
Abstract
In order to facilitate communication and communication, this paper studies the optimization of the current computer-aided translation system, and proposed a design method of English communication language computer-aided translation system based on grey clustering evaluation. By optimizing the hardware configuration and algorithm function keys of the system, the English translation mechanism of multilanguage interaction, the design idea of editing and modifying after English translation and knowledge database management are realized, and the system function framework was constructed, including the system transceiver unit, automatic translation unit, manual correction unit, task management unit and memory management unit, the performance of task management unit and memory management unit is analyzed. On this basis, the specific work flow of the design system mainly includes the English translation service flow integrating multilanguage interaction and the project-based multilanguage interaction English translation service flow design, which realizes the English translation online assistance under the multilanguage interaction environment. The experimental results show that the design system has the advantages of high online translation speed, pronunciation success rate and multilanguage translation success rate.
Introduction
Language translation is a common task in learning and scientific research. Manual translation has high requirements for translators and wastes a lot of time and energy, so people usually choose software translation [1]. However, at present, the translation quality of all translation software is far from that of manual translation, and most of the results can not be used directly. Although the algorithms of translation software are constantly improving, the quality of translation still needs to be improved [2]. Based on this, this paper designs a computer-aided translation system of English communication language based on grey clustering evaluation. Taking English Chinese translation as an example, combined with the idea of artificial intelligence, this paper constructs a translation system including system transceiver unit, automatic translation unit and manual error correction unit, optimizes the English translation service process integrated with multi language interaction, and carries out English translation under multi language interaction environment, so as to better improve the translation accuracy and ensure the operation effect of the system [3, 4].
Computer aided translation system for english communication language
Hardware configuration of computer aided translation system for English communication language
The translation system can use the communication computer as the platform, combine the web server with the database technology, transform the information needed in the auxiliary translation mode into data, and the professional management personnel can supervise and manage the system [5]. The translator can log in to the system and set up his own translation assistant studio to carry out the auxiliary translation activities. In the web-based assisted translation system, the establishment and composition of the assisted translation team and the assistance among translators will change with the demand [6]. In the system design, the assisted translation process should be taken as the data flow basis, and the translator management authority should be used to assist the management. Based on this, the hardware configuration of the language computer-aided translation system is optimized, as shown in Fig. 1.
Structure of language computer aided translation system.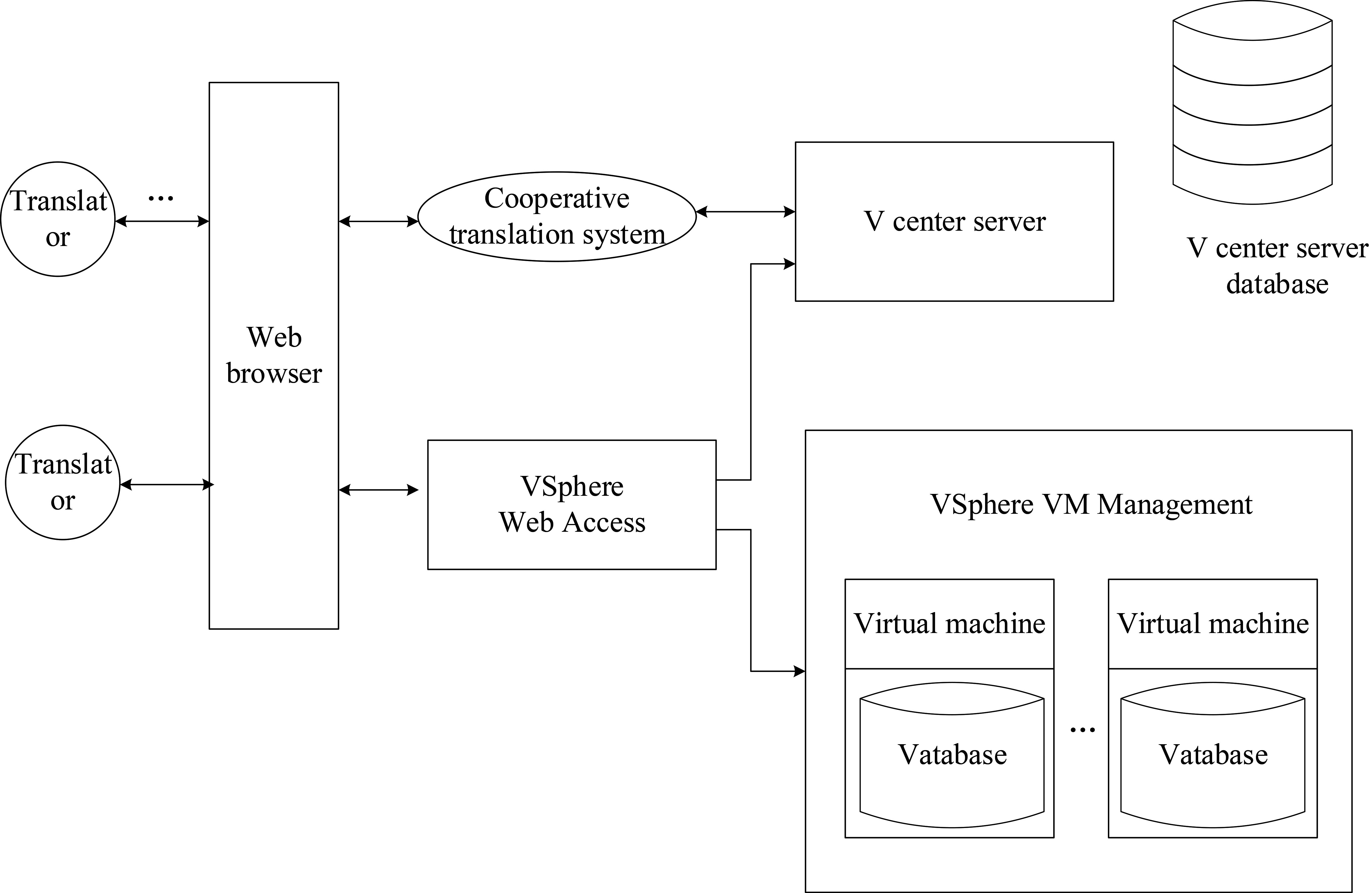
In this framework, the business logic layer is implemented by spring, which uses the control transformation IOC dependency injection Di mechanism as the core of the spring framework. IOC injects the implementation dependency of each module of business logic into the action module by reading the configuration file, so as to actually call the business logic. During runtime, Di container dynamically injects dependencies (such as construction parameters, construction objects or interfaces) into components. By using bean attributes to configure corresponding attributes in bean. XML file, spring framework uses bean’s reverse control to put bean into spring container to make bean become a component of business logic layer. For example, in the on-line auxiliary conversion module, only need to configure the bean properties, create a Dao object that inherits the hibernate Dao class provided by spring, and then copy the crud method to complete the loading of the business logic components and integrate them into the spring container management. Due to the complex hardware structure of the system, you need to add multiple circuits and use Pt pulse signal to measure the surge current of the arrester. Hardware circuit diagram as shown in Fig. 2.
System hardware configuration structure.
In Fig. 2, in the online auxiliary transformation module, you only need to configure bean properties, create a DAO object that inherits the hibernatedao class provided by spring, and then copy the crud method to complete the loading of business logic components and integrate them into spring container management [7]. Due to the complexity of the hardware structure of the system, multiple circuits need to be added, and Pt pulse signal is used to measure the surge current of the arrester. MCU chip is selected as the hardware circuit structure of the system, which is produced by silicon company. It has the ability of real-time information collection, small size and strong anti-interference ability [8]. Because the oscillator is added in the chip, it has the programming ability. At the same time, it integrates 15 bit 150 ksps ADC and 2 UARTS, which greatly enhances the processing speed of the chip, up to 25 mips. The memory in the chip is 15 KB flash memory, which can store 1282 bytes of data. Two I/O ports are used to connect two external power supplies to ensure that the chip can stably output 2 V–5 V power supply voltage [9]. The monitoring system has 12 different timers in four different positions, and controls the system kernel with pipeline structure, which can meet the requirements of measurement and processing [10]. System framework is the basic structure of system design, which plays a guiding role in a system design. The framework of the system is based on B/S architecture. B/S architecture, full name of browser/server in Chinese, is a three-tier architecture, which is composed of data logic layer, business logic layer and display logic layer, as shown in Fig. 3.
B/S three-layer architecture.
In Fig. 3, the main storage language information and a variety of translation programs. The communication module selects TL16C554 asynchronous communication module produced by TI company [11]. In order to ensure the expansion function of serial port, four serial ports are added. Each serial port can be converted to the serial port in MCU. All communication states, including normal state and error state, are recorded through registers to ensure the reliability of communication process [12, 13]. FIFO communication mode is extended to the common communication mode, which can receive and cache up to 16 bytes of data and improve the data transmission rate of the communication process [14]. The input level is TLT level. The structure of communication module is shown in Fig. 4.
Communication module structure of English translation system.
The communication module in the figure has four TL16C554 asynchronous communication components, each communication component has a programmable baud rate generator, and the highest baud rate is 1.5 mbps [15]. The data state is controlled by data controller and register. The data control mode is full duplex control, and each receiving and sending is independent. At the same time, the design of interrupt control is strengthened, which can receive data even if the timeout interrupt. The integration and unified management of server resources through cloud operating system can save computer resources and ensure the safe and stable operation of the system [16]. The device used for language translation processing is a single chip microcomputer. It is composed of a series of hardware components such as arithmetic unit, controller, memory, input and output device, which is equivalent to a microcomputer. The single chip microcomputer in the system is atmega6490. The MCU achieves the throughput of 1 mips per megahertz and balances the power consumption and processing speed [17]. Therefore, high performance and low power consumption are its biggest advantages. The technical parameters of atmega6490 are shown in Table 1.
Technical parameters of single chip microcomputer
Using virtualization technology, while providing a large number of virtual resources to the data center, summarize the basic physical hardware resources among multiple systems. As an assistant translation system, VMware vSphere can manage large-scale infrastructure seamlessly and dynamically [18]. Through the services provided by the center server, the system manages and uses the resources in the virtual machine cluster, and manages the complex data center at the same time. Users can use the web browser to access the auxiliary translation system. Sphere web access is used to resolve the physical location of the virtual machine and redirect the web browser to the virtual machine [19]. The auxiliary translation system requires strong operation ability to support online translation activities.
The auxiliary translation activities based on grey clustering evaluation only need a computer connected to the Internet to ensure the smooth development of translation work. Auxiliary can create a greater effect than the simple accumulation of a single workload, and realize the synergistic effect. The advantage of assistance is that it can make full use of the organization resources, shorten the working time, and focus on the tasks that are difficult for individuals to complete in a short time [20]. The construction of auxiliary platform is to make full use of organizational resources to achieve common goals. In the process of team assisted translation, creative ideas and translation methods often appear unexpectedly. In order to make the platform play a positive role and effectively promote the assistance and communication between translators, it is necessary to build a convenient and standardized network assisted translation environment. On the auxiliary translation platform, translators can create their own independent translation studios, and then invite translators to join their own translation studios according to the actual needs [21]. A translator can belong to multiple translation studios. In this way, translators jointly construct an assisted translation environment. In the process of assisted translation activities, translators can also participate in each other’s translation activities. The whole translation activity is a synchronous, dynamic and open process. The membership of the platform is shown in Fig. 5.
Optimization of the function and structure of the assisted translation platform.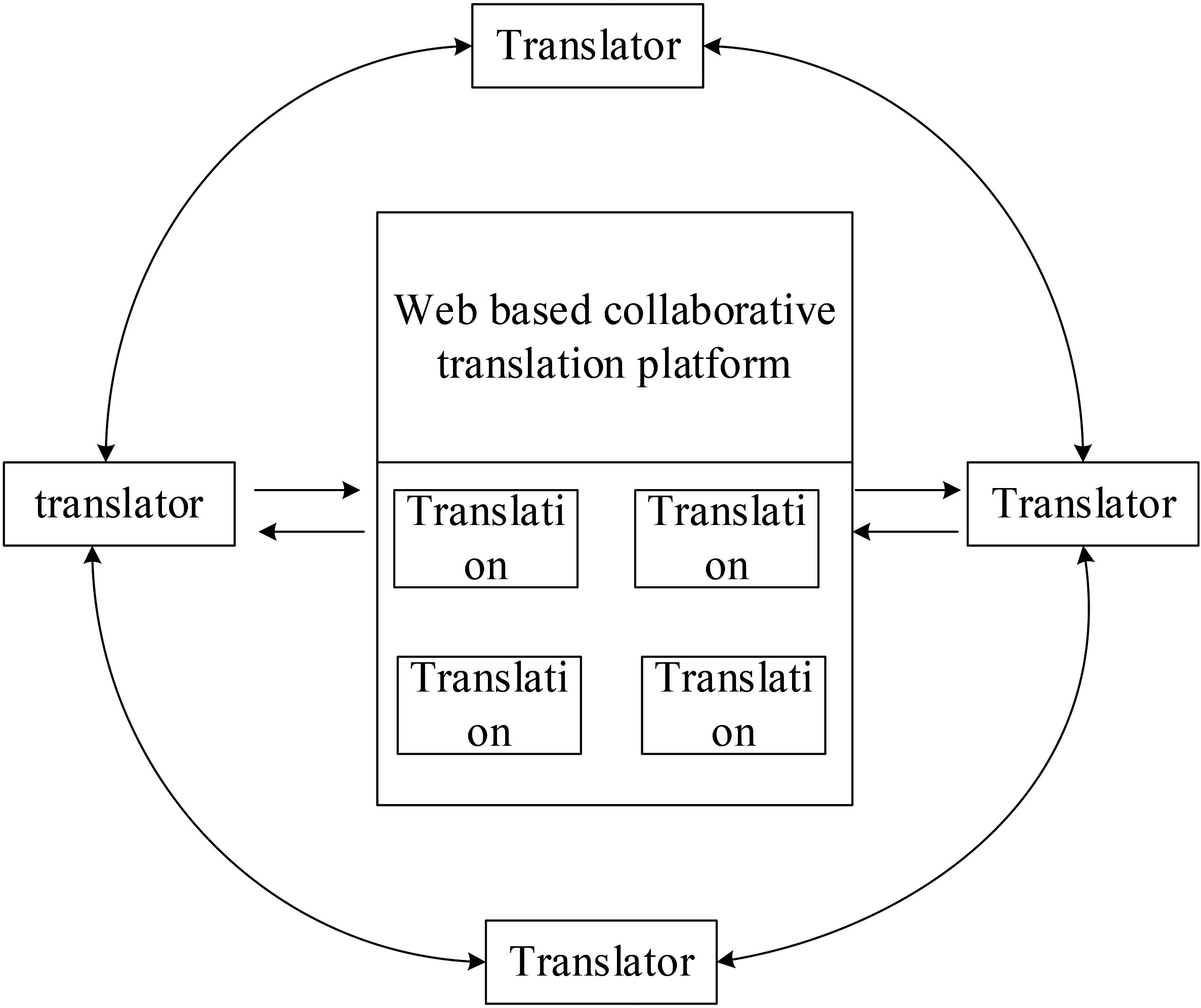
The knowledge base is divided into local data and network data, and some common templates are put in the local database to improve the search speed. However, the local database can only store a small part of the huge knowledge base, and a large amount of data needs to be obtained from the network. When translating, first search from the local knowledge base, and then search from the network [22, 23]. If the content to be translated is the same as the existing translation template, the results will be returned directly. If there is no same template, the search results will be ranked according to the possibility, and finally choose the translation method with the highest possibility as the formal translation method. Based on this, the translation process based on the knowledge base will be carried out Optimization, as shown in Fig. 6.
Optimization of translation process based on knowledge base.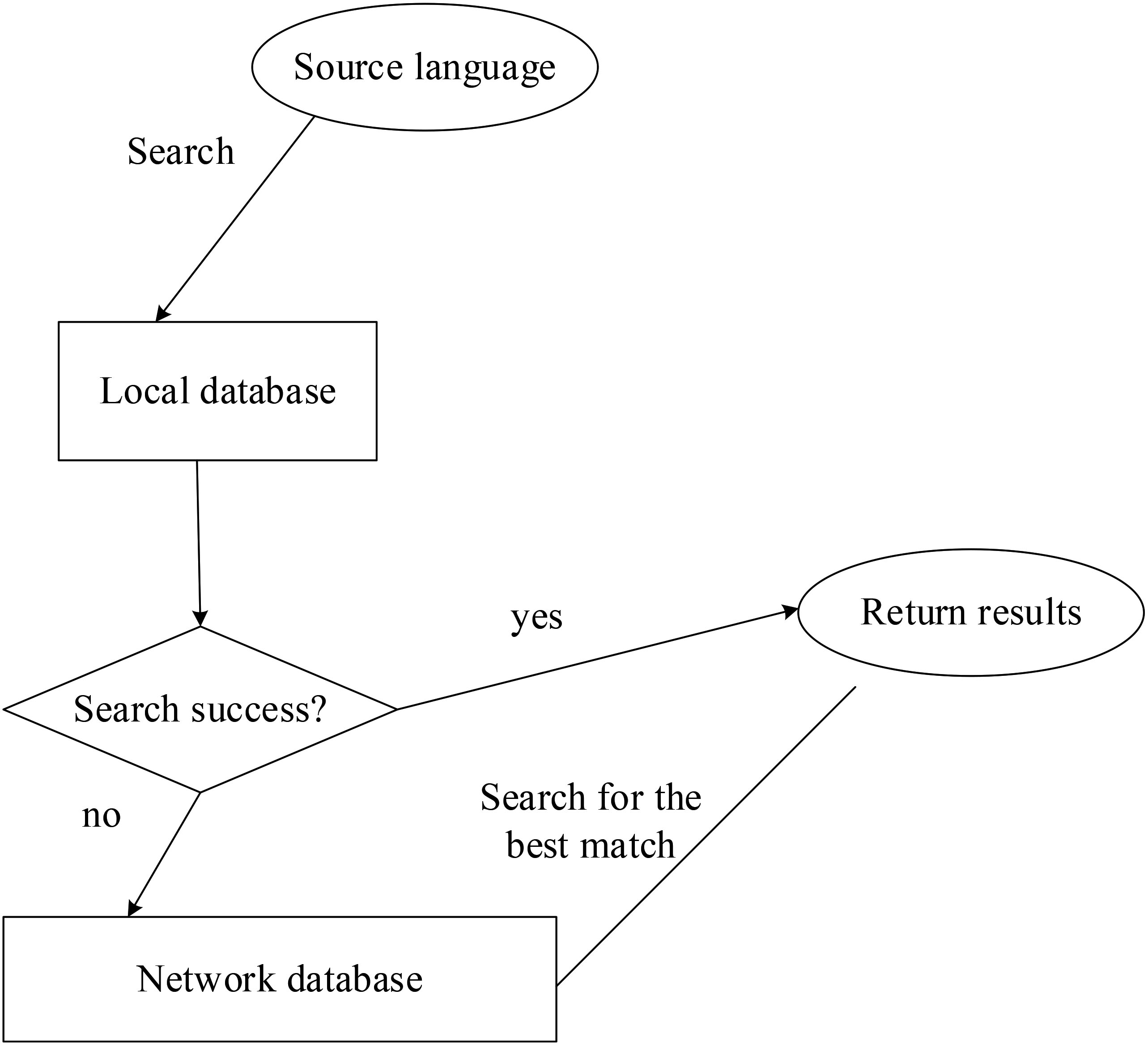
In computer programming, translation is widely used and important. According to the different amount of translation records processed by them, AI machine translation and external translation are two major parts of translation. Among them, the most widely used artificial intelligence machine translation, which stores the data to be arranged completely in the memory, and then translates according to their own translation rules, is suitable for the element sequence with a small amount of data. Translation can be divided into direct insertion translation, Hill translation, simple selection translation, heap translation, bubble translation, fast translation, merge translation and cardinal translation. These translation algorithms can translate data or records to achieve the effect of easy to find, but the actual data processing method of each translation algorithm is not the same. Direct insertion translation is a binary sequence to be translated, forming a pattern of ordered table and unordered table. The initial state is that no element is in the ordered table, and all elements are placed in another table. The data that can be inserted into the ordered table is the first element in the unordered table during each scan, and then the ordered table is reordered until the unordered table is empty complete.
In the process of designing the computer-aided translation system for English communication language, first of all, simply select the translation, select the number with the minimum (large) key value from the data, and put it in the first position, then select the maximum value from the data except the arranged number, and put this element in the back position of the previously selected element, and cycle until the full formation of the existing system Sequence. Bubble translation compares the key values of every two adjacent records in the data. When comparing each time, the condition that two elements need to be exchanged is that when the translation condition is opposite to the required translation condition, it will repeat until the sequence is in order. On this basis, the data to be arranged is divided into groups, and the elements in the same group are separated by multiple before translation. Each group forms an ordered sequence according to the principle of insertion translation. After each group is ordered, the second increment is taken as the basis of grouping and each group is inserted into translation. When the last increment is taken, all data are inserted into translation. The main algorithm steps of translating basic words of compound words into Chinese are as follows.
The formula calculates the conditional probability of context words of a word, and the variable
Where
Where:
In the above formula,
In order to ensure the effectiveness of the intelligent research of English language translation based on the grey clustering evaluation algorithm, the simulation experiment was carried out. In the process of the experiment, different English translations are taken as the experimental objects, and the translation accuracy and translation response time are simulated. The quantity and difficulty of English translation are simulated. In order to ensure the effectiveness of the experiment, the conventional English translation research method is used as the comparison object, and the results of the two simulation experiments are compared. In order to investigate the distribution of syntactic equivalent pairs, we put statistics on the number and length of syntactic equivalent pairs in the experiment. In the table, we give the statistical results of the number of syntactic equivalent pairs. Based on the above analysis process, combined with Figs 1 and 2, the setting is as follows: The first line is the average length of the extended reference translation. The second is the number of all syntactic nodes contained in the syntactic structure of the behavioral reference translation. The third is the number of syntactic equivalent pairs in the syntactic structure of behavioral reference translation. The fourth is the average number of syntactic nodes in each reference translation. Fifth, in the syntactic structure of the behavioral reference translation, the average number of nodes in the syntactic equivalent pairs contained in each reference translation.
Node statistics of reference translation syntax tree
Node statistics of reference translation syntax tree
Based on the statistical results of Table 2, the similarity ratio of N groups of words between the translated version and the reference translation is calculated. Its values range from 0.0 to 1.0. If two sentences match perfectly, value is 1.0. On the contrary, if two sentences do not match, bleu is 0.0. Therefore, the closer to 1.0, the higher the translation quality and the more accurate the interaction.
Comparison of operation accuracy of translation system
By using different systems to translate the three test samples, it is concluded that the bleu index value of the designed system is larger and the translation speed is faster, the translation accuracy of the proposed English translation research method is 25.33% higher than that of the English translation research method. The designed system solves the lag and error problems of the current translation system and improves the interaction between users. In this paper, two different methods of English translation research are used to analyze the changes in translation accuracy in the simulated environment. The test results are shown in Table 3.
Through the arithmetic mean value processing of the proposed English translation research method and the conventional English translation research method, it is concluded that the translation accuracy of the proposed English translation research method is higher than that of the English translation research method. During the experiment, two different English translation research methods was also used to analyze the change of translation response time in the simulated environment. The comparison curve of test results is shown in Fig. 7.
Comparison of response time of translation system.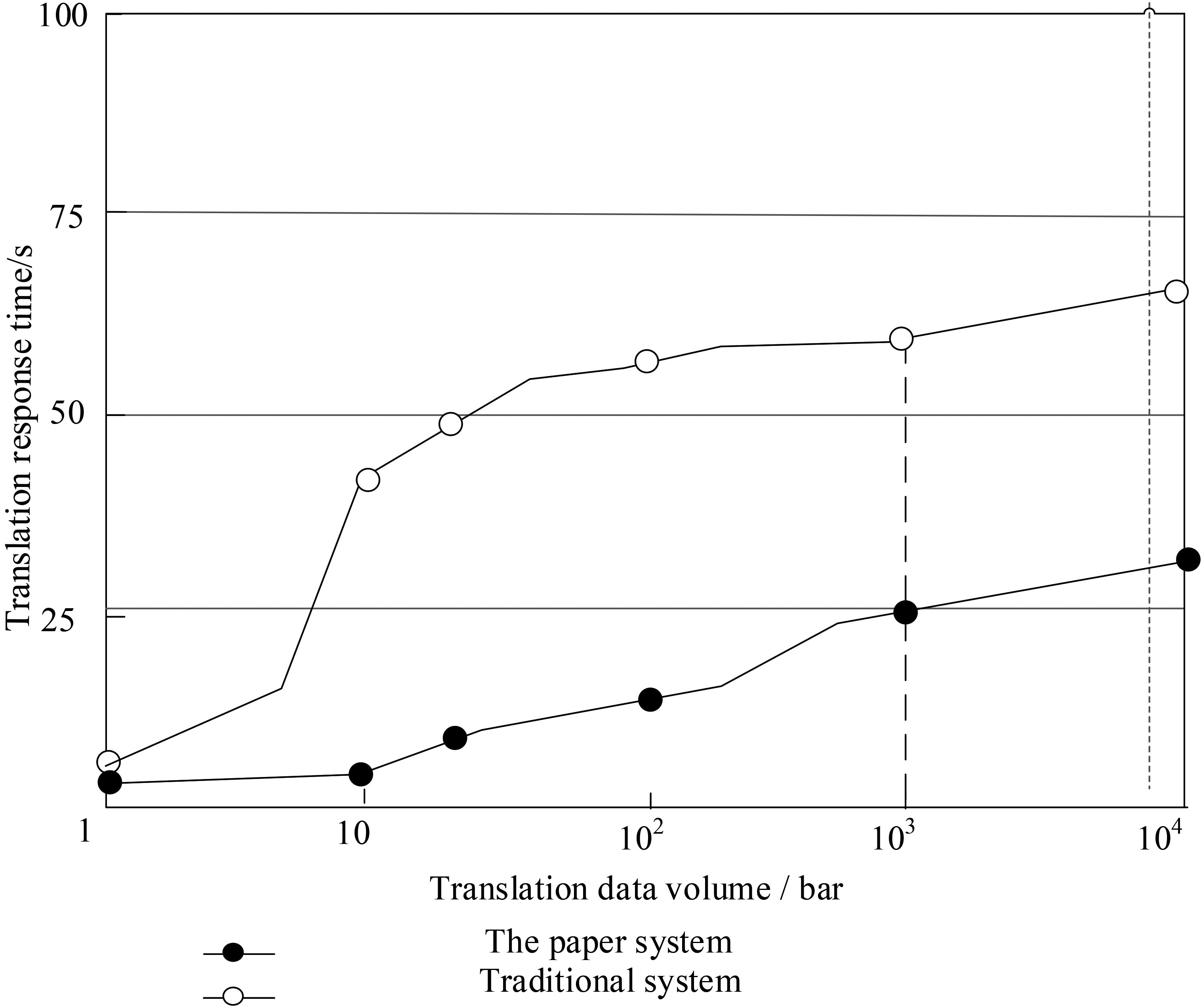
Compared with the traditional translation system, in the same environment, the corresponding speed of the proposed system is significantly faster, and the amount of translation information processing is also significantly increased. The translation response time of the designed system not more than 50 s. Therefore, it is proved that the gray clustering evaluation based English communication language computer-aided translation system is feasible. The language computer aided translation system has high effectiveness in practical application and fully meets the research requirements.
The traditional language translation system is mainly based on the lexical structure analysis method for deduction, which has the problem of poor standardization of translation results, which leads to the inherent defects of this translation method. Based on this, this paper designs the computer-aided translation system of English communication language based on grey clustering evaluation, explains the principle of grey clustering evaluation in detail, and proves it through experiments. Compared with the traditional translation method based on lexical structure analysis, this method has many advantages.
In the future research, we should focus on the proportion of the total number of verbs in the total number of verbs and adjectives in the process of English translation, so as to make the translation results more targeted.