
Abstract
An order to improve the execution efficiency of Rijndael algorithm, starting from the analysis of the transformation of the core part of the Rijndael algorithm, a method based on data stream decomposition was proposed in the multi-core platform for parallel optimization of Rijndael algorithm. The main method adopted is to divide the effect of each component transformation of the wheel transform on the whole state into the effect of each component unit of the state, so that the component transformation can be carried out in parallel. The experimental results show that the average acceleration ratio of the decomposition of Rijndael algorithm based on data stream is 1.0674, and the performance is 6.74% higher than before . Therefore, the scheme of parallel optimization of Rijndael algorithm based on data flow decomposition is feasible, and the performance improvement brought by parallel optimization of Rijndael algorithm basically meets the expected requirements of the experiment.
Introduction
An encryption algorithm developed by IBM in 1977, published by the National Bureau of Standards (NIST) and approved as a data encryption standard (DES) used by non-essential departments [1]. However, the traditional data encryption standard DES can not meet the existing security requirements. The use of multi-core multi-thread technology to parallel optimization of encryption algorithms has important theoretical and practical value for improving network communication speed and strengthening computer network security. By analyzing the wheel transform of the Rijndael algorithm, the parallel transformation of the Rijndael algorithm is carried out based on data decomposition and data flow decomposition [2]. Data flow decomposition is a method that decomposes problems according to the data flow relationship between tasks. It decomposes problems according to the way data is transferred in tasks. In data flow decomposition, the output of one thread ACTS as input to another thread. Parallel computing is relative to serial computing. To put it simply, parallel computing refers to using multiple components to complete computing tasks together [3]. In data flow decomposition, the output of one thread ACTS as input to another thread [4].
Literature review
In China, researchers have also conducted a lot of research and analysis on the Rijndael algorithm. Alazeez gives a simple algorithm for solving s-box algebra expression by studying the properties of q-polynomial. It has the characteristics of pre-calculation, simple operation and certain versatility, and carries on a kind of s-box proposed by Zeng. The affine equivalence partitioning clarifies the relationship between these s-boxes [5]. Ji and the like used the trace representation of the Boolean function to give the expression of the permutation function, and studied the relationship between the s-boxes generated by the power function synthetic reversible affine transformation [6]. Ban changes and improves the Rijndael algorithm, so that the new algorithm can improve the statistical effect without reducing the anti-differential attack performance, sacrificing a little key filling speed, and can partially resist the Square attack [7]. Choudhary uses Walsh spectral theory to analyze the cryptographic properties of the strict avalanche characteristics, diffusion characteristics and related immunity of the s-box of the Rijndael algorithm, and proposes the concept of generalized autocorrelation function, which solves the problem of determining the strict avalanche criterion and the diffusion criterion order. The division of equivalence classes, the solution of linear equations and the calculation of dual bases of standard bases give three methods for the expression of domain element algebraic expressions, and propose a new attack based on birthday paradox and using activity. The method proposed that the Square-6 attack was unsuccessful and gave a modified attack plan [8].
Research methods
The structure of the Rijndael algorithm
AES has a packet length of 128 bits and three key lengths: 128 bits, 192 bits, and 256 bits; The packet length and key length of the Rijndael algorithm are variable and can be independently set to 128 bits, 192 bits, and 256 bits. The Rijndael algorithm is a packet iterative cipher algorithm. All operations of encryption and decryption are performed on an intermediate result called state. The state can be represented by the matrix array diagram shown in Fig. 1, the element of the diagram is a byte. The array has 4 rows and the number of columns is
The encryption process of the Rijndael algorithm is as follows: firstly, the initial key addition AddRoundKey is performed, then the Nr-1 second round transformation Round is performed, and finally the round transformation FinalRound is performed, and the round transformation of the Rijndael algorithm is used on the state State. The flow chart of 128-bit Rijndael is shown in Fig. 1. As can be seen from Fig. 1, the 128-bit Rijndael algorithm is a 10-round iterative cipher algorithm. The input is a data block and an initial key. The intermediate result of each round transformation after the previous round transformation is a sequence of four transformations: SubBytes, ShiftRows, MixColumns, and AddRoundKey. The last round of transformations is slightly different, with fewer MixColumns than others. The output is an encrypted block of data after 10 rounds of conversion.
Rijndael algorithm flow.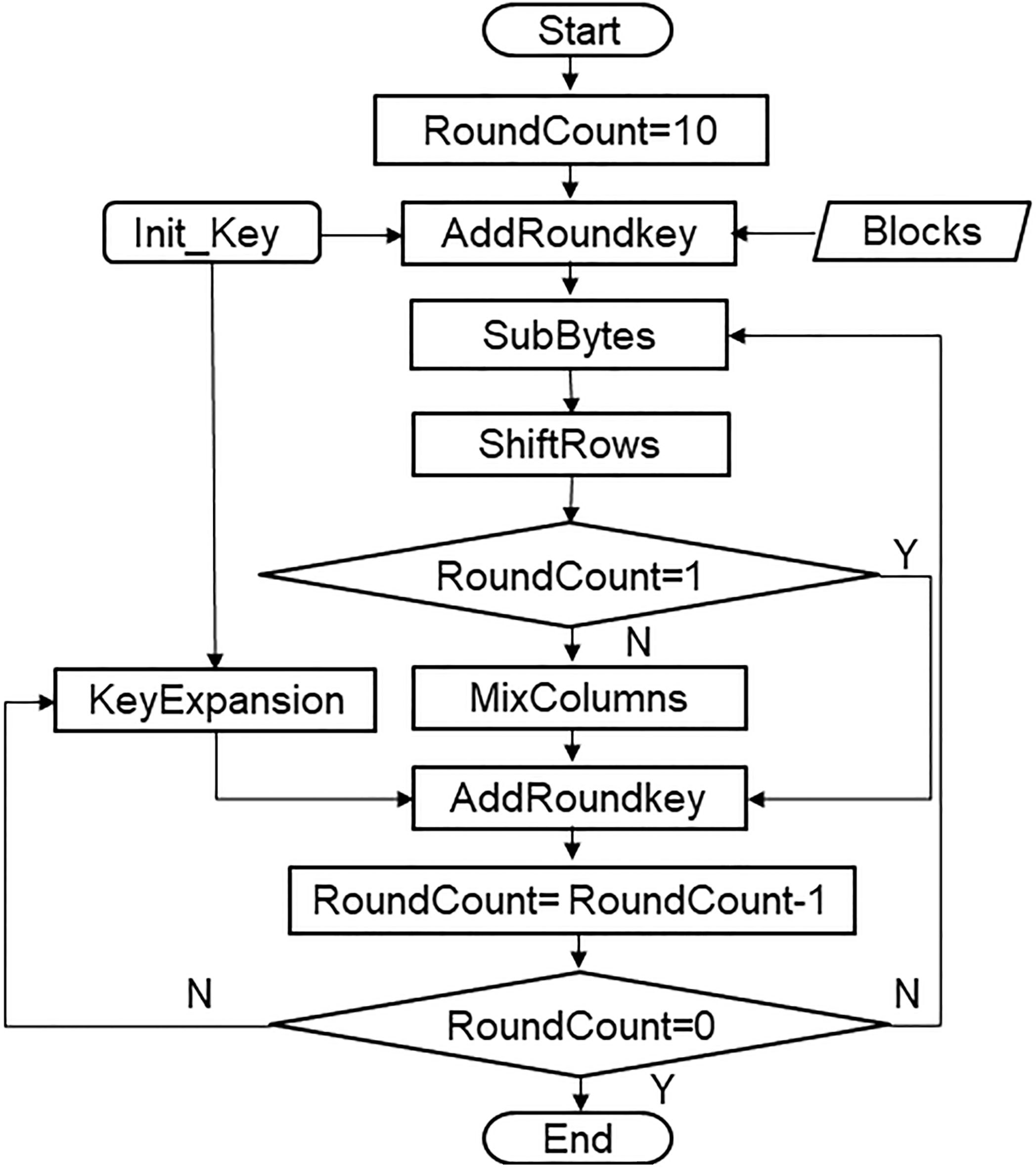
Key arrangement
The key scheduling scheme consists of two components, namely the expansion of the key and the selection of the round key.
3.2.1.1. Key extension
Key extension refers to obtaining the ExpandedKey under the condition that the cryptographic key is known, instead of directly specifying the ExpandedKey. In the key expansion phase, the key is expanded into an extended key array of 4 rows of
Round transformation
Each Round of the Round contains the following four stages of substitution, SubBytes, ShiftRows, MixColumns, and AddRoundKey.
3.2.2.1. SubBytes transformation
The byte transform SubBytes are the only non-linear transform in the Rijndael cipher that operates independently of each state byte. Byte substitution consists of the following two steps: first, find the multiplicative inverse element of each byte in GF (2
3.2.2.2. ShiftRows transformation
The row shift transform, ShiftRows, is a linear combination that results in the proliferation of bits between multiple cycles. According to different packet lengths and key lengths, the row shift transformation will make different rotations. It is assumed that the number of shifted bytes in each row in different states is C0, C1, C2 and C3 respectively, so C1, C2 and C3 are related to the packet length
3.2.2.3. AddRoundKey transformation
The transformation mainly performs an exclusive-OR operation on the data obtained by the above three transformations and the round key of the round, and the obtained data is subjected to the next round of round transformation.
Experimental analysis of parallel optimization algorithm
Since there is a correlation between the four constituent transforms in the round transformation of the Rijndael algorithm, that is, the result of the previous transform must be known before the execution of the latter transform, and each transform cannot be executed at the same time, so the algorithm should not be paralleled by the method based on task decomposition.
The Rijndael algorithm round transform consists of four constituent transforms. Starting from the second transform, each transform needs to know the result of the previous transform after execution, that is, the output of the previous transform is the input of the latter transform. If two transforms are executed in parallel using different threads, then the thread that processes the next transform needs to wait until the previous transform completes the transform work before starting execution.
By analyzing the SubBytes transform and the ShiftRows transform, the ShiftRows transform acts independently on each row of the state matrix, so each time a Subrows transformation of a row of the state matrix is performed, the ShiftRows transformation can be started on the row, instead of waiting for all state bytes to perform a SubBytes transformation, the ShiftRows transformation is performed. The Nth row of the state matrix performs SubBytes transformation to SB(N), and the ShiftRows transformation is performed to SR(N). Based on the above analysis, the transformation process of the first two components of the round transformation can be performed by the decomposition method .
Since the ShiftRows transform operates on the state matrix row by row, the MixColumns transform operates the state matrix column by column, so the MixColumns transform must be executed after all the state bytes of the state matrix perform the ShiftRows transform. Therefore, the data stream-based decomposition method cannot be used for parallel optimization between the MixColumns transform and the ShiftRows transform. Then the MixColumns transform AddRoundKey transform is analyzed and found that these two transforms can also be optimized in parallel by means of data stream decomposition. After each column of the state matrix performs the MixColumns transformation, the AddRoundKey transformation can be performed on the column without having to wait for all the bytes of the entire state matrix to perform the MixColumns transformation before performing the AddRoundKey transformation.In the Nth column of the state matrix, the MixColumns is transformed into MC(N), and the MixColumns is transformed into ARK(N).
Assuming that a column of bytes of the state matrix performs a MixColumns transformation requires c time units, and performing a AddRoundKey transformation on a column of bytes of the state matrix requires d time units, then all state bytes of the state matrix are executed in serial mode. The two transformations require a total of (4c
Table 1 shows the results of the encryption and decryption test before and after parallelization of the Rijndael algorithm based on the data stream decomposition method. It shows the comparison of the running time of serial and parallel operation when the key length and packet length are both 128 bits. The total number of input plaintext bytes is recorded as N, the serial program running time before data stream decomposition is recorded as T1, the parallel program running time T2 is based on the data stream decomposition, and the time unit is 10-6s. In order to ensure the universality and accuracy of the test, the experiment uses the large data amount of plain text to serially and parallelly test the Rijndael algorithm respectively. The running times T1 and T2 in Table 1 are obtained by averaging ten test results.
Performance comparison data
Performance comparison data
By comparing the serial and parallel time in Table 1, it can be seen that the decomposition of each constituent transformation based on the data stream decomposition method Rijndael algorithm is used to round the Round, after the decomposition, the Rijndael algorithm realizes that the running time of the program is shorter than that of the serial program before the decomposition. The average speedup obtained by the parallel Rijndael algorithm
Through the analysis of each component transformation of the rotation transformation of the Rijndael algorithm, the component transformation is decomposed based on the data flow, and the effect of each component transformation on the whole state is divided into the role of each component unit of the state, so that the component transformation can be carried out in parallel. The optimization scheme is verified by experiments, and the performance improvement is achieved under the condition of ensuring security and keeping the memory space requirement basically unchanged. It has important theoretical significance and practical value for strengthening computer network security and improving network communication efficiency.
As a defense,In order to improve the execution efficiency of Rijndael algorithm, starting from the analysis of the transformation of the core part of the Rijndael algorithm, a method based on data stream decomposition was proposed in the multi-core platform for parallel optimization of Rijndael algorithm. Therefore, the scheme of parallel optimization of Rijndael algorithm based on data flow decomposition is feasible, and the performance improvement brought by parallel optimization of Rijndael algorithm basically meets the expected requirements of the experiment.
Footnotes
Acknowledgments
The study was supported by “Science and Technology Project of China Railway Corporation, China (Grant No. 1341324011)”.