
Abstract
As the technical demand-supply text information increases rapidly in electric power technology transfer, traditional matching methods could no longer meet the need. To solve this problem, this paper proposed a new technical demand-supply matching method based on electric power technical field feature. First, the improved TF-IDF algorithm was used to extract technical field feature, then scientific and technological achievements with higher relevancy were retrieved based on technical field feature to build a background library of electric power technological achievements, and the matching degree of electric power technological achievements based on word vector was used to verify the matching efficiency of this method. We adopted the China smart grid technical transaction service platform and the text message of electric power technical demand and technological achievements on Keyi net for application, and the results indicate this method has raised the matching efficiency by 23.4% compared to traditional methods. In this paper, a new idea of taking technical field feature as the demand-supply matching basis of electric power technology transfer platform was proposed, which opens a new perspective for the research of demand-supply matching efficiency on electric power technology transfer platform, helps to promote the matching efficiency of technical demand and technological achievements, and further raises the success rate of electric power technology transfer.
Introduction
With the development of science and technology and the continuous emergence of scientific and technological achievements, technology transfer has become one of the hot topics of science and technology management work in China [1], and a lot of online technology transfer platforms have sprung up. Due to obvious non-structural characteristics of technical demand and technological achievement information as well as too colloquial description of technical demand text, technical demands are very difficult to match with technological achievements, the searching cost has been raised [2], the demand and supply parties are hard to dock with each other, and many potential technology transfer opportunities can’t be discovered by people [3]. Till July 2020, the online technology transaction platform of Keyi net have released a total of 287,764 scientific and technological achievements, including 11,070 signed programs which occupy less than 4% of total scientific and technological achievements. Numerous scientific and technological achievements can’t be transferred for application, and technical needs can’t find corresponding technological achievements they want. If only relying on technical field as retrieval word for demand-supply matching, there will be a huge amount of work to do, significantly increasing the time to match technical demand with supply. Therefore, regarding the non-structural text information of technical demand and technological achievements that is described with natural language, studying the matching model and method of technical demand-supply text has important practical significance to promote the docking of technical demand and supply parties, to guide technical research direction, and to improve success rate of technology transfer. Electric power industry featured by capital-intensive and technology-intensive has played an important role in national economy, and electric power technology transfer becomes a vital driving force to the development of electric power industry. This paper will study the demand-supply matching problem in electric power technology transfer, expecting to increase the transfer efficiency.
The early study of technical demand-supply matching mainly focused on matching preference and matching decision,etc. In 1989, Brownlie et al. [4] discovered the preference relation between technical demand and product research and development, thus put forward the management idea of demand-supply matching; in view of the bilateral matching preference order problem, Liang et al. [5] established four preference satisfaction oriented decision models and finally obtained the optimal demand-supply matching scheme; according to different preferences of demander and supplier in the market, Klerkx et al. [6] proposed the innovative intermediary to meet the need of both parties. For the problems in matching decision, Le [7] transformed intuitive fuzzy set into score and matching matrix and solved this model to prove the feasibility of this matching decision; on basis of the study of intuitive fuzzy set theory, Yang et al. [8] applied this theory in the transformation of scientific and technological achievements, and built the matching decision model based on intuitive fuzzy set, providing an idea for solving the matching problem in the transformation of scientific and technological achievements. Based on the study of matching preference and matching decision, Kong et al. [9] combined the two and provided a matching decision model based on demander’s and supplier’s preference, so as to obtain the most stable matching scheme.
As the data size of technical demand-supply text increases, traditional keyword-based technical demand-supply matching method couldn’t cope with the retrieval information redundancy under large-scale data, thus studying the word frequency and semantic similarity with training corpus becomes a focus of the study of technical demand-supply matching method. Wu et al. [10] proposed a new method based on Wikipedia’s semantic matching to improve matching accuracy. Yang et al. [11] used vector space model and TF-IDF algorithm to calculate the similarity of technical demand-supply text. For better reflecting the relation between keywords and context, the matching methods using positional relation of keywords to determine text similarity emerge. Xie et al. [12] designed a TextRank algorithm based thesis recommendation system, which calculated the cosine vector of keywords for similarity matching; Benedetti et al. [13] raised a knowledge-based inter-document similarity computing technology to effectively calculate inter-document similarity; on the basis of studying TF-IDF and TextRank algorithms, Yan et al. [14] put forward a graph-based keyword extraction method to solve the corpus dependency problem.
Word vector based semantic similarity matching effectively solve the polysemy issue, but these methods merely take the inter-word up-down structural relation rather than deeply understand the text semanteme. Ferreira and George [15] brought forward an interpretation identification system combining syntactic and semantic similarity, which expressed every pair of sentences as a combination of different similarity measurement, and proved the accuracy of this system in sentence interpretation identification by experiment; in order to fully excavate such inter-word properties as correlation unit and type, Jiang et al. [16] proposed a neural network based word vector model, which trained the corpus with inter-word grammar and context relation and eventually verified model feasibility. Wang et al. [17] put forward a theme model based text similarity calculation method, which built a theme model for corpus, excavated the inter-word similarity relation, and finally obtained the text features, for figuring out the similarity between texts; based on traditional theme model, Li [18] put forward a SL-LDA-based field feature acquisition method by introducing the word frequency features, and used this model to extract the “theme-phase” of the context for extracting keywords. In 2013, Google developed a Word2Vec model able to produce word vector, which was used for studying feature extraction [19], emotion analysis [20], text classification [21], text similarity [22], etc. Shun Yao et al. investigated the BM25 model [23] using probability model to score and rank the matching results, which was widely applied to the scoring and ranking of matching relevance.
To solve the low efficiency in matching the power enterprises’ technical demand with the supply of scientific and technological achievements, this article proposed to take electric power technical field features as the basis of demand-supply matching, and extract the electric power technical field feature to build a background library of scientific and technological achievements. By measuring the matching degree of technical field feature and the scientific and technological achievements background library, it is validated that the technical demand-supply matching method based on electric power technical field feature has significant effect on promoting technical demand-supply matching efficiency.
Feature-based electric power technical online demand-supply matching method
The idea of the proposed feature-based electric power technical online demand-supply matching method is: first, extract the technical field feature to build an electric power technical field feature set; then, take “China smart grid technical transaction service platform” (
The technical requirements of electric power enterprises refer to the specific needs of electric power enterprises for a certain technology that is beneficial to the development of enterprises in the process of production and operation, which can be called technical requirements of electric power enterprises. Scientific and technological achievements refer to the achievements with practical value produced through scientific research and technological development.
Technical field feature extraction based on improved TF-IDF algorithm
Technical field feature (TFF) is a professional term on behalf of technical field which represents the features of the whole technical field, and the set of all technical field features in a technical field is called technical field feature set (TFFS).
TF-IDF is a statistical method to assess the importance of a word to a document set or one of the documents in a corpus. The importance of a word increases proportionally to the number of times it appears in the document, but decreases inversely to the frequency it appears in the corpus. If a word appears frequently in one article TF, and rarely appears in other articles, it is considered that the word or phrase has a good ability to distinguish between categories and is suitable for classification.
Improvement to TF-IDF algorithm
In traditional TF-IDF algorithm, only the word occurrence frequency and in how many texts the words have appeared have been taken into account [24, 25], resulting in slow computing speed and poor feature extraction effect.
In a text, many information can play a good role in feature extraction, for example, part of speech, the position that a word appears in a text, etc. In the technical demand-supply text, noun as a kind of words defining real entity carries more key information, so noun can be endowed with higher weight in feature extraction. In addition, the beginning and ending paragraphs of technical demand-supply text are more important than the text information of other paragraphs, so the words in these positions should also be endowed with higher weight. Based on this, the paper proposed an improved TF-IDF algorithm dividing corpus into foreground corpus and background corpus, to improve the slow calculation of word frequency, and meanwhile added related indexes such as technical field relevancy, technical field evenness, impact factor and technical field membership.
Related indexes and meanings
The paper involves multiple indexes such as technical field feature, technical field membership, etc. Here, related indexes and their meanings are introduced, as shown in Table 1.
Related indexes
Related indexes
In the improved TF-IDF algorithm, the word weight is used to represent the degree how important this word is in the context. Take a word i of a technical demand-supply context j of an electric power enterprise for example, the formula of this word’s TF value is as below:
in which,
For every word
in which,
Normally, the TF-IDF algorithm integrates the TF algorithm with IDF algorithm, then the TF-IDF value can be calculated as below:
The computing formula of its technical field relevancy is as below:
in which, the
The simplified TFR
in which,
The computing method of TFR is an improvement on TF-IDF algorithm, conforming to TF-IDF algorithm. The TFR algorithm also consists of two parts: lg(TFi,k) is the times that the word i appears in the corpus,
Technical field evenness (TFE) reflects the evenness that the words positively correlated to technical field (TFR
in which,
The impact factor
Therein:
It can be found out from above formula that, when
In practical operation, in order to reduce the time of calculating
in which,
in which,
This section improves the TF-IDF algorithm to obtain the TFR of every word, meanwhile introduces such indexes as TFE and impact factor to finally obtain the related data of TFM. Then, the TFR data of each word was ranked to pick out the TFF relevant to this technical field.
The too colloquial and non-structured description of technical demand-supply text leads to low efficiency in technical demand-supply matching and redundant matching results. As a result, for one thing, the scientific and technological achievements in technical field should be screened out to build an index database of electric power scientific and technological achievements as the scientific and technological achievements supply database; for another thing, the BM25F-based relevancy retrieval model should be used to search out the scientific and technological achievements set with high relevancy with electric power TTF from the index database of electric power scientific and technological achievements, for establishing a background library of electric power scientific and technological achievements (p).
BM25F is an improved algorithm of BM25 model. In BM25 relevancy retrieval model, the text is considered as a whole in calculating text relevancy [26, 27]. However, with the rapid development of retrieval technique, structured data gradually replaces text data, and every text is cut into multiple independent domains, for example, a webpage is cut into such domains as headline, subject term and content. The contents in different domains contribute differently to the subject, so their weights are also different, thus BM25F retrieval model was proposed. This model divides text into individuals according to domain and conducts weighted sum on the score of every word in each domain. The specific process is:
By using BM25F relevancy retrieval model, TTF is taken as query term Q(Query) to retrieve in the index database of electric power scientific and technological achievements, and the BM25F relevancy score is obtained through calculation, then the background library of electric power scientific and technological achievements (p) can be obtained according to the score. The calculation process is: first, resolve the morphemes of technical query terms Q(Query) to get the morpheme
in which,
in which,
in which,
in which,
Thus, the BM25F scoring formula is simplified as:
in which,
To verify the matching efficiency of technical demand-supply matching model based on electric power TFF, the word vector-based text matching degree was adopted to figure out the matching value. The calculation process is:
Judge the technical demand D contains TFF Remove the common portion of Build a semantic similarity matrix. Work out the semantic similarity of
in which, the
Find out the maximum of sim(
Work out the electric power technical demand-supply matching degree. The electric power technical demand-supply matching degree
in which,
Extraction of electric power TFF
Corpus establishment
The 3267 texts of technical demand or scientific and technological achievements related to electric power university and enterprise on Keyi net and China smart grid technical transaction service platform were taken as the corpus. This corpus covers 15 technical fields such as ultra-high voltage power transmission and transformation technique, high and extra-high voltage power transmission technique, high voltage direct current power transmission technique, power distribution and utilization, power grid planning and economics, so it is classified according to technical field.
Evaluation indexes
In machine learning, the common indexes used to evaluate model and algorithm are recall rate (R) and precision rate (P). But only relying on these two indexes couldn’t fully evaluate the algorithmic performance, so it is necessary to introduce the
This paper extracted 128 electric power TFF in total. Due to the limit of article length, the technical field of power distribution and utilization was taken as an example for introduction. A total of 314 technical demand texts in power distribution and utilization technical field were taken as the foreground corpus (Cf
Top ten words with the largest TFR in power distribution and utilization field
Top ten words with the largest TFR in power distribution and utilization field
Top ten words with the largest TFE in power distribution and utilization field
Top ten words with the largest TFM in power distribution and utilization field
From above results, it can be concluded:
When ranked according to TFR value, the words show higher relevancy wit power distribution and utilization technical field, that is to say, the frequency that these words appear in foreground corpus is far higher that background corpus. But several words also show lower TFE values. TFF distributes in Cf For the words with higher TFR value and those with higher TFM value, their Following the TFM values in Table 4, we obtain the TFF of power distribution and utilization field. See details in Table 5.
TFF of power distribution and utilization field
By comparing traditional TF-IDF algorithm to improved algorithm, the performance of the improved TF-IDF algorithm can be seen. See details in Figs 1 and 2.
Performance comparison of traditional and improved TF-IDF.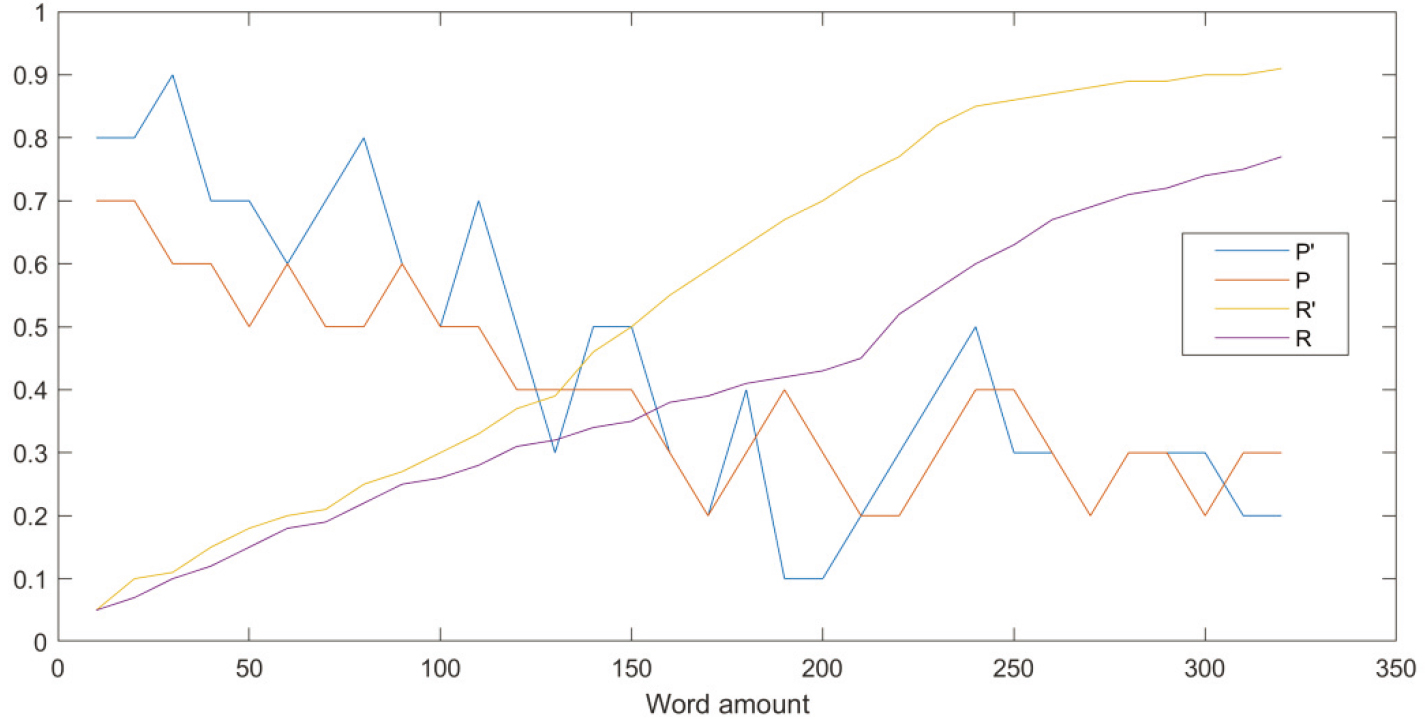
Comparison of F
Figure 1 indicates that, as word amount increases, in most cases, the precision of improved TF-IDF algorithm is higher than that of traditional TF-IDF algorithm, and the greatest precision difference between two algorithms is as high as 30%. Figure 2 shows that, as word amount increases, in most cases, the Comparing the precision, recall and By measuring the algorithm indexes like recall, precision and
A total of 5,864 scientific and technological achievements in electric power field were selected on Keyi net, to build an index database of electric power scientific and technological achievements. The 128 TFFs obtained in above section were taken as retrieval words to search in the index database of electric power scientific and technological achievements through BM25F retrieval model, and the retrieved achievements were ranked according to relevancy, then the top 60 achievements were returned to build a background library p of electric power scientific and technological achievements. Take the “power distribution equipment” in power distribution and utilization field as an example. Some of the background libraries of electric power scientific and technological achievements are displayed in Table 6.
Background libraries of “power distribution equipment” scientific and technological achievements in power distribution and utilization field (segment)
Background libraries of “power distribution equipment” scientific and technological achievements in power distribution and utilization field (segment)
The 3,267 technical demands and 5,684 scientific and technological achievements in technical demand-supply corpus were tested through the TFF-based technical demand-supply matching model. Those with feature matching degree higher than 0.5 were retained as the matching results. Taking the power distribution and utilization field as an example, the results of one technical demand is shown in Table 7. Meanwhile, the matching efficiency
in which, G
The demand-supply matching table for a technical demand based on electric power TFF (segment)
Comparison of matching efficiency before and after using the model.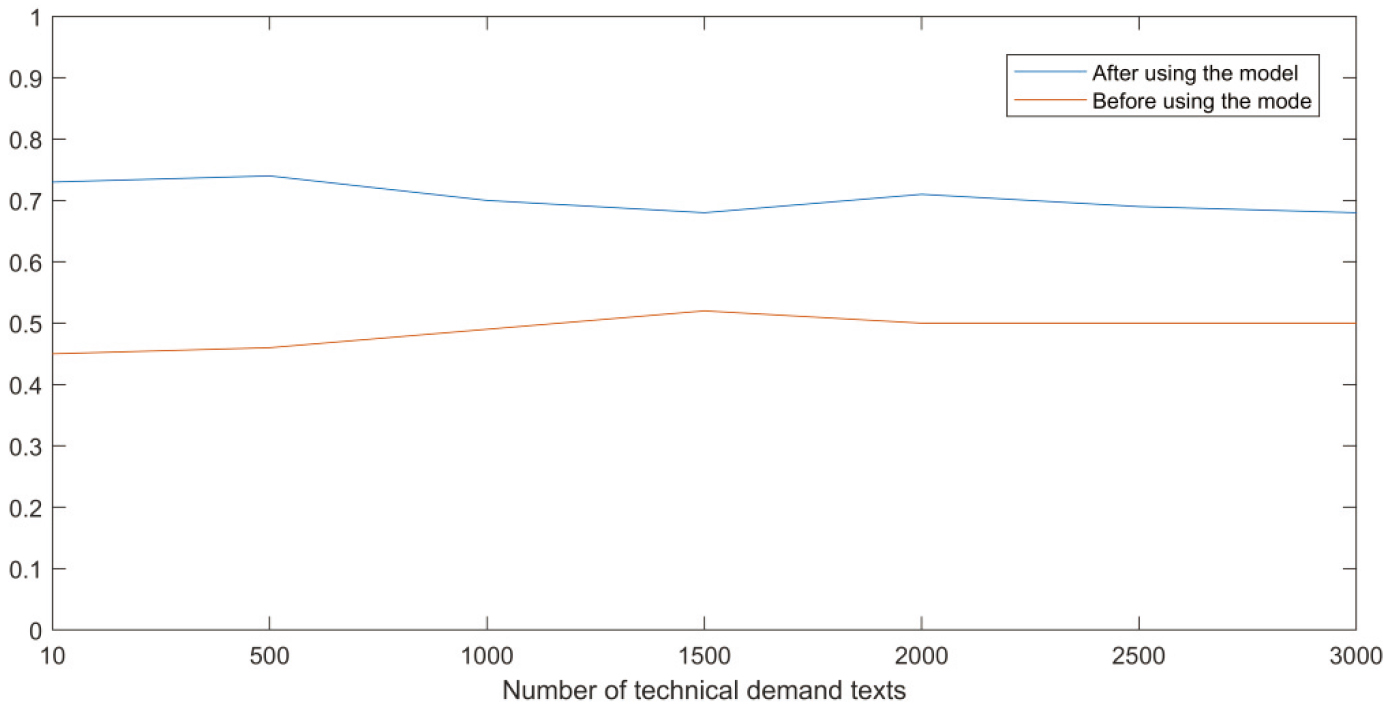
It is obtained from Fig. 2 that:
Before using the model, the maximal technical demand-supply matching efficiency is only 53.4%. After all 3,267 technical demands are matched, merely 1,702 scientific and technological achievements meet the technical demand, with a matching efficiency of 52.1%. Before using the model, the average value of technical demand-supply matching efficiency is only 47.3%, which is too low. After using the TFF-based demand-supply matching model, the maximal technical demand-supply matching efficiency increases from 53.4% to 74.1%. After all 3,267 technical demands are matched, 2,247 scientific and technological achievements meet the technical demand, with a matching efficiency of 68.8%. After using the model, the average value of technical demand-supply matching efficiency increases from 47.3% to 70.7%, which has been significantly promoted. The electric power TFF-based online demand-supply matching model improves the electric power technical demand-supply matching efficiency.
To solve the technical demand-supply matching problem in electric power technology transfer platform, this paper raised a new idea of taking TFF as matching basis for technical demand-supply matching, proposed an online demand-supply matching method based on electric power TFFs, Based on the improved TF-IDF algorithm, this paper combined BM25F algorithm to measure its accuracyand verified the effectiveness of this demand-supply matching method by application.
In this paper, the text sample data of technical demands and scientific and technological achievements were obtained from open technology transfer platform, and the data texts are not very large. This is varied from practical electric power technical demand and supply information amount to some extent. In follow-up study, more electric power technology transfer demand and supply texts will be collected as corpus, and the algorithm will be optimized continuously to improve its performance.