
Abstract
Cloud computing technology in the epoch of large data, which subvert the traditional data computing storage model completely, it is a new type of computing service model. And an increasing number of individuals become the subscribers of the cloud computing, the size of the data center is also growing, the problem of the low utilization of resource and high energy consumption are serious. Then how can we use resources efficiently, reduce energy consumption and improve service quality for the large data center. It is an important method to improve the performance of the entire cloud computing server cluster by the improvement of the cloud computing platform. This paper has studied in-depth research on mainstream open source cloud computing platforms such as OpenStackand improved the resource scheduling mechanism which existed. The works are composed of two parts: the virtual machine initial placement mechanism based on resource performance perceptionand the dynamic migration mechanism of virtual machine based on load perception.
Introduction
Big Data and Cloud Computing are the new darlings of today’s social information technology arena. They are the protagonists of this high-tech era. It can also be said the present society is a cloud computing or big data society and has crossed the IT era toward the DT (Data Technology) era [1], which can be further understood as big data cloud computing era. Cloud computing is a commercial computing model that provides processing big data services. Its core is to effectively construct a large number of scattered physical machine resources into a dynamically scalable resource pool. Users can purchase and acquire them on demand, which improves the utilization of physical resources and reduce the cost of value-added processing of massive data processing [2]. In the “Guidelines on Actively Promoting “Internet
The important feature of the massive data in the DT era is not only its large volume, but the high value of these data. Massive data with high value can only make sense if it is analyzed by specialization, otherwise it will be useless orlost its important value. In other words, massive data is a product of human information industry and a derivative product of raw materials. The profit base of the derivative industry is the ability to convert and process large amounts of data processing and processing, through processing and processing seemingly chaotic data, to explore the potential Unlimited combination value to achieve value-added data. However, with the increase in the amount of global data, the difficulty in processing these massive amounts of data has increased in different dimensions. The computing power of a single server has a limit, so cloud computing with a distributed computing architecture has the opportunity to demonstrate capabilities. Therefore, cloud computing adopting distributed computing architecture has got the opportunity of displaying capabilities. It relies on distributed processing, distributed storage, distributed databases and virtualization technologies to integrate numerous high-performance servers into physical clusters, achieving effects that one add one is greater than two. Cloud computing and big data have been like left-handed and right-handed, they are closely cooperating with each other and contribute their own power to the development of the information industry since 2013. Big data cannot be separated from cloud computing and Cloud computing also depends on big data.
With the rapidly development of big data and cloud computing, the size of cloud data centers are also growing and the problem of high energy consumption is more serious when it confront the demand for efficient and fast processing of big data requirements, which has become a major challenge [3] in the resource management of cloud data centers. The frequency of server load imbalance [4], low resource utilization, server failures. etc., which are also rising. According to IBM’s research report [5], the average CPU utilization of physical machines in the cloud data center is range from 15% to 20%, while the physical machines in idle state generally consume 70% of the peak energy consumption of the full load [6]. It can be seen that the average resource utilization rate of the cloud computing data center is very low, and the number of physical machines that are close to being completely idle is numerous, which not only causes serious waste of various physical resources, but also brings a lot of unnecessary energy consumption. Finally, the result is an increase in the cost of cloud service providers and a decline in the quality of cloud services [7]. Therefore, we need cloud computing with better performance. This paper believes that the cloud computing platform must be a big data cloud platform in the future, which namely Big Data Cloud Platform. Otherwise, when it confront the rapid growth of big data, cloud computing could integrate different computing, storage, networks and other capabilities to solve data processing problems, but performance and efficiency must drop sharply or it will not meet the needs of big data processing, so our cloud computing should also be developed and improved according to the characteristics of big data, so it could providing more powerful computing capabilities.
Understanding the theory and concepts of cloud computing is just an armchair strategist. The poet Lu You of the Southern Song Dynasty of China said that “Tell me and I’ll forget. Show me and I may not remember. Let me try and I’ll understand”. The real practice of cloud computing requires the cloud platform to manage a certain scale of data. The center has realized that the IaaS platform based on open source infrastructure services has been widely adopted by cloud computing service providers. The typical cloud open source (Open Source) platforms include OpenStack, CloudStack, Eucalypyus, etc. These open source platforms have emerged and developed rapidly. It is easier, faster, and more efficient for enterprises to provide cloud services. It also providesresearchers with the foundation of experimental learning. More importantly, resources waste and energy consumption in the cloud data center are effectively improved. But it is inevitably that OpenStack and other cloud platforms also have its deficiencies, such as the platform’s resource scheduling mechanism is too simple and there is no dynamic resource scheduling mechanism. At present, the improvement of the cloud computing platform is a good way to improve the performance of the entire cloud computing server cluster, so that the cloud computing can provide more flexible expansion space, and more importantly, the cloud computing can provide more powerful computing capabilities and complete big data processing with fast and efficient.
In this paper, we make a deep research on OpenStack from the source code. We find that OpenStack has the following problems on the scheduling of virtual machines: OpenStack virtual machine initial scheduling mechanism will lead to low resource utilizationand lack of automatic virtual machine dynamic migration mechanism during operation. And in these two processes, OpenStack’s scheduling mechanism does not have much consideration for energy saving. As the scale of OpenStack cloud continues to grow, OpenStack is become more worst in terms of resource utilization, service quality and energy efficiency. Therefore, we believes that it necessary to further study and improve OpenStack’s virtual machine scheduling mechanism.
Research status
Cloud computing platform resource scheduling has attracted more and more researchers’ attention as cloud computing development and application, and cloud computing platforms have exposed more and more problems. The current resource scheduling mechanism is researched in cloud service providers and users can find the balance between the interests of both parties. From the perspective of different interests, the goal pursued by the resource scheduling mechanism also changes with the change of roles. For example, the resource usage of the cloud data center is maximizedfrom the perspective of resource utilization. In terms of energy consumption, it is to minimize the energy consumption of cloud data centers. From the perspective of service quality, it is to ensure the performance requirements of users and the stability and sustainability of cloud data centers. Although the angles are different, they can be considered from two aspects of cloud computing platform resource scheduling.
The existing researches on virtual machine placement and dynamic migration in cloud computing platform are mainly divided into traditional heuristic methods such as first-time matching algorithm, best matching algorithm and bio-intelligence heuristic algorithm such as genetic algorithm and ant colony algorithm. In terms of virtual machine placement, Kord and Haghighi et al. proposed a virtual machine placement algorithm based on minimum correlation coefficient (MCC) for energy consumption-efficiency in cloud data centers, considering both service level agreements (SLAs) and low energy consumption, and they are used the Fuzzy Analysis Hierarchy Process (AHP) to weigh these two factors. The algorithm uses the Energy Sensing Best Match (PABFD) and Minimum Correlation Coefficient (MCC) methods. A good balance point was found between the two problems of consumption and SLA violation rate [8]. Yang et al. established a ant colony algorithm based on performance matching for virtual machine batch deployment and added performance-aware strategy and path selection mechanism to solve the resource competition problem that caused by the same type of virtual machine clustering, which is better than the existing greedy algorithm and basic ant colony algorithm, but it does not consider the resource requirements of virtual machine dynamics [9]. Liang and Ge. proposed an improved heuristic genetic ant colony algorithm GACA-VMP to solve the problem of virtual machine placement. The goal is to minimize the total resources of a group of servers, which not only to minimize the number of servers but also to ensure high resources of services. The utilization algorithm has excellent performance when the number of virtual machines are large, but this algorithm performs ordinary when the number of virtual machines are not large and considers a homogeneous cloud environment [10]. Su et al. proposed a virtual machine placement method based on double threshold-based improved simulated annealing algorithm (ISA) to solve the problem that the traditional heuristic algorithm converges slowly and meet the real generation environment to which is difficult. The algorithm improves the process of data sampling and cooling. Meanwhile the virtual machine dynamic scheduling model is defined to solve the virtual machine placement combination optimization problem, but the response time and other factors are not considered [11]. Wang et al. proposed a virtual machine placement optimization algorithm based on energy consumption and QoS perception, but the algorithm is only applicable to the tree-like data center network and the services hosted in the virtual machine are single services [12]. Yang et al. proposed an exact integer nonlinear programming (INLP) and heuristic algorithm to solve the problem of reliable virtual machine placement (RVMP), the algorithm performs well in virtual machine acceptance rate and average number of physical nodes used, but the execution time is significantly more than other heuristic algorithms [13]. Anton and Buyya proposed a DVFS algorithm applied to heterogeneous power-aware data centers to adjust the power consumption of physical hosts in the energy-aware data center according to changes in CPU resource utilization, and to place virtual machines through the first adaptation method. It reduces the energy consumption of the data center and improves the resource utilization [14]. In the research of dynamic migration of virtual machines, Liang proposed a reconfiguration framework based on request prediction and corresponding AVMR algorithm to solve the problem of dynamically allocating resources according to different needs of users. The utility ratio matrix (URM) Virtual machines and physical machines in the same data structure utilization, the algorithm can predict application requests and formulate resource allocation schemes in advance, which not only improves response time, but also ensures Qos while reducing energy consumption [15]. Liu et al. studied the virtual machine migration 3w problem in dynamic cloud environment, and proposed a SLA-based soft migration model to determine the timing of virtual machine trigger migration, effectively reducing the number of virtual machine migrations. The maximum correlation algorithm (MaCVMS) selected by the virtual machine and the minimum correlation algorithm (MiCDS) selected by the target physical machine, which reduces the migration cost of the virtual machine as a whole, and also improves the resource utilization of the physical server of the data center [16]. Bala and Chana proposed an effective resource utilization load forecasting model, the most accurate stochastic forest model was adopted and the active load balancing method effectively enhanced the performance of the virtual machine migration strategy [17]. Based on the historical data analysis, Beloglazov proposed a new self-adaptive heuristic algorithm for dynamically integrating virtual machines. The actual load data of PlanetLab in a real production environment was used to verify that the algorithm significantly reduces energy consumption and increases data center resource utilization Rate, while ensuring a high level of service level agreement SLA [14].
Those above algorithm research can all show good performance under certain application conditions, but there are also some shortcomings. This study also found that the initial placement of virtual machines did not consider the matching of the resource requirement characteristics of virtual machines with the physical host resource configuration [18]. Virtual machine resource allocation and scheduling cannot be dynamically adapted. These two issues are important that still need to be solved in the virtual machine resource scheduling mechanism of the cloud data center. This problem also exists in the OpenStack cloud platform and it is need to study and solve the basic issues.
The research is mainly focused on two major issues of cloud computing in the current big data era: low utilization of data center resources, high energy consumption and the inability of OpenStack’s current resource scheduling mechanism to meet the actual service quality requirements of large data cloud computing. This paper studies the dynamic allocation and scheduling mechanism of Data Center Virtualization computing resources in OpenStack IaaS cloud platform. It improves the initial resource scheduling mechanism and runtime scheduling mechanism of OpenStack, and proposes corresponding improved initial placement algorithm (Virtual Machine Placement Algorithms based on Resource Performance Perception, RPP-VMP) and virtual machine dynamic migration algorithm LA-VMDM to make the cloud data center can ensure the quality of service, improve the resource utilization, reduce energy consumptionand make the load of the data center more balanced.
Virtual machine initial placement mechanism based on resource performance perception
In the OpenStack cloud platform, the choice of a physical machine is the key factor in the placement process of virtual machine, it determines location of virtual machine and has a continuous impact on the overall maintenance of the data center in the late stage. Preferably, the physical machine selection is capable of long-term and stable operation without being performed frequent migration. According to the resource requirements of virtual machines, selecting the destination physical machines reasonably and efficiently, that can reduce the frequency of jitter which caused by the frequent migration of virtual machines on the physical machines and improve the resource utilization of the data center so as to ensure stable and high-performance operation of all physical machines in the data center.
Analysis of OpenStack virtual machine placement algorithm
The process of virtual machine placement
OpenStack is an open source cloud computing platform, studying the source code of OpenStack Discovery Resource Scheduling task is responsible for the OpenStack Scheduler module that determines which target physical machine aslocation of the created virtual machine to study the Scheduler resource scheduling module source. The code tells me that the Schedule_run_instance method of FilterScheduler calls the _schedule method to get a list of weighted hosts. In essence, the initial resource scheduling of OpenStack is implemented through the implementation of the virtual machine scheduling algorithm by the _schedule method, which is defined specifically in OpenStack’s source code file filter_scheduler. py. The initial four-step process of the OpenStack virtual machine scheduling algorithm is as shown in Fig. 1.
Filter the physical machine for a list of available compute nodes. The nova-scheduler module in OpenStack obtains the actual remaining resources of all physical machines and the virtual machine resource requests. Then FilterScheduler filters the list of physical machines according to the parameters required for scheduling and filters out the physical machines that do not meet the requirements for creating virtual machines. Returns the list of physical machines that meet the requirements. Weight calculation, calculating the available computing node weights. In OpenStack, the most suitable physical machine in the list of physical machines returned in step 1 is selected. The cost function is used to calculate the weight of each host and use multiple weights and resources of the physical machine. The result of multiplication is summed to obtain the weight of the physical machine. From the source code of OpenStack weight calculation, the weight of the host is actually the weighted sum of the weights given to the host by each weight class. One of the weight class definitions two ways: a. _weight_multiplier method that returns the weight of the current weight class; b. The_weigh_object method that returns the weight given to the host by the current weight class. At present, Nova defines only the standard weight class of RAMWeigher whose weight is configured by the ram_weight_multiplier configuration item in the nova. conf configuration file. The default value is The selection of target physical machine. Selecting one compute node with the highest weight from the scheduler_host_subset_size compute nodes with the highest weight as the node to create the VM. Update resources. Updating the hardware resource information of the selected compute node to reserve the required resources for the virtual machine.
OpenStack’s initial virtual machine schedule.
In the above we have analyzed the OpenStack resource scheduling mechanism, its scheduling mechanism module is relatively simple, but also because of its implementation of the concept of open source, which encourage developers to tailor their own needs to meet the scheduling needs of their own scheduling mechanism. Its initial resource scheduling mechanism is a relatively static scheduling mechanism, the virtual machine to create the end, the mechanism will complete its own mission, which no longer have an effect, that is to saythe initial OpenStack scheduling mechanism will only initial virtual Machine placement plays a role. When the virtual machine is placed, the current resource scheduling mechanism cannot implement subsequent dynamic resource scheduling, that isdynamic load-aware virtual machine migration. From this we can see deficiencies of OpenStack initial resource scheduling mechanism in resource optimization and dynamic allocation, which is an important reason for cloud computing platform resource with low utilization.
Second, there are many deficiencies in the details of scheduling algorithm. First, in weight calculation, the weight of the host is equal to the sum of the product of the weight of the host and the weight given to the host by the current weight object. The calculation of the weight does not discriminate the coefficient (weight) of the formula for calculating the weight according to the resource characteristics of the host. At the same time, there is a problem in the method of calculating the weight (remaining resources). OpenStack pre-allocates the requested resources to the virtual machine when it receives the virtual machine creation request, but the reserved resource is not 100% used by the virtual machine. However, whencomputing the remaining available resources of the physical machine, OpenStack considers that the virtual machine completely uses the pre-allocated resource, the calculation method is applicable when the utilization of the virtual machine resource reaches 100%, but the reality is that the resources of the virtual machine cannot be fully used, and the calculation result inevitably causes the resources of the physical machine not to be fully utilized. And then use the remaining resources of the largest physical machine to place the virtual machine, although the virtual machine to place an increased chance of effective, but also it cause a lot of resource fragmentation. The last choice of physical machines using a random selection, a large number of random algorithms cannot utilize physical machine resources efficiently [19].
Design of OpenStack initial placement mechanism
In view of the above problems of OpenStack, we propose a virtual machine initial placement mechanism based on resource performance awareness in paper. First, the personalized resource requirements of the deployed virtual machine are matched with the available resources of the physical machine, not only paying attention to the resource matching degree, but also adopting the pseudo over-allocation of resources, then the virtual machine on the physical machine will be added to the consideration of resource retracement in the future. We finally choose the resource retracement expectation to be small, which means that the virtual machine’s subsequent time on the physical machine has less competition for resources, and the matching degree is high which means that the resources of the physical machine and the personalized resources requested by the virtual machine are the best match. A physical machine with low resource utilization is used as a physical machine placed by the virtual machine.
Model of virtual machine placement
The initial placement problem of the virtual machine is a packing problem (Bin Packing) [20]. A lot of research proves that it is a classic NP-hard problem [21]. By loading
Min
The mapping between virtual machines and physical machines is many-to-one, that is to say one virtual machine can be placed on only one server, and 0 to multiple virtual machines can be deployed on one server [22]. Both physical and virtual machines may be heterogeneous. Both virtual machines and physical machines have the most important resource attributes of CPU, memory, bandwidth, and disk storage resources, which are independent and do not affect each other. In this paper, four resource attributes combine to determine how to match a virtual machine with a physical machine.
The OpenStack resource scheduling process is a process of using a scheduling mechanism to properly map virtual resources to physical resources. In the cloud computing IaaS platform, a virtual resource can be abstracted into a virtual machine, such as one with CPU, memory, storage, and bandwidth physical resources of Virtual machine can be abstracted into:
Meet Demand:
Equation (3) means that the sum of the CPU resources of all the virtual machines on a physical machine, which cannot exceed the CPU resources of the physical machine of the physical machine, and the other three resource characteristics also correspond to such formulas.
3.2.2.1 Physical machine resources pseudo-excess use
Virtual machines in a physical machinethat get pre-allocated resources after they are created, but they share all the physical resources of a physical machine instead of being exclusive, and there is some resource competition with them. The ideal one is that reserve sufficient resources for each virtual machine which can meet the performance requirements, but this will product problems like low resource utilization, so this article does not reserve the appropriate resources for the virtual machine, but rather when it has the appropriate resource requirements in a timely manner to provide adequate resources to ensure the corresponding performance, which does not violate the service level agreement signed by users and cloud service providers. However, OpenStack thinks that once the virtual machine is created on the physical machine, the corresponding physical machine resource is already 100% utilized. Although that may not be achieved, OpenStack always reserves the corresponding resource for the virtual machine. However, according to the study [14], it shows that most resource utilization of virtual machines in the current server cluster is only 70% at the highest level, which also means that there is always a relatively idle virtual machine, that is most of the resources allocated to the virtual machine in much time are not used completely, but when computing, the resources allocated to the virtual machines are used to calculate the resource utilization of the physical machines, which leads to a corresponding decrease in the resource utilization of the physical machines, resulting in the waste of resources.
In order to solve the above problem, we need to define the usage of resources in the initial placement of virtual machines in this paper. In the operating system, overuse of resources refers to allowing the task request to use more resources than the physical machine can provide the actual resources [19], of course, this is only a theoretical resource pseudo-over-use.
In terms of computing, the total resources pre-allocated by all the virtual machines on the physical machine have exceeded the actual resources that the physical machine can provide. However, all the virtual machines actually consumes the total of multiple resources and do not exceed the actual resources of the physical machine. Taking memory as an example, assuming that there is a physical machine with 8 G memory, the memory usage of each of the 5 sets of 2 G memory in the definition 1 which is hard to reach 100%. Assuming that most of the 5 virtual machines can achieve the highest usage of resources Situation, the utilization rate reached 70%, calculate the actual use of these 5 virtual machine 7 G memory, physical memory does not exceed the real memory resources 8 G, which is the pseudo-excess use of resources. the surface from the pre-distribution point of view, the resources have been overused, but the actual situation, there are remaining resources, there is no real excess.
At present, OpenStack also makes technical support for the excessive use of physical resources of this platform. In this paper, we try to avoid the situation that pseudo-over-use is converted to true over-use when pursuing the pseudo-over-use of resources, otherwise the service-level protocol violates the probability. Therefore, it is necessary to find a balance point between the excessive use of resources and the violation of service levels. On this issue, it is reasonable that the service level agreement should be controlled within 3% in the literature [19], and it is verified through experiments that the resource upper limit multiple is set to 1.5 finally. The article also verifies with specific experiments, in the experimental environment of this article will eventually be set to 1.2 multiple.
3.2.2.2 Material virtuality to match the performance of resources
For a virtual machine to be allocated, it looked for a physical machine which is closest to the resource request and it as a distribution selection target, matching the expectation of the performance of the virtual machine resource with the performance of the idle resources of the physical machine to find the most suitable one for placing the virtual machine, that is the best match of the physical machine, which reduce resource fragmentation.
In order to obtain the matching degree of resource performance between the physical machine and the virtual machine to be placed, this paper uses Eucidean distances to measure the degree of resource performance matching between the physical machine and the virtual machine through
3.2.2.3 Resource retracement expectations
The cloud service provider provides the resources which get the requirements according to the user resource request, and ensure to provide virtual machines with corresponding performance for users, and the resources are allocated according to the pre-allocation on-demand manner, that is the corresponding resources are reserved for the virtual machines. Actually, physical machine resources are shared by the virtual machine, which are not exclusive, there is no need to reserve resources, only it need to be able to provide resources when the virtual machine resource requirements, ensuring that the performance of the virtual machine to meet the service request, and because the virtual machine cannot always maintain 100% of the pre-allocated resources requirements, and most of the time, only part of the pre-allocated resources to meet the performance requirements, which resulted in a lot of resources are idle, so we are using pseudo-excess resources, in other words, it is over-allocation of resources. Pseudo-over-allocation is not really excessive use of resources in nature, the real over-use of resources will result in reduced service performance, which is completely unacceptable after the user paid. In this paper, the pseudo-over allocation is actually make some of the virtual machine temporarily idle resources “secondment” to other resources, at the same time demanding the use of virtual machines, since it is a secondment, then the source of virtual machines in the face of high-performance requests, It will need to retract its own resources that were previously loaned out. As this time, the utilization rate of physical resources is high, the chances of failing backwards will be raised because there are not enough resources to retrace the borrowed source virtual machine. Itis inevitably bringsthe migration probability of the virtual machine to increase and affect the performance of the entire cloud platform. In order to reduce such impact, we propose the concept of virtual machine resource retracement expectations (
The essence of expectation of virtual machine resource retracement is the expectation of the resource retracement by the virtual machine that has called out the resource. That is different from the expected value in mathematics, which need to be distinguished. In this paper, the expectation of demand for withdrawing resources by virtual machines is the desire degree of withdrawal of virtual machines on the resources that are loaned out, that is the expectation of withdrawals of resources loaned out.
Expectancy theory was proposed by Viktor Vroom, it shows that motivation depends on assessment of the value that the result of the action and the likelihood of achieving the goal, which is Exciting Force
In this paper,
Finally, the evaluation index selected by the physical machine is the function matching of the virtual machine’s resource matching with the physical machine, the resource withdrawal expectation of the physical machine and the resource comprehensive utilization rate of the physical machine, as shown in formula Eq. (11):
Form the previous analysis, it is known that match degree
If the virtual machine in all physical machine of current data center which did not find a suitable objective physical machine, it means that the resources available of physical machine at the data center cannot meet the request of virtual machine resources, because the number of cloud data center server is dynamically extensible, this will make a new physical machine as the purpose of the physical machine, if a lot of physical machines in current data center is a low load condition, the virtual machine which in low load of the physical machine will migration until it is free. Finally, closing the physical machine and reducing energy consumption.
In the operation process of OpenStack cluster, there may be the following statements: a Nova Compute node running many virtual machines, which have been overwhelmed, but other nodes may be free and even without any operation of a virtual machine, this situation mean load is not balanced between the different physical machine. As this time, if the migration of virtual machines from computing nodes to busy idle nodes, it can achieve better load balancing. Dynamic migration of virtual machine is process of resource allocation that reposition the cloud data center caused by load aware virtual machine dynamic optimization. Dynamic migration of virtual machine is divided into three stages, monitoring the resources of the physical machine and virtual machine, virtual machine migration time judgment trigger (when), which is to determine the virtual machine migration of virtual machine (which) and to find the physical machine migration of virtual machines (where), that is problems of 3 W (when, which, where) [25]. This section studies the problems in the 3w process, taking into account the physical machine virtual machine migration time of the most appropriate and most suitable for migration of virtual machine and find the most suitable one, completing the dynamic migration of virtual machines fast and efficient, enhancing cloud data center resource utilization rate and reducing the energy consumption [26].
Dynamic migration mechanism of OpenStack virtual machine
After analyzes dynamic OpenStack migration mechanism of the virtual machine, we found that OpenStack does not automatically trigger the transfer, that is say only the administrator select the source physical machine and decide when the virtual machine begins migration, virtual machine migration and choose a physical machine as the target host to receive the transfer to choose a virtual machine, the whole process in the management of the page is completely artificial manual operation and lack of real-time and accuracy, when OpenStack cloud platform positioning the target host only through the remainder of the amount of memory filtering host to decide. Regardless of other resource attributes, this does not meet the requirements of large-scale data centers in today’s enterprises, and there is an urgent need for accurate and efficient algorithms to solve these problems. OpenStack cloud platform uses the mainstream virtual machine online migration currently which is live migration, its core technology uses pre copy, which only needs a short time downtime to complete online dynamic migration operation, and it has little effect on the quality of service.
Therefore, this paper mainly expounds the live migration transfer operation of OpenStack, virtual machine migration in OpenStack cloud platform is mainly carried out in the Nova package, it involving three modules of Nova components. They are: Nova_Compute module, Nova_Scheduler module and Nova_Conductor module, virtual machine migration process is completed by the three modules. The first is the Nova component get informations that is migration of virtual machine information and through the _migrate_live() method calls to acquire the physical machine migration of virtual machines, but the real operation of virtual machine migration is completed in the Nova_Compute module, the physical machine selection is completed by the Nova_Scheduler module when the administrator does not specify a target of course in the physical machine, if you have specified physical machine, then you do not need to use the Nova_Scheduler module, Nova_Compute module call live_migrate() method, at the same time the call method send the informations that virtual machine is migrating by sending a AMQP message queue, then Nova_Conductor module calls its execute() method to perform dynamic migration of virtual machines, Libvirt-driver live_migration (last call methods of heat transfer). After the success of the heat migration, the hypervisor take over in libvirt runs on the virtual machine operation of the target host, and the specific calling process is shown in Fig. 2.
OpenStack live migration method call flowchart.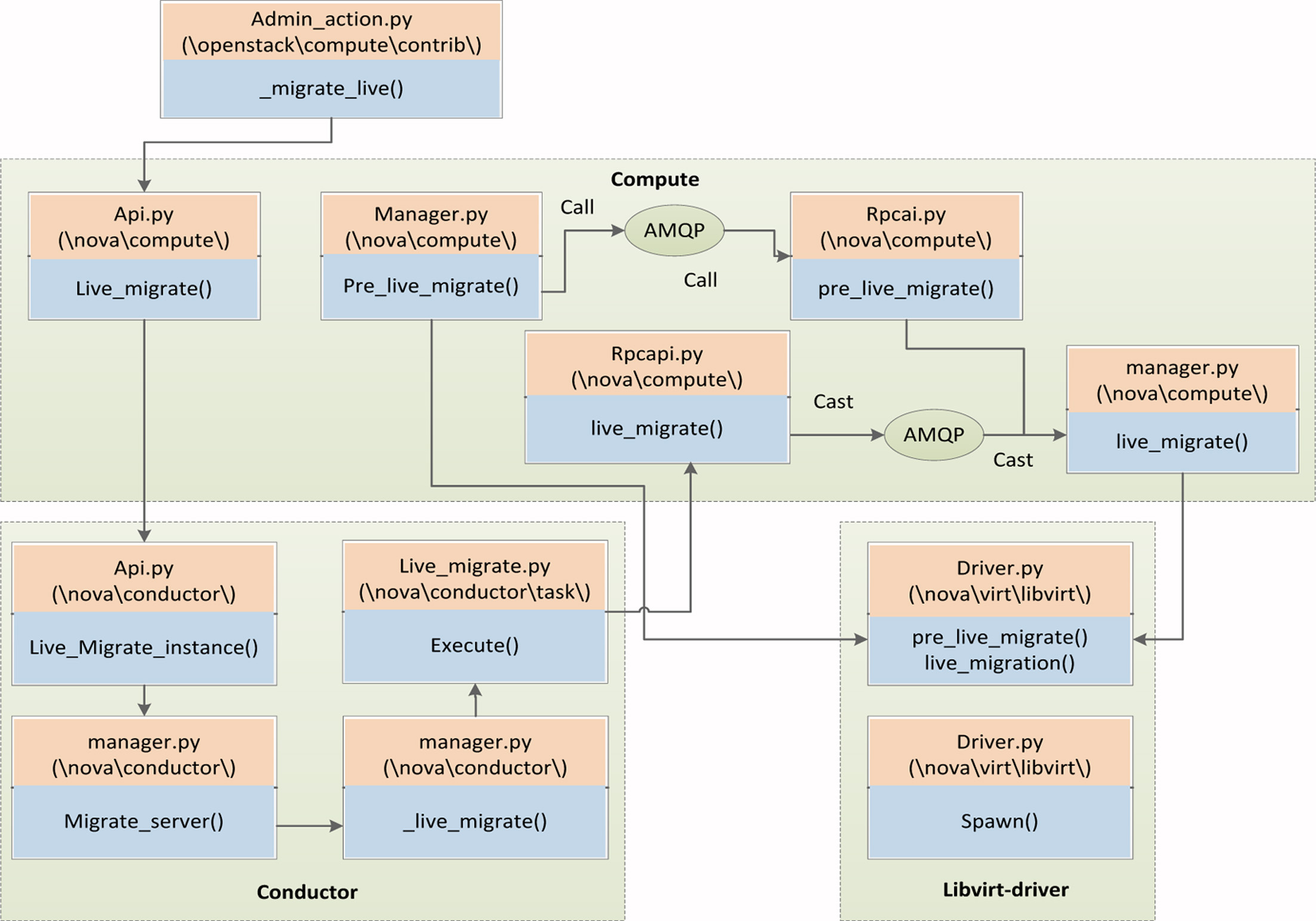
Description of the problem
The migration of virtual machines trigger mechanism is that when physical machine trigger upper and lower thresholds which lead to dynamic migration, the specific way is collect resource usage which is physical machine in cloud data center and virtual machine CPU, memory, storage and bandwidth resources, determining the physical machine resource utilization is or not meet the normal range. The migration of virtual machines divided into the upper and lower threshold trigger, it is determine the physical machine state is overload or low load, the literature [27] research shows that the resource utilization of CPU is not only the key factors that affecting the cloud data center energy consumption, but also the weathercock of the cloud data center in the whole, so according to the utilization rate of physical machine CPU resources and set a lower threshold in this paper, which is the transfer trigger condition, judging the CPU load conditions and detecting whether the host is need to make the operation of the above virtual machine migration to the target host.
Documents [28, 29, 30] set the static threshold to trigger the migration of virtual machine. At the same time, all the upper and lower threshold values were set to 30% and 70%, that is to say when the CPU utilization rate of physical machine is not in interval [30% or 70%], it will trigger the migration of virtual machine. To a certain extent, it can trigger the migration of virtual machine effectively to achieve the effect of data center’s resource scheduling and adjustment. If one static threshold is set, it will cause unnecessary migration due to the instability of physical machine CPU utilization. In order to response instantaneous shock rate of the CPU utilization rate and avoid the instantaneous load peak trigger threshold caused by migration, this paper collected historical physical machine resource usage and analyze the historical changes of the load. The physical machine load overload detection and strong local weighted regression prediction algorithm SLWR is used to predict whether the resource utilization rate of physical machine is still higher than the set threshold at the next time. It is prospectively determined whether the physical machine is overloaded and whether it needs to migrate.
Design of migration trigger mechanism of virtual machine
The virtual machine trigger migration mechanism TMM (Trigger migration mechanism) in this paper is a migration trigger mechanism that based on the prediction model, which can avoid unnecessary migration. The process of the mechanism is that when system detect the resource utilization of physical machine in the data center, which has exceeded the threshold interval that we set. In this paper, the reference [19] study set the trigger threshold range of virtual machine migration is
It is based on historical data utilization of CPU resources of the host computer in this paper. which is more than a time series prediction to use physical host next time to monitor the rate of CPU [31], usingSLWR algorithm to weighted load data of some hosts, and then estimate the fitting value by weighted least square method to predict the CPU utilization of the physical host at the next moment. The strong local weighted regression method is composed of two parts: local regression and local weighted regression. The fitting process is robust. Strong local weighted regression (SLWR) is an improvement on the local weighted regression (SLWR) algorithm. In this paper, the physical machine CPU resource utilization of the specific process is as follows:
At each monitoring moment, the estimated value of the m-order polynomial regression
The m-order local weighted regression method is used to calculate the estimated CPU resource utilization rate
At each monitoring moment, the weight of the regression estimation process Repeat steps 2 and 3 more than once, and finally get a strong local regression
The strong local regression fitting value
Because the migration of the virtual machine involves the trigger up and down migration, it is explained that the upper bound trigger condition is different from the priority of the lower limit trigger condition. Because the migration of the virtual machine involves triggering the migration of the upper limit and the lower limit, it is indicated here that the priority of the upper limit trigger condition and the lower limit trigger condition are different. As soon as the resource usage of the physical center of the data center reaches the upper limit, it needs to be processed in time. Otherwise, the performance of all the virtual machines in the physical machine will be degraded. However, the lower limit will not be affected for a short time. Therefore, Priority lower than the upper trigger, and in the lower trigger the migration process, if there is no suitable physical machine to place the virtual machine, then abandon the scheduling rather than re-open a physical machine as the target host, because it is turned on, it only turns a low-utilization physical machine into another one, and it brings a lot of virtual machine migration, resulting in a decline in service performance provided by the data center.
Description of the problem
Now that the OpenStack cloud platform which does not have the mechanism to independently select the VM to be migrated, the administrator issues an operation command to designate which virtual machines to be migrated as virtual machines to be migrated, that is man-appointed manner. In the existing migration algorithms, some select the resource with the largest resource volume as the virtual machine to be migrated in order to relieve the overload of the physical machine as much as possible, and others select the resource in order to quickly complete the migration of a single virtual machine. The smallest virtual machine is a virtual machine to be migrated. Therefore, the migration algorithm considering only one factor which has some limitations and cannot be well adapted to the migration of numerous virtual machines in a large-scale cloud data center. Considering both the impact of performance degradation and the migration time involved in the process of virtual machine migration, that is consider the cost of dynamic migration of virtual machines, which not only considers the CPU resources but also the memory resources, and proposes the virtual machine selection based on the minimum migration cost Mechanism MMC-SM (Minimum migration cost Selection mechanism) to balance resource utilization and quality of service issues.
Design of virtual machine selection mechanism
When migrating virtual machines, researchers consider the overhead of migrating virtual machines, which is generally measured by the time it takes to migrate. That is the ratio of memory to bandwidth is chosen to migrate a small number of virtual machines
According to Eq. (15), we can see that the magnitude of performance degradation is proportional to the scheduling migration timing, and the migration cost is measured by the migration time. The virtual machine migration time is defined as the ratio of memory to bandwidth.
As can be seen from the point of view, the author’s view is to choose a virtual machine with the least migration time, which means that the migration cost is the least. Literature [7] proposed a virtual machine dynamic integration algorithm AOTS-VMDC based on adaptive overload threshold selection. The minimum transfer time is selected based on the virtual machine migration. If this method is adopted, there will be the following: after the migration of virtual machines
Section 4.1 shows that virtual machine migration only needs to copy the virtual machine memory state. The migration process is short means that the migration time is short and the impact is small. However, the number of migrations has a great impact on service quality and cloud provider benefits. In this paper, the number of virtual machine migrations are ignored by many research scholars is taken as the first consideration. Secondly, the migration time of virtual machines is considered. One of the keys to the algorithm in this section is to minimize the number of virtual machine migrations. Minimizing the number of migrations means choosing the best virtual machine to migrate each time, migration means that as long as one or more virtual machines can make the utilization rate of return to the safety value of physical machine resources CPU. Section 4.2 sets the trigger threshold range of virtual machine migration
For example, the CPU utilization rate of existing physical
Equation (18) shows that as long as the actual consumed resource volume
Slightly different from Eq. (16),
If the migration times
Because this section considers not only CPU resources but also memory resources, if a physical machine is overloaded with only CPU usage and memory usage is within normal limits, a virtual machine whose CPU resource usage satisfies Eq. (18) is selected. If the physical machine’s CPU usage and memory usage are both overloaded, you will need to select virtual machines that have both CPU and memory resource consumption that satisfy Eq. (18) so that the CPU and memory resources of the physical machines are relieved after the virtual machine migration is successful. If no virtual machine can satisfy Eq. (18), then the virtual machine with the largest amount of resources
To sum up, when selecting a migrated virtual machine, the number of virtual machine migrations and the time of migration are taken into consideration. That is the virtual machine with a small impact on performance degradation and a small migration duration is selected for migration.
Description of the problem
When the virtual machine to be migrated is selected, during the virtual machine migration, a suitable target physical machine needs to be found to receive the virtual machine. When the Nova_Scheduler module in the OpenStack cloud platform selects a target physical machine, it only considers the amount of memory left by the host and does not consider other resources [34], which is not sufficient. This paper elaborates the initial placement mechanism of OpenStack virtual machine in the third section, which is to find the suitable placement physical machine for the virtual machine. In this section, we find the suitable placement physical for the virtual machine in the process of dynamic migration Machine. Therefore, based on the content of the third section, the target host selection mechanism for the dynamic migration process is proposed.
In the placement mechanism proposed in Section 3, it is more appropriate to think that the physical resources of the remaining physical resources are closer to the resources required by the virtual machine, the physical machines are selected according to the size of the comprehensive evaluation indexes
Design of target host selection mechanism
Taking full account of the correlation between the physical node’s resource matching retracement expectation and the multi-resource utilization between the virtual machine and the physical machine in this paper, and considers the distributed allocation of virtual machines and uses a probabilistic move to select migrate virtual machines to avoid clustering effects [37]. According to the literature [38], this paper borrows probabilistic roulette in genetic algorithm to select the destination physical machine, and makes the resource dependency matching retraction expectation in the following into probabilistic roulette. By means of generating random numbers in a certain area of the roulette Choose, specific steps are as follows:
Calculate n candidate hosts by using the RPP-VMP algorithmthat was proposed, and match the retracement expectation Consider the correlation between resource utilization of virtual machines to be migrated and resource utilization of many target physical machines, the correlation coefficient is defined as
Calculate resource match retracement expectation
According to the probability was in Step 3, making a selection probability roulette for each target physical machine to be migrated correspondingly, as shown in Fig. 3 below, the concrete realization can be achieved by generating a random number between (0, 1) to achieve the selection of the target physical machine.
Virtual machine choice probability roulette.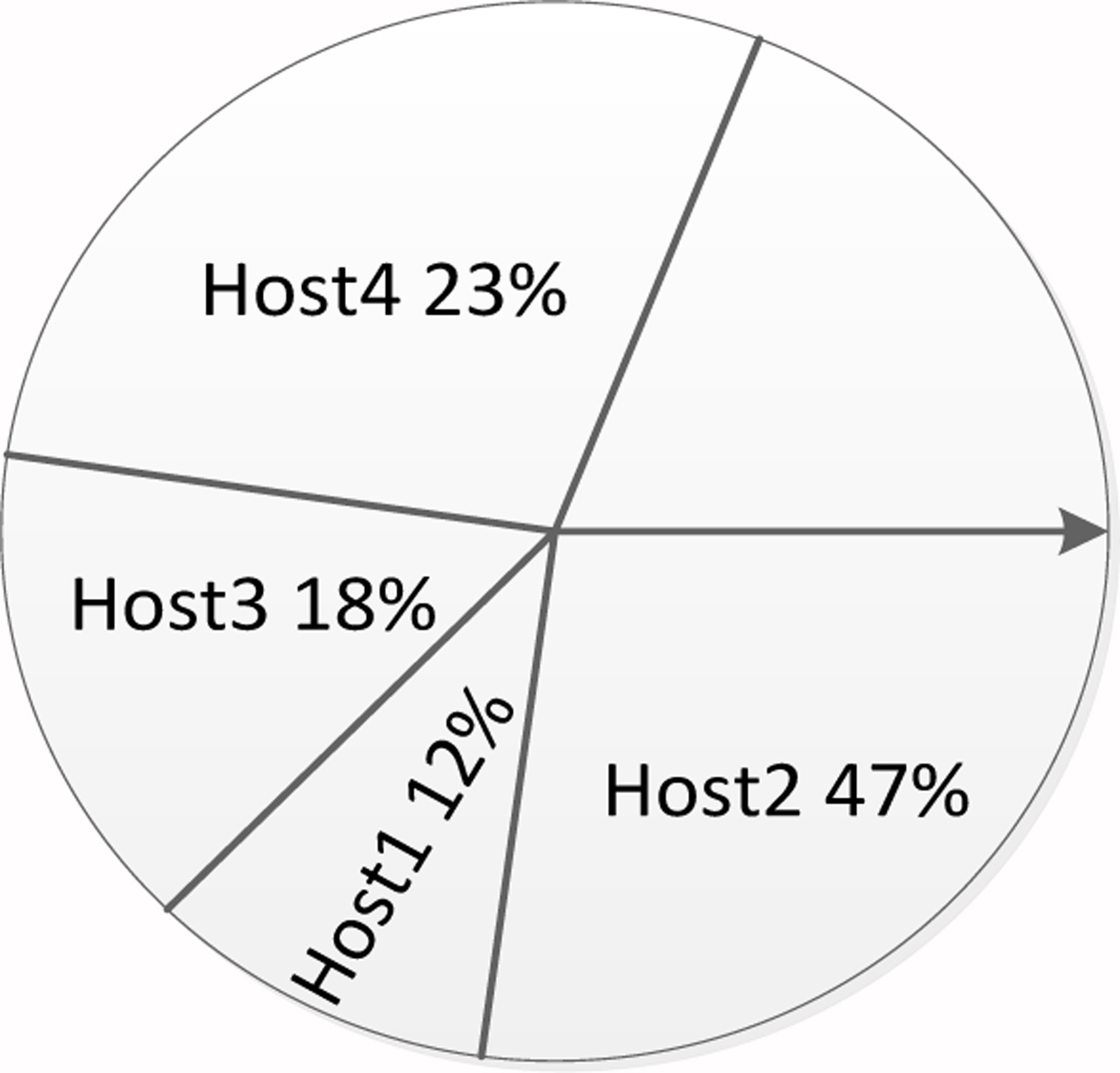
As can be seen from the above figure, the physical machine withlarger
In the above Sections 4.2–4.4, the mechanism corresponding to the virtual machine dynamic migration 3w problem is elaborated in detail. They are the prediction-based SLWR-TMM mechanism for determining when to perform virtual machine migration, and the minimum migration based on the virtual machine to be migrated. The cost of the MMC-SM mechanism and the probabilistic disk-based PR-DPS mechanism that locates the virtual machine to which the virtual machine is migrated. These three mechanisms constitute the load-aware virtual machine dynamic migration algorithm LA-VMDM (Load-Aware Virtual Machine Dynamic Migration Algorithm). When a large number of cloud tasks are being executed in the data center, the load of the data center changes at any time. Once a physical machine is overloaded, whether the virtual machine on the physical machine needs to be migrated is determined by using SLWR-TMM, and if necessary, then the MMC-SM selects the virtual machine with the least cost to migrate for dynamic migration. Finally, the virtual machine is placed on the most suitable target physical machine by using PR-DPS. The dynamic migration process of the virtual machine is completed, that is the circuit of the virtual machine dynamic migration algorithm LA-VMDM based on load sensing.
Simulation process of LA-VMDM algorithm
The pseudo code implementation and specific process of LA-VMDM algorithm simulation are shown in Fig. 4.
LA-VMDM algorithm flowchart.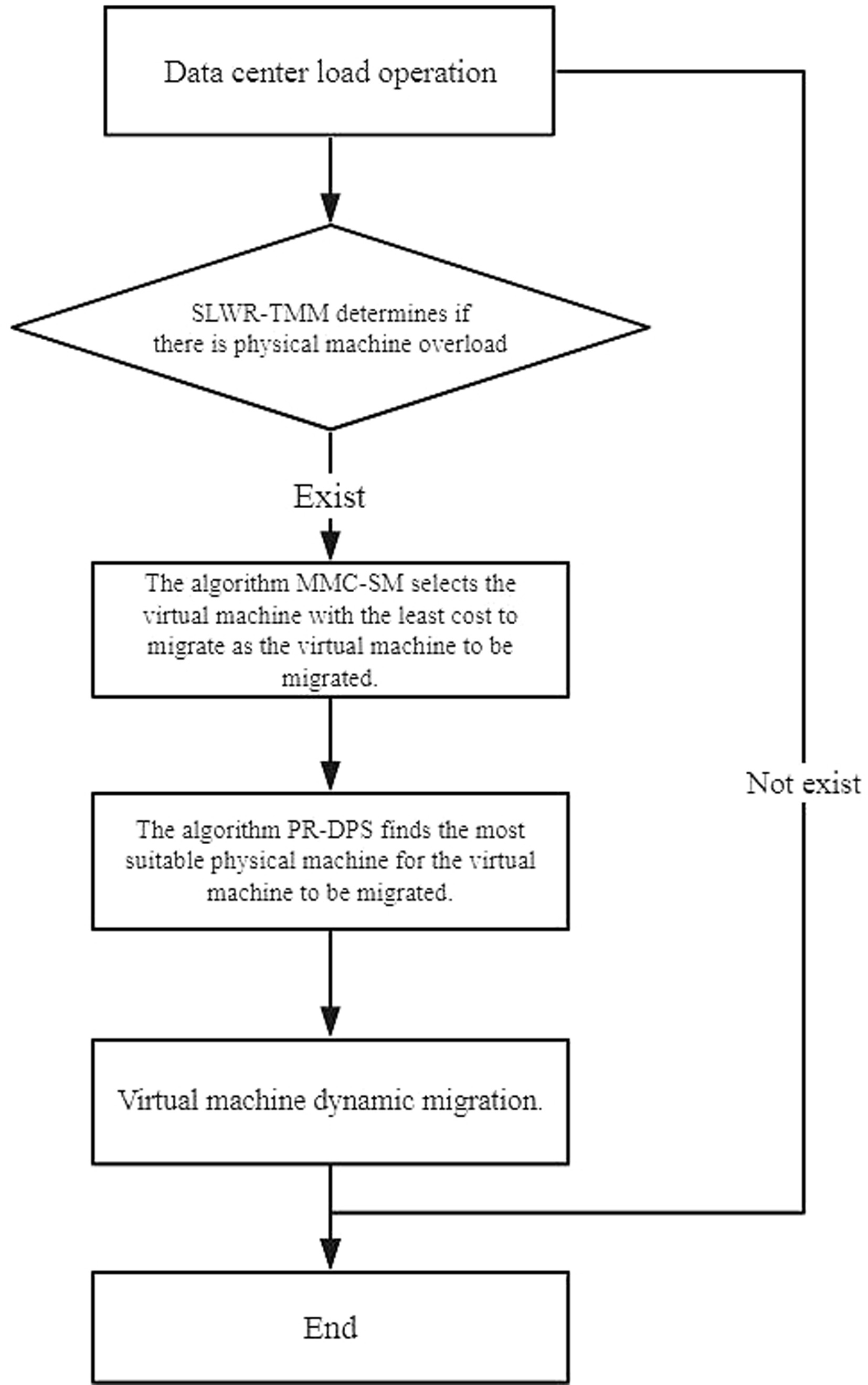
The LA-VMDM algorithm is also simulated in the CloudSim cloud platform through Java language. The important class diagram of the LA-VMDM algorithm is shown in Fig. 6. The specific process is as follows:
The newly written main entry LAVMDM class of the algorithm, which has only one main method, specifies the workload data workload and the algorithm vmAllocationPolicy placed by the virtual machine, and the virtual machine selection algorithm vmSelectionPolicy during the dynamic migration of the virtual machine; Call the CloudSim’sPlanetLabRunner class’s init (String inputFolder) method to specify the data center’s physical hosts and virtual machines list, then create a cloud task list; The PlanetLabRunner class inherits the simulation run abstract class RunnerAbstract starts the submission of the virtual machine list and the cloud task list and overrides the getVmAllocationPolicy() method of the RunnerAbstract class, which invokes the overridden virtual machine to place a subclass of themigration abstract class PowerVmAllocationPolicyMigrationAbstractPowerVmAllocationPolicyMigrationStaticThreshold (Optional) public PowerVmAllocationPolicyMigrationStaticThreshold (List At the same time, we call the prediction method based on the prediction of the virtual machine trigger migration algorithm SLWR-TMM implementation class PowerVmAllocationPolicyMigrationLocalRegressionRobust in the construction method to predict the next time the physical machine CPU utilization to determine the physical host load state, this class inheritance to achieve local weighted regression Method LR class PowerVmAllocationPolicyMigrationLocalRegression; New wrote a minimum migration cost class PowerVmSelectionPolicyMinimizePredictedRelevant, this class inherits the abstract class PowerVmSelectionPolicy, call the minimum Vm override VmgetVmToMigrate (PowerHost host) if it is determined in step 4 that the physical machine load status is overloaded or underloaded, Method, the method selects the virtual machine with the lowest migration cost as the virtual machine to be migrated according to the idea of the MMC-SM mechanism; Rewrite the virtual machine to place the getNewVmPlacement() method in the migration abstract class PowerVmAllocationPolicyMigrationAbstract, which calls the target physical machine positioning method PRMDHFindHostForVm (vm, excludedHosts) newly written according to the virtual machine migration target selection mechanism PR-DPS proposed in this paper. Find the right place for the migrated virtual machine.
Experimental conditions
UsingCloudSim simulation platform to simulate a real production cloud data center, the analog data center is composed of 800 heterogeneous physical machines, the physical host is divided into two types, which are Hp ProLiant ML110 G4 and Hp ProLiant ML110 G5, the specific parameters of resourceattributes are shown in Table 1. In order to better get close to the actual production environment, Amazon EC2 virtual machines are used in the experiment. There are four types of EC2 virtual machines in the experiment: Hypervisor VM1, Hypervisor VM2, VM3, and VM4, the specific resource attribute parameters are shown in Table 2. Cloud Mission Data Ten days of CPU resource real load data in the real production environment of the PlantLab platform provided in [17] is used to better verify the effectiveness of the algorithm in a real production environment. Because the actual utilization of the four kinds of resources such as virtual machine CPU, memory, disk and bandwidth required for the experiment in this paper cannot be accurately obtained in the CloudSim platform temporarily, reference [39, 40] and the normal utilization of the four resources in the actual production environment Rate range, the utilization of the four kinds of resources in the experiment is set to satisfy the normal distribution, in which CPU, memory, disk and bandwidth are respectively normal distribution N (0.1, 1), N (0.3, 1), N (0.2, 0.5) and N (0.1, 1).
Server host parameters
Server host parameters
Virtual machine parameters
Actual production environment load data
LA-VMDM algorithm important class diagram.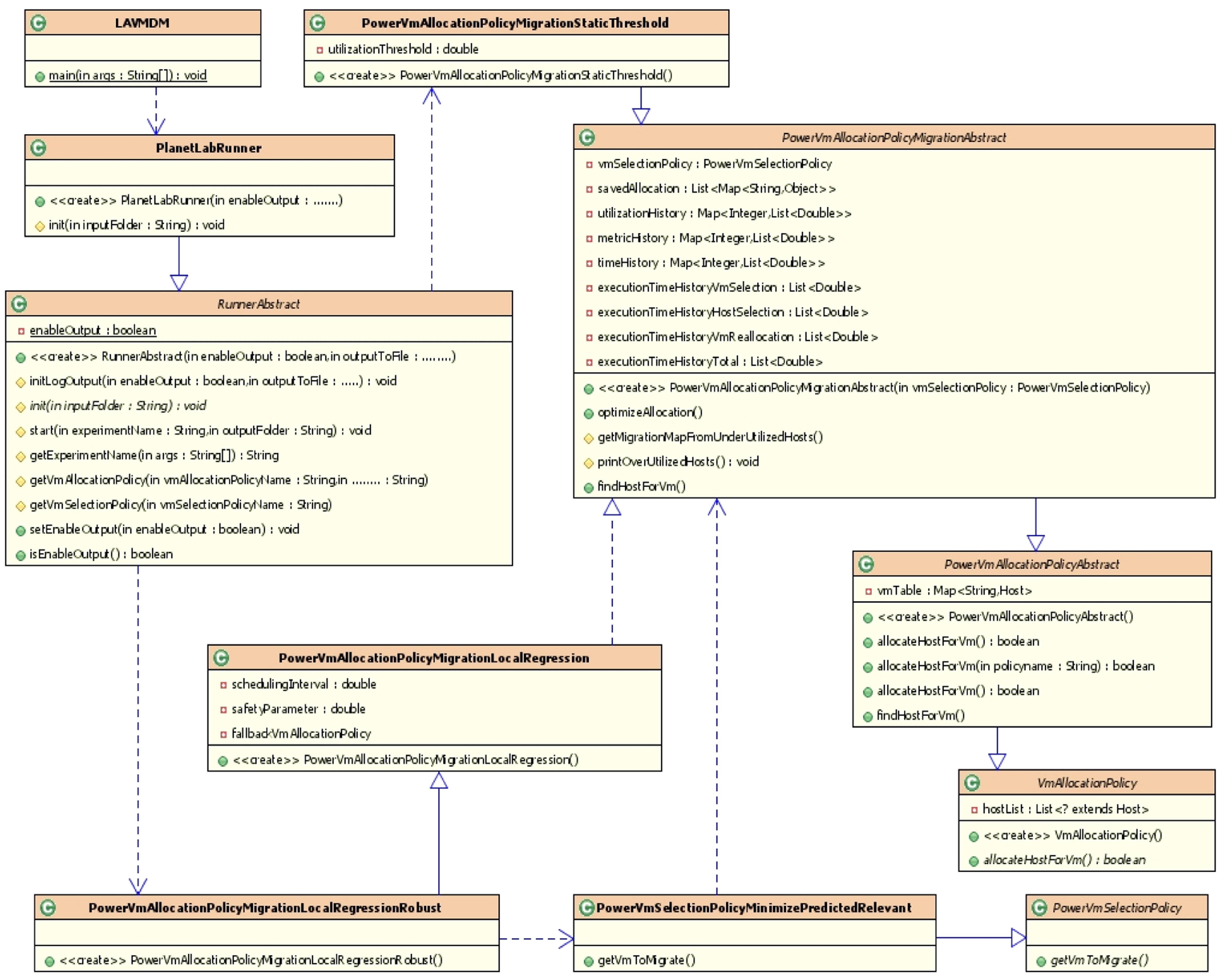
In the literature [14], in order to assess the performance of the algorithm fairly, many performance evaluation indicators are proposed. In this paper, we refer to the literature [14] and propose seven performance evaluation indicators according to the characteristics of the algorithm. They are as follows: service level agreement violation rate SLAV and energy consumption EC’s Energy and SLA Violation (ESV), Total Performance Degradation (TPD), Number of VM Migrations, CPU Utilization Average, CPU Utilization Uneven Degree, Number of running hosts (NRH), and Energy Consumption (EC). For example, the physical host overload detection algorithms ST, MAD, IQR, LR, and the virtual machine migration selection algorithm MMT, MC and RS are implemented in CloudSim. The literature [7] shows that both LR-MMT and LR-MC have comprehensive advantages in performance evaluation. Therefore, the LA-VMDM algorithm in this paper is compared with LR-MMT and LR-MC algorithms. The result is that the three algorithms correspond to the average of the experimental data obtained from the 10 different workloads in Table 3 to ensure the comparability and validity of the algorithm.
The concept of ESV is proposed in literature [17],
ESV.
Sum of performance degradation.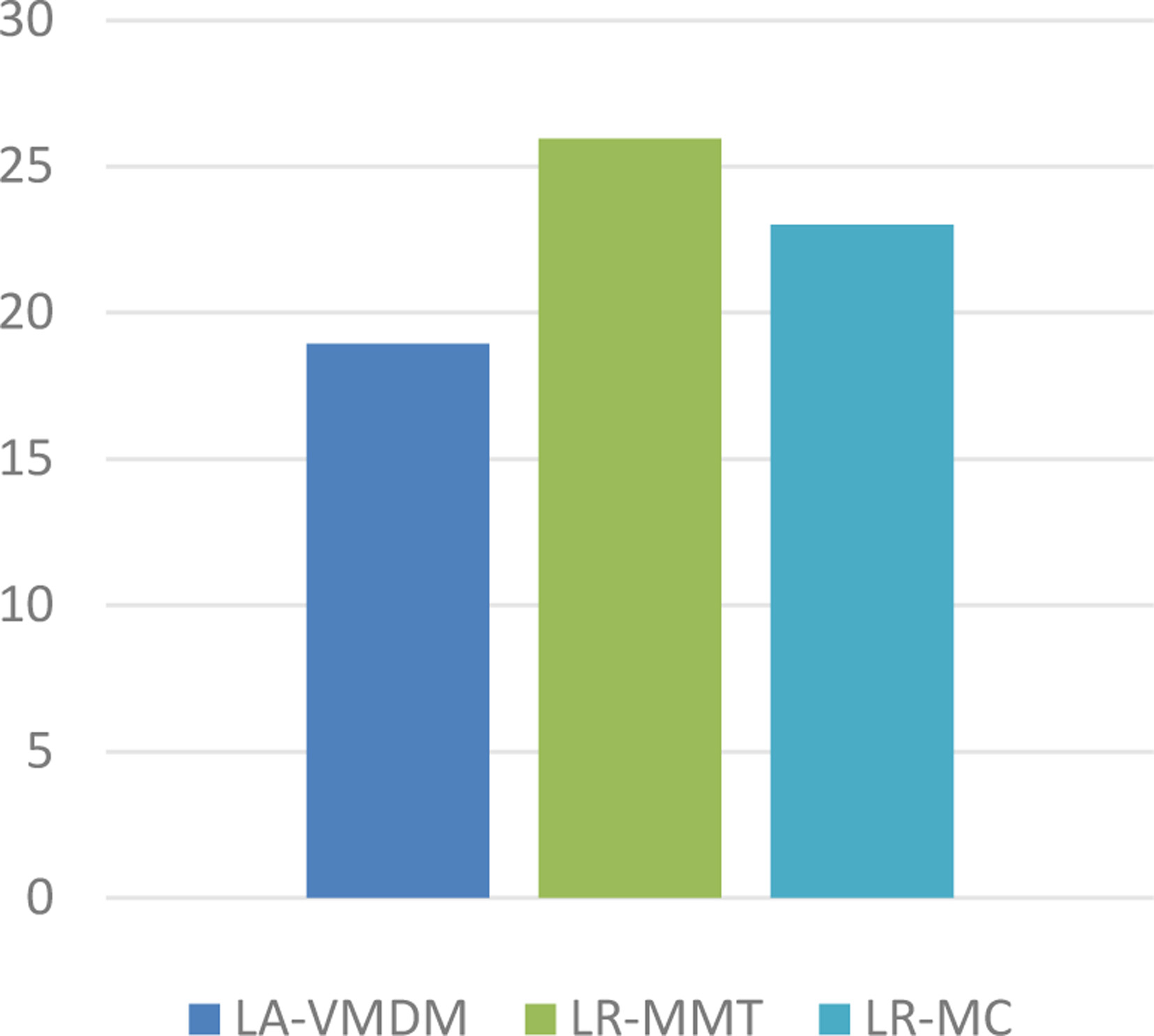
Number of virtual machine migration.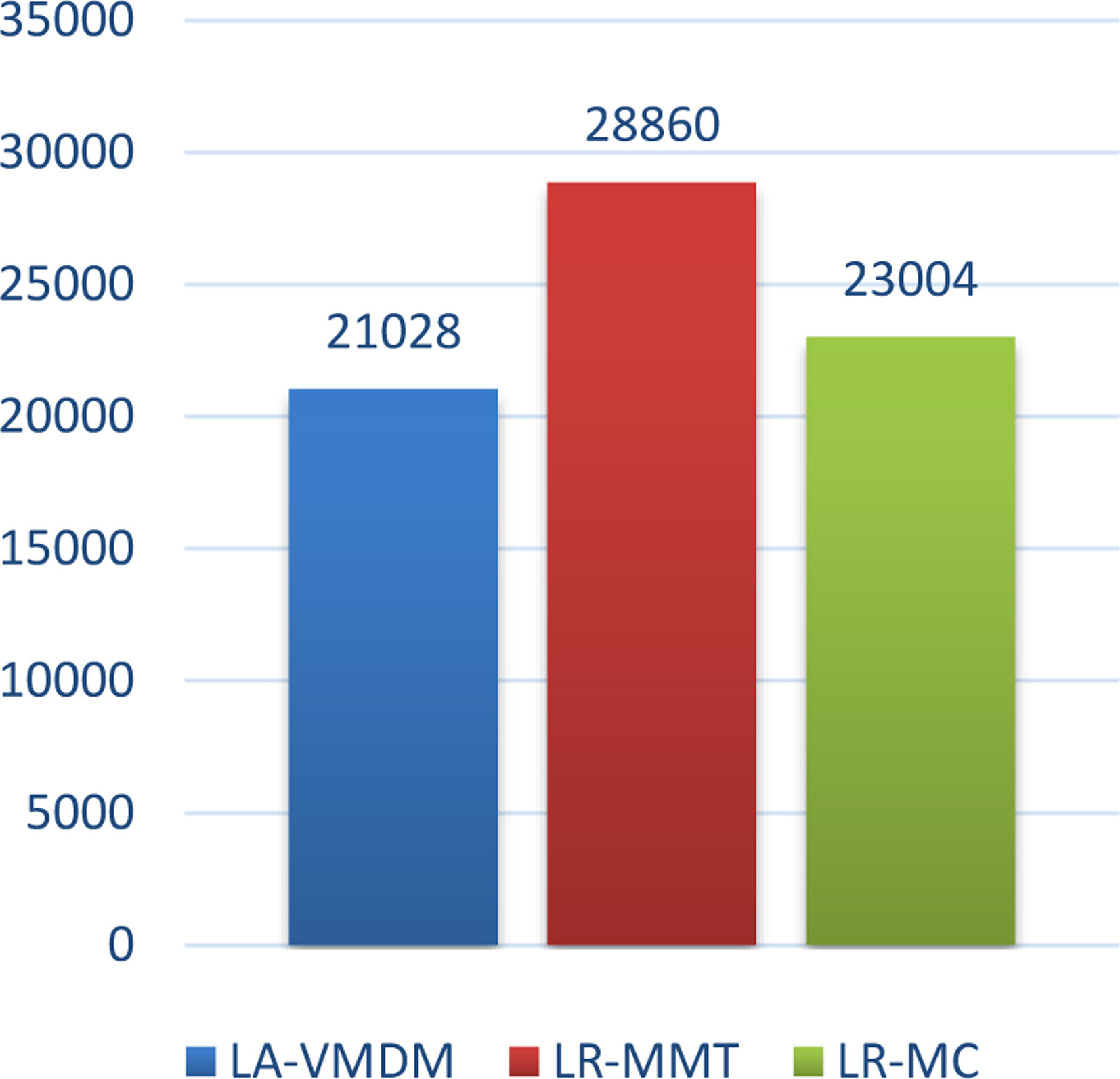
The number of running hosts.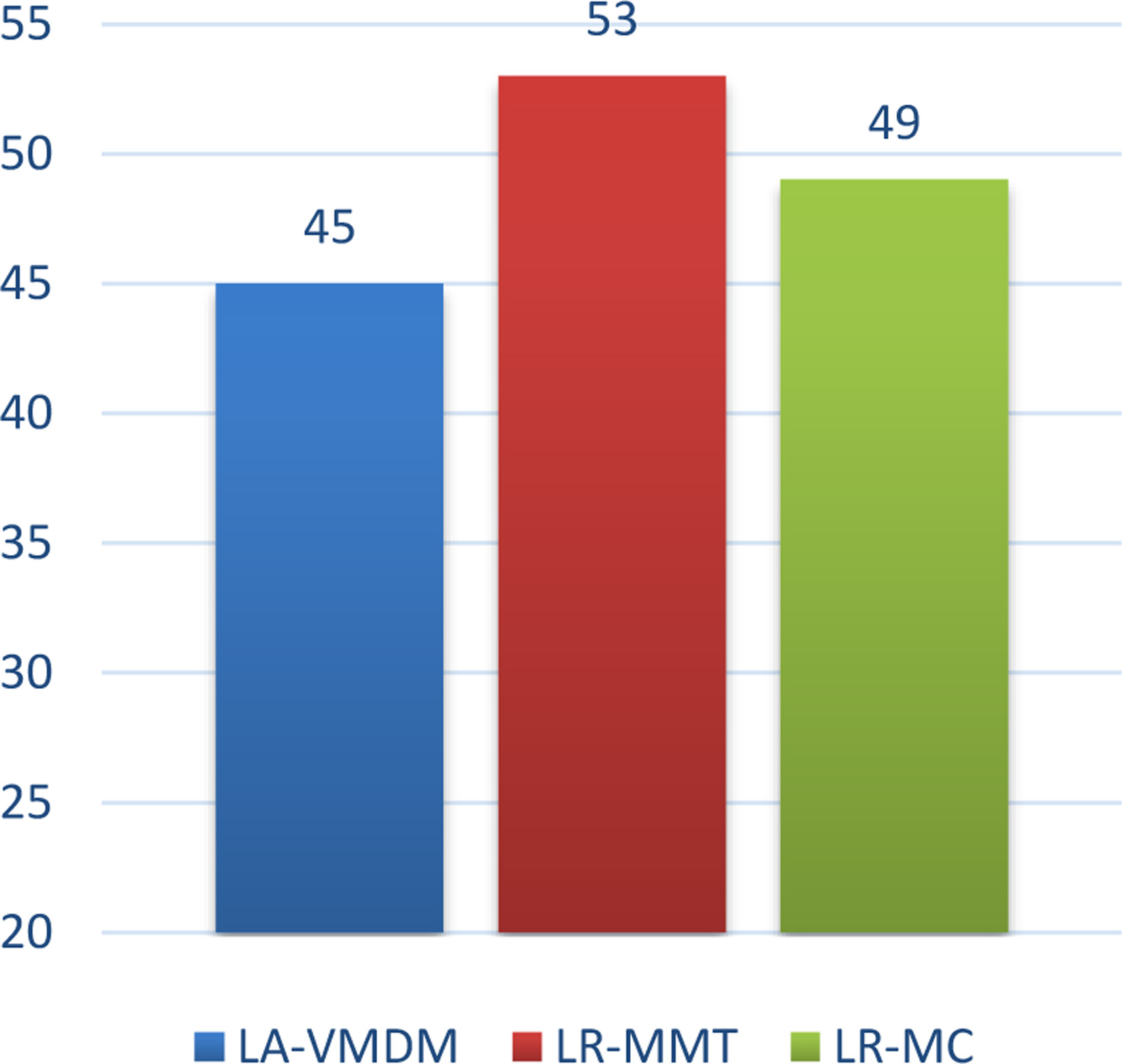
Then, the analysisfrom the perspective of stability and sustainability of the data center, it is inevitably thatthe virtual machine migration bring the data center jitter, the number of running hosts also affects the cloud provider’s operating costs. As can be seen from Figs 9 and 10, the LA-VMDM algorithm is superior to the LR-MMT algorithm and the LR-MC algorithm in terms of the number of virtual machine migrations and the number of running hosts. In terms of the number of virtual machine migrations, LA-VMDM algorithm compared with LR-MMT algorithm, whichhas a decrease of 27.14%, and that compared with the LR-MC algorithm, which has a decrease of 8.59%, because the algorithm in this paper that has minimize the number of virtual machine migration. In terms of the number of running hosts, LA-VMDM algorithm compared with LR-MMT algorithm, which has a decrease of 15.09%, and which compared with LR-MC algorithm, it has a decreased of 8.16%. Therefore, LA-VMDM algorithm can effectively ensure the stability and sustainability of data center.
At the same time, we collect the CPU utilization of 45 physical machines that the cloud task runs at the last moment in the data center implementation. As shown in Fig. 11 below, the CPU utilization rate of 45 physical machines is stable between 30% and 80%. The threshold in this paper is basically stable at the average value. From Figs 11–13, we can see that the average CPU utilization of the 45 physical machines reaches 68.17% when using the LA-VMDM algorithm. Compared with LR-MMT algorithm, it increased by 16.93%, which compared with LR-MC algorithm, it increased by 12.99%. In terms of CPU resource imbalance, it compared with the LR-MMT algorithm, the LA-VMDM algorithm decreased by 13.14%, and compared with the LR-MC algorithm it decreased by 6.28%. This shows that the LA-VMDM algorithm effectively improves the imbalance of the CPU utilization rate.
CPU utilization.
Average CPU utilization.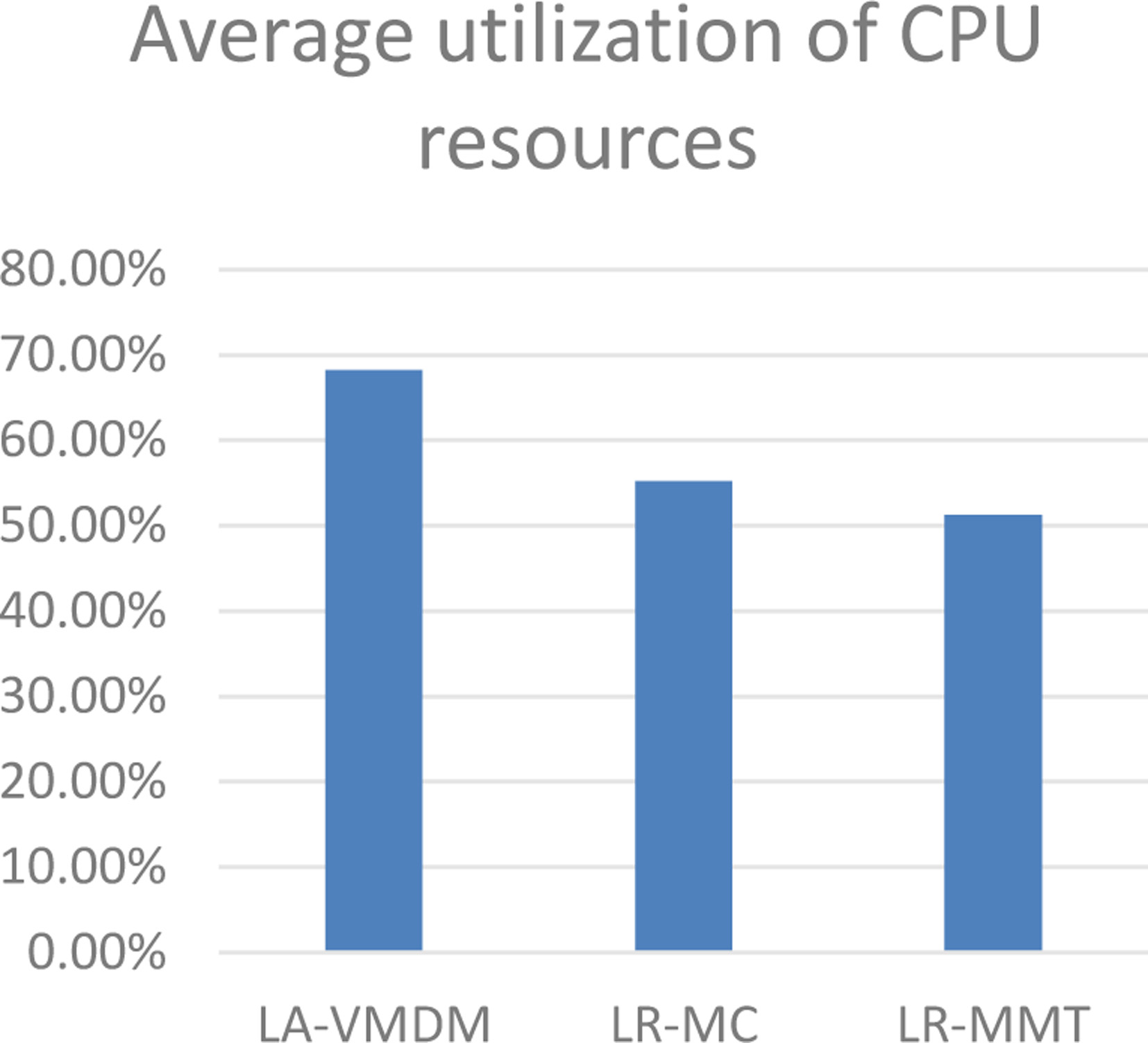
CPU Utilization ratio imbalances.
Among them, the experiment results of the three algorithms in energy consumption EC are shown in Fig. 13. LA-VMDM is obviously superior to LR-MMT and LR-MC in terms of energy consumption, the reduction ratio is 13.65% and 4.35%.
Energy consumption (EC).
From the comparison of the above seven performance evaluation indexes, the LA-VMDM algorithm is superior to the other two algorithms in terms of service center quality, stability and energy consumption. The LA-VMDM algorithm can improve the energy efficiency while ensuring the stability and sustainable service of the data center.
Conclusion
In the epoch of big data, cloud computing is the foundation support technology. Foreign IT giants like Google, Amazon and Alibaba that in domestic, which are actively engaged in cloud computing and achieved good results. OpenStack has become the most popular and promising cloud platform. It builds the public cloud and private cloud of many service providers and enterprise companies. However, OpenStack is not perfect at present, and there are many deficiencies in the resource scheduling mechanism, which result resource utilization is not high in the data center and the load is unbalanced and high energy consumption. In this paper, we study the key mechanism of resource scheduling based on OpenStack virtual machine from initial resource scheduling.
First of all, it introduces cloud computing virtualization technology and resource scheduling mechanism as well as the important components of OpenStack platform, such as Nova, Cinder, Neutron and so on. At the same time, it expounds the resource scheduling module in OpenStack platform. Then we analyze the initial resources scheduling mechanism, that is the initial placement mechanism of virtual machines and the dynamic resource scheduling mechanism in operation, it is the dynamic migration of virtual machines. Finally, we analyze the resources scheduling mechanism in OpenStack platform from the aspects of improving resource utilization of cloud data center, service quality in cloud data centers and reducing energy consumption.
Research contents consist of two parts. First, it is based on the perception of resource performance virtual machine initial placement mechanism:
Analyzing OpenStack platform is a relatively static scheduling mechanism in the initial resource scheduling mechanism, we only considering the remaining memory resources in the calculation of the host weight and considering that the physical machine with the most remaining resources is the most suitable. At the same time, we use a large number of random selection. In order to solve some shortcomings of OpenStack in the initial resource scheduling mechanism, the concept of resource matching retracement expectation between physical machine and virtual machine is proposed. Only the physical machine with the best matching resources and low resource utilization with low resource utilization in the future are the most suitable. we consider the four resources of CPU, memory, storage and bandwidth and proposed the virtual machine placement algorithm RPP-VMP based on resource performance awareness. Finally, the performance of the simulation experiment evaluation algorithm is designed by using CloudSim cloud simulation platform.
Then, it is based on the load-aware virtual machine dynamic migration mechanism:
Analyzing the dynamic migration mechanism of virtual machines in OpenStack. Because there is no automatic trigger migration in OpenStack, it still relies on manual instructions for virtual machine migration, which lacks precise virtual machine selection and target physical machine positioning mechanism. In order to enable the OpenStack platform to automatically trigger virtual machine migration, the threshold interval is set to [0.3, 0.8], and SLWR (Strong Local Weighted Regression) is used to predict resource utilization at the next moment, it is prevent to unnecessary migration of resource utilization jitters matches the probabilistic roulette mechanism PR-DPS of retracement expectations. A predictive virtual machine trigger migration mechanism SLWR-TMM is proposed. At the same time, the virtual machine selection mechanism MMC-SM based on the minimum migration cost is designed. Then, in order to avoid the clustering effect in the circuit of finding the target physical machine, the resource correlation matches the probabilistic roulette mechanism PR-DPS of the retracement expectation is designed. Based on the above improved ideas and mechanisms, a load-aware virtual machine migration algorithm LA-VMDM is proposed. The algorithm is used to realize the dynamic migration of virtual machines in OpenStack operation. Finally, the performance of simulation experiment evaluation algorithm is designed based on CloudSim platform.
In this paper, two kinds of resource scheduling mechanism in the initialization and running of OpenStack are improved respectively, the efficiency and quality of OpenStack resource scheduling are improved to some extent. However, when the virtual machine initial placement algorithm RPP-VMP calculates the virtual machine’s retracement expectation of resources in the future, it is considered that all virtual machines have the same retracement probability, which has some impacts on the performance of the algorithm, we need to come up with an effective way to determine the specific retracement probability value in the follow-up study. In terms of the dynamic migration of virtual machines, only the CPU resources are considered in the factors that trigger the migration, so the above problems can be further studied in future research work. Finally, these algorithms are still in the simulation stage, and there is no application verification in a certain scale OpenStack cloud environment. For this reason, in the future, we will verify and optimize the algorithm in the real OpenStack cloud data center environment.
Footnotes
Acknowledgments
The work has been supported by the National Natural Science Foundation of China (No. 61672004), the CERNET Innovation Project (No. NGII20180409), and the Chongqing Research Program of Basic Research and Frontier Technology under Grant No. cstc2016jcyjA0590.