
Abstract
In this paper, we present a Meta genetic algorithm (GA) optimization approach to tune the parameters of the multi niche crowding (MNC) GA, previously used to successfully describe the potential energy surface of different molecular systems at the semi empirical level of theory. The optimization is performed using a second layer of the same algorithm for a set of molecules of different sizes. Several sets of parameters were found that lead to a high performance of the algorithm in terms of the number of the minima found. The variation of the parameters for each molecule is discussed. A relationship between the changes of parameters as a function of the number of degrees of freedom of the molecule has been established.
Introduction
Evolution algorithms (EA) are a family of algorithms inspired by the evolution theory in order to solve a variety of problems. They have been successfully applied to complex optimisation problems where more classical optimisation algorithms failed to produce reliable results. Among this class of EA, genetic algorithms (GA) were widely used in optimisation problems. In the perspective of chemical studies, GA were applied to various problems including geometries of transition metal clusters [1], geometries of molecular clusters [2], ligand docking [3], and molecular design [4].
In previous papers [5, 6, 7, 8, 9, 10, 11], we have used the Multi Niche Crowding (MNC) GA [12, 13], to satisfactory describe the potential energy surface (PES) of a wide set of molecular systems. In these studies, we have followed the recommendations of the author of the MNC GA in order to choose the best set of the algorithm input parameters. Although the chosen parameter values have led to locate the global minimum for all of the molecules studied, the niche count corresponding to some of the minima was quite low in some cases. While, this situation does not prevent the algorithm to locate the minima, it inspires us to think about optimizing the parameters of the MNC GA that are most suitable for the problem of PES computation.
In general, for any type of GA, the parameter setting can significantly influence the performance of the algorithm in terms of the quality of the results found. With this consideration in mind, various studies have been conducted in order to find optimal GA parameters. Bartz-Beielstein et al. [14] used a technique called Sequential Parameter Optimization (SPO). Their objective is to design the experimental plan prior to actually doing the experiments. Some other studies focused on evaluating the sensitivity of certain parameters, but limited to the study of the independent influence of parameters values on the fitness [15, 16].
Another approach to the parameter optimization is the technique known as Meta-GA, which consists of using a second GA on top of the first one in order to tune its parameters. In this case, the genome of the meta-GA encodes all the parameters of the GA we would like to optimize. This technique was proposed in some previous studies [17, 18, 19]. However, most of these studies were limited to optimizing one or two parameters and holding all the others constant.
In the special case of PES computations, we are only aware of very few studies that were conducted to asset the best set of GA parameters. Brodmeier and Pretsch [20] have examined the influence of population size, scaling function, mutation and crossover rates on a conformer search. Brain and Addicoat [21] have proposed a more general approach for optimizing all GA parameters. However, they only focused on finding global minimum of the molecules they studied.
In this paper, we focus on optimizing the parameters of the MNC GA previously used to successfully describe the PES of various molecular systems at the semi empirical level, using the AM1 [22] and PM3 [23] methods. In order to do so; we have used a second layer of the MNC GA as a meta-GA in order to find the best combinations of parameters that lead to the best results in term of the number of minima found for a set of molecules of different sizes.
Overview of MNC GA
The MNC GA [12, 13] is a GA for multimodal search. That is, it allows locating different minima for a fitness minimization problem such as the PES scan. We have used it previously to study the PES of different molecules. The algorithm was implemented in a package of programs interfaced with MOPAC [24] in order to optimize the heat of formation (HF) of the molecule studied which is the fitness function in this special case.
As described in detail in Ref. [5], in MNC, the crowding concept is used in both the selection and the replacement steps. The algorithm uses what the author calls “Crowding selection” instead of the traditional Fitness Proportionate Reproduction (FPR) technique. For a given individual
Computational procedure
As previously described [5], a real encoding scheme was used to encode the genome of each individual (conformation). In fact, the real encoding gives better results for problems of continuous space [25]. A conformation is described by n dihedral angels (
In summary, the MNC GA is governed by seven different parameters: population size, crowding selection size (
In this study we have used a meta-MNC GA to optimize all these parameters except three of them: the population size,
The genome of the meta-MNC GA is thus composed by the following parameters:
Genome definition of the meta-MNC GA
Genome definition of the meta-MNC GA
The flow of execution of the meta-MNC GA.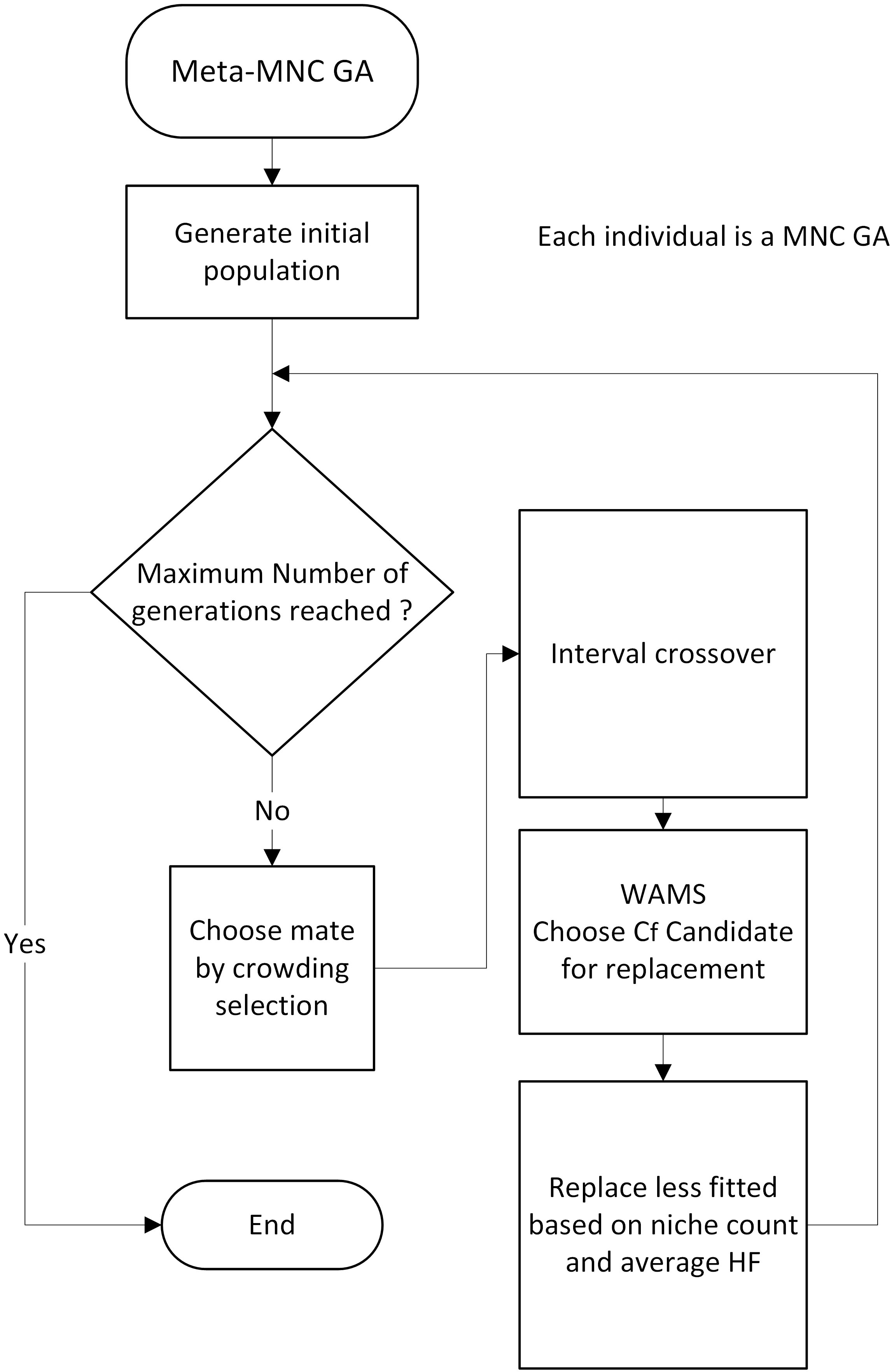
Five different molecules with different sizes were used to perform the parameter optimization. Namely: glycine (Gly), di-glycine (Gly
The five molecules used in this study to optimize the parameters of the MNC GA.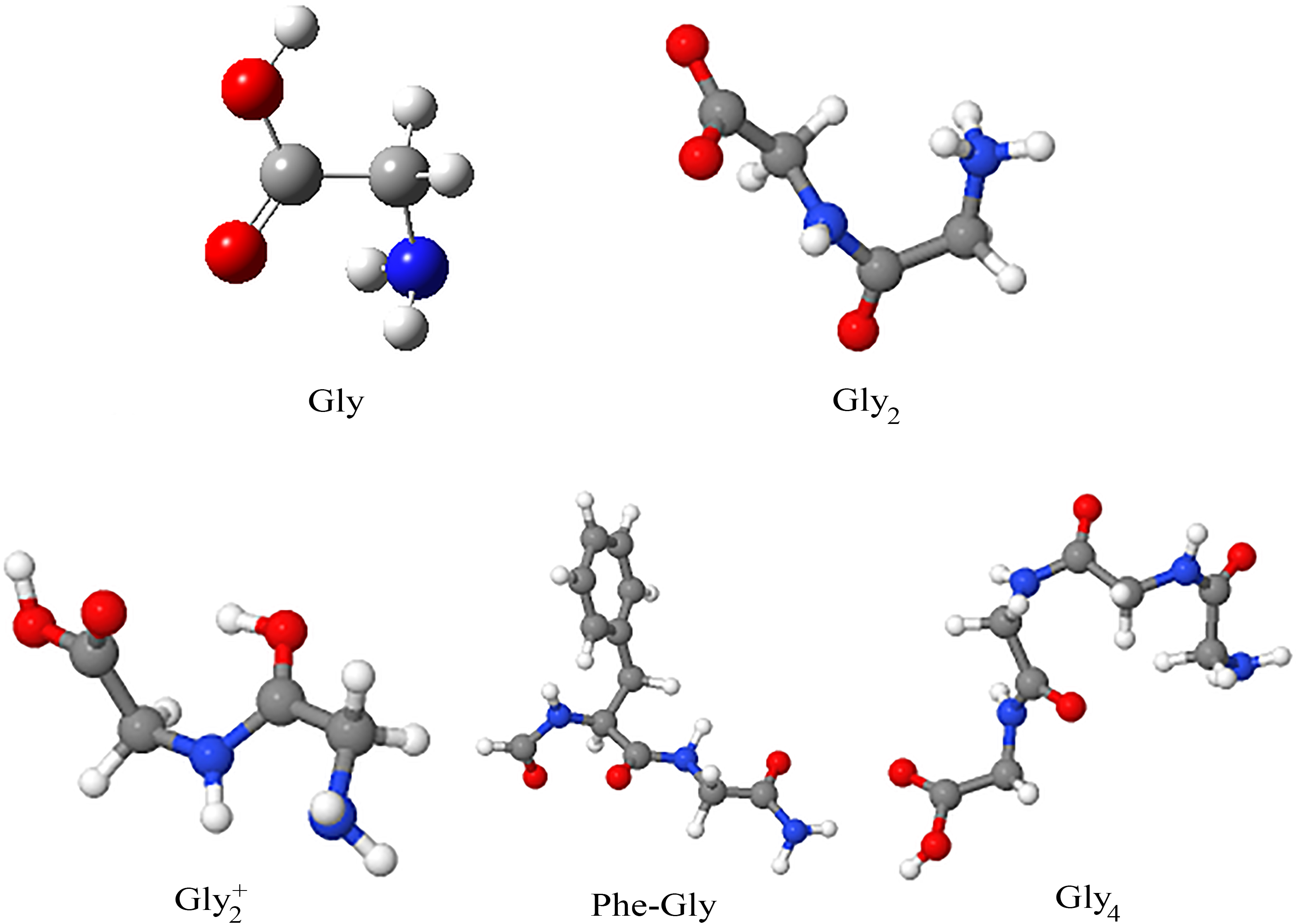
The ultimate goal of this study is, while finding the most optimal combination of parameters for each of these molecular systems, learn some insights on how each parameter is related to the number of degrees of freedom and therefore to the size of the molecule being studied.
K-means clustering is a well known and widely used unsupervised machine learning algorithm [26]. It allows identifying clusters or groups of similar characteristics in a given data set. We have used the version of the algorithm implemented in the scikit-learn Python library [27] to identify the niches in the final population of the meta-MNC GA.
K-means clustering algorithm starts with a set of N elements, in this case the final population of the meta-MNC GA, and group them based on Euclidean distance into K distinct groups or clusters of closest members. Each of the clusters is described by its mean or centoid
Given the high variance of possible values across different parameters, scaling the data to the same order of magnitude is required for an optimal computation of the distances. The standard scaler implemented in the scikit-learn library [27] was used for all the parameters.
The elbow method is used to find out the optimum number of clusters for a given final population. This analysis method allows to find the optimum number of clusters by minimising WCSS. This optimum number is so that adding other clusters does not reduce the WCSS any further. Figure 3 shows an illustration of the elbow method for glycine.
The illustration of the elbow method showing that the optimal number of clusters for glycine is five.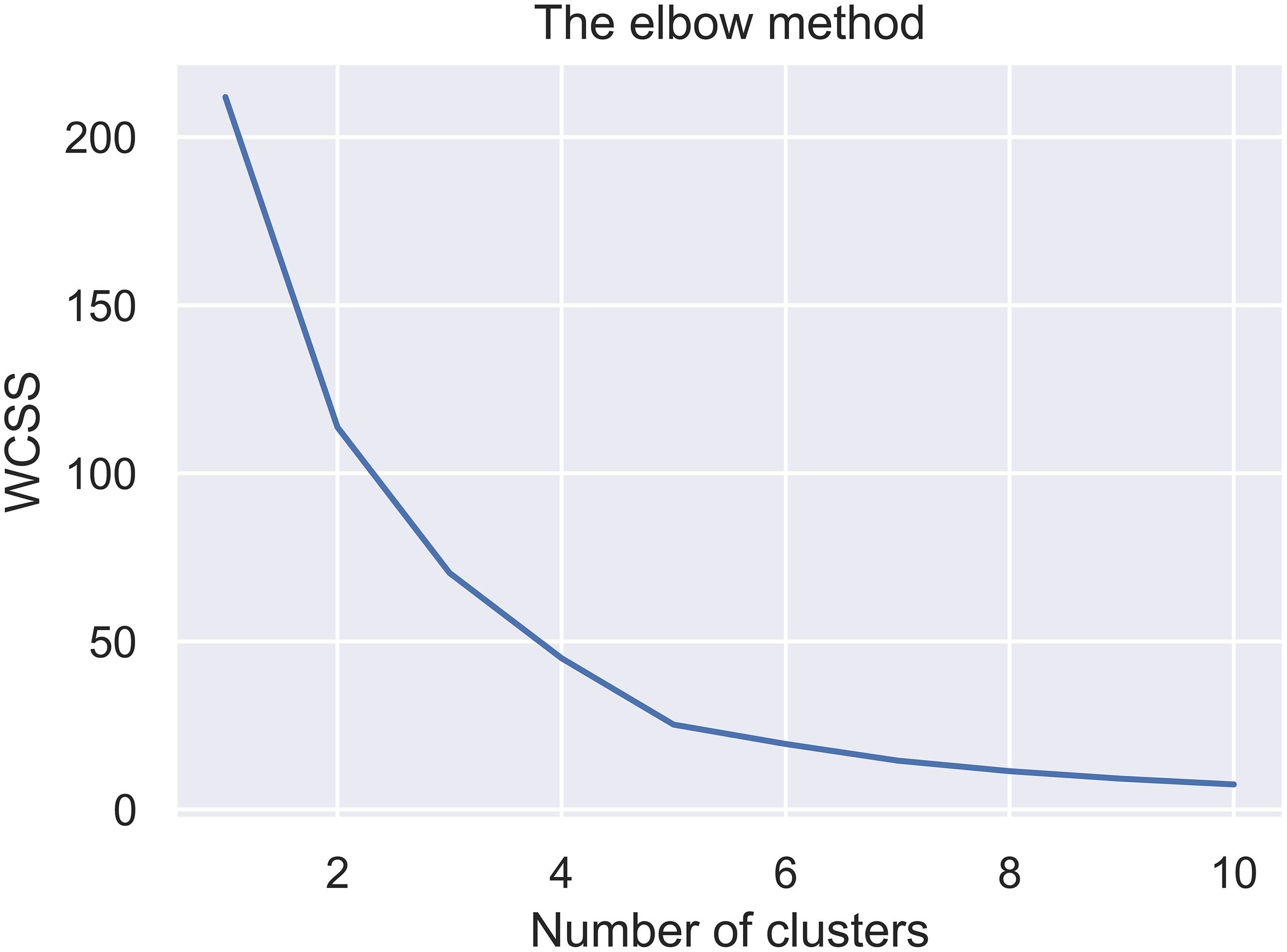
PCA [28] is a statistical technique that simplifies a data set, reducing its dimensions by projecting the original variables to a new coordinate system so that the new variables (the principal components), are linear functions of the original ones. We are using it here to visually project the clusters computed previously to the first two components that represent the most of the variance of the original values. The projections were done using scikit-learn Python library [27].
The Gly clusters colored by niche count from low (blue) to high (yellow), showing two clusters of high performance. PC1 and PC2 are the first principal components representing the most of the variance in the original set of the parameters.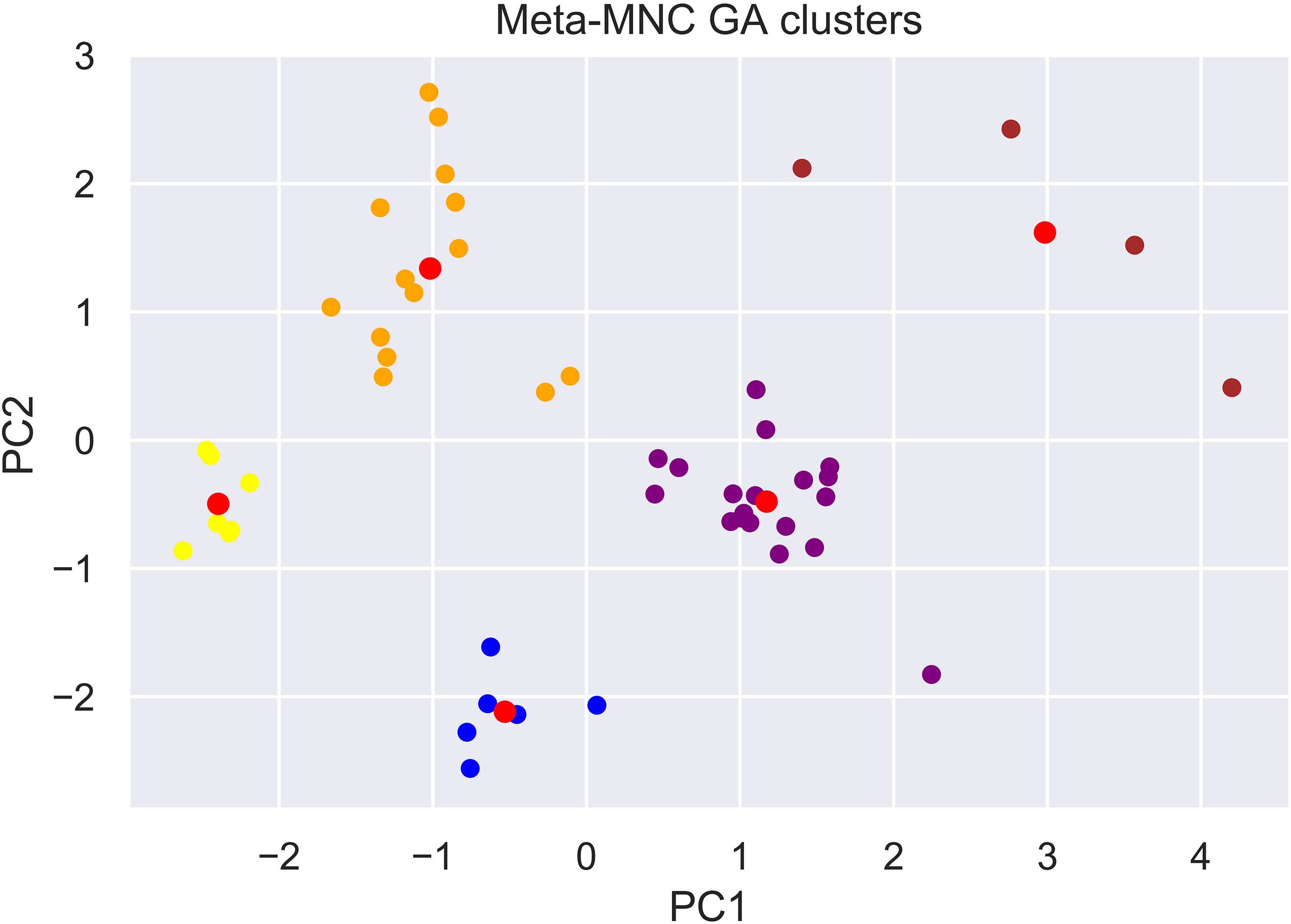
In order to facilitate the interpretation of the results, we have evaluated the performance of the MNC GA by assigning to each combination of parameters (which is basically an individual of the meta-MNC GA) a niche count category, based on the total number of niches obtained. The categories are defined as follows: The combination that lead to a niche count of less than 6, were considered to belong to the low performance category. Those having the niche count between 6 and 9 were regrouped in the medium performance category. Finally those with more than 9 were considered in the high performance category. Figure 4 shows an illustration of the clusters identified for Gly, projected in two dimensions using PCA showing two clusters of high performance. PC1 and PC2 are the first two principal components representing the most of the variance of the set of the parameters.
The high performance parameter sets obtained for each of the molecules studied
The high performance parameter sets obtained for each of the molecules studied
Distribution of the different parameters in the parameter set optimized by the meta-MNC GA highlighted by performance category for each of the molecules studied.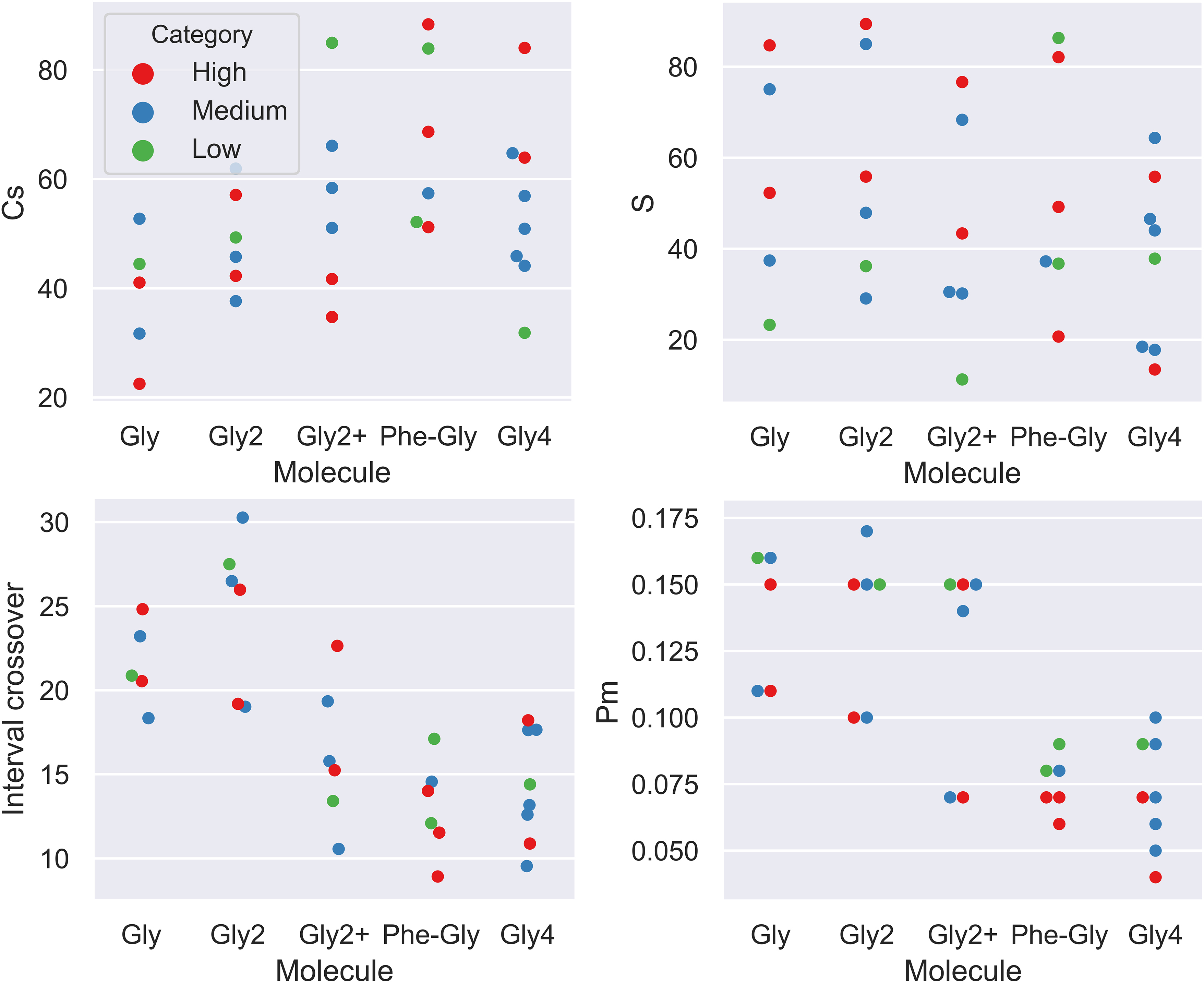
Table 2 regroups the high performance combinations obtained for each of the molecules studied. Figure 5 shows the distribution of the values of the parameters by performance category for the molecules used in this study.
Two sets of parameters leading to high performance fitness have been identified for each of the molecules studied; except for Phe-Gly for which an additional set was obtained. In the second set for Gly, a relatively low value of
However, we cannot say the same for the medium size molecule Gly
The picture is completely different for the bigger molecules Phe-Gly and Gly
Variation trends of the different parameters in the parameter set optimized by the meta-MNC GA as a function of molecule number of degrees of freedom. Blue lines within highlighted areas were obtained using linear regression to show the general variations of each parameter.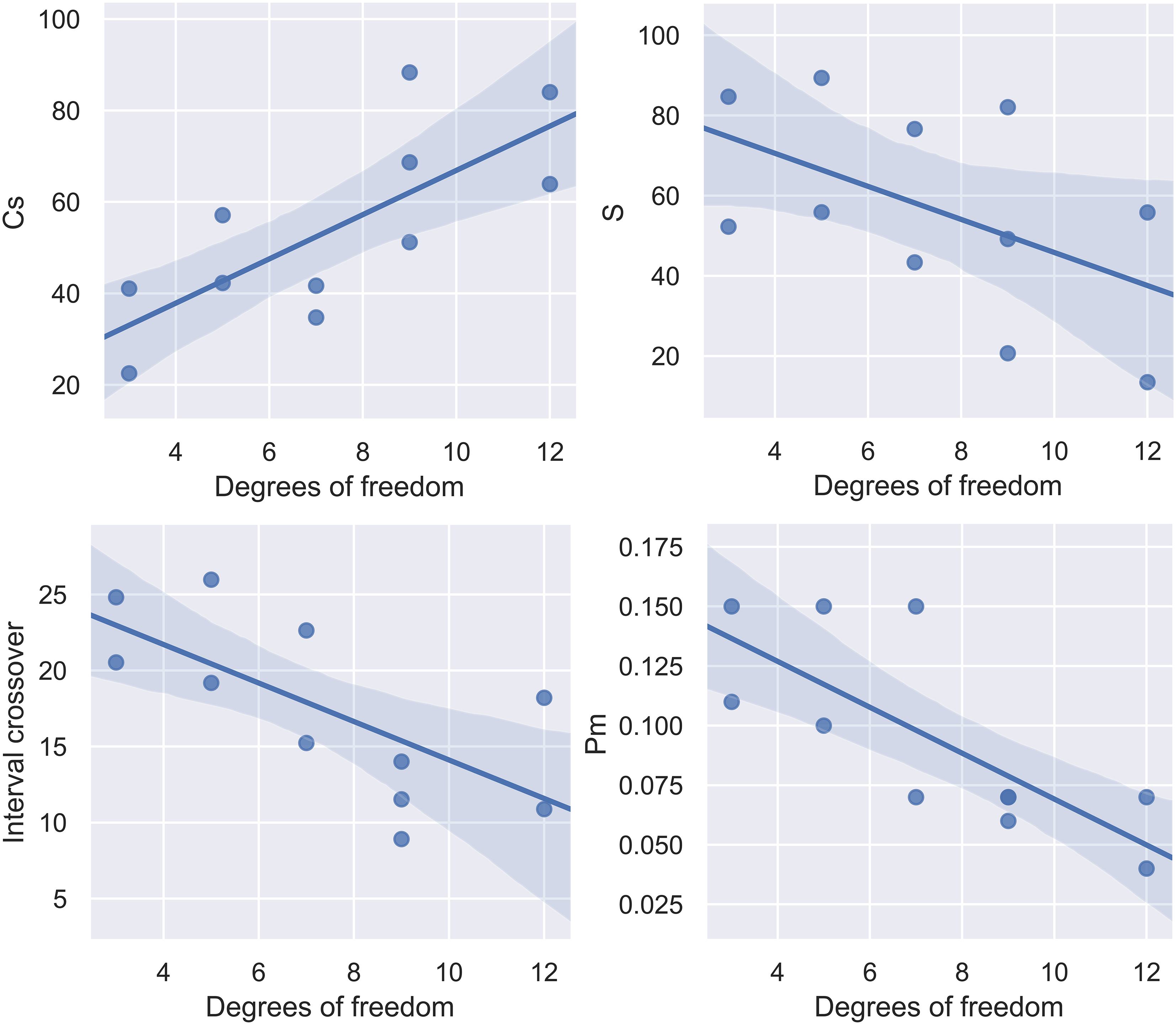
Figure 6 shows a representation of the high performance variation trends of the different parameters as a function of the number of degrees of freedom. Each of these graphs reveals that higher values of
It is worth mentioning that the opposite variation of
In this paper, a meta-GA approach was proposed to optimize the parameters of the MNC GA for PES computations at the semi empirical level of theory using the AM1 method along with a second layer of the same algorithm. The interaction of different parameters has been discussed for a set of molecules of different sizes.
Smaller molecules seem to require a combination of higher values of the parameters
We are aware that parameter tuning is extremely time and computer resources consuming. Extending this study to different kind of molecules may be of a great interest. Taking advantage of statistical learning methods may greatly help to shed more light on the variation of those parameters for more extended molecular systems.