
Abstract
Traditional discriminant correlation filters fuse hand-crafted features and deep features fusion for tracking, which will cause features redundancy too much and lead to model overfitting when parameters are updated. Moreover, it is difficult to deal with various complex problems in video by using the same label map for different features. In addition, the model updating strategy of the traditional method is relatively single, the model is updated by one frame or several frames. Different from the traditional methods of response map fusion, this paper proposes a multi-layer features correlation filter algorithm to estimate the target model from multiple perspectives. The corresponding label maps are used for different features, and an adaptive model updating strategy is proposed. The proposed tracker achieving leading performance in OTB2013, OTB2015 and VOT2016 datasets.
Introduction
Target tracking is one of the important research directions in the field of computer vision. It is widely used in daily life, such as video surveillance, tracking navigation, unmanned driving, etc. [1, 2]. The appearance of the target is easily disturbed by illumination, deformation, fast motion, occlusion and so on, which increase the difficulty of target tracking. In addition, the lack of training samples and the real-time requirement of the algorithm are also great challenges [3, 4].
Target tracking methods can be roughly divided into two categories, one is online update method, the other is offline learning method. Offline learning methods mainly include full convolutional Siamese Networks (SiamFC) [5] and correlation filter Networks (CFnet) [6]. These methods are trained offline with large-scale image pairs and do not update the model. The testing speed is relatively fast, the accuracy is generally lower than online methods. Online updating methods are mainly discriminant correlation filters (DCF) [7, 8, 9, 10], which trains a regressor by exploiting the properties of circular correlation and performing operations in the Fourier domain.
In recent years, discriminant correlation filter based methods have achieved good results in target tracking competition. Most of these methods use the fusion features of deep features and traditional features [11], or integrate shallow features with high-level semantic features which extracted by neural network [12, 13]. The fusion of deep features and traditional features will make features redundancy too much, and it is easy to cause model overfitting when parameters are updated. The dimension of features can be reduced by principal component analysis (PCA) [14] and other dimension reduction algorithms. However, based on too complex features method is not conducive to the fine-tune hyper-parameters. The information utilization of trackers based on deep features is improved, but the fusion features may not deal with all the challenges (illumination, deformation, fast motion, occlusion and so on). In addition, the performance of a single tracker may be unstable when meet different video sequences [15].
High-level semantic features are more robust to object shape change, and shallow features are good for precise positioning. If the two features are merged directly, the high-level features will cover the shallow features. In this paper, a multi stage features adaptive updating correlation filter method is proposed. It is different from merging deep features and traditional features. The proposed algorithm firstly fuses the features of deep network by weighting, and then solves the trackers for several features respectively. The final result is selected by robust decision. Considering the output of multiple trackers in the decision stage, the system can not only make full use of the features information, but also effectively improve the robustness of the system when deal with different video sequences. In addition, ECO [9] and similar methods make use of the multi-layer features of deep network, but it’s unreasonable that high-level semantic features and shallow features all adopt the same label map. The method proposed in this paper takes into account the differences of deep and shallow features to distinguish label maps. In model updating stage, we adopt the adaptive update method instead of the fixed update, so the algorithm can better adapt to the change of the target environment.
The contributions can be summarized as following folds. 1). We using four weighted integration of different layers of network features to calculate the parameters of correlation filters separately. 2). Unlike previous methods, which used the same label map as the target value of regression, we use different label maps in order to adapt to the difference between features. 3) It is difficult for a tracker to deal with all types of situations in a video sequence, so we get the tracking results by different fusion features and select the final result by robust decision. 4) We propose an adaptive model updating strategy.
Discriminant correlation filters (DCF)
The discriminant correlation filter (DCF) combined with convolution features based tracking methods have gained much attention in benchmark test. DCF is designed to train a correlation filter through a series of training samples. In the field of object tracking, the training sample is the first picture. Suppose the picture is x, and the size is
Where
In order to reduce the adverse effects of edge effects, Hanning window is usually added to the signal to suppress the boundary effects [8] which produced by circular sample blocks. The online update can be obtained by the following:
where
In the field of object detection, many methods combine shallow features with deep features by means of fusion [17, 18]. High-level semantic features have good robustness, and the shallow features are helpful to the accuracy of location.
Multi-layer features weighted fusion
This paper uses VGG19 [19] (removing the full connection layer) to extract features.
In order to make full use of the features information of deep network, we fuse the pre-processed
We fuse multiple features to train multiple trackers. In this way, the proposed method can effectively deal with the interference of video sequence. The sum of the weights is 1, we train the tracker by minimizing the regression error. During fusion stage, we can get the weights according to regression error.
The performance of single tracker may sometimes be unstable. Unlike the response map fusion methods [9, 10, 12, 20], the proposed method estimates the tracker from multiple angles according to the features of the multi-layer fusion of the VGG19 network. In order to make full use of features information, different features should be labeled differently.
In experiment, we find that the selection of standard deviation
We use the method of target scale estimation in DSST tracker to estimate the size of bounding box [34]. Four correlation filters can be obtained according to the corresponding fusion features. The bounding boxes of object corresponding to different fusion features in
In order to prevent the occurrence of extreme cases, the non-linear Gauss function is used to estimate the score between the bounding boxes.
The variance of the scores between the bounding box
Considering the time series nature of video, the adjacent frames have more similarities, so the weight setting is larger than previous frames. We set weights
The robustness score of the
The size of the object in adjacent frames varies slightly. So, object’s bound box between frames should be smooth.
In Eq. (12),
The final bounding box of the object is determined by the robustness score. The highest score box is the best bounding box in the current frame. In Eq. (13),
Most of the discriminant correlation filter methods update filter parameters [8, 10, 12] per frame. When the object moves too fast or deforms too much, the incorrect prediction will lead to model drift, and even lead to tracker has a failure tracking. Therefore, there is a method to update the parameter [9] at intervals of several frames, which not only reduce the update frequency, but also effectively reduces the possibility of drift. However, it is difficult to flexibly cope with the model updating caused by the change of the object when the frequency is fixed. In this paper, an adaptive update mechanism is proposed.
Peak-to-sidelobe ratio (PSR) can reflect the reliability of tracking results [21]. PSR is showed as follow.
Online learning can effectively adapt to the changing situations of object in video. If the PSR of the current frame is larger than the average PSR of the historical frame, the selection of the current learning rate is appropriate. If it is lower than the average PSR of the historical frame, it means that the current learning rate needs to be updated.
For clearly understanding the proposed method in this paper, the framework of our method is depicted in Fig. 1.
Lowchart of the proposed tracking algorithm.
In order to verify the effectiveness of the proposed method, a large number of experiments have been carried out on OTB2013 [22], OTB2015 [23] and VOT 2016 [24] datasets. The experimental platform is Intel (R) Core (TM) i7-8700 CPU@3.2 GHz, 8 GB memory, and implemented on MatConvNet. The GPU version is GeForce GTX 1080Ti. In OTB2013 and OTB2015 database experiments, We evaluate the proposed approach with 15 recent state of-the-art trackers including MDNet [25], CCOT [10], CREST [20], ECO-HC [9], BACF [26], LCT [27], SRDCF [28], CF2 [13], HDT [29], Staple [30], CNN-SVM [31], SAMF [32], MEEM [33], DSST [34], KCF [8]. In the experiment, all the tracking methods are evaluated by the distance precision (at an threshold 20 pixels). In addition, we use overlap success plots over these datasets using one-pass evaluation (OPE).
Evaluation on OTB2013
OTB2013 database has 50 video sequences and 51 test scenarios. These video sequences involve 11 attributes of target tracking, including illumination change, scale change, occlusion, deformation, motion blur, fast motion, in-plane rotation, out-of-plane rotation, out-of-view, background interference and low-pixel. Each video sequence corresponds to two or more attributes. (a) and (b) in Fig. 2 are Precision plots and Success plots respectively. The threshold of precision maps is set to 20 pixels. That is to say, within 20 pixels of the distance between the predicted central of the bounding box and the actual central of ground truth, the tracking result is considered success. The success plots of OPE is calculated based on the area under the curve (AUC).
Precision plots and Success plots for trickers on OTB2013.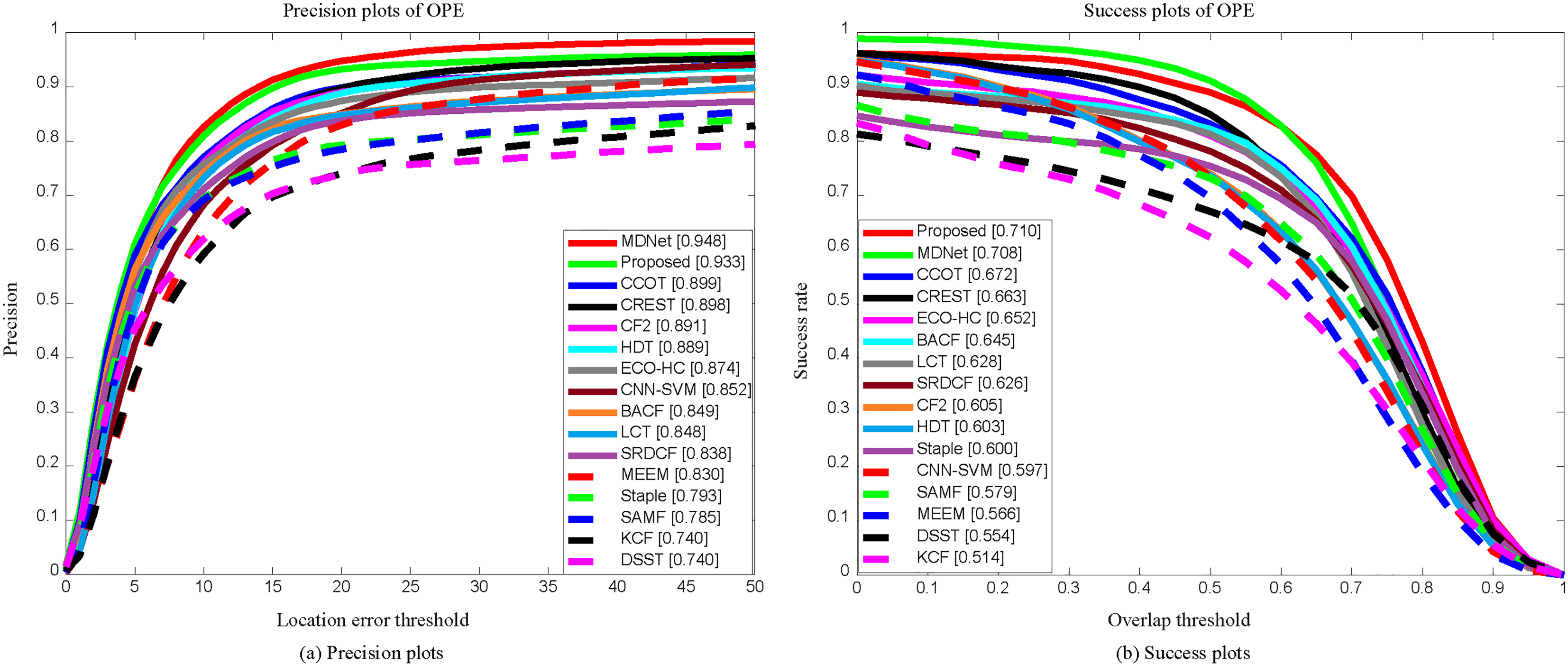
As can be seen from Fig. 2a, the accuracy of our algorithm is higher than the other methods except a little bit lower than MDNet. Figure 2b shows that the success rate of the proposed method is the best among all the comparison methods. It is worth noting that MDNet is a deep learning method which is trained offline in an end-to-end manner. Although the accuracy of MDNet method is higher than proposed method, the testing speed of MDNet is very slow, which is below the real-time requirement of 1 fps. When test a new video sequence, the results of MDNet may be worse. The proposed method not only has good robustness, but also achieves the test speed of 12.4 fps.
OTB2015 database has 98 video sequences and 100 test scenarios. Compared with OTB2013, OBT2015 adds video sequences, which makes the performance evaluation of tracking algorithm more reasonable.
Precision plots and Success plots for trickers on OTB2015.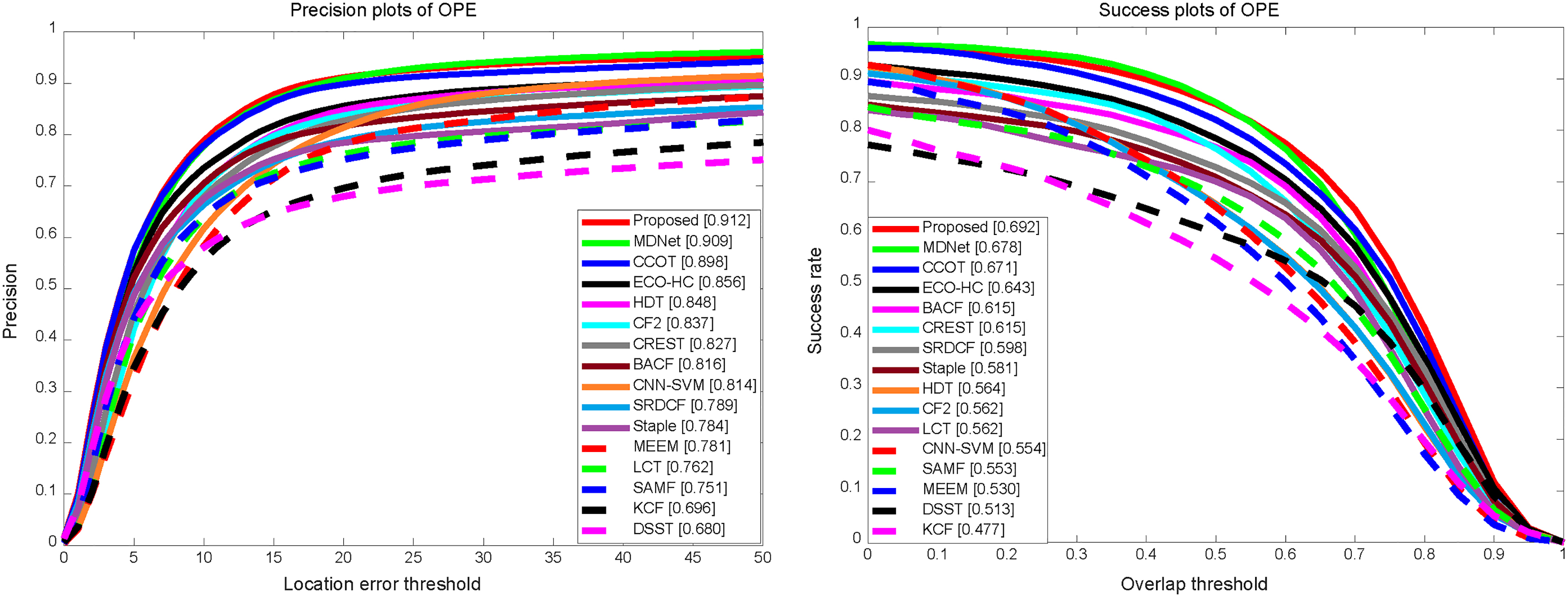
Figure 3 is the experiments of all trackers in OTB2015 database. From the precision plots, we can find that the accuracy of this method is the highest. From the success plots, the area under the curve (AUC) of the proposed method is also the highest, which is outperforming 1.4% than MDNet and nearly 8% higher than CREST (ICCV2017) and BACF (CVPR2017).
In order to compare the performance of each tracker in videos of different properties, we select videos with occlusion, vision, background interference and fast motion as the test database. The experimental results in Fig. 4 show that the accuracy of the proposed method is slightly lower than that of MDNet and CCOT under fast motion, but the area under the curve of the success rate of the proposed method is the highest. In addition, the proposed method exhibits optimal performance under occlusion, out-of-view and background interference.
VOT 2016 database is one of the most commonly used databases in the field of object tracking. The database is short video sequence, but it is more challenging than OTB video database. In the experiment, accuracy, failure rate and expected average overlap (EAO) are used to measure the performance of tracking algorithm. We use the official VOT algorithm results as a comparison, the experimental methods in this section are MDNet, CCOT, Staple, SRDCF, SSAT [35], EBT [36] and MLDF [24].
Table 1 shows our method along with several trackers listed in the report of the VOT2016. In comparison, the proposed method rank 1st according to EAO. Specifically, it can surpass CCOT in the 2nd place by 5.1%. From Table 1, it can be seen intuitively that the performance of our method is the best except that the accuracy is slightly less than SSAT method. The failure rate reflects the number of times the tracker fails in tracking the object, our method has the lowest failure rate compared with other methods.
Precision plots and Success plots in video sequences under occlusion, out of view, background clutter, fast motion.
In order to intuitively see the tracking results of the trackers, we show the results of Dragon Baby, Biker and Tiger2 video sequences. It is shown in Fig. 5.
Indicators of tracking methods for VOT 2016 dataset
Indicators of tracking methods for VOT 2016 dataset
Tracking results.
Figure 5 shows our method is able to outperform CREST (ICCV 2017) in tracking videos regardless of the fast change or occlusion. When the appearance of object varies greatly, such as frame 71 in Biker video sequence, our method can effective track the object. Overall, our algorithm performs favorably against CREST, DSST, MEEM and KCF.
It is difficult for a single correlation filter to deal with all situations in the field of target tracking. The method in this paper makes full use of the features information of the network. Besides, an adaptive updating method was proposed in the paper. High-level semantic features are more robust to object shape changes, while shallow features are more accurate for location. The proposed algorithm firstly fuses the features by weighting, then we train the trackers by minimizing the regression error for several fused features respectively. During decision stage, we select the final result from the outputs of multiple trackers. In this manner, the method makes full use of the deep features information, and also effectively improves the robustness of the system. In addition, our method in this paper takes into account the differences of high-level and shallow features to set different label maps. In terms of update strategy, adaptive update method is adopted instead of fixed update. In future, we will focus on how to further enhance the robustness of the proposed method. And how to effectively combine offline learning with online update model.