
Abstract
Each pixel can be classified in the image by the semantic segmentation. The segmentation detection results of pixel level can be got which are similar to the contour of the target object. However, the results of semantic segmentation trained by Fully convolutional networks often lead to the loss of detail information. This paper proposes a CRF-FCN model based on CRF optimization. Firstly, the original image is detected based on feature pyramid networks, and the target area information is extracted, which is used to train the high-order potential function of CRF. Then, the high-order CRF is used as the back-end of the complete convolution network to optimize the semantic image segmentation. The algorithm comparison experiment shows that our algorithm makes the target details more obvious, and improves the accuracy and efficiency of semantic segmentation.
Introduction
The more computer vision technology develops, the more people are increasingly trying to use the theory of deep learning to solve many problems in image processing and recognition technology. Convolutional neural networks based on deep learning can fuse image segmentation and image recognition, and image features can be extracted by the convolutional network. The image is divided into a group of regions with certain semantics, and their categories are identified. Finally, the semantic image with each pixel tag is obtained, and the image analysis and understanding are completed.
The traditional image segmentation divides the digital image into several specific regions with unique properties. These regions do not intersect each other, and each region meets some similarity criteria of gray, texture, color and other features. The target is separated from the background based on these features. This method does not need complex model construction and large-scale training samples, so the method is more intuitive. However, the target recognition method based on feature points needs to correctly match the feature operator and calculate the model estimation from the template image to the image to be matched. The matching accuracy will be affected by image noise and parameter space transformation, and the algorithm is relatively inefficient. Later, scholars put forward the idea of target recognition based on random sampling consistency and global information probability model. For example, Fischler and Bolles proposed RANSAC algorithm [1], which is based on the framework of hypothesis verification, estimates the parameters of the model from the data set containing external points by iterative method, and obtains the correct interior point. The whole process is random and data-driven. Matas et al. [2] tested the subset of sample points and selected subsets from the data set. Only when all the points in the subset become interior points can the remaining set of points be verified, which improves the efficiency of the algorithm. Later, Lafferty et al. [3] proposed a CRF model, which integrates local features of multiple types of images, links global information and direct posterior probability modeling, effectively and accurately completes pixel classification, and integrates image segmentation and recognition tasks.
For semantic image segmentation through deep learning, in the early days, the pre-segmentation map was first generated by traditional image segmentation methods, and then the pre-segmented images are classified by CNN network training. But now, it is more through the design of various convolution neural network models, so that the image semantic segmentation results can be directly obtained by training the image. Compared with target detection, semantic segmentation is a deeper level of image understanding, and it is a more important way of image understanding. For example, super-pixel image segmentation based on fully convolution neural network (FCN) is the most widely used semantic image segmentation and recognition model. Reference [4] proposed the design idea of changing the deep neural network into fully convolution network (FCN) to complete image recognition, and obtained more accurate semantic image segmentation results. Compared with the SDS method proposed in reference [5], the accuracy and speed have been improved. Convolution neural network models SegNet [6] and DeconvoNet [7] train image pixel features through convolution and deconvolution to solve the segmentation problem caused by the change of object size. In addition, target recognition based on multi-scale depth structure image segmentation network [8, 14], using CRF or Region Proposal to help reasoning, training multi-scale convolution neural network, etc. This paper will focus on how to optimize semantic segmentation based on deep learning to improve the accuracy and efficiency of semantic segmentation.
Semantic segmentation based on conditional random field
Conditional random field [1] (CRF) is to model the target sequence based on the observation sequence. It is an undirected graph model, which calculates the joint probability distribution of the whole marker sequence under the given observation sequence to be marked. When dealing with the semantic segmentation problem, the basic analysis method is to convert the image segmentation problem into the image label problem.
For an image
Let variable
Where
Equation (2) indicates that in the Markov random field represented by undirected graph
The posterior probability of conditional random field conforms to the Gibbs distribution, and its expression is defined as follows:
Where
The energy formula is as follows:
Where
In order to enhance the constraint relationship between pixels and their regions, Kohli [8] proposed a high-order potential function as an additional constraint condition, which greatly improved the efficiency of the algorithm. The higher order energy function is defined as:
Where
Kohli defines two kinds of high-order potential functions, which are based on the region consistent potential function and the segmentation quality sensitive potential function, one of the definitions is as follows:
Another definition is as follows:
The higher-order potential function introduces a higher-level consistency criterion, that is, by judging the quality of a group of hyperpixel segmentation, better semantic segmentation effect can be obtained.
Semantic segmentation results by conditional random field. (a) Original picture (b) univariate potential function (c) binary potential function (d) higher-order potential function.
It shows the segmentation effect of different potential functions in Fig. 1. It is clear that the segmentation results with binary potential function are better than those with only one variable potential function, and the target details are more obvious. The high-order potential function can improve the segmentation effect slightly and improve the efficiency of the algorithm.
Conditional random field model is almost perfect in mathematics, involving probability, expectation, optimization and other knowledge, and has good effect in natural language processing. However, the segmentation accuracy of this kind of algorithm depends on the image label to some extent. Algorithm execution speed and accuracy need to be improved to better meet the real-time requirements of robot vision.
Jonathan Long [2] and others proposed a Fully convolutional networks (FCN) model at the CVPR2015 conference in 2015, which can realize end-to-end semantic image segmentation. FCN uses the deconvolution layer to replace the full connection layer in CNN network, and uses bilinear interpolation upsampling method to restore the same size of the input image, and produces a prediction for each pixel. Finally, it classifies pixel by pixel on the up sampled feature map to obtain the semantic segmentation image result.
Usually, there will connect several full connection layers after the convolution layer in CNN network. The feature map generated by convolution is mapped to a feature vector in the sample label space to obtain the prediction probability for the whole image category, which is suitable for classification and regression tasks. For example, the output of the final fully connected layer of the AlexNet [3] is a vector has 1000 dimensional. The probability of the input image belonging to each category is given by the softmax classifier, which can achieve 1000 category classification. Although this network structure can accurately determine the category of objects contained in an image, it cannot classify each pixel, nor can it outline the specific outline of the object, so it is hard to achieve precise semantic image segmentation.
Fully convolutional networks is an endtoend image segmentation method, which allows the network to predict the pixel level and directly get the label map. It can accept input images of any size. The feature map is classified pixelbypixel based on the feature map of up sampling. However, the convolution pooling operation in the front end of Fully convolutional networks will reduce the original image and reduce the image resolution. Although the end-to-end output is guaranteed by upsampling, the segmentation accuracy is not high due to the loss of information. In order to make the classification of pixels more accurate, we can combine the high-resolution features in front of the convolution layer with the low-resolution features of the following layers.
Upsampling optimization graph based on skip layer.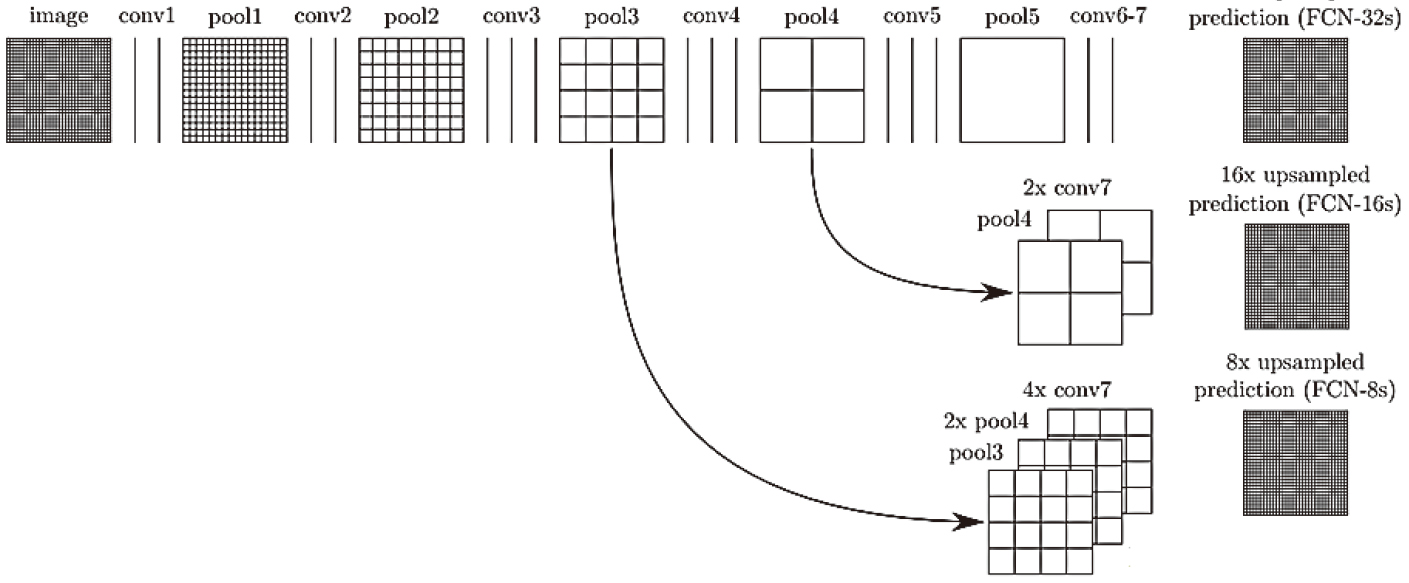
As shown in Fig. 2, if the original image is convoluted and pooled once, the output step is halved. After five convolution pooling operations, the image will be reduced to 1/32 of its original size. At this time, the original image size can be obtained by 32x upsampling. We call this net FCN-32s. If a 1
Although Fully convolutional networks can better achieve semantic image segmentation, due to its high-dimensional feature information after convolution operation is relatively abstract, and the upsampling operation is relatively simple, resulting in the loss of detailed information of target structure, easy to ignore and allocate small target objects, cannot well express the category correlation between adjacent pixels, and lack of spatial consistency.
Comparison of semantic image segmentation results. (a) Original image (b) FCN-32s (c) FCN-16s (d) FCN-8s (e) Ground truth.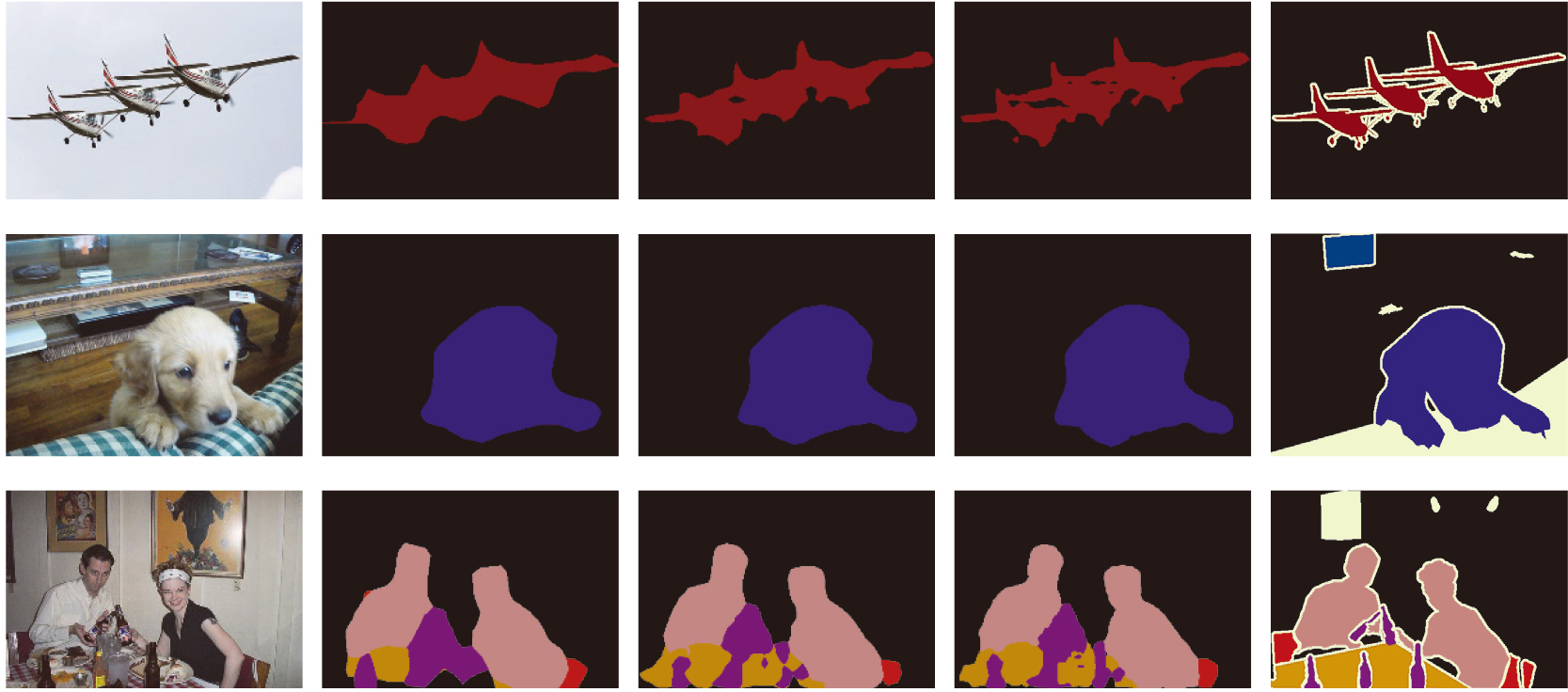
For improving the accuracy of segmentation, inspired by CRFasRNN, we use high-order conditional random field as the back-end of complete convolution network to optimize semantic image segmentation. First of all, we need to detect the original image based on feature pyramid networks, extract the target area information, and construct the high-order potential function of conditional random field. Then, we input the images to be segmented to Fully convolutional networks training to generate a rough prediction graph. Then, the prediction graph is upsampling, and the high-order conditional random field is used for iterative optimization.
Target detection based on feature pyramid networks
In order to detect small objects, this paper uses feature pyramid networks to achieve target detection. Based on the images in voc2012 database, the network training results are shown in Fig. 4. As you can see that the target detection based on feature pyramid networks can also detect small objects in the image, and the relative accuracy is relatively high, and the speed is relatively fast. Then the detected region of interest is trained to determine the parameter model of the high-order potential function of the conditional random field.
Target detection based on feature pyramid networks.
The iterative algorithm flow of CRF-FCN is as follows:
The input image The approximate distributions of input sample initialization
According to the current model parameters, the energy function of the
Update Calculate the approximate distribution of random variables
If it does not reach the maximum number of falls T we set, go to step 3 and repeat the cycle.
The Fully convolutional networks is based on conditional random field model optimization in this paper. The main FCNs use FCN-8s. The high-order conditional random field model trained by feature pyramid networks target detection information is written as a network layer structure similar to convolution layer, which is added after the softmax layer of fully convolutional networks. This method can avoid the influence on the forward and backward propagation of the network. The structure of networks and training process are shown in Fig. 5.
CRF-FCN convolution neural network model.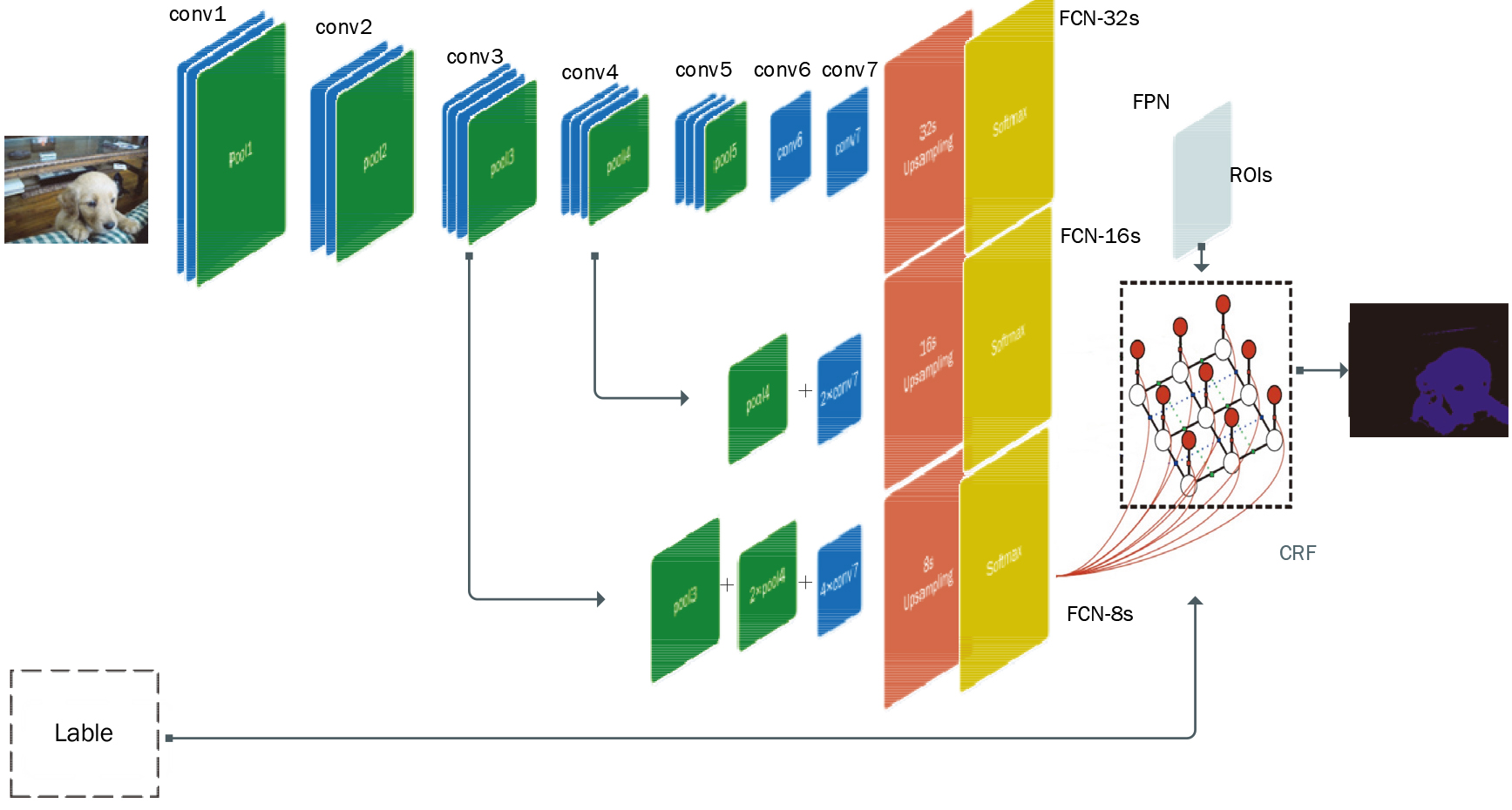
The Comparison of segmentation results. (a) Original image (b) FCN-8s (c) Ours (d) Ground truth.
The steps of network training are as follows:
The input image is processed and the size is 256 Make image data set (training data set, test data set) and label data set (LMDB or LEVELDB format); The ground truth image in the dataset is processed to generate the label image for training, and then the LMDB is generated; After compiling the conditional random field algorithm written in C++, it is written into the fully convolutional networks according to the definition requirements of relevant network layer, and added to the back of softmax network layer; Select the images of voc2012 dataset as experimental data, and train and test the effectiveness of semantic image segmentation performance improvement based on CRFFCN networks on the basis of trained FCN-8s like Fig. 6.
From the image segmentation, we can see that compared with FCN-8s, the fully convolutional networks model optimized by high-order conditional random field has better semantic image segmentation effect. Because the high-order potential function of conditional random field is trained based on feature pyramid networks, the recognition and segmentation effect for small-scale targets is obviously better than that of the conditional random field, and the segmentation in the details should be more accurate, and the edges can be more clearly recognized.
In the semantic segmentation experiment, we generally use the mean pixel accuracy and the Intersection of Union (IoU) for each type of target to quantitatively evaluate the segmentation accuracy of the model, and use the time spent by each algorithm in processing an image to evaluate the executive efficiency of the algorithm.
The average pixel accuracy is defined as:
Intersection of Union is defined as:
Where
The experiment is running on the computer of AMD FX 8300, FX-8300, 8-Core, 8G memory. The experimental platform is Caffe (Python 3.6) under Windows 10, and NVIDIA GeForce GTX 1080 Ti graphics card is selected to accelerate convolution network training.
Comparison of the mean IoU with difference object of the algorithm
The comparison of the accuracy of each algorithm in different lines is given in Table 1.
Comparison of segmentation accuracy and running time of the algorithm
The comparison of average segmentation accuracy and running time of each algorithm is given in Table 2.
The experiment is tested by using the trained network model. Compared with FCN-8s model, our model improves the segmentation accuracy by optimizing the semantic segmentation results based on CRFs. As can be seen from mean IOU. Compared with FCN-8s+CRF model, our model has similar segmentation accuracy. However, from the perspective of semantic segmentation images, the segmentation at the details is more accurate, and the edge can be more clearly recognized.
In our model, the high-order conditional random field model trained by FPN target detection information is written as a network layer structure similar to convolution layer, which is added after the softmax layer of FCN. Therefore, compared with FCN-8s+CRF model, the influence time of out model is greatly reduced using the trained model for semantic segmentation can improve the efficiency and greatly shorten the image processing time. Therefore, after training the model for semantic segmentation can improve the efficiency and greatly shorten the image processing time.
This paper analyzes in detail the structure of CRF and FCNs for semantic segmentation. Based on the discussion of the above methods, we propose a CRF-FCN networks based on conditional random field optimization. It takes the high-order conditional random field of target detection as the back-end network layer of the complete convolution networks, and iteratively optimizes the pre segmentation results of the complete convolution networks to obtain better segmentation accuracy. The effectiveness and accuracy of the method in semantic image segmentation and recognition are verified by image segmentation experiments.
Footnotes
Acknowledgments
This research has been financed by Projects funded by National Natural Science Foundation of China (Grant: 51875266).