighted by a Hanning window. Secondly, raw time series data is converted into the frequency domain representation by performing a Fourier Transform on each frame. Thirdly, the frequency domain for each frame is divided into 33 non-overlapping sub-bands from 300 Hz to 2000 Hz with a logarithmic spacing. Finally, the sign of energy differences between subsequent sub-bands is calculated to obtain 32-bits as a sub-fingerprint from each frame.
Let
where
In applications, however, a single sub-fingerprint is usually too short to contain sufficient information. Thus, a fingerprint block as the basic unit is referred. Let
where
Moreover, bit error rate is usually used to represent similarity (distance). In this paper, the Hamming distance is used. If
where
Finally, we introduce the fingerprint block distance short for FD. For two fingerprint blocks
In this section, the goal is to carry out the similarity analysis based on Haitsma and Kalker’s fingerprint features. Our method is to first cut a sub-fingerprint sequence into fixed-length blocks and then analyze the similarities of blocks. There are three typical relationships between fingerprint blocks: subsequent, non-similar and similar. Here the similar refers to having similar melodies. We design three separate experiments, with respect to three aspects. The training corpus consists of 100 songs performed by both male and female singers with different musical genres.
Similarities of subsequent fingerprint blocks
Because the large overlap is used for extracting features, subsequent frames have a large similarity and are varying as the increasing FD. Therefore, it is essential to learn the distribution of similarities in subsequent 31 blocks, namely FD from 1 to 31. The objective of the first experiment is to observe the distribution of similarities for subsequent fingerprint blocks. We select all fingerprint blocks of the training corpus, which contains about 2.5 million blocks corresponding to 77.5 million samples.
The distribution of similarities in subsequent blocks.
The distribution of similarities in non-similar blocks.
The similarity distribution of subsequent fingerprint blocks is illustrated in Fig. 2. Firstly, because the lines coincide, it is evident that the similarity distribution of subsequent fingerprint blocks mainly relates to FD and is not associated with block length. Secondly, an important rule is shown in Fig. 2: as the FD increases, the similarity first decreases to the global minimum (BER gets to the global maximum), then increases and finally fluctuates around 0.5. In addition, by further observations, when
This experiment mainly indicates that subsequent blocks have a large similarity.
The goal of the second experiment is to study the similarities of non-similar blocks. Here the non-similar is relative to the similar. How to get non-similar blocks is the key to success in this experiment. In theory, each pair of fingerprint blocks from two different songs should be less likely to be similar or the probability of the similar can be almost ignored.
Based on these analyses, the second experiment is designed: randomly choose 2 K thousand pairs of fingerprint blocks for every two songs, and build 1 M pairs of fingerprint blocks from the training corpus. Moreover, to further observe similarities of different block lengths, we also choose four representative lengths: 1, 64, 128, and 256 for experiments. Finally, we calculate the BER scores for these block pairs and observe the score distributions.
The distribution of similarities in similar blocks.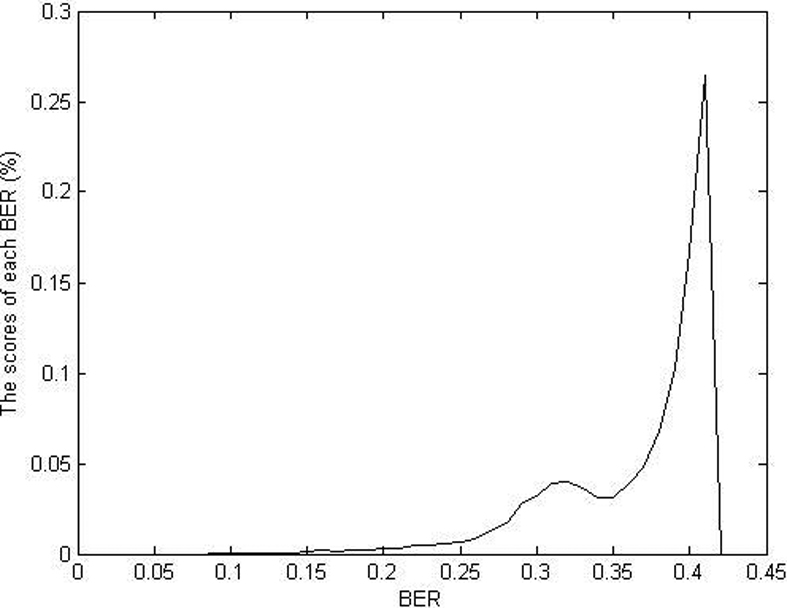
The distribution of similarities in non-similar blocks approximately follows the normal distribution as illustrated in Fig. 3. Besides, as the block length is increasing, the distribution is more concentrated, which means that the longer block is more expressive and representative.
Here we mainly focus on
This experiment shows that the non-similar similarity assumes highly localized distributions, especially, as the block length is increasing and the distribution is more centralized.
The third experiment will investigate similarities of similar blocks. We here focus on
A fingerprint sequence
where Scanning from
We exploit this algorithm to generate similar blocks and observe similarities. Dataset comes from the training corpus. Experimental results are shown in Fig. 4.
Hash table of storing similar blocks.
Figure 4 indicates that as the BER increases, the BER score reaches the first peak at
This experiment indicates that similar similarities are the smaller compared with non-similar.
In this section, according to the analyses of Section 3, a new algorithm is designed to detect repeating patterns. It has been proven that the longer block is more expressive and representative, so the block-to-block measure is more suitable in our method. Besides, repeating patterns come from similar blocks and a repeating pattern is usually consisted of many subsequent blocks, so we first capture similar blocks, join these blocks to form the longer blocks and finally obtain repeating patterns by refining the longer blocks. This approach is described as the following subsections.
Capturing similar blocks
We use the method of Section 3.3 to generate similar blocks. In addition, parameter settings are as follows: the similar threshold
Mergence
A lot of similar blocks are obtained in Section 4.1. In this subsection, subsequent similar blocks will be combined to form the longer blocks. Because of using the high overlapping factor in the feature extraction, it also causes misalignments in subsequent blocks. So the error of 32 sub-fingerprints is allowed in combining.
Mergence rule: subsequent similar blocks are combined together to form the longer block by modifying length of the first sub-fingerprint and deleting the combined nodes.
Mergence description: assume that subsequent similar blocks
then, they belong to the same pattern. Equation (8) is used to update length of the first sub-fingerprint
After merging, we obtain a lot of the longer blocks. But, there are still some of similar blocks which have not been combined. Such blocks mainly come from the noise or slightly similar blocks, which are difficult to distinguish. Therefore, in this paper, we restrict length of repeating patterns to be longer than 512 sub-fingerprints (approximates 6 sec duration) and the shorter will be removed.
In our method, using segmented blocks are to capture similar blocks, so there should be some of missing sub-fingerprints in boundaries of the longer blocks. It needs to perform the boundary refinement. This operation is very easily done by traversing along two boundaries and the whole fingerprint sequence.
After the boundary refinement, in HT, each node represents a detected repeating pattern. According to sampling rate, the duration of each pattern is easily computed.
Experiments and analyses
According to analyses of Section 3, Section 4 proposes an approach to discover repeating patterns. This section carries out experiments to evaluate the whole algorithm. It is well know that no matter what types of music, the comprehension for repeating patterns is the same. Besides, discovering repeating pattern is in the same song, so for different orchestrations, different rhythms and different human voices of a music, it will not affect the final evaluations. Thus, songs with clear structure and relatively strict repetition should be used to test for improving the quality of experiments.
These works [2, 5] have shown that pop music usually has relatively strict recurrence and clear structures. Consequently, we select a test corpus of 30 familiar pop songs, which contains male and female singers with different musical genres. We also annotate the ground truth of the repeating patterns on these 30 songs and these annotated patterns are exploited as our ground truth patterns. In annotating, such repeating patterns with longer than 6 s are chosen.
Evaluation
In this paper, the proposed method is based on similarity analysis. This subsection will evaluate our method by using three criteria: recall, precision and
According to sample rate, time representation of the annotated patterns can be easily converted into sub-fingerprint representation.
To evaluate our method, we construct two sparse
where the operator “
The precision
The
The average recall, precision and
Average performance
Table 1 shows how our approach can discover the true repeating patterns well. It shows that exploiting segmented blocks instead of the whole repeating patterns is feasible. Besides, the setting of similar threshold
In Section 5.1, it has shown that our method based similarity analysis is correct. In this subsection, we will analyze its performance. Because the longer block is more expressive and representative, the block-to-block similarity measure should be more efficient. This paper employs the fourth and fifth experiments to compare its performance with two relevant approaches: self-similarity [5] and AMG [2]. These three methods focus on melody, namely having similar melodies. Besides, their features are also similar.
The fourth experiment: computed the element-wise similarities (
The fifth experiment: randomly selected a pair of the similar blocks (
Distribution of element-wise BER scores in repeating patterns.
The distribtuion of subsequent element-wise similarities in a similar block pair.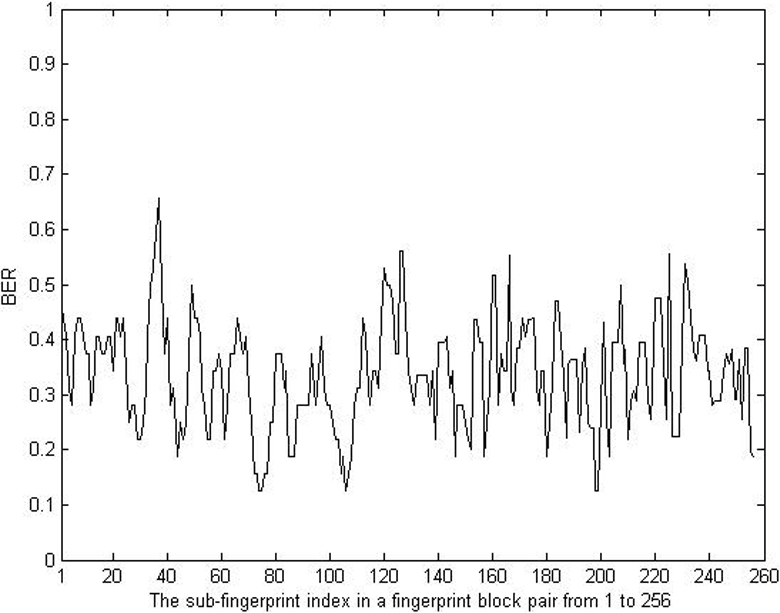
The element-wise similarity mainly lies in the domain from 0.05 to 0.8 based on detected repeating patterns as shown in Fig. 6. In each repeating pattern, the element-wise similarity greatly varies and the change of subsequent element-wise similarities is disorder as illustrated in Fig. 7. Therefore, literature [5] used a single threshold to capture similar data and literature [2] tried to use adaptive thresholds and suffix tree to capture variable similar segments based on the global correlation, clearly the ability of repeating pattern recognition is low. That leads to heavily relying on refinements to extract repeating patterns in these two approaches. In our method, the block-to-block similarity measure is applied and the longer block is more expressive and representative as shown in Fig. 3, obviously the ability for recognizing repeating patterns is remarkable. Therefore, similar blocks are easily identified and tasks of extracting repeating patterns are more efficient compared with [2, 9].
This paper mainly study and analyze similarities of patterns in fingerprint features and to verify the analysis results, a relevant algorithm is also presented to detect repeating patterns. Final evaluations show that how our approach can capture the true repeating patterns well, namely for the given conditions, similarity distributions of repeating patterns and non-similar repeating patterns can be approximately distinguishable. In addition, in finding repeating patterns, the block-to-block similarity match is employed, and the analysis results show that this method is more efficient in extracting repeating patterns.
This paper has shown that similarity analysis can be employed to study repeating patterns. It also provides a new way to understand and study repeating patterns.
In further works, we will exploit the similarity analysis to mine more valuable applications in fingerprint features and try to extend the similarity analysis to other features.