
Abstract
In order to solve the problem of low efficiency of traditional theme crawlers in searching theme pages, the crawling algorithm based on Context Graph was discussed. After analyzing the working principle and process of the algorithm, we introduced a new algorithm idea named feature selection algorithm. This new algorithm improved the original TF-IDF formula accordingly and solved the algorithm problems.
Introduction
From the perspective of the whole study history of crawler algorithm, there are much more theme algorithms. From the traditional perspective, however, there are two main types of corresponding algorithms: text-based hyperlink structure and network-based hyperlink structure. To achieve this theme crawling algorithm, first of all, the Context Graph should be built for the crawler to find the crawling path independently, which is actually the link between pages and the hierarchical structure diagram composed by it.
The crawling algorithm based on content analysis can effectively predict the degree of page correlation, which has a good theoretical basis, and the calculation method is relatively simple, but this method ignores the link structure information between pages. Represented by PageRank crawling algorithm based on link structure, by analysing the relation between the page link relations to determine the importance of the pages, and access to link in order to sort, but they only consider the relationship between the links between pages, ignore the page itself related situations and relatively large amount of calculation, the theme of the affected crawling speed. At the same time, these two types of crawling algorithms predict the importance of links mainly based on the information obtained during crawling, which is often local and difficult. Therefore, these two types of crawling algorithms generally have the disadvantage of “local optimal”, while the improved topic-crawling algorithm based on Context Graph can better solve this problem.
Universal crawler structure.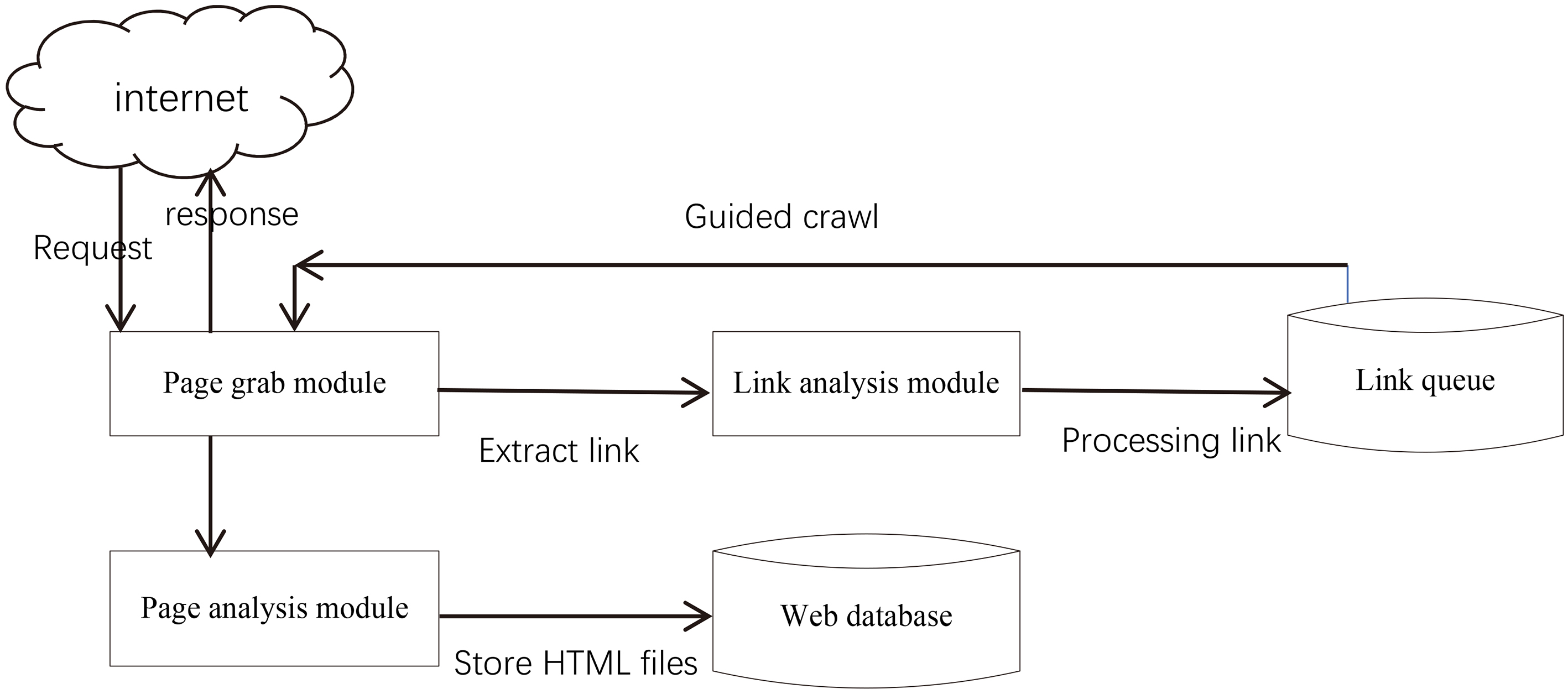
Context Graph carries out classification training on the pages set of each layer through the experience automatically improved computer algorithm (machine learning method), and it can estimate the probability of relevant characteristic words and prior probability. Through the crawling process of the theme web crawler, the classification training of each layer is firstly achieved, and then the probability that the page belongs to each layers can be calculated by the text classifier when a new page is acquired. After the probability sorted, the layer with the highest probability will be determined to be part of the link path.
M. Diligenti first proposed the topic crawling idea of Context Graph, which was mainly based on the assumption that when searching pages with similar topics, the crawlers must also take similar routes. When designing this algorithm again, in order to make this crawling strategy more reasonable than other strategies, we should not only consider the theme feature of crawling, but also pay attention to the tunnel feature. If you want to pass a crawler to crawl on a particular subject, search crawl after, will be related to the subject of a large number of papers in the web page, may also have some of these pages link to point to other pages may have an association or download address, this layer, web page, will form a hierarchy between users to search the hierarchical structure of the target page crawled path.
To design the topic crawling algorithm based on Context Graph, the first step is to use the reverse search function provided by the existing search engine to expand the scope search of the sample pages related to the theme provided by the user, and see whether the search of these sample pages can be realized through the limited link path in the page to be searched. After the result of the page query is processed, a Context Graph model corresponding to the query process can be obtained.
Under the background of graph, crawler algorithm can not only judge the path of new visited page that is not the target page, but also determine how far the page is from the target page, that is, the level in the path, so the training of classifier in advance will become the priority among priorities. Providing training sample set for training text classifier is an important goal of constructing Context Graph.
The Context Graph of the two layers.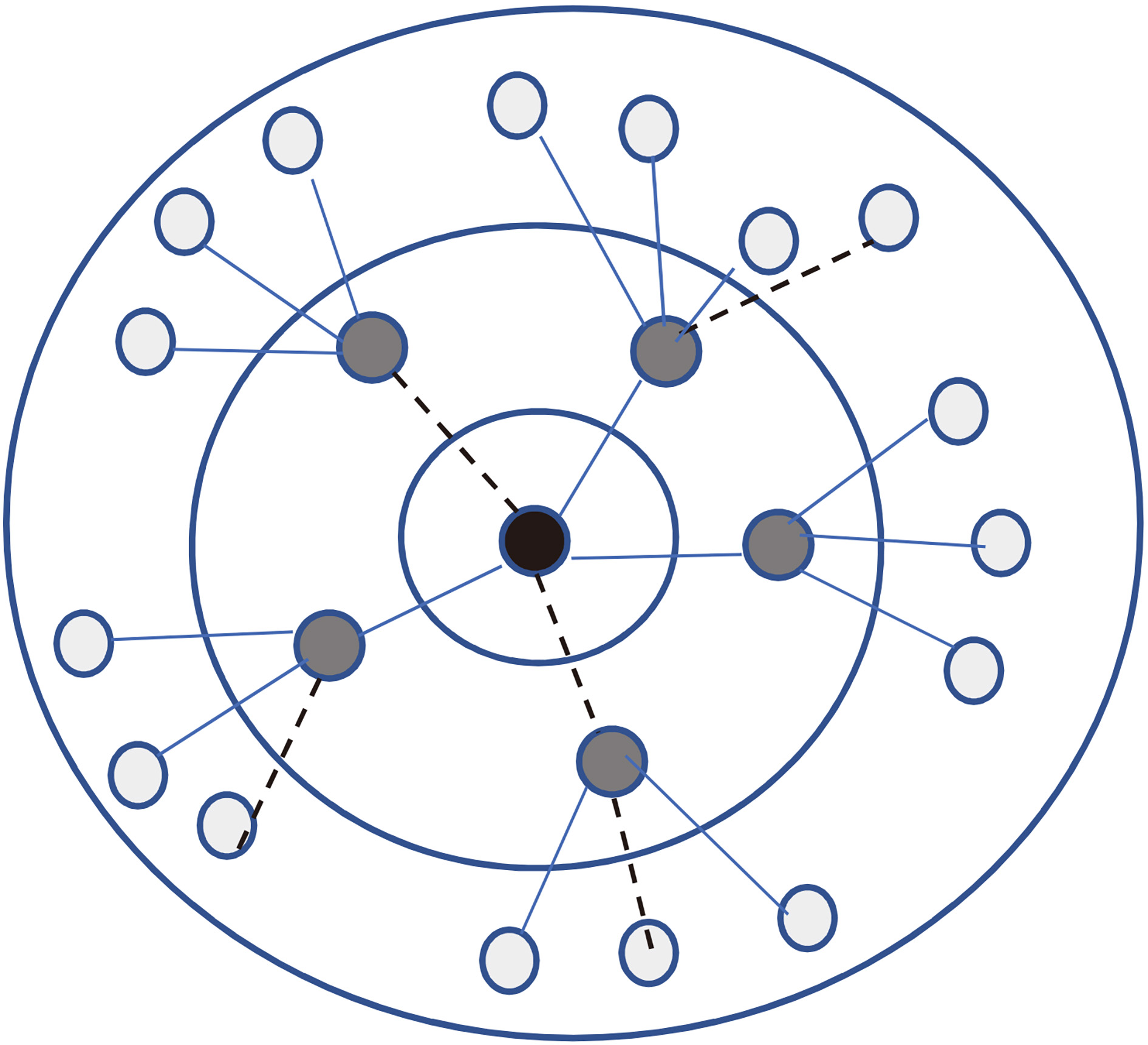
The classifier training should be realized through a specific set of pages. As for specific page content it expresses the theme and the keywords that represent the theme of the page. When taking classifier training of one level page, the webpage will have a hierarchical division according to the established model and merge them together. That is the so-called Context Graph of the merged page.
Here, we use TF-IDF for analysis. TF-IDF (term frequency – inverse document frequency) is a commonly used weighting technology for information retrieval and text mining. The main idea of TF-IDF is: if a certain word appears in one article with a high frequency of TF, and rarely in other articles, it is considered that this word or phrase has a good classification ability and is suitable for classification.
The first step is to select the features of each layer by the method we have mentioned before, and use TF-IDF formula to calculate the weight of characteristic words in the original algorithm. For instance, to calculate the weight of a word m, first we should assume the document which it belongs to as
In this formula, some variable names are defined to indicate corresponding value. Variable name
After having finished the whole process, you can get a set of feature words which is represented by K here. This set of feature words corresponds to the Context Graph of each layer in the page of key sets, and it uses the vector space form of the original algorithm to reveal it. Then we will get the training samples which are made up of the corresponding standard vector. At last, we will use the corresponding layer of the classifier training so that the ultimate aim will be getting the prior probability. If the constructed Context Graph has
To construct the n-layer Context Graph,
The theme of traditional crawling algorithm exists obvious deficiency, will reduce the search speed of network, and based on the Context of the Graph topics crawling algorithm can solve part of the problem, the corresponding to judge new access to the page as the target, whether the precursor node, and predicted its in crawl path depending on the level of the distance of the target page from, for those who have potential value of the crawling path reserved as much as possible. So compared with the traditional crawling algorithm, the theme crawling algorithm based on Context Graph has some noticeable advantages. However, it also has its own shortcomings. The weight of each feature word calculated by this algorithm should be referred to the page set obtained by the crawler. But the value obtained by this set is not accurate because the page set that crawls in each layer with this kind of algorithm is not typical enough and the TF-IDF formula also has certain deficiencies in itself. In order to make up for these shortcomings, the thesis proposes an improved algorithm, which also perfects the TF-IDF formula, especially solves the problem that the weight calculation of characteristic words is not accurate enough.
Document feature application
The higher the dimension of the feature word set is, the more complex the feature set extraction and the longer process of crawling will be so that the quality of crawling will also be affected. How to reduce dimension becomes the problem to be solved, which is also the core of feature selection of document set. The process can be represented by the course of feature selection of the graph text set in Fig. 2.
Processing of document set feature selection.
The feature words in a feature set are not representative, so it is impossible to calculate the exact weight of the feature words. Therefore another feature selection algorithm is needed for evaluation, and the specific process of evaluation will completed by constructing the evaluation function. After the evaluation, the representative feature word sets and their corresponding weights will obtained. Therefore, the core of the evaluation process is the evaluation function. Here are two commonly used evaluation functions.
First, we will set some names:
We assume that the probability that the word mk belongs to category
In practice, it always takes the average of them:
If
It shows that the greater the probability of an event is, the less information can be provided when it occurs, and vice versa. Similarly, the less frequently a word appears, the higher the weight value and higer probability of being selected as a feature word it has.
Based on these theories, if
This formula shows that the value of log
After the text classifier classifies the training samples, the obtained classification set is not detailed and accurate. Therefore, in the practical application, the document set representing the category should be further refined to obtain more refined subcategories. For example, the computer category can be subdivided into mainframe, microcomputer and other subcategories. A large category document set may contain many subcategories, and the proportion of each subcategory is not the same. On account of this situation, the sample set itself will restrict the application. It may happens that in a collection of computer-class documents, 70% of the documents may belong to the subcategories of the minicomputer class, 20% of the documents may belong to mainframes’, and only 10% of the documents may belong to giant-scale computers’. Maybe different subcategories will have the same feature words. These feature words can indicate that these subcategories belong to the computer category. However, if the giant-scale computer category has a few feature words and document in the whole document collection of computer category, this part of the word will not get attention and be wrongly abandoned according to the above theory.
In order to avoid the frequent occurrence of this situation, this paper proposes another judgment method, that is, some words are important enough to be extracted as long as they occur frequently in a certain subclass of documents set, even if they appear in a certain class of documents set very rarely.
After further research, this paper discusses a new feature selection method to solve the deficiencies. Feature selection algorithm bases on word frequency difference, and it will improve the existing TF-IDF formula.
We use
Where
Then we can come up with the following improved TF-IDF formula:
It is an adjustment of the original formula, which is based on the original formula and multiplied by the weight of the word category. The reason is that documents of different categories should distinguish the different degrees of the importance of the same word. If one word is important for the document of the specified category, while it must be unimportant for other categories. This is what the improved algorithm can reflect.
On the basis of the original crawling algorithm, we make the following changes by using the new feature selection algorithm idea and the improved word weight calculation formula as following:
Sample collection is carried out in the current corpus (such as sogou). According to the sample classification, the weight According to the category di of the subject, the previous category weight Category d by subject; using the category weight of the word calculated before
In the crawler system, precision ratio, recall ratio and F1 value can all be calculated. These three values are generally used to evaluate the performance of a crawler system. To determine whether a newly acquired page is related to a topic, it is necessary to calculate the precision ratio, which is relatively simple to achieve compared with the other two. In the further process of crawling, we need to calculate the recall ratio to count the total number of pages related to crawling topic, and the workload of this process is very complicated. In the calculation, the application of precision ratio and recall ratio should be combined. In this paper, F1 value (F-measure) is introduced to realize this process.
First, the crawling results are sorted, and the first
At present, the corpus of sogou is relatively comprehensive. Due to its comprehensive classification, it mainly contains information saved from Sohu website. News corpus and relevant classification information are manually sorted and classified, and many experimental samples are used. This paper also USES the corpus of sogou as the data source to extract documents and special words.
In order to compare the performance of the algorithm, this paper makes an experimental measurement using the crawling algorithm based on the Context Graph and the theme crawling algorithm under the improved background. The sample is the theme of “car”. In order to obtain standard crawling data, we take several conditional values for the number of pages obtained. According to the two algorithms at 1000, 1500,
Comparison of recall ratio, precision ratio and F1 value
After a new feature selection algorithm is introduced into the improved algorithm, the TF-IDF formula has been improved so that the performance of the subject crawler system is greatly improved. The figure below compares the performance of the two algorithms more intuitively:
Comparison of FI values of the two algorithms.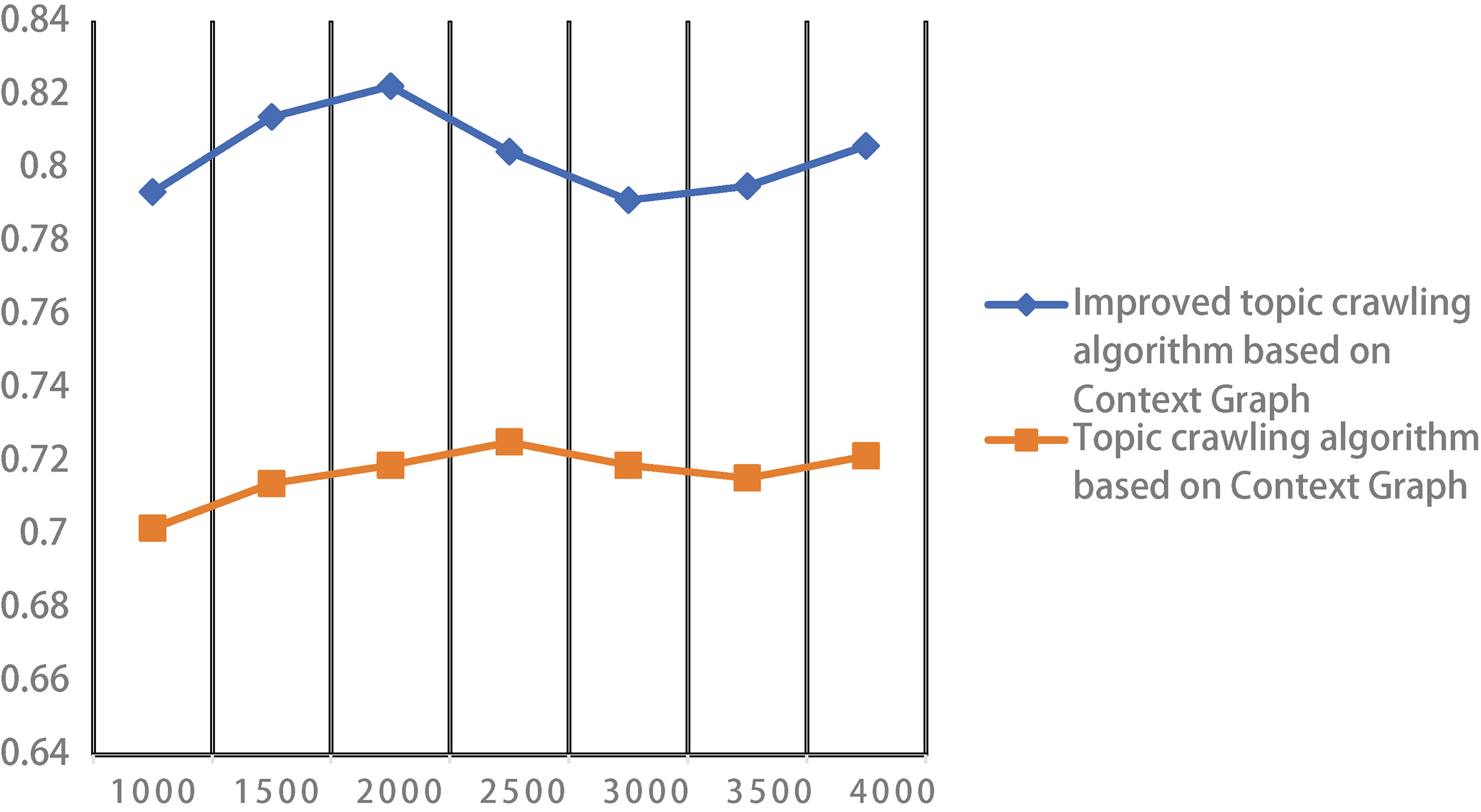
After introducing a new feature selection algorithm into the improved algorithm and improving the TF-IDF formula, the performance of the subject crawler system is improved to a large extent. By comparing the corresponding values obtained by the two algorithms, it can be seen that in the context of the calculation of recall rate and improvement, the crawling algorithm is much better than the subject crawling algorithm based on the context. At the same time, the optimized subject crawling algorithm is much better than the subject crawling algorithm in the precise calculation. This result indicates that the improved Context Graph crawler algorithm has more advantages in terms of precision than the crawler based on Context Graph.
With the rapid development of the network, the theme crawler can meet the needs of users who pursue “specialization, sophistication, profundity”. Traditional crawler cannot fulfill the characteristics both of web crawler search strategy subject and the tunnel. The topic crawler search strategy which is based on the Context Graph can solve the problem of the tunnel well. However, it does not take into consideration of link anchor text, the title and page text. So this thesis, through introducing the idea of judging level in the algorithm, can only solve the problem of frequency crawling speed. After analyzing the working principle and process of the algorithm, a new algorithm idea named feature selection algorithm is introduced. In this new algorithm, the original TF-IDF formula is improved accordingly, and the algorithm problem can be solved as well .
Some deficiencies in this paper need to be improved. In practical application, some noisy pages may appear, that is, the links in these pages do not match the search theme, so how to eliminate it is also a matter for further study.
Footnotes
Acknowledgments
This work was supported in part by Science and Technology Project of Jilin Provincial Department of Education (JJKH20180949KJ, JJKH20191203KJ), Jilin Provincial Science and Technology Department No. 20190201195JC, 20180101047JC.