
Abstract
Face modelling is the key to modern visuals in special effects movies and computer games. In this paper, based on the dynamic modelling of 3D face model, a modelling method based on feature extraction is proposed. For the captured face image, firstly locate the face region, then extract the face feature points of the face region, and deform the standard 3D face model according to the extracted face feature points, and finally obtain a real-time three-dimensional image. Face animation system. The experimental results show that the proposed method can accurately complete the face modelling of the corresponding expression in real time for 3D face modelling, which has high real-time and accuracy.
Introduction
The human face image carries and conveys human emotions, identity and spiritual state, and expresses rich and colourful social and cultural significance. In addition to its own natural physiological characteristics, the human face also contains and carries a wealth of social information, which is inseparable from the participation and expression of human face in social, cultural and artistic fields. Especially in the interaction between people, the face plays a unique and important information transmission function. With the voice and gestures, the face can express the emotions, contents and hints necessary in social interaction [1].
Face animation is an important research topic in computer animation, human-computer interaction and computer vision. It brings great convenience and fun to people’s communication, culture and entertainment. Whether it is film and television, virtual teaching or web conferencing, or video games, face animation technology has been applied to become an integral part [2]. This paper starts from the recognition of face shape features based on video, and proposes an expression face animation generation technology under the premise of extracting features. The technology is divided into two major processing steps. Firstly, based on the key frame generation technology of expression mapping and image fusion, a complete key frame library containing various deformations and expressions of the face is generated through a small number of pre-recorded key frame images; The fast incremental intermediate frame generation algorithm dynamically selects key frames according to known key frame libraries and input parameters, and inserts intermediate frames between key frames to generate smooth natural and expressive face animation. Experiments show that the method of this paper can generate facial expressions with rich expressions, and it is also convenient to combine with the driving methods such as voice. At the same time, the method can also realize the generation of stylized facial expression animation such as cartoon.
Face shape feature extraction based on condensation algorithm
The condensation algorithm is an important technology based on video object recognition, and it is also an algorithm framework, which can be easily improved. Its main idea is to assume that there is a first-order Markov property between the frames before and after the video, that is, the position, shape and other information of the target in a certain frame are only affected by the previous frame, so that the target information that has been identified in the previous frame is utilized. Predicting the target information of the current frame, and correcting the predicted value according to some properties of the current frame image to obtain a final recognition result.
In an observation-true value model, let
When
It can be seen that the new sample set constructed at this time must conform to the
The probability distribution of the shape feature of the face is expressed by a sample-set, so at time
Sampling is based on the numerical ratio of
This process is called movement and diffusion. The two matrices
The weights are calculated separately for the samples in the new sample set. The weights are measured by the difference between them and the current frame image (observation). The larger the difference, the less the sample is closer to the true shape of the current face, and the lower the weight.
The observation method of the current frame image can be diversified. In the paper, the edge detection method is adopted, and the Euclidean distance between the face shape of the sample and the nearest edge curve is measured, and the weight with the larger distance is lower. Upgrade the parameters of the estimated model and output the average of the samples.
The personalized face model is based on the Candide-3 neutral face model. Firstly, the three-dimensional face is realized by binding the face feature points extracted from the video image with the feature points of the features in the Candide-3 model. The initial displacement of the model feature points is then refined by the RBF interpolation algorithm and finally the texture information is added to obtain the final realistic 3D face model. Each vertex in the Candide-3 neutral model corresponds to three coordinate values
Characteristic point calibration structure.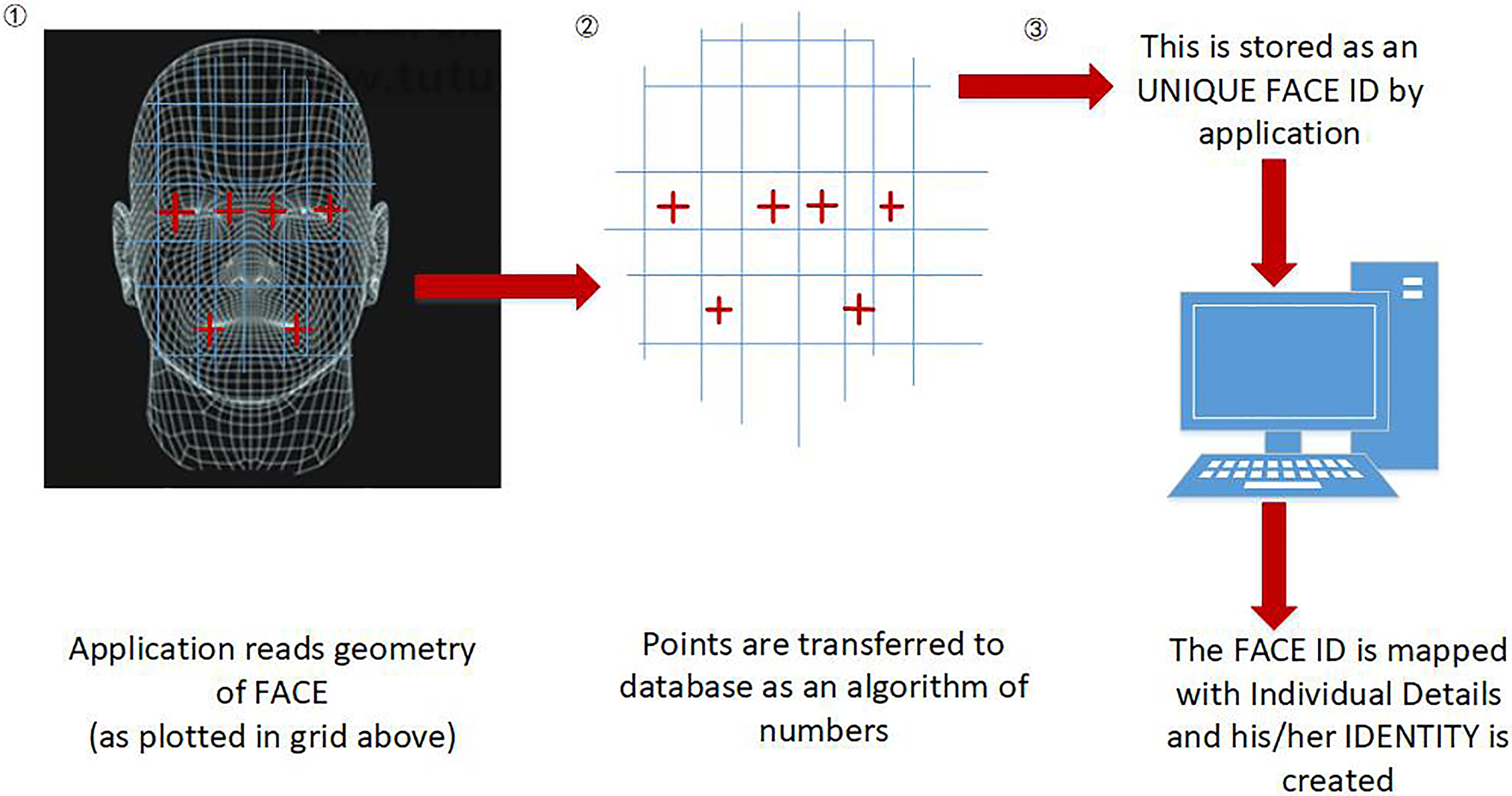
In order to be able to fine-tune the face mesh model, this paper uses the convolution method. Firstly, it is necessary to select a finite feature point and calculate its displacement, then select the appropriate scattered data interpolation method to calculate the displacement of other feature points by solving the appropriate spatial interpolation function, thus completing the elasticity of the entire character avatar mesh model. Deformation. Binding textures can make the model look more realistic.
This article uses the 8-point method. Among them, 8 points include: two points to determine the left eye distance, two points to determine the right eye distance, the nose tip point flash, the left mouth corner point and the right mouth corner point, and the lip centre point. Accurate feature point positioning results can be used to correct the face angle and posture, thereby improving the accuracy of face recognition as shown in Fig. 1. The excellent feature point calibration algorithm not only can obtain the feature point position efficiently and accurately, but also has certain robustness to the face being affected by expression, posture, rotation, occlusion and illumination. This paper chooses to use convolutional neural networks for the study of feature point calibration algorithms.
Local weight sharing strategy
The local weight sharing strategy is to divide the input feature map into A and other regions. The shared weight kernel weight is shared within each region, which is equivalent to extracting a local texture feature. The schematic diagram of the local weight sharing strategy is shown in Fig. 2.
Local weight sharing strategy.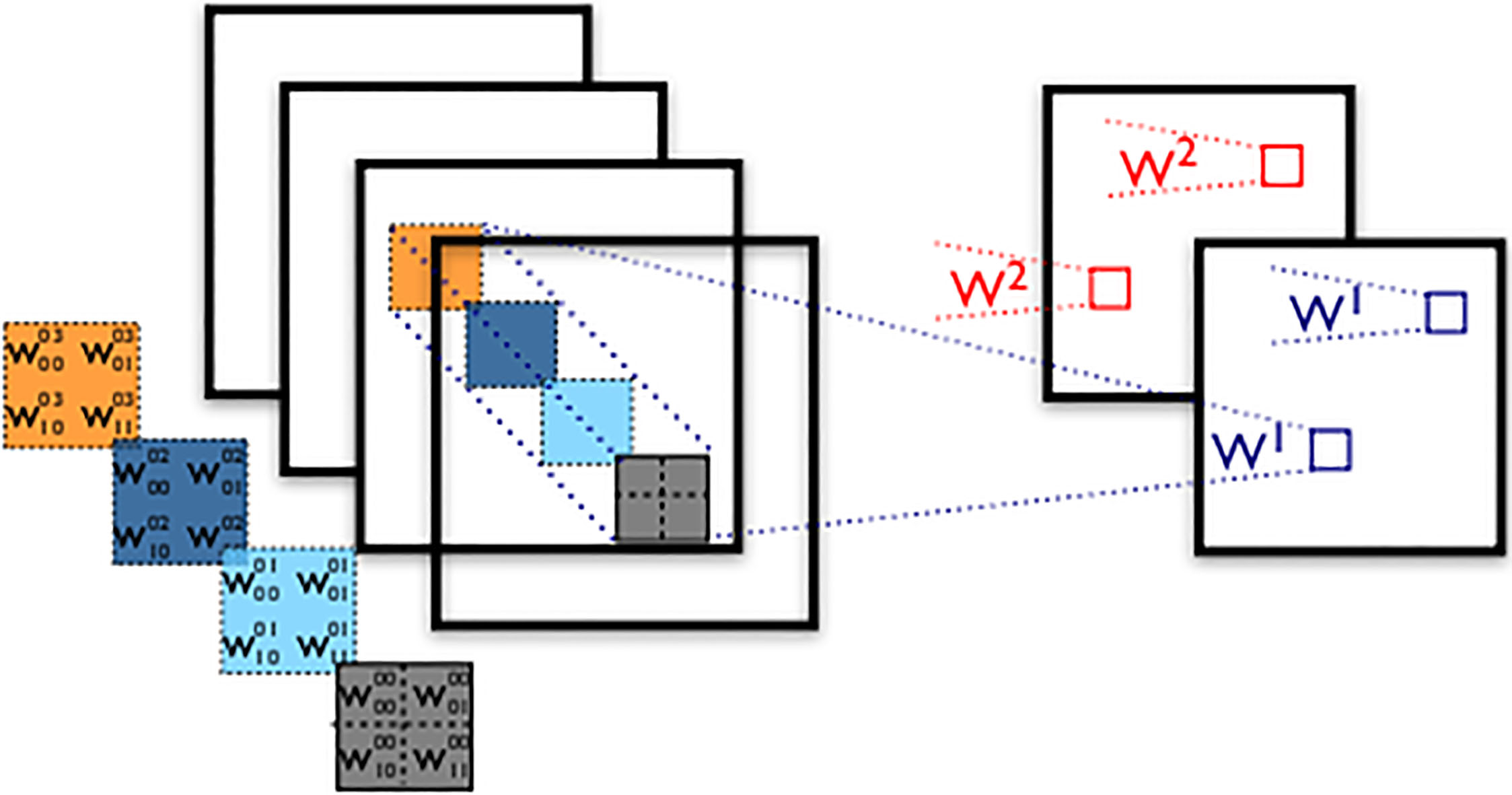
Suppose
Expressions of expressions are expressed through facial deformation and texture changes. An influential expression classification standard divides expression into neutral, sad, happy, amazed, angry, and fearful. In practice, we can divide expressions into neutral, sad, happy, surprised, and angry. Therefore, expression recognition can be seen as a process of classifying face images according to this label. We use a sample-based generation method, that is, an image of a basic face shape in which a good expression is pre-recorded, and an image with a corresponding expression after the face is deformed [5]. The face pose is expressed as
Phoneme-visual position correspondence table
Phoneme-visual position correspondence table
In summary, we combine the three major factors of face deformation, expression, posture and mouth shape into two types: expression and mouth shape. For everyone, the requirement to build a keyframe library is to include a face image of all combinations of expressions and mouth shapes. A single person needs at least 20
In order to get a vivid expression and a face image, we took a method of collecting a small number of samples and then using the key frame image synthesis algorithm to obtain the key frame library. There are two outstanding advantages to doing this:
Firstly, the feature-based image synthesis makes the expressions and mouth features vivid, and the synthesized face image is realistic and credible. Secondly, it is limited by the original data. It can handle the difficulty of the original image, especially for synthesizing avatars or new characters that do not exist in the original image library.
We regard expressions and gestures as two separate features of the human face, and for each character to be processed, an expression-pose matrix is established. Each element in the matrix is the key frame image and its auxiliary data combined with the corresponding expression and gesture. Our task is to synthesize unknown elements through a small number of known elements in this matrix.
Voice and video data
The speech training and test corpus are all from the Chinese Academy of Sciences’ speech database. Currently, a female Mandarin speech data is used. The speech data is divided into five categories: natural, angry, happy, sad and surprised. Each category includes the same sentence. These corpora are used as training and test data for phoneme and emotion recognition. In the end, each sentence is divided into phonemes, and each phoneme and the emotional tag of the phoneme are identified. We recorded the video data ourselves and invited a female model as the recording object. Recordings include reading a lone phoneme, various expressions without utterance, a combination of gestures and expressions, and a video of a sentence [6].
Automatic selection of keyframes based on phonemes and emotional tags
We use phonemes and emotion tags as input parameters to guide the combination of face animations. The format of each phoneme data is triplet
Inserting frames and generating animations
As shown in Fig. 3, after getting the key frame data, we can insert the intermediate frame to generate a cartoon animation. The number of intermediate frames to be inserted and the corresponding parameters are determined by the time stamp of the key frame and the frame rate of the video. We still use
Cartoon style keyframe generation.
In the research fields of face recognition and reconstruction, face animation generation, computer vision, human-computer interaction and computer animation researchers publish a large number of excellent papers each year to study and discuss these issues. The paper proposes a method for generating face animation key frames based on feature point data. The algorithm vividly implements expression mapping and image fusion based on a small number of known face key frame images and feature point data, and generates the remaining key frame images to obtain a complete key frame matrix. The illumination changes are automatically compensated during the generation process and local consistency corrections are made. At the same time, the paper proposes that the expression face animation generation algorithm is applied to the speech-driven face animation generation, and the satisfactory results are obtained. At the same time, the algorithm can realize the key frame image synthesis of the cartoon face based on the sample, which is not limited by style, and then generate the cartoon face animation. With the active exploration of truth and the relentless pursuit of a better life, we believe that in the near future, we can see more intelligent and lifelike face animation.