
Abstract
The traditional generalized linear model (GLM) can not effectively analyze discrete road traffic accidents when analyzing road traffic accidents with spatial dependence and heterogeneity. Therefore, a risk analysis method of highway traffic accidents based on geographically weighted negative binomial regression model (GWNBR) is proposed. Using geographical weighted regression (GWR) model and negative binomial regression (NB) model, this paper makes a comparative analysis of highway traffic accidents in Xi’an, including local spatial geographical weighted Poisson regression (GWPR) model and two geographical weighted negative binomial regression (GWNBRg and GWNBR) models. The corresponding model bandwidth is determined, and the performance of the model is compared based on the data of traffic environment, road characteristics, crowd characteristics and road alignment. The experimental results show that compared with the single NB model, the proposed model can effectively reduce the interference of the spatial nonstationarity of the data, and can effectively extract the risk factors affecting the accident. The coefficients of GWNBRg model and GWNBR model are positive, which are better than GLM in the mean and likelihood of the residuals. The spatial autocorrelation of the residuals is significantly reduced, and the significance level is 5%, which reduces the spatial heterogeneity of the data. The over dispersion parameter value of GWNBRg model shows a downward trend from southwest to northeast in space, which can effectively reflect the spatial relationship between traffic flow and accident rate, indicating that GWNBR model has a good effect in traffic accident risk analysis of super discrete highway. Therefore, the application of geographical weighted negative binomial regression to highway traffic accident risk prediction has a good application effect, and can effectively reduce the probability of accidents as safety prevention and early warning.
Keywords
Introduction
The traffic environment and road characteristics of the road lead to the potential danger of the road and the frequent occurrence of traffic accidents [1]. The highway drives the regional economic development and attracts more traffic. However, the continuous increase of vehicles under the existing road conditions leads to the increase in the number of highway accidents. Different traffic environments also affect the rescue difficulty of traffic accidents. The occurrence of road traffic accidents is random, and there is spatial autocorrelation between the complex environment of the accident and the main causes of the accident [2]. In addition to spatial autocorrelation, accidents are also affected by spatial heterogeneity. Spatial heterogeneity can define spatial related factors, that is, the structural relationship of regional continuous change, which is systematically changed between regions [3]. In order to improve highway traffic safety and identify highway traffic accident risk black spots, it is of great significance to establish a highway accident risk analysis model.
How to identify the road accident risk, effectively establish the road traffic accident risk analysis model, and more accurately analyze, study and judge the road accident risk has attracted the extensive attention of scholars in relevant fields. At present, experts and scholars in related fields have carried out many researches on traffic accident analysis and prediction methods. For example, Duan et al. [4] introduced Pearson coefficient to analyze the correlation between IHSDM predicted accident results and section AADT and section length. The predicted results are quite different from the actual results. Zhang et al. [5] proposed a solution algorithm based on k-shortest path. The model only considers the impact of saturation on traffic accidents, but does not consider factors such as road geometric characteristics and traffic composition. Considering the characteristics of traffic accidents and time series, Ma et al. [6] applied Markov chain algorithm to accident dynamic prediction, the results show that this method can effectively correct the relative error and has a good early warning effect for the randomness and fuzziness of accidents, but its application effect is large, which is limited by the timeliness of data information.
Aiming at the special constraints of highway traffic accidents, the negative binomial distribution model is creatively integrated into the geographically weighted regression model, and a traffic accident risk analysis method based on GWNBR model is proposed. Based on Xi’an Highway traffic accident database, a geographically weighted negative binomial regression model is established for analysis, which explains the effect of accident influencing factors on traffic accidents in special environment, and provides a basis for the interdependence between highway accidents and accident risk black spots.
Road traffic accident risk analysis method based on GWNBR model
Negative binomial distribution model
The negative binomial (NB) distribution is a statistically discrete probability distribution [7]. Because the NB distribution is improved on the basis of Poisson distribution, the study of NB distribution should begin with the derivation of Poisson regression formula. The distribution function of Poisson regression is:
In Eq. (1),
In Eq. (2),
In Eq. (3),
The distribution function after adding the error term
The functional relationship between distribution expectation and variance is as follows:
The error term
In Eq. (7),
The heterogeneity of data makes it impossible for the relationship of variables in space to be constant, and too many factors are involved, making it difficult to determine the variables of non-stationary data by global regression. Da Silva and Rodrigues [8] found through simulation experiments that the geographically weighted negative binomial regression (GWNBR) method can better realize the spatial modeling of over discrete non-stationary data than the single Poisson model and geographically weighted Poisson regression (GWPR); Yasin et al. [9] also believe that negative binomial regression can effectively overcome the problem of excessive deviation and dispersion of data in Poisson regression. Through r-shiny web application, GWNBR model is used to simulate spatial data, and it is found that it has good adaptability in application experiments, and the significance of variable data is obvious. From previous studies, it can be found that the advantage of GWNBR model is that it can better deal with the spatial representation of non-stationary data and reduce the experimental error caused by over dispersed data features. Therefore, the GWNBR model is used to model the traffic accident data, and the over dispersed parameter
In Eq. (8),
The basic idea of the GWR model is that the observation data near the point
In Eqs (9) and (10),
In Eq. (11),
In Eq. (12),
In Eq. (13),
In order to ensure the rationality and accuracy of the established model, it is necessary to check the multicollinearity and spatial autocorrelation of the independent variables of the model before establishing the regression model.
(1) Multicollinearity: When it is necessary to study the relationship between multiple independent variables and dependent variables, on the premise that the independent variables are independent of each other, the promotion or inhibition between these variables is generally explored by establishing a multiple regression model. In real life, the relationship between things may be obvious, which can be judged according to experience, but the relationship between some things may not be obvious, but it is actually related. This correlation can be called multicollinearity [11]. If you select correlated independent variables for parametric regression to establish a regression model, this violates the premise assumptions of the regression model and makes the established model unusable. Therefore, it is necessary to check the size of the multicollinearity between variables before modeling, and the tolerance and variance inflation factor (VIF) judgment method can be used to quantify the multicollinearity. The smaller the tolerance, the higher the multicollinearity. When the tolerance is less than 0.1, it is considered that there is serious multicollinearity [12]. The reciprocal of tolerance when the variance expansion factor is:
When the variance expansion factor is greater than 10, it indicates that there is serious multicollinearity.
(2) Spatial autocorrelation: It means that the distribution of things in space is not irregular, and the changes in space are not sudden changes, but slowly and evenly. Things are not independent of each other. There is a certain relationship between them. This relationship changes with the distance. The closer the distance, the stronger the relationship. When the distance is far, the degree of association is weaker. Spatial autocorrelation analysis is to judge whether there is agglomeration effect of variables in the study area through a certain method [13]. The commonly used judgment method is the global Moran’s I test. The calculation method of the global index
In Eq. (15),
Study area selection and data source
By using the traffic area model to determine the frequency of traffic accidents, the modeling techniques are compared. Taking Xi’an traffic accident data as an example, this paper discusses and compares local spatial analysis models of regional traffic flow, including non-spatial generalized linear models (GLM negative binomial model) and geographically weighted regression models (GWPR, GWNBRg, and GWNBR). The heterogeneity and spatial dependence of the impact of variables on traffic accidents [14].
In this paper, the highway traffic accident data of Xi’an is used as the reference database. The database contains 1711 highway traffic accident data in Xi’an, including the traffic environment at the accident point, traffic accident characteristic data, social and economic losses caused by the accident, etc. The data provides data information such as regional highway length, regional population, driver characteristics, vehicle characteristics and road characteristics, and provides information on all highway traffic accidents from 2015 to 2019. Use standard GIS tools, use all traffic accident information summarized by traffic districts for database integration, and realize the functions of spatial search and layer overlay according to the topological relationship of geographic entities. This study cites SAS/IML macros developed by Da Silva and Rodrigues [8], use the geographic weighted spatial model (GWPR, GWNBRg, and GWNBR) given in the SAS/IML macro to perform calculations, and use SAS to analyze the model. The explanatory variables constructed by the model are divided into four categories: traffic environment, road characteristics, crowd characteristics, and the proportion of road alignment. The statistical variables of road traffic accidents are as Table 1.
Statistical variables of highway traffic accidents
Statistical variables of highway traffic accidents
Taking age characteristics as a risk factor, the age of the person involved in a regional traffic accident can be used as a risk factor. The variables representing the age of persons involved in traffic accidents are the percentage of residents between 0 and 17 years old (representing minors involved in traffic accidents), the percentage between 18 and 59 years old (representing adults and minors involved in traffic accidents) and the percentage of population over 60 years old (representing elderly participants in traffic accidents).
According to relevant statistics, the mileage of Expressway in China accounts for 1.85% of the total mileage of highway traffic, and the number of accidents and deaths account for 7.76% and 13.54% of the total number of highway traffic accidents respectively; The accident rate and death rate of 100 km expressway are about 4.47 and 8.31 times that of ordinary highway respectively. There are many reasons that affect the occurrence of road accidents. The vehicle type, weather conditions, incident time, special road section, road mileage and other factors will increase the incidence of accidents. Some studies show that the vehicle volume, traffic flow and road conditions will interfere with the driving conditions of vehicles, and different road characteristics and road structures may affect the risk of traffic accidents. The proportion of driving accidents under different road characteristics is used to reflect the traffic accident risk of different types of road traffic accidents. In this paper, with the help of geographical weighted negative binomial regression method, the dispersion degree and correlation matrix of various variables affecting traffic accidents and traffic accident frequency are analyzed, and the variables are preliminarily selected. Through the analysis of the dispersion and correlation matrix between each variable and the frequency of traffic accidents, the variables are preliminarily selected. The correlation matrix shows that there is a significant correlation between the regional road mileage, the age of relevant personnel and the number of regional accidents; The correlation between other explanatory variables and accidents is between 0.31 (regional scope) – 0.51 (proportion of minors), in which the total length of regional roads, population, traffic flow, road mileage and so on are the main influencing factors. At the same time, the proportion of uphill and downhill vehicle accidents, the proportion of bridge vehicle accidents, the proportion of adults and explanatory variables are significantly higher than other variables. The model is used to test one of the multiple variables such as the proportion of vehicle uphill and downhill accidents, the proportion of vehicle axle accidents and the proportion of adults, and the variables with high correlation are excluded. In each group, Vif was used to evaluate multicollinearity, and the values of all variables were less than or equal to 5, indicating the presence of moderate multicollinearity.
Geographically weighted regression model coefficient estimation
A negative binomial GLM model is established for each selected non-collinear variable set, and the model with the best adjustment for ML and AIC of all variable sets is selected. Since there is a fairly high correlation (0.89) between the regional road mileage (km) and the regional population (10,000 people), these two variables were tested in two global NB models. The preliminary test adjusts the model, the RMSE of the overall regional population is 75, the log likelihood is estimated to be
Cumulative residual distribution results of population and road mileage under NB model.
Figure 1 shows the cumulative residual distribution results of population and road mileage under NB model. The magnitude of cumulative residual value has a negative correlation with the accuracy of model test variables. It can be seen from Fig. 1 that the cumulative residual value of the population basically fluctuates in the range of 0–1390 with the increase of the population. There are many fluctuation nodes before the population is 600000. When the population reaches more than 750000, the cumulative residual value is basically stable at about
The SAS/IML macro can be used to determine the optimal bandwidth of the biquadratic adaptive and Gaussian fixed kernel function, and select the bandwidth of the GWPR and GWNBRg models with the lowest AICc. In GWNBR, the definition of the optimal bandwidth (including fixed and adaptive bandwidth) uses the CV optimization criterion (AICc optimization criterion) to select the bandwidth with the highest ML. In the GWPR and GWNBRg models, the fixed core bandwidth provides a slightly lower AICc. Xi’an is located in the southern part of the plain, with alluvial plains in the north and denuded mountains in the south. The general terrain is high in the southeast, low in the northwest and southwest, in the shape of a dustpan. This makes the kernel function attenuate more severely at a fixed distance from the kernel bandwidth, so a small sub-sample will be considered to calibrate the area. This sub-sample may also lead to higher coefficient standard errors, so all local models use adaptive bandwidth. The descriptive statistics of the measured values of NB and GWR, the mean, minimum and maximum values of the model, and the first quarter and last quarter of the coefficient are as Table 2.
NB, GWPR, GWNBRg and GWNBR model coefficients
Note: PV, Avg, Min, Max, Lwr, Upr are the
Through the analysis of Table 2, it can be found that the NB coefficient has a positive effect on all the coefficients of the frequency of injury accidents. In Table 2, the average coefficient of the GWPR model is very different from the non-spatial global regression. In addition, the GWNBRg and GWNBR models have average values on coefficients close to NB. The difference between the NB coefficient and the GWPR coefficient may be due to the fact that GWPR does not take into account the excessive dispersion of data.
The regression intercept, Y_60 and R-S variables of the GWPR model are all negative. The regression intercept, Y_60 and R-S variables of the GWNBR model are all negative, and the value of the variables is smaller than that of the GWPR model. The coefficient effects of all variables in the GWNBRg model are positive.
The coefficients found in GWPR and GWNBR are abnormal. The prediction result may be caused by multicollinearity between local coefficients, rather than the need to adjust the model according to the more specific conditions of each region. The level of multicollinearity between the coefficients can be estimated by the minimum root mean square error expansion factor (referred to by the minimum root mean square error expansion factor). The VIF estimation range of GWPR model is 1.01–1.80, and the VIF estimation range of GWNBR model is 1.03–1.62, indicating that the multicollinearity between local coefficients has little influence. According to the research on the multicollinearity of spatial coefficients, this problem is not the cause of coefficient anomalies.
Aiming at the multiple tests in the geographically weighted regression box, Da Silva and Fotheringham [15] proposed the family error rate based on the correlation process and compared it with the correction scheme proposed by other scholars. They found that the correction in the traditional test can effectively avoid the false positive of the regression model. Based on this, it is considered that the abnormal GWPR and GWNBR coefficients caused by the multicollinearity of local coefficients are not affected by the multicollinearity of local coefficients after the traditional
Spatial distribution of GWPR and GWNBRg coefficients.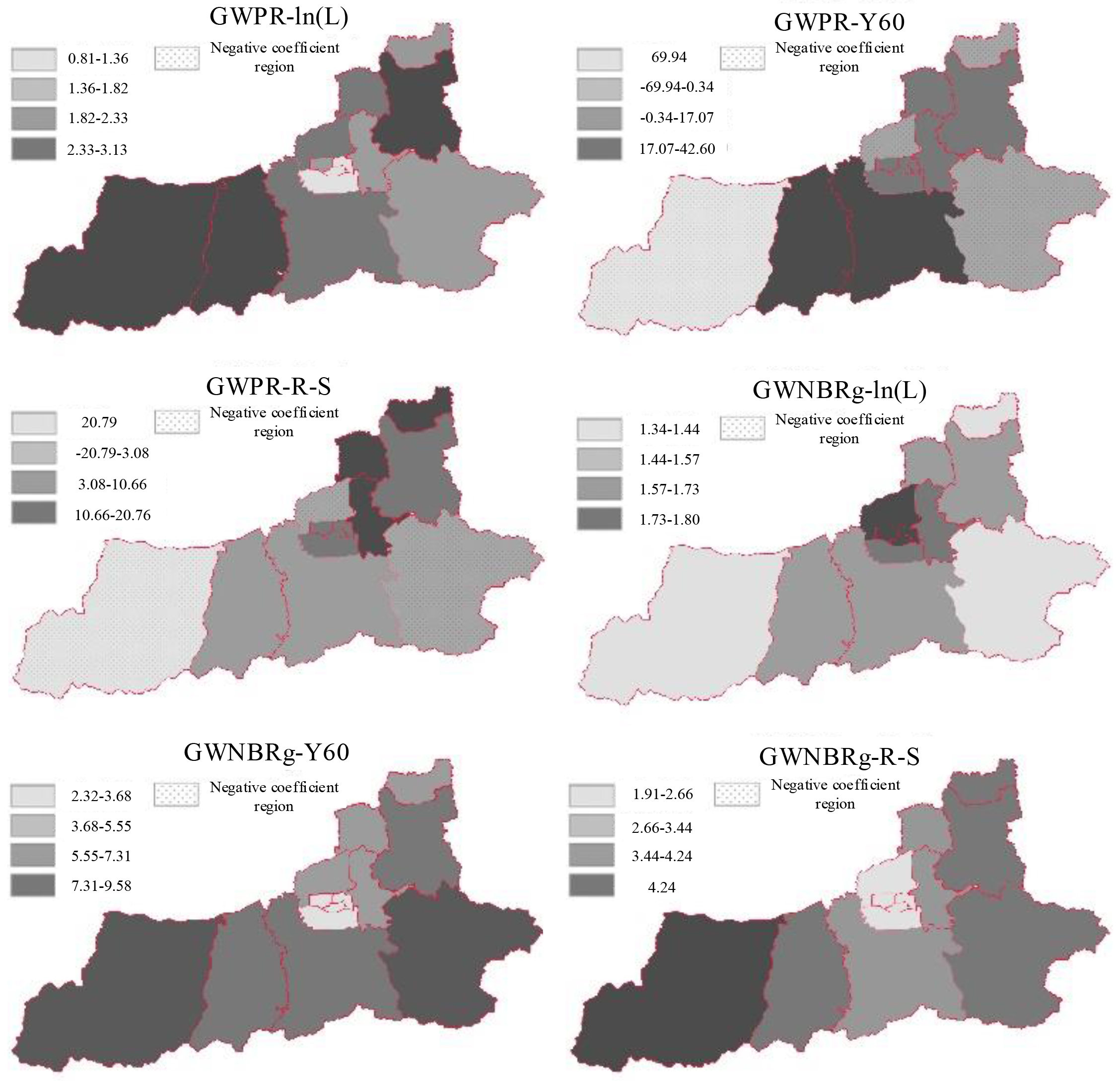
As can be seen from Fig. 2, the regression intercept and y of GWPR model and GWNBR model_60 and R-S variables are negative, and there are many low value areas and negative correlation areas in GWPR model, and the regression intercept and Y_ The maximum values of 60 and R-S variables do not exceed 4, 43 and 21. The coefficients of all variables in GWNBR model are positive, and the low value area accounts for a large proportion in the whole picture. There are some differences in the coefficients between GWPR model and GWNBR model, which may be caused by the multicollinearity between local coefficients. At the same time, it is found that there is little difference in the estimation range of the variance expansion coefficient of the two models. At the same time, the statistical significance of the model coefficient is calculated to obtain y in the GWPR model_ The variable coefficient of 60 (
Spatial distribution of GWNBR coefficients and over-dispersion parameters.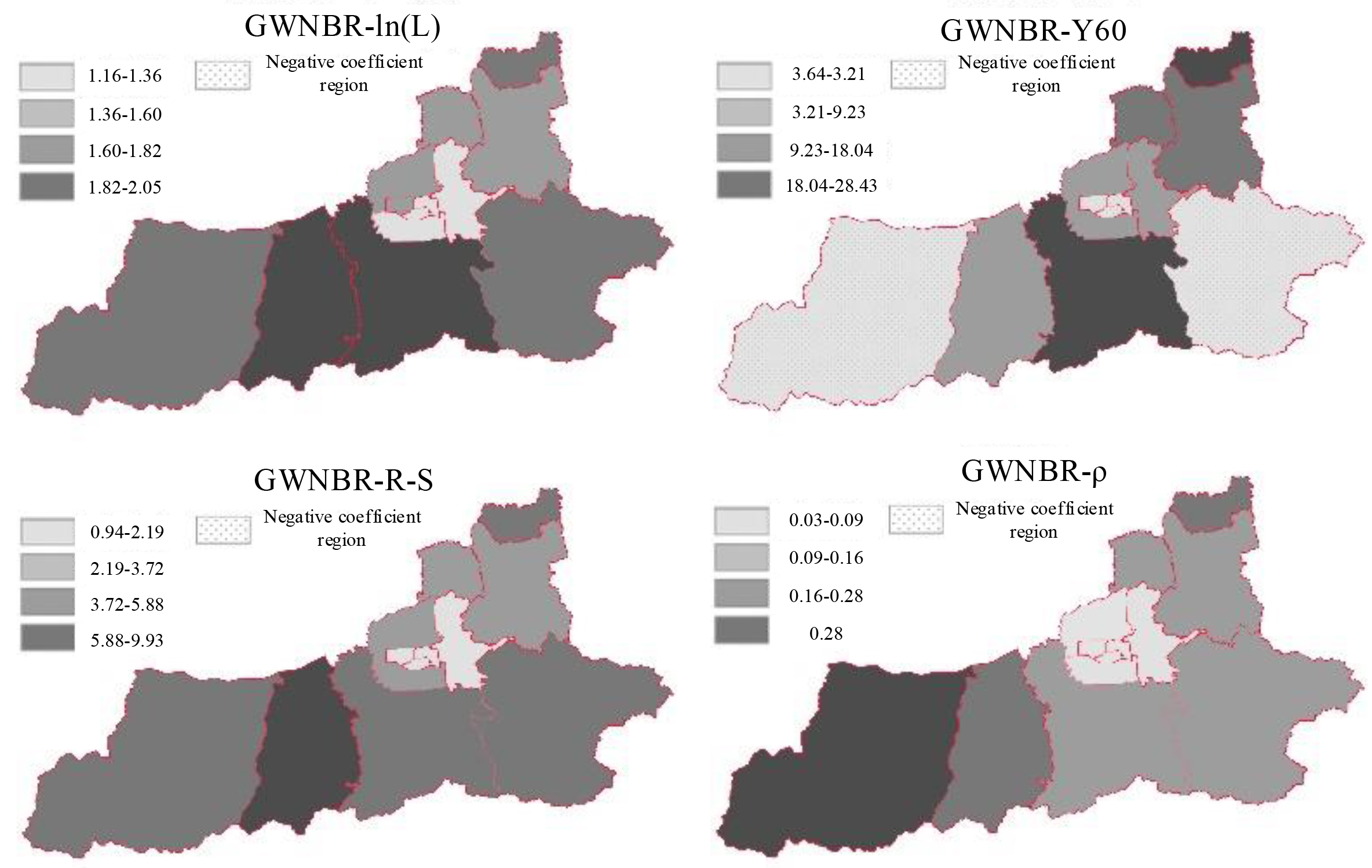
As can be seen from Fig. 3, the regression intercept and y of GWNBR model_ 60 and R-S variables are in the positive range, and the negative correlation area is less than that of GWPR model in Fig. 3. Compared with Fig. 3, the variables of the proportion of middle-aged and elderly people and the proportion of straight-line depot accidents in GWPR model in 13 regions show negative values in 4 regions and 3 regions respectively; In the GWNBR model, the variable changes to 2, and the area of 0 shows a negative value, indicating that the excessive dispersion of traffic accidents has a greater impact on the model coefficients. At the same time, it is found that the overdispersion parameter in GWNBR changes with space, and the spatial distribution is quite different. Its value shows a decreasing trend from southwest to northeast, that is, the value of overdispersion parameter is lower in the middle and Southeast, and increases in the West and north of the city. The value of the excessive dispersion coefficient is closely related to the interpretation ability between the models, and the change of high regional traffic volume will also increase the excessive dispersion parameter coefficient in the GWNBR model, which makes the model stronger in the interpretation of variable data.
Use root mean square error (RMSE), AICc criterion and ML to quantify and analyze the performance of the comparison model. RMSE can be expressed as:
In Eq. (16),
The formula in Da Silva and Fotheringham’s study is introduced [15], as shown in Eq. (17).
where
Adjustment of traffic accident model variables
According to Table 3, the NB global model has the worst adjustment effect on RMSE and ML, followed by GWNBRg, GWNBR and GWPR models. Because the local GWNBRg and GWNBR models are not easily affected by extreme values, the RMSE adjustment is worse than GWPR. The local GWNBRg and GWNBR model bandwidth size and the spatial variation of model coefficients are more uniform than the GWPR model. The best performance of AICc is the GWNBRg value of 1352, followed by NB. The performance of GWPR is poor due to excessive discrete data.
The comparison of the spatial autocorrelation values and P-values of the four models is as Table 4.
Spatial correlation of model residuals
According to Table 4, since the over-dispersion parameter used in the GWNBRg model uses a constant value
Statistical table of traffic data processing coefficients under different models
The correlation coefficient of road length coefficient has a negative correlation with the risk of road traffic accidents in this area. It can be seen from Table 5 that the accident risk in the northern part of Xi’an is higher than that in the southern part of Xi’an in terms of the spatial distribution of road length coefficient (L) of GWNBR model. The reason is that the road network in the northern part is relatively dense and there is a large gap between the northern part and the development of the southern region. In the GWPR model, the correlation coefficient in the south of the city is relatively high, and the correlation coefficient in the central and eastern regions is negatively correlated. The spatial variation of GWNBRg model is more uniform, and the correlation coefficient in the central and eastern regions is small. When moving to the southeast and southwest, the correlation coefficient gradually increases. In the GWNBR model, the correlation coefficients of the central and southwest regions are the lowest.
In this paper, GWNBR model is used to analyze the accident risk in different areas of Xi’an. Using geographical weighted regression model and negative binomial regression model, this paper makes a comparative analysis of Xi’an expressway, and then establishes a traffic accident risk assessment model. The results show that GWNBR model effectively considers the influence of risk factors on geospatial elements in residual analysis, and the spatial autocorrelation of residual is significantly reduced, with a significance level of 5%. The negative correlation coefficient area of GWNBR model is lower than that of GWPR model, and the interference between traffic accident frequency and explanatory variables is less affected by spatial heterogeneity, indicating that GWNBR model has better effect in the risk analysis of over discrete road traffic accidents. When analyzing the actual data, the spatial coefficient of the model shows a decreasing trend from south to east, indicating that the continuous reduction of traffic accident risk is also consistent with the actual situation, and has good application value and early warning function, so as to reduce the occurrence of highway accidents.