
Abstract
Augmented reality is currently a research hotspot in the field of computer vision and computer graphics, and its applications are becoming more and more extensive. One of its key technologies is the three-dimensional registration of virtual objects. Three-dimensional registration requires accurate camera pose estimation and scene three-dimensional reconstruction. Therefore, this paper studies the 3D registration based on visual SLAM, and mainly contributes the following three aspects. (1) A dense matching method based on a depth camera is proposed, which can be well applied to scenes where the camera moves fast or rotates strongly, such as augmented reality. (2) A dense reconstruction method based on Voxel Hashing is designed, which alleviates the low computational efficiency and low precision of the existing RGB-D SLAM method. (3) A simple augmented reality system was designed to verify the effects of the registration and fusion of virtual objects. Experiments show that compared with the state-of-the-art methods, the algorithm proposed in this paper generates a more refined and smooth reconstructed model, and the virtual-real fusion effect based on this model is also more realistic.
Introduction
With the increasing popularity of mobile and wearable devices, augmented reality has received unprecedented attention in recent years and has become a research hotspot in the field of computer vision and computer graphics. One of the difficulties of augmented reality is how to achieve stable and accurate 3D registration of virtual objects [1]. The premise to solve the problem is how to realize accurate camera pose estimation and real-time three-dimensional reconstruction. This happens to be the problem that the Simultaneous Localization and Mapping (SLAM) system is committed to solving. It refers to construct a digital model of the environment during the movement process, and at the same time estimate its own movement with specific sensors, without prior knowledge of the environment [2].
The sensors of the SLAM system are generally LIDAR, inertial sensor (IMU) and camera, the SLAM with the camera as the main data acquisition device is called visual SLAM (V-SLAM). Traditional V-SLAM can be divided into monocular, binocular and depth camera (RGB-D) SLAM according to different camera types and working methods. The V-SLAM system should solve two core problems which are camera positioning and map construction. Since depth cameras such as Microsoft Kinect V2 have become affordable commodity in recent years, they can easily measure the distance between the object and the camera (ie depth) with the help of infrared structured light or Time-of-Flight. Compared with the need to calculate the object depth with the help of algorithms in binocular cameras, the depth camera can save a lot of resources [3]. Therefore, the research and application of SLAM system based on RGB-D cameras have received more and more attention, and many research results have published (such as KinectFusion, Kintinuous, ElasticFusion, DVO-SLAM, etc.). However, the existing algorithms cannot meet the requirements well in terms of robustness and accuracy when the camera has rapid motion and violent rotation or the texture of scene is relatively poor.
This paper mainly studies the technology of camera localization and real-time 3D reconstruction based on V-SLAM, and proposes a tracking method based on RGB-D dense matching (Direct Method), which includes pose estimation and loop closure. Then, based on the Voxel Hashing technology [46], the dense 3D model is reconstructed and applied to the augmented reality system to realize the 3D registration. Compared with traditional algorithms, the algorithm proposed can effectively improve the accuracy of 3D registration and achieve a better fusion effect.
The main contributions of this paper are as follows.
A dense matching method based on depth camera is proposed, which can be well applied to scenes with fast camera movement or severe rotation such as augmented reality. A dense reconstruction method based on Voxel Hashing is designed, which alleviates the low computational efficiency and low precision of the existing RGB-D SLAM reconstruction method. A simple augmented reality system is designed to verify the registration and fusion of virtual objects in dense scenes. Experiments show that the algorithm proposed in this paper can achieve a more realistic fusion effect.
V-SLAM and augmented reality have been deeply studied in their respective fields. In recent years, due to the improvement of hardware and algorithms, the accuracy of camera pose estimation and the quality of real-time 3D reconstruction have been gradually improved which all provide better technical support for 3D registration. Recently, the research in the two fields shows a trend of crossing and driving each other. This section analyzes the impressive results of the two fields, and discusses the pros and cons of each.
Visual SLAM
Visual SLAM uses a camera as a sensor, which has the advantages of small size, low cost and rich information. A conventional classical frame structure of the system is shown in Fig. 1.
V-SLAM structure.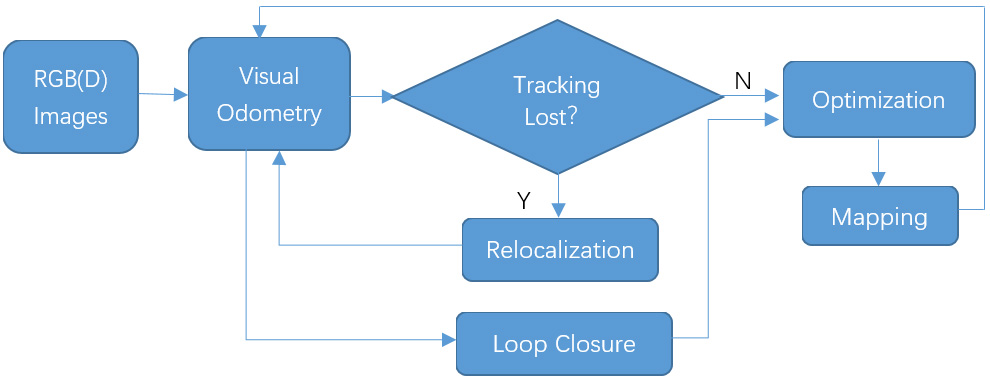
The function of the visual odometry is to estimate the relative pose transformation of the camera using two frames. If the transformation matrix can be obtained, the correct tracking of the camera can be realized. From a global perspective, since the visual odometry will accumulate errors during the tracking process, optimization is required for error suppression, and finally the map is updated with the estimated camera pose. During the tracking process, the camera may move violently and cause the tracking to be lost, so relocalization is generally required. In the optimization process, loop closure detection will be performed to reduce the amount of calculations and improve the optimization effect.
Early V-SLAM mostly adopted a filter-based approach, the representatives are MonoSLAM [2] and MSCKF [4]. MonoSLAM is a representative work of filter-based SLAM, in which the motion parameters of the camera and the 3D position of the landmark are jointly expressed as a probability state. For each frame, EKF (Extended Kalman Filter) is used to predict and update the joint state. The biggest disadvantage of MonoSLAM is the O (N3) running time (N is the number of landmarks), which limits its scalability, resulting that it can only be applied to a relatively small space containing a small number of landmarks (about a few hundred). In addition, the use of EKF can easily cause quickly error accumulation. Therefore, MonoSLAM can only handle small scenes. To solve the problem of error accumulation, MSCKF introduces IMU (Inertial Measurement Unit) data as input data, and uses a sliding window to reduce error It discards the constraints between the camera and the map points when calculating, and only considers the camera position, what effectively reduces the amount of calculation, however, it only discusses the monocular case.
Due to the noise, the equations of the motion and the observation must not be accurate. Therefore, instead of assuming that the data must conform to the equation, it is better to optimize the noisy data to obtain a relatively accurate state estimation. With the development of nonlinear optimization technology, more and more V-SLAM systems begin to adopt iterative optimization as backend. Visual odometry can be divided into sparse method and dense method according to how many pixels are used.
The typical representatives of the sparse method are the PTAM and ORB-SLAM series. PTAM [5] decouples the classic architecture of V-SLAM. Specifically, it divides tracking and mapping and allocates different threads to enable them to be executed in parallel, so that the system can run in real time. PTAM is the first to use Bundle Adjustment to optimize both the pose and map. Although the system is divided into two threads, the back-end optimization takes longer time to run than the front-end. Based on PTAM, researchers have successively made some improvement. For example, in 2015, Mur-Artal et al. proposed the ORB-SLAM [6], which used ORB features characterized by (1) the faster extraction and rotation invariance; (2) optimizing the global pose by constructing a pose map; (3) improving the key frame selection scheme and map updating method, and deleting redundant key frames and map points to ensure the accuracy of pose estimation and the scale of the optimization parameters will not grow too fast.
The principle of the feature point matching is to estimate the pose between frames by calculating and minimizing the reprojection error, but some problems such as bigger time cost and mismatching exists. The method is also sensitive to the texture of image and the rapid movement of the camera, etc., so some scholars have proposed to use all pixels in the image to help estimate the pose, that is, the direct method.
The direct method minimizes the pixel metric error of the two frames to realize the pose estimation without extracting and matching feature points, so there is no problem of mismatching as well as no strict constraint on the texture of the image. DTAM [7] which proposed by Newcombe et al. in 2011 used a monocular camera to realize dense visual odometry and reconstructed the surface of the scene, but it requires parallel computing with the help of GPU. LSD-SLAM [8] proposed by Engel et al. in 2014 does not require the computing power of the GPU. It minimizes the error of the region with large gradients in the image, making the algorithm portable to mobile platforms. Forster et al. proposed SVO [9] in 2016, which only extracts the key points in the image, omits the calculation of feature descriptors, and uses the direct method to match the key points, which can significantly accelerate the calculation. Although the direct method has certain advantages in the use of overall information, there are still some problems. The reason is that the direct method assumes that the intensity of the same point in the image is constant at different moments and different observation angles, and this assumption is violated easily by factors such as light changes, exposure time, etc. In addition, it can only handle situations where the camera movement is small.
Monocular V-SLAM has scale ambiguity. Generally, it is necessary to estimate the depth information of the feature points through triangulation. The RGB-D camera represented by the Kinect series can simultaneously obtain the color image and the depth image of the scene, which saves the time-consuming depth estimation, and there is basically no problem of scale drift, so many V-SLAM systems use RGB-D images as input. Earlier to propose the use of RGB-D cameras for real-time indoor 3D reconstruction is Peter Henry et al. of the University of Washington [10], who used surfels to represent 3D models [11]. Pose is estimated based on sparse feature and dense ICP (Iterative Closest Point), TORO tools are used for back-end optimization [12, 13, 14, 15]. Lourakis et al. released a software package called Sparse Bundle Adjustment [16] in 2010, which achieved faster back-end optimization. Endres et al. [17] used RGB-D cameras to construct a 3D map. In addition, the article also compared and analyzed the performance of using different feature such as SIFT [18], SURF [19] and ORB to match between frames and the influence of the number of feature points on the estimation accuracy, the g2o toolkit is used for back-end optimization [20].
In addition to the above-mentioned RGB-D SLAM using feature points, two frames of RGB-D can be directly matched, and the pose between two adjacent frames can be estimated by minimizing intensity error and depth error [21, 22]. KinectFusion [23] was proposed by Microsoft Research Institute in 2011. This algorithm constructs a volume model for the local space, and uses the ICP algorithm to match the depth image with the built model to estimate pose, and at the same time, it reconstructs indoor scenes. However, the algorithm is only limited to indoor-sized spaces, and only the depth information is used in the calculation, and it does not provide a loop closure detection for global optimization. Based on KinectFusion, Whelan et al. expanded the size of reconstruction, adding color information and loop closure detection [24, 25, 26, 27].
Augmented reality is a technology that integrates virtual objects into the real environment and can achieve seamless integration, rendering and interaction. With the technology, users can better perceive and interact with things in the real environment. This term first appeared in the work of Caudell et al. from Boeing Company [28]. Azuma defines the characteristics of augmented reality as the combination of virtual and real, real-time interaction and three-dimensional registration [29]. At present, augmented reality has been widely used in medical, entertainment, industry, education and other domains. 3D registration is one of the core technologies of the augmented reality system. With the maturity of augmented reality hardware and the expansion of application fields, the vision-based 3D registration has received more attention and development due to its strong versatility, high precision, and low cost [30]. Vision-based 3D registration can be divided into artificial identification registration, natural feature registration and model-based registration according to different implementation methods [31].
The method based on artificial identification usually puts the specific identification in the real environment, uses the camera to recognize its position, then compares it with the matching identification to estimate the pose and calibrate the position of the virtual object through coordinate conversion which will be finally fused in real scenes [32]. The most famous libraries are ARToolkit [33] and ARTag [34]. However, the registration based on artificial identification can only be applied to scenarios where the identification has been arranged in advance, which seriously affects the scope of application of augmented reality, and is therefore not suitable for large-scale outdoor environments.
The process of registration based on natural feature is to track the natural features in the image, use the detected targets to calculate the camera pose, and then calibrate of the objects through the conversion of the natural feature coordinates and the camera pose [35]. Commonly used feature operators include SIFT [18], SURF [19], FAST [36], ORB [37] and BRISK [38]. The registration does not need to place an identification in the real environment, but some algorithms have problems such as low running speed, low matching accuracy, and scale ambiguity during the registration process.
The model-based 3D registration generally uses the tracking object based on distinguishable features, and realizes the prediction of the camera pose through the external features of the model By converting the 3D coordinates of the model to the 2D image coordinates to augment the reality [39]. Vial et al. proposed a real-time model-based line tracking method which minimizes the distance between the sampling point on the projection line of a given 3D model and the corresponding maximum value of the image gradient to estimate the camera pose [40]. Combining edge information, Reitmayr et al. proposed a hybrid tracking system based on textured 3D model, which dynamically determines the camera pose and completes registration at runtime [41]. This kind of method has limitations in tracking region and high computational cost.
Due to the complexity of the real environment, the traditional visual SLAM does not perform well. For example, when a novice is using a mobile device to experience AR application, he probably does not have any prior knowledge of how to carefully operate the mobile device to obtain a good AR experience. In this process, it is easy to move quickly and rotate violently, and these actions even pose a huge challenge to the most advanced visual SLAM system.
Framework overview
This paper uses the dense matching based on RGB-D image in the visual odometry, and uses the color and depth information error metrics when optimization in the back-end. At the same time, when the camera loops back, the depth map of the key frame is constructed, and the model is updated accordingly, so as to construct a globally consistent 3D model. The algorithm flow is shown in Fig. 2.
Algorithm flow.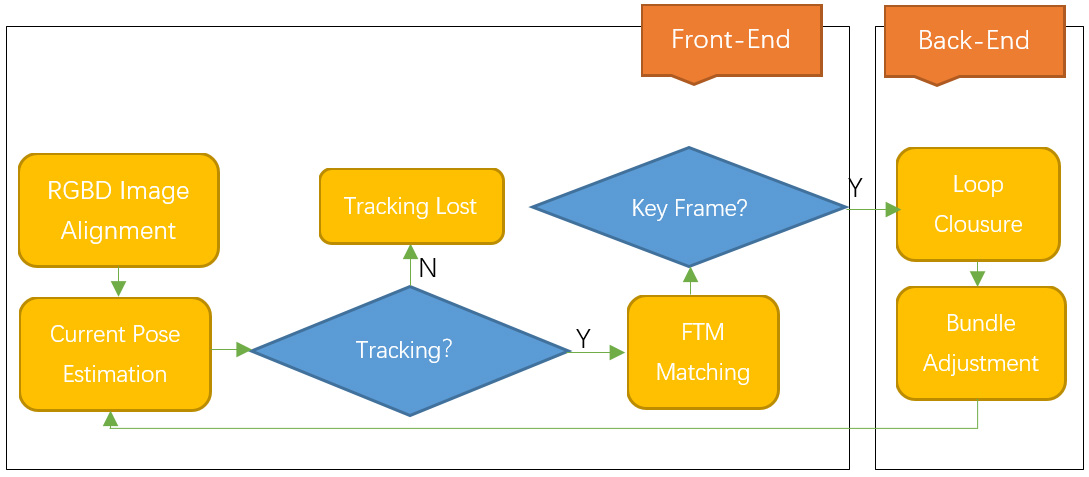
Both the pose estimation and map construction of this system need to be accelerated by GPU. Since the goal of map construction is to be applied to augmented reality, the localization algorithm is required to be more efficient to save time for the construction of dense models, that is, localization is mainly for mapping services, and high-quality maps in turn optimize localization accuracy. To make full use of the depth and color information, the direct method is used for pose estimation. In the pose estimation and optimization stage we refer to DVO [44, 45] for the algorithm implementation which detailed in Section 4. The map is also constructed by the dense method, and we adopt the method based on TSDF. The TSDF-based model is an implicit surface representation. For each point
At time
However, due to the error of the camera itself and illumination difference, Eq. (1) cannot be strictly established. Therefore, the optimal estimation of the pose can be achieved by minimizing the intensity error. In addition to color, the depth information collected at a certain point in the space can also be compared with its reprojection. If the pose is accurate enough, the depth error should be close to zero.
Assume that a point
To recover
where
The movement of the camera can be seen as a continuous translation or rotation. Theoretically, the motion of the camera can be represented by a transformation matrix T called a special Euclidean group SE (3).
Where
Where the symbol
The pixels in the previous image are restored, and the coordinates in the new image obtained by re-projecting under the new camera pose
In dense matching, Eq. (7) is used to define the intensity error and depth error of a single pixel as follows.
We use the weighted least squares method which is same as [45] to iteratively estimate the pose. The objective function to be optimized is as follows.
Where
The above is the complete process of pose estimation by minimizing the intensity error and depth error of the RGB-D image.
Because the dense 3D model can effectively solve the occlusion problem of the virtual object and the real scene faced with the monocular camera, realize more natural registration of virtual objects, and improve the user experience, so this paper uses a dense map to represent the 3D structure of the environment. In order to improve the speed of surface reconstruction and reduce the memory footprint, we modified the voxel hashing provided by [46], changing the parameters of the hash function, the size of the bucket, and the conflict handling method [47]. We use Eq. (12) to calculate the address of a voxel block.
Where
In the experiment, the size of our reconstructed space is about 3 m
After setting the data structure, in order to save storage, the algorithm has two constraints. One is to divide the voxel block only for the scene in the view frustum, eliminating most of the current invisible scenes; the other is to only divide the voxel block within the truncated distance. The detail is to synchronously emit a light beam for each pixel from the optical center, and determine the block to be stored by the TSDF value.
After the voxel block allocation, the GPU accesses all entries in the hash table in parallel, identifies that occupied and visible, and marks the corresponding element in the identification array (initialized to 0) as 1 according to the index, and then uses parallel prefix sum [48] to scan the array. If an entry in the hash table meets the condition, it is accumulated on the basis of the previous element value by what forming an index array. The position where the number changes in the index array is the voxel block to be selected. The GPU is used to update the TSDF value, weight and color of each voxel in voxel block.
The map construction using the above method is equivalent to the construction of the surface of the object in space. When constructing the model surface, the TSDF zero level set can be extracted by ray casting [49], and the world coordinates can be obtained by the trilinear interpolation, finally the scene are rendered.
Voxel hashing.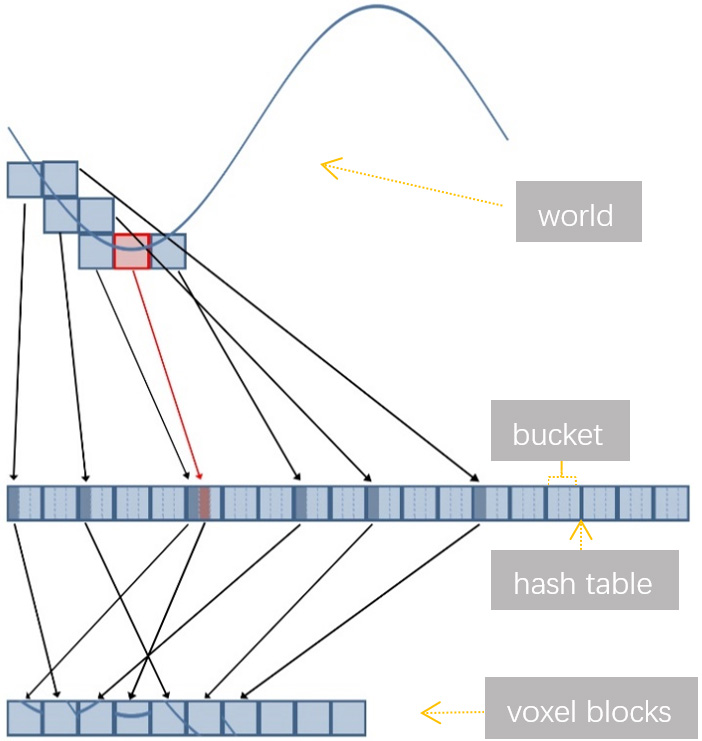
Loop closure detection generally refers to judging whether the robot has returned to a place it has been before based on the feedback of the sensor in the SLAM. If the sensor is mainly a camera, the image is used to determine whether the current frame has a corresponding description in the previous path. Loop closure can be used to adjust the estimated camera pose which can effectively suppress error accumulation. If the global pose can be corrected, a consistent map can be obtained. In the paper, Bag-of-Words is used to represent the visual features to realize image classification and similarity detection.
To improve the accuracy of closed-loop detection, the whole closed-loop detection process is divided into three steps. The first step is keyframe retrieval. For the current frame, the Bag-of-Words vector is constructed and matched with all key frames in the existing database. The key frame with the highest similarity Bag-of-Words vector is selected and the distance
3D registration
The fusion effect of virtual and real scene depends on the registration of the virtual object. At present, most of augmented reality systems based on monocular cameras simply superimpose virtual objects on real scene due to lack of depth information [50], and cannot show the occlusion of real objects on virtual objects. Since we use an RGB-D camera, the occlusion of virtual and real objects can be better controlled through the dense depth map. We have implemented a simple augmented reality system. After completing the reconstruction of the 3D scene, the method of layered rendering of virtual and real objects are used which show the occlusion effect naturally [42], see the experimental part for details.
According to the estimated camera pose and dense reconstruction model, we use OpenGL to adjust the pose of the controller and the cup 3D model, and the virtual object was superimposed on the corresponding position of the windowsill and desktop through rotation and translation. Then the projection transformation and view transformation were carried out to create a 2D image of the 3D scene.
Experiments
In order to verify the feasibility and effectiveness of the algorithm designed in the paper, we conducted two sets of experiments in an indoor environment. The parameters of the experimental equipment are as follows: Kinect V2 RGB-D camera, Intel i9 9900Kprocessor, 32G DDR4 memory, NVidia RTX 2080Ti graphics card, and OpenGL library. We take Microsoft Visual Studio 2013 IDE as the development and testing tool, and the language is C
Dense reconstruction
In order to analyze the performance and model quality of the reconstruction, we compared our system with KinectFusion, which also uses TSDF for voxel representation. The depth range was set as 0.5 m
Living reconstruction scenes.
Figure 5 shows the scenes rendered by the two algorithms (width: 4 m, height: 2.5 m, depth: 3 m), with a scan period of 45 seconds. The left image is still captured by KinectFusion, and the right is ours. Both methods can maximize the integrity of the model in the scene, and the surfaces of the objects reconstructed by the two algorithms are relatively smooth. To further compare the details of the reconstruction, the algorithm in this paper uses the hash table data structure and GPU streaming processing, which can fully utilize the memory, so the gap between the radiators is obvious, seeing Fig. 5b, the edges and corners of the object are more distinct, and the details of the reconstruction are more complete and clear, while Fig. 5a has lots of overlapped area which are filled with surface redundant.
Reconstruction senses after scanning.
We designed a simple augmented reality system that supports users to fuse virtual objects to the scene. Since the system is based on the camera pose obtained by the dense 3D model, it can calculate the relatively complete and accurate depth information of each frame. During the rendering process, the distance relationship between the virtual object and the real scene can be obtained, so that it can effectively dealing with the occlusion, producing a better visual effect of fusion of virtual and real. Figure 6 shows the screenshots of fusing the two virtual objects of the kettle and the controller into the real scene. It can be seen that the controller (with glass and window as the fulcrum) in the left image and the cup in the right image have achieved a more realistic occlusion effect, and the accuracy of the 3D registration meets the requirements of scene integration and consistency. We define the registration accuracy as the ratio of the area where virtual and real are fused to the corresponding area of the image captured with real objects. Comparing the effect of the algorithm in the paper with the fusion results with PTAM, the registration accuracy of our algorithm is improved by about 4.60%.
Fusion senses.
We mainly study dense matching for estimating camera pose, dense reconstruction of scenes based on voxel hashing, global optimization based on Bag-of-Words and graph optimization methods, and simple virtual and real scene fusion algorithms with RGB-D camera. Through quantitative and qualitative evaluation of experiments, the system realizes pose estimation and real-time dense 3D reconstruction for indoor environment. Compared with the existing algorithms, the reconstruction effect of this algorithm is more refined and smooth, the accuracy of the 3D registration of virtual objects is increased by about 4.60%, but for outdoor scenes, due to the limitations of the sensor itself, it is not so robust. In addition, when the camera is moving fast, the system generate ghost image and even lost the tracking which will be need further research in the future.
Footnotes
Acknowledgments
This research was jointly supported by the Jilin Provincial Science and Technology Development Program (20190201265JC) and CCIT Science and Technology Project (320200011).