
Abstract
The image caption generation algorithm allows computer to understand the picture and generate sentences that comply with grammar rules and picture features. Under the Encoder-Decoder framework, the CNN (Convolutional Neural Networks) model is widely used as an encoder to extract image features and the RNN (Recurrent Neural Networks) model as a decoder to generate the description sentence to solve the problem of image caption generation. The most famous algorithm is the NIC, which used Inception-v3 as the encoder, and the LSTM (Long Short-term Memory) as the decoder. However, there are too many parameters in LSTM, and the quality of generated sentences is not high. In the field of visual features, deepening the network structure can improve the feature extraction ability, but the network will degenerate. Therefore, the NIC algorithm is improved. The Inception-ResNet-v2 network is used as the encoder, and the LSTMP network is introduced as the decoder. Taking BLUE-4, ROUGE, METEOR, and CIDEr as evaluation indicators, MSCOCO and Flickr30k are used as datasets to make comparative test between the NIC and the improved NIC. Experimental results show that the improved NIC algorithm outperforms the NIC algorithm in all four evaluation indicators.
Perface
Image processing techniques use computers to analyze images to achieve the desired results, and can be applied to the image retrieval, target detection, semantic segmentation, image classification, image enhancement and restoration. Natural language processing (NLP) is an important direction of the Artificial Intelligence. It is a field of interaction between computer science, mathematics, and human languages. It is the study and realization of various theories and methods for effective communication between humans and computers with natural language, including semantic analysis, information extraction, text mining, machine translation, information retrieval, dialogue systems.
Given a picture, the technology of learning and accurately extracting the image content with a computer and generating the proper text description is called image caption generation technology, which includes image processing technology and natural language processing (NLP) technology. Among them, the accurate extraction of image content includes image type characteristics, color characteristics, position characteristics, and so on. To convert the image content into corresponding text, it is necessary to realize the mapping relationship between the image content and the text features. For humans, people can easily learn the content and meaning of images based on their own thinking and analysis. But it is difficult for computers. Computers not only need to identify the objects in the images, but also need to be able to understand the various characteristics, attributes of the objects and the relationships between multiple objects, and then need to generate information that humans can understand and meets grammar rules. Early image caption generation algorithms, such as those based on templates and language parsing, have great limitations. Nowadays, image description algorithms generally draw on the research ideas of machine translation algorithms [1, 2], and use Encoder-Decoder structure. Firstly, the CNN model will be used to encode the image into a fixed-length feature vector. Then, the RNN model generates the description language. This method could generate high quality and flexible sentences. The most essential task of the image caption algorithm is to correctly describe the content of the image, and it is helpful for the visually impaired people [3]. It can also be used for image retrieval, intelligent robot interaction, and so on.
In the field of computer vision, by deepening the depth of the network, better image feature extraction results can be achieved. But there is a problem of gradient disappearance or gradient explosion, resulting in the network can not converge. This problem can be solved by the normalization method. However, at this time, the network begins to degenerate, that is, increasing the depth of the network leads to greater errors. This problem can be solved by residual network (ResNet). Compared to Inception-v3 network, Inception-ResNet-v2 network structure is more complex, but it has better image feature extraction capabilities, and can avoid the degradation caused by the deepening of the network. So we use Inception-ResNet-v2 as an encoder. LSTMP is introduced as a decoder for generating textual descriptions of image encoding content to solve the problems that there are many parameters in LSTM and the quality of generation caption sentence is not high.
Related work
The image caption generation algorithm mainly includes four methods: based on templates, language-based analysis, based on common embedding ideas and neural network.
Template-based and language-based analysis methods are the early image-digest generation algorithm. Frahadi et al. uses a template-based triple model to generate image caption [6]; Kulkarni et al. proposed a three-dimensional graphical model [7]. The model uses a detector and combines conditions to determine the objects, attributes, etc. in the image and then uses the template to generate text. The method based on the template is relatively simple, but because the sentence template is invariant, the generation sentence structure is single and fluency is poor. The algorithm model based on semantic analysis [8, 9, 10] can also describe the image content to a certain extent, but the generated description statements are still relatively rigid.
Based on the idea of co-embedding [11, 12, 13], images and text are mapped together into the same vector space. For the image queries, the description of the closest image is retrieved in the vector space. This method requires a large number of manual annotation statements. The training set must satisfy a variety of conditions and the workload is very large.
The neural network methods have a good effect on image summary generation. Mao et al. proposed m-RNN neural network model to generate image description [14]. The m-RNN uses convolutional neural network to extract image features, and uses recurrent neural network RNN to predict the next word. Xu et al. introduced the adaptive attention mechanism into the neural network, segmented the image into equal-sized image blocks, and used the features of each extracted image block as the input to the LSTM [15]. It can learn the local feature of image. Kiros et al. used a powerful deep convolutional neural network and a long and short-term memory network to jointly construct a multi-mode annotation method [16]. Donahue et al. proposed an end-to-end LRCN model for image caption generation and video description tasks [17]. Jia et al. used the g-LSTM model to generate image caption that added semantic information to each LSTM block [18].
Models
NIC algorithm model
CNN model
CNN uses a series of operations such as convolution, pooling, and activation functions. The convolution operation fully utilizes the information of the neighboring areas in the picture, reduces the size of the parameter matrix through sparse connections and weight sharing, and greatly improves the convergence speed. Convolution can extract various features in the image. Pooling can sample the features obtained after convolution. The activation operation non-linearly transforms features after convolution and pooled. The commonly used activation function are RELU, PRELU [19]. With the development of deep learning, models like AlexNet [20], VGGNet [21], GoogLeNet [22] and others have emerged.
LSTM model-based NIC algorithm
RNN adopts BPTT algorithm to update parameters. However, as the time step increases, the gradient of subsequent nodes gradually decreases in the process of back propagation, and it is difficult to update the previous nodes effectively. Therefore, the prediction accuracy is poor.
The Long Short-Term Memory is a variant of the RNN model and it solves the problem of the decrease in the perceived ability of distant nodes due to gradient dispersion in traditional RNNs. In each time step of LSTM, there are multiple gates, including Input Gate, Forget Gate, and Output Gate. The ratio of the passing information can be controlled by sigmoid function. Based on the original short-term memory unit, the LSTM model adds a memory unit to maintain long-term memory. With the deepening of research, there are many improvements in LSTM, such as GRU [23] and peephole-LSTM [24]. Ignoring bias, the internal definition and update methods are shown as follows:
The process of image caption generation using the LSTM network is an Encoder-Decoder process. Encoder maps an image to a vector representation. Decoder is the process of transforming a feature into a sentence statement based on image features. The specific process is shown in Fig. 1.
NIC algorithm model.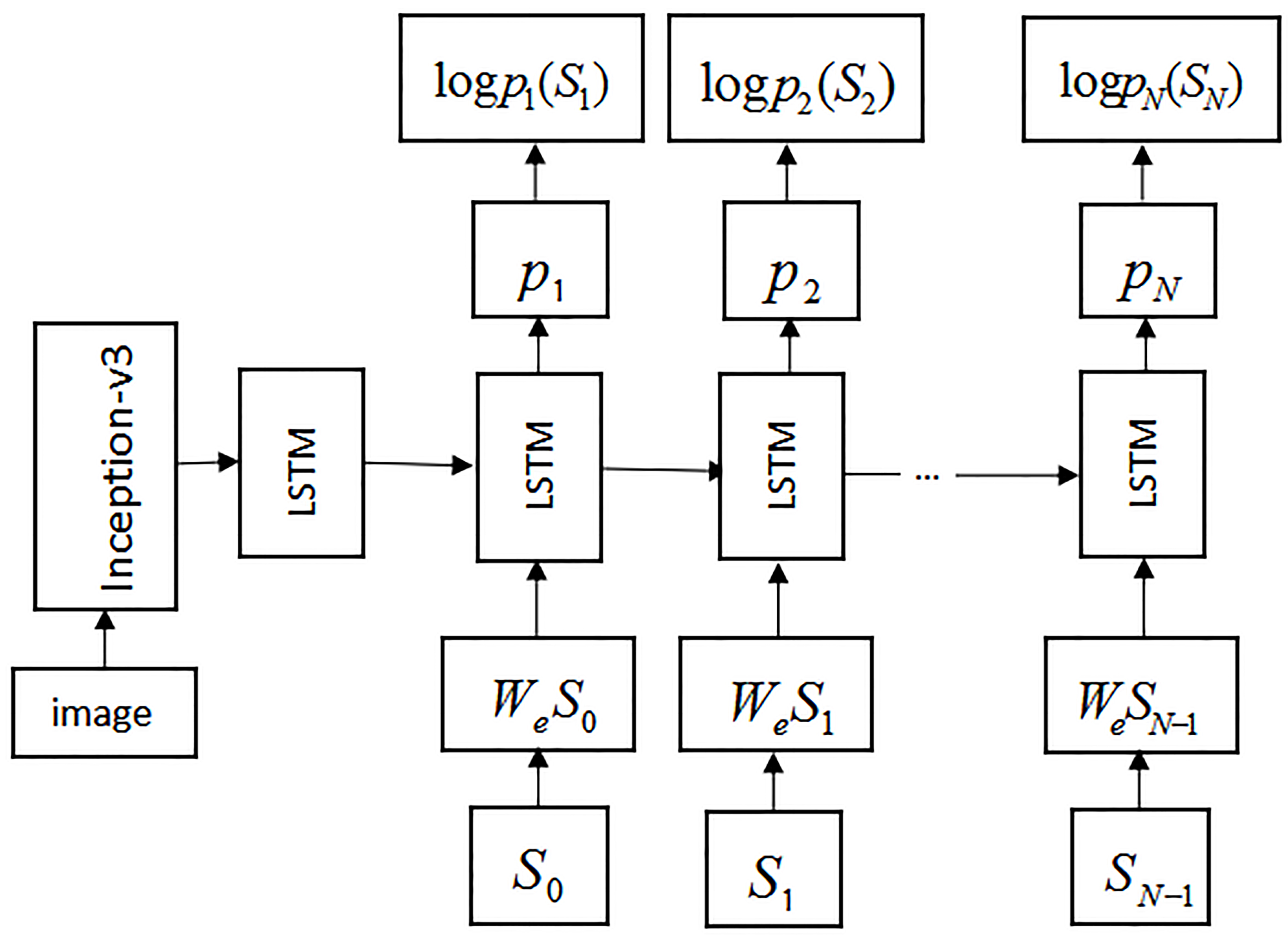
Encoding the image into feature vectors, then mapping the annotations of the image and the image feature vectors into the same dimension to generate an image caption. Using Eq. (2) to transform the image caption problem into a model of the maximum probability optimization problem:
where,
During training, (
where,
The improved algorithm model.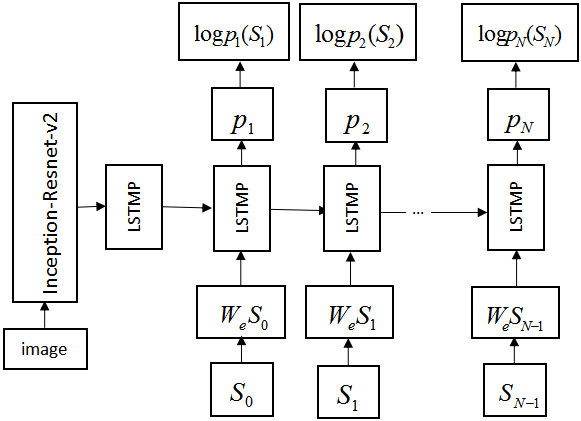
The improved algorithm model is shown in Fig. 2. The training phase and the prediction phase are different. In the training phase, the image features and the vectorized words need to be input into the LSMTP network at the same time and the input of the word comes from the actual sentence. In the prediction phase, the image features need to be input into the network and the words information are generated by the algorithm itself, and then input the generation words into the algorithm again.
In the training phase,
where,
In the test phase, a caption statement is generated by using the BeamSearch method. The beam size is 20, and Top
Resident network (ResNet) is proposed by the He et al. [25]. When transmitting information on the general convolutional layer or on the fully connected layer, information is lost to some extent. The residual network is a better solution for this problem. Information is transferred from the input to the output directly. The network only needs to learn the difference between input and output. The residual network changes the learning objectives, reduces the difficulty of learning, and avoids the problem of the disappearance of gradients and the decrease of accuracy rate as the number of network layers increase. Finally it improves the training accuracy of the network.
Residual unit.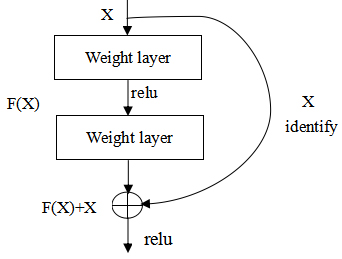
Inception-ResNet-v2 structure.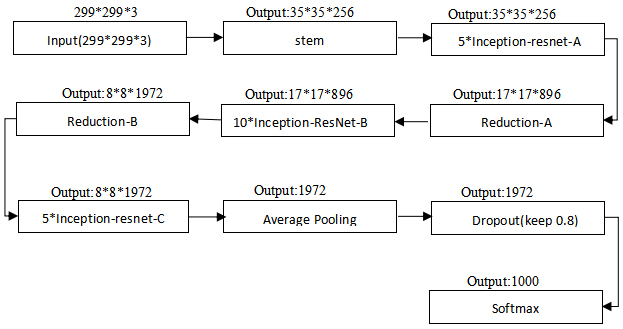
In the area of feature extraction, Google has proven that Inception-ResNet-v2 is a more effective deep learning network than Inception-v3 [26], and it is also a evolution result based on the Inception-v3 network. The depth of Inception-v3 is 42, but Inception-ResNet-v2 has a deeper structure than Inception-v3. The most important change is the introduction of residuals in each Inception module. Compared to Inception-v3, the Inception module of Inception-ResNet-v2 contains fewer parallel towers, and each Inception uses a 1
Incorporating the residual connection in all Inception modules can effectively solve the problem of network degradation, speed up the training speed of the network, and improve the extraction accuracy of image features. Before adding the residual module to the active layer, scaling the residual module with the residual scaling factor of [0.1, 0.3] can effectively stabilize the training process.
The input data is multiple batch packets which containing 32 RGB pictures of 299
LSTMP
A standard LSTM network has many memory blocks. Each memory block has a memory cell. The number of memory cells is
When the number of LSTM network input units is moderate, the network size and computational complexity are determined by
The model is based on the LSTM structure and has a separate linear projection layer after the LSTM layer. The recurrent connections now connect from this recurrent projection layer to the input of the LSTM layer. The network output units are connected to this recurrent layer. This operation changes the number of model parameters [27, 28]. Let the number of recurrent units be
The size and computational complexity of the LSTMP model are determined by
where
Datasets
LSTMP network structure.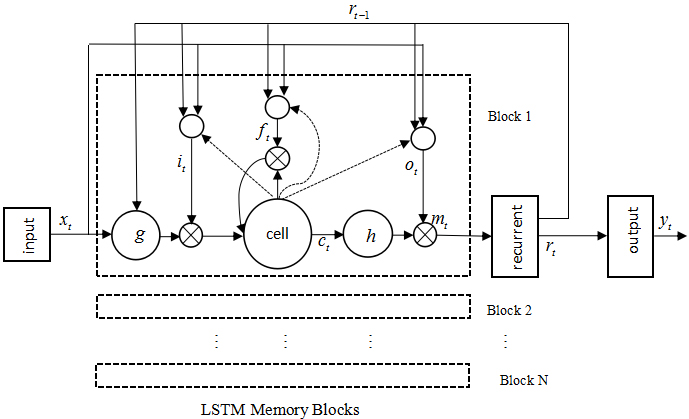
The LSTMP network is an improvement over the LSTM network. The LSMTP structure is shown in Fig. 5.
Datasets
We use MSCOCO and Flickr30k datasets. The MSCOCO data has 82,783 training set and 40,504 validation set. There is no test set. So we select 5000 images as validation set, and another 5000 images as test set from the validation set. Flickr30k has 28000 training data, 1000 validation sets and 1000 test sets respectively. The final size of the dataset is shown in Table 1. Each image has 5 personally labeled statements, as shown in Fig. 6.
Example pictures and description of dataset.
This article uses the MSCOCO datasets as an example to briefly explain the pretreatment of datasets. LSTMP network parameters, Inpcetion-ResNet-v2 network parameters and word vectorization parameters together constitute the total parameters of the improved model. There are 29,415 words in the MSCOCO dataset. But have great differences in the frequency of the description of the pictures. Therefore, all the words appearing less than 5 times are filtered. Finally, there are 11,519 words after filtering.
After training, without modifying the visual content, slight modification of any image in the training set may cause output that differs greatly from the original training image output. In order to enhance the model’s ability to deal with this phenomenon, it is necessary to modify the image data randomly during the training process, including aspects such as hue, size, position, and gray level. The input data of the Inception-ResNet-v2 is an RGB image of 299
Plenty of images are inputted into the network for training. If a single sample is used as the basic unit to correct the entire dataset gradually with reverse gradient method, the training speed will be slow or even have a problem of gradient divergence. Therefore, firstly, we transform input data into a batch package with batch_with_dynamic_pad function, then enter the batch package into network for training. In the prediction, the test data is not large, so the test data is inputted into the network with the placeholder method, and the images’ annotations need not to be inputted.
Evaluation methods
This article uses four evaluation methods: BLUE-4, ROUGE, METEOR, and CIDEr.
BLUE-4 evaluation method
BLUE is an accuracy-based similarity measurement method to analyze the number of matching n-grams between the reference statement and the generated statement. The ratio of the number of matches to the number of n-grams is used as the matching similarity. However, the word matching statistical method used by BLUE is independent of position, and it is difficult to measure the semantic information related to order.
The specific formula is:
where,
where,
ROUGE uses the recall rate as an indicator. The basic idea is using the n-gram contribution statistics between the generated sentence and the reference sentence as the judgment. The formula is as follows:
where,
METEOR finds the matching maximum values of words between the generated statement and the reference statement according to the exact match, root match, and synonym match. When the maximum value exists the same value, the dynamic programming algorithm is used to regard the matching with the least number of crossover times as “alignment”, and continue to add it to the alignment set. Then using the ratio of the number of the elements in the set to the total number of words in the reference sentence as the recall rate, and using the ratio of the number of the elements in the set to the total number of words in the generated sentence as the accuracy rate. Finally using the harmonic mean value calculates the final value.
where,
CIDEr is proposed for image description problems. The eigenvectors of the sentences are constructed by counting the word frequency information of all the image description samples, and then the eigenvectors are measured to represent the degree of similarity between the two description sentences. The specific formula is:
where, the
The larger the value of these four evaluation methods is, the better the quality of the generated cation sentence will be.
Generate statements and analysis
Some examples of the image generation description sentences on MSCOCO and the Flickr30k datasets are shown in Fig. 7. For each image, the first sentence is generated by the NIC algorithm, and the second sentence is generated by the improved algorithm. The content of the first and fourth pictures is relatively simple, and the generation sentences almost have no difference in the meaning of the picture. About the second picture, the word of “with” in the statement generated by the NIC algorithm doesn’t clearly express the action between the dog and the teddy bear. But the statement generated by the improved algorithm in this paper vividly describes the dog “holding” the teddy bear and the phrase of “laying on the bed” is a more detailed description about the dog’s movement. In the third picture, the second sentence contains a phrase of “big-eyed” that is a description about the size of boy’s eyes. In addition, “put a toothbrush at his mouth” is obviously more consistent than the “holding a toothbrush in his hand” about the picture’s meaning. In the fifth picture, the second statement contains a color word of “blonde” and feature phrase of “his mouth wide open”. These are detailed descriptions of the boy. About the sixth picture, the word of “red” in the sentence generated by the improved algorithm is a description about the character’s clothes and “others laughing” is a more accurate description of the surrounding scene. By observing and comparing Fig. 7, we can find that the sentences generated by the NIC algorithm and the improved algorithm can meet the basic meaning of the image. But the semantic of the description sentence generated by the improved algorithm is more abundant. The improved algorithm can describe more content about the image, and describe the details, including actions, colors, features, scenes and so on. These information is more accurately. So the improved algorithm is more effective.
Evaluation results on MSCOCO dataset
Evaluation results on MSCOCO dataset
Evaluation results on Flickr30k dataset
Generating option examples.
The evaluation results of the NIC algorithm and the improved NIC algorithm on MSCOCO and Flickr30k datasets are shown in Tables 2 and 3 respectively.
By comparison, it can be found that with the same dataset, the values obtained by the improved NIC algorithm in four evaluation indicators are higher than the NIC algorithm. On the MSCOCO dataset, the improved algorithm is 4.7, 3.1, 1.9, and 5.6 higher than the NIC algorithm respectively. On the Flickr30k dataset, the improved algorithm is 4.1, 3.2, 2.2, and 4.9 higher than the NIC algorithm respectively. Comparing Tables 2 and 3, we can find that both the improved algorithm and the NIC algorithm have higher evaluation results on the MSCOCO dataset than the Flickr30k dataset. Because MSCOCO training set is far more than Flickr30k’s and the more datasets are, the stronger learning ability and the better the generalization ability will have. Also the accurate of the prediction results will be. These results also show that the improved algorithm is correct and more effective.
Conclusion
The image caption generation algorithm combines image feature extraction and natural language processing technique. The image and its annotations are used as the input of the algorithm to generate sentences that comply with grammar rules and image features. This study is very challenging due to the large scale of the network and the size of the dataset. The Encoder-Decoder framework is a very good deep learning framework. The LSTM as a generator is widely used in machine translation and image description. This article uses Inception-ResNet-v2 as an encoder and LSTMP as a decoder, uses MSCOCO and Flickr30k as datasets respectively, and uses BLUE-4, ROUGE, METEOR, and CIDEr as evaluation indicators, and compares it with NIC algorithm. The results show that the improved algorithm has a good image description generation effect. In the next step, we will continue to try to improve the encoder and generator networks and look forward to improving the effect of generating image caption statements.