
Abstract
Various methods have been proposed recently to solve the problem of weak domain adaptability of Chinese word segmentation (CWS) models based on neural networks. However, although some of these improved models achieve high segmentation accuracy in a specific domain, they need to be retrained when applied to another. After rethinking the domain adaptability, two criteria, including the segmentation accuracy and the universality, are suggested for measuring it. Taking the above two criteria into consideration, an improved neural-based CWS model is proposed, which incorporates the common lexicon and unlabeled data into BERT. To make the most use of lexicon, a new method is proposed to construct the lexicon-based feature vector. In addition, the domain-specific words can be effectively extracted by pre-training a language model on the unlabeled data. Finally, a GRU-like gate structure is used to integrate the lexicon-based feature vector and language model into BERT. Experiments on five different domains reveal that the domain adaptability of this model is very strong.
Introduction
For Chinese, a word instead of a single character should be the smallest semantic unit since a character is often not clear enough to express the semantic it contains in the text. Hence, CWS is the first step in many Chinese natural language processing tasks, and its importance is self-evident.
In recent years, great success has been achieved in segmentation accuracy with the use of neural-based CWS models [1, 2, 3, 12]. Compared with CWS models based on traditional machine learning, neural-based CWS models are superior in utilizing the long-distance contextual information and able to avoid manual feature engineering [1, 2]. However, such models still suffer from the problem of weak domain adaptability. Specifically, the test set contains many domain-specific words that are not available in the training set. In addition, the difference of domains the datasets belong to may lead to the different contexts of the same word, which finally results in different segmentation [4, 5]. The domains of the training and test sets are referred to as the source and target domain respectively in the following.
It is pointed out that out of vocabulary (OOV) words could not be well recognized by changing neural architecture without the additional resources [6]. Lexicons and unlabeled data contain many domain-specific words, and the latter reflects the contextual information of the target domain, so both can be used as additional resources. Various methods have been proposed to integrate lexicons and unlabeled data into the neural-based CWS models [5, 7, 8, 23, 24]. These methods can improve segmentation accuracy in the target domain, indeed. However, some of the above models can only be applied to a specific domain, and they need to be retrained when applied to another [8, 9]. There does exist some universal models [5, 7], but most researchers only focus on cross-domain segmentation and ignore the universality of the model. Cross-domain segmentation focuses on studying transfer learning from the source domain to a specific target domain from the perspective of segmentation accuracy. But it ignores the universality of the model, that is, the model can be applied to various target domains after training.
Based on the above analysis, we hold the point that the domain adaptability means that the model can achieve outstanding segmentation accuracy in different domains without retraining. Therefore, two aspects, including segmentation accuracy and universality, should be considered simultaneously when it comes to domain adaptability.
In this paper, we propose a novel neural-based CWS model which incorporates both common lexicons and unlabeled data derived from the target domain into BERT [10] to improve the domain adaptability of CWS models. With the consideration of the segmentation accuracy and universality, we adopt BERT instead of BiLSTM for CWS. Since BERT is pre-trained on a large-scale unlabeled corpus, it is, of course, suitable for more domains than BiLSTM. The pre-trained parameters of BERT are fine-tuned using the annotation set of the source domain to obtain the BERT based CWS model (BERT-CWS). In order to further enhance the domain adaptability, a common lexicon is used to design a feature vector for each character in the sequence. The vector can represent the position of a character in the word containing it, which is beneficial for word segmentation. Finally, by incorporating the vectors into BERT-CWS, we realize the fusion of BERT and lexicons and get the model BERT-DICT-CWS.
It is almost impossible for the common lexicons to include all domain-specific words. To deal with this problem, we use the target domain unlabeled data to train a language model which can reflect the compactness between characters, so as to capture domain-specific words not included in lexicons. However, because the unlabeled data comes from the target domain, after incorporating the language model into BERT-DICT-CWS, the final model BERT-DICT-LM-CWS is almost equivalent to BERT-DICT-CWS in terms of universality. The improvement of BERT-DICT-LM-CWS is that its segmentation accuracy is higher than BERT-DICT-CWS in a specific domain. Experiments show that the domain adaptability of BERT-DICT-LM-CWS is very strong.
Related work
To improve the domain adaptation of the neural-based CWS models, our final model uses BERT to replace the basic BiLSTM, and we propose a new method to use lexicons and unlabeled data. This chapter will analyze some of the work related to the use of BERT, lexicons and unlabeled data from the perspective of segmentation accuracy and universality.
[11] proposed Transformer which based solely on self-attention mechanism. Comparing with the recurrent neural network (RNN), Transformer is parallelizable and superior in training speed [11]. [10] pre-trained BERT based on Transformer in a large corpus and then fine-tuned the parameters of the pre-trained model with the annotation dataset for a specific task. Since the corpus used in pre-training was derived from various kinds of domains, the model BERT has wide universality.
The idiom lexicon is used by [2] to replace the idioms matched in the training set with a specific tag before training the LSTM based CWS model. [13, 21] selected several words randomly from lexicons to generate pseudo labeled data for handling lacking the training set. To provide valuable information about different aspects, [7] constructed an 8-dimensional feature vector based on lexicons for each character in the sequence and used BiLSTM to integrate it. [22] incorporated the unlabeled data and lexicon into model training as indirect supervision.
[14] obtained numeric statistical features from target domain unlabeled data and incorporated them into LSTM. [15] proposed a general semi-supervised approach for adding pre-trained context embeddings obtained from a bidirectional language model, which pre-trained on a large number of unlabeled data, to sequence labeling tasks. [8] used a gate mechanism to combine BiLSTM with the bidirectional language model trained on the target domain unlabeled data. Among them, [8, 14] did not improve the universality of their models because they only used unlabeled data derived from a specific target domain.
In order to improve the universality of our model, we incorporate lexicons (not including target domain lexicon) into BERT-CWS. In addition, to make up for the shortcoming that the common lexicon cannot contain all of domain-related vocabularies, and further improve the segmentation accuracy of our model, we incorporate the target domain unlabeled data into BERT-DICT-CWS.
Model introduction
This chapter first introduces how to adapt BERT to CWS. Then, a new approach to construct the feature vector based on lexicons is proposed to achieve the purpose of incorporating useful lexicon information into BERT-CWS to get the model BERT-DICT-CWS, which can improve the domain adaptability of BERT-CWS from the aspects of universality and segmentation accuracy. Finally, without reducing the universality of BERT-DICT-CWS, we incorporate a language model pre-trained on the target domain unlabeled data into BERT-DICT-CWS so that the segmentation accuracy of BERT-DICT-LM-CWS is further improved in a specific target domain.
BERT-CWS
CWS is generally treated as a sequence labeling task. Specifically, each word in the sequence is marked with {B, M, E, S}, where B (Begin), M (Middle) and E (End) represent the first character, the middle character, the end character of the word respectively, and S (Single) represents the word composed of a single character. Our BERT-CWS model is also based on the idea of sequence labeling. We choose BERT because it is a model based on bidirectional Transformer, which constructed entirely on the self-attention and Multi-head attention mechanism. For the single character, Transformer calculates the attention of it with all other characters in the related sequence. Through Transformer, a character vector will be obtained, which embodies its dependence on surrounding characters, which is beneficial for word segmentation. [10] used Masked LM to pre-train BERT on a large-scale corpus. Hence, the character vector obtained by the pre-trained BERT model can reflect its context very well.
BERT-DICT-CWS. Trm means Transformer block.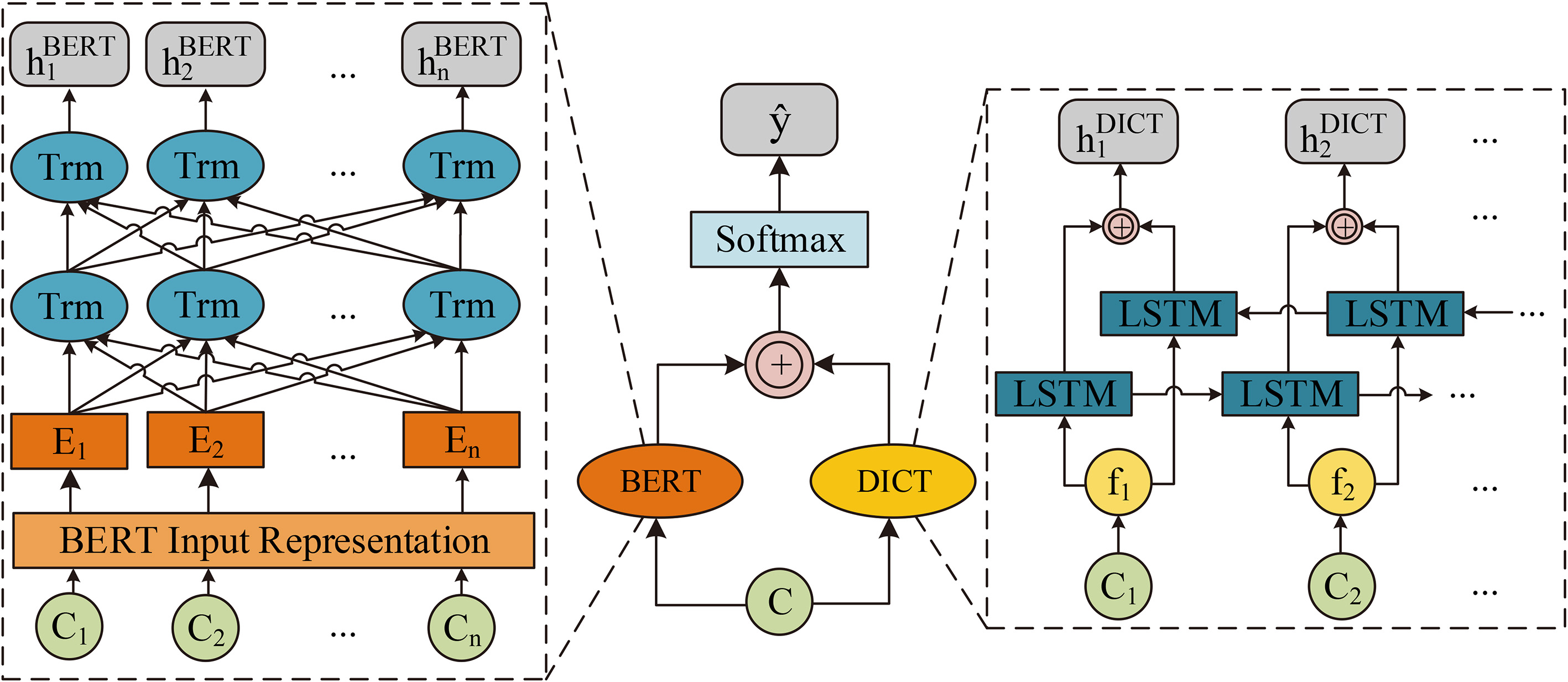
The BERT-CWS model is shown in the left dotted box of Fig. 1. In word embedding layer, BERT uses three kinds of word embeddings to represent a single character. First, each character will find its corresponding word embedding from WordPiece embeddings [16]. Next, because Transformer can’t reflect temporal information, BERT adds position information for each character. Finally, it also incorporates the embedding of the related sentence where the character is located. The formula of word embedding for the
where
Through the bidirectional Transformer module, we can get the output of BERT.
where
Finally, the
where
Given the truth labels
where
By minimizing the cross-entropy loss function, the model implements backpropagation and updates the parameters of the model, making BERT suitable for CWS.
Lexicons contain some words that do not exist in source domain training set but exist in the target domain test set. For example, “UTF8gbsn柴胡” (Bupleurum) is likely to not exist in the source domain, but it does exist in both lexicons and the medical domain. Therefore, lexicons contribute to improving domain adaptability. For an input sequence, we construct a lexicon-based feature vector for each character in it. According to the characteristics of the words, these feature vectors only consider the local dependencies of the characters, so they need to be passed to BiLSTM to obtain the long-distance dependency. Finally, the output of BiLSTM is concatenated with the output of BERT to obtain the model BERT-DICT-CWS.
The position of a character in a word can be known with lexicons, but this position is sometimes not fixed in a sequence. For example: the sequence “UTF8gbsn产品质量”, “UTF8gbsn品” is the end of the word “UTF8gbsn产品”, but also the first character of the word “UTF8gbsn品质”. In order to be able to express the possibility of characters becoming B, M, E, S in a neural network, we give the following method.
For an input sequence
For each character
With the consideration of out of vocabulary words and deficiencies of string matching, the number 0.1 is added at last.
The BERT-DICT-CWS model is designed as Fig.1. Here, the lexicon-based feature vector is passed to BiLSTM because the lexicon information only considers the local dependence while BiLSTM can obtain the long-distance dependence of the character so that the representation vector corresponding to the single character can better express its position information in the word. The output formula of BiLSTM is as follows.
Where
We concatenate the output of BERT and BiLSTM. The formula is as follows.
The following softmax normalization process and the cross-entropy loss function are the same as before.
n-grams of
BERT-DICT-LM-CWS. F_LSTM meams forward LSTM.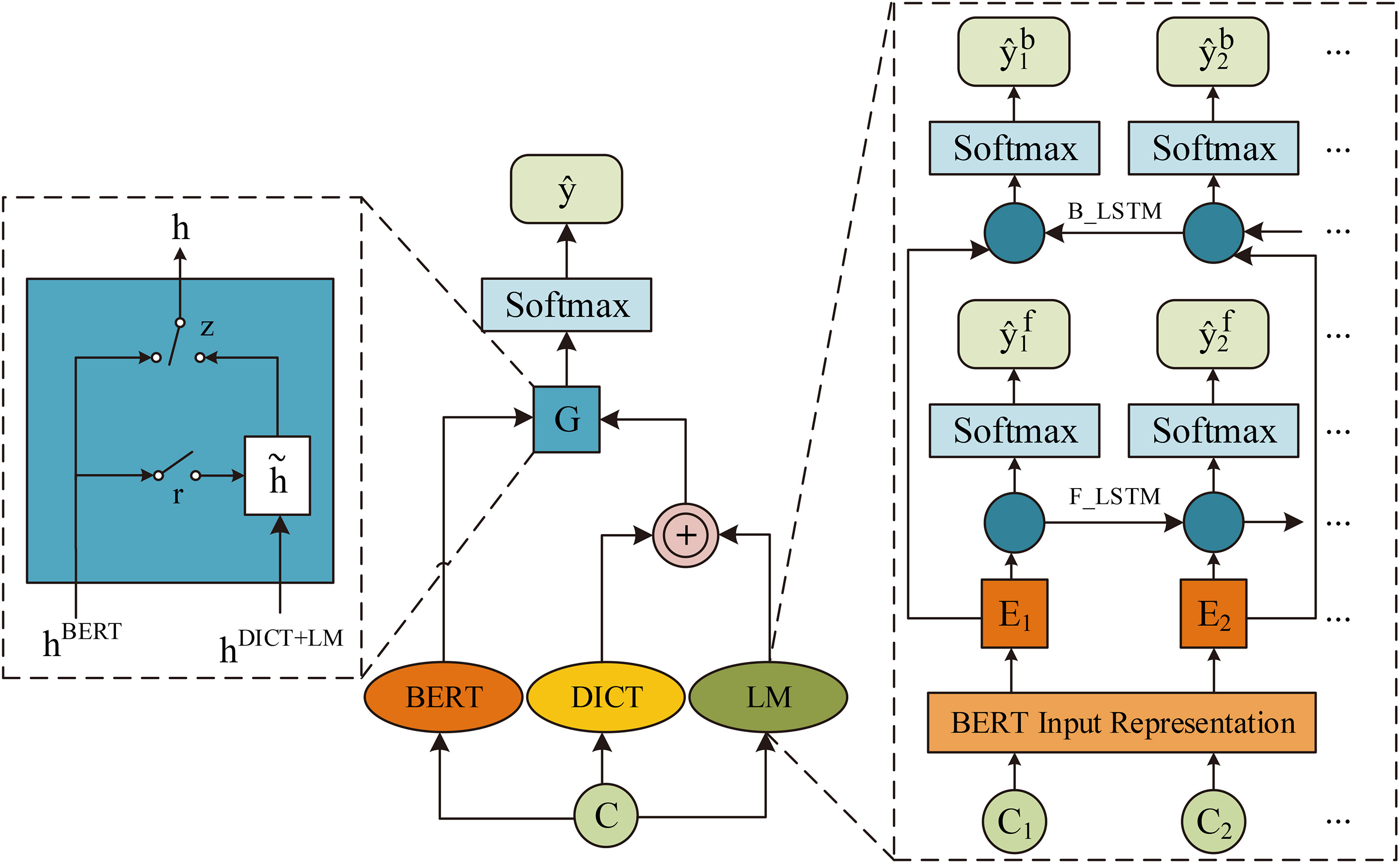
Taking some special areas into consideration, they have not been pre-trained by BERT, and most of their domain vocabularies do not exist in the common lexicon. In this case, unlabeled dataset of the target domain is used to pre-train a language model to improve the word segmentation accuracy in this area.
The language model uses previous words in the sequence to predict the probability of the next word. For a sequence
The neural network structure of the language model can be seen in the right dotted box of Fig. 2. For the character
After Incorporating a language model pre-trained on the target domain unlabeled data, our final model BERT-DICT-LM-CWS is designed as Fig. 2.
The difficulty in designing this model is how to handle the relationship of the output of BERT, the lexicon module, and the language model, i.e.
Concatenation is superior in retaining the original information of each part, but there is also a disadvantage that at each time-step, the weight of a certain part for the current sequence cannot be highlighted. In addition, continuous concatenating will cause the problem of excessive dimensions. Referring to [8], we use a GRU-like gate mechanism to deal with the relationship between
where
Finally, the obtained
Datasets
We use Chinese Treebank 5.0 (CTB5) as the source domain labeled training set. Zhuxian (a Chinese novel) and four other self-made datasets are used as the target domain test sets. Zhuxian was annotated by [17]. In accordance with the method of [18], we have produced development and test sets in four different domains, including literature, medicine, computer and finance. The literary dataset comes from “A Dream of Red Mansions” and “Journey to the West”. The medical dataset comes from “Hu Xishu talks about typhoid fever” and “Chinese Pharmacy”. The computer dataset comes from HowNet. The financial dataset comes from “Modern Monetary Theory”.
In addition, the lexicon we use is a common lexicon which comes from jieba. The unlabeled datasets come from the corresponding field of the test set. For example, when testing Zhuxian, we will use its remaining data, excluding the development and test sets, as the unlabeled dataset.
Finally, to test the performance of the proposed model in the same domain, we also use Chinese Treebank 6.0 (CTB6) , and PKU and MSR which come from SIGHAN2005 [25].
Datasets
Datasets
In the experiment, we mainly trained three models: BERT-CWS, BERT-DICT-CWS and BERT-DICT-LM-CWS. BERT-CWS and BERT-DICT-CWS can be used to test different target domains after training on CTB5. However, the BERT-DICT-LM-CWS model needs to be retrained in different target domains because it requires the target domain unlabeled data.
Table 3 shows some of the important hyperparameters that are needed for these three models. In order to fine-tune the parameters of the pre-trained BERT model, we set a relatively small initial learning rate, and after training a batch, the learning rate will decay linearly. Too small a learning rate can lead to overfitting, so we set up dropout rate to prevent this problem. In addition, the model uses Adam [19] as the optimizer.
Hyperparameters
Hyperparameters
Table 4 shows the F1 values of different neural-based CWS models in eight domains. The cross-domain segmentation results are shown from the second column to the six, and the last three columns reveal F1 values in the same domain. The bold models in this table indicate that they are retrained in each target domain. Domain adaptation of our model is analyzed emphatically in the following.
F1 values of different neural-based CWS models
F1 values of different neural-based CWS models
In the first block, we present two benchmark models BiLSTM and BiLSTM
In the second block, we present models using additional resources. [17] used external lexicons and unlabeled target domain data to improve domain adaptation for joint CWS and POS. [20] used partially-labeled data derived from target domain to train a CRF model. This approach can solve the problem of the insufficient training set, but the universality of the model cannot be enhanced. [5] attempted to solve the domain adaptability problem based on the semantic similarity between the target domain unlabeled data and the source domain labeled data. [8] used a language model pre-trained on unlabeled data to obtain co-occurrence information for words. They only considered the segmentation accuracy in a specific domain without considering the universality of the model. Because of this, it is necessary to retrain the model of [8] in different domains. [7] constructed an 8-dimensional lexicon-based feature vector and used two methods to integrate it into the neural network. Here, we just use the method of concatenation.
In the last block, we present three models designed in this paper and a BERT-DICT-COM-CWS model. As can be seen from Table 4, the segmentation result of BERT-CWS is better than BiLSTM and BiLSTM
The in-domain segmentation performance of our model is analyzed as follows. In-domain means the source and target domain data are derived from the same domain. [26] built a modular segmentation model and pre-train the most important submodule using rich external sources. [7, 8] used lexicons and unlabeled data, respectively. The last three columns in Table 4 show that the F1 values of the above three models are higher than the benchmark model BiLSTM, which proves the usefulness of external resources. BERT also pre-trained on large-scale datasets, which leads to the high performance of the model BERT-CWS. After using the scheme of this paper to integrate the lexicons and unlabeled data into BERT, the F1 value is further improved, which proves that our scheme is effective.
Words that have not appeared in the labeled data can be called out of vocabulary (OOV) words. Accurately identifying OOV words is a difficult task for cross-domain segmentation task. The OOV recall can reflect the strength of domain adaptability to a certain degree. Therefore, Table 5 shows the OOV recall for BiLSTM and the three models proposed in our experiments in five different domains. It can be seen that BERT-CWS has a much higher OOV recall than BiLSTM. After incorporating the lexicon and unlabeled data, the OOV recall is further improved.
OOV recall
OOV recall
The main drawback of the proposed model is that the amount of parameters is too large. This leads to a longer time for the model to be trained, and the speed of word segmentation on the test set is about three times lower than normal BiLSTM based CWS model. In order to minimize the complexity of the model, a four-dimensional lexicon-based feature vector is constructed. Comparing with the eight-dimensional lexicon-based feature vector proposed by [7], our method uses less dimension and is superior in training speed.
To compare the two methods of constructing a lexicon-based feature vector proposed by [7] and us, respectively, we replace the feature vector part of Zhang’s model with ours without changing other parts. B_4 is used to represent our model, and B_8 is the model of Zhang. As can be seen from Fig. 3, these two feature vectors have almost the same effects. When the hidden layer dimension is small, our method will have a slight advantage. With the increase of dimension, the segmentation accuracy of both methods will decrease, and our method drops faster. In addition, since our feature vector uses only four dimensions, it will be faster in training speed.
Comparation of two lexicon-based feature vectors. The horizontal axis represents the hidden layer dimension and the vertical axis represents the F1 value.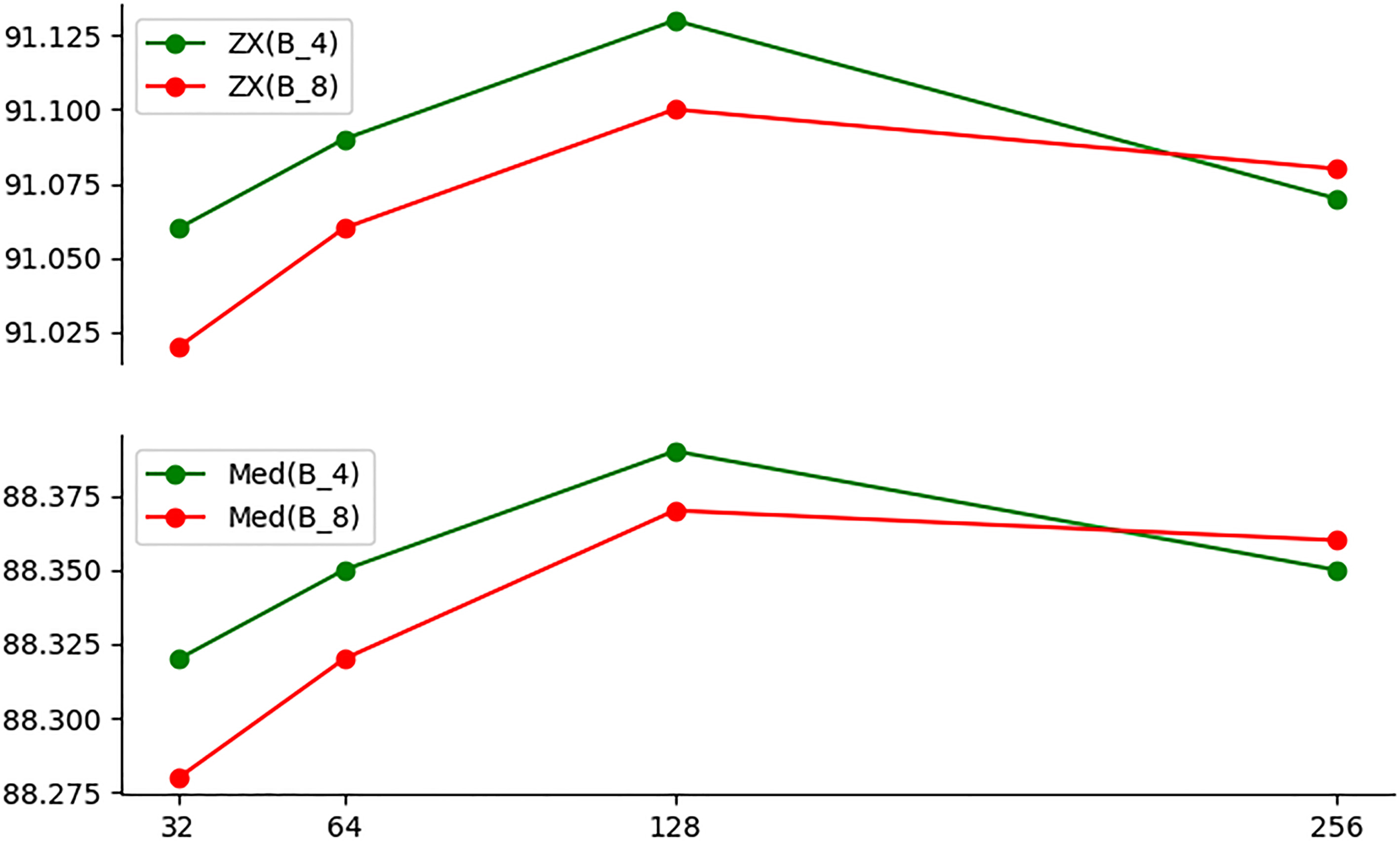
This paper analyzes the domain adaptability of CWS models based on neural network and holds the point that the strength of domain adaptability should be measured from the aspects of segmentation accuracy and universality. Based on this point, we propose to combine the BERT model with lexicons and target domain unlabeled data to improve the domain adaptability. Experiments show that the fusion of BERT-CWS and lexicon can improve both the segmentation accuracy and universality of BERT-CWS. What’s more, incorporating the target domain unlabeled data into BERT-DICT-CWS can improve the segmentation accuracy in a specific domain, but unable to improve the universality of BERT-DICT-CWS. In summary, our final BERT-DICT-LM-CWS model has very strong domain adaptability.
Footnotes
Acknowledgments
This work is supported by Zhejiang Provincial Technical Plan Project (No. 2020C03105).