
Abstract
The background segmentation of human motion images is the first step in the process of human motion analysis. It is the low-level processing part of human motion analysis. The processing effect at this stage directly affects the progress of the follow-up work. The segmentation results have a great impact on the final human motion analysis results. An important purpose of our research is to endow the computer with the ability being similar to the human vision. So, the computer can feel the motion object in the view and apprehend the behavior of the human more easily. The paper is studied on the representative theories and algorithms of the background subtraction with human motion monocular image. And this paper analyses the predominance and deficiency of these theories and algorithm. These algorithms include differential images, Running Gaussian average, the Mixture of Gaussians and BP neural network. The basic principle and steps of realization are expounded. Also the data of the evaluation is given. Experiment shows that the proposed algorithm of background subtraction is highly effective and it can cast the reflected light, shadow and inverted image well. The algorithm improves the correct rate of target segmentation and is suitable for human motion image segmentation in this complex ice field environment.
Keywords
Introduction
Background segmentation of human motion images is one of the leading research topics concerned too much in computer vision field in recent years, an important technique with the combination of modern biomechanics and computer vision [1, 2]. The technology gains very wide and important applications, especially extensively applied in the field of intelligent monitoring, man-machine interaction, motion analysis and virtual reality. Although in the last decades, lots of useful work were done about it, till now no general algorithm has been developed for motion image segmentation in various cases [3, 4]. Existing researches on background segmentation of human motion images were presented to specific application problem. A universal algorithm needs exploration [5].
In segmenting interesting target in the scenario, the adopted method is closely associated with relative movement of both camera and target [6, 7]. In the practical application system, the motion state of camera and interesting target in scene includes four combination methods:
Camera static-target static, which is static scene; the processing method is the one for static images, extensively applied in human recognition, iris recognition; Camera static-target motion: this is a very important dynamic scenario; its processing refers to motion target detection, classification, tracking and behavior understanding, applied in pre-warning, security monitor field [8, 9]; Camera moving-target static: mainly used in robot vision navigation, automatic generation of electronic map and 3D scene understanding; Camera motion-target motion: this is the most complicated situation in the moving target detection, such as surveillance system in satellite or airplane. In the paper, we discuss how to implement moving human segmentation in specific environment from the perspective of camera static-target motion condition [10].
We introduce two algorithms: (1) one based on difference image, including inter-frame differential and background subtraction method; (2) one based on background model. Here we discuss mainly online single Gaussian background model. This paper mainly studies online single Gaussian background model and mixed Gaussian model based on probability density model.
The method based on inter-frame difference is the one getting moving target foreground by making the difference between the current image and neighboring frame image. The method based on background subtraction is the one obtaining moving foreground by making difference between current image and pre-stored background image. Usually it chooses empty scene image which does not include moving target as background image and uses the first frame as background image for background differential. The key to background model method is descriptive model of background image, i.e. background model. It is the foundation of background segmentation motion foreground. The background model mainly has two modes: Unimodal and Multimodal. The former has a concentrated color distribution on each background pixel, which can be described by a single distribution probability model. The latter distribution is more scattered. Need to use a multi-distribution probability model to describe together. In many application scenarios, such as ripples on the surface of the water, swaying branches, flying flags, etc. Pixel values all exhibit multimodality. The most commonly used probability density model describing the color distribution of the background point of the scene is the Gaussian distribution (normal distribution). Both the online single Gaussian background model and the mixed Gaussian model described in this paper are such models.
The difference method is a technique utilizing the value between current image frame and reference image to complete segmentation of moving target through subtraction in the way of pixels. The value of image can be expressed by gray value or gradient value of pixels. The result of subtraction reflects different pixels included by current image frame and reference image, such as motion target and noise [11, 12]. Different used reference images, difference method is divided into inter-frame difference method and background subtraction method. The reference image of the forward method refers to the previous one frame of the current one or combination of several foregoing frames; for background subtraction method, the adopted reference image is referential background image of the current scenario. Most existing systems employ background subtraction method because with it, the background reference image of a denoised, non-motion target can be easily acquired in static condition. To improve background subtraction method, it needs to update background reference image with the use of current image frame, making such image adaptive to change scenes. We discuss two kinds of segmentation methods.
Inter-frame difference method
This method utilizes pixel-based temporal difference and thresholding to fetch motion area from images in two or three adjacent frames in a consecutive image sequence. The segmentation method for motion target based on time difference has strong adaptability to dynamic environment; however, it’s unable to extract all relative feature pixels, and that cavitation can easily appear in moving object body. The variation between the kth frame image
In Eq. (1),
We choose one frame of motion video in ice arena place to get segmentation result as Figs 1 and 2 after binarizing the frame with neighboring frame difference method. It can be seen from Figs 1 and 2. In spite of desirable segmentation effect, empty space incurs inside the moving human body.
Source color image.
Result of subtraction on binary image.
Inter-frame difference reflects fewer pixels in target moving state, and object which is cut through inter-frame difference between two consecutive frame images is much bigger than real object. To improve neighboring inter-frame difference effect of successive images, we can segment motion target with the help of three consecutive frame images. At the moment, to judge whether a pixel belongs to move target, the principle to be followed by as:
The background segmentation method of moving image based on inter-frame difference features with less complicated computation and easy implementation. It’s not sensitive to gradual change of light in scenario. The detection is effective and stable, with low false drop rate and omission ratio, as well as strong robustness. However in general, it can’t wholly segment and fetch all relevant feature pixels that cavitation is produced inside moving object. The segmentation result is not accurate especially when target moves fast and there’s too big moving displacement between adjacent frames, resulting in big covered and uncovered background areas of moving changeable region in differential image. Moreover, virtual shadows easily appear; hence accurate extraction of the motion target area is greatly affected.
The background subtraction method is designed to get motion foreground by making difference between current image and pre-stored background image. It’s simple and easily carried out. Generally the method uses images which do not include motion target as background image. However, in most cases in reality, that condition is not met. The selection of background image has huge influence on segmentation effect. Some algorithm regards the first frame image as background image, requiring camera to capture scene graphs without moving target. That technique has fatal shortcoming. When moving target is included in the first frame, the segmented outcome has virtual image. Some improved approaches overcame that weakness. Segmentation result forwarded to background image and that the improved methods are adaptive. But, they’re too weak to deal with situations where background changes heavily or background elements repeat moving [13, 14].
We choose a set of motion video in ice arena condition, with one frame whose image doesn’t include moving body and the first frame which contain moving target as background image differential result. After binarization, the segmentation results of two images are acquired.
Through observations, we find better segmentation effect is realized in the first group by selecting scenario which does not include moving target as background picture; while interference area of moving target in the first frame appears and erroneous segmentation shadow is formed in the other group where the first frame picture which contains moving target is chosen as background image. In this case, it’s seen that the selection of background image have decisive influences on segmentation result. It is shown in Figs 3 and 4.
Source color image.
Result of subtraction on binary image.
The method based on background model is the most popular background segmentation technology so far, which utilizes current image to match with background model and then splits out moving foreground through binarization. With fixed camera as premise, for background image sequence, this method assumes background follows Gaussian distribution and background noise is white noise. It can utilize consecutive N-frame images which initially don’t include foreground to construct initial background model; then updates background model at certain renewal speed to make it compliant to slow illumination change. The background model conforms to natural condition. It can be adaptive to slow background change, with strong fitness. But it can’t deal with sudden illumination change and background disturbance. For an object which has a shadowy image, it can’t segment accurately out foreground object, causing inconvenience to subsequent processing. Most of the existing visual monitoring systems do foreground detection with background model. Up to now, a plenty of researchers have been focusing on the performance of various background models to minimize possibly the effect of scene changes on precise division [15].
As mentioned above, the most difficult point in moving object analysis technology of background model method doesn’t rest with t-point frame image and background; instead, the key is whether a good background model (description of real-time background and relative statistical features) can be maintained as always in the whole process. Background model is created on the whole through two ways: regression and non-regression. Generally speaking, during background extraction computation, non-regression algorithm requires certain buffer memory to maintain sample data of motion calculation during background extraction calculation. Regression algorithm models background of single-frame image based on all input frames, without saving buffer memory of sample data for supporting.
Non-regression background model method utilizes dynamically the observational data starting from one time point to the current point as sample to model background template. During background modeling, what’s usually applied is the recently observational data saved in the buffer. Hence it’s named non-regression background modeling method. Regression algorithm doesn’t need maintain and reserve buffer zone of background estimation frame in the estimation. It updates background model at one time point based on each input frame image in the way of regression.
Online Gaussian background model
Background model has strong capacity of resisting disturbance against moving target because the renewal process, the model is “trained” for each newly acquired pixel value, which, in real application, whether belongs to the background or moving target. What we expect to see is background model is “trained” by using background pixel value. The training of moving target’s pixel value can impair the accuracy of background model, particularly when color uniform moving object is big or moves slowly, such long-time “training” will result in false scene background.
For each pixel point in video image, the variation of its value in sequence image can be regarded as random process where pixel value is generated. The process is described as:
Where,
Single Gaussian distribution model is suitable for single mode background. It uses single Gaussian distribution
Gaussian mean model is an idealized Gaussian probability density function constructed with the last N pixel values. The renewal of single Gaussian distribution background model means that of Gaussian function parameters which describe scene background. We introduce learning rate
Where,
Single Gaussian background model can deal with tiny and slow changing scene. When complex scene background changes greatly or suddenly, or background pixel value is of multimode distribution, e.g. tiny repetitive movement, background pixel value varies quickly, not transiting from one relatively steady single-modal distribution to another. For the moment, single Gaussian background model is too hopeless to depict background accurately.
Still we choose motion video used in previous part. We select image of moving human at the 17th frame, the segmentation result without after treatment by online single Gaussian background model. It is shown in Figs 5and 6.
Source color image.
Result of subtraction on binary image.
The observations can be found online single Gauss background model in complex ice environment, the segmentation effect of the athletes is better, but there is a certain interference area. In the segmentation results can clearly see the reflection of light and athletes on the ice caused by shadow.
Different background targets are likely to appear in the same pixel position. When the scene undergoes permanent parametric changes, all models will reflect the value of the current background target more or less. However, sometimes the change in background target is non-parametric and it appears at a faster rate than the background update. For a complex background with chaos, the single Gaussian model cannot be used to estimate the background. Considering that the distribution of background pixel values is multi-peak, it can be based on the single-modal thought method. Multiple single modal sets are used to describe changes in pixel values in complex scenes. The mixed Gaussian model is studied by Stauffer and Grimson uses multiple single Gaussian functions to describe the multi-modal scene background. In fact, this model can more appropriately define the model to describe the foreground and background values.
A video sequence for a pixel at a particular location a can be viewed as a time series whose historical observations can be defined as:
Where, in Eq. (5),
Comparing each pixel of each frame with the existing Gaussian distribution, if the difference between its observation and the mean is within 2.5 standard deviations, if the confidence of the model matching is more than 90%, the new pixel point is considered to match the Gaussian probability model. If a pixel matches a Gaussian model, the variable of this distribution can be updated with the following Eqs (7) and (8):
Where,
Where, when the current pixel matches the Gaussian probability model,
To determine which of the
In the experiment of this paper, it is considered that the first frame video image is more likely to be the scene background. Even if some areas of the first frame image are moving targets, the motion area only accounts for a small part relative to the whole image. Taking the pixel value of the first frame image to initialize the mean parameter of a Gaussian distribution in the mixed Gaussian model, and the weight of the Gaussian distribution takes a relatively large value, and the mean values of other Gaussian distributions are taken as zero, and the weights are equal. The variance of all Gaussian functions in the mixed Gaussian model takes equal large initial values. Therefore, in the learning process of mixed Gaussian parameters, it is more likely to take the mean of the larger weighted Gaussian function as the scene background. There is a complex scene of the moving target when the parameter is initialized, so that the processing speeds up the generation of the scene background. In the extracted background, only a few pixel regions have a process of generating a real static background from the wrong moving target background learning.
In real-world applications, the speed of background model updates is important. If the background model update speed is slower than the change of the real scene background, a large number of false positives will occur for a long time. If the background model is updated too fast, the moving target or the slower moving target in the field of view will become part of the background of the scene by learning, causing the moving target to miss detection. Since the background model parameter update speed has different requirements in different applications, the ideal background update algorithm should be able to easily adjust the update speed according to the specific application conditions.
BP neural network is a common network in image processing, and it is a very effective network. Figure 7 is a three-layer (input layer, hidden layer and output layer) neural network. In video object segmentation, the input data of standard video detection sequence is YUV format. In the input layer, three components of YUV are selected to form the input eigenvector, and a node is selected in the input layer. In order to get object template based on background subtraction image, the content of image is usually divided into background class and object class, so two nodes are selected in the output layer. Let
Calculated according to Eq. (11), the hidden layer takes 4 nodes. Each node is a neuron, and the excitation function of the input layer node is defined as:
Where,
BP neural network.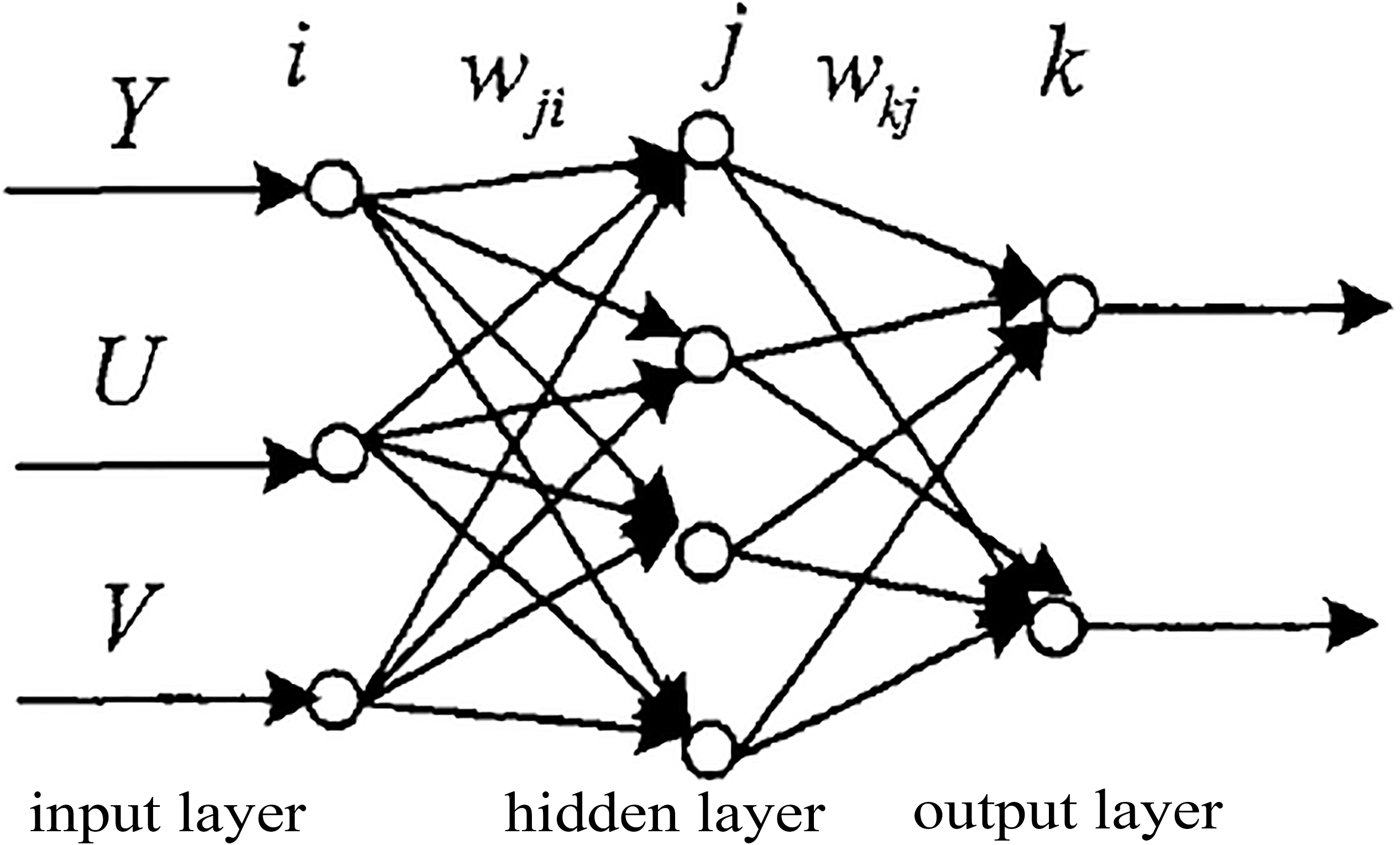
Neural network classifies background subtraction images, which can be divided into two steps. The first step is to input data samples to conduct supervised training on the network. The second step is to classify the background subtraction image by using the network weight obtained by the training.
In general, the differential method has the fastest processing speed and lower memory requirements, but its detection effect is poor. The method of inter-frame difference has strong adaptability to the dynamic environment, but generally cannot completely extract all relevant feature pixel points, and it is easy to generate void phenomenon inside the moving entity. The background subtraction method is not easy to generate voids inside the moving entity. However, the background image is a pre-stored image. This method is not suitable for occasions where the background changes, such as light changes. The online Gaussian background model approach is between the difference method and the mixed Gaussian model in terms of processing speed and memory requirements. At the same time, it has strong adaptability to the dynamic environment. The BP neural network method has less segmentation noise, more accurate contours and better adaptability. It is easy to create voids inside the moving entity. The mixed Gaussian model has the best segmentation effect. However, for simple scenes, the single Gaussian background estimation has little difference with the segmentation effect of mixed Gaussian background estimation. However, the mixed Gaussian model has a slower processing speed and higher memory requirements. Consider the performance of various algorithms in terms of processing speed, memory requirements, and detection effects. A mixed Gaussian background estimation algorithm of
Experimental analysis and results
Experimental video image acquisition
Data samples here are videos of highway speed skating team athletes doing curve training in AVI format got by monocular static camera, at 25 fps; each frame image is level 256 colorful image of 576*720 pixels. Apart from static background information and dynamic target information (skating players) in data samples, there are numerous noises, typically such as athlete shadow, obscure inverted image of players who do not appear in other motion detection scene, as well as other dynamic non-target areas. The background features of those video data samples agree with the described properties of complicated ice arena scene in the above.
Experimental design
The main process of the experiment consists of the following steps:
Read AVI video files. Select the background segmentation method of the human motion image. The experimental results of the segmentation are obtained according to the background segmentation method of the selected human motion image. These methods include the described methods, such as inter-frame difference, background subtraction, online single Gaussian model, mixed Gaussian model. Visually compare the segmentation results of various methods. In order to clearly compare the segmentation effect of the moving image, subjectively, the segmentation result without post-processing is judged by the observation method, that is, the performance of the algorithm is judged by visual observation of the segmentation result. Post-processing the segmentation results. Remove noise and interference areas. Quantitatively evaluate the experimental results of various algorithms. Compare the performance of each algorithm in our complex ice rink environment.
To validate effectiveness of the proposed algorithm, we perform simulations with a few kinds of videos and compare it with Gaussian mean method, hybrid Gaussian model. The experimental environment is Intel core i3 generation, RAM is 8 G, Simulation platform is C++6.0 Visual.
Data samples used here are videos of highway speed skating team athletes doing curve training in AVI format got by monocular static camera, at 25 fps; each frame image is level 256 colorful images of 576*720 pixels. The selection of the parameter values of the algorithm is shown in Table 1.
Choice of the parameter
Choice of the parameter
Source color image.
The experiment data of twelfth frames, Fifteenth frames, seventeenth frames and nineteenth frames in the experiment video are selected. It is shown in Figs 8–11.
Result of subtraction on binary image between adjacent frames.
Result of subtraction on binary image with first image.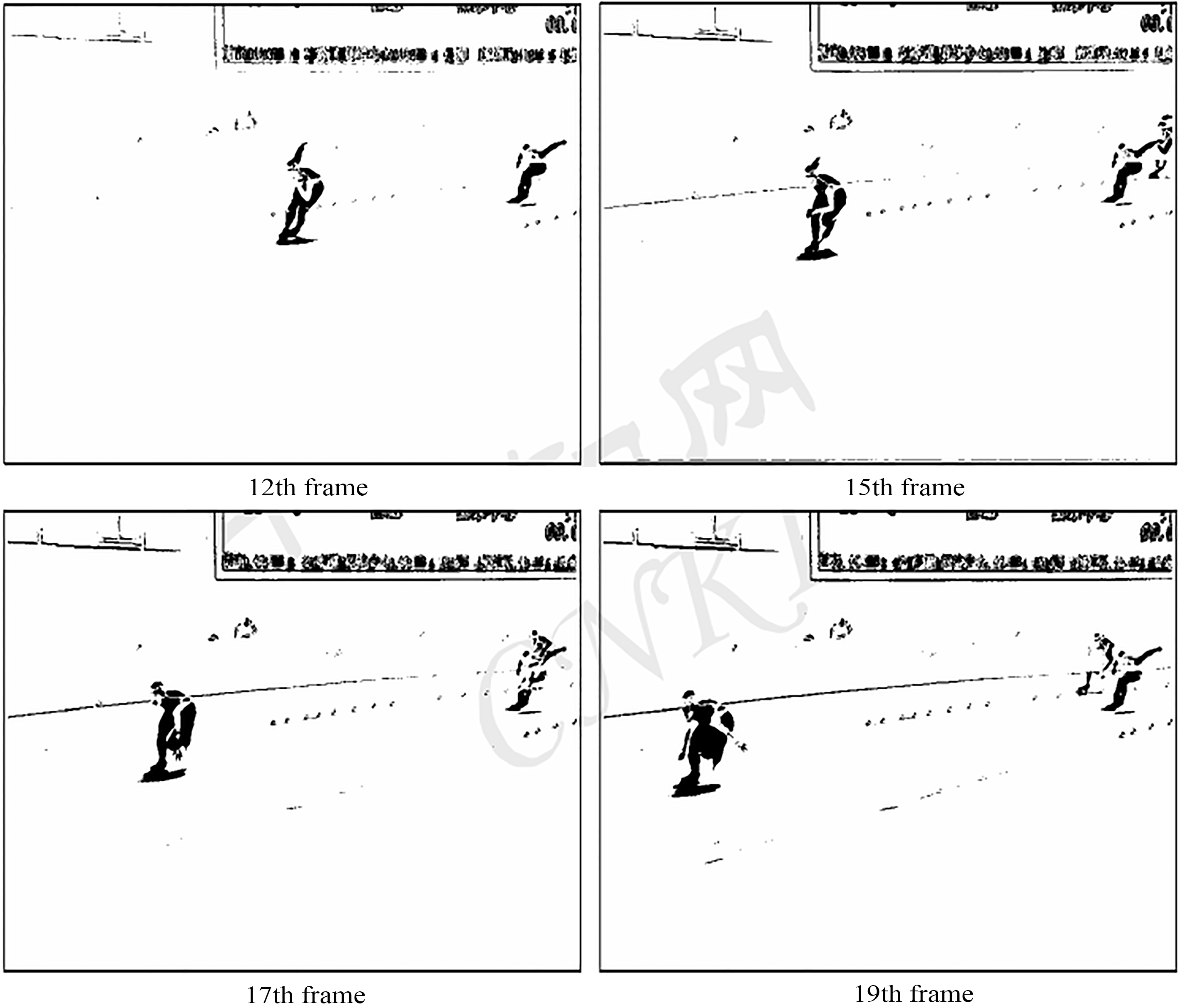
Result of subtraction on binary image with the method of Running Gaussian average.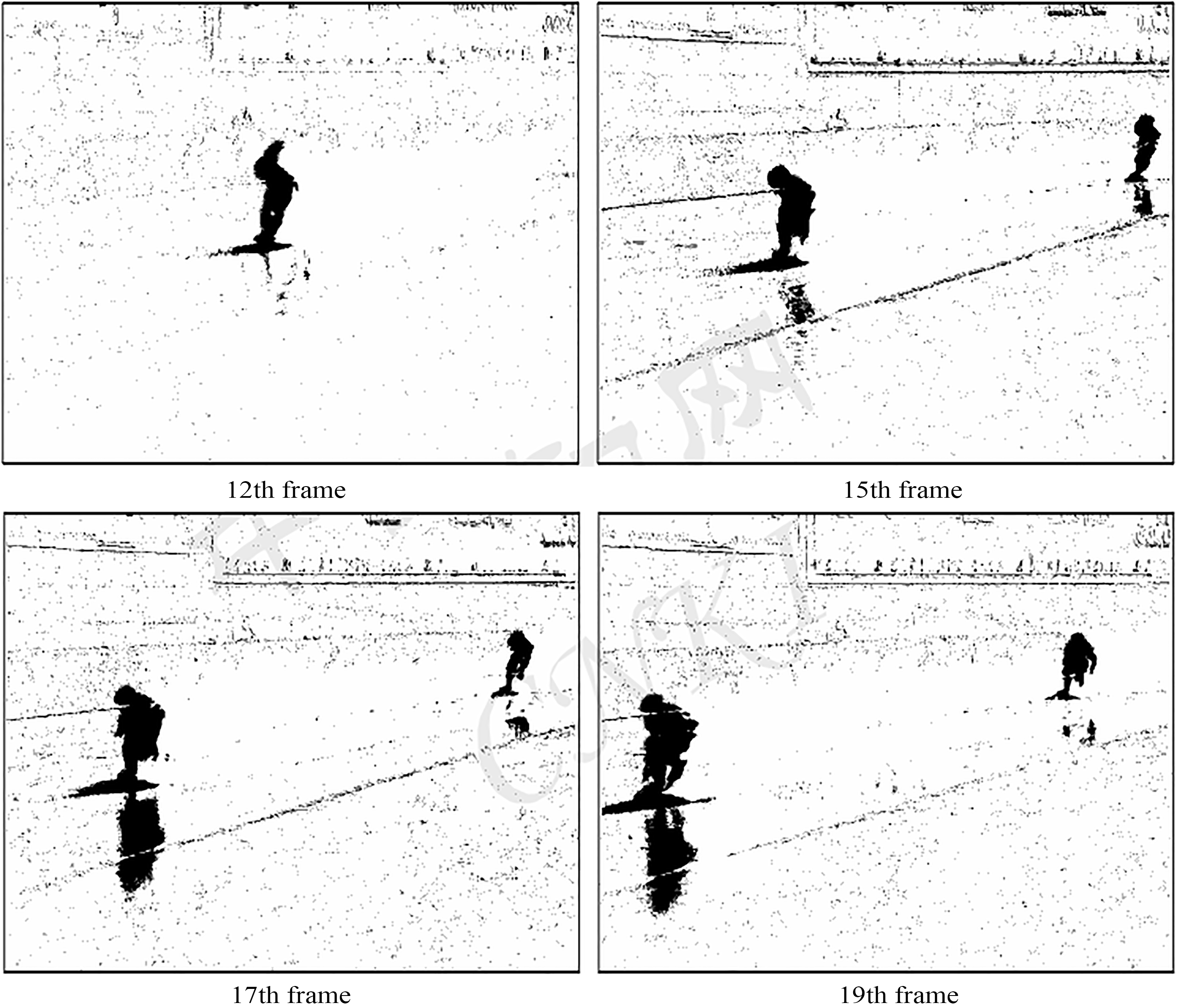
With subjective observation method, i.e. visual observation of segmentation results, we get:
In four pictures of segmentation results by inter-frame difference method in Fig. 9, large cavitation occurs in motion human body; and because moving target skates too fast, double shadow forms, implying that in ice arena place, inter-frame difference method doesn’t fit the scene owing to too fast moving speed of athletes; Figure 10 is effective graph acquired by selecting the first frame as background image to make a difference. Although target human segmentation is well achieved, moving targets existing in the first frame lead to the 1st frame moving target in segmented results, forming interference area. It reveals that with the method, the selection of suitable scene background picture affects a lot of segmenting results. This method has special requirements for the acquisition of video information. Four pictures in Fig. 11 portray background segmentation without after treatment by online single Gaussian model method. We observe that too many interference areas appear in the picture and there are plentiful impulse noises. However it has the advantage: renewing dynamically background model and adaptive to background changes.
In short, as experimental results suggest, the method presented here outperforms other background segmentation algorithms, which not only segments out dynamically foreground information of players and also inhibit effectively shadow, intense illumination and can recognize inverted image on ice surface. Therefore, in complicated ice arena scene, our algorithm stands out by achieving better processing effect.
Quantitative evaluation method for the performance of background segmentation algorithm
After years of efforts, researchers have proposed a number of different scenarios, different forms of movement background segmentation algorithm. So, the performance of these algorithms in practice requires a unified evaluation method to evaluate.
In the field of motion analysis, there is no unified evaluation system and standard for the motion background segmentation algorithm. The evaluation of the performance of the algorithm is carried out by means of subjective observation, that is to say, the performance of the algorithm is judged by the visual observation of the results.
It is obvious that this subjective approach is difficult to accurately evaluate an algorithm. Therefore, it is of great realistic significance to propose a quantitative evaluation method.
With regard to the quantitative evaluation of the motion segmentation algorithm, two quantitative indicators were proposed based on the results of the segmentation results, the actual detection of Recall and Precision, and the two indexes are defined according to the following formula.
Where, Recall and Precision. The value of the two evaluation indexes ranged from 0 to 1. Recall reflects the ability of the algorithm to correctly segment the moving pixels. Precision reflects the accuracy of the algorithm segmentation.
It can be seen from the Eq. (8.4.1). Two metrics used to evaluate the performance of the segmentation algorithm. Recall and Precision have the following relationships:
The value of Recall increases with the increase of the number of foreground pixels detected by the algorithm. The number of foreground pixels detected by the algorithm increase to lead to a reduction in Precision.
Therefore, it is generally believed that a good background segmentation algorithm should be in the case of Precision without sacrificing the Recall as much as possible to achieve a higher value.
If the two quantization indexes are used in the whole image sequence, they reflect the average performance of the algorithm for all the observation frames.
Typical ice environment, the performance of the final test method is tested experimentally on the speed skating curve AVI video. We use the manually labelled segmentation results to approximate the results. And the experimental results are presented in the interference region of the non-algorithm.
Based on the above, the quantitative evaluation method is introduced. Recall and Precision data are shown in Table 2.
Result of the improved Gaussian mixture model
Result of the improved Gaussian mixture model
Result of Gaussian mixture model
Result of Running Gaussian average
Result of BP neural network model method
Result of inter-frame difference method
Result of background subtraction method
From Tables 3–7, Recall value of the four methods based on background model is much higher than that of simple image segmentation. In the four methods, the improved algorithm is about 80%. The algorithm of mixed Gauss model is about 90%. Online single Gauss model is about 95%. BP neural network model is about 85%. Precision is still based on the background model of the four methods are higher than the other there, the values of the online single Gauss model for these four methods are the lowest, which is between 20% and 40%. The value of the mixed Gauss model is followed, which is between 30% and 50%. The value of BP neural network model is between 50% and 70%. The algorithm in this paper is about 90%. The other there methods are always very low.
Analysis of the above data can be found. Two methods of inter-frame difference and background subtraction are very low for Recall and Precision. The reason is that the inter-frame difference method removes most of the foreground pixels, exposing the shortcomings of easily forming voids on moving targets, and the background subtraction method is mainly because the background image selection has a great influence on the segmentation effect. The other two methods are compared with the method of this paper, the online single Gaussian model Recall is up to about 95%. However, its Precision is too low, indicating that there are more points in the front of the moving target segmentation, but in the segmented front spots, there is too much noise and the correct rate is too low. The algorithm Recall in this paper is not much different from other algorithms, but Precision is very high, reaching about 90%, indicating less noise. Therefore, from the above data analysis, the algorithm in this paper has the best effect.
This paper mainly introduces the common background segmentation algorithm of human body moving image, including the difference method and background subtraction, BP neural network model algorithm and Hybrid Gaussian model algorithm, based on the probability density background model method in the online Gauss background model method. Experiment shows that the proposed algorithm of background subtraction is highly effective and it can cast the reflected light, shadow and inverted image well. The Recall value of the mixed Gaussian model is slightly lower than the online single Gaussian model. But Precision has increased dramatically, and noise has been greatly reduced. The experimental results of various segmentation methods were compared with subjective observation, and the experimental data were quantitatively evaluated and statistically performed. The method used in this paper is better than other methods, which improve the correct rate of target segmentation and are suitable for human motion image segmentation in this complex ice field environment.